NVIDIA-NeMo/Megatron-Bridge
GitHub: NVIDIA-NeMo/Megatron-Bridge
连接 Hugging Face 与 Megatron-Core 的高性能大模型训练库,支持双向权重转换、分布式预训练和 LoRA 微调。
Stars: 730 | Forks: 365
# NeMo Megatron Bridge
[](https://codecov.io/github/NVIDIA-NeMo/Megatron-Bridge)
[](https://github.com/NVIDIA-NeMo/Megatron-Bridge/actions/workflows/cicd-main.yml)
[](https://www.python.org/downloads/release/python-3100/)
[](https://github.com/NVIDIA-NeMo/Megatron-Bridge/stargazers/)
[文档](https://docs.nvidia.com/nemo/megatron-bridge/latest/) | [支持的模型](#supported-models) | [示例](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/examples) | [贡献](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/CONTRIBUTING.md)
## 📣 新闻
* [12/16/2025] [Mind Lab](https://macaron.im/mindlab) 成功使用 Megatron-bridge 和 [VeRL](https://github.com/volcengine/verl) 在 64 张 H800 上训练了万亿参数模型的 GRPO Lora - 参见他们的[技术博客](https://macaron.im/mindlab/research/building-trillion-parameter-reasoning-rl-with-10-gpus)。
* [12/15/2025] 对 [NVIDIA-NeMotron-3-Nano-30B-A3B-FP8](https://huggingface.co/nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-FP8) 提供第 0 天支持 和自定义 NGC 容器:[nvcr.io/nvidia/nemo:25.11.nemotron_3_nano](https://catalog.ngc.nvidia.com/orgs/nvidia/containers/nemo?version=25.11.nemotron_3_nano)
## 概述
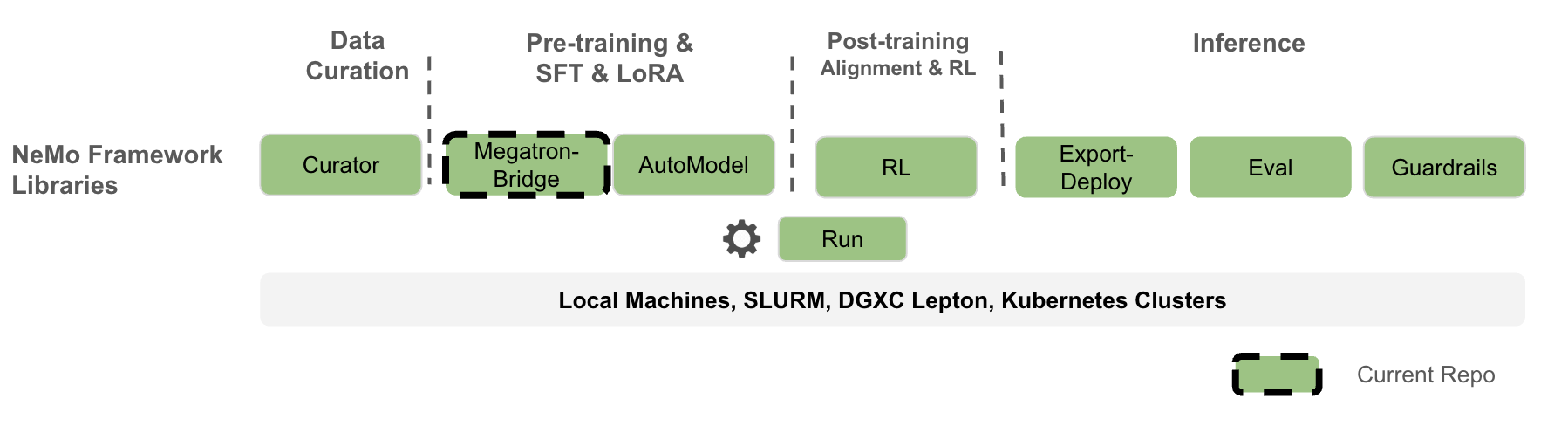
NeMo Megatron Bridge 是 [NeMo Framework](https://github.com/NVIDIA-NeMo) 中的一个 PyTorch-native 库,为流行的 LLM 和 VLM 模型提供预训练、SFT 和 LoRA 支持。它充当了 🤗 Hugging Face 和 [Megatron Core](https://github.com/NVIDIA/Megatron-LM/tree/main/megatron/core) 之间强大的**桥梁、转换和验证层**。它提供了这些格式之间的双向 checkpoint 转换,使其他项目能够利用 Megatron Core 的并行能力,或将模型导出用于各种推理引擎。该 bridge 包含内置的验证机制,以确保转换的准确性以及不同模型格式下 checkpoint 的完整性。
在该 bridge 之上,NeMo Megatron Bridge 提供了一个高性能且可扩展的 PyTorch-native 训练循环,利用 [Megatron Core](https://github.com/NVIDIA/Megatron-LM/tree/main/megatron/core) 提供最先进的训练吞吐量。它支持预训练和微调,具备 tensor 和 pipeline 并行以及混合精度(FP8, BF16, FP4 等)等特性。用户可以使用现有的 🤗 Hugging Face 模型,也可以定义自定义 PyTorch 模型,以实现灵活的端到端工作流。
NeMo Megatron Bridge 是对[先前 NeMo](https://github.com/NVIDIA/NeMo) 训练栈的重构,采用了 PyTorch-native 训练循环,为开发者提供了更大的灵活性和可定制性。
## 🔧 安装
### 🐳 NeMo Framework 容器
[NeMo Framework 容器](https://catalog.ngc.nvidia.com/orgs/nvidia/containers/nemo/tags) 提供了最佳体验、最高性能和完整的功能支持。获取最新的 $TAG 并运行以下命令来启动容器:
```
docker run --rm -it -w /workdir -v $(pwd):/workdir \
--entrypoint bash \
--gpus all \
nvcr.io/nvidia/nemo:${TAG}
```
关于开发安装和更多详细信息,请参阅我们的[贡献指南](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/CONTRIBUTING.md)。
## ⚡ 快速入门
首先,安装 Megatron Bridge 或下载[上文](#-installation)所述的 NeMo Framework 容器。
登录 Hugging Face Hub:
```
huggingface-cli login --token
```
仅转换的快速入门(✅ Core):
```
from megatron.bridge import AutoBridge
# 1) 从 Hugging Face 模型(hub 或本地路径)创建 bridge
bridge = AutoBridge.from_hf_pretrained("meta-llama/Llama-3.2-1B", trust_remote_code=True)
# 2) 获取 Megatron provider 并在实例化前配置 parallelism
provider = bridge.to_megatron_provider()
provider.tensor_model_parallel_size = 1
provider.pipeline_model_parallel_size = 1
provider.finalize()
# 3) 实例化 Megatron Core 模型
model = provider.provide_distributed_model(wrap_with_ddp=False)
# 4a) 导出 Megatron → Hugging Face(包含 config/tokenizer/weights 的完整 HF 文件夹)
bridge.save_hf_pretrained(model, "./hf_exports/llama32_1b")
