facebookresearch/vjepa2
GitHub: facebookresearch/vjepa2
Meta FAIR 推出的自监督视频预训练模型,支持视频理解、动作预测及机器人零样本操作规划。
Stars: 4244 | Forks: 521
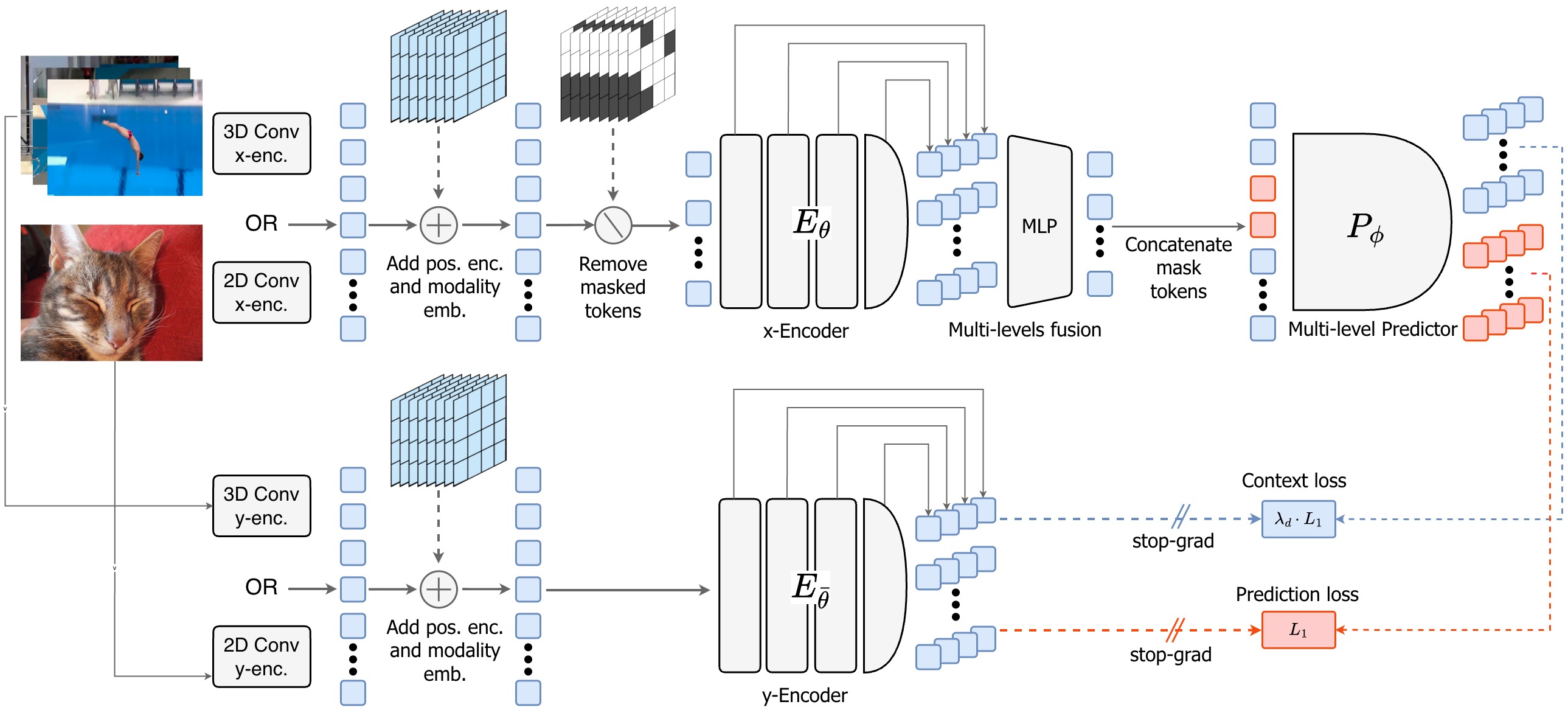
🆕 **[2026-03-16]:** :fire: V-JEPA 2.1 发布 :fire: 采用全新配方训练的新模型系列,能够学习高质量且时间一致的密集特征 !!!
