sansan0/TrendRadar
GitHub: sansan0/TrendRadar
AI 驱动的全网舆情聚合与热点筛选工具,支持多平台热榜抓取、RSS 订阅、智能推送和对话式数据分析。
Stars: 59470 | Forks: 24670
 最快30秒部署的热点助手 —— 告别无效刷屏,只看真正关心的新闻资讯
最快30秒部署的热点助手 —— 告别无效刷屏,只看真正关心的新闻资讯
**中文** | **[English](README-EN.md)**
## 📑 快速导航
| | | |
|:---:|:---:|:---:|
| [🚀 **快速开始**](#-快速开始) | [AI 智能分析](#-ai-智能分析) | [⚙️ **配置详解**](#配置详解) |
| [Docker部署](#6-docker-部署) | [MCP客户端](#-mcp-客户端) | [📝 **更新日志**](#-更新日志) |
| [🎯 **核心功能**](#-核心功能) | [☕ **支持项目**](#-支持项目) | [📚 **项目相关**](#-项目相关) |
### 🤝 二次开发与引用 如果你在项目中使用或借鉴了本项目的思路、核心代码,**非常欢迎**在 README 或文档中注明来源并附上本仓库链接。 这将有助于项目的持续维护和社区发展,感谢你的尊重与支持!❤️ ### 💬 交流与反馈 - **GitHub Issues**:适合具体的技术问题。提问时请提供完整信息(截图、错误日志等),有助于快速定位。 - **公众号交流**:建议优先在相关文章下的留言区交流。若需后台提问,**先点赞/推荐**文章是最好的“敲门砖”,我在后台都能感受到这份心意哟 (´▽`ʃ♡ƪ)。
|公众号关注 |
|:---:|
|  |
|
|
## 📝 更新日志 - **提示**:建议查看【历史更新】,明确具体的【功能内容】 ### 2026/03/12 - v6.5.0 - **AI 智能筛选系统**:不用再手动设关键词!在 `ai_interests.txt` 里用日常语言写下你关注的方向(如"我想看 AI 和新能源相关新闻"),AI 会自动提取标签并对每条新闻打分,只推送真正和你相关的内容。万一 AI 筛选出了问题,会自动切回关键词匹配,推送不中断 - **每个时段支持不同的筛选方式和关注方向**:Timeline 中的每个时间段现在可以独立设置用什么方式筛选、看什么类型的新闻。比如:早上用"科技关键词"快速过滤,晚上换成"金融 AI 兴趣描述"做深度筛选——同一个系统,不同时段看不同内容 - **AI 分析范围独立于推送**:AI 分析的数据范围可以和推送内容不同。比如推送只发新增消息(避免重复打扰),但 AI 分析当天全部新闻(看完整趋势)。每个时段也能单独设置 AI 分析模式 - **AI 筛选智能省钱**:已分析过的新闻不会重复消耗 token;兴趣描述修改后,AI 自动判断变化幅度——小改动只更新受影响的标签,大改动才全量重新分类 - **多文件配置与标签隔离**:自定义关键词文件放 `config/custom/keyword/`,AI 兴趣文件放 `config/custom/ai/`,不同文件产生的标签各自独立、互不干扰 - **AI 翻译精准控制**:可分别控制热榜、RSS、独立展示区是否翻译,没开启显示的区域自动跳过,不浪费 token - **远程存储批量上传**:多次写操作攒在一起统一提交云端,减少 API 调用次数 - **每组关键词/标签展示数量限制**:通过 `max_news_per_keyword` 控制每个分组最多显示多少条新闻,避免单个热门话题占满整条推送 - **时段冲突智能检测**:两个时间段如果有时间重叠,系统会自动报错提醒修改,避免配置冲突导致意外行为 - 修复若干bug ### 2026/02/09 - mcp-v4.0.0 - **🔥 AI 消息直推所有渠道**:让 AI 写好的内容一键推送到飞书、钉钉、Telegram、邮件等 9 个渠道,Markdown 自动适配各平台格式,不用操心格式差异 - **新增格式化策略指南**:新增 `get_channel_format_guide` 工具,告诉 AI 每个渠道支持什么格式、有什么限制,生成的内容排版更好看 - **智能分批发送**:超长消息自动按各渠道字节限制拆分(飞书 30KB、钉钉 20KB 等),配置读取自 config.yaml - **修复渠道误检测**:ntfy 不再因为默认地址被误报为"已配置" - **代码复用优化**:批次处理函数直接复用 trendradar 核心模块,不重复造轮子
👉 点击展开:历史更新
### 2026/02/09 - v6.0.0 - **统一调度系统**:新增 `timeline.yaml`,用一套配置控制「什么时间采集 / 推送 / AI 分析」 - **5 种预设模板**:`always_on`(全天候,默认)、`morning_evening`(早晚汇总)、`office_hours`(办公时间)、`night_owl`(夜猫子)、`custom`(自定义);也支持在 `presets:` 下新增自己的模板,只要 key 不重复,然后在 config.yaml 里填你的模板名即可 - **灵活的时间段配置**:支持工作日/周末差异化、跨午夜时间段、per-period once 去重 - **可视化配置编辑器**: - 新增 `timeline.yaml` 编辑标签页,与 config.yaml / frequency_words.txt 并列 - 预设模式卡片选择:点击即切换,自动同步 config.yaml 的 `schedule.preset` - 周视图时间线:7 天 × 24 小时水平条,用颜色区分推送/分析/采集状态 - 可交互控件:开关、下拉框、时间选择器,右侧修改实时同步到左侧 YAML - 周映射下拉选择:根据日计划动态填充,拖拉点击即可完成调度配置 - **AI 提示词稳定性优化**(ai_analysis_prompt.txt v2.0.0): - 格式规范独立说明:将换行/标签/序号/禁止事项从 JSON value 中抽出,作为独立章节 - JSON 模板简化:字段描述缩短为一句话 + 字数限制,减少 AI 输出格式混乱 - 去除 system prompt 中的 Markdown 格式,与"禁止 Markdown"指令保持一致 - 所有 JSON 字段声明为可选,缺少任何字段不会报错,增强容错性 - **新增独立展示区 AI 概括分析**(`ai_analysis.include_standalone`): - 新增独立开关,开启后 AI 对每个 standalone 源生成核心概括 - AI 分析与推送展示解耦:无需开启独立展示区的推送显示,AI 也可独立分析完整热榜数据 - 支持热榜平台和 RSS 源,含排名/时间/轨迹数据 - 轨迹分析与 `include_rank_timeline` 联动:开启时利用轨迹数据做深度趋势分析,关闭时基于排名做简要判断 - 新增 `standalone_summaries` JSON 字段(独立源点速览),所有推送渠道均已适配渲染 ### 2026/01/28 - v5.5.0 - 增加 trendradar 的可视化配置编辑器 ### 2026/02/02 - mcp-v3.2.0 - **新增 read_article 工具**:通过 Jina AI Reader 读取单篇文章正文(Markdown 格式) - **新增 read_articles_batch 工具**:批量读取多篇文章(最多 5 篇,自动限速) - **推荐工作流**:`search_news(query="关键词", include_url=True)` → `read_article(url=...)` 读取正文 - **文档更新**:README-MCP-FAQ.md 和 README-MCP-FAQ-EN.md 新增 Q19-Q20 文章读取相关说明 ### 2026/01/10 - mcp-v3.0.0~v3.1.5 - **Breaking Change**:所有工具返回值统一为 `{success, summary, data, error}` 结构 - **异步一致性**:所有 21 个工具函数使用 `asyncio.to_thread()` 包装同步调用 - **MCP Resources**:新增 4 个资源(platforms、rss-feeds、available-dates、keywords) - **RSS 增强**:`get_latest_rss` 支持多日查询(days 参数),跨日期 URL 去重 - **正则匹配修复**:`get_trending_topics` 支持 `/pattern/` 正则语法和 `display_name` - **缓存优化**:新增 `make_cache_key()` 函数,参数排序+MD5 哈希确保一致性 - **新增 check_version 工具**:支持同时检查 TrendRadar 和 MCP Server 版本更新 ### 2026/01/23 - v5.4.0 - 增加 AI 分析模式的独立控制功能,可选 follow_report | daily | current | incremental - 新增 AI 分析时间窗口控制,支持自定义运行段及每日频次限制 - 增加配置文件版本管理功能 - 修复若干bug ### 2026/01/19 - v5.3.0 - **统一 AI 接口**:使用 LiteLLM 替代手动实现,支持 100+ AI 提供商 - **简化配置**:移除 `provider` 字段,改用 `model: "provider/model_name"` 格式 - **新增功能**:自动重试 (`num_retries`)、备用模型 (`fallback_models`) - **配置变更**: - `ai.provider` → 移除(已合并到 model) - `ai.base_url` → `ai.api_base` - `AI_PROVIDER` 环境变量 → 移除 - `AI_BASE_URL` 环境变量 → `AI_API_BASE` - **模型格式示例**: - DeepSeek: `deepseek/deepseek-chat` - OpenAI: `openai/gpt-4o` - Gemini: `gemini/gemini-2.5-flash` - Anthropic: `anthropic/claude-3-5-sonnet` ### 2026/01/17 - v5.2.0 **🌐 AI 翻译功能** - **多语言翻译**:支持将推送内容翻译为任意语言 - **批量翻译**:智能批量处理,减少 API 调用次数 - **自定义提示词**:支持自定义翻译风格 **🔧 配置架构优化** - **AI 模配置独立**:分析和翻译共享模型配置 - **区域开关统一**:统一管理推送区域显示 - **区域排序自定义**:支持自定义各区域的显示顺序 **✨ AI 分析增强** - **AI 分析嵌入 HTML**:分析结果直接嵌入 HTML 报告,邮件通知直接使用 - **富样式 AI 区块**:渐变蓝色背景卡片式布局,清晰分隔各分析维度 - **排名时间线支持**:AI 可获取每条新闻在每个抓取时间点的精确排名 - **板块重组 (7→4)**:整合为核心热点态势、舆论风向争议、异动与弱信号、研判策略建议 **🔧 多模型适配** - **通用参数透传**:支持向 API 透传任意高级参数 - **Gemini 适配**:原生参数支持,内置安全策略放宽 **🐛 Bug 修复** - 修复若干已知问题,提升系统稳定性 ### 2026/01/10 - v5.0.0 **✨ 推送内容"五大板块"重构** 本次更新对推送消息进行了区域化重构,现在推送内容清晰地划分为五大核心板块: 1. **📊 热榜新闻**:根据你的关键词精准筛选后的全网热点聚合。 2. **📰 RSS 订阅**:你的个性化订阅源内容,支持按关键词分组。 3. **🆕 本次新增**:实时捕捉自上次运行以来的全新热点(带 🆕 标记)。 4. **📋 独立展示区**:指定平台的完整热榜或 RSS 源展示,**完全不受关键词过滤限制**。 5. **✨ AI 分析板块**:由 AI 驱动的深度洞察,包含趋势概述、热度走势及**极其重要**的情感倾向分析。 **✨ AI 智能分析推送功能** - **AI 分析集成**:使用 AI 大模型对推送内容进行深度分析,自动生成热点趋势概述、关键词热度分析、跨平台关联、潜在影响评估等 - **情感倾向分析**:新增深度情感识别,精准捕捉舆论的正负面、争议或担忧情绪 - **多 AI 提供商支持**:支持 DeepSeek(默认,性价比高)、OpenAI、Google Gemini 及任意 OpenAI 兼容接口 - **两种推送模式**:`only_analysis`(仅 AI 分析)、`both`(两者都推送) - **自定义提示词**:通过 `config/ai_analysis_prompt.txt` 文件自定义 AI 分析角色和输出格式 - **多维度数据分析**:AI 可分析排名变化、热度持续时间、跨平台表现、趋势预测等 **📋 独立展示区功能** - **完整热榜展示**:指定平台的完整热榜单独展示,不受关键词过滤影响 - **RSS 独立展示**:RSS 源内容可完整展示,适合内容较少的订阅源 - **灵活配置**:支持配置展示平台列表、RSS 源列表、最大展示条数 **📊 推送体验重构** - **排版升级**:重新设计并统一各渠道统计头部,强化区块组织,消息层次一目了然 - **配置简化**:优化飞书等通知渠道的配置逻辑,上手更简单 - **热度趋势箭头**:新增 🔺(上升)、🔻(下降)、➖(持平) 趋势标识,直观展示热度变化 - **通用 Webhook**:支持自定义 Webhook URL 和 JSON 模板,轻松适配 Discord、Matrix、IFTTT 等任意平台 **🔧 配置优化** - **频率词配置增强**:新增 `[组别名]` 语法,支持 `#` 注释行,配置更清晰(感谢 [@songge8](https://github.com/sansan0/TrendRadar/issues/752) 提出的建议) - **环境变量支持**:AI 分析相关配置支持环境变量覆盖(`AI_API_KEY`、`AI_PROVIDER` 等) ### 2026/01/02 - v4.7.0 - **修复 RSS HTML 显示**:修复 RSS 数据格式不匹配导致的渲染问题,现在按关键词分组正确显示 - **新增正则表达式语法**:关键词配置支持 `/pattern/` 正则语法,解决英文子字符串误匹配问题(如 `ai` 匹配 `training`)[📖 查看语法详解](#关键词基础语法) - **新增显示名称语法**:使用 `=> 备注` 给复杂的正则表达式起个好记的名字,推送消息显示更清晰(如 `/\bai\b/ => AI相关`) - **不会写正则?