Cisco-Talos/PEAK-Assistant
GitHub: Cisco-Talos/PEAK-Assistant
PEAK-Assistant 是一款由 AI 驱动的威胁狩猎助手,遵循 PEAK 框架帮助安全团队自动化完成从威胁研究、假设生成到狩猎计划制定的全流程。
Stars: 58 | Forks: 10
# PEAK-Assistant
PEAK-Assistant 是一款由 AI 驱动的威胁狩猎助手,旨在引导狩猎人员快速完成研究和规划假设驱动狩猎的整个过程。它与 [PEAK 威胁狩猎框架](https://www.splunk.com/en_us/blog/security/peak-threat-hunting-framework.html) 保持一致,并利用大语言模型、AI 智能体团队以及自动化研究工具,来简化准备狩猎的过程。
⛔️⛔️ **PEAK Assistant 仅作为概念验证项目,旨在展示智能体安全解决方案的潜力。它尚未经过安全测试。除了本地系统环境外,将其部署到其他任何环境时请务必谨慎。** ⛔️⛔️
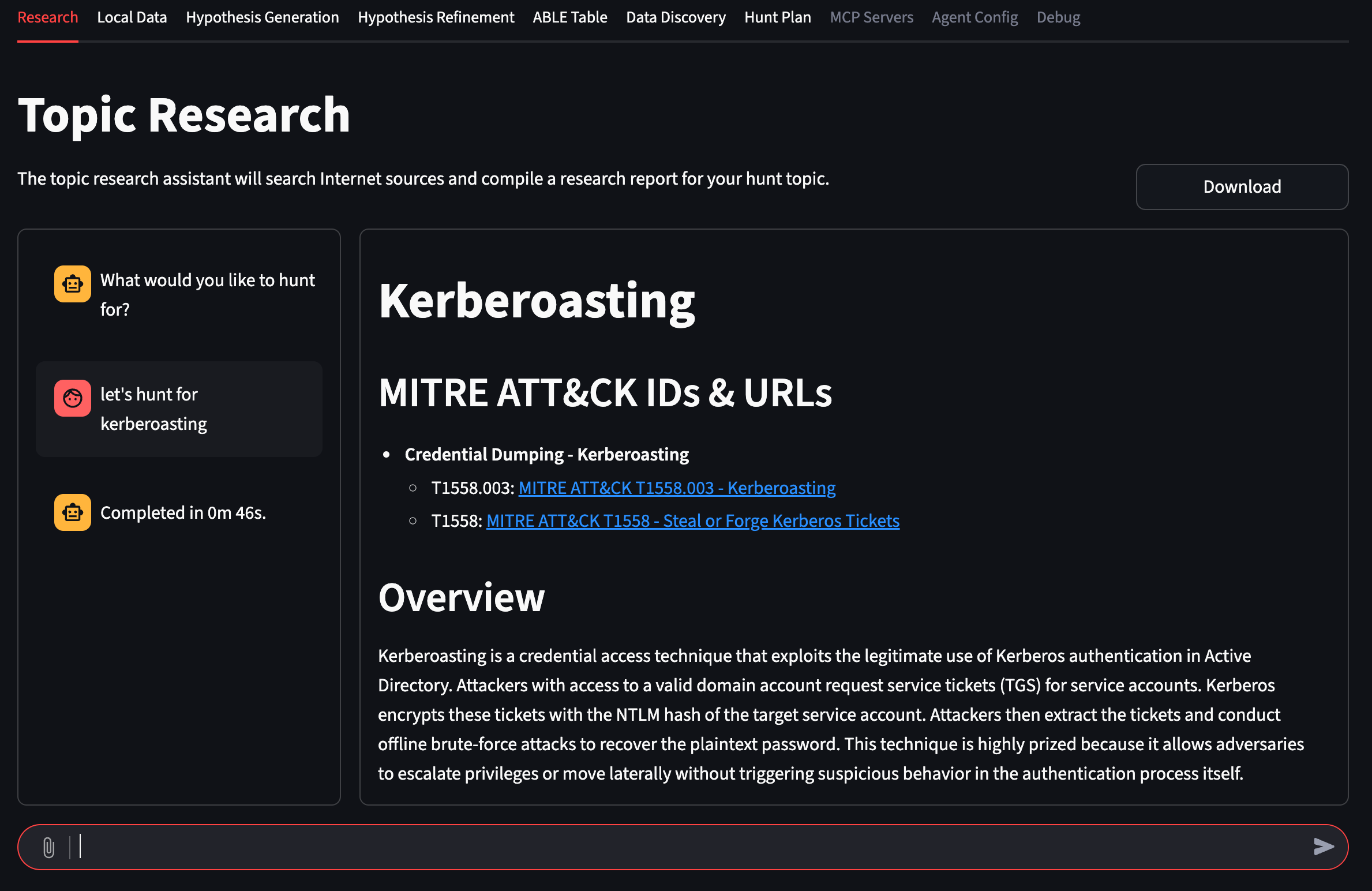 ## 功能特性
PEAK Assistant Web 应用提供以下功能:
- 针对特定技术、战术或攻击者生成详细的威胁狩猎研究报告。它可以同时访问基于互联网的来源和本地数据库(工单系统、Wiki 页面、威胁情报平台等)。
- 根据其执行的研究建议并完善威胁狩猎假设。
- 创建 PEAK ABLE 表以帮助确定狩猎范围。
- 在您的 Splunk 实例中自动识别相关的索引、源类型和字段名。
- 创建循序渐进的狩猎计划,包括关于如何分析和解释结果的指导
- 以 Markdown 格式导出文档
- 上传您自己准备好的文档,这样 AI 就不必重新生成它们。
- 通过用户提供的本地或远程 MCP 服务器集成研究和 Splunk 数据源,包括支持 OAuth2、API 密钥和 Bearer 令牌认证
- 大多数阶段都采用了类似聊天的界面,因此您可以与助手协作完善输出,直到完全正确为止
- *自带模型 (Bring-Your-Own-Model)* 方案,允许您使用任何喜欢的 LLM。您可以设置所有智能体使用的默认 LLM,也可以为每个智能体指定不同的 LLM,从而让您选择最适合的模型。
## 设置 Python 环境
将 GitHub 仓库克隆到本地系统的目录中:
```
git clone https://github.com/cisco-foundation-ai/PEAK-Assistant
cd PEAK-Assistant
```
**我们强烈建议您使用 'uv' 来管理您的 Python 环境。** 它将负责创建虚拟环境并安装所有依赖项。
```
uv sync
```
## 环境变量
PEAK Assistant 使用 `.env` 文件来存储 API 密钥和其他敏感配置。提供了一个示例文件供您快速入门:
```
cp .env.example .env
```
编辑 `.env` 并填写您计划使用的提供商的相应值。您只需配置 `model_config.json` 中引用的提供商对应的变量——其余的可以保持注释状态。有关设置提供商的详细信息,请参阅下文的[模型配置](#model-configuration)。
## 生成 TLS 证书
完成上述操作后,您需要生成 TLS 证书和私钥。文件必须命名为 `cert.pem` 和 `key.pem`,并存放在本地目录中(或启动时由 `--cert-dir` 指定的目录中)。您可以像这样手动执行此操作:
```
openssl req -x509 -newkey rsa:2048 -keyout key.pem -out cert.pem -days 365 -nodes -subj "/CN=localhost"
```
如果您愿意,可以使用 `generate_certificates.sh` 实用工具来完成此操作。只需运行脚本并按照提示操作即可。
```
./generate_certificates.sh
```
## MCP 服务器配置
您还需要配置助手用于研究主题和发现可用数据的 MCP 服务器。在仓库的根目录中创建一个名为 `mcp_servers.json` 的文件。该文件的格式与您在 Claude Desktop 或其他流行的聊天应用程序中配置 MCP 服务器时可能熟悉的格式相同。您可以使用以下示例作为模板:
```
{
"mcpServers": {
"tavily-search": {
"transport": "stdio",
"description": "Provides Internet searches",
"command": "npx",
"args": [
"-y",
"tavily-mcp@0.1.2"
],
"env": {
"TAVILY_API_KEY": "tvly-dev-YOUR-KEY"
}
},
"splunk-mcp": {
"description": "Connect to a running Splunk server and run searches.",
"command": "npx",
"args": [
"-y",
"mcp-remote",
"https://YOUR-SERVER-HOST:8089/services/mcp",
"--header",
"Authorization: Bearer YOUR-SPLUNK-AUTH-TOKEN"
]
},
"atlassian-remote-mcp": {
"transport": "sse",