**[2025-06-25]:** V-JEPA 2 发布。[[`博客`](https://ai.meta.com/blog/v-jepa-2-world-model-benchmarks)]
# V-JEPA 2:自监督视频模型实现理解、预测与规划
### Meta FAIR
Mahmoud Assran∗, Adrien Bardes∗, David Fan∗, Quentin Garrido∗, Russell Howes∗, Mojtaba
Komeili∗, Matthew Muckley∗, Ammar Rizvi∗, Claire Roberts∗, Koustuv Sinha∗, Artem Zholus*,
Sergio Arnaud*, Abha Gejji*, Ada Martin*, Francois Robert Hogan*, Daniel Dugas*, Piotr
Bojanowski, Vasil Khalidov, Patrick Labatut, Francisco Massa, Marc Szafraniec, Kapil
Krishnakumar, Yong Li, Xiaodong Ma, Sarath Chandar, Franziska Meier*, Yann LeCun*, Michael
Rabbat*, Nicolas Ballas*
*核心团队
[[`论文`](https://arxiv.org/abs/2506.09985)] [[`博客`](https://ai.meta.com/blog/v-jepa-2-world-model-benchmarks)] [[`BibTex`](#Citation)]
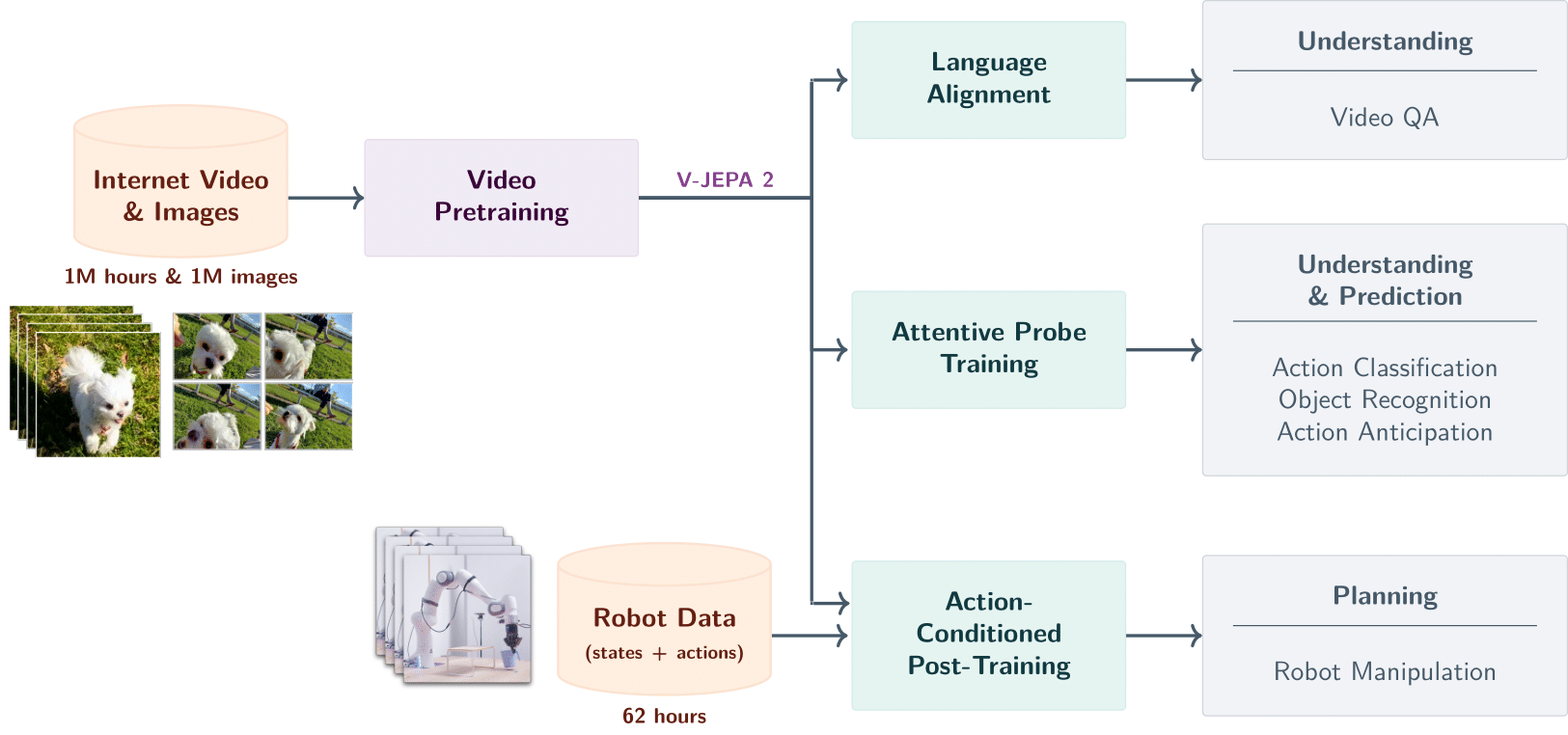
V-JEPA 2、V-JEPA 2-AC 和 V-JEPA 2.1 的官方 Pytorch 代码库。
V-JEPA 2 是一种利用互联网规模视频数据训练视频编码器的自监督方法,在运动理解和人类动作预测任务上达到了最先进的性能。V-JEPA 2-AC 是基于 V-JEPA 2(使用少量机器人轨迹交互数据)进行后训练得到的潜在动作条件世界模型,无需针对特定环境的数据收集或针对特定任务的训练或校准即可解决机器人操作任务。
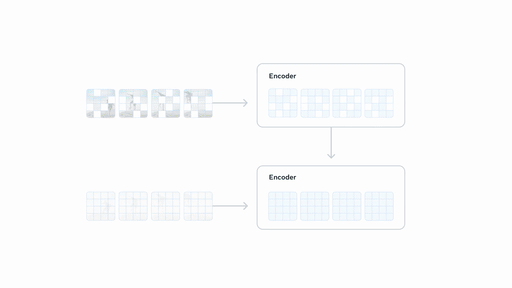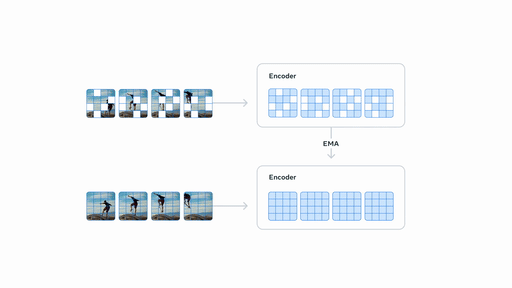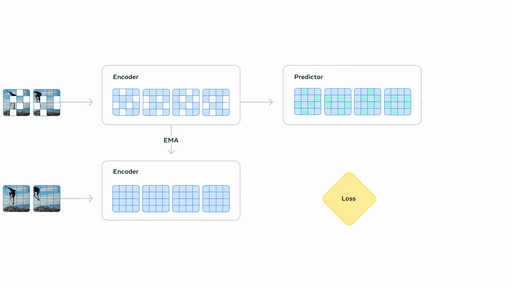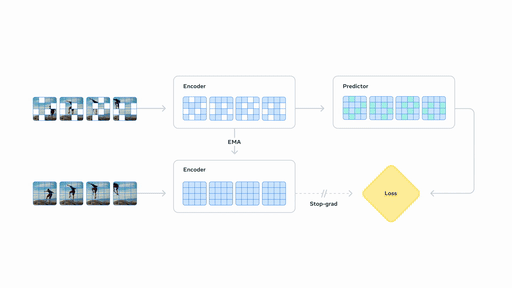
## V-JEPA 2-AC 后训练
**(上图)** 在使用少量机器人数据进行后训练后,我们可以将模型部署在新环境中的机械臂上,并通过从图像目标进行规划来处理基本任务,如到达、抓取和拾取放置。**(下图)** 使用 Franka 机械臂在机器人操作任务上的性能,输入通过单目 RGB 摄像头提供。

## 模型
### V-JEPA 2 和 V-JEPA 2.1
#### HuggingFace
请参阅我们的 HuggingFace [合集](https://huggingface.co/collections/facebook/v-jepa-2-6841bad8413014e185b497a6) 以获取 V-JEPA 2。
#### V-JEPA 2 预训练检查点
#### V-JEPA 2.1 预训练检查点
#### 预训练骨干网络 (通过 PyTorch Hub)
请在本地安装 [Pytorch](https://pytorch.org/get-started/locally/)、[timm](https://pypi.org/project/timm/) 和 [einops](https://pypi.org/project/einops/),然后运行以下命令加载每个模型。强烈建议安装带有 CUDA 支持的 Pytorch。
