kar-dim/Watermarking-Accelerated
GitHub: kar-dim/Watermarking-Accelerated
基于GPU加速的高效图像和视频数字水印嵌入与盲检测工具,支持CUDA/OpenCL/Eigen多种后端和FFmpeg视频流处理。
Stars: 2 | Forks: 0
# 高效图像和视频水印

这是我在爱琴海大学工程学院信息与通信系统工程系撰写的毕业论文代码,题目为“利用图形处理器高效实现图像和视频的水印及水印检测算法” [链接](https://hellanicus.lib.aegean.gr/handle/11610/19672)。
# 致谢与理论基础
本实现基于 Irene G. Karybali 和 Kostas Berberidis 提出的水印算法:[基于新型感知掩蔽和盲检测方案的高效空间图像水印技术](https://www.icsd.aegean.gr/publication_files/637538981.pdf)。关于抗攻击鲁棒性的理论框架和数学证明在原始论文中有详细阐述。
本仓库提供了一个为实际环境设计的高性能实现,具有 GPU 加速、磁盘镜像支持以及通过 FFmpeg 实现的本地视频容器支持。
**注意**:本仓库包含经过高度重构和优化的原始论文实现版本,改进了算法、执行时间和功能。
已弃用的原始论文代码位于归档仓库的 old 分支。原始论文代码支持 OpenCL 和 Eigen,而本实现增加了对 CUDA 的支持。
# 概述
`-march=native`。性能提升微乎其微,为了更广泛的兼容性,我们默认使用 AVX2。 CLI 应用程序应从相应的 `settings.ini` 文件中进行参数化。以下是每个参数的详细说明: | 参数 | 描述 | |-----------------------------------|----------------------------------------------------------------------------------------------------------------------------- | | \[image\]/mode | ```[single, batch_embed, batch_detect]```:(仅限图像模式)设置图像模式选项。如果为 ```single```,应用程序将读取在 ```[image]/path]``` 中指定的图像文件,并嵌入/检测水印并打印结果。如果为 ```batch_embed``` 或 ```batch_detect```,则读取在 ```[image]/path]``` 中指定的目录,它要么为找到的所有图像文件嵌入水印,并将它们写入指定文件夹中名为 ```watermark_output``` 的新文件夹中,要么尝试检测水印并打印相关值。 | \[image\]/path | 输入图像(或批量操作的目录)的路径,用于嵌入/检测水印。这会将示例应用程序设置为 ```image mode``` | | watermark_password | 水印密码。用于生成确定性和安全(尽可能)的水印。 | | save_to_disk | ```[true/false]```:(仅限图像模式)设置为 true 以将带水印的 NVF 和预测误差文件保存到磁盘,仅在模式为 ```single``` 时有效。 | | display_fps | ```[true/false]```:设置为 true 以 FPS 显示执行时间。否则,它将以秒为单位显示执行时间。 | | p | 掩膜算法的窗口大小。所有实现都支持 ```p=3,5,7``` 和 ```9``` 的值。 | | psnr | PSNR(峰值信噪比)。值越高,图像中的水印越少,减少了噪声,但使检测更困难。 | | benchmark_loops | (仅限图像模式)多次循环算法,模拟更多工作。```100~1000``` 的值会产生一致的执行时间。仅在模式为 ```single``` 时有效。 | | opencl_device_id | ```[仅限 OpenCL / 数字]```:仅适用于 OpenCL 二进制文件。如果发现多个 OpenCL 设备,则将其设置为所需设备。如果发现一个设备,则将其设置为 0。 | **仅限视频的设置:** | 参数 | 描述 | |-----------------------------------|----------------------------------------------------------------------------------------------------------------------------- | | mode | ```[embed/detect]```:设置视频模式。两个选项都将 ```[video]/path``` 作为输入视频读取,并嵌入水印(通过 ffmpeg 编码)或尝试检测水印。 | \[video\]/path | 视频文件的路径,如果我们想为视频嵌入或检测水印。这会将示例应用程序设置为 ```video mode```,并将读取本节中描述的视频专用设置以及通用设置(```watermark_seed```、```display_fps```、```p```、```psnr``` 和 ```opencl_device_id```) | | watermark_interval | ```[数字]```:每 ```watermark_interval``` 帧嵌入或尝试检测一次水印。如果在嵌入时设置为 1,则所有帧都将嵌入水印,这会降低视频质量。如果当前帧不能被此参数整除,则对于嵌入,帧按原样传递给编码器(无水印),对于检测,帧被解码并跳过。 | | cuda_hw_decoder | ```[仅限 CUDA]```:使用 **NVDEC** 将解码卸载到 GPU。这对于 ```HEVC``` 或 ```AV1``` 视频(尤其是 4K 及以上)以及水印检测等任务**更**有效,因为软件解码器通常对于较低分辨率和不太复杂的算法(如 ```H264```)较快。有效选项为 ```hevc_cuvid```、```h264_cuvid``` 和 ```av1_cuvid```。其他解码器可能可用,如 ```vp9_cuvid```、```vc1_cuvid``` 或 ```mjpeg_cuvid```。如果硬件解码器不可用,应用程序将自动回退到 CPU 解码。| | cuda_hw_encoder | ```[仅限 CUDA: true/false]```:使用 **NVENC** 将编码卸载到 GPU。与 **NVDEC** 结合使用更有意义,但不是必需的。如果设置,则忽略 ```encode_codec_options``` 设置的编码器选项,并且必须在 ```hw_encode_options``` 部分提供有效的 nvenc 编解码器选项。 | | encode_output_path | 将此值设置为文件路径,以便从 ```[video]/path``` 参数在视频上嵌入水印,并将带水印的文件保存到磁盘。这会将示例应用程序设置为 ```video embedding mode```。如果您想从 ```video``` 参数检测水印,则注释掉此行,从而有效地将示例应用程序设置为 ```video detect mode```。 | | encode_codec_options | 这些是仅用于编码的 FFmpeg 选项。它配置编码库及其选项。示例:```-c:v libx265 -preset fast -crf 23``` 会将这些编码选项传递给 FFmpeg。| | hw_encode_options | 这些是使用 NVENC 编码的 FFmpeg 选项。仅在 `cuda_hw_encoder` 为 `true` 时使用,并覆盖 ```encode_codec_options``` 选项。示例:```-c:v hevc_nvenc -preset p6 -tune hq -cq 26 -b:v 0``` 是用于 CPU 编码器的示例的 NVENC 等效项。注意:编码和解码是分开的,我们可以用 CPU 解码并用 NVENC 编码(反之亦然),当然我们也可以两者都做! # 用于视频编码的 FFmpeg 命令 以下 FFmpeg 命令用于编码新视频,同时保留原始输入的元数据、字幕和音轨。它解码输入视频,嵌入水印,并将结果帧传递到标准输入 进行编码,同时按原样从原始输入文件复制音频/字幕。您可以通过 ```encode_codec_options``` 选项自定义 **视频编解码器** 编码设置(编解码器、CRF、预设等),如上所述。 ``` ffmpeg -y -f rawvideo -pix_fmt
-s x
-r
-i -
-i
-c:s copy -c:a copy
-map 1:s? -map 0:v -map 1:a?