"description": "Provides access to Jira and Confluence",
"url": "https://mcp.atlassian.com/v1/sse"
}
},
"serverGroups": {
"research-external": [
"tavily-search"
],
"local-data-search": [
"atlassian-remote-mcp"
],
"data_discovery": [
"splunk-mcp"
]
}
}
```
您必须为所有三个必需的服务器组提供 MCP 服务器:
* **互联网搜索**(例如 Tavily) - 用于外部研究
* **本地数据源**(例如 Atlassian MCP、Confluence、Jira) - 用于基于过去狩猎和组织知识的内部研究
* **SIEM/数据平台**(例如 Splunk MCP 服务器) - 用于自动化数据发现
在此示例配置中,我们使用 Tavily 进行互联网搜索,使用 [Atlassian 官方 MCP 服务器](https://www.atlassian.com/platform/remote-mcp-server)来搜索 Jira 工单和 Confluence Wiki 页面,并使用 Splunk MCP 服务器进行数据发现。
请随意用功能等效的 MCP 服务器进行替换。例如,如果您使用的是不同的互联网搜索提供商,请用您正在使用的任何服务替换 Tavily 配置。
### 告知助手要使用哪些 MCP 服务器
除了定义服务器外,您还必须将它们添加到相应的 MCP 服务器组中,以让不同的智能体知道它们应该使用哪个服务器。
服务器组分别为:
* `research-external`:用于主题研究阶段的任何互联网搜索
* `local-data-search`:用于在主题研究阶段搜索任何本地数据源
* `data_discovery`:允许访问 Splunk(或您使用的任何其他 SIEM)以进行自动化数据发现。
如果您希望助手能够访问多个来源,您可以向每个组添加多个 MCP 服务器。**这三个组都是必需的,并且每个组必须至少配置一个服务器。**
### 环境变量插值
MCP 服务器配置支持使用 `${ENV_VAR}` 语法进行环境变量插值。这允许您将敏感凭据排除在配置文件之外:
```
{
"mcpServers": {
"tavily-search": {
"transport": "stdio",
"command": "npx",
"args": ["-y", "tavily-mcp@0.1.2"],
"env": {
"TAVILY_API_KEY": "${TAVILY_API_KEY}"
}
},
"secure-api": {
"transport": "http",
"url": "https://api.example.com/mcp",
"auth": {
"type": "bearer",
"token": "${API_BEARER_TOKEN}"
}
}
}
}
```
**支持的语法:**
- `${ENV_VAR}` - 替换为环境变量值(如果未找到则引发错误)
- `${ENV_VAR|default}` - 替换为环境变量或使用默认值
- `${ENV_VAR|null}` - 替换为环境变量或空字符串
将您的实际机密信息存储在 `.env` 文件中(参见上文的[环境变量](#environment-variables)),或者在运行应用程序之前将它们设置为环境变量。
### MCP 认证
您可以在助手的“MCP Servers”选项卡上找到所有已配置的 MCP 服务器列表。如果 MCP 服务器需要身份验证,您将在该服务器所在行看到一个 `Authenticate` 按钮。点击此按钮将重定向您到该服务器的身份验证提供商。
PEAK Assistant 支持对远程 MCP 服务器进行 OAuth2 身份验证,以及 OAuth 资源自发现。如果您的 MCP 服务器也支持这些功能,当您点击 `Authenticate` 按钮时,系统会自动将您引导至该服务器的身份验证提供商。
## 本地上下文文件
助手支持一个用于提供“本地上下文”的可选文件。这为您提供了一种向 LLM 提供有关您的环境或偏好的提示和指导的方法,以便您可以根据自己的需求调整 AI,而无需编辑提示词。如果存在此上下文文件,其名称应为 `context.txt`,并应放置在仓库的根目录中。它应包含有助于 AI 智能体了解您特定环境的信息,例如:
- 组织结构和命名约定
- 正在使用的特定技术和工具
- 与您的组织相关的已知威胁行为者或活动
- 合规性要求或监管注意事项
- 关于在何处查找以往安全事件工单、狩猎文档或其他本地数据源的提示
- 有关您最常用的数据源及其访问方式的详细信息
没有特定的格式要求,但您可能会发现建立某种基本结构有助于您随着时间推移轻松维护它。以下是一个简单的示例:
```
Environmental hints:
- We use primarily Splunk SIEM and Zeek NIDS.
Local Information Sources:
- Always consult the following sources of information when you are preparing your local research
reports, using the Atlassian MCP server.
- Hunt team documents hunts in Confluence wiki, under the "Threat Hunting" space