```
import torch
# 预处理器
processor = torch.hub.load('facebookresearch/vjepa2', 'vjepa2_preprocessor')
# 模型
# V-JEPA 2
vjepa2_vit_large = torch.hub.load('facebookresearch/vjepa2', 'vjepa2_vit_large')
vjepa2_vit_huge = torch.hub.load('facebookresearch/vjepa2', 'vjepa2_vit_huge')
vjepa2_vit_giant = torch.hub.load('facebookresearch/vjepa2', 'vjepa2_vit_giant')
vjepa2_vit_giant_384 = torch.hub.load('facebookresearch/vjepa2', 'vjepa2_vit_giant_384')
# V-JEPA 2.1
vjepa2_1_vit_base_384 = torch.hub.load('facebookresearch/vjepa2', 'vjepa2_1_vit_base_384')
vjepa2_1_vit_large_384 = torch.hub.load('facebookresearch/vjepa2', 'vjepa2_1_vit_large_384')
vjepa2_1_vit_giant_384 = torch.hub.load('facebookresearch/vjepa2', 'vjepa2_1_vit_giant_384')
vjepa2_1_vit_gigantic_384 = torch.hub.load('facebookresearch/vjepa2', 'vjepa2_1_vit_gigantic_384')
```
#### Huggingface 上的预训练检查点
您也可以使用我们在 [Huggingface for V-JEPA 2](https://huggingface.co/collections/facebook/v-jepa-2-6841bad8413014e185b497a6) 上的预训练检查点。
```
from transformers import AutoVideoProcessor, AutoModel
hf_repo = "facebook/vjepa2-vitg-fpc64-256"
# facebook/vjepa2-vitl-fpc64-256
# facebook/vjepa2-vith-fpc64-256
# facebook/vjepa2-vitg-fpc64-256
# facebook/vjepa2-vitg-fpc64-384
model = AutoModel.from_pretrained(hf_repo)
processor = AutoVideoProcessor.from_pretrained(hf_repo)
```
#### 评估注意力探针 (Attentive Probes)
我们分享了我们两个视觉理解评估(Something-Something v2 和 Diving48)以及动作预测评估 EPIC-KITCHENS-100 的训练好的注意力探针。
### V-JEPA 2-AC
我们的动作条件检查点是从 ViT-g 编码器训练而来的。