-max_interleave_delta 0
-vf "" (OPTIONAL)
-color_range:v:0
```
### 说明:
- `-f rawvideo -pix_fmt `:指定原始像素格式,为 ```yuv420p``` 或 ```yuvj420p```(有限或全范围,从输入中提取)。
- `-s x`:指定帧大小(从输入中提取)。
- `-r `:视频的帧率(从输入中提取)。
- `-i -`:接受来自 stdin 的原始视频。
- `-i `:**用户提供**:原始输入文件。
- ``:**用户提供**:编码器选项,如编解码器、预设和质量选项。如果请求 CUDA NVENC,则从设置文件中读取 ```hw_encode_options``` 参数,否则读取 ```encode_codec_options```。
- `-c:s copy -c:a copy`:复制字幕和音频流而不重新编码。
- `-map 1:s? -map 0:v -map 1:a?`:映射原始输入的字幕/音频,以及来自 stdin 的视频。
- `-max_interleave_delta 0`:减少潜在的交错延迟问题。
- `-vf ""`:应用于旋转输出视频的过滤器(可选,可能未设置,从输入中提取)。
- `-color_range:v:0 `:设置输出颜色范围元数据以帮助视频播放器(提供值 "tv" 或 "pc",从输入中提取)。
- ``:**用户提供**:最终视频的输出文件路径。
**注意:**
- 只有恒定帧率 (CFR) 对输入视频按预期工作。如果输入视频是可变帧率 (VFR),输出文件可能会出现音频/字幕不同步的问题。
- 10 位视频支持处于实验阶段:非 HDR 的 10 位完全受支持。HDR 位通过 CPU 色调映射 到 SDR,FFMPEG 尚不支持硬件加速的色调映射。编码始终为 8 位。
# 如何构建
本项目使用 **Visual Studio** 构建,由一个 **包含各种项目的解决方案** 组成。
- Watermarking-Impl:本项目的核心,实现了每个后端的算法。它还实现了使用 OpenMP 的快速、高效、安全和确定性的水印生成(仅限基于 CPU)。它作为 **静态库** 构建。
- Watermarking-CLI:与核心项目交互以在图像和视频中嵌入和检测水印的示例命令行应用程序。
- Watermarking-BenchUI:基准测试项目。它与核心项目交互并评估图像水印的性能。它使用 Qt 作为 UI。
- Watermarking-Tests:核心项目的基本测试。
### 解决方案配置
解决方案提供多种构建配置,每个配置针对特定的后端:
| 配置 | 后端 | 说明 |
|------------------|-------------|---------------------------------------------|
| `CUDA_Release` | CUDA | 推荐用于具有 NVIDIA GPU 的系统。比 OpenCL 后端更快,增加了对 CUDA 硬件加速视频解码的支持 |
| `CUDA_ReleaseDist` | CUDA | 发布 CUDA 构建,包含最常见架构的 SASS (Fatbin)。具体包括:RTX 2000、RTX 3000、RTX 4000 和 RTX 5000 SASS。仅在我们想要分发可执行文件时使用。相反,`CUDA_Release` 仅定义一种架构以加快构建速度 (RTX 4000)。
| `CUDA_Debug` | CUDA | 用于调试 CUDA 特定代码 |
| `OPENCL_Release` | OpenCL | 推荐用于没有 NVIDIA GPU 的系统。提供跨各种硬件(NVIDIA、AMD、Intel 等)的 GPU 加速,并提供比 CPU 后端更好的性能,尽管通常比 CUDA 实现慢 |
| `EIGEN_Release` | Eigen | 优化的基于 CPU 的实现,用于实现其最大兼容性。使用 Clang 编译器 以获得最大性能 [ ](https://clang.llvm.org/) |