** README 新增 AI 生成正则的引导,告诉 ChatGPT/Gemini/DeepSeek 你想匹配什么,让 AI 帮你写 ### 2025/12/30 - mcp-v2.0.0 - **架构调整**:移除 TXT 支持,统一使用 SQLite 数据库 - **RSS 查询**:新增 `get_latest_rss`、`search_rss`、`get_rss_feeds_status` - **统一搜索**:`search_news` 支持 `include_rss` 参数同时搜索热榜和 RSS ### 2026/01/01 - v4.6.0 - **修复 RSS HTML 显示**:将 RSS 内容合并到热榜 HTML 页面,按源分组显示 - **新增 display_mode 配置**:支持 `keyword`(按关键词分组)和 `platform`(按平台分组)两种显示模式 ### 2025/12/30 - v4.5.0 - **RSS 订阅源支持**:新增 RSS/Atom 抓取,按关键词分组统计(与热榜格式一致) - **存储结构重构**:扁平化目录结构 `output/{type}/{date}.db` - **统一排序配置**:`sort_by_position_first` 同时影响热榜和 RSS - **配置结构重构**:`config.yaml` 重新组织为 7 个逻辑分组(app、report、notification、storage、platforms、rss、advanced),配置路径更清晰 ### 2025/12/26 - mcp-v1.2.0 **MCP 模块更新 - 优化工具集,新增聚合对比功能,合并冗余工具:** - 新增 `aggregate_news` 工具 - 跨平台新闻去重聚合 - 新增 `compare_periods` 工具 - 时期对比分析(周环比/月环比) - 合并 `find_similar_news` + `search_related_news_history` → `find_related_news` - 增强 `get_trending_topics` - 新增 `auto_extract` 模式自动提取热点 - 修复若干bug - 同步更新 README-MCP-FAQ.md 文档的中英文版 (Q1-Q18) ### 2025/12/20 - v4.0.3 - 新增 URL 标准化功能,解决微博等平台因动态参数(如 `band_rank`)导致的重复推送问题 - 修复增量模式检测逻辑,正确识别历史标题 ### 2025/12/17 - v4.0.1 - StorageManager 添加推送记录代理方法 - S3 客户端切换至 virtual-hosted style 以提升兼容性(支持腾讯云 COS 等更多服务) ### 2025/12/13 - mcp-v1.1.0 **MCP 模块更新:** - 适配 v4.0.0,同时也兼容 v3.x 的数据 - 新增存储同步工具:`sync_from_remote`、`get_storage_status`、`list_available_dates` ### 2025/12/13 - v4.0.0 **🎉 重大更新:全面重构存储和核心架构** - **多存储后端支持**:引入全新的存储模块,支持本地 SQLite 和远程云存储(S3 兼容协议,例如 Cloudflare R2),适应 GitHub Actions、Docker 和本地环境。 - **数据库结构优化**:重构 SQLite 数据库表结构,提升数据效率和查询能力。 - **核心代码模块化**:将主程序逻辑拆分为 trendradar 包的多个模块,显著提升代码可维护性。 - **增强功能**:实现日期格式标准化、数据保留策略、时区配置支持、时间显示优化,并修复远程存储数据持久化问题,确保数据合并的准确性。 - **清理和兼容**:移除了大部分历史兼容代码,统一了数据存储和读取方式。 ### 2025/12/03 - v3.5.0 **🎉 核心功能增强** 1. **多账号推送支持** - 所有推送渠道(飞书、钉钉、企业微信、Telegram、ntfy、Bark、Slack)支持多账号配置 - 使用分号 `;` 分隔多个账号,例如:`FEISHU_WEBHOOK_URL=url1;url2` - 自动验证配对配置(如 Telegram 的 token 和 chat_id)数量一致性 2. **推送区域配置** - 通过 `display.region_order` 自定义各区域的显示顺序(v5.2.0 替代原 `reverse_content_order`) - 通过 `display.regions` 控制各区域是否显示(热榜、新增热点、RSS、独立展示区、AI 分析) 3. **全局过滤关键词** - 新增 `[GLOBAL_FILTER]` 区域标记,支持全局过滤不想看到的内容 - 适用场景:过滤广告、营销、低质内容等 **🐳 Docker 双路径 HTML 生成优化** - **问题修复**:解决 Docker 环境下 `index.html` 无法同步到宿主机的问题 - **双路径生成**:当日汇总 HTML 同时生成到两个位置 - `index.html`(项目根目录):供 GitHub Pages 访问 - `output/index.html`:通过 Docker Volume 挂载,宿主机可直接访问 - **兼容性**:确保 Docker、GitHub Actions、本地运行环境均能正常访问网页版报告 **🐳 Docker MCP 镜像支持** - 新增独立的 MCP 服务镜像 `wantcat/trendradar-mcp` - 支持 Docker 部署 AI 分析功能,通过 HTTP 接口(端口 3333)提供服务 - 双容器架构:新闻推送服务与 MCP 服务独立运行,可分别扩展和重启 - 详见 [Docker 部署 - MCP 服务](#6-docker-部署) **🌐 Web 服务器支持** - 新增内置 Web 服务器,支持通过浏览器访问生成的报告 - 通过 `manage.py` 命令控制启动/停止:`docker exec -it trendradar python manage.py start_webserver` - 访问地址:`http://localhost:8080`(端口可配置) - 安全特性:静态文件服务、目录限制、本地访问 - 支持自动启动和手动控制两种模式 **📖 文档优化** - 新增 [推送内容怎么显示?](#7-推送内容怎么显示) 章节:自定义推送样式和内容 - 新增 [什么时候给我推送?](#8-什么时候给我推送) 章节:设置推送时间段 - 新增 [多久运行一次?](#9-多久运行一次) 章节:设置自动运行频率 - 新增 [推送到多个群/设备](#10-推送到多个群设备) 章节:同时推送给多个接收者 - 优化各配置章节:统一添加"配置位置"说明 - 简化快速开始配置说明:三个核心文件一目了然 - 优化 [Docker 部署](#6-docker-部署) 章节:新增镜像说明、推荐 git clone 部署、重组部署方式 **🔧 升级说明**: - **GitHub Fork 用户**:更新 `main.py`、`config/config.yaml`(新增多账号推送支持,无需修改现有配置) - **多账号推送**:新功能,默认不启用,现有单账号配置不受影响 ### 2025/11/26 - mcp-v1.0.3 **MCP 模块更新:** - 新增日期解析工具 resolve_date_range,解决 AI 模型计算日期不一致的问题 - 支持自然语言日期表达式解析(本周、最近7天、上月等) - 工具总数从 13 个增加到 14 个 ### 2025/11/28 - v3.4.1 **🔧 格式优化** 1. **Bark 推送增强** - Bark 现支持 Markdown 渲染 - 启用原生 Markdown 格式:粗体、链接、列表、代码块等 - 移除纯文本转换,充分利用 Bark 原生渲染能力 2. **Slack 格式精准化** - 使用专用 mrkdwn 格式处理分批内容 - 提升字节大小估算准确性(避免消息超限) - 优化链接格式:`
优化前
|
优化后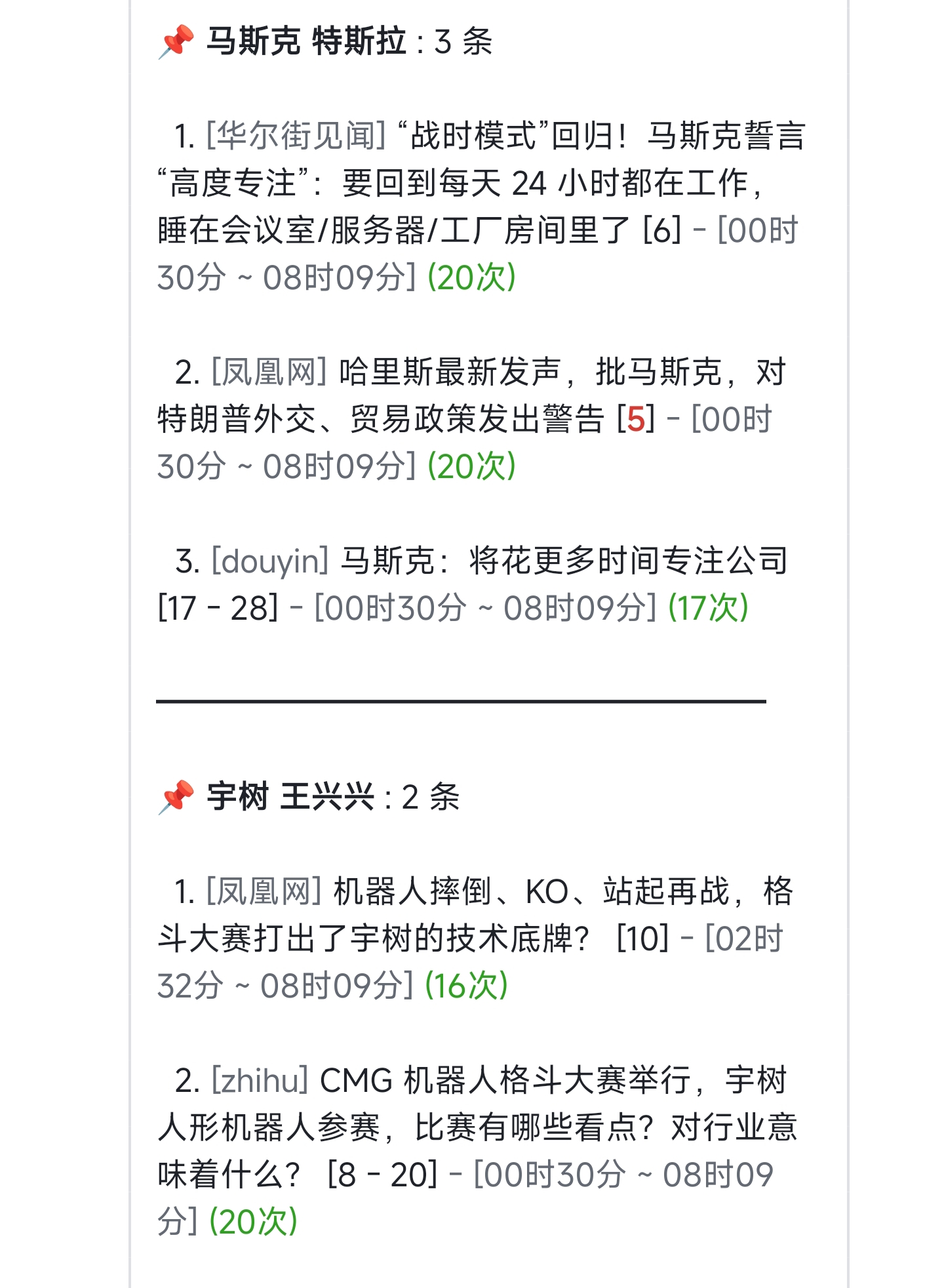
|
## ✨ 核心功能 ### **全网热点聚合** - 知乎 - 抖音 - bilibili 热搜 - 华尔街见闻 - 贴吧 - 百度热搜 - 财联社热门 - 澎湃新闻 - 凤凰网 - 今日头条 - 微博 默认监控 11 个主流平台,也可自行增加额外的平台 ### **RSS 订阅源支持**(v4.5.0 新增) 支持 RSS/Atom 订阅源抓取,按关键词分组统计(与热榜格式一致): - **统一格式**:RSS 与热榜使用相同的关键词匹配和显示格式 - **简单配置**:直接在 `config.yaml` 中添加 RSS 源 - **合并推送**:热榜和 RSS 合并为一条消息推送 - **新鲜度过滤**:自动过滤超过指定天数的旧文章,避免重复推送。支持全局默认天数和单源独立设置 ### **可视化配置编辑器** 提供基于 Web 的图形化配置界面,无需手动编辑 YAML 文件,通过表单即可完成所有配置项的修改与导出。 👉 **在线体验**:[https://sansan0.github.io/TrendRadar/](https://sansan0.github.io/TrendRadar/)
 ### **智能推送策略**
**三种推送模式**:
| 模式 | 适用场景 | 推送特点 |
|------|---------|---------|
| **当日汇总** (daily) | 企业管理者/普通用户 | 按时推送当日所有匹配新闻(会包含之前推送过的) |
| **当前榜单** (current) | 自媒体人/内容创作者 | 按时推送当前榜单匹配新闻(持续在榜的每次都出现) |
| **增量监控** (incremental) | 投资者/交易员 | 仅推送新增内容,零重复 |
**附加功能**(可选):
| 功能 | 说明 | 默认 |
|------|------|------|
| **调度系统** | 按周一到周日逐日编排:为每天分配不同时间段、推送模式和 AI 分析策略。**每个时段可独立设置筛选方式(关键词/AI)和关注方向**,实现不同时间看不同类型新闻。内置 5 种预设(always_on / morning_evening / office_hours / night_owl / custom),也可自定义。支持工作日/周末差异化、跨午夜时段、per-period 去重、时段冲突检测(v6.0.0 + v6.5.0) | morning_evening |
| **内容顺序配置** | 通过 `display.region_order` 调整各区域(热榜、新增热点、RSS、独立展示区、AI 分析)的显示顺序;通过 `display.regions` 控制各区域是否显示(v5.2.0) | 见配置文件 |
| **显示模式切换** | `keyword`=按关键词分组,`platform`=按平台分组(v4.6.0 新增) | keyword |
### **精准内容筛选**
设置个人关键词(如:AI、比亚迪、教育政策),只推送相关热点,过滤无关信息
### **AI 智能筛选新闻**(v6.5.0 新增)
用自然语言描述你的兴趣,AI 自动分类新闻,替代传统关键词匹配
- **自然语言兴趣描述**:在 `ai_interests.txt` 中用日常语言写下关注方向,无需学习关键词语法
- **两阶段智能处理**:AI 先从兴趣描述提取结构化标签,再对新闻按标签批量分类打分
- **分数阈值控制**:通过 `ai_filter.min_score` 精确控制推送质量,只推送高相关度新闻
- **自动回退保障**:AI 筛选失败时自动回退到关键词匹配,确保推送不中断
- **智能标签更新**:兴趣变更时 AI 自动评估变化幅度,决定增量或全量重分类
- **灵活切换**:`filter.method` 支持 `keyword`(默认)和 `ai` 两种模式,Timeline 可按时段覆盖
- **分时段个性化**:不同时间段可以使用不同的关键词文件或 AI 兴趣描述。例如早上用"科技词库"快速过滤,晚上换成"金融兴趣"做 AI 深度筛选
```
# config.yaml 快速启用示例
filter:
method: ai # keyword(默认)| ai
ai_filter:
min_score: 6 # 推送最低分数阈值(1-10)
```
### **热点趋势分析**
实时追踪新闻热度变化,让你不仅知道"什么在热搜",更了解"热点如何演变"
- **时间轴追踪**:记录每条新闻从首次出现到最后出现的完整时间跨度
- **热度变化**:统计新闻在不同时间段的排名变化和出现频次
- **新增检测**:实时识别新出现的热点话题,用🆕标记第一时间提醒
- **持续性分析**:区分一次性热点话题和持续发酵的深度新闻
- **跨平台对比**:同一新闻在不同平台的排名表现,看出媒体关注度差异
### **个性化热点算法**
不再被各个平台的算法牵着走,TrendRadar 会重新整理全网热搜
### **多渠道多账号推送**
支持**企业微信**(+ 微信推送方案)、**飞书**、**钉钉**、**Telegram**、**邮件**、**ntfy**、**Bark**、**Slack**、**通用 Webhook**(可对接 Discord、IFTTT 等任意平台),消息直达手机和邮箱
### **AI 多语言翻译**(v5.2.0 新增)
将推送内容翻译为任意语言,打破语言壁垒,无论是阅读国内热点还是通过 RSS 订阅海外资讯,都能以母语轻松获取
- **一键翻译**:在 `config.yaml` 中设置 `ai_translation.enabled: true` 和目标语言即可
- **多语言支持**:支持 English、Korean、Japanese、French 等任意语言
- **智能批量处理**:自动批量翻译,减少 API 调用次数,节省成本
- **自定义风格**:通过 `ai_translation_prompt.txt` 自定义翻译风格和术语
- **共享模型配置**:与 AI 分析功能共用 `ai` 配置段的模型设置
```
# config.yaml 快速启用示例
ai_translation:
enabled: true
language: "English" # 翻译目标语言
```
**RSS 源参考**:以下是一些 RSS 订阅源合集,可按需选用
- [awesome-tech-rss](https://github.com/tuan3w/awesome-tech-rss) - 科技、创业、编程领域博客和媒体
- [awesome-rss-feeds](https://github.com/plenaryapp/awesome-rss-feeds) - 世界各国主流新闻媒体 RSS 合集
