j1sk1ss/CordellCompiler
GitHub: j1sk1ss/CordellCompiler
一个用于学习编译器原理和优化技术的C风格系统编程语言编译器实现
Stars: 6 | Forks: 3

# Cordell 编译器
Cordell Compiler 是一个为 `Cordell Programming Language` 设计的紧凑型爱好级编译器,其灵感来源于 C 的不安全特性和 Rust 的语法。它的首要设计目的是用于学习编译、代码优化、翻译以及底层微码生成。次要目的——这是我的测试平台。
- *本 README 仍在编写中*
# 本项目的主要思想
本项目的主要目标是学习编译器架构,并将其移植到我的另一个项目 `CordellOS` 中(我只是想在 `我的` OS 里面为 `我的` OS 编写应用程序)。此外,考虑到我对 `assembly` 和 `C` 语言的偏好,这种语言将尽可能保持“底层”,但在未来可能会添加一些关于字符串的功能(内置连接、比较等)。
# 概述
本 `README` 文件包含有关该编译器的主要信息,以及我在开发过程中所学到的开发方法。简而言之——本 README 试图将构建同类优化编译器(或更好的编译器)所需的所有有用信息打包在一起。本仓库还包含一个具有类似内容和一些交互式章节的[网站](https://j1sk1ss.github.io/CordellCompiler/#/)。为了您的方便,此处提供了带有快速链接到本文件各主题的 `导航` 区块。
- [引言](#introduction)
- [代码片段](#sample-code-snippet)
- [编译流水线](#compilation-pipeline)
- [PP 阶段](#pp-part)
- [词法分析阶段](#tokenization-part)
- [标记阶段](#markup-part)
- [AST 阶段](#ast-part)
- [AST 优化](#ast-optimization)
- [HIR 阶段](#hir-part)
- [CFG 阶段](#cfg-part)
- [支配者计算](#dominant-calculation)
- [严格支配](#strict-dominance)
- [支配边界](#dominance-frontier)
- [SSA 形式](#ssa-form)
- [Phi 函数](#phi-function)
- [DAG 阶段](#dag-part)
- [HIR 优化](#hir-optimization)
- [常量折叠/传播(第一次遍历)](#constant-folding--propagation-first-pass)
- [死函数消除 (DFE)](#dead-function-elimination-dfe)
- [尾递归消除 (TRE)](#tail-recursion-elimination-tre)
- [函数内联](#function-inlining)
- [循环规范化](#loop-canonicalization)
- [循环不变代码外提 (LICM)](#loop-invariant-code-motion-licm)
- [LIR 阶段](#lir-part)
- [LIR 指令规划](#lir-instruction-planning)
- [LIR (x86_64) 指令选择](#lir-x86_64-instruction-selection)
- [LIR 应用常量传播](#lir-applying-const-propagation)
- [LIR x86_64 示例](#lir-x86_64-example)
- [活性分析器阶段](#liveness-analyzer-part)
- [USE 和 DEF](#use-and-def)