| `EIGEN_Debug` | Eigen | 用于调试 CPU 实现 [](https://clang.llvm.org/) |
## 构建说明
1. 必须安装 **Git**,并且需要 **Git LFS** 来下载大型库二进制依赖项。使用以下命令安装:`git lfs install`。
2. 克隆此仓库:`git clone https://github.com/kar-dim/Watermarking-Accelerated`。
3. 在 **Visual Studio 2022**(或更高版本)中打开 `.sln` 文件。
4. 在 **解决方案配置** 下拉菜单(顶部工具栏)中,选择您的配置(例如 `CUDA_Release`)或选择 `批生成` 并选择您想要构建的配置。
5. 通过 **生成 > 生成解决方案** 构建解决方案。
我们将所有必要的 DLL 与预构建的二进制文件捆绑在一起,因此应用程序开箱即用,无需本地 ArrayFire 或 CImg 开发环境。
| 后端 | 依赖项 |
|---------|--------------|
| **All** | `FFmpeg (所有 libav*.dll 二进制文件)` |
| **CUDA** | `FreeImage.dll`, `afcuda.dll`, `cublas64_12.dll`, `cublasLt64_12.dll`, `cufft64_11.dll`, `cusolver64_11.dll`, `cusparse64_12.dll`, `nvrtc64_120_0.dll`, `nvJitLink_120_0.dll` |
| **OpenCL** | `FreeImage.dll`, `afopencl.dll`, `mkl_rt.2.dll` |
| **Eigen** | `zlib1.dll`, `libpng16.dll`, `jpeg62.dll`, `tiff.dll`, `libomp.dll`, `libwebp.lib` (静态库) |
**注意:**
- OpenCL 实现:[OpenCL Headers](https://github.com/KhronosGroup/OpenCL-Headers)、[OpenCL C++ Bindings](https://github.com/KhronosGroup/OpenCL-CLHPP) 和 [OpenCL Library file](https://github.com/KhronosGroup/OpenCL-SDK) 已包含并为此项目配置。
- CUDA 实现:构建需要 NVIDIA CUDA Toolkit。支持最低 Compute Capability 7.0 (sm_75) 或更新的 GPU,CUDA Toolkit 10.0 或更新。
- CPU 实现:图像库(libjpeg、libpng、libtiff 等)已包含并由 CImg 内部用于加载和保存图像。
- ArrayFire 应全局安装,使用默认安装选项。环境变量 "AF_PATH" 将自动定义。
- FFmpeg 必须存在于系统 PATH 中(预构建的二进制文件已包含 FFmpeg 二进制文件和 DLL)。
# 使用的库/工具
- [Eigen](https://eigen.tuxfamily.org/index.php?title=Main_Page):用于线性代数的 C++ 模板库。
- [ArrayFire](https://arrayfire.org):用于快速 GPU 计算的 C++ 库。
- [FFmpeg](https://www.ffmpeg.org/):用于录制、转换和流式传输音频和视频的完整跨平台解决方案。
- [CImg](https://cimg.eu/):用于图像处理的 C++ 库。
- [inih](https://github.com/jtilly/inih):用于解析 .ini 配置文件的轻量级 C++ 库。