#### 预训练动作条件骨干网络 (通过 PyTorch Hub)
请在本地安装 [Pytorch](https://pytorch.org/get-started/locally/)、[timm](https://pypi.org/project/timm/) 和 [einops](https://pypi.org/project/einops/),然后运行以下命令加载每个模型。强烈建议安装带有 CUDA 支持的 Pytorch。
```
import torch
vjepa2_encoder, vjepa2_ac_predictor = torch.hub.load('facebookresearch/vjepa2', 'vjepa2_ac_vit_giant')
```
请参阅 [energy_landscape_example.ipynb](notebooks/energy_landscape_example.ipynb),这是一个示例笔记本,使用从我们实验室收集的机器人轨迹计算预训练动作条件骨干网络的能量景观。
要运行此笔记本,您需要在 conda 环境中额外安装 [Jupyter](https://jupyter.org/install) 和 [Scipy](https://scipy.org/install/)。
## 入门指南
### 设置
```
conda create -n vjepa2-312 python=3.12
conda activate vjepa2-312
pip install . # or `pip install -e .` for development mode
```
**macOS 用户注意:** V-JEPA 2 依赖于 [`decord`](https://github.com/dmlc/decord),它不支持 macOS(不幸的是,也不再处于开发状态)。为了在 macOS 上运行 V-JEPA 2 代码,您需要一个不同的 `decord` 实现。我们不做具体推荐,尽管一些用户报告使用了 [`eva-decord`](https://github.com/georgia-tech-db/eva-decord)(参见 [PR 1](https://github.com/facebookresearch/vjepa2/pull/1)) 或 [`decord2`](https://github.com/johnnynunez/decord2)(参见 [PR 31](https://github.com/facebookresearch/vjepa2/pull/31))。我们将 `decord` 包的选择权留给用户自行决定。
### 使用演示
请参阅 [vjepa2_demo.ipynb](notebooks/vjepa2_demo.ipynb) [(Colab 链接)](https://colab.research.google.com/github/facebookresearch/vjepa2/blob/main/notebooks/vjepa2_demo.ipynb) 或 [vjepa2_demo.py](notebooks/vjepa2_demo.py),了解如何加载 HuggingFace 和 PyTorch V-JEPA 2 模型并在示例视频上运行推理以获取示例分类结果的示例。
该脚本假定存在已下载的模型检查点,因此您需要下载模型权重并更新脚本中的相应路径。例如:
```
wget https://dl.fbaipublicfiles.com/vjepa2/vitg-384.pt -P YOUR_DIR
wget https://dl.fbaipublicfiles.com/vjepa2/evals/ssv2-vitg-384-64x2x3.pt -P YOUR_DIR
# 然后在 vjepa2_demo.py 中更新你的模型路径。
pt_model_path = YOUR_DIR/vitg-384.pt
classifier_model_path = YOUR_DIR/ssv2-vitg-384-64x2x3.pt