### **灵活存储架构**(v4.0.0 重大更新)
**多存储后端支持**:
- **远程云存储**:GitHub Actions 环境默认,支持 S3 兼容协议(R2/OSS/COS 等),数据存储在云端,不污染仓库
- **本地 SQLite 数据库**:Docker/本地环境默认,数据完全可控
- **自动后端选择**:根据运行环境智能切换存储方式
### **多端部署**
- **GitHub Actions**:定时自动爬取 + 远程云存储(需签到续期)
- **Docker 部署**:支持多架构容器化运行,数据本地存储
- **本地运行**:Windows/Mac/Linux 直接运行
### **AI 分析推送(v5.0.0 新增)**
使用 AI 大模型对推送内容进行深度分析,自动生成热点洞察报告
- **智能分析**:自动分析热点趋势、关键词热度、跨平台关联、潜在影响
- **多提供商**:基于 LiteLLM 统一接口,支持 100+ AI 提供商(DeepSeek、OpenAI、Gemini、Anthropic、本地 Ollama 等),还支持备用模型自动切换
- **分析模式独立**:AI 的分析范围可以和推送不同——推送只发新增消息(避免打扰),但 AI 可以分析当天全部新闻(看完整趋势)
- **灵活推送**:可选仅原始内容、仅 AI 分析、或两者都推送
- **自定义提示词**:通过 `config/ai_analysis_prompt.txt` 自定义分析角度
### **独立展示区(v5.0.0 新增)**
为指定平台提供完整热榜展示,不受关键词过滤影响
- **完整热榜**:指定平台的热榜完整展示,适合想看完整排名的用户
- **RSS 独立展示**:RSS 源内容可完整展示,不受关键词限制
- **AI 深度分析**:可独立开启 AI 对完整热榜的趋势分析,无需在推送中展示
- **灵活配置**:支持配置展示平台、RSS 源、最大条数
### **AI 智能分析(v3.0.0 新增)**
基于 MCP (Model Context Protocol) 协议的 AI 对话分析系统,让你用自然语言深度挖掘新闻数据
### **网页部署**
运行后根目录生成 `index.html`,即为完整的新闻报告页面。
### **减少 APP 依赖**
从"被算法推荐绑架"变成"主动获取自己想要的信息"
**适合人群:** 投资者、自媒体人、企业公关、关心时事的普通用户
**典型场景:** 股市投资监控、品牌舆情追踪、行业动态关注、生活资讯获取
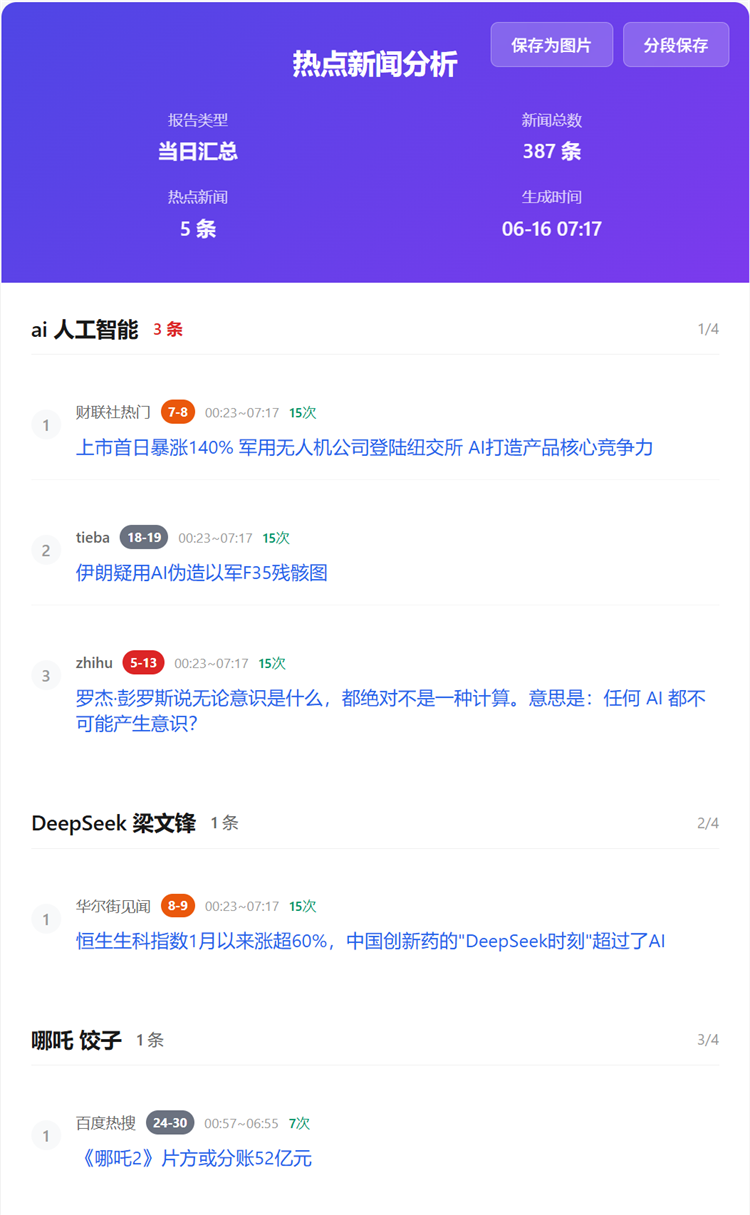
| 网页效果(邮箱推送效果) | 飞书推送效果 | AI 分析推送效果 |
|:---:|:---:|:---:|
|  |  |  |
### **智能推送策略**
**三种推送模式**:
| 模式 | 适用场景 | 推送特点 |
|------|---------|---------|
| **当日汇总** (daily) | 企业管理者/普通用户 | 按时推送当日所有匹配新闻(会包含之前推送过的) |
| **当前榜单** (current) | 自媒体人/内容创作者 | 按时推送当前榜单匹配新闻(持续在榜的每次都出现) |
| **增量监控** (incremental) | 投资者/交易员 | 仅推送新增内容,零重复 |
**附加功能**(可选):
| 功能 | 说明 | 默认 |
|------|------|------|
| **调度系统** | 按周一到周日逐日编排:为每天分配不同时间段、推送模式和 AI 分析策略。**每个时段可独立设置筛选方式(关键词/AI)和关注方向**,实现不同时间看不同类型新闻。内置 5 种预设(always_on / morning_evening / office_hours / night_owl / custom),也可自定义。支持工作日/周末差异化、跨午夜时段、per-period 去重、时段冲突检测(v6.0.0 + v6.5.0) | morning_evening |
| **内容顺序配置** | 通过 `display.region_order` 调整各区域(热榜、新增热点、RSS、独立展示区、AI 分析)的显示顺序;通过 `display.regions` 控制各区域是否显示(v5.2.0) | 见配置文件 |
| **显示模式切换** | `keyword`=按关键词分组,`platform`=按平台分组(v4.6.0 新增) | keyword |
### **精准内容筛选**
设置个人关键词(如:AI、比亚迪、教育政策),只推送相关热点,过滤无关信息
### **AI 智能筛选新闻**(v6.5.0 新增)
用自然语言描述你的兴趣,AI 自动分类新闻,替代传统关键词匹配
- **自然语言兴趣描述**:在 `ai_interests.txt` 中用日常语言写下关注方向,无需学习关键词语法
- **两阶段智能处理**:AI 先从兴趣描述提取结构化标签,再对新闻按标签批量分类打分
- **分数阈值控制**:通过 `ai_filter.min_score` 精确控制推送质量,只推送高相关度新闻
- **自动回退保障**:AI 筛选失败时自动回退到关键词匹配,确保推送不中断
- **智能标签更新**:兴趣变更时 AI 自动评估变化幅度,决定增量或全量重分类
- **灵活切换**:`filter.method` 支持 `keyword`(默认)和 `ai` 两种模式,Timeline 可按时段覆盖
- **分时段个性化**:不同时间段可以使用不同的关键词文件或 AI 兴趣描述。例如早上用"科技词库"快速过滤,晚上换成"金融兴趣"做 AI 深度筛选
```
# config.yaml 快速启用示例
filter:
method: ai # keyword(默认)| ai
ai_filter:
min_score: 6 # 推送最低分数阈值(1-10)
```
### **热点趋势分析**
实时追踪新闻热度变化,让你不仅知道"什么在热搜",更了解"热点如何演变"
- **时间轴追踪**:记录每条新闻从首次出现到最后出现的完整时间跨度
- **热度变化**:统计新闻在不同时间段的排名变化和出现频次
- **新增检测**:实时识别新出现的热点话题,用🆕标记第一时间提醒
- **持续性分析**:区分一次性热点话题和持续发酵的深度新闻
- **跨平台对比**:同一新闻在不同平台的排名表现,看出媒体关注度差异
### **个性化热点算法**
不再被各个平台的算法牵着走,TrendRadar 会重新整理全网热搜
### **多渠道多账号推送**
支持**企业微信**(+ 微信推送方案)、**飞书**、**钉钉**、**Telegram**、**邮件**、**ntfy**、**Bark**、**Slack**、**通用 Webhook**(可对接 Discord、IFTTT 等任意平台),消息直达手机和邮箱
### **AI 多语言翻译**(v5.2.0 新增)
将推送内容翻译为任意语言,打破语言壁垒,无论是阅读国内热点还是通过 RSS 订阅海外资讯,都能以母语轻松获取
- **一键翻译**:在 `config.yaml` 中设置 `ai_translation.enabled: true` 和目标语言即可
- **多语言支持**:支持 English、Korean、Japanese、French 等任意语言
- **智能批量处理**:自动批量翻译,减少 API 调用次数,节省成本
- **自定义风格**:通过 `ai_translation_prompt.txt` 自定义翻译风格和术语
- **共享模型配置**:与 AI 分析功能共用 `ai` 配置段的模型设置
```
# config.yaml 快速启用示例
ai_translation:
enabled: true
language: "English" # 翻译目标语言
```
**RSS 源参考**:以下是一些 RSS 订阅源合集,可按需选用
- [awesome-tech-rss](https://github.com/tuan3w/awesome-tech-rss) - 科技、创业、编程领域博客和媒体
- [awesome-rss-feeds](https://github.com/plenaryapp/awesome-rss-feeds) - 世界各国主流新闻媒体 RSS 合集
### **灵活存储架构**(v4.0.0 重大更新)
**多存储后端支持**:
- **远程云存储**:GitHub Actions 环境默认,支持 S3 兼容协议(R2/OSS/COS 等),数据存储在云端,不污染仓库
- **本地 SQLite 数据库**:Docker/本地环境默认,数据完全可控
- **自动后端选择**:根据运行环境智能切换存储方式
### **多端部署**
- **GitHub Actions**:定时自动爬取 + 远程云存储(需签到续期)
- **Docker 部署**:支持多架构容器化运行,数据本地存储
- **本地运行**:Windows/Mac/Linux 直接运行
### **AI 分析推送(v5.0.0 新增)**
使用 AI 大模型对推送内容进行深度分析,自动生成热点洞察报告
- **智能分析**:自动分析热点趋势、关键词热度、跨平台关联、潜在影响
- **多提供商**:基于 LiteLLM 统一接口,支持 100+ AI 提供商(DeepSeek、OpenAI、Gemini、Anthropic、本地 Ollama 等),还支持备用模型自动切换
- **分析模式独立**:AI 的分析范围可以和推送不同——推送只发新增消息(避免打扰),但 AI 可以分析当天全部新闻(看完整趋势)
- **灵活推送**:可选仅原始内容、仅 AI 分析、或两者都推送
- **自定义提示词**:通过 `config/ai_analysis_prompt.txt` 自定义分析角度
### **独立展示区(v5.0.0 新增)**
为指定平台提供完整热榜展示,不受关键词过滤影响
- **完整热榜**:指定平台的热榜完整展示,适合想看完整排名的用户
- **RSS 独立展示**:RSS 源内容可完整展示,不受关键词限制
- **AI 深度分析**:可独立开启 AI 对完整热榜的趋势分析,无需在推送中展示
- **灵活配置**:支持配置展示平台、RSS 源、最大条数
### **AI 智能分析(v3.0.0 新增)**
基于 MCP (Model Context Protocol) 协议的 AI 对话分析系统,让你用自然语言深度挖掘新闻数据
### **网页部署**
运行后根目录生成 `index.html`,即为完整的新闻报告页面。
### **减少 APP 依赖**
从"被算法推荐绑架"变成"主动获取自己想要的信息"
**适合人群:** 投资者、自媒体人、企业公关、关心时事的普通用户
**典型场景:** 股市投资监控、品牌舆情追踪、行业动态关注、生活资讯获取
| 网页效果(邮箱推送效果) | 飞书推送效果 | AI 分析推送效果 |
|:---:|:---:|:---:|
|  |  |  |
## 🚀 快速开始 ### 请选择适合你的部署方式 #### 🅰️ 方案一:Docker 部署(推荐 🔥) * **特点**:比 GitHub Actions 更稳定,数据本地存储(无需配置云存储) * **适用**:有自己的服务器、NAS 或长期运行的电脑 * **注意**:你需要阅读了解下方的基础配置流程,然后跳转到 Docker 教程进行部署。 #### 🅱️ 方案二:GitHub Actions 部署(本章节内容 ⬇️) * **特点**:无服务器,数据存储在 **远程云存储**(推荐配置) * **适用**:没有服务器的用户,利用 GitHub 免费资源 * **注意**:需配置云存储以获得完整体验,且需定期签到续期 ### 1️⃣ 第一步:获取项目代码 点击本仓库页面右上角的绿色 **[Use this template]** 按钮 → 选择 "Create a new repository"。
### 2️⃣ 第二步:设置 GitHub Secrets 在你 Fork 后的仓库中,进入 `Settings` > `Secrets and variables` > `Actions` > `New repository secret` **📌 重要说明(请务必仔细阅读):** - **一个 Name 对应一个 Secret**:每添加一个配置项,点击一次"New repository secret"按钮,填写一对"Name"和"Secret" - **保存后看不到值是正常的**:出于安全考虑,保存后重新编辑时,只能看到 Name(名称),看不到 Secret(值)的内容 - **严禁自创名称**:Secret 的 Name(名称)必须**严格使用**下方列出的名称(如 `WEWORK_WEBHOOK_URL`、`FEISHU_WEBHOOK_URL` 等),不能自己随意修改或创造新名称,否则系统无法识别 - **可以同时配置多个平台**:系统会向所有配置的平台发送通知 **配置示例:**
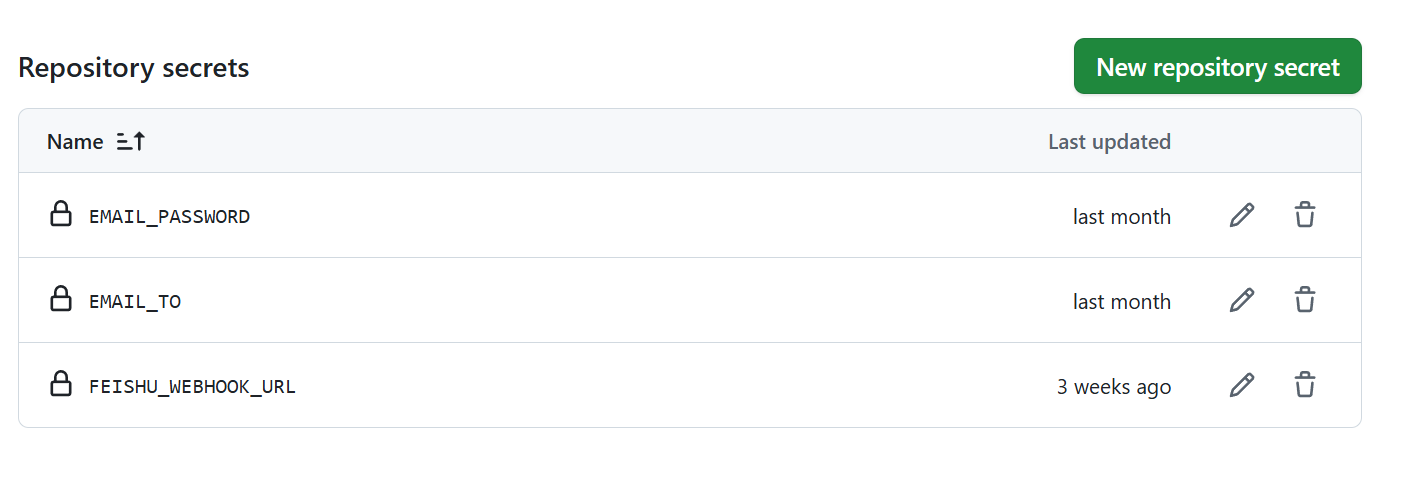 如上图所示,每一行是一个配置项:
- **Name(名称)**:必须使用下方展开内容中列出的固定名称(如 `WEWORK_WEBHOOK_URL`)
- **Secret(值)**:填写你从对应平台获取的实际内容(如 Webhook 地址、Token 等)
如上图所示,每一行是一个配置项:
- **Name(名称)**:必须使用下方展开内容中列出的固定名称(如 `WEWORK_WEBHOOK_URL`)
- **Secret(值)**:填写你从对应平台获取的实际内容(如 Webhook 地址、Token 等)
<>
**GitHub Secret 配置(⚠️ Name 名称必须严格一致):** - **Name(名称)**:`WEWORK_WEBHOOK_URL`(请复制粘贴此名称,不要手打,避免打错) - **Secret(值)**:你的企业微信机器人 Webhook 地址
**机器人设置步骤:** #### 手机端设置: 1. 打开企业微信 App → 进入目标内部群聊 2. 点击右上角"…"按钮 → 选择"消息推送" 3. 点击"添加" → 名称输入"TrendRadar" 4. 复制 Webhook 地址,点击保存,复制的内容配置到上方的 GitHub Secret 中 #### PC 端设置流程类似
👉 点击展开:个人微信推送(基于企业微信应用,推送到个人微信)