- Hunt team tracks in-progress and upcoming hunts in Jira, under the "Threat Hunting" project
- The Atlassian server is my-cloud-tenant.atlassian.net.
Splunk hints:
- If you encounter base64-encoded data, and if you decide that you must decode it,
you can use the following sample SPL as a reference:
## 功能特性
PEAK Assistant Web 应用提供以下功能:
- 针对特定技术、战术或攻击者生成详细的威胁狩猎研究报告。它可以同时访问基于互联网的来源和本地数据库(工单系统、Wiki 页面、威胁情报平台等)。
- 根据其执行的研究建议并完善威胁狩猎假设。
- 创建 PEAK ABLE 表以帮助确定狩猎范围。
- 在您的 Splunk 实例中自动识别相关的索引、源类型和字段名。
- 创建循序渐进的狩猎计划,包括关于如何分析和解释结果的指导
- 以 Markdown 格式导出文档
- 上传您自己准备好的文档,这样 AI 就不必重新生成它们。
- 通过用户提供的本地或远程 MCP 服务器集成研究和 Splunk 数据源,包括支持 OAuth2、API 密钥和 Bearer 令牌认证
- 大多数阶段都采用了类似聊天的界面,因此您可以与助手协作完善输出,直到完全正确为止
- *自带模型 (Bring-Your-Own-Model)* 方案,允许您使用任何喜欢的 LLM。您可以设置所有智能体使用的默认 LLM,也可以为每个智能体指定不同的 LLM,从而让您选择最适合的模型。
## 设置 Python 环境
将 GitHub 仓库克隆到本地系统的目录中:
```
git clone https://github.com/cisco-foundation-ai/PEAK-Assistant
cd PEAK-Assistant
```
**我们强烈建议您使用 'uv' 来管理您的 Python 环境。** 它将负责创建虚拟环境并安装所有依赖项。
```
uv sync
```
## 环境变量
PEAK Assistant 使用 `.env` 文件来存储 API 密钥和其他敏感配置。提供了一个示例文件供您快速入门:
```
cp .env.example .env
```
编辑 `.env` 并填写您计划使用的提供商的相应值。您只需配置 `model_config.json` 中引用的提供商对应的变量——其余的可以保持注释状态。有关设置提供商的详细信息,请参阅下文的[模型配置](#model-configuration)。
## 生成 TLS 证书
完成上述操作后,您需要生成 TLS 证书和私钥。文件必须命名为 `cert.pem` 和 `key.pem`,并存放在本地目录中(或启动时由 `--cert-dir` 指定的目录中)。您可以像这样手动执行此操作:
```
openssl req -x509 -newkey rsa:2048 -keyout key.pem -out cert.pem -days 365 -nodes -subj "/CN=localhost"
```
如果您愿意,可以使用 `generate_certificates.sh` 实用工具来完成此操作。只需运行脚本并按照提示操作即可。
```
./generate_certificates.sh
```
## MCP 服务器配置
您还需要配置助手用于研究主题和发现可用数据的 MCP 服务器。在仓库的根目录中创建一个名为 `mcp_servers.json` 的文件。该文件的格式与您在 Claude Desktop 或其他流行的聊天应用程序中配置 MCP 服务器时可能熟悉的格式相同。您可以使用以下示例作为模板:
```
{
"mcpServers": {
"tavily-search": {
"transport": "stdio",
"description": "Provides Internet searches",
"command": "npx",
"args": [
"-y",
"tavily-mcp@0.1.2"
],
"env": {
"TAVILY_API_KEY": "tvly-dev-YOUR-KEY"
}
},
"splunk-mcp": {
"description": "Connect to a running Splunk server and run searches.",
"command": "npx",
"args": [
"-y",
"mcp-remote",
"https://YOUR-SERVER-HOST:8089/services/mcp",
"--header",
"Authorization: Bearer YOUR-SPLUNK-AUTH-TOKEN"
]
},
"atlassian-remote-mcp": {
"transport": "sse",
"description": "Provides access to Jira and Confluence",
"url": "https://mcp.atlassian.com/v1/sse"
}
},
"serverGroups": {
"research-external": [
"tavily-search"
],
"local-data-search": [