# 然后运行脚本(假设你的机器有 GPU)
python -m notebooks.vjepa2_demo
```
### 基于探针的评估
基于探针的评估包括在冻结的 V-JEPA 2 特征之上训练一个注意力探针。我们提供用于训练您自己的探针的训练脚本,以及用于直接运行推理的检查点。
#### 训练探针
评估可以在本地运行,也可以通过 SLURM 分布式运行。(本地运行对于调试和验证很有用)。
这些示例命令启动 Something-Something v2 视频分类;其他评估通过指定相应的配置来启动。
使用“评估注意力探针”下提供的训练配置。这些配置允许使用各种优化参数并行训练多个探针。
根据需要更改文件路径(例如 `folder`、`checkpoint`、`dataset_train`、`dataset_val`)以匹配您本地文件系统上数据和下载检查点的位置。
根据需要更改节点数和本地批大小,以不超过可用的 GPU 内存。
##### 本地
要在本地运行,请指定要使用的 GPU
```
python -m evals.main --fname configs/eval/vitl16/ssv2.yaml \
--devices cuda:0 cuda:1
```
##### 分布式
```
python -m evals.main_distributed \
--fname configs/eval/vitl/ssv2.yaml \
--time 8600 \
--account my_account --qos=my_qos
```
#### 从现有探针推理
使用 [评估注意力探针](#evaluation-attentive-probes) 下提供的推理配置。
下载相应的检查点,将其重命名为 'latest.pt',并创建一个包含该检查点的文件夹,格式与配置中的变量匹配:
```
[folder]/[eval_name]/[tag]/latest.pt
```
然后运行推理,在本地或分布式运行,使用与上述相同的评估命令,但使用 `configs/inference` 中的配置。
### 预训练
同样,训练也可以在本地或分布式运行。预训练和冷却训练阶段使用不同的配置,通过相同的命令运行。
这些示例命令启动 ViT-L 模型的初始训练。冷却(或动作条件)训练的配置可以在初始训练配置的同一目录中找到。
#### 本地
```
python -m app.main --fname configs/train/vitl16/pretrain-256px-16f.yaml \
--devices cuda:0
```
#### 分布式
```
python -m app.main_distributed \
--fname configs/train/vitl16/pretrain-256px-16f.yaml
--time 6000
--account my_account --qos=my_qos
```
### 后训练
从预训练的 VJEPA 2 骨干网络开始,动作条件模型的后训练也遵循类似的接口,可以使用 [此配置](configs/train/vitg16/droid-256px-8f.yaml) 在本地或分布式运行。
我们从 ViT-g/16 骨干网络开始后训练模型。
#### 本地
```
python -m app.main --fname configs/train/vitg16/droid-256px-8f.yaml \
--devices cuda:0
```
#### 分布式
```
python -m app.main_distributed \
--fname configs/train/vitg16/droid-256px-8f.yaml
--time 6000
--account my_account --qos=my_qos
```
## 代码结构
```
.