**GitHub Secret 配置(⚠️ Name 名称必须严格一致):** - **Name(名称)**:`WEWORK_WEBHOOK_URL`(请复制粘贴此名称,不要手打) - **Secret(值)**:你的企业微信应用 Webhook 地址 - **Name(名称)**:`WEWORK_MSG_TYPE`(请复制粘贴此名称,不要手打) - **Secret(值)**:`text`
**设置步骤:** 1. 完成上方的企业微信机器人 Webhook 设置 2. 添加 `WEWORK_MSG_TYPE` Secret,值设为 `text` 3. 按照下面图片操作,关联个人微信 4. 配置好后,手机上的企业微信 App 可以删除
 **说明**:
- 与企业微信机器人使用相同的 Webhook 地址
- 区别在于消息格式:`text` 为纯文本,`markdown` 为富文本(默认)
- 纯文本格式会自动去除所有 markdown 语法(粗体、链接等)
**说明**:
- 与企业微信机器人使用相同的 Webhook 地址
- 区别在于消息格式:`text` 为纯文本,`markdown` 为富文本(默认)
- 纯文本格式会自动去除所有 markdown 语法(粗体、链接等)
👉 点击展开:飞书机器人(消息显示相对友好)
若启用 **AI 分析**,飞书推送偶发(约 5% 概率)会有数分钟延迟(推测为平台对 AI 生成内容的合规性审核)。 **GitHub Secret 配置(⚠️ Name 名称必须严格一致):** - **Name(名称)**:`FEISHU_WEBHOOK_URL`(请复制粘贴此名称,不要手打) - **Secret(值)**:你的飞书机器人 Webhook 地址(该链接开头类似 https://www.feishu.cn/flow/api/trigger-webhook/********)
有两个方案,**方案一**配置简单,**方案二**配置复杂(但是稳定推送) 其中方案一,由 **ziventian**发现并提供建议,在这里感谢他,默认是个人推送,也可以配置群组推送操作[#97](https://github.com/sansan0/TrendRadar/issues/97) , **方案一:** 1. 电脑浏览器打开 https://botbuilder.feishu.cn/home/my-command 2. 点击"新建机器人指令" 3. 点击"选择触发器",往下滑动,点击"Webhook 触发" 4. 此时你会看到"Webhook 地址",把这个链接先复制到本地记事本暂存,继续接下来的操作 5. "参数"里面放上下面的内容,然后点击"完成" ``` { "message_type": "text", "content": { "text": "{{内容}}" } } ``` 6. 点击"选择操作" > "通过官方机器人发消息" 7. 消息标题填写"TrendRadar 热点监控" 8. 最关键的部分来了,点击 + 按钮,选择"Webhook 触发",然后按照下面的图片摆放 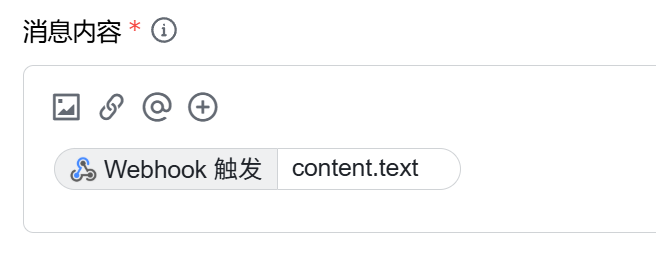 9. 配置完成后,将第 4 步复制的 Webhook 地址配置到 GitHub Secrets 中的 `FEISHU_WEBHOOK_URL`
**方案二:** 1. 电脑浏览器打开 https://botbuilder.feishu.cn/home/my-app 2. 点击"新建机器人应用" 3. 进入创建的应用后,点击"流程设计" > "创建流程" > "选择触发器" 4. 往下滑动,点击"Webhook 触发" 5. 此时你会看到"Webhook 地址",把这个链接先复制到本地记事本暂存,继续接下来的操作 6. "参数"里面放上下面的内容,然后点击"完成" ``` { "message_type": "text", "content": { "text": "{{内容}}" } } ``` 7. 点击"选择操作" > "发送飞书消息",勾选 "群消息",然后点击下面的输入框,点击"我管理的群组"(如果没有群组,你可以在飞书 app 上创建群组) 8. 消息标题填写"TrendRadar 热点监控" 9. 最关键的部分来了,点击 + 按钮,选择"Webhook 触发",然后按照下面的图片摆放  10. 配置完成后,将第 5 步复制的 Webhook 地址配置到 GitHub Secrets 中的 `FEISHU_WEBHOOK_URL`
👉 点击展开:钉钉机器人
**GitHub Secret 配置(⚠️ Name 名称必须严格一致):** - **Name(名称)**:`DINGTALK_WEBHOOK_URL`(请复制粘贴此名称,不要手打) - **Secret(值)**:你的钉钉机器人 Webhook 地址
**机器人设置步骤:** 1. **创建机器人(仅 PC 端支持)**: - 打开钉钉 PC 客户端,进入目标群聊 - 点击群设置图标(⚙️)→ 往下翻找到"机器人"点开 - 选择"添加机器人" → "自定义" 2. **配置机器人**: - 设置机器人名称 - **安全设置**: - **自定义关键词**:设置 "热点" 3. **完成设置**: - 勾选服务条款协议 → 点击"完成" - 复制获得的 Webhook URL - 将 URL 配置到 GitHub Secrets 中的 `DINGTALK_WEBHOOK_URL` **注意**:移动端只能接收消息,无法创建新机器人。
👉 点击展开:Telegram Bot
**GitHub Secret 配置(⚠️ Name 名称必须严格一致):** - **Name(名称)**:`TELEGRAM_BOT_TOKEN`(请复制粘贴此名称,不要手打) - **Secret(值)**:你的 Telegram Bot Token - **Name(名称)**:`TELEGRAM_CHAT_ID`(请复制粘贴此名称,不要手打) - **Secret(值)**:你的 Telegram Chat ID **说明**:Telegram 需要配置**两个** Secret,请分别点击两次"New repository secret"按钮添加
**机器人设置步骤:** 1. **创建机器人**: - 在 Telegram 中搜索 `@BotFather`(大小写注意,有蓝色徽章勾勾,有类似 37849827 monthly users,这个才是官方的,有一些仿官方的账号注意辨别) - 发送 `/newbot` 命令创建新机器人 - 设置机器人名称(必须以"bot"结尾,很容易遇到重复名字,所以你要绞尽脑汁想不同的名字) - 获取 Bot Token(格式如:`123456789:AAHfiqksKZ8WmR2zSjiQ7_v4TMAKdiHm9T0`) 2. **获取 Chat ID**: **方法一:通过官方 API 获取** - 先向你的机器人发送一条消息 - 访问:`https://api.telegram.org/bot<你的Bot Token>/getUpdates` - 在返回的 JSON 中找到 `"chat":{"id":数字}` 中的数字 **方法二:使用第三方工具** - 搜索 `@userinfobot` 并发送 `/start` - 获取你的用户 ID 作为 Chat ID 3. **配置到 GitHub**: - `TELEGRAM_BOT_TOKEN`:填入第 1 步获得的 Bot Token - `TELEGRAM_CHAT_ID`:填入第 2 步获得的 Chat ID
👉 点击展开:邮件推送(支持所有主流邮箱)
- 注意事项:为防止邮件群发功能被**滥用**,当前的群发是所有收件人都能看到彼此的邮箱地址。 - 如果你没有过配置下面这种邮箱发送的经历,不建议尝试
**GitHub Secret 配置(⚠️ Name 名称必须严格一致):** - **Name(名称)**:`EMAIL_FROM`(请复制粘贴此名称,不要手打) - **Secret(值)**:发件人邮箱地址 - **Name(名称)**:`EMAIL_PASSWORD`(请复制粘贴此名称,不要手打) - **Secret(值)**:邮箱密码或授权码 - **Name(名称)**:`EMAIL_TO`(请复制粘贴此名称,不要手打) - **Secret(值)**:收件人邮箱地址(多个收件人用英文逗号分隔,也可以和 EMAIL_FROM 一样,自己发送给自己) - **Name(名称)**:`EMAIL_SMTP_SERVER`(可选配置,请复制粘贴此名称) - **Secret(值)**:SMTP服务器地址(可留空,系统会自动识别) - **Name(名称)**:`EMAIL_SMTP_PORT`(可选配置,请复制粘贴此名称) - **Secret(值)**:SMTP端口(可留空,系统会自动识别) **说明**:邮件推送需要配置至少**3个必需** Secret(EMAIL_FROM、EMAIL_PASSWORD、EMAIL_TO),后两个为可选配置
**支持的邮箱服务商**(自动识别 SMTP 配置): | 邮箱服务商 | 域名 | SMTP 服务器 | 端口 | 加密方式 | |-----------|------|------------|------|---------| | **Gmail** | gmail.com | smtp.gmail.com | 587 | TLS | | **QQ邮箱** | qq.com | smtp.qq.com | 465 | SSL | | **Outlook** | outlook.com | smtp-mail.outlook.com | 587 | TLS | | **Hotmail** | hotmail.com | smtp-mail.outlook.com | 587 | TLS | | **Live** | live.com | smtp-mail.outlook.com | 587 | TLS | | **163邮箱** | 163.com | smtp.163.com | 465 | SSL | | **126邮箱** | 126.com | smtp.126.com | 465 | SSL | | **新浪邮箱** | sina.com | smtp.sina.com | 465 | SSL | | **搜狐邮箱** | sohu.com | smtp.sohu.com | 465 | SSL | | **天翼邮箱** | 189.cn | smtp.189.cn | 465 | SSL | | **阿里云邮箱** | aliyun.com | smtp.aliyun.com | 465 | TLS | | **Yandex邮箱** | yandex.com | smtp.yandex.com | 465 | TLS | | **iCloud邮箱** | icloud.com | smtp.mail.me.com | 587 | SSL | **常见邮箱设置:** #### QQ邮箱: 1. 登录 QQ邮箱网页版 → 设置 → 账户 2. 开启 POP3/SMTP 服务 3. 生成授权码(16位字母) 4. `EMAIL_PASSWORD` 填写授权码,而非 QQ 密码 #### Gmail: 1. 开启两步验证 2. 生成应用专用密码 3. `EMAIL_PASSWORD` 填写应用专用密码 #### 163/126邮箱: 1. 登录网页版 → 设置 → POP3/SMTP/IMAP 2. 开启 SMTP 服务 3. 设置客户端授权码 4. `EMAIL_PASSWORD` 填写授权码
**高级配置**: 如果自动识别失败,可手动配置 SMTP: - `EMAIL_SMTP_SERVER`:如 smtp.gmail.com - `EMAIL_SMTP_PORT`:如 587(TLS)或 465(SSL)
**如果有多个收件人(注意是英文逗号分隔)**: - EMAIL_TO="user1@example.com,user2@example.com,user3@example.com"
👉 点击展开:ntfy 推送(开源免费,支持自托管)
**两种使用方式:** ### 方式一:免费使用(推荐新手) 🆓 **特点**: - ✅ 无需注册账号,立即使用 - ✅ 每天 250 条消息(足够 90% 用户) - ✅ Topic 名称即"密码"(需选择不易猜测的名称) - ⚠️ 消息未加密,不适合敏感信息, 但适合我们这个项目的不敏感信息 **快速开始:** 1. **下载 ntfy 应用**: - Android:[Google Play](https://play.google.com/store/apps/details?id=io.heckel.ntfy) / [F-Droid](https://f-droid.org/en/packages/io.heckel.ntfy/) - iOS:[App Store](https://apps.apple.com/us/app/ntfy/id1625396347) - 桌面:访问 [ntfy.sh](https://ntfy.sh) 2 **订阅主题**(选择一个难猜的名称): 建议格式:trendradar-{你的名字缩写}-{随机数字} 不能使用中文 ✅ 好例子:trendradar-zs-8492 ❌ 坏例子:news、alerts(太容易被猜到) 3. **配置 GitHub Secret(⚠️ Name 名称必须严格一致)**: - **Name(名称)**:`NTFY_TOPIC`(请复制粘贴此名称,不要手打) - **Secret(值)**:填写你刚才订阅的主题名称 - **Name(名称)**:`NTFY_SERVER_URL`(可选配置,请复制粘贴此名称) - **Secret(值)**:留空(默认使用 ntfy.sh) - **Name(名称)**:`NTFY_TOKEN`(可选配置,请复制粘贴此名称) - **Secret(值)**:留空 **说明**:ntfy 至少需要配置 1 个必需 Secret (NTFY_TOPIC),后两个为可选配置 4. **测试**: curl -d "测试消息" ntfy.sh/你的主题名称 ### 方式二:自托管(完全隐私控制) 🔒 **适合人群**:有服务器、追求完全隐私、技术能力强 **优势**: - ✅ 完全开源(Apache 2.0 + GPLv2) - ✅ 数据完全自主控制 - ✅ 无任何限制 - ✅ 零费用 **Docker 一键部署**: ``` docker run -d \ --name ntfy \ -p 80:80 \ -v /var/cache/ntfy:/var/cache/ntfy \ binwiederhier/ntfy \ serve --cache-file /var/cache/ntfy/cache.db ``` **配置 TrendRadar**: ``` NTFY_SERVER_URL: https://ntfy.yourdomain.com NTFY_TOPIC: trendradar-alerts # 自托管可用简单名称 NTFY_TOKEN: tk_your_token # 可选:启用访问控制 ``` **在应用中订阅**: - 点击"Use another server" - 输入你的服务器地址 - 输入主题名称 - (可选)输入登录凭据 **常见问题:**
Q1: 免费版够用吗?