- [IN 和 OUT](#in-and-out)
- [释放点](#point-of-deallocation)
- [寄存器分配阶段](#register-allocation-part)
- [图着色](#graph-coloring)
- [LIR 窥孔优化](#lir-peephole-optimization)
- [PTRN 领域特定语言](#ptrn-domain-specific-language)
- [第一次遍历](#first-pass)
- [第二次遍历](#second-pass)
- [第三次遍历](#third-pass)
- [代码生成 (nasm) 阶段](#codegen-nasm-part)
- [生成代码示例](#example-of-generated-code)
## 引言
本编译器与语言本身、复杂的语法和抽象无关(CPL 甚至不支持结构体)。我主要是想实现现代的代码优化方法,观察输入代码如何转化为具有 `更优性能` 的版本,并测试一些想法,例如神经网络的应用或符号表的压缩。本 `README` 描述了我到目前为止所做的工作。
简述上述语言:CPL 拥有 `EBNF 定义` [[?]](https://en.wikipedia.org/wiki/Extended_Backus%E2%80%93Naur_form) 的语法,其专属的 [VS Code 扩展](https://github.com/j1sk1ss/CordellCompiler/tree/HIR_LIR_SSA/vscode),以及简短的[文档](j1sk1ss.github.io/CordellCompiler/)。这与本 README 并无直接关联,如果您对 CPL 本身而非其编译器更感兴趣,请查阅相关文献站点。
P.S.:*我已经说过该语言不会在 README 中详述,但在解释编译器的每一层时,我也会提供用该语言编写的直接示例(其语法与 C 语言几乎相同,这意味着它不会引起任何阅读障碍)。*
## 示例代码片段
让我们从下面的简单代码片段(在折叠区中)开始介绍。它演示了 `CPL` 语言的主要功能和形式,但不包括已支持的功能,如 `while` 循环、`syscalls`、条件运算符等(我们将在稍后讨论它们的工作原理)。
基本上,每一次编译或解释都始于原始代码。同样,原始代码的示例可以在下面找到。这是一个经典的 "Hello world" 程序,在本 README 的最后,我们将为我的个人 Mac15Pro 2012 (MacOS Catalina) 编译它。
P.S.:*上面的代码将作为本 README 中某些章节的示例,这就是为什么我强烈建议您展开并查看这些折叠的内容。*
## 编译流水线
## AST 阶段
接下来,我们需要解析这一系列带标记的 token,以构建 `AST`(抽象语法树)结构。有许多方法可以实现这一点——例如,`LL` 解析、`LR` 解析,甚至是结合 `LL` 和 `LR` 的 `hybrid`(混合)技术。更完整的解析器类型列表可以在[[这里]](https://www.geeksforgeeks.org/compiler-design/types-of-parsers-in-compiler-design/)或相关的编译器设计书籍中找到(参见[使用的链接和文献](#used-links-and-literature)部分)。本编译器使用的是 `LL` 方法。
此时,我们可以直接进入代码生成阶段或中间表示阶段。该编译器不允许跳过带有 IR 生成的必要阶段,这意味着编译器使用了第二种方法。
### AST 优化
当我们获得了输入代码的正确 `AST` 表示后,我们可以选择性地执行一些可用的优化。我们不会在这里花费大量时间,仅涵盖几个示例。请注意,`AST 级别` 的优化在本项目中大多是多余的(当本编译器还没有 `IR` 层时,它们曾非常有用)。