├── app # training loops
│ ├── vjepa # V-JEPA 2 pre-training
│ ├── vjepa_2_1 # V-JEPA 2.1 pre-training
│ ├── vjepa_droid # training the action-conditioned model
│ ├── main_distributed.py # entrypoint for launch app on slurm cluster
│ └── main.py # entrypoint for launch app locally on your machine
├── configs # config files with experiment params for training and evaluation
│ ├── train # pretraining with V-JEPA 2 (phase 1), cooldown (phase 2), and action-conditioned training
│ ├── train_2_1 # pretraining with V-JEPA 2.1 (phase 1), cooldown (phase 2)
│ └── eval # frozen evaluations
│ └── inference # inference only frozen evaluations
├── evals # evaluation loops training an attentive probe with frozen backbone...
│ ├── action_anticipation_frozen # action anticipation
│ ├── image_classification_frozen # image understanding
│ ├── video_classification_frozen # video understanding
│ ├── main_distributed.py # entrypoint for distributed evaluations
│ └── main.py # entrypoint for locally-run evaluations
├── src # the package
│ ├── datasets # datasets, data loaders, ...
│ ├── models # model definitions
│ ├── masks # mask collators, masking utilities, ...
│ └── utils # shared utilities
├── tests # unit tests for some modules in `src`
```
## 许可证
V-JEPA 2 的大部分内容根据 MIT 许可证授权,但项目的部分内容适用单独的许可条款:
[src/datasets/utils/video/randaugment.py](src/datasets/utils/video/randaugment.py)
[src/datasets/utils/video/randerase.py](src/datasets/utils/video/randerase.py)
[src/datasets/utils/worker_init_fn.py](src/datasets/utils/worker_init_fn.py)
根据 Apache 2.0 许可证授权。 ## 引用 如果您发现此仓库在您的研究中有用,请考虑给它一个星标 :star: 并引用这些论文: ``` @article{assran2025vjepa2, title={V-JEPA~2: Self-Supervised Video Models Enable Understanding, Prediction and Planning}, author={Assran, Mahmoud and Bardes, Adrien and Fan, David and Garrido, Quentin and Howes, Russell and Komeili, Mojtaba and Muckley, Matthew and Rizvi, Ammar and Roberts, Claire and Sinha, Koustuv and Zholus, Artem