"atlassian-remote-mcp"
],
"data_discovery": [
"splunk-mcp"
]
}
}
```
您必须为所有三个必需的服务器组提供 MCP 服务器:
* **互联网搜索**(例如 Tavily) - 用于外部研究
* **本地数据源**(例如 Atlassian MCP、Confluence、Jira) - 用于基于过去狩猎和组织知识的内部研究
* **SIEM/数据平台**(例如 Splunk MCP 服务器) - 用于自动化数据发现
在此示例配置中,我们使用 Tavily 进行互联网搜索,使用 [Atlassian 官方 MCP 服务器](https://www.atlassian.com/platform/remote-mcp-server)来搜索 Jira 工单和 Confluence Wiki 页面,并使用 Splunk MCP 服务器进行数据发现。
请随意用功能等效的 MCP 服务器进行替换。例如,如果您使用的是不同的互联网搜索提供商,请用您正在使用的任何服务替换 Tavily 配置。
### 告知助手要使用哪些 MCP 服务器
除了定义服务器外,您还必须将它们添加到相应的 MCP 服务器组中,以让不同的智能体知道它们应该使用哪个服务器。
服务器组分别为:
* `research-external`:用于主题研究阶段的任何互联网搜索
* `local-data-search`:用于在主题研究阶段搜索任何本地数据源
* `data_discovery`:允许访问 Splunk(或您使用的任何其他 SIEM)以进行自动化数据发现。
如果您希望助手能够访问多个来源,您可以向每个组添加多个 MCP 服务器。**这三个组都是必需的,并且每个组必须至少配置一个服务器。**
### 环境变量插值
MCP 服务器配置支持使用 `${ENV_VAR}` 语法进行环境变量插值。这允许您将敏感凭据排除在配置文件之外:
```
{
"mcpServers": {
"tavily-search": {
"transport": "stdio",
"command": "npx",
"args": ["-y", "tavily-mcp@0.1.2"],
"env": {
"TAVILY_API_KEY": "${TAVILY_API_KEY}"
}
},
"secure-api": {
"transport": "http",
"url": "https://api.example.com/mcp",
"auth": {
"type": "bearer",
"token": "${API_BEARER_TOKEN}"
}
}
}
}
```
**支持的语法:**
- `${ENV_VAR}` - 替换为环境变量值(如果未找到则引发错误)
- `${ENV_VAR|default}` - 替换为环境变量或使用默认值
- `${ENV_VAR|null}` - 替换为环境变量或空字符串
将您的实际机密信息存储在 `.env` 文件中(参见上文的[环境变量](#environment-variables)),或者在运行应用程序之前将它们设置为环境变量。
### MCP 认证
您可以在助手的“MCP Servers”选项卡上找到所有已配置的 MCP 服务器列表。如果 MCP 服务器需要身份验证,您将在该服务器所在行看到一个 `Authenticate` 按钮。点击此按钮将重定向您到该服务器的身份验证提供商。
PEAK Assistant 支持对远程 MCP 服务器进行 OAuth2 身份验证,以及 OAuth 资源自发现。如果您的 MCP 服务器也支持这些功能,当您点击 `Authenticate` 按钮时,系统会自动将您引导至该服务器的身份验证提供商。
## 本地上下文文件
助手支持一个用于提供“本地上下文”的可选文件。这为您提供了一种向 LLM 提供有关您的环境或偏好的提示和指导的方法,以便您可以根据自己的需求调整 AI,而无需编辑提示词。如果存在此上下文文件,其名称应为 `context.txt`,并应放置在仓库的根目录中。它应包含有助于 AI 智能体了解您特定环境的信息,例如:
- 组织结构和命名约定
- 正在使用的特定技术和工具
- 与您的组织相关的已知威胁行为者或活动
- 合规性要求或监管注意事项
- 关于在何处查找以往安全事件工单、狩猎文档或其他本地数据源的提示
- 有关您最常用的数据源及其访问方式的详细信息
没有特定的格式要求,但您可能会发现建立某种基本结构有助于您随着时间推移轻松维护它。以下是一个简单的示例:
```
Environmental hints:
- We use primarily Splunk SIEM and Zeek NIDS.
Local Information Sources:
- Always consult the following sources of information when you are preparing your local research
reports, using the Atlassian MCP server.
- Hunt team documents hunts in Confluence wiki, under the "Threat Hunting" space
- Hunt team tracks in-progress and upcoming hunts in Jira, under the "Threat Hunting" project
- The Atlassian server is my-cloud-tenant.atlassian.net.