- `条件展开`。如果我们有一个带有常量条件的 `if` 语句,例如 `if 1; { ... }`,或者 `while` 关键字或 `switch` 语句的类似情况,我们可以通过移除条件并仅保留主体来展开它们。
- `死作用域消除`。如果一个作用域不影响环境,则可以安全地将其移除。
为了理解它们的实际作用,我们可以考虑以下 `DSE`(死作用域消除)的示例:
```
start() {
{
i32 a = 10;
a += 10 * 10 - 11;
}
exit 1;
}
```
根据编译器的标记阶段逻辑,`exit` 语句看不到(也不可能看到)变量 `a`。此外,该作用域对环境没有影响(它不调用任何东西,不改变任何东西,不返回也不退出),这意味着我们可以在 AST 层级安全地移除它。
P.S.:*我保留这些优化是因为它们并没有复制 HIR 或 LIR 层级中已有的优化。旧版本的编译器拥有更多的 AST 级别优化,如果您感兴趣,可以在 GitHub 上查看标签 v2.0 和 v1.0。*
## HIR 阶段
考虑到未来的优化阶段,输入代码的 `AST` 表示必须被展平。这里的一种常见方法是将 `AST` 结构转换为 `三地址码` (3AC) 列表 [[?]](https://web.stanford.edu/class/archive/cs/cs143/cs143.1128/lectures/13/Slides13.pdf)。
*三地址码*意味着每条指令中只有三个地址占位符。例如,`a += b` 命令可以转换为 `3AC`,即 `a = a + b`。此外,简单的索引命令 `a[x] = 0` 将被转换为:
```
tmp_head = &a;
tmp_off = x * sizeof(typeof(a));
tmp_head = tmp_head + tmp_off;
*tmp_head = 0;
```
图 5 展示了本编译器中 `AST -> HIR` 过程的示意图。
P.S.:*您可能已经注意到函数名被更新了 (_main)。这是 'start' 函数的 '虚拟' 名称。在重载和不同架构方面,虚拟名称是必不可少的东西。我们稍后将讨论它们,但此时,您只需记住用户的名称会链接到它们的虚拟名称即可。*
## CFG 阶段
在获得完整的 `3AC` 指令列表后,我们几乎可以立即进入 `CFG`(控制流图)[[?]](https://en.wikipedia.org/wiki/Control-flow_graph) [[?]](https://www.geeksforgeeks.org/software-engineering/software-engineering-control-flow-graph-cfg/) 的生成阶段。有几种方法可以将 `3AC` 划分为基本块,其中一种是使用 `leaders`(领导者),另一种是为每条命令创建一个块。第二种方法很直接——每个 `3AC` 指令都成为其独立的块。*Dragon Book*(《编译原理》)中描述的 `leaders` 方法定义了识别块起始位置的三条规则- 函数中的第一条指令。
- JMP 指令的目标。
- 紧跟在 JMP 之后的指令。
P.S.:*在本编译器中,这两种方法都已实现,但在示例中,我们将使用 Dragon Book 中的方法*