- [cub](https://github.com/NVIDIA/cccl):专为光速并行算法设计的底层 CUDA 库。用于设备级、块级和 warp 级归约。
- [Intel VTune Profiler](https://www.intel.com/content/www/us/en/develop/tools/vtune-profiler.html) 和 [AMD uProf](https://developer.amd.com/amd-uprof/):用于分析 CPU 性能。
- [NVIDIA Nsight Systems](https://developer.nvidia.com/nsight-systems) 和 [NVIDIA Compute](https://developer.nvidia.com/nsight-compute):用于分析整体系统级 CUDA 性能,并单独分析具有详细性能指标的特定 CUDA 内核。
# 比较
下面我们包含了原始图像(左)与基于 NVF 掩膜(中)和提出的预测误差掩膜(右)的最终水印图像之间的一些比较。图像已放大以便进行比较。
](https://clang.llvm.org/) |
| `EIGEN_Debug` | Eigen | 用于调试 CPU 实现 [](https://clang.llvm.org/) |
## 构建说明
1. 必须安装 **Git**,并且需要 **Git LFS** 来下载大型库二进制依赖项。使用以下命令安装:`git lfs install`。
2. 克隆此仓库:`git clone https://github.com/kar-dim/Watermarking-Accelerated`。
3. 在 **Visual Studio 2022**(或更高版本)中打开 `.sln` 文件。
4. 在 **解决方案配置** 下拉菜单(顶部工具栏)中,选择您的配置(例如 `CUDA_Release`)或选择 `批生成` 并选择您想要构建的配置。
5. 通过 **生成 > 生成解决方案** 构建解决方案。
我们将所有必要的 DLL 与预构建的二进制文件捆绑在一起,因此应用程序开箱即用,无需本地 ArrayFire 或 CImg 开发环境。
| 后端 | 依赖项 |
|---------|--------------|
| **All** | `FFmpeg (所有 libav*.dll 二进制文件)` |
| **CUDA** | `FreeImage.dll`, `afcuda.dll`, `cublas64_12.dll`, `cublasLt64_12.dll`, `cufft64_11.dll`, `cusolver64_11.dll`, `cusparse64_12.dll`, `nvrtc64_120_0.dll`, `nvJitLink_120_0.dll` |
| **OpenCL** | `FreeImage.dll`, `afopencl.dll`, `mkl_rt.2.dll` |
| **Eigen** | `zlib1.dll`, `libpng16.dll`, `jpeg62.dll`, `tiff.dll`, `libomp.dll`, `libwebp.lib` (静态库) |
**注意:**
- OpenCL 实现:[OpenCL Headers](https://github.com/KhronosGroup/OpenCL-Headers)、[OpenCL C++ Bindings](https://github.com/KhronosGroup/OpenCL-CLHPP) 和 [OpenCL Library file](https://github.com/KhronosGroup/OpenCL-SDK) 已包含并为此项目配置。
- CUDA 实现:构建需要 NVIDIA CUDA Toolkit。支持最低 Compute Capability 7.0 (sm_75) 或更新的 GPU,CUDA Toolkit 10.0 或更新。
