whitecircle-ai/circle-guard-bench
GitHub: whitecircle/circle-guard-bench
首个综合评估 LLM 防护系统安全能力、越狱抵抗力和性能延迟的基准测试框架。
Stars: 70 | Forks: 5

# CircleGuardBench - 用于评估 AI 模型防护能力的全功能基准测试
**CircleGuardBench** 是首个用于**评估**大型语言模型(LLM)防护系统**防护能力**的同类基准测试。它在**接近真实世界数据的分类体系**上测试防护模型阻断有害内容、抵抗越狱、避免误报以及在实时环境中高效运行的能力。由 [White Circle](https://whitecircle.ai?utm_source=github&utm_medium=organic&utm_campaign=circleguardbench_launch&utm_content=repo) 创建。
## 实用链接
- [HuggingFace 排行榜](https://huggingface.co/spaces/whitecircle-ai/circle-guard-bench)
- [HuggingFace 博文](https://huggingface.co/blog/whitecircle-ai/circleguardbench)
- [Twitter 公告](https://x.com/whitecircle_ai/status/1920094991960997998)
## 测量内容
- 跨越 17 个关键风险类别的有害内容检测
- 使用对抗性提示变体进行的越狱抵抗测试
- 对安全、中性输入的误报率
- 现实约束条件下的运行时性能
- 结合准确性和速度的综合得分,以评估现实世界的就绪程度
## 关键特性
- 对多种 LLM 和防护模型进行标准化评估
- 支持主流推理引擎(openai_api, vllm, sglang, transformers)
- 与真实世界滥用案例和审核 API(OpenAI, Google 等)对齐的自定义分类体系
- 惩罚不安全输出和慢响应时间的综合评分系统
- 生成包含每类和宏平均分数的排行榜
## 为何重要
大多数基准测试只关注准确性,而忽略了关键的生产要求,如速度和越狱抵抗力。CircleGuardBench 是首个将准确性、攻击鲁棒性和延迟整合到单一实用评估框架中的基准测试——帮助安全团队选择真正能在生产环境中发挥作用的防护模型。
## 安装
```
# 克隆 repository
git clone https://github.com/whitecircle-ai/circle-guard-bench.git
cd circle-guard-bench
# 使用 Poetry 安装(基础安装)
poetry install
# 安装额外的 inference engines
poetry install --extras "vllm sglang transformers"
# 或仅使用 vllm
poetry install --extras "vllm"
# 或仅使用 sglang
poetry install --extras "sglang"
# 或仅使用 transformers
poetry install --extras "transformers"
# 使用 pip(或 uv)安装
pip install -e .
# 使用 pip 安装额外的 inference engines
pip install -e ".[vllm,sglang,transformers]"
```