Splunk hints:
- If you encounter base64-encoded data, and if you decide that you must decode it,
you can use the following sample SPL as a reference:
| code field=base64_encoded_field method=base64 action=decode destfield=decoded_field
Where the "field" parameter is the name of the field that has base64 data in it, and
the "destfield" parameter is the name of a new field you want to hold the decoded value.
- Some of the indices are extremely large and have many events. You will need to check your
SPL queries carefully to ensure that they are as efficient as possible. One good strategy
is to use 'tstats' whenever possible, rather than normal searches.
- Don't try to use accelerated datamodels. There are no datamodels on this server.
```
我们强烈建议您至少包含一些关于您最重要的 Splunk 索引、源类型和字段的基本信息。这将有助于 AI 智能体更好地理解您的数据并生成更准确的查询。这不是必需的,因为自动数据发现实际上相当出色,但这会很有帮助。
## 模型配置
PEAK Assistant 需要一个 `model_config.json` 文件来配置 LLM 提供商和模型。此文件必须放置在仓库根目录中(您运行应用程序的目录)。
以下示例展示了一个基本配置,全部使用 OpenAI 的 `gpt-4.1` 模型。
```
{
"version": "1",
"providers": {
"openai": {
"type": "openai",
"config": {
"api_key": "${OPENAI_API_KEY}",
}
}
},
"defaults": {
"provider": "openai",
"model": "gpt-4.1"
}
}
```
还支持更复杂的配置,包括:
- 使用多个 LLM 提供商(Azure OpenAI、OpenAI、兼容 OpenAI 的本地或远程服务、Anthropic)
- 为每个智能体分配模型
- 一次将模型分配给一组智能体
- 环境变量插值
完整指南请参见 **[MODEL_CONFIGURATION.md](MODEL_CONFIGURATION.md)**。
## 运行助手
现在已经配置完毕,是时候运行应用了。由于您将其作为模块安装,您只需运行助手即可:
```
uv run peak-assistant
```
默认情况下,应用程序将在 `https://127.0.0.1:8501/` 上可用。
## 工作流
PEAK-Assistant 遵循与 PEAK 威胁狩猎框架保持一致的结构化工作流:
1. **研究阶段**:基于公共互联网来源,针对指定的网络安全技术或威胁行为者生成全面的研究报告
2. **本地研究阶段**:查询本地数据源,例如事件工单、狩猎文档和威胁情报数据库,以获取补充公共研究的并能用于调整计划的相关信息
3. **假设生成**:基于研究结果创建可测试的假设
4. **假设完善**:通过自动或人工引导的反馈来改进和完善假设
5. **ABLE 表创建**:开发 Actor(攻击者)、Behavior(行为)、Location(位置)、Evidence(证据)表以界定狩猎范围
6. **数据发现**:识别您的 SIEM 中的相关数据源
7. **狩猎规划**:将所有组件组合成一份全面的威胁狩猎计划
## 实时集成测试(可选)
本仓库包含对配置的 LLM 提供商进行真实调用的实时集成测试。这些测试标有 `@pytest.mark.live`,并且需要在当前工作目录中存在一个配置正确的 `model_config.json` 文件。
- 运行所有实时测试:
uv run pytest -m live tests/integration -q
注意:这些测试会进行真实的网络调用,在使用托管 LLM 提供商时可能会产生费用。
## Docker 支持
PEAK Assistant 可以在 Docker 容器中运行。为此,您的系统上需要安装 Docker。替代方案(如 `podman` 或其他使用 Docker 镜像的容器系统)也可以运行,但不提供官方支持。
### 从容器注册中心拉取 Docker 镜像
项目提供了预构建的 Docker 镜像,可以通过运行以下命令下载:
```
docker pull ghcr.io/cisco-foundation-ai/peak-assistant:latest
```
### 从源码构建 Docker 镜像
如果您倾向于从源码构建镜像,可以通过在仓库根目录运行以下命令来实现:
```
docker build -t peak-assistant .
```
### 运行 Docker 容器
下载镜像后,您可以通过运行以下命令来运行容器:
```
docker run --rm -it \
--mount "type=bind,src=$(PWD)/cert.pem,target=/certs/cert.pem" \
--mount "type=bind,src=$(PWD)/key.pem,target=/certs/key.pem" \
--mount "type=bind,src=$(PWD)/context.txt,target=/home/peakassistant/context.txt" \
--mount "type=bind,src=$(PWD)/.env,target=/home/peakassistant/.env" \
--mount "type=bind,src=$(PWD)/model_config.json,target=/home/peakassistant/model_config.json" \
--mount "type=bind,src=$(PWD)/mcp_servers.json,target=/home/peakassistant/mcp_servers.json" \
-p "127.0.0.1:8501:8501" \
ghcr.io/cisco-foundation-ai/peak-assistant:latest
```
请注意,您仍然需要提供与在本地原生运行应用时相同的配置文件:
* `context.txt`
* `model_config.json`
* `mcp_servers.json`
* `cert.pem` & `key.pem`
* `.env`
示例命令将当前目录挂载为 `/certs`,并将其他文件映射到容器中运行的应用的工作目录中。它假定这些文件位于当前目录中,但您可以根据需要调整路径。
### 通过 Docker 访问助手
容器运行后,您可以像本地原生运行一样访问它。在浏览器中打开 `https://127.0.0.1:8501/`。
## 常见问题
### 如果我想使用 Podman 而不是 Docker 来运行容器怎么办?
Podman 命令通常与 Docker 命令高度兼容,因此您应该可以交替使用它们。唯一的区别是,在上述命令中您需要使用 `podman` 而不是 `docker`。