每天 250 条消息对大多数用户足够。按 30 分钟抓取一次计算,每天约 48 次推送,完全够用。Q2: Topic 名称真的安全吗?
如果你选择随机的、足够长的名称(如 `trendradar-zs-8492-news`),暴力破解几乎不可能: - ntfy 有严格的速率限制(1 秒 1 次请求) - 64 个字符选择(A-Z, a-z, 0-9, _, -) - 10 位随机字符串有 64^10 种可能性(需要数年才能破解)👉 点击展开:Bark 推送(iOS 专属,简洁高效)
**GitHub Secret 配置(⚠️ Name 名称必须严格一致):** - **Name(名称)**:`BARK_URL`(请复制粘贴此名称,不要手打) - **Secret(值)**:你的 Bark 推送 URL
**Bark 简介:** Bark 是一款 iOS 平台的免费开源推送工具,特点是简单、快速、无广告。 **使用方式:** ### 方式一:使用官方服务器(推荐新手) 🆓 1. **下载 Bark App**: - iOS:[App Store](https://apps.apple.com/cn/app/bark-给你的手机发推送/id1403753865) 2. **获取推送 URL**: - 打开 Bark App - 复制首页显示的推送 URL(格式如:`https://api.day.app/your_device_key`) - 将 URL 配置到 GitHub Secrets 中的 `BARK_URL` ### 方式二:自建服务器(完全隐私控制) 🔒 **适合人群**:有服务器、追求完全隐私、技术能力强 **Docker 一键部署**: ``` docker run -d \ --name bark-server \ -p 8080:8080 \ finab/bark-server ``` **配置 TrendRadar**: ``` BARK_URL: http://your-server-ip:8080/your_device_key ``` **注意事项:** - ✅ Bark 使用 APNs 推送,单条消息最大 4KB - ✅ 支持自动分批推送,无需担心消息过长 - ✅ 推送格式为纯文本(自动去除 Markdown 语法) - ⚠️ 仅支持 iOS 平台 **相关链接:** - [Bark 官方网站](https://bark.day.app/) - [Bark GitHub 仓库](https://github.com/Finb/Bark) - [Bark Server 自建教程](https://github.com/Finb/bark-server)
👉 点击展开:Slack 推送
**GitHub Secret 配置(⚠️ Name 名称必须严格一致):** - **Name(名称)**:`SLACK_WEBHOOK_URL`(请复制粘贴此名称,不要手打) - **Secret(值)**:你的 Slack Incoming Webhook URL
**Slack 简介:** Slack 是团队协作工具,Incoming Webhooks 可以将消息推送到 Slack 频道。 **设置步骤:** ### 步骤 1:创建 Slack App 1. **访问 Slack API 页面**: - 打开 https://api.slack.com/apps?new_app=1 - 如果未登录,先登录你的 Slack 工作空间 2. **选择创建方式**: - 点击 **"From scratch"**(从头开始创建) 3. **填写 App 信息**: - **App Name**:填写应用名称(如 `TrendRadar` 或 `热点新闻监控`) - **Workspace**:从下拉列表选择你的工作空间 - 点击 **"Create App"** 按钮 ### 步骤 2:启用 Incoming Webhooks 1. **导航到 Incoming Webhooks**: - 在左侧菜单中找到并点击 **"Incoming Webhooks"** 2. **启用功能**: - 找到 **"Activate Incoming Webhooks"** 开关 - 将开关从 `OFF` 切换到 `ON` - 页面会自动刷新显示新的配置选项 ### 步骤 3:生成 Webhook URL 1. **添加新的 Webhook**: - 滚动到页面底部 - 点击 **"Add New Webhook to Workspace"** 按钮 2. **选择目标频道**: - 系统会弹出授权页面 - 从下拉列表中选择要接收消息的频道(如 `#热点新闻`) - ⚠️ 如果要选择私有频道,必须先加入该频道 3. **授权应用**: - 点击 **"Allow"** 按钮完成授权 - 系统会自动跳转回配置页面 ### 步 - **建议**:配置远程云存储以获得完整体验。 - **Docker / 本地用户**: - **现状**:数据默认保存在本地硬盘。 - **建议**:云存储为可选项,可作为异地备份。
👉 点击展开:远程云存储配置教程(以 Cloudflare R2 为例)
**⚠️ 前置条件(重要):** 根据 Cloudflare 平台规则,开通 R2 需绑定支付方式。 * **目的**:仅作身份验证,**不产生扣费**。 * **支付**:支持双币信用卡或国区 PayPal。 * **用量**:R2 的免费额度(10GB存储/月)足以覆盖本项目日常运行,无需担心付费。 **GitHub Secret 配置(需添加 4 项):** | Name(名称) | Secret(值)说明 | |-------------|-----------------| | `S3_BUCKET_NAME` | 存储桶名称(如 `trendradar-data`) | | `S3_ACCESS_KEY_ID` | 访问密钥 ID(Access Key ID) | | `S3_SECRET_ACCESS_KEY` | 访问密钥 | | `S3_ENDPOINT_URL` | S3 API 端点(如 R2:`https://
**详细操作步骤(获取凭据):** 1. **进入 R2 概览**: - 登录 [Cloudflare Dashboard](https://dash.cloudflare.com/)。 - 在左侧侧边栏找到并点击 `R2对象存储`。 2. **创建存储桶**: - 点击`概述` - 点击右上角的 `创建存储桶` (Create bucket)。 - 输入名称(例如 `trendradar-data`),点击 `创建存储桶`。 3. **创建 API 令牌**: - 回到 **概述**页面。 - 点击**右下角** `Account Details `找到并点击 `Manage` (Manage R2 API Tokens)。 - 同时你会看到 `S3 API`:`https://
### 6️⃣ 第六步:开启 AI 分析推送 这是 v5.0.0 的核心功能,让 AI 帮你总结和分析新闻,建议尝试。 **配置方法:** 在 GitHub Secrets (或 `.env` / `config.yaml`) 中添加: - `AI_API_KEY`: 你的 API Key(支持 DeepSeek、OpenAI 等) - `AI_PROVIDER`: 服务商名称(如 `deepseek`, `openai`) 就这样,无需复杂部署,下次推送时你就会看到智能分析报告了。
### 7️⃣ 第七步:🎉 部署成功! 恭喜!现在你可以开始享受 TrendRadar 带来的高效信息流了。 💬 **加入社区**:欢迎关注公众号「**[硅基茶水间](#-支持项目)**」,分享你的使用心得和高级玩法。
### 8️⃣ 第八步:进阶:选择你的 AI 助手 TrendRadar 提供了两种 AI 使用方式,满足不同需求: | 特性 | ✨ AI 分析推送 | 🧠 AI 智能分析 | | :--- | :--- | :--- | | **模式** | **被动接收** (每日日报) | **主动对话** (深度调研) | | **场景** | "今天有什么大事?" | "分析一下过去一周 AI 行业的变化" | | **部署** | 极简 (填 Key 即可) | 进阶 (需本地运行/Docker) | | **客户端** | 手机 | 电脑 | 👉 **结论**:先用 **AI 分析推送** 满足日常需求;如果你是数据分析师或需要深度挖掘,再尝试 **[AI 智能分析](#-ai-智能分析)**。
## ⚙️ 配置详解 ### 1. 我要看哪些平台?
👉 点击展开:选择资讯来源
**配置位置:** `config/config.yaml` 的 `platforms` 部分 本项目的资讯数据来源于 [newsnow](https://github.com/ourongxing/newsnow) ,你可以点击[网站](https://newsnow.busiyi.world/),点击[更多],查看是否有你想要的平台。 具体添加可访问 [项目源代码](https://github.com/ourongxing/newsnow/tree/main/server/sources),根据里面的文件名,在 `config/config.yaml` 文件中修改 `platforms` 配置: ``` platforms: enabled: true # 是否启用热榜平台抓取 sources: - id: "toutiao" name: "今日头条" - id: "baidu" name: "百度热搜" - id: "wallstreetcn-hot" name: "华尔街见闻" # 添加更多平台... ```
👉 点击展开:基础语法教程
**配置位置:** `config/frequency_words.txt` ##### 1. **普通关键词** - 基础匹配 ``` 华为 OPPO 苹果 ``` **作用:** 新闻标题包含其中**任意一个词**就会被捕获 ##### 2. **必须词** `+词汇` - 限定范围 ``` 华为 OPPO +手机 ``` **作用:** 必须同时包含普通词**和**必须词才会被捕获 ##### 3. **过滤词** `!词汇` - 排除干扰 ``` 苹果 华为 !水果 !价格 ``` **作用:** 包含过滤词的新闻会被**直接排除**,即使包含关键词 ##### 4. **数量限制** `@数字` - 控制显示数量(v3.2.0 新增) ``` 特斯拉 马斯克 @5 ``` **作用:** 限制该关键词组最多显示的新闻条数 **配置优先级:** `@数字` > 全局配置 > 不限制 ##### 5. **全局过滤** `[GLOBAL_FILTER]` - 全局排除指定内容(v3.5.0 新增) ``` [GLOBAL_FILTER] 广告 推广 营销 震惊 标题党 [WORD_GROUPS] 科技 AI 华为 鸿蒙 !车 ``` **作用:** 在任何情况下过滤包含指定词的新闻,**优先级最高** **使用场景:** - 过滤低质内容:震惊、标题党、爆料等 - 过滤营销内容:广告、推广、赞助等 - 过滤特定主题:娱乐、八卦(根据需求) **过滤优先级:** 全局过滤 > 词组内过滤(`!`) > 词组匹配 **区域说明:** - `[GLOBAL_FILTER]`:全局过滤区,包含的词在任何情况下都会被过滤 - `[WORD_GROUPS]`:词组区,保持现有语法(`!`、`+`、`@`) - 如果不使用区域标记,默认全部作为词组处理(向后兼容) **匹配示例:** ``` [GLOBAL_FILTER] 广告 [WORD_GROUPS] 科技 AI ``` - ❌ "广告:最新科技产品发布" ← 包含全局过滤词"广告",直接拒绝 - ✅ "科技公司发布AI新产品" ← 不包含全局过滤词,匹配"科技"词组 - ✅ "AI技术突破引发关注" ← 不包含全局过滤词,匹配"科技"词组中的"AI" **注意事项:** - 全局过滤词应谨慎使用,避免过度过滤导致遗漏有价值内容 - 建议全局过滤词控制在 5-15 个以内 - 对于特定词组的过滤,优先使用词组内过滤词(`!` 前缀) ##### 6. **正则表达式** `/pattern/` - 精确匹配模式(v4.7.0 新增) 普通关键词使用子字符串匹配,这在中文环境下很方便,但在英文环境可能会产生误匹配。例如 `ai` 会匹配到 `training` 中的 `ai`。 使用正则表达式语法 `/pattern/` 可以实现精确匹配: ``` /(? 备注` - 自定义显示文本(v4.7.0 新增) 正则表达式在推送消息和 HTML 页面显示时可能不太友好。使用 `=> 备注` 语法可以设置显示名称: ``` /(? AI 相关 人工智能 ``` **作用:** 推送消息和 HTML 页面显示 "AI 相关" 而不是复杂的正则表达式 **语法格式:** ``` # 正则 + 显示名称 /pattern/ => 显示名称 /pattern/i => 显示名称 # 支持 flags 写法(flags 被忽略) /pattern/=>显示名称 # => 两边空格可选 # 普通词 + 显示名称 deepseek => DeepSeek 动态 ``` **匹配示例:** ``` # 配置 /(? AI 相关 人工智能 ``` | 原始配置 | 推送/HTML 显示 | |---------|---------------| | `/(? AI 相关` + `人工智能` | **`AI 相关`** | **注意事项:** - 显示名称只需写在词组的第一个词上 - 如果词组中多个词都有显示名称,使用第一个 - 不设置显示名称时,自动使用词组内所有词拼接 #### 🔗 词组功能 - 空行分隔的重要作用 **核心规则:** 用**空行**分隔不同的词组,每个词组独立统计 ##### 示例配置: ``` iPhone 华为 OPPO +发布 A股 上证 深证 +涨跌 !预测 世界杯 欧洲杯 亚洲杯 +比赛 ``` ##### 词组解释及匹配效果: **第1组 - 手机新品类:** - 关键词:iPhone、华为、OPPO - 必须词:发布 - 效果:必须包含手机品牌名,同时包含"发布" **匹配示例:** - "iPhone 15正式发布售价公布" ← 有"iPhone"+"发布" - ✅ "华为Mate60系列发布会直播" ← 有"华为"+"发布" - ✅ "OPPO Find X7发布时间确定" ← 有"OPPO"+"发布" - ❌ "iPhone销量创新高" ← 有"iPhone"但缺少"发布" **第2组 - 股市行情类:** - 关键词:A股、上证、深证 - 必须词:涨跌 - 过滤词:预测 - 效果:关注股市涨跌实况,排除预测类内容 **匹配示例:** - ✅ "A股今日大幅涨跌分析" ← 有"A股"+"涨跌" - ✅ "上证指数涨跌幅创新高" ← 有"上证"+"涨跌" - ❌ "专家预测A股涨跌趋势" ← 有"A股"+"涨跌"但包含"预测" **第3组 - 足球赛事类:** - 关键词:世界杯、欧洲杯、亚洲杯 - 必须词:比赛 - 效果:只关注比赛相关新闻 #### 📝 配置技巧 ##### 1. **从宽到严** ``` # 第一步:先用宽泛关键词测试 人工智能 AI ChatGPT # 第二步:发现误匹配后,加入必须词限定 人工智能 AI ChatGPT +技术 # 第三步:发现干扰内容后,加入过滤词 人工智能 AI ChatGPT +技术 !广告 !培训 ``` ##### 2. **避免过度复杂** ❌ **不推荐:** 一个词组包含太多词汇 ``` 华为 OPPO 苹果 三星 vivo 一加 魅族 +手机 +发布 +销量 !假货 !维修 !二手 ``` ✅ **推荐:** 拆分成多个精确的词组 ``` 华为 OPPO +新品 苹果 三星 +发布 手机 销量 +市场 ```
👉 点击展开:高级配置教程
##### 关键词排序优先级 **配置位置:** `config/config.yaml` ``` report: sort_by_position_first: false # 排序优先级配置 ``` | 配置值 | 排序规则 | 适用场景 | |--------|---------|---------| | `false`(默认) | 热点条数 ↓ → 配置位置 ↑ | 关注热度趋势 | | `true` | 配置位置 ↑ → 热点条数 ↓ | 关注个人优先级 | **示例:** 配置顺序 A、B、C,热点数 A(3条)、B(10条)、C(5条) - `false`:B(10条) → C(5条) → A(3条) - `true`:A(3条) → B(10条) → C(5条) ##### 全局显示数量限制 ``` report: max_news_per_keyword: 10 # 每个关键词最多显示10条(0=不限制) ``` **Docker 环境变量:** ``` SORT_BY_POSITION_FIRST=true MAX_NEWS_PER_KEYWORD=10 ``` **综合示例:** ``` # config.yaml report: sort_by_position_first: true # 按配置顺序优先 max_news_per_keyword: 10 # 全局默认每个关键词最多10条 ``` ``` # frequency_words.txt 特斯拉 马斯克 @20 # 重点关注,显示20条(覆盖全局配置) 华为 # 使用全局配置,显示10条 比亚迪 @5 # 限制5条 ``` **最终效果:** 按配置顺序显示 特斯拉(20条) → 华为(10条) → 比亚迪(5条)
👉 点击展开:三种推送模式详细对比