# 4b) 或仅流式传输 weights(Megatron → HF)
for name, weight in bridge.export_hf_weights(model, cpu=True):
print(name, tuple(weight.shape))
```
使用预配置配方 (recipes) 的训练快速入门:
```
from megatron.bridge.recipes.llama import llama32_1b_pretrain_config
from megatron.bridge.training.gpt_step import forward_step
from megatron.bridge.training.pretrain import pretrain
if __name__ == "__main__":
# The recipe uses the Llama 3.2 1B model configuration from HuggingFace
cfg = llama32_1b_pretrain_config(seq_length=1024)
# Override training parameters
cfg.train.train_iters = 10
cfg.scheduler.lr_decay_iters = 10000
cfg.model.vocab_size = 8192
cfg.tokenizer.vocab_size = cfg.model.vocab_size
pretrain(cfg, forward_step)
```
您可以使用以下命令启动上述脚本:
```
torchrun --nproc-per-node= /path/to/script.py
```
更多示例:
- [转换脚本概述](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/examples/conversion/README.md)
- [导入/导出 checkpoint](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/examples/conversion/convert_checkpoints.py)
- [使用 bridge 进行生成](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/examples/conversion/hf_to_megatron_generate_text.py)
- [从 HF 多 GPU 加载](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/examples/conversion/hf_megatron_roundtrip_multi_gpu.py)
- [比较 HF 与 Megatron 输出](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/examples/conversion/compare_models.py)
- [使用 Bridge 进行 Toy RLHF(HF 推理 + Megatron 训练)](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/examples/rl/rlhf_with_bridge.py)
欲深入了解转换设计和高级用法,请参阅 [models README](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/models/README.md)。
## 🚀 关键特性
- **与 🤗 Hugging Face 桥接**:在 🤗 Hugging Face 和 Megatron 格式之间实现无缝双向转换,以实现互操作性([模型 bridges](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/models)、[Auto Bridge](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/models/conversion/auto_bridge.py)、[转换示例](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/examples/conversion))
- 无需中间完整 checkpoint 的在线导入/导出
- 转换过程中感知并行性(TP/PP/VPP/CP/EP/ETP)
- 内存高效的逐参数流式传输
- 具备架构自动检测功能的简单高级 `AutoBridge` API
- Transformer Engine 可用时的优化路径
- **灵活定制**:轻量级自定义训练循环,便于在数据加载、分布式训练、checkpoint、评估和日志记录中配置自定义逻辑([训练框架](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/training)、[训练工具](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/training/utils))
- **监督与参数高效微调**:专为基于 Megatron 的模型定制的 SFT & PEFT 实现,支持 LoRA、DoRA 和用户定义的 PEFT 方法([PEFT 实现](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/peft)、[微调模块](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/training/finetune.py)、[SFT 数据集](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/data/datasets/sft.py))
- **SOTA 训练配方**:为 Llama 3 等流行模型提供预配置的生产级训练配方,包含优化的超参数和分布式训练配置([Llama 配方](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/recipes/llama)、[配方示例](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/examples/models))
- **性能优化**:内置支持 FP8 训练、模型并行和内存高效技术,以提供高利用率并在数千个节点上实现近线性可扩展性。([混合精度](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/training/mixed_precision.py)、[通信重叠](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/training/comm_overlap.py)、[优化器工具](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/utils/optimizer_utils.py))