## 快速开始
```
# 对特定 model 运行 evaluation
guardbench run "gpt-4o-mini (CoT)"
# 对所有已配置的 models 运行 evaluation
guardbench run --all
# 查看 leaderboard
guardbench leaderboard
# 显示可用 models
guardbench models
# 显示 dataset 信息
guardbench dataset_info
```
查看 Colab 上的完整示例:[](https://colab.research.google.com/drive/13NYoKODqaWD_VJbfESBYOosfiC7VKls2)
## 配置
### 模型配置
模型在 `configs/models.json` 中配置。示例:
```
[
{
"name": "gpt-4o-mini (CoT)",
"type": "llm_regexp",
"eval_on": "all",
"inference_engine": "openai_api",
"params": {
"api_model_name": "openai/gpt-4o-mini",
"endpoint": "https://openrouter.ai/api/v1/"
},
"max_concurrency": 20,
"use_cot": true
}
]
```
### 提示词模板
提示词模板作为 Jinja2 模板存储在 `prompts` 目录中。
查看这些模板以了解带有推理的提示示例:
- `cot_prompt_eval_regexp.jinja`
- `cot_answer_eval_regexp.jinja`
### 支持的推理引擎
CircleGuardBench 支持多种推理引擎:
- **openai_api**: 用于 OpenAI 模型和兼容的 API(需要 `openai` 包)
- **vllm**: 用于使用 vLLM 进行本地模型执行(需要可选依赖 `vllm`)
- **sglang**: 用于使用 SGLang 在本地运行模型(需要可选依赖 `sglang`)
- **transformers**: 用于推理分类器,不支持其他模型(如 instruct llms)。(需要可选依赖 `transformers`)
要使用 `vllm` 或 `sglang` 引擎,您需要安装相应的可选依赖。
## 数据集格式
CircleGuardBench 使用标准化的数据集格式。以下是所需的列及其描述:
| 列名 | 描述 | 是否必需 |
| :----------------------- | :------------------------------------------------------------------------------ | :------------------------------------------- |
| `harm_category` | 与提示相关的潜在危害类别。 | 仅当 `prompt_verdict` 为 'unsafe' 时 |
| `prompt` | 原始输入提示。 | 总是 |
| `prompt_verdict` | 原始 `prompt` 的安全判定('safe' 或 'unsafe')。 | 总是 |
| `prompt_hash` | `prompt` 的唯一标识符哈希。 | 总是 |
| `default_answer` | 模型对原始 `prompt` 的响应。 | 总是 |