**配置位置:** `config/config.yaml` 的 `report.mode` ``` report: mode: "daily" # 可选: "daily" | "incremental" | "current" ``` #### 详细对比表格 | 模式 | 适用人群 | 推送时机 | 显示内容 | 典型使用场景 | |------|----------|----------|----------|------------| | **当日汇总**
`daily` | 📋 企业管理者/普通用户 | 按时推送(默认每小时推送一次) | 当日所有匹配新闻
+ 新增新闻区域 | **案例**:每天下午6点查看今天所有重要新闻
**特点**:看全天完整趋势,不漏掉任何热点
**提醒**:会包含之前推送过的新闻 | | **当前榜单**
`current` | 📰 自媒体人/内容创作者 | 按时推送(默认每小时推送一次) | 当前榜单匹配新闻
+ 新增新闻区域 | **案例**:每小时追踪"哪些话题现在最火"
**特点**:实时了解当前热度排名变化
**提醒**:持续在榜的新闻每次都会出现 | | **增量监控**
`incremental` | 📈 投资者/交易员 | 有新增才推送 | 新出现的匹配频率词新闻 | **案例**:监控"特斯拉",只在有新消息时通知
**特点**:零重复,只看首次出现的新闻
**适合**:高频监控、避免信息打扰 | #### 实际推送效果举例 假设你监控"苹果"关键词,每小时执行一次: | 时间 | daily 模式推送 | current 模式推送 | incremental 模式推送 | |-----|--------------|----------------|-------------------| | 10:00 | 新闻A、新闻B | 新闻A、新闻B | 新闻A、新闻B | | 11:00 | 新闻A、新闻B、新闻C | 新闻B、新闻C、新闻D | **仅**新闻C | | 12:00 | 新闻A、新闻B、新闻C | 新闻C、新闻D、新闻E | **仅**新闻D、新闻E | **说明**: - `daily`:累积展示当天所有新闻(A、B、C 都保留) - `current`:展示当前榜单的新闻(排名变化,新闻D上榜,新闻A掉榜) - `incremental`:**只推送新出现的新闻**(避免重复干扰) #### 常见问题 #### ⚠️ 增量模式重要提示
👉 点击展开:自定义热点权重
**配置位置:** `config/config.yaml` 的 `advanced.weight` 部分 ``` advanced: weight: rank: 0.6 # 排名权重 frequency: 0.3 # 频次权重 hotness: 0.1 # 热度权重 ``` 当前默认的配置是平衡性配置 #### 两个核心场景 **追实时热点型**: ``` advanced: weight: rank: 0.8 # 主要看排名 frequency: 0.1 # 不太在乎持续性 hotness: 0.1 ``` **适用人群**:自媒体博主、营销人员、想快速了解当下最火话题的用户 **追深度话题型**: ``` advanced: weight: rank: 0.4 # 适度看排名 frequency: 0.5 # 重视当天内的持续热度 hotness: 0.1 ``` **适用人群**:投资者、研究人员、新闻工作者、需要深度分析趋势的用户 #### 调整的方法 1. **三个数字加起来必须等于 1.0** 2. **哪个重要就调大哪个**:在乎排名就调大 `rank`,在乎持续性就调大 `frequency` 3. **建议每次只调 0.1-0.2**,观察效果 核心思路:追求速度和时效性的用户提高排名权重,追求深度和稳定性的用户提高频次权重。
👉 点击展开:消息样式预览
#### 推送示例 📊 热点词汇统计 🔥 [1/3] AI ChatGPT : 2 条 1. [百度热搜] 🆕 ChatGPT-5正式发布 [**1**] - 09时15分 (1次) 2. [今日头条] AI芯片概念股暴涨 [**3**] - [08时30分 ~ 10时45分] (3次) ━━━━━━━━━━━━━━━━━━━ 📈 [2/3] 比亚迪 特斯拉 : 2 条 1. [微博] 🆕 比亚迪月销量破纪录 [**2**] - 10时20分 (1次) 2. [抖音] 特斯拉降价促销 [**4**] - [07时45分 ~ 09时15分] (2次) ━━━━━━━━━━━━━━━━━━━ 📌 [3/3] A股 股市 : 1 条 1. [华尔街见闻] A股午盘点评分析 [**5**] - [11时30分 ~ 12时00分] (2次) 🆕 本次新增热点新闻 (共 2 条) **百度热搜** (1 条): 1. ChatGPT-5正式发布 [**1**] **微博** (1 条): 1. 比亚迪月销量破纪录 [**2**] 更新时间:2025-01-15 12:30:15 #### 消息格式说明 | 格式元素 | 示例 | 含义 | 说明 | | ------------- | --------------------------- | ------------ | --------------------------------------- | | 🔥📈📌 | 🔥 [1/3] AI ChatGPT | 热度等级 | 🔥高热度(≥10条) 📈中热度(5-9条) 📌普通热度(<5条) | | [序号/总数] | [1/3] | 排序位置 | 当前词组在所有匹配词组中的排名 | | 频率词组 | AI ChatGPT | 关键词组 | 配置文件中的词组,标题必须包含其中词汇 | | : N 条 | : 2 条 | 匹配数量 | 该词组匹配的新闻总数 | | [平台名] | [百度热搜] | 来源平台 | 新闻所属的平台名称 | | 🆕 | 🆕 ChatGPT-5正式发布 | 新增标记 | 本轮抓取中首次出现的热点 | | [**数字**] | [**1**] | 高排名 | 排名≤阈值的热搜,红色加粗显示 | | [数字] | [7] | 普通排名 | 排名>阈值的热搜,普通显示 | | - 时间 | - 09时15分 | 首次时间 | 该新闻首次被发现的时间 | | [时间~时间] | [08时30分 ~ 10时45分] | 持续时间 | 从首次出现到最后出现的时间范围 | | (N次) | (3次) | 出现频率 | 在监控期间出现的总次数 | | **新增区域** | 🆕 **本次新增热点新闻** | 新话题汇总 | 单独展示本轮新出现的热点话题 |
👉 点击展开:Docker 部署完整指南
#### 方式一:使用 docker compose(推荐) 1. **创建项目目录和配置**: # 克隆项目到本地 git clone https://github.com/sansan0/TrendRadar.git cd TrendRadar ``` 当前目录/ ├── config/ │ ├── config.yaml # 核心功能配置(必需) │ ├── frequency_words.txt # 关键词配置(必需) │ ├── timeline.yaml # 时间线配置 │ ├── ai_analysis_prompt.txt # AI 分析提示词(可选) │ ├── ai_translation_prompt.txt # AI 翻译提示词(可选) │ ├── ai_interests.txt # AI 兴趣过滤配置(可选) │ ├── ai_filter/ # AI 过滤相关提示词 │ │ ├── prompt.txt │ │ ├── extract_prompt.txt │ │ └── update_tags_prompt.txt │ └── custom/ # 用户自定义配置(可选) │ ├── ai/ # 自定义 AI 提示词 │ └── keyword/ # 自定义关键词文件 └── docker/ ├── .env # 敏感信息 + Docker 特有配置 └── docker-compose.yml # Docker Compose 编排文件 ``` 2. **配置文件说明**: **配置分工原则(v4.6.0 优化)**: | 文件 | 用途 | 修改频率 | 说明 | |------|------|---------|------| | `config/config.yaml` | **核心功能配置** | 低 | 报告模式、推送设置、存储格式、推送窗口、AI 分析开关、平台启用等全局行为控制 | | `config/frequency_words.txt` | **关键词配置** | 高 | 设置你关心的热点词汇,支持分组、正则、别名等高级语法 | | `config/timeline.yaml` | **时间线配置** | 低 | 控制新闻时间线的展示和过滤规则 | | `config/ai_analysis_prompt.txt` | **AI 分析提示词** | 中 | 自定义 AI 分析的角色定义和输出格式(v5.0.0+) | | `config/ai_translation_prompt.txt` | **AI 翻译提示词** | 低 | 自定义 AI 翻译的提示词模板 | | `config/ai_interests.txt` | **AI 兴趣过滤** | 中 | 定义 AI 基于兴趣自动过滤新闻的规则 | | `config/ai_filter/` | **AI 过滤提示词** | 低 | AI 过滤模块的内部提示词(一般无需修改) | | `config/custom/` | **用户自定义扩展** | 按需 | `custom/ai/` 放自定义 AI 提示词,`custom/keyword/` 放自定义关键词文件 | | `docker/.env` | **敏感信息 + Docker 特有配置** | 低 | webhook URLs、API Key、S3 密钥、定时任务等,**不会被 git 追踪** | **⚙️ 环境变量覆盖机制(v3.0.5+)** `.env` 文件中的环境变量会覆盖 `config.yaml` 中的对应配置: | 环境变量 | 对应配置 | 示例值 | 说明 | |---------|---------|-------|------| | `ENABLE_WEBSERVER` | - | `true` / `false` | 是否自动启动 Web 服务器 | | `WEBSERVER_PORT` | - | `8080` | Web 服务器端口 | | `WEBSERVER_WATCHDOG` | - | `true` / `false` | 是否开启“网页服务自动恢复”(服务异常时自动重开) | | `WEBSERVER_WATCHDOG_INTERVAL` | - | `60` | 自动恢复检查间隔(秒) | | `FEISHU_WEBHOOK_URL` | `notification.channels.feishu.webhook_url` | `https://...` | 飞书 Webhook(多账号用 `;` 分隔) | | `AI_ANALYSIS_ENABLED` | `ai_analysis.enabled` |true` / `false` | 是否启用 AI 分析(v5.0.0 新增) | | `AI_API_KEY` | `ai.api_key` | `sk-xxx...` | AI API Key(ai_analysis 和 ai_translation 共享) | | `AI_PROVIDER` | `ai.provider` | `deepseek` / `openai` / `gemini` | AI 提供商 | | `S3_*` | `storage.remote.*` | - | 远程存储配置(5 个参数) | **配置优先级**:环境变量 > config.yaml **使用方法**: - 修改 `.env` 文件,填写需要的配置 - 或在 NAS/群晖 Docker 管理界面的"环境变量"中直接添加 - 重启容器后生效:`docker compose up -d` 3. **启动服务**: **选项 A:启动所有服务(推送 + AI 分析)** # 拉取最新镜像 docker compose pull # 启动所有服务(trendradar + trendradar-mcp) docker compose up -d **选项 B:仅启动新闻推送服务** # 只启动 trendradar(定时抓取和推送) docker compose pull trendradar docker compose up -d trendradar **选项 C:仅启动 MCP AI 分析服务** # 只启动 trendradar-mcp(提供 AI 分析接口) docker compose pull trendradar-mcp docker compose up -d trendradar-mcp 4. **查看运行状态**: # 查看新闻推送服务日志 docker logs -f trendradar # 查看 MCP AI 分析服务日志 docker logs -f trendradar-mcp # 查看所有容器状态 docker ps | grep trendradar # 停止特定服务 docker compose stop trendradar # 停止推送服务 docker compose stop trendradar-mcp # 停止 MCP 服务 #### 方式二:本地构建(开发者选项) 如果需要自定义修改代码或构建自己的镜像: ``` # 克隆项目 git clone https://github.com/sansan0/TrendRadar.git cd TrendRadar # 修改配置文件 vim config/config.yaml vim config/frequency_words.txt # 使用构建版本的 docker compose cd docker cp docker-compose-build.yml docker-compose.yml ``` **构建并启动服务**: ``` # 选项 A:构建并启动所有服务 docker compose build docker compose up -d # 选项 B:仅构建并启动新闻推送服务 docker compose build trendradar docker compose up -d trendradar # 选项 C:仅构建并启动 MCP AI 分析服务 docker compose build trendradar-mcp docker compose up -d trendradar-mcp ``` #### 镜像更新 ``` # 方式一:手动更新(爬虫 + MCP 镜像) docker pull wantcat/trendradar:latest docker pull wantcat/trendradar-mcp:latest docker compose down docker compose up -d # 方式二:使用 docker compose 更新 docker compose pull docker compose up -d ``` **可用镜像**: | 镜像名称 | 用途 | 说明 | |---------|------|------| | `wantcat/trendradar` | 新闻推送服务 | 定时抓取新闻、推送通知 | | `wantcat/trendradar-mcp` | MCP 服务 | AI 分析功能(可选) | #### 服务管理命令 ``` # 查看运行状态 docker exec -it trendradar python manage.py status # 手动执行一次爬虫 docker exec -it trendradar python manage.py run # 查看实时日志 docker exec -it trendradar python manage.py logs # 显示当前配置 docker exec -it trendradar python manage.py config # 显示输出文件 docker exec -it trendradar python manage.py files # Web 服务器管理(用于浏览器访问生成的报告) docker exec -it trendradar python manage.py start_webserver # 启动 Web 服务器 docker exec -it trendradar python manage.py stop_webserver # 停止 Web 服务器 docker exec -it trendradar python manage.py webserver_status # 查看 Web 服务器状态 # 查看帮助信息 docker exec -it trendradar python manage.py help # 重启容器 docker restart trendradar # 停止容器 docker stop trendradar # 删除容器(保留数据) docker rm trendradar ``` #### 数据持久化 生成的报告和数据默认保存在 `./output` 目录下,即使容器重启或删除,数据也会保留。 **📊 网页版报告访问路径**: TrendRadar 生成的当日汇总 HTML 报告会同时保存到两个位置: | 文件位置 | 访问方式 | 适用场景 | |---------|---------|---------| | `output/index.html` | 宿主机直接访问 | **Docker 部署**(通过 Volume 挂载,宿主机可见) | | `index.html` | 根目录访问 | **GitHub Pages**(仓库根目录,Pages 自动识别) | | `output/html/YYYY-MM-DD/当日汇总.html` | 历史报告访问 | 所有环境(按日期归档) | **本地访问示例**: ``` # 方式 1:通过 Web 服务器访问(推荐,Docker 环境) # 1. 