## 支配者计算
有了结构化的 `CFG`,我们就可以进入 `SSA` 形式 [[?]](https://en.wikipedia.org/wiki/Static_single-assignment_form) [[?]](https://www.geeksforgeeks.org/compiler-design/static-single-assignment-with-relevant-examples/) [[?]](https://dl.acm.org/doi/10.1145/75277.75280) 阶段了。首先,我们需要计算 `CFG` 中每个块的支配者 [[?]](https://en.wikipedia.org/wiki/Dominator_(graph_theory))。简而言之,块 `Y` 的支配者是出现在从起始块到 `Y` 的每条路径上的块 `X`。例如,图 7 说明了这是如何工作的。
## HIR 优化
在进一步深入之前,我们应该利用这一层级可用的元信息来优化我们的 HIR。由于 `DAG` 的存在,这里最简单的优化是 `constant fold`(常量折叠)优化。`DFE` 优化也是同样的情况。让我们来谈谈这些方法。
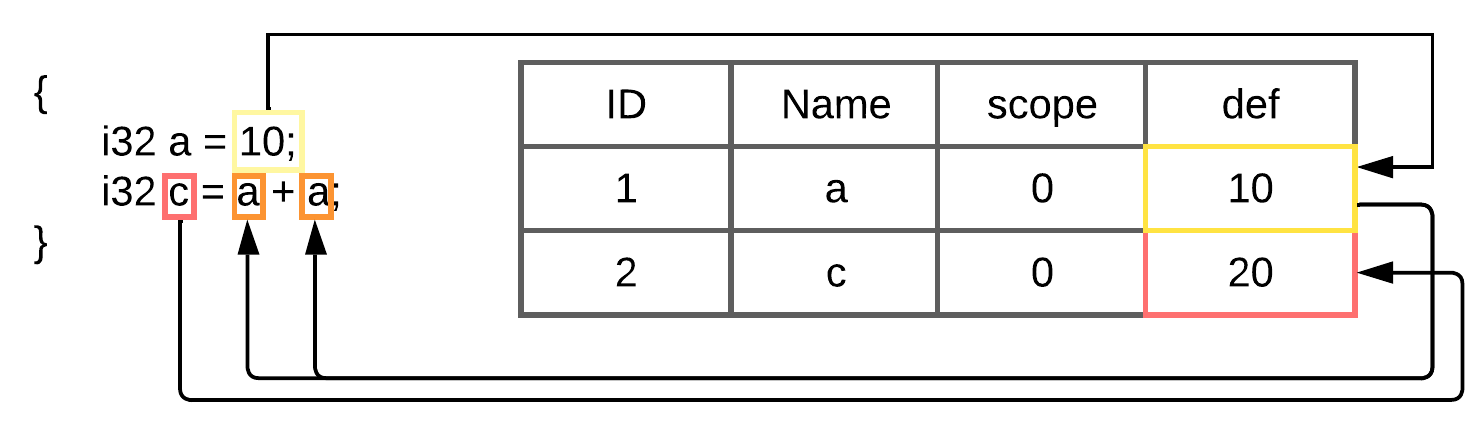
### 常量折叠 / 传播(第一次遍历)
通过构建好的 `DAG`,我们可以知道每个变量被赋予了什么值。在这个阶段我们不会转换代码,我们只会在符号表中定义变量的值。此外,我们还跟踪算术运算,因此我们可以对符号表中已经定义的变量执行简单的操作。
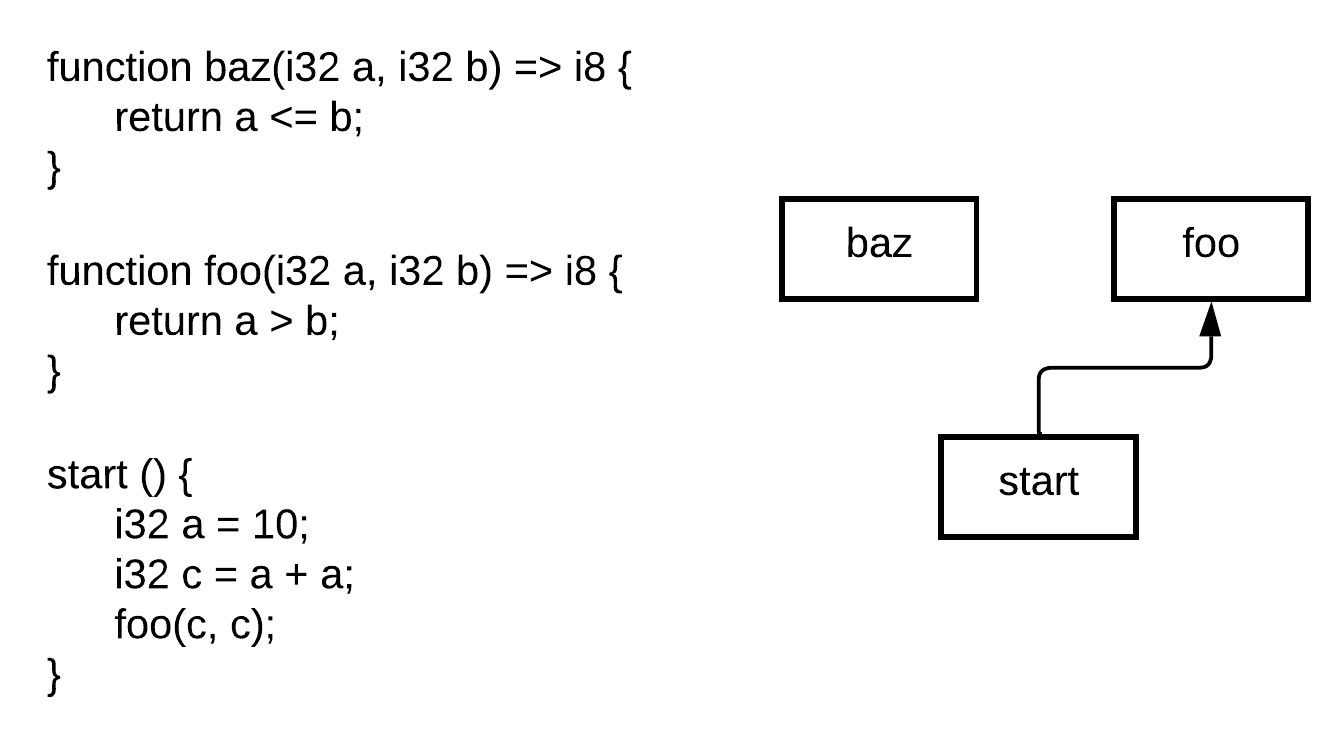
### 死函数消除 (DFE)
死函数消除与 `HIR` 常量折叠类似,不会转换源代码。此优化并不转换代码,而是将所有未使用的函数标记为未使用。这种方法基于 `Call Graph`(调用图),如下所示。
### 尾递归消除 (TRE)
尾递归消除(基于 CFG)会找出所有在末尾发生自调用的函数。最简单的例子如下:
```
function foo(i32 a = 10) -> i8 {
if a > 20; { return a; }
return foo(a + 1);
}
```
当我们找到这样的函数时,我们会判断它是否准备好进行 `TRE`。然后我们将其转换为循环:
```
function foo(i32 a = 10) -> i8 {
lbX:
if a > 20; { return a; }
a += 1;
goto lbX;
}
```
这种优化使我们免于栈帧分配,这种分配的代价很高,尤其是在递归频繁发生的情况下。
### 函数内联
当函数调用获得 3 分或以上的启发式得分时,就会发生函数内联。什么是启发式得分?每个函数调用都会根据以下参数进行评估:
- 函数调用是否在循环中? `+2`
- 以下之一:
- 函数大小(以 BaseBlocks 计)是否小于 2? `+3`
- 函数大小(以 BaseBlocks 计)是否小于 5? `+2`
- 函数大小(以 BaseBlocks 计)是否小于 10? `+1`
- 函数大小(以 BaseBlocks 计)是否大于 15? `-3`
当函数调用被标记为 `inline candidate`(内联候选)时,编译器只需复制函数体中的所有内容,替换参数赋值和返回语句:
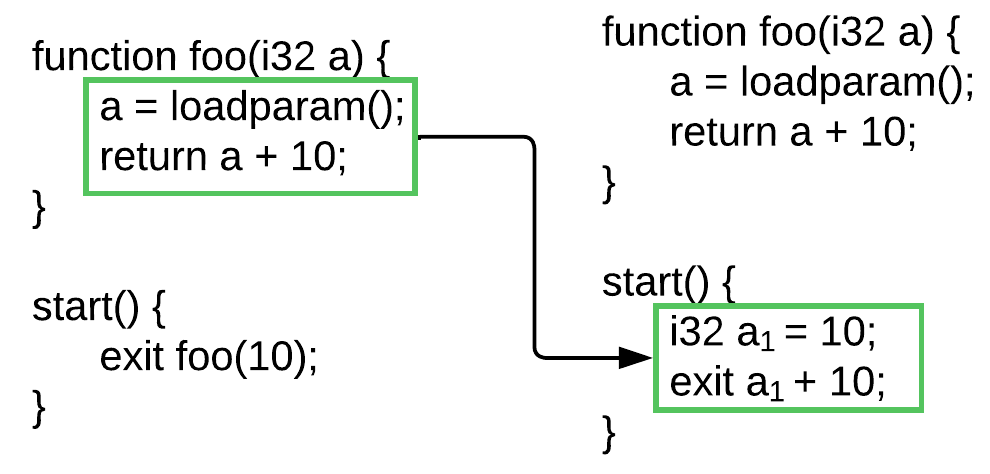
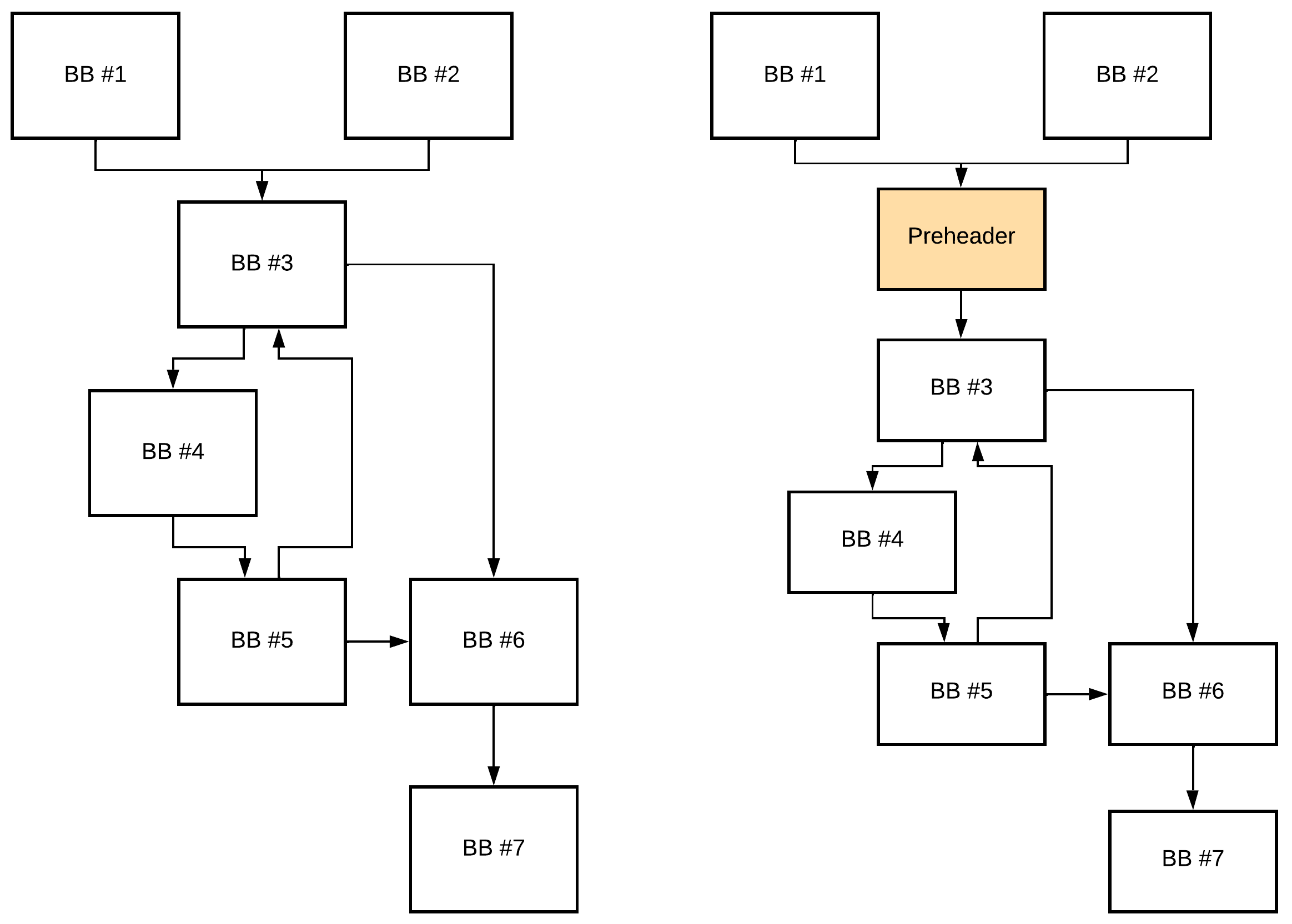
### 循环规范化
循环规范化是 LICM 优化之前的重要步骤。此阶段的主要思想是在循环中创建一个入口和出口点。让我们考虑下面的 `CFG`:
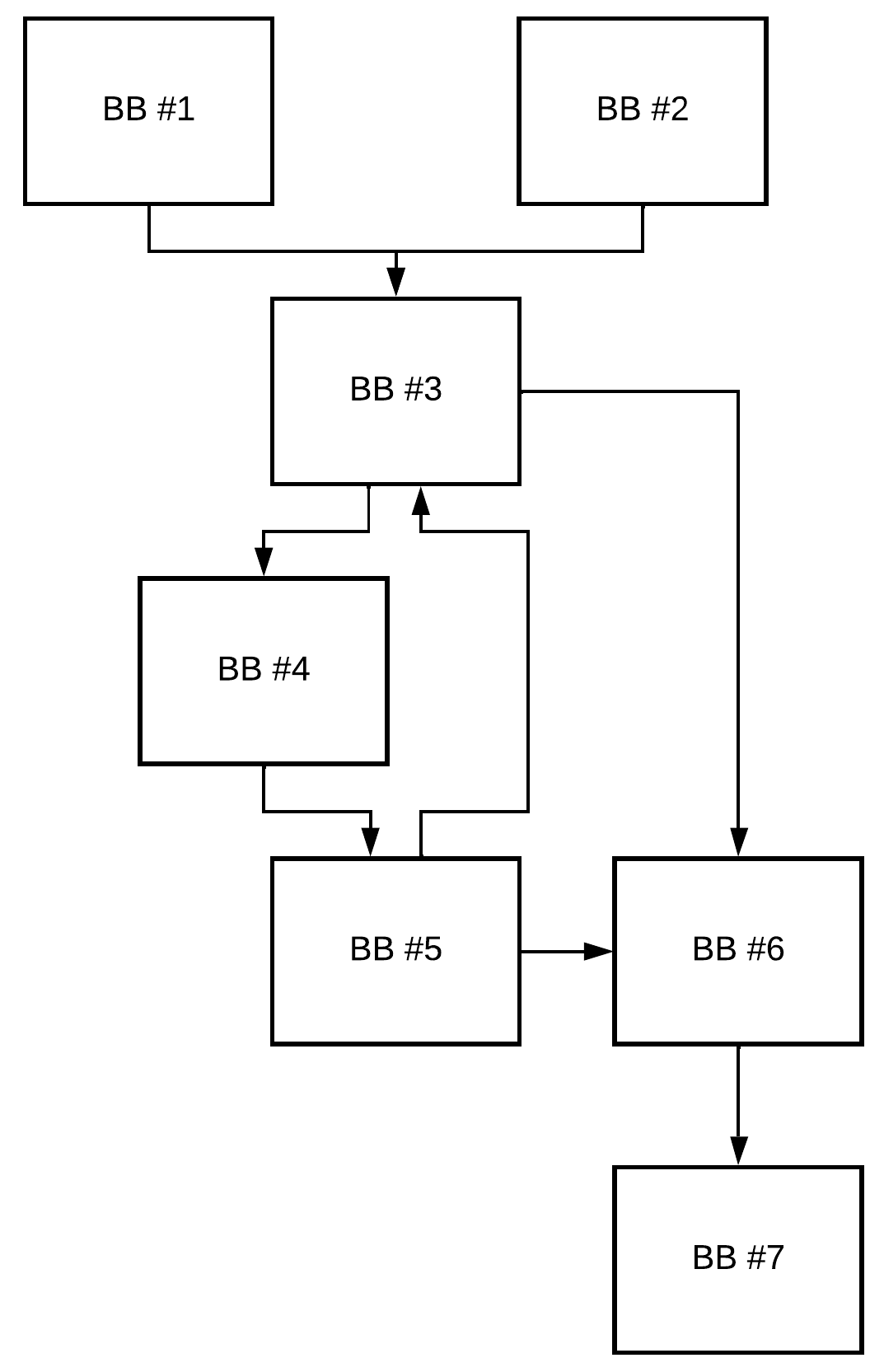
这里的主要问题是,我们在 `BB1` 到 `BB3` 之间存在 `critical edge`(关键边),这阻碍了我们将一些冗余代码移出循环。为了解决这个问题,我们可以简单地创建一个 `preheader`(前置头)基本块:
### 循环不变代码外提 (LICM)
哪些 `HIR` 操作我们可以安全地从循环中移出?