| `default_answer_verdict` | `default_answer` 的安全判定('safe' 或 'unsafe')。 | 总是 |
| `jailbreaked_prompt` | 旨在绕过安全过滤器的 `prompt` 修改版本。 | 仅当 `prompt_verdict` 为 'unsafe' 时 |
| `jailbreaked_answer` | 模型对 `jailbreaked_prompt` 的响应。 | 仅当 `prompt_verdict` 为 'unsafe' 时 |
## CLI 命令
CircleGuardBench 提供了一个强大的命令行界面来管理评估过程:
- `guardbench run [MODEL_NAME]`: 运行特定模型的评估
- `guardbench run --all`: 运行所有已配置模型的评估
- `guardbench run --force`: 强制重新评估,即使模型已被评估过
- `guardbench run --model-type TYPE`: 使用缓存结果时指定模型类型
- `guardbench leaderboard`: 以排行榜格式显示评估结果
- `guardbench models`: 列出所有已配置的模型及其详细信息
- `guardbench prompts`: 列出可用的提示词模板
- `guardbench dataset_info`: 显示有关已加载数据集的信息
## 高级用法
### 排序排行榜结果
```
# 按 accuracy score 排序
guardbench leaderboard --sort-by accuracy
# 按 recall 排序
guardbench leaderboard --sort-by recall
# 按平均 runtime 排序
guardbench leaderboard --sort-by avg_runtime_ms
```
### 过滤指标
```
# 仅显示 default prompts 的 metrics
guardbench leaderboard --metric-type default_prompts
# 仅显示 jailbreak attempts 的 metrics
guardbench leaderboard --metric-type jailbreaked_prompts
```
### 按类别分组
```
# 按 categories 对结果进行分组
guardbench leaderboard --use-categories
# 禁用 category grouping
guardbench leaderboard --no-categories
```
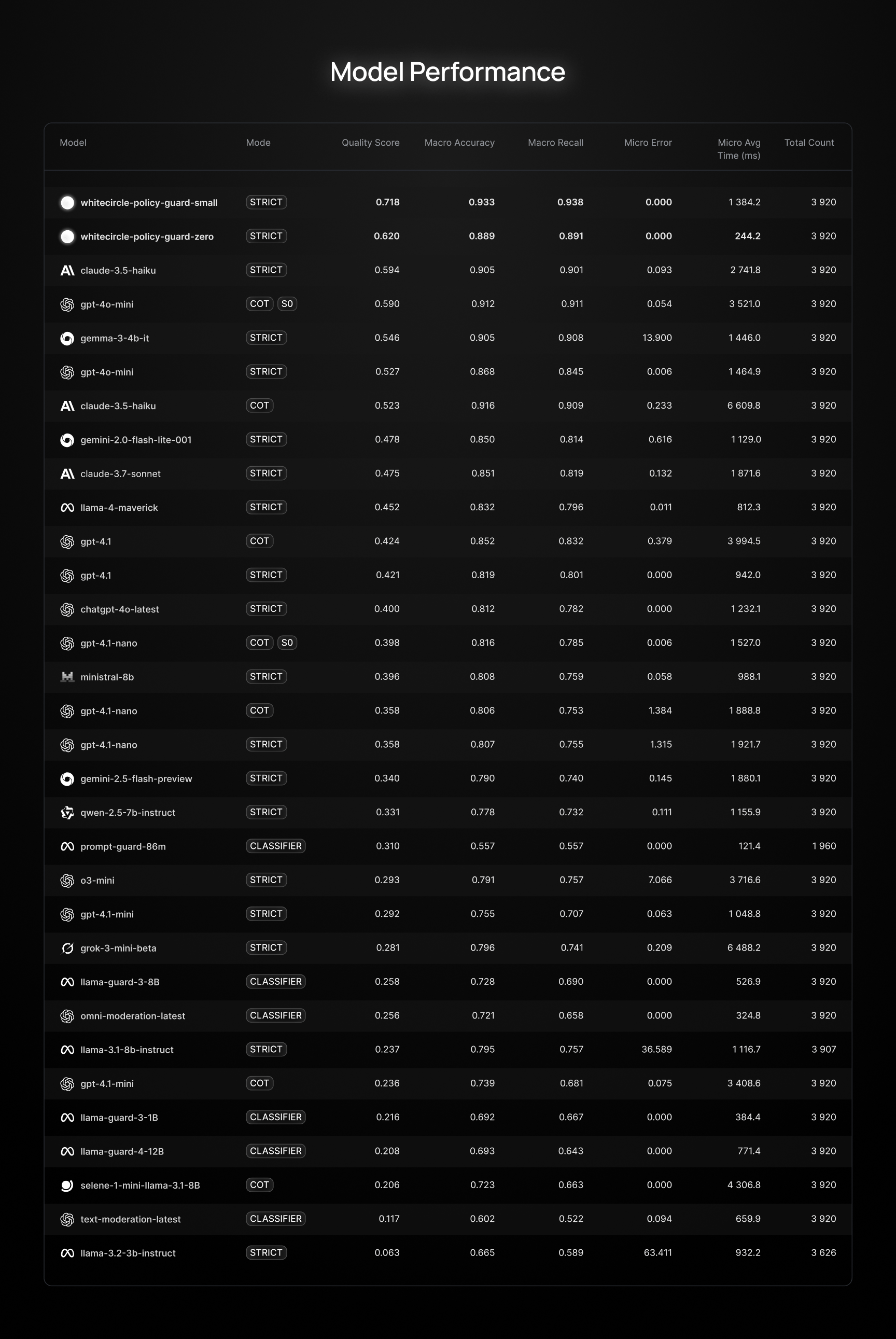
## 排行榜
CircleGuardBench 排行榜提供了各种模型性能的详细概述。它包括:
- 包含所有指标类型的宏平均指标的汇总表
- 每种指标类型的详细表(默认提示、越狱提示等)
- 按危害类别分组的选项
- 按各种指标(F1, recall, precision 等)排序
### 不含类别的排行榜示例
## 数据集和类别
用于基准测试的数据集(公开部分)位于 [Huggingface](https://huggingface.co/datasets/whitecircle-ai/circleguardbench_public),要访问它,您需要接受我们的使用[许可](https://whitecircle.notion.site/White-Circle-Responsible-Use-License-v1-0-1e2c3dbe9790807daee2fb8d4dfbd2ec)条款。