启动 Web 服务器 docker exec -it trendradar python manage.py start_webserver # 2. 在浏览器访问 http://localhost:8080 # 访问最新报告(默认 index.html) http://localhost:8080/html/2025-xx-xx/ # 访问指定日期的报告 # 方式 2:直接打开文件(本地环境) open ./output/index.html # macOS start ./output/index.html # Windows xdg-open ./output/index.html # Linux # 方式 3:访问历史归档 open ./output/html/2025-xx-xx/当日汇总.html ``` **为什么有两个 index.html?** - `output/index.html`:Docker Volume 挂载到宿主机,本地可直接打开 - `index.html`:GitHub Actions 推送到仓库,GitHub Pages 自动部署 #### 故障排查 ``` # 检查容器状态 docker inspect trendradar # 查看容器日志 docker logs --tail 100 trendradar # 进入容器调试 docker exec -it trendradar /bin/bash # 验证配置文件 docker exec -it trendradar ls -la /app/config/ ``` #### MCP 服务部署(AI 分析功能) 如果需要使用 AI 分析功能,可以部署独立的 MCP 服务容器。 **架构说明**: ``` flowchart TB subgraph trendradar["trendradar"] A1[定时抓取新闻] A2[推送通知] end subgraph trendradar-mcp["trendradar-mcp"] B1[127.0.0.1:3333] B2[AI 分析接口] end subgraph shared["共享卷"] C1["config/ (ro)"] C2["output/ (ro)"] end trendradar --> shared trendradar-mcp --> shared ``` **快速启动**: 如果已按照 [方式一:使用 docker compose](#方式一使用-docker-compose推荐) 完成部署,只需启动 MCP 服务: ``` cd TrendRadar/docker docker compose up -d trendradar-mcp # 查看运行状态 docker ps | grep trendradar-mcp ``` **单独启动 MCP 服务**(不使用 docker compose): ``` # Linux/Mac docker run -d --name trendradar-mcp \ -p 127.0.0.1:3333:3333 \ -v $(pwd)/config:/app/config:ro \ -v $(pwd)/output:/app/output:ro \ -e TZ=Asia/Shanghai \ wantcat/trendradar-mcp:latest # Windows PowerShell docker run -d --name trendradar-mcp ` -p 127.0.0.1:3333:3333 ` -v ${PWD}/config:/app/config:ro ` -v ${PWD}/output:/app/output:ro ` -e TZ=Asia/Shanghai ` wantcat/trendradar-mcp:latest ``` **验证服务**: ``` # 检查 MCP 服务健康状态 curl http://127.0.0.1:3333/mcp # 查看 MCP 服务日志 docker logs -f trendradar-mcp ``` **在 AI 客户端中配置**: MCP 服务启动后,根据不同客户端进行配置: **Cherry Studio**(推荐,GUI 配置): - 设置 → MCP 服务器 → 添加 - 类型:`streamableHttp` - URL:`http://127.0.0.1:3333/mcp` **Claude Desktop / Cline**(JSON 配置): ``` { "mcpServers": { "trendradar": { "url": "http://127.0.0.1:3333/mcp", "type": "streamableHttp" } } } ```
👉 点击展开:自定义推送样式和内容
**配置位置:** `config/config.yaml` 的 `report` 和 `display` 部分 ``` report: mode: "daily" # 推送模式 display_mode: "keyword" # 显示模式(v4.6.0 新增) rank_threshold: 5 # 排名高亮阈值 sort_by_position_first: false # 排序优先级 max_news_per_keyword: 0 # 每个关键词最大显示数量 display: region_order: # 区域显示顺序(v5.2.0 新增) - new_items # 新增热点区域 - hotlist # 热榜区域 - rss # RSS 订阅区域 - standalone # 独立展示区 - ai_analysis # AI 分析区域 ``` #### 常用配置项说明 | 我想调整什么 | 修改哪个参数 | 默认值 | 说明 | |-------------|-------------|-------|------| | **推送模式** | `mode` | `daily` | 决定推送时机和内容,详见 [推送模式详解](#3-推送模式详解) | | **分组方式** | `display_mode` | `keyword` | `keyword`=按关键词分组(如"AI"),`platform`=按平台分组(如"微博") | | **高亮重点** | `rank_threshold` | `5` | 排名在前 5 的新闻会**加粗**显示,一眼看到最火的 | | **排序规则** | `sort_by_position_first` | `false` | `false`=热度高的排前面,`true`=你配置的词排前面 | | **数量限制** | `max_news_per_keyword` | `0` | 每个关键词最多看几条?`0`表示不限制 | | **显示顺序** | `display.region_order` | 见上方配置 | 调整列表顺序即可控制各区域的显示位置 | #### 分组方式对比(display_mode) 你是想看"这个话题下有哪些新闻",还是"这个平台上有哪些新闻"? | 模式 | 分组方式 | 标题前缀 | 适用场景 | |------|---------|---------|---------| | `keyword`(默认) | **按关键词聚合** | `[平台名]` | 我关注"AI",想看各平台关于AI的新闻 | | `platform` | **按平台聚合** | `[关键词]` | 我关注"微博",想看微博上关于我关注词的新闻 | #### 区域显示顺序(region_order) 通过调整 `display.region_order` 列表的顺序,可以控制推送消息中各区域的显示位置。 **默认顺序**:新增热点 → 热榜 → RSS → 独立展示区 → AI 分析 **自定义示例**:想让 AI 分析放在最前面? ``` display: region_order: - ai_analysis # 移到第一行 - new_items - hotlist - rss - standalone ``` **注意**:区域需同时满足两个条件才会显示: 1. 在 `region_order` 列表中 2. 在 `display.regions` 中对应开关为 `true` #### 区域开关 通过 `display.regions` 控制各区域是否在推送中显示: ``` display: regions: hotlist: true # 热榜区域(关键词匹配的热点新闻) new_items: false # 新增热点区域(含热榜新增 + RSS 新增) rss: true # RSS 订阅区域(关键词匹配的 RSS 内容) standalone: false # 独立展示区(完整热榜/RSS,不受关键词过滤) ai_analysis: true # AI 分析区域 ``` | 区域 | 配置键 | 默认值 | 说明 | |------|--------|-------|------| | **热榜** | `hotlist` | `true` | 按关键词匹配的热点新闻聚合 | | **新增热点** | `new_items` | `false` | 本轮新出现的热点话题(含热榜新增 + RSS 新增)。注:热榜区域中的 🆕 标记不受此开关影响 | | **RSS** | `rss` | `true` | 按关键词匹配的 RSS 订阅内容。关闭后跳过 RSS 分析,但独立展示区中的 RSS 不受影响 | | **独立展示区** | `standalone` | `false` | 指定平台/RSS 的完整内容展示,不受关键词过滤 | | **AI 分析** | `ai_analysis` | `true` | AI 生成的热点分析摘要 | #### 排序优先级(sort_by_position_first) 假设你配置了关键词:1.特斯拉,2.比亚迪。 实际热度:比亚迪(10条),特斯拉(3条)。 | 配置值 | 排序结果 | 你的想法 | |-------|---------|---------| | `false`(默认) | 比亚迪(10条) → 特斯拉(3条) | "谁火谁排前面" | | `true` | 特斯拉(3条) → 比亚迪(10条) | "我配置的顺序就是优先级,不管它火不火" | #### 独立展示区 **场景**:有些平台(比如知乎热榜、HackerNews),我想**完整看一遍**,不管有没有匹配我的关键词。 ``` display: regions: standalone: true # 推送中展示独立展示区(关闭不影响 AI 分析) standalone: platforms: ["zhihu", "weibo"] # 这些平台的热榜给我完整显示 rss_feeds: ["hacker-news"] # 这些RSS源的内容给我完整显示 max_items: 20 # 最多显示多少条 ```
👉 点击展开:设置推送时间(调度系统)
**配置位置:** `config/config.yaml` 的 `schedule` 部分 + `config/timeline.yaml` #### 快速上手 只需在 `config.yaml` 中选一个预设模板,不需要编辑 `timeline.yaml`: ``` schedule: enabled: true preset: "morning_evening" # 改这里就行 ``` #### 可选预设模板 | 模板名 | 说明 | 推送行为 | |-------|------|---------| | `morning_evening` | 全天增量 + 晚间汇总(推荐) | 全天有新增就推 + 19:00-21:00 晚间当日汇总 | | `always_on` | 全天候监控 | 全天有新增就推送,不划分时间段 | | `office_hours` | 办公时间 | 工作日三段式(到岗速览→午间热点→收工汇总),周末增量自由推 | | `night_owl` | 夜猫子 | 午后速览 + 深夜全天汇总(22:00-01:00 跨午夜) | | `custom` | 完全自定义 | 编辑 `timeline.yaml` 底部的 custom 段 | #### 完全自定义 如果预设模板都不满足需求,可以编辑 `config/timeline.yaml` 底部的 `custom` 段,自由定义时间段、日计划和周映射。详见 `timeline.yaml` 文件内的注释说明。 #### 重要提示
👉 点击展开:设置自动运行频率
**配置位置:** `.github/workflows/crawler.yml` 的 `schedule` 部分 ``` on: schedule: - cron: "0 * * * *" # 每小时运行一次 ``` #### 怎么修改运行频率? GitHub Actions 使用一种叫 "Cron" 的时间格式,不需要深入理解,直接复制下面的代码替换即可。 **配置位置:** `.github/workflows/crawler.yml` 文件中的 `schedule` 部分 | 我想要... | 复制这行代码 | 说明 | |-----------|------------|------| | **每小时一次** | `- cron: "0 * * * *"` | **默认配置**,第 0 分钟运行 | | **每 30 分钟** | `- cron: "*/30 * * * *"` | 每隔 30 分钟运行一次 | | **每天早 8 点** | `- cron: "0 0 * * *"` | ⚠️ 写 `0` 是因为 UTC 时间 (0点) = 北京时间 (8点) | | **工作时间每半小时** | `- cron: "*/30 0-14 * * *"` | 对应北京时间 8:00 - 22:00 | | **一日三餐点** | `- cron: "0 0,6,12 * * *"` | 对应北京时间 8:00、14:00、20:00 | #### ⚠️ 两个重要提醒 1. **时差问题**:GitHub 的服务器在国外,用的是 UTC 时间。 - **简单的算术题**:你想设定的北京时间 **减去 8 小时** = 你要填的时间。 - *例子:想让它北京时间 20:00 运行,设置里要填 12:00* 2. **不要太频繁**:建议间隔不要少于 30 分钟。 - GitHub 免费资源有限,跑得太勤可能会被官方限制账号。 - 而且 Actions 启动本身就有几分钟延迟,太精确的控制没有意义。 #### 手把手修改步骤 1. 在你的 GitHub 仓库中,找到 `.github/workflows/crawler.yml` 文件 2. 点击右上角的 ✏️ (Edit) 按钮 3. 找到 `cron: "..."` 那一行,把引号里的内容换成上面的"代码" 4. 点击右上角的绿色 **Commit changes** 按钮保存
👉 点击展开:同时推送给多个接收者
#### 怎么同时推送到多个地方? 很简单,在配置时用分号 `;` 把多个地址隔开就行了。 **举个例子**: 假设你有两个飞书群,想同时收到推送: - 群1地址:`https://.../webhook/aaa` - 群2地址:`https://.../webhook/bbb` 配置时填写: `https://.../webhook/aaa;https://.../webhook/bbb` #### 支持多账号的平台 | 平台 | 配置方法 | 注意事项 | |------|---------|----------| | **飞书/钉钉/企微** | 用 `;` 分隔多个 Webhook URL | 最简单,直接串起来就行 | | **Bark (iOS)** | 用 `;` 分隔多个 Key URL | 推多台 iPhone | | **Telegram** | Token 和 ChatID 都要用 `;` 分隔 | ⚠️ **注意顺序要对应**:Token1 对应 ChatID1
Token2 对应 ChatID2 | | **ntfy** | Topic 和 Token 都要用 `;` 分隔 | 如果某个Topic不需要Token,留空即可:
`token1;;token3` (中间那个是空的) | #### 常用配置示例 (GitHub Secrets / .env) ``` # 飞书发给 3 个群 FEISHU_WEBHOOK_URL=https://hook1...;https://hook2...;https://hook3... # 钉钉发给 2 个群 DINGTALK_WEBHOOK_URL=https://oapi...;https://oapi... # Telegram 发给 2 个人 (注意一一对应) TELEGRAM_BOT_TOKEN=tokenA;tokenB TELEGRAM_CHAT_ID=userA;userB ```
👉 点击展开:选择数据存储位置