## 支持的模型
Megatron Bridge 为广泛的模型提供开箱即用的 bridge 和训练配方,这些构建在 [Megatron Core](https://github.com/NVIDIA/Megatron-LM/tree/main/megatron/core) 的基础模型架构之上。请参阅 [models 目录](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/models) 以获取最新的模型 bridge 列表。
### 支持的模型概述
有关支持模型的更多详细信息,请参阅我们的文档:
- **[大型语言模型](https://docs.nvidia.com/nemo/megatron-bridge/latest/models/llm/index.html)**
- **[视觉语言模型](https://docs.nvidia.com/nemo/megatron-bridge/latest/models/vlm/index.html)**
| 模型 | Checkpoint 转换 | 预训练配方 | SFT & LoRA 配方 |
|-------|-------------------|-------------------|-------------------|
| [DeepSeek V2](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/models/deepseek) | ✅ | ✅ ([v2](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/deepseek/deepseek_v2.py)) | 即将推出 |
| [DeepSeek V2 Lite](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/models/deepseek) | ✅ | ✅ ([v2-lite](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/deepseek/deepseek_v2.py)) | 即将推出 |
| [DeepSeek V3](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/models/deepseek) | ✅ | ✅ ([v3](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/deepseek/deepseek_v3.py)) | 即将推出 |
| [Gemma](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/models/gemma) | ✅ | 即将推出 | 即将推出 |
| [Gemma 2](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/models/gemma) | ✅ | 即将推出 | 即将推出 |
| [Gemma 3](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/models/gemma) | ✅ | ✅ ([1B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/gemma/gemma3.py)) | ✅ ([1B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/gemma/gemma3.py)) |
| [Gemma 3-VL](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/models/gemma_vl) | ✅ | 即将推出 | ✅ ([4B/12B/27B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/gemma3_vl/gemma3_vl.py)) |
| [GLM-4.5](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/models/glm) | ✅ | ✅ ([106B-Air/355B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/glm/glm45.py)) | ✅ ([106B-Air/355B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/glm/glm45.py)) |
| [GPT-oss](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/models/gpt_oss) | ✅ | ✅ ([20B/120B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/gpt_oss/gpt_oss.py)) | ✅ ([20B/120B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/gpt_oss/gpt_oss.py)) |
| [Llama 2](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/models/llama) | ✅ | ✅ ([7B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/llama/llama2.py)) | 即将推出 |
| [Llama 3](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/models/llama) | ✅ | ✅ ([8B/70B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/llama/llama3.py)) | ✅ ([8B/70B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/llama/llama3.py)) |
| [Llama 3.1](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/models/llama) | ✅ | ✅ ([8B/70B/405B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/llama/llama3.py)) | ✅ ([8B/70B/405B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/llama/llama3.py)) |
| [Llama 3.2](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/models/llama) | ✅ | ✅ ([1B/3B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/llama/llama3.py)) | ✅ ([1B/3B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/llama/llama3.py)) |