- CPU 实现:图像库(libjpeg、libpng、libtiff 等)已包含并由 CImg 内部用于加载和保存图像。
- ArrayFire 应全局安装,使用默认安装选项。环境变量 "AF_PATH" 将自动定义。
- FFmpeg 必须存在于系统 PATH 中(预构建的二进制文件已包含 FFmpeg 二进制文件和 DLL)。
# 使用的库/工具
- [Eigen](https://eigen.tuxfamily.org/index.php?title=Main_Page):用于线性代数的 C++ 模板库。
- [ArrayFire](https://arrayfire.org):用于快速 GPU 计算的 C++ 库。
- [FFmpeg](https://www.ffmpeg.org/):用于录制、转换和流式传输音频和视频的完整跨平台解决方案。
- [CImg](https://cimg.eu/):用于图像处理的 C++ 库。
- [inih](https://github.com/jtilly/inih):用于解析 .ini 配置文件的轻量级 C++ 库。
- [cub](https://github.com/NVIDIA/cccl):专为光速并行算法设计的底层 CUDA 库。用于设备级、块级和 warp 级归约。
- [Intel VTune Profiler](https://www.intel.com/content/www/us/en/develop/tools/vtune-profiler.html) 和 [AMD uProf](https://developer.amd.com/amd-uprof/):用于分析 CPU 性能。
- [NVIDIA Nsight Systems](https://developer.nvidia.com/nsight-systems) 和 [NVIDIA Compute](https://developer.nvidia.com/nsight-compute):用于分析整体系统级 CUDA 性能,并单独分析具有详细性能指标的特定 CUDA 内核。
# 比较
下面我们包含了原始图像(左)与基于 NVF 掩膜(中)和提出的预测误差掩膜(右)的最终水印图像之间的一些比较。图像已放大以便进行比较。


 # 基准测试
本节包括三个后端之间的性能比较:CPU (Eigen)、CUDA 和 OpenCL。基准测试测量了水印算法在各种分辨率(480p 到 4K)和窗口大小(p=3,5,7,9)下的吞吐量(以每秒帧数 FPS 为单位)。结果也可在 [Releases](https://github.com/kar-dim/Watermarking-Accelerated/releases) 部分的 `time_comparisons.zip` 文件中找到。它们是通过在 ```single image``` 模式下运行 CLI 并循环 ```1000``` 次以确保稳定性而生成的,针对 ```samples``` 目录(在 Releases 中)中使用的每个图像。
## 测试环境
所有基准测试均在以下硬件配置上进行:
- CPU: AMD Ryzen 7 7800X3D (8 核)
- GPU: NVIDIA RTX 4070 SUPER (12 GB VRAM)
- RAM: 32 GB DDR5 @ 6000 MHz (2x16GB)
## 方法论
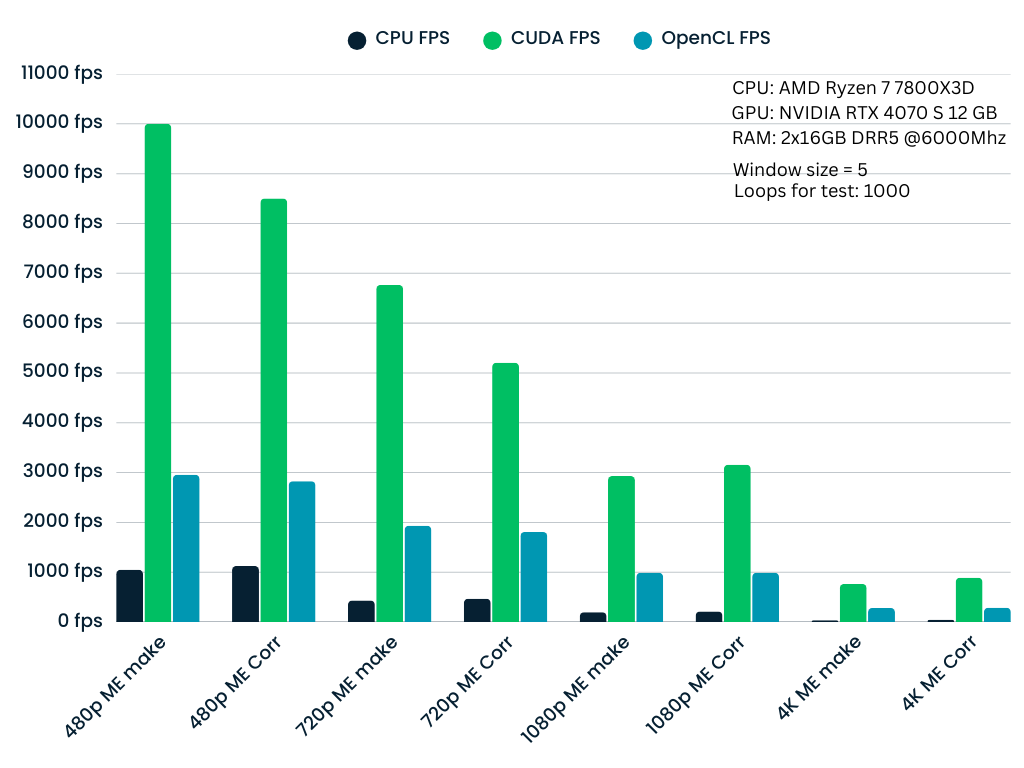
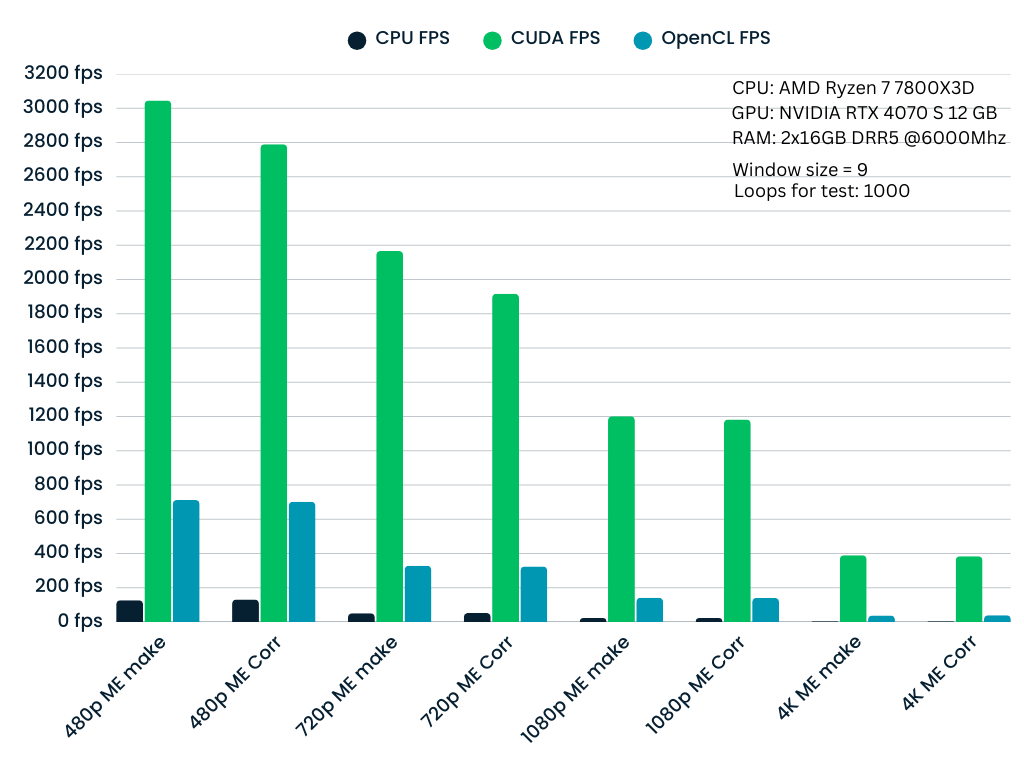
测试以 1000 次迭代的循环计数执行,以确保统计稳定性。下图显示了嵌入(ME make)和相关(ME Corr)阶段的性能扩展。
## 观察结果
- CUDA:始终提供最高的吞吐量,是实时应用的理想选择。
- OpenCL:作为中间地带,在 CPU 之上提供良好的加速,同时保持跨非 NVIDIA 硬件(AMD、Intel 等)的可移植性。其主要目的是将工作从 CPU 卸载到 GPU,以释放 CPU 用于其他任务(如视频编码或批处理)。