#### 数据会存在哪里? 系统会自动帮你选择最合适的地方,你通常不需要操心: | 你的运行环境 | 数据存在哪 | 说明 | |-------------|-----------|------| | **Docker / 本地运行** | **本地硬盘** | 存在项目目录下的 `output/` 文件夹里,随时可以查看。 | | **GitHub Actions** | **云端存储** | 因为 GitHub Actions 运行完就会销毁环境,所以必须配置云存储(例如 Cloudflare R2)。 | #### 怎么配置云存储?(GitHub Actions 用户必看) 如果你是用 GitHub Actions 运行,你需要一个"云端硬盘"来存数据。例如使用 Cloudflare R2(因为有免费额度)。 **在 GitHub Secrets 里添加这 5 个变量:** | 变量名 | 填什么 | |-------|-------| | `STORAGE_BACKEND` | `remote` | | `S3_BUCKET_NAME` | 你的存储桶名字 | | `S3_ACCESS_KEY_ID` | 你的 Access Key | | `S3_SECRET_ACCESS_KEY` | 你的 Secret Key | | `S3_ENDPOINT_URL` | 你的 R2 接口地址 | #### 数据会保存多久? 默认情况下,我们不会自动删除你的数据。但如果你觉得数据太多占空间,可以设置"自动清理"。 **配置位置**:`config/config.yaml` ``` storage: local: retention_days: 30 # 本地数据只保留 30 天 (0 表示永久) remote: retention_days: 30 # 云端数据只保留 30 天 ``` #### 推送时间不对?(时区设置) 如果你身在海外,或者发现推送时间跟你的本地时间对不上,可以修改时区。 **配置位置**:`config/config.yaml` ``` app: timezone: "Asia/Shanghai" # 默认是中国时间 ``` - 比如你在美国洛杉矶,改成:`America/Los_Angeles` - 比如你在英国伦敦,改成:`Europe/London`
👉 点击展开:开启 AI 智能分析功能
#### AI 能帮我做什么? 开启这个功能后,AI 会像一个专业的分析师,在推送每一批新闻时: 1. **自动阅读**:阅读所有匹配到的热点新闻 2. **深度思考**:分析原本孤立的新闻之间的关联 3. **撰写报告**:在推送消息的末尾,附上一份简短深刻的"洞察报告" **包含内容**:热点趋势总结、舆论风向判断、跨平台关联分析、潜在影响评估等。 #### 怎么开启 AI 分析? 最简单的方法是通过环境变量配置(推荐 GitHub Secrets 或 .env)。 **必需的配置项**: | 变量名 | 填什么 | 说明 | |-------|-------|------| | `AI_ANALYSIS_ENABLED` | `true` | 开启开关 | | `AI_API_KEY` | `sk-xxxxxx` | 你的 API Key | | `AI_MODEL` | `deepseek/deepseek-chat` | 模型标识(格式:`provider/model`) | **支持的 AI 提供商**(基于 LiteLLM,支持 100+ 提供商): | 提供商 | AI_MODEL 填什么 | 说明 | |-------|----------------|------| | **DeepSeek** (推荐) | `deepseek/deepseek-chat` | 性价比极高,适合高频分析 | | **OpenAI** | `openai/gpt-4o`
`openai/gpt-4o-mini` | GPT-4o 系列 | | **Google Gemini** | `gemini/gemini-1.5-flash`
`gemini/gemini-1.5-pro` | Gemini 系列 | | **自定义 API** | 任意格式 | 配合 `AI_API_BASE` 使用 | **可选配置项**: | 变量名 | 默认值 | 说明 | |-------|-------|------| | `AI_API_BASE` | (自动) | 自定义 API 地址(如 OneAPI、本地模型) | | `AI_TEMPERATURE` | `1.0` | 采样温度(0-2,越高越随机) | | `AI_MAX_TOKENS` | `5000` | 最大生成 token 数 | | `AI_TIMEOUT` | `120` | 请求超时时间(秒) | | `AI_NUM_RETRIES` | `2` | 失败重试次数 | #### 进阶玩法:AI 翻译 如果你关注了国外的 RSS 源(比如 Hacker News),AI 可以帮你把内容翻译成中文推送。 **配置位置**:`config/config.yaml` ``` ai_translation: enabled: true # 开启翻译 language: "Chinese" # 翻译成什么语言 (Chinese, English, Japanese...) ``` #### 进阶玩法:自定义 AI "人设" 觉得 AI 说话太官方?你可以修改它的提示词,让它变成你喜欢的风格(比如"毒舌评论员"、"资深投资顾问")。 - **修改文件**:`config/ai_analysis_prompt.txt` - **修改方法**:直接用记事本打开编辑,告诉 AI 你想要什么样的分析风格。
## ✨ AI 智能分析 TrendRadar v3.0.0 新增了基于 **MCP (Model Context Protocol)** 的 AI 分析功能,让你可以通过自然语言与新闻数据对话,进行深度分析。 ### ⚠️ 使用前必读 **重要提示:AI 功能需要本地新闻数据支持** AI 分析功能**不是**直接查询网络实时数据,而是分析你**本地已积累的新闻数据**(存储在 `output` 文件夹中) #### 使用说明: 1. **项目自带测试数据**:`output` 目录默认包含 **2025-12-21~2025-12-27** 一周的热榜新闻数据,可用于快速体验 AI 功能 2. **查询限制**: - ✅ 只能查询已有日期范围内的数据(12月21-27日,共7天) - ❌ 无法查询实时新闻或未来日期 3. **获取最新数据**: - 测试数据仅供快速体验,**建议自行部署项目**获取实时数据 - 按照 [快速开始](#-快速开始) 部署运行项目 - 等待至少 1 天积累新闻数据后,即可查询最新热点 ### 1. 快速部署 Cherry Studio 提供 GUI 配置界面,5 分钟快速部署,复杂的部分是一键安装的。 **图文部署教程**:现已更新到我的[公众号](#-支持项目),回复 "mcp" 即可 **详细部署教程**:[README-Cherry-Studio.md](README-Cherry-Studio.md) **部署模式说明**: - **STDIO 模式(推荐)**:一次配置后续无需重复配置,**图文部署教程**中仅以此模式的配置为例。 - **HTTP 模式(备选)**:如果 STDIO 模式配置遇到问题,可使用 HTTP 模式。此模式的配置方式与 STDIO 基本一致,但复制粘贴的内容就一行,不易出错。唯一需要注意的是每次使用前都需要手动启动一下服务。详细请参考 [README-Cherry-Studio.md](README-Cherry-Studio.md) 底部的 HTTP 模式说明。 ### 2. 学习与 AI 对话的姿势 **详细对话教程**:[README-MCP-FAQ.md](README-MCP-FAQ.md)

## 🔌 MCP 客户端 TrendRadar MCP 服务支持标准的 Model Context Protocol (MCP) 协议,可以接入各种支持 MCP 的 AI 客户端进行智能分析。 ### 支持的客户端 **注意事项**: - 将 `/path/to/TrendRadar` 替换为你的项目实际路径 - Windows 路径使用双反斜杠:`C:\\Users\\YourName\\TrendRadar` - 保存后记得重启
👉 点击展开:Cursor
#### 方式一:HTTP 模式 1. **启动 HTTP 服务**: # Windows start-http.bat # Mac/Linux ./start-http.sh 2. **配置 Cursor**: **项目级配置**(推荐): 在项目根目录创建 `.cursor/mcp.json`: { "mcpServers": { "trendradar": { "url": "http://localhost:3333/mcp", "description": "TrendRadar 新闻热点聚合分析" } } } **全局配置**: 在用户目录创建 `~/.cursor/mcp.json`(同样内容) 3. **使用步骤**: - 保存配置文件后重启 Cursor - 在聊天界面的 "Available Tools" 中查看已连接的工具 - 开始使用:`搜索今天的"AI"相关新闻` #### 方式二:STDIO 模式(推荐) 创建 `.cursor/mcp.json`: ``` { "mcpServers": { "trendradar": { "command": "uv", "args": [ "--directory", "/path/to/TrendRadar", "run", "python", "-m", "mcp_server.server" ] } } } ```👉 点击展开:VSCode (Cline/Continue)
#### Cline 配置 在 Cline 的 MCP 设置中添加: **HTTP 模式**: ``` { "trendradar": { "url": "http://localhost:3333/mcp", "type": "streamableHttp", "autoApprove": [], "disabled": false } } ``` **STDIO 模式**(推荐): ``` { "trendradar": { "command": "uv", "args": [ "--directory", "/path/to/TrendRadar", "run", "python", "-m", "mcp_server.server" ], "type": "stdio", "disabled": false } } ``` #### Continue 配置 编辑 `~/.continue/config.json`: ``` { "experimental": { "modelContextProtocolServers": [ { "transport": { "type": "stdio", "command": "uv", "args": [ "--directory", "/path/to/TrendRadar", "run", "python", "-m", "mcp_server.server" ] } } ] } } ``` **使用示例**: ``` 分析最近7天"特斯拉"的热度变化趋势 生成今天的热点摘要报告 搜索"比特币"相关新闻并分析情感倾向 ```👉 点击展开:MCP Inspector(调试工具)
MCP Inspector 是官方调试工具,用于测试 MCP 连接: #### 使用步骤 1. **启动 TrendRadar HTTP 服务**: # Windows start-http.bat # Mac/Linux ./start-http.sh 2. **启动 MCP Inspector**: npx @modelcontextprotocol/inspector 3. **在浏览器中连接**: - 访问:`http://localhost:3333/mcp` - 测试 "Ping Server" 功能验证连接 - 检查 "List Tools" 是否返回 17 个工具: - 基础查询:get_latest_news, get_news_by_date, get_trending_topics - 智能检索:search_news, find_related_news - 高级分析:analyze_topic_trend, analyze_data_insights, analyze_sentiment, aggregate_news, compare_periods, generate_summary_report - RSS 查询:get_latest_rss, search_rss, get_rss_feeds_status - 系统管理:get_current_config, get_system_status, resolve_date_range
👉 点击展开:其他支持 MCP 的客户端
任何支持 Model Context Protocol 的客户端都可以连接 TrendRadar: #### HTTP 模式 **服务地址**:`http://localhost:3333/mcp` **基本配置模板**: ``` { "name": "trendradar", "url": "http://localhost:3333/mcp", "type": "http", "description": "新闻热点聚合分析" } ``` #### STDIO 模式(推荐) **基本配置模板**: ``` { "name": "trendradar", "command": "uv", "args": [ "--directory", "/path/to/TrendRadar", "run", "python", "-m", "mcp_server.server" ], "type": "stdio" } ``` **注意事项**: - 替换 `/path/to/TrendRadar` 为实际项目路径 - Windows 路径使用反斜杠转义:`C:\\Users\\...` - 确保已完成项目依赖安装(运行过 setup 脚本)
👉 点击展开:Q1: HTTP 服务无法启动?
**检查步骤**: 1. 确认端口 3333 未被占用: # Windows netstat -ano | findstr :3333 # Mac/Linux lsof -i :3333 2. 检查项目依赖是否安装: # 重新运行安装脚本 # Windows: setup-windows.bat 或者 setup-windows-en.bat # Mac/Linux: ./setup-mac.sh 3. 查看详细错误日志: uv run python -m mcp_server.server --transport http --port 3333 4. 尝试自定义端口: uv run python -m mcp_server.server --transport http --port 33333
👉 点击展开:Q2: 客户端无法连接到 MCP 服务?
**解决方案**: 1. **STDIO 模式**: - 确认 UV 路径正确(运行 `which uv` 或 `where uv`) - 确认项目路径正确且无中文字符 - 查看客户端错误日志 2. **HTTP 模式**: - 确认服务已启动(访问 `http://localhost:3333/mcp`) - 检查防火墙设置 - 尝试使用 127.0.0.1 替代 localhost 3. **通用检查**: - 重启客户端应用 - 查看 MCP 服务日志 - 使用 MCP Inspector 测试连接
👉 点击展开:Q3: 工具调用失败或返回错误?
**可能原因**: 1. **数据不存在**: - 确认已运行过爬虫(有 output 目录数据) - 检查查询日期范围是否有数据 - 查看 output 目录的可用日期 2. **参数错误**: - 检日期格式:`YYYY-MM-DD` - 确认平台 ID 正确:`zhihu`, `weibo` 等 - 查看工具文档中的参数说明 3. **配置问题**: - 确认 `config/config.yaml` 存在 - 确认 `config/frequency_words.txt` 存在 - 检查配置文件格式是否正确
## 📚 项目相关 - [可在该文章下方留言,方便项目作者用手机答疑](https://mp.weixin.qq.com/s/KYEPfTPVzZNWFclZh4am_g) - [2个月破 1000 star,我的GitHub项目推广实战经验](https://mp.weixin.qq.com/s/jzn0vLiQFX408opcfpPPxQ) - [github fork 运行本项目的注意事项 ](https://mp.weixin.qq.com/s/C8evK-U7onG1sTTdwdW2zg) - [基于本项目,如何开展公众号或者新闻资讯类文章写作](https://mp.weixin.qq.com/s/8ghyfDAtQZjLrnWTQabYOQ) - 如果你有小众需求,完全可以基于我的项目自行开发,零编程基础的也可以试试 - 我所有的开源项目或多或少都使用了自己写的**AI辅助软件**来提升开发效率,这款工具已开源 - **核心功能**:迅速筛选项目代码喂给AI,你只需要补充个人需求即可 - **项目地址**:https://github.com/sansan0/ai-code-context-helper ### 其余项目 - https://github.com/sansan0/mao-map - https://github.com/sansan0/bilibili-comment-analyzer [](https://www.star-history.com/#sansan0/TrendRadar&Date)
## 📄 许可证 GPL-3.0 License
[🔝 回到顶部](#trendradar)
标签:AI 翻译, AI 趋势分析, Docker 部署, MCP 架构, Python, RSS 聚合阅读器, Slack 集成, Telegram Bot, 云端部署, 企业微信, 信息聚合, 信息过滤, 微信机器人, 情感分析, 新闻筛选, 无后门, 智能简报, 消息推送, 漏洞探索, 热点追踪, 网络运维, 自托管, 舆情监控, 请求拦截, 逆向工具, 钉钉通知, 飞书机器人