and Arnaud, Sergio and Gejji, Abha and Martin, Ada and Robert Hogan, Francois and Dugas, Daniel and Bojanowski, Piotr and Khalidov, Vasil and Labatut, Patrick and Massa, Francisco and Szafraniec, Marc and Krishnakumar, Kapil and Li, Yong and Ma, Xiaodong and Chandar, Sarath and Meier, Franziska and LeCun, Yann and Rabbat, Michael and Ballas, Nicolas}, journal={arXiv preprint arXiv:2506.09985}, year={2025} } ``` ``` @article{murlabadia2026vjepa2_1, title={V-JEPA 2.1: Unlocking Dense Features in Video Self-Supervised Learning}, author={Mur-Labadia, Lorenzo and Muckley, Matthew and Bar, Amir and Assran, Mahmoud and Sinha, Koustuv and Rabbat, Michael and LeCun, Yann and Ballas, Nicolas and Bardes, Adrien}, journal={arXiv preprint arXiv:2603.14482}, year={2026} } ```

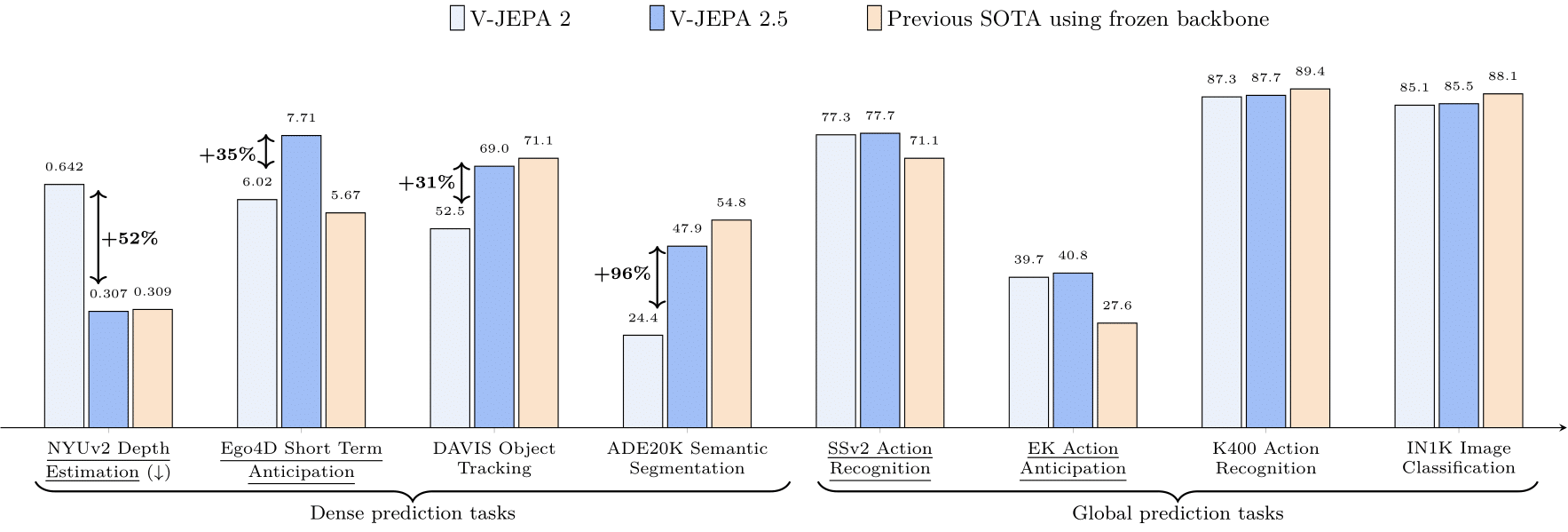
| 基准测试 | V-JEPA 2 | 之前最佳 |
|---|---|---|
| EK100 | 39.7% | 27.6% (PlausiVL) |
| SSv2 (Probe) | 77.3% | 69.7% (InternVideo2-1B) |
| Diving48 (Probe) | 90.2% | 86.4% (InternVideo2-1B) |
| MVP (Video QA) | 44.5% | 39.9% (InternVL-2.5) |
| TempCompass (Video QA) | 76.9% | 75.3% (Tarsier 2) |
| 抓取 (Grasp) | 拾取放置 (Pick-and-Place) | ||||
|---|---|---|---|---|---|
| 方法 | 到达 (Reach) | 杯子 | 盒子 | 杯子 | 盒子 |
| Octo | 100% | 10% | 0% | 10% | 10% |
| Cosmos | 80% | 0% | 20% | 0% | 0% |
| VJEPA 2-AC | 100% | 60% | 20% | 80% | 50% |
| 模型 | #参数量 | 分辨率 | 下载链接 | 预训练配置 |
|---|---|---|---|---|
| ViT-L/16 | 300M | 256 | checkpoint | configs |
| ViT-H/16 | 600M | 256 | checkpoint | configs |
| ViT-g/16 | 1B | 256 | checkpoint | configs |
| ViT-g/16384 | 1B | 384 | checkpoint | configs |
| 模型 | #参数量 | 分辨率 | 下载链接 | 预训练配置 |
|---|---|---|---|---|
| ViT-B/16 | 80M | 384 | checkpoint | configs |
| ViT-L/16 | 300M | 384 | checkpoint | configs |
| ViT-g/16 | 1B | 384 | checkpoint | configs |
| ViT-G/16 | 2B | 384 | checkpoint | configs |
| 模型 | SSv2 | Diving48 | EK100 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 检查点 | 训练配置 | 推理配置 | 结果 | 检查点 | 训练配置 | 推理配置 | 结果 | 检查点 | 训练配置 | 推理配置 | 结果 | |