- CPU:作为后备实现。虽然较慢,但它针对 CPU 架构进行了优化,并确保在没有专用 GPU 的系统上的兼容性。
- 窗口大小 (p) 的影响:随着窗口大小的增加,计算复杂度呈二次方增长。
- p=3(小窗口):极高的吞吐量。
- p=9(大窗口):由于更重的矩阵构建和求解步骤(80×80 线性系统),吞吐量自然会下降,但由于 Tensor Cores 和独家功能(warp shuffles、快速原子操作),CUDA 实现仍保持实时性能。
- 分辨率扩展:性能与像素数成反比。然而,即使在 4K 分辨率下,GPU 实现对于交互式帧率仍然可行,而 CPU 实现成为瓶颈。
p = 3 | p = 5
:-------------------------:|:-------------------------:
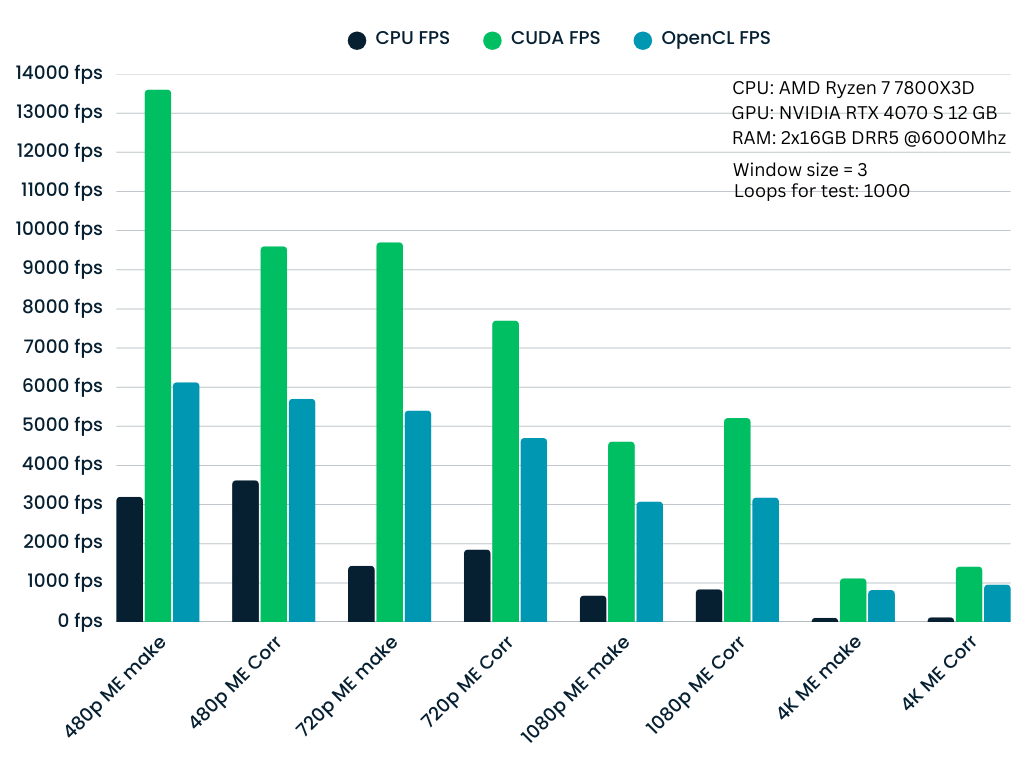 | 
p = 7 | p = 9
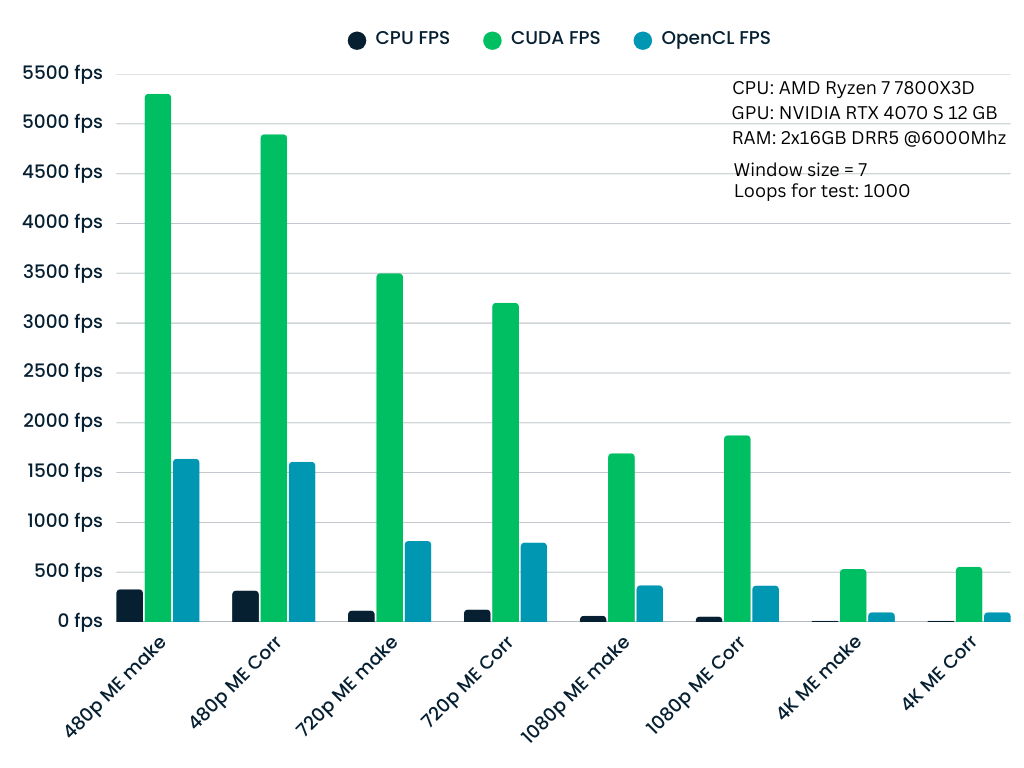 | 
# 基准测试 UI
基准测试屏幕 | 结果屏幕
:-------------------------:|:-------------------------:
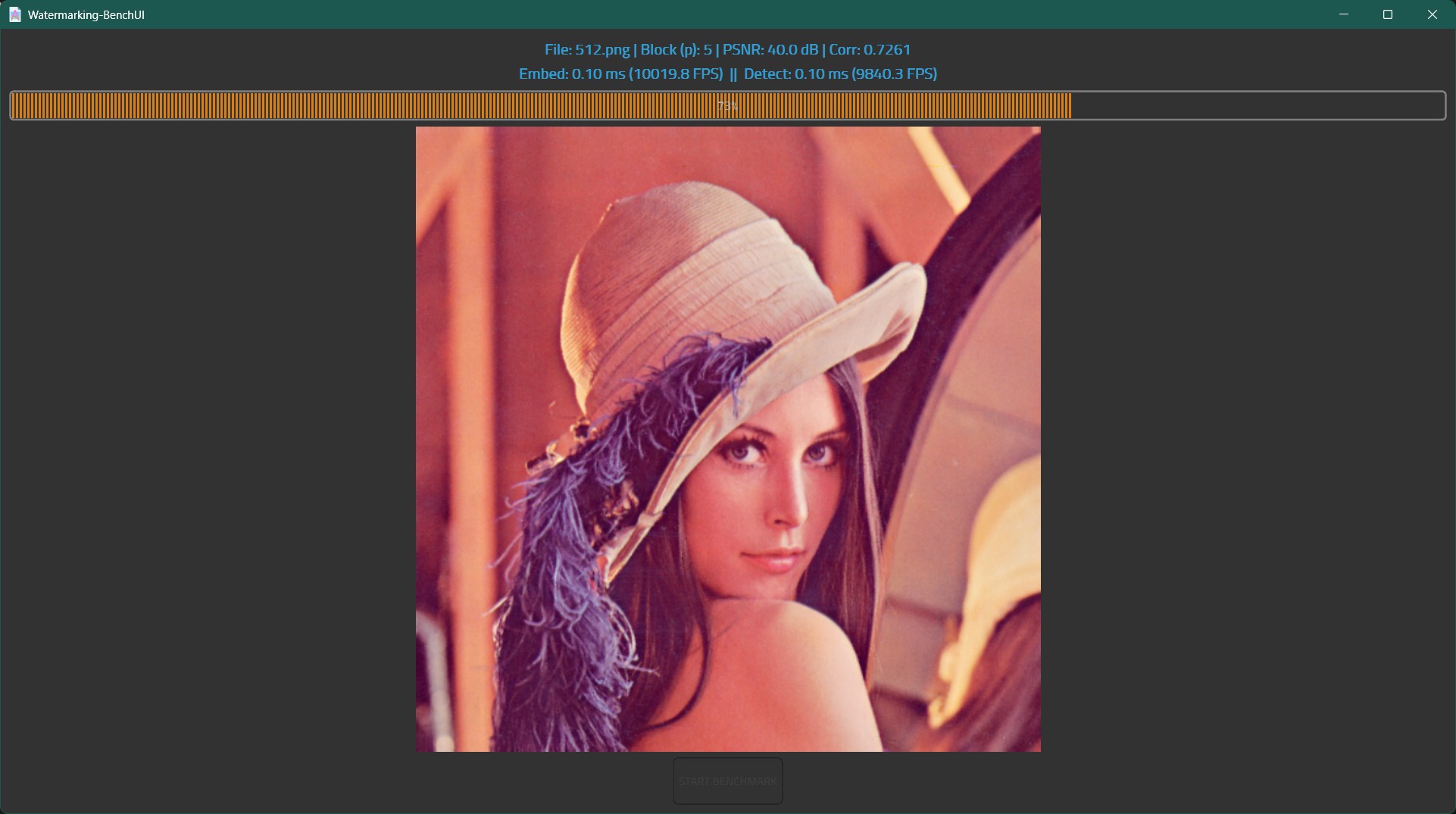 | 
 | 
# 基准测试
本节包括三个后端之间的性能比较:CPU (Eigen)、CUDA 和 OpenCL。基准测试测量了水印算法在各种分辨率(480p 到 4K)和窗口大小(p=3,5,7,9)下的吞吐量(以每秒帧数 FPS 为单位)。结果也可在 [Releases](https://github.com/kar-dim/Watermarking-Accelerated/releases) 部分的 `time_comparisons.zip` 文件中找到。它们是通过在 ```single image``` 模式下运行 CLI 并循环 ```1000``` 次以确保稳定性而生成的,针对 ```samples``` 目录(在 Releases 中)中使用的每个图像。
## 测试环境
所有基准测试均在以下硬件配置上进行:
- CPU: AMD Ryzen 7 7800X3D (8 核)
- GPU: NVIDIA RTX 4070 SUPER (12 GB VRAM)
- RAM: 32 GB DDR5 @ 6000 MHz (2x16GB)
## 方法论
测试以 1000 次迭代的循环计数执行,以确保统计稳定性。下图显示了嵌入(ME make)和相关(ME Corr)阶段的性能扩展。
## 观察结果
- CUDA:始终提供最高的吞吐量,是实时应用的理想选择。
- OpenCL:作为中间地带,在 CPU 之上提供良好的加速,同时保持跨非 NVIDIA 硬件(AMD、Intel 等)的可移植性。其主要目的是将工作从 CPU 卸载到 GPU,以释放 CPU 用于其他任务(如视频编码或批处理)。
- CPU:作为后备实现。虽然较慢,但它针对 CPU 架构进行了优化,并确保在没有专用 GPU 的系统上的兼容性。
- 窗口大小 (p) 的影响:随着窗口大小的增加,计算复杂度呈二次方增长。
- p=3(小窗口):极高的吞吐量。
- p=9(大窗口):由于更重的矩阵构建和求解步骤(80×80 线性系统),吞吐量自然会下降,但由于 Tensor Cores 和独家功能(warp shuffles、快速原子操作),CUDA 实现仍保持实时性能。
- 分辨率扩展:性能与像素数成反比。然而,即使在 4K 分辨率下,GPU 实现对于交互式帧率仍然可行,而 CPU 实现成为瓶颈。
p = 3 | p = 5
:-------------------------:|:-------------------------:
 | 
p = 7 | p = 9
 | 
# 基准测试 UI
基准测试屏幕 | 结果屏幕