### 如果我想使用不同的 LLM 提供商怎么办?
助手通过 `model_config.json` 文件支持多个提供商:
- OpenAI
- Azure OpenAI
- Anthropic
- 兼容 OpenAI 的服务器(例如 Ollama、vLLM、LM Studio)
您可以为不同的智能体配置不同的模型,或者为所有智能体使用单一模型。有关详细的配置示例和特定于提供商的要求,请参阅 [MODEL_CONFIGURATION.md](MODEL_CONFIGURATION.md)。
## 故障排除
### PEAK Assistant 提示我的 `model_config.json` 文件无效,我该怎么办?
PEAK Assistant 使用 `model_config.json` 文件来配置 LLM 提供商和模型。如果您在该文件上遇到问题,可以尝试以下步骤:
1. 验证该文件是否为有效的 JSON
2. 验证该文件格式是否正确
3. 验证该文件是否位于正确的路径
您可以使用 `validate-config` 命令来检查 `model_config.json` 文件的状态:
```
uv run validate-config
```
如果您的配置中有错误,该命令将确切地告诉您 JSON 在何处无效以及问题是什么。
如果 JSON 有效,该命令将提供有关智能体及其各自使用的模型的详细信息:
```
================================================================================
Model Configuration Validation Report
================================================================================
✓ Configuration is valid
⚠ 1 warning(s):
⚠ Provider 'anthropic' is defined but not used by any agent
Providers (4 defined)
--------------------------------------------------------------------------------
├─ cisco-azure (azure)
│ ├─ Endpoint: https://YOUR-ENDPOINT
│ ├─ API Version: 2025-04-01-preview
│ └─ Credentials: ✓
│
└─ anthropic (anthropic)
├─ Credentials: ✓
└─ Model: (configured per agent)
Agent Model Assignments (14 agents)
================================================================================
┌────────────────────────────┬─────────────────┬─────────────────────┬───────────────────┐
│ Agent │ Provider │ Model │ Source │
├────────────────────────────┼─────────────────┼─────────────────────┼───────────────────┤
│ external_search_agent │ cisco-azure │ gpt-4.1 (gpt-4.1) │ defaults │
│ summarizer_agent │ cisco-azure │ gpt-4.1 (gpt-4.1) │ defaults │
│ summary_critic │ cisco-azure │ gpt-4.1 (gpt-4.1) │ defaults │
│ research_team_lead │ cisco-azure │ gpt-4.1 (gpt-4.1) │ defaults │
│ local_data_search_agent │ cisco-azure │ gpt-4.1 (gpt-4.1) │ defaults │
│ local_data_summarizer_agent│ cisco-azure │ gpt-4.1 (gpt-4.1) │ defaults │
│ hypothesis-refiner │ cisco-azure │ gpt-4.1 (gpt-4.1) │ defaults │
│ hypothesis-refiner-critic │ cisco-azure │ gpt-4.1 (gpt-4.1) │ defaults │
│ Data_Discovery_Agent │ cisco-azure │ gpt-4.1 (gpt-4.1) │ defaults │
│ Discovery_Critic_Agent │ cisco-azure │ gpt-4.1 (gpt-4.1) │ defaults │
│ hunt_planner │ cisco-azure │ o4-mini (o4-mini) │ group:reasoning-ag│
│ hunt_plan_critic │ cisco-azure │ o4-mini (o4-mini) │ group:reasoning-ag│
│ able_table │ cisco-azure │ gpt-4.1 (gpt-4.1) │ defaults │
│ hypothesizer_agent │ cisco-azure │ gpt-4.1 (gpt-4.1) │ defaults │
└────────────────────────────┴─────────────────┴─────────────────────┴───────────────────┘
Provider Usage Summary
================================================================================
Provider: cisco-azure (type: azure)
Total agents: 14
• gpt-4.1: 12 agent(s)
external_search_agent, summarizer_agent, summary_critic, research_team_lead, local_data_search_agent, ... (+7 more)
• o4-mini: 2 agent(s)