| [Llama 3.3](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/models/llama) | ✅ | 即将推出 | 即将推出 |
| [Llama Nemotron](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/models/llama_nemotron) | ✅ | 即将推出 | 即将推出 |
| [Mistral](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/models/mistral) | ✅ | 即将推出 | 即将推出 |
|[Ministral](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/models/ministral3)| ✅| ✅ [3B/8B/14B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/ministral3/ministral3.py)|✅ [3B/8B/14B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/ministral3/ministral3.py)|
| [Moonlight](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/models/deepseek) | ✅ | ✅ ([16B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/moonlight/moonlight_16b.py)) | ✅ ([16B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/moonlight/moonlight_16b.py)) |
| [Nemotron](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/models/nemotron) | ✅ | 即将推出 | 即将推出 |
| [Nemotron-nano-v3](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/nano-v3/src/megatron/bridge/models/nemotronh) | ✅ | ✅ ([30B-A3B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/nano-v3/src/megatron/bridge/recipes/nemotronh/nemotron_3_nano.py)) | ✅ ([A3B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/nano-v3/src/megatron/bridge/recipes/nemotronh/nemotron_3_nano.py)) |
| [Nemotron-H](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/models/nemotronh) | ✅ | ✅ ([4B/8B/47B/56B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/nemotronh/nemotronh.py)) | 即将推出 |
| [Nemotron Nano v2](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/models/nemotronh) | ✅ | ✅ ([9B/12B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/nemotronh/nemotron_nano_v2.py)) | 即将推出 |
| [Nemotron Nano v2 VL](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/models/nemotron_vl) | ✅ | 即将推出 | ✅ ([9B/12B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/nemotron_vl/nemotron_nano_v2_vl.py)) |
| [OlMoE](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/models/olmoe) | ✅ | ✅ ([7B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/olmoe/olmoe_7b.py)) | ✅ ([7B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/olmoe/olmoe_7b.py)) |
| [Qwen2](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/models/qwen) | ✅ | ✅ ([500M/1.5B/7B/72B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/qwen/qwen2.py)) | ✅ ([500M/1.5B/7B/72B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/qwen/qwen2.py)) |
| [Qwen2.5](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/models/qwen) | ✅ | ✅ ([500M/1.5B/7B/14B/32B/72B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/qwen/qwen2.py)) | ✅ ([500M/1.5B/7B/14B/32B/72B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/qwen/qwen2.py)) |
| [Qwen2.5-VL](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/models/qwen_vl) | ✅ | 即将推出 | ✅ ([3B/7B/32B/72B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/qwen_vl/qwen25_vl.py)) |
| [Qwen3](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/models/qwen) | ✅ | ✅ ([600M/1.7B/4B/8B/14B/32B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/qwen/qwen3.py)) | ✅ ([600M/1.7B/4B/8B/14B/32B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/qwen/qwen3.py)) |