:-------------------------:|:-------------------------:
 | 
 | 





`-march=native`。性能提升微乎其微,为了更广泛的兼容性,我们默认使用 AVX2。 CLI 应用程序应从相应的 `settings.ini` 文件中进行参数化。以下是每个参数的详细说明: | 参数 | 描述 | |-----------------------------------|----------------------------------------------------------------------------------------------------------------------------- | | \[image\]/mode | ```[single, batch_embed, batch_detect]```:(仅限图像模式)设置图像模式选项。如果为 ```single```,应用程序将读取在 ```[image]/path]``` 中指定的图像文件,并嵌入/检测水印并打印结果。如果为 ```batch_embed``` 或 ```batch_detect```,则读取在 ```[image]/path]``` 中指定的目录,它要么为找到的所有图像文件嵌入水印,并将它们写入指定文件夹中名为 ```watermark_output``` 的新文件夹中,要么尝试检测水印并打印相关值。 | \[image\]/path | 输入图像(或批量操作的目录)的路径,用于嵌入/检测水印。这会将示例应用程序设置为 ```image mode``` | | watermark_password | 水印密码。用于生成确定性和安全(尽可能)的水印。 | | save_to_disk | ```[true/false]```:(仅限图像模式)设置为 true 以将带水印的 NVF 和预测误差文件保存到磁盘,仅在模式为 ```single``` 时有效。 | | display_fps | ```[true/false]```:设置为 true 以 FPS 显示执行时间。否则,它将以秒为单位显示执行时间。 | | p | 掩膜算法的窗口大小。所有实现都支持 ```p=3,5,7``` 和 ```9``` 的值。 | | psnr | PSNR(峰值信噪比)。值越高,图像中的水印越少,减少了噪声,但使检测更困难。 | | benchmark_loops | (仅限图像模式)多次循环算法,模拟更多工作。```100~1000``` 的值会产生一致的执行时间。仅在模式为 ```single``` 时有效。 | | opencl_device_id | ```[仅限 OpenCL / 数字]```:仅适用于 OpenCL 二进制文件。如果发现多个 OpenCL 设备,则将其设置为所需设备。如果发现一个设备,则将其设置为 0。 | **仅限视频的设置:** | 参数 | 描述 | |-----------------------------------|----------------------------------------------------------------------------------------------------------------------------- | | mode | ```[embed/detect]```:设置视频模式。两个选项都将 ```[video]/path``` 作为输入视频读取,并嵌入水印(通过 ffmpeg 编码)或尝试检测水印。 | \[video\]/path | 视频文件的路径,如果我们想为视频嵌入或检测水印。这会将示例应用程序设置为 ```video mode```,并将读取本节中描述的视频专用设置以及通用设置(```watermark_seed```、```display_fps```、```p```、```psnr``` 和 ```opencl_device_id```) | | watermark_interval | ```[数字]```:每 ```watermark_interval``` 帧嵌入或尝试检测一次水印。