| ViT-L/16 | checkpoint | config | config | 73.7% | checkpoint | config | config | 89.0% | checkpoint | config | config | 32.7 R@5 |
| ViT-g/16384 | checkpoint | config | config | 77.3% | checkpoint | config | config | 90.2% | checkpoint | config | config | 39.7 R@5 |
| 模型 | 下载链接 | 训练配置 |
|---|---|---|
| ViT-g/16 | checkpoint | config |
[src/datasets/utils/video/randerase.py](src/datasets/utils/video/randerase.py)
[src/datasets/utils/worker_init_fn.py](src/datasets/utils/worker_init_fn.py)
根据 Apache 2.0 许可证授权。 ## 引用 如果您发现此仓库在您的研究中有用,请考虑给它一个星标 :star: 并引用这些论文: ``` @article{assran2025vjepa2, title={V-JEPA~2: Self-Supervised Video Models Enable Understanding, Prediction and Planning}, author={Assran, Mahmoud and Bardes, Adrien and Fan, David and Garrido, Quentin and Howes, Russell and Komeili, Mojtaba and Muckley, Matthew and Rizvi, Ammar and Roberts, Claire and Sinha, Koustuv and Zholus, Artem and Arnaud, Sergio and Gejji, Abha and Martin, Ada and Robert Hogan, Francois and Dugas, Daniel and Bojanowski, Piotr and Khalidov, Vasil and Labatut, Patrick and Massa, Francisco and Szafraniec, Marc and Krishnakumar, Kapil and Li, Yong and Ma, Xiaodong and Chandar, Sarath and Meier, Franziska and LeCun, Yann and Rabbat, Michael and Ballas, Nicolas}, journal={arXiv preprint arXiv:2506.09985}, year={2025} } ``` ``` @article{murlabadia2026vjepa2_1, title={V-JEPA 2.1: Unlocking Dense Features in Video Self-Supervised Learning}, author={Mur-Labadia, Lorenzo and Muckley, Matthew and Bar, Amir and Assran, Mahmoud and Sinha, Koustuv and Rabbat, Michael and LeCun, Yann and Ballas, Nicolas and Bardes, Adrien}, journal={arXiv preprint arXiv:2603.14482}, year={2026} } ```
标签:AI, CV, JEPA架构, Meta FAIR, PyTorch, SOTA, V-JEPA, Yann LeCun, 世界模型, 人工智能, 具身智能, 凭据扫描, 动作预测, 机器人, 机器人操作, 深度学习, 潜在空间, 特征提取, 用户模式Hook绕过, 神经网络, 自动化代码审查, 自监督学习, 视频模型, 视频理解, 视频编码器, 计算机视觉, 运动分析, 逆向工具, 预测规划