| [Qwen3-MoE](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/models/qwen) | ✅ | ✅ ([A3B/A22B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/qwen/qwen3_moe.py)) | ✅ ([A3B/A22B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/qwen/qwen3_moe.py)) |
| [Qwen3 Next](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/models/qwen) | ✅ | ✅ ([80B-A3B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/qwen/qwen3_next.py)) | ✅ ([80B-A3B](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/qwen/qwen3_next.py)) |
| [Qwen3-VL](https://github.com/NVIDIA-NeMo/Megatron-Bridge/tree/main/src/megatron/bridge/models/qwen_vl) | ✅ | 即将推出 | ✅ ([8B/A3B-A30B-MoE](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/src/megatron/bridge/recipes/qwen_vl/qwen3vl.py)) |
#### 启动配方
关于配方如何构建、覆盖以及如何使用 `torchrun` 或 NeMo-Run 启动的概念概述,请阅读[使用配方指南](https://docs.nvidia.com/nemo/megatron-bridge/latest/recipe-usage.html)。
可运行的教程位于 `tutorials/recipes/llama`,涵盖:
- `00_quickstart_pretrain.py` 用于 mock-data 预训练
- `01_quick_finetune.py` + LoRA 配置
- YAML 驱动的工作流和启动辅助工具
## 性能基准测试
有关详细的性能基准测试,包括不同 GPU 系统(DGX-GB200、DGX-B200、DGX-H100)和模型配置下的吞吐量指标,请参阅我们文档中的[性能摘要](https://docs.nvidia.com/nemo/megatron-bridge/latest/performance-summary.html)。
## 项目结构
```
Megatron-Bridge/
├── examples/
│ ├── models/ # Bridge usage examples
│ └── recipes/ # Training examples
├── src/megatron/bridge/
│ ├── data/ # Dataloaders and iterators
│ ├── models/ # Hugging Face bridge infrastructure and model-specific implementations
│ │ ├── llama/ # Llama model providers
│ │ └── .../ # Other models (gpt, t5, etc.)
│ ├── peft/ # PEFT transformations and wrappers
│ ├── recipes/ # Complete training recipes
│ ├── training/ # Training loop components
│ │ ├── tokenizers/ # Tokenizer library
│ │ └── utils/ # Training-specific utilities
│ └── utils/ # Generic utilities for repo-wide usage
└── tests/ # Comprehensive test suite
```
## 致谢与贡献
Megatron-Bridge 是由 [Yan Bai](https://github.com/ISEEKYAN) 开发的 [MBridge](https://github.com/ISEEKYAN/mbridge) 的延续。我们感谢社区合作伙伴的所有贡献和采用:
- [Mind Lab](https://macaron.im/mindlab) 成功使用 Megatron-bridge 和 [VeRL](https://github.com/volcengine/verl) 在 64 张 H800 上训练了万亿参数模型的 GRPO Lora - 参见他们的[技术博客](https://macaron.im/mindlab/research/building-trillion-parameter-reasoning-rl-with-10-gpus)。
- [VeRL](https://github.com/volcengine/verl) 已采用 Megatron-Bridge 作为 Megatron-Core 的连接器并提供 LoRA 支持。
- [Slime](https://github.com/THUDM/slime) 已采用 Megatron-Bridge 作为 Megatron-Core checkpoint 转换器。
- [SkyRL](https://github.com/NovaSky-AI/SkyRL) 已采用 Megatron-Bridge 作为 Megatron-Core 连接器。
- [Nemo-RL](https://github.com/NVIDIA/nemo-rl) 已采用 Megatron-Bridge 作为 Megatron-Core 连接器。
- 社区贡献:特别感谢来自微信集团基础设施中心的 [Guanyou He](https://github.com/Thaurun) 和 [Junyu Wu](https://github.com/nrailg)。
请参阅我们的[贡献者指南](https://github.com/NVIDIA-NeMo/Megatron-Bridge/blob/main/CONTRIBUTING.md),了解关于如何参与的更多信息。标签:AI框架, checkpoint转换, DLL 劫持, DNS解析, Hugging Face, LLM, LoRA, Megatron, NeMo, Nemotron, Python, PyTorch, SFT, Unmanaged PE, VLM, 凭据扫描, 分布式训练, 多模态, 大语言模型, 开源项目, 微调, 无后门, 机器学习库, 模型并行, 模型转换, 深度学习, 请求拦截, 逆向工具, 预训练, 高性能计算