- 那些不使用归纳变量的操作
- 那些不使用循环变量的操作
## LIR 阶段
与生成 `HIR` 时一样,我们现在生成一种类似于 `3AC` 的中间表示——但只使用两个地址。这一步相对简单,因为它主要涉及使指令适应目标机器的寻址模型。因为具体的实现在很大程度上取决于目标架构(寄存器数量、指令集、寻址模式等),所以我们通常不会在此层级花费大量时间进行优化或泛化。它的主要目的仅仅是桥接高级的 `HIR` 表示和特定于目标的汇编形式,确保每条指令都可以直接翻译为有效的机器指令。
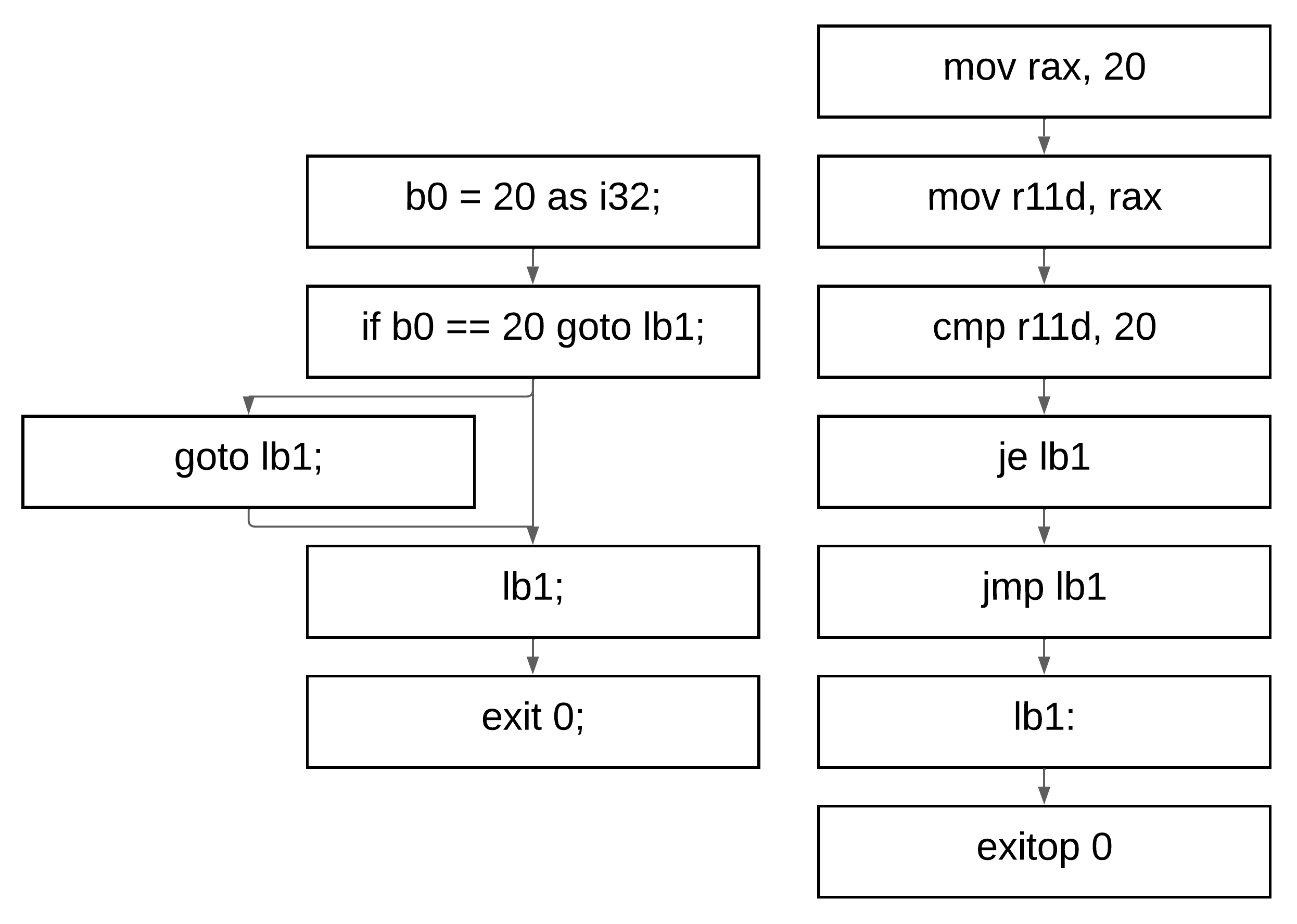
## LIR 指令规划
## LIR (x86_64) 指令选择
## LIR 应用常量传播
## 活性分析器阶段
几种优化技术是基于数据流分析的。数据流分析本身依赖于活性分析,而活性分析又依赖于程序的 `SSA` 形式和控制流图 (CFG)。现在我们已经建立了这些基础表示,我们可以继续进行 `USE–DEF–IN–OUT` 的计算过程。
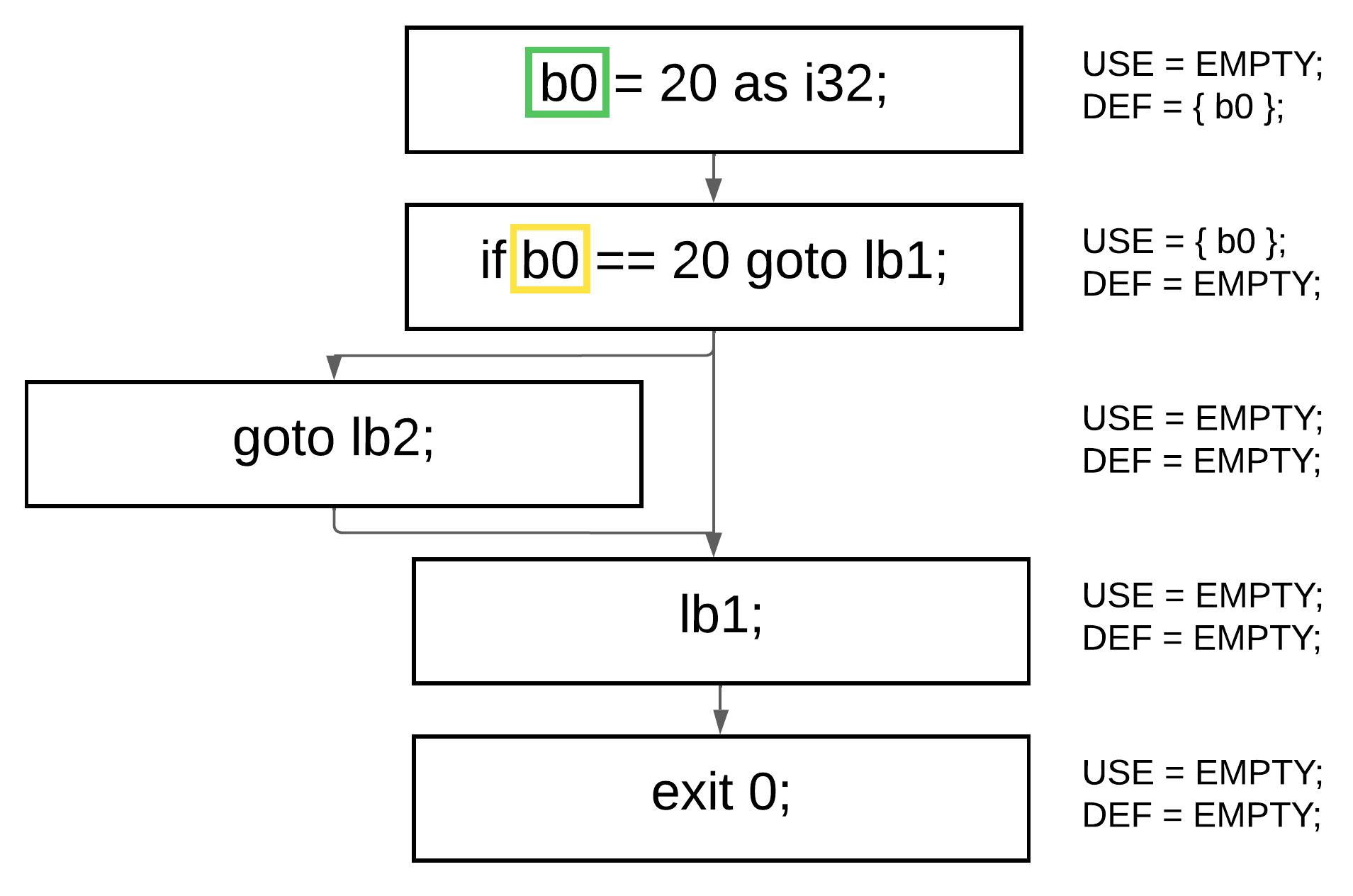
### USE 和 DEF
`USE` 和 `DEF` 是与每个 `CFG` 块相关联的两个集合。这些集合表示块内变量的所有定义和使用(回想一下,代码已经处于 `SSA` 形式)。简而言之:
- `DEF` 包含所有被写入(即被赋予新值)的变量。
- `USE` 包含所有被读取(即使用了其值)的变量。
### IN 和 OUT
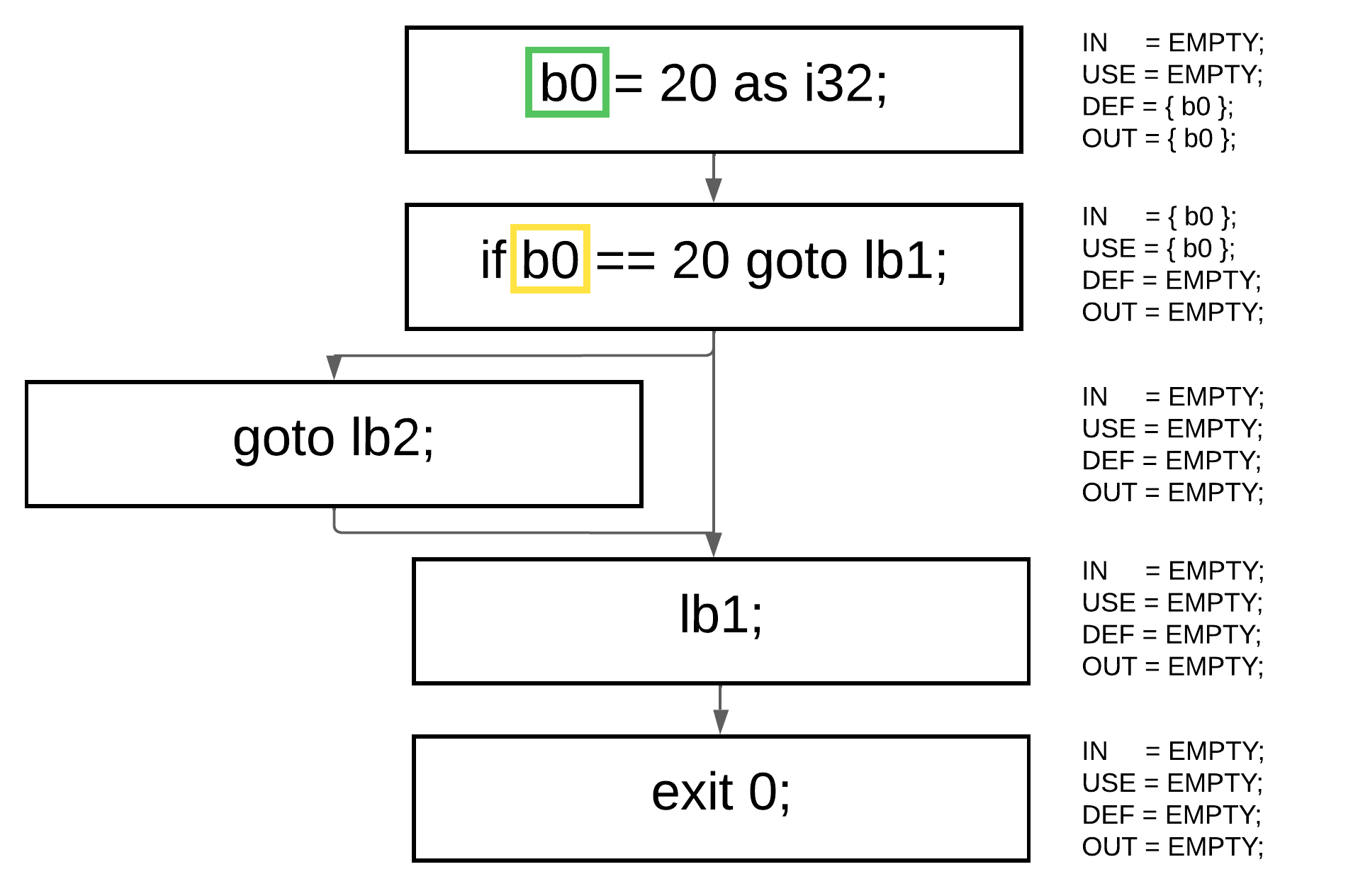
`IN` 和 `OUT` 是这里稍微复杂的部分。
```
OUT[B] = union(IN[S])
IN[B] = union(USE[B], OUT[B] − DEF[B])
```
首先,为了使计算快得多,我们应该以逆序遍历我们的 `CFG` 块列表,使用上面的公式计算每个块的 `IN` 和 `OUT`,并重复此过程直到它稳定。当先前的集合(`primeIN` 和 `primeOUT`)等于当前集合(`currIN` 和 `currOUT`)时,即达到了稳定。这意味着对于每个块,我们应该维护四个集合:
- primeIN
- currIN
- primeOUT
- currOUT
在每次迭代之后,当前值被复制到相应的 prime 集合中,为下一个比较周期做准备。
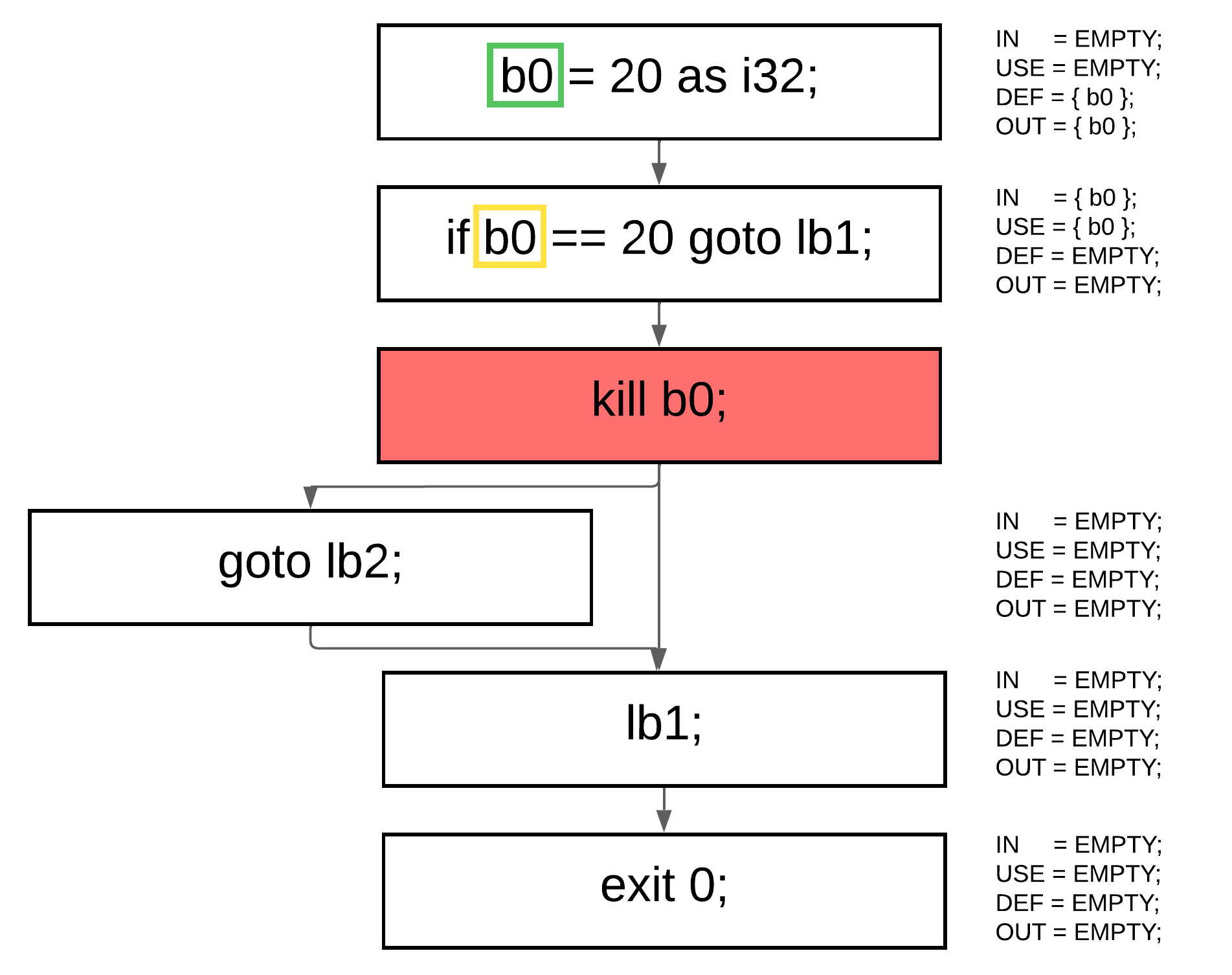
### 释放点
此时,我们可以确定每个变量在哪里死亡。如果一个变量出现在 `IN` 或 `DEF` 集合中,但不存在于 `OUT` 集合中,这意味着该变量在此块之后不再使用,我们可以安全地插入一个特殊的 `kill` 指令将其标记为死亡。然而,在处理指针类型时会出现一个重要的细节。为了正确处理它们,我们构建了一个称为 `aliasmap` 的特殊结构,它跟踪变量之间的所有权关系。该映射记录了哪个变量拥有另一个变量——这意味着一个变量的生命周期依赖于另一个变量。例如,在如下代码中:
```
{
i32 a0 = 10;
ptr i32 b0 = ref a0;
dref b0 = 20;
}
```
变量 `a` 归 `b` 所有,因此在 `b` 仍然存活时,我们绝不能杀死 `a`。换言之,`a` 的活性取决于 `b` 的活性,这种依赖关系通过别名映射得以保留。
## 寄存器分配阶段
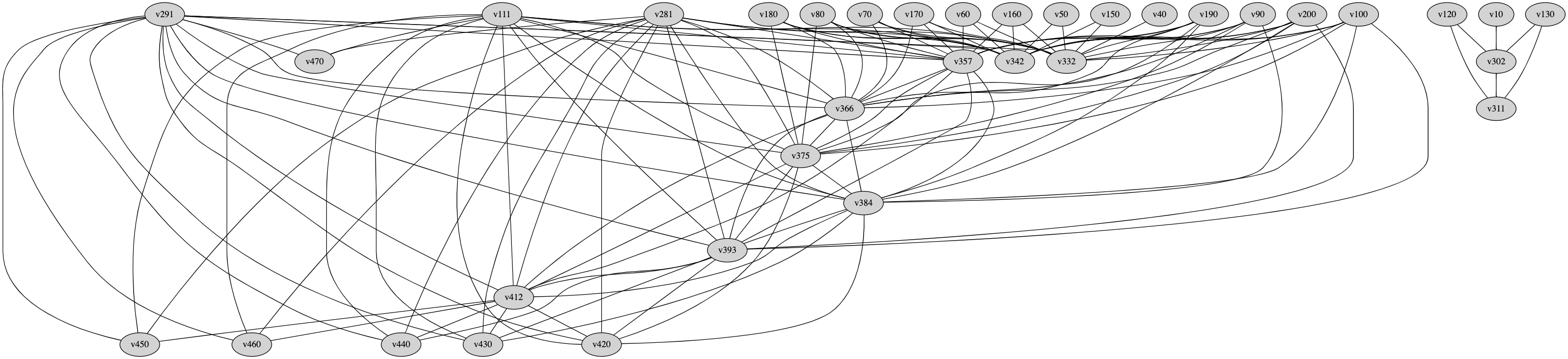
现在我们有了 `IN`、`OUT`、`DEF` 和 `USE` 集合,我们可以构建一个干涉图。其思想很简单:我们为符号表中的每个变量创建一个顶点,然后对于每个 `CFG` 块,我们将该块的 `DEF` 集合中的每个变量与其 `OUT` 集合中的每个变量连接起来(即,在它们之间添加一条边)。这种连接表示这两个变量同时存活。最终的结构就是干涉图,其中:
- 顶点代表程序变量。
- 边代表变量之间的活性冲突(干涉)。