hunt_planner, hunt_plan_critic
================================================================================
⚠ Validation complete: 1 warning(s) found
================================================================================
```
### 我的 MCP 服务器无法工作/无法认证。我该怎么办?
如果您在 MCP 服务器上遇到问题或想验证您的配置,请使用 `mcp-status` 命令检查所有已配置服务器的状态:
```
uv run mcp-status
```
此命令将:
- 按服务器组显示所有已配置的 MCP 服务器
- 显示每个服务器的身份验证状态
- 识别缺少的 OAuth2 环境变量
- 提供精确的 `export` 命令来设置所需的凭据
**示例输出:**
```
✓ tavily-search
Transport: stdio
Auth: none
Status: Ready
✗ atlassian-remote-mcp
Transport: sse
Auth: oauth2_authorization_code (requires user authentication)
Status: Missing credentials
Missing environment variable(s):
✗ PEAK_MCP_ATLASSIAN_REMOTE_MCP_TOKEN
✗ PEAK_MCP_ATLASSIAN_REMOTE_MCP_USER_ID
To enable, set:
export PEAK_MCP_ATLASSIAN_REMOTE_MCP_TOKEN="your_token_here"
export PEAK_MCP_ATLASSIAN_REMOTE_MCP_USER_ID="your_user_id"
```
**详细模式** 会显示额外的详细信息,如命令、URL 和描述:
```
uv run mcp-status --verbose
# 或
uv run mcp-status -v
```
**注意:** `mcp-status` 命令仅检查配置和环境变量——它不会尝试连接到服务器。这使其在任何时候运行起来都快速且安全。
### 在 CLI 模式下使用 OAuth2 MCP 服务器
经过 OAuth2 身份验证的 MCP 服务器需要基于浏览器的身份验证,并且主要用于 Streamlit 界面。但是,您可以通过环境变量提供 OAuth 令牌,从而在 CLI 模式下使用它们(例如,配合 `research-assistant`):
```
# 适用于没有用户身份验证的服务器
export PEAK_MCP_SERVER_NAME_TOKEN="your_access_token"
# 适用于需要用户身份验证的服务器(例如,Atlassian)
export PEAK_MCP_ATLASSIAN_REMOTE_MCP_TOKEN="your_access_token"
export PEAK_MCP_ATLASSIAN_REMOTE_MCP_USER_ID="your_user_id"
```
**获取令牌:**
1. 通过 Streamlit Web 界面进行身份验证 (`uv run peak-assistant`)
2. 使用服务器的开发者门户生成个人访问令牌
3. 在运行 CLI 命令之前设置环境变量
**注意:** 在 CLI 模式下,没有设置环境变量的 OAuth2 服务器将被自动跳过,并会显示清晰的警告信息。
**注意:** 这是一个实验性功能,可能并非在所有情况下都有效。
### 应用程序正常运行,但当我尝试下载任何文件时出现网络错误。
最可能的原因是您正在使用自签名的 TLS 证书,虽然 Chrome 可能允许您访问应用的页面,但它不会允许您下载任何文件。如果可能,请使用受认可的证书颁发机构来颁发您的 TLS 证书。如果这不可行(例如,如果您在本地开发机器上运行),您将需要把您的 CA 添加到系统的根证书存储中作为受信任的 CA。最简单的方法是使用 [mkcert](https://github.com/FiloSottile/mkcert) 工具创建本地 CA,将其安装到您的系统上,然后使用它为应用创建 TLS 证书。
## 许可证
详情请参阅 [LICENSE](LICENSE)。
## 功能特性
PEAK Assistant Web 应用提供以下功能:
- 针对特定技术、战术或攻击者生成详细的威胁狩猎研究报告。它可以同时访问基于互联网的来源和本地数据库(工单系统、Wiki 页面、威胁情报平台等)。
- 根据其执行的研究建议并完善威胁狩猎假设。
- 创建 PEAK ABLE 表以帮助确定狩猎范围。
- 在您的 Splunk 实例中自动识别相关的索引、源类型和字段名。
- 创建循序渐进的狩猎计划,包括关于如何分析和解释结果的指导
- 以 Markdown 格式导出文档
- 上传您自己准备好的文档,这样 AI 就不必重新生成它们。
- 通过用户提供的本地或远程 MCP 服务器集成研究和 Splunk 数据源,包括支持 OAuth2、API 密钥和 Bearer 令牌认证
- 大多数阶段都采用了类似聊天的界面,因此您可以与助手协作完善输出,直到完全正确为止
- *自带模型 (Bring-Your-Own-Model)* 方案,允许您使用任何喜欢的 LLM。您可以设置所有智能体使用的默认 LLM,也可以为每个智能体指定不同的 LLM,从而让您选择最适合的模型。
## 设置 Python 环境
将 GitHub 仓库克隆到本地系统的目录中:
```
git clone https://github.com/cisco-foundation-ai/PEAK-Assistant
cd PEAK-Assistant
```
**我们强烈建议您使用 'uv' 来管理您的 Python 环境。** 它将负责创建虚拟环境并安装所有依赖项。
```
uv sync
```
## 环境变量
PEAK Assistant 使用 `.env` 文件来存储 API 密钥和其他敏感配置。提供了一个示例文件供您快速入门:
```
cp .env.example .env
```
编辑 `.env` 并填写您计划使用的提供商的相应值。您只需配置 `model_config.json` 中引用的提供商对应的变量——其余的可以保持注释状态。有关设置提供商的详细信息,请参阅下文的[模型配置](#model-configuration)。
## 生成 TLS 证书
完成上述操作后,您需要生成 TLS 证书和私钥。文件必须命名为 `cert.pem` 和 `key.pem`,并存放在本地目录中(或启动时由 `--cert-dir` 指定的目录中)。您可以像这样手动执行此操作:
```
openssl req -x509 -newkey rsa:2048 -keyout key.pem -out cert.pem -days 365 -nodes -subj "/CN=localhost"
```
如果您愿意,可以使用 `generate_certificates.sh` 实用工具来完成此操作。只需运行脚本并按照提示操作即可。
```
./generate_certificates.sh
```
## MCP 服务器配置
您还需要配置助手用于研究主题和发现可用数据的 MCP 服务器。在仓库的根目录中创建一个名为 `mcp_servers.json` 的文件。该文件的格式与您在 Claude Desktop 或其他流行的聊天应用程序中配置 MCP 服务器时可能熟悉的格式相同。您可以使用以下示例作为模板:
```
{
"mcpServers": {
"tavily-search": {
"transport": "stdio",