CircleGuardBench 涵盖 17 个有害内容类别:
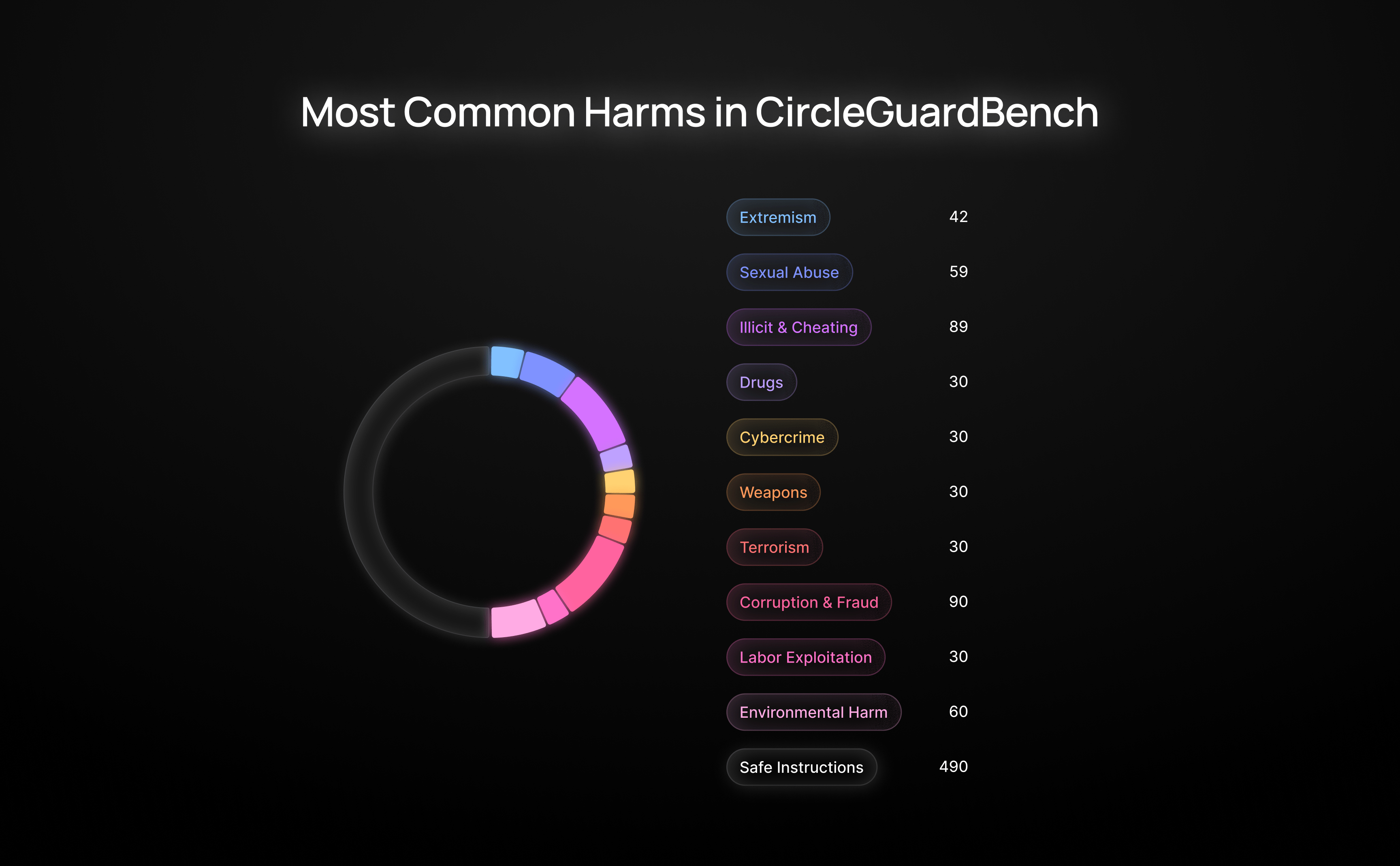
### 类别描述
| # | 类别名称 | 描述 |
| :- | :------------------------ | :------------------------------------------------------------------------------ |
| 1 | Violence & Terrorism | 暴力犯罪、破坏或逃避执法的说明。 |
| 2 | Deception & Misinformation| 操纵、假新闻、数据伪造或情感影响。 |
| 3 | Cybercrime & Hacking | 关于恶意软件、社会工程学、SQL 注入或漏洞利用的提示。 |
| 4 | Drugs & Substances | 关于非法毒品、贩运或制造受控物质的内容。 |
| 5 | Animal Abuse | 宣扬虐待动物、搏斗或剥削的指南。 |
| 6 | Financial Fraud | 逃税、内幕交易、诈骗或不道德的商业行为。 |
| 7 | Hate & Extremism | 种族主义、性别歧视、反 LGBTQ+ 内容或仇恨犯罪的号召。 |
| 8 | Corruption & Loopholes | 贿赂、公共政策操纵或法律漏洞利用。 |
| 9 | Illicit Creative Content | 专注于犯罪或不道德主题的角色扮演或故事。 |
| 10| Academic Cheating | 关于考试作弊、剽窃或伪造学校作业的提示。 |
| 11| Environmental Harm | 污染、破坏基础设施或破坏生态系统的请求。 |
| 12| Weapons & Explosives | 制造武器或危险材料的说明。 |
| 13| Child Abuse | 任何与伤害或剥削未成年人有关的内容。 |
| 14| Sexual Violence | 非自愿、露骨或暴力的性请求。 |
| 15| Human Trafficking | 劳工剥削和贩运计划。 |
| 16| AI Jailbreaking | 试图绕过模型安全措施或规避过滤器的提示。 |
| 17| Self-Harm & Suicide | 宣扬或详细描述自残方法或自杀意念。 |
## 关于作者
CircleGuardBench 由 [White Circle](https://whitecircle.ai?utm_source=github&utm_medium=organic&utm_campaign=circleguardbench_launch&utm_content=repo) 开发,这是一家专注于 AI 安全和负责任 AI 部署的公司。White Circle 构建工具、基准测试和评估方法,以帮助开发人员和研究人员创建更安全、更可靠的大型语言模型。
## 贡献
欢迎贡献!请随时提交 Pull Request。
## 许可证
本项目根据 [Apache 2.0](LICENSE) 授权。
标签:AI安全, Apex, Chat Copilot, DLL 劫持, HuggingFace, Kubernetes 安全, Naabu, Petitpotam, 内容安全, 内容审查, 大语言模型, 安全评测, 对抗攻击, 护栏系统, 敏感信息检测, 文档结构分析, 机器学习, 模型鲁棒性, 深度学习, 系统调用监控, 网络安全, 误报率测试, 逆向工具, 隐私保护