### 图着色
现在我们可以通过图着色来确定哪些变量可以共享同一个寄存器。这个问题的解决方案纯粹是数学上的,并且有许多可能的策略来给图着色。简而言之,目标是为每个节点(变量)分配一种颜色,使得没有两个相连的节点共享相同的颜色。该算法的输出是一个着色的干涉图,其中每种颜色代表一个不同的物理寄存器,并且所有具有相同颜色的变量可以安全地复用同一个寄存器而不会出现生命周期重叠。

## LIR 窥孔优化
窥孔优化 [[?]](https://www.geeksforgeeks.org/compiler-design/peephole-optimization-in-compiler-design/) 是最简单也是最具影响力的优化之一(至少在本编译器中是如此)。简而言之,这种优化只是像正则表达式那样进行模式匹配和替换。它在汇编代码 / LIR 表示中寻找低效的模式,并将其替换为高效的同义形式。
这里最简单的例子是用高效的命令替换低效的命令:
```
; mox rax, 0
xor rax, rax
```
### PTRN 领域特定语言
如前所述,窥孔优化主要基于模式。这里的问题在于,针对汇编语言优化的现有模式非常多。如果试图用 C 语言手工实现这些模式(考虑到 CordellCompiler 的 LIR 支持的必要性),那将是非常不方便的。
为了解决这个问题,我们可以使用产生此类优化器以用于 LIR 表示的 DSL 语言。有关此 DSL 的更多信息,请参见[此](src/lir/peephole/pattern_generator/README.md) README 文件。
### 第一次遍历
窥孔优化器的第一次遍历是模式匹配器遍历。此遍历涉及到前面提到的生成的模式匹配器函数。
### 第二次遍历
第二次遍历会传播值以消除一系列复杂的冗余 mov 操作。在这里,我将以下命令序列视为复杂的冗余 mov 序列:
```
mov rax, rbx
mov rdx, rax
mov rcx, rdx
mov r10, rcx
mov r11, r10
mov rax, r10
```
这种奇怪的代码是在 HIR 和 LIR 优化之后生成的。在第二次遍历之后,上面的代码被转换为以下代码:
```
mov rax, rbx
mov rdx, rbx