"description": "Provides Internet searches",
"command": "npx",
"args": [
"-y",
"tavily-mcp@0.1.2"
],
"env": {
"TAVILY_API_KEY": "tvly-dev-YOUR-KEY"
}
},
"splunk-mcp": {
"description": "Connect to a running Splunk server and run searches.",
"command": "npx",
"args": [
"-y",
"mcp-remote",
"https://YOUR-SERVER-HOST:8089/services/mcp",
"--header",
"Authorization: Bearer YOUR-SPLUNK-AUTH-TOKEN"
]
},
"atlassian-remote-mcp": {
"transport": "sse",
"description": "Provides access to Jira and Confluence",
"url": "https://mcp.atlassian.com/v1/sse"
}
},
"serverGroups": {
"research-external": [
"tavily-search"
],
"local-data-search": [
"atlassian-remote-mcp"
],
"data_discovery": [
"splunk-mcp"
]
}
}
```
您必须为所有三个必需的服务器组提供 MCP 服务器:
* **互联网搜索**(例如 Tavily) - 用于外部研究
* **本地数据源**(例如 Atlassian MCP、Confluence、Jira) - 用于基于过去狩猎和组织知识的内部研究
* **SIEM/数据平台**(例如 Splunk MCP 服务器) - 用于自动化数据发现
在此示例配置中,我们使用 Tavily 进行互联网搜索,使用 [Atlassian 官方 MCP 服务器](https://www.atlassian.com/platform/remote-mcp-server)来搜索 Jira 工单和 Confluence Wiki 页面,并使用 Splunk MCP 服务器进行数据发现。
请随意用功能等效的 MCP 服务器进行替换。例如,如果您使用的是不同的互联网搜索提供商,请用您正在使用的任何服务替换 Tavily 配置。
### 告知助手要使用哪些 MCP 服务器
除了定义服务器外,您还必须将它们添加到相应的 MCP 服务器组中,以让不同的智能体知道它们应该使用哪个服务器。
服务器组分别为:
* `research-external`:用于主题研究阶段的任何互联网搜索
* `local-data-search`:用于在主题研究阶段搜索任何本地数据源
* `data_discovery`:允许访问 Splunk(或您使用的任何其他 SIEM)以进行自动化数据发现。
如果您希望助手能够访问多个来源,您可以向每个组添加多个 MCP 服务器。**这三个组都是必需的,并且每个组必须至少配置一个服务器。**
### 环境变量插值
MCP 服务器配置支持使用 `${ENV_VAR}` 语法进行环境变量插值。这允许您将敏感凭据排除在配置文件之外:
```
{
"mcpServers": {
"tavily-search": {
"transport": "stdio",
"command": "npx",
"args": ["-y", "tavily-mcp@0.1.2"],
"env": {
"TAVILY_API_KEY": "${TAVILY_API_KEY}"
}
},
"secure-api": {
"transport": "http",
"url": "https://api.example.com/mcp",
"auth": {
"type": "bearer",
"token": "${API_BEARER_TOKEN}"
}
}
}
}
```
**支持的语法:**
- `${ENV_VAR}` - 替换为环境变量值(如果未找到则引发错误)
- `${ENV_VAR|default}` - 替换为环境变量或使用默认值
- `${ENV_VAR|null}` - 替换为环境变量或空字符串
将您的实际机密信息存储在 `.env` 文件中(参见上文的[环境变量](#environment-variables)),或者在运行应用程序之前将它们设置为环境变量。
### MCP 认证
您可以在助手的“MCP Servers”选项卡上找到所有已配置的 MCP 服务器列表。如果 MCP 服务器需要身份验证,您将在该服务器所在行看到一个 `Authenticate` 按钮。点击此按钮将重定向您到该服务器的身份验证提供商。
PEAK Assistant 支持对远程 MCP 服务器进行 OAuth2 身份验证,以及 OAuth 资源自发现。如果您的 MCP 服务器也支持这些功能,当您点击 `Authenticate` 按钮时,系统会自动将您引导至该服务器的身份验证提供商。
## 本地上下文文件
助手支持一个用于提供“本地上下文”的可选文件。这为您提供了一种向 LLM 提供有关您的环境或偏好的提示和指导的方法,以便您可以根据自己的需求调整 AI,而无需编辑提示词。如果存在此上下文文件,其名称应为 `context.txt`,并应放置在仓库的根目录中。它应包含有助于 AI 智能体了解您特定环境的信息,例如:
- 组织结构和命名约定
- 正在使用的特定技术和工具
- 与您的组织相关的已知威胁行为者或活动
- 合规性要求或监管注意事项
- 关于在何处查找以往安全事件工单、狩猎文档或其他本地数据源的提示
- 有关您最常用的数据源及其访问方式的详细信息
没有特定的格式要求,但您可能会发现建立某种基本结构有助于您随着时间推移轻松维护它。以下是一个简单的示例:
```
Environmental hints:
- We use primarily Splunk SIEM and Zeek NIDS.
Local Information Sources:
- Always consult the following sources of information when you are preparing your local research
reports, using the Atlassian MCP server.
- Hunt team documents hunts in Confluence wiki, under the "Threat Hunting" space
- Hunt team tracks in-progress and upcoming hunts in Jira, under the "Threat Hunting" project
- The Atlassian server is my-cloud-tenant.atlassian.net.
Splunk hints:
- If you encounter base64-encoded data, and if you decide that you must decode it,
you can use the following sample SPL as a reference:
标签:ABCD/ABLE表格, AI助手, API集成, C2, DLL 劫持, Generative AI, Kubernetes, LLM, MCP服务器, PEAK框架, PoC, PyRIT, Unmanaged PE, 假设驱动狩猎, 可观测性, 多智能体系统, 大语言模型, 威胁情报, 威胁研究, 安全运营, 底层编程, 开发者工具, 扫描框架, 暴力破解, 概念验证, 网络安全, 自动化报告生成, 请求拦截, 逆向工具, 隐私保护