如果在嵌入时设置为 1,则所有帧都将嵌入水印,这会降低视频质量。如果当前帧不能被此参数整除,则对于嵌入,帧按原样传递给编码器(无水印),对于检测,帧被解码并跳过。 | | cuda_hw_decoder | ```[仅限 CUDA]```:使用 **NVDEC** 将解码卸载到 GPU。这对于 ```HEVC``` 或 ```AV1``` 视频(尤其是 4K 及以上)以及水印检测等任务**更**有效,因为软件解码器通常对于较低分辨率和不太复杂的算法(如 ```H264```)较快。有效选项为 ```hevc_cuvid```、```h264_cuvid``` 和 ```av1_cuvid```。其他解码器可能可用,如 ```vp9_cuvid```、```vc1_cuvid``` 或 ```mjpeg_cuvid```。如果硬件解码器不可用,应用程序将自动回退到 CPU 解码。| | cuda_hw_encoder | ```[仅限 CUDA: true/false]```:使用 **NVENC** 将编码卸载到 GPU。与 **NVDEC** 结合使用更有意义,但不是必需的。如果设置,则忽略 ```encode_codec_options``` 设置的编码器选项,并且必须在 ```hw_encode_options``` 部分提供有效的 nvenc 编解码器选项。 | | encode_output_path | 将此值设置为文件路径,以便从 ```[video]/path``` 参数在视频上嵌入水印,并将带水印的文件保存到磁盘。这会将示例应用程序设置为 ```video embedding mode```。如果您想从 ```video``` 参数检测水印,则注释掉此行,从而有效地将示例应用程序设置为 ```video detect mode```。 | | encode_codec_options | 这些是仅用于编码的 FFmpeg 选项。它配置编码库及其选项。示例:```-c:v libx265 -preset fast -crf 23``` 会将这些编码选项传递给 FFmpeg。| | hw_encode_options | 这些是使用 NVENC 编码的 FFmpeg 选项。仅在 `cuda_hw_encoder` 为 `true` 时使用,并覆盖 ```encode_codec_options``` 选项。示例:```-c:v hevc_nvenc -preset p6 -tune hq -cq 26 -b:v 0``` 是用于 CPU 编码器的示例的 NVENC 等效项。注意:编码和解码是分开的,我们可以用 CPU 解码并用 NVENC 编码(反之亦然),当然我们也可以两者都做! # 用于视频编码的 FFmpeg 命令 以下 FFmpeg 命令用于编码新视频,同时保留原始输入的元数据、字幕和音轨。它解码输入视频,嵌入水印,并将结果帧传递到标准输入 进行编码,同时按原样从原始输入文件复制音频/字幕。您可以通过 ```encode_codec_options``` 选项自定义 **视频编解码器** 编码设置(编解码器、CRF、预设等),如上所述。 ``` ffmpeg -y -f rawvideo -pix_fmt
Resolution: 512x152, p=5, PSNR=40dB
Resolution: 1280x720, p=5, PSNR=45dB
Resolution: 3840x2160, p=5, PSNR=40dB
标签:C++, CUDA, DNS 反向解析, FFmpeg, IP 地址批量处理, Vectored Exception Handling, Veh, 信息隐藏, 图像处理, 图像水印, 多媒体安全, 并行计算, 感知掩蔽, 数字水印, 数据擦除, 毕业论文, 爱琴海大学, 盲检测, 空间域水印, 算法实现, 视频处理, 视频水印, 高性能计算