mov rcx, rbx
mov r10, rbx
mov r11, rbx
mov rax, rbx
```
### 第三次遍历
现在,当我们获得了代码的优化版本后,我们需要对其进行清理。为了完成此任务,我们可以简单地使用 CFG 并检查当前行中所考虑的寄存器(例如,让我们以 `mov rax, rbx` 这一行为例)是否被用于读取操作,如果被使用了,就跳过它。否则,如果它在某处被用于写入操作(在任何读取操作之前),我们就可以安全地删除这一行。
正如我们所见,经过第二次遍历后,`rax` 寄存器仅在代码片段末尾的写入操作中被使用。这表明我们可以安全地删除这一行。
```
; mov rax, rbx [dropped]
mov rdx, rbx
mov rcx, rbx
mov r10, rbx
mov r11, rbx
mov rax, rbx
```
此外,如果寄存器不影响程序环境(例如,未用于 syscall、函数调用等),它也可以被安全地标记为 `dropped`(丢弃):
```
; mov rax, rbx [dropped]
; mov rdx, rbx [dropped]
; mov rcx, rbx [dropped]
; mov r10, rbx [dropped]
; mov r11, rbx [dropped]
; mov rax, rbx [dropped]
```
P.S. 不过,这是一个非常符合人为设想的例子。
## LIR x86_64 指令选择
下一步是 LIR 降低。这里最常见的方法是指令选择。这是编译器中第一个依赖于具体机器的步骤,因此这里我们针对不同的 asm 方言(例如 nasm x86_64 gnu、at&at x86_64 gnu 等)提供了一些抽象和实现。
您可能已经注意到,我们在这里也应用了寄存器分配。我们一直等到这个阶段的原因是 `pre-coloring`(预着色)。其主要思想是,我们用已知的寄存器(例如算术运算中的 `rax` 和 `rbx`,ABI 函数调用中的 `rdi`、`rsi` 等)对某些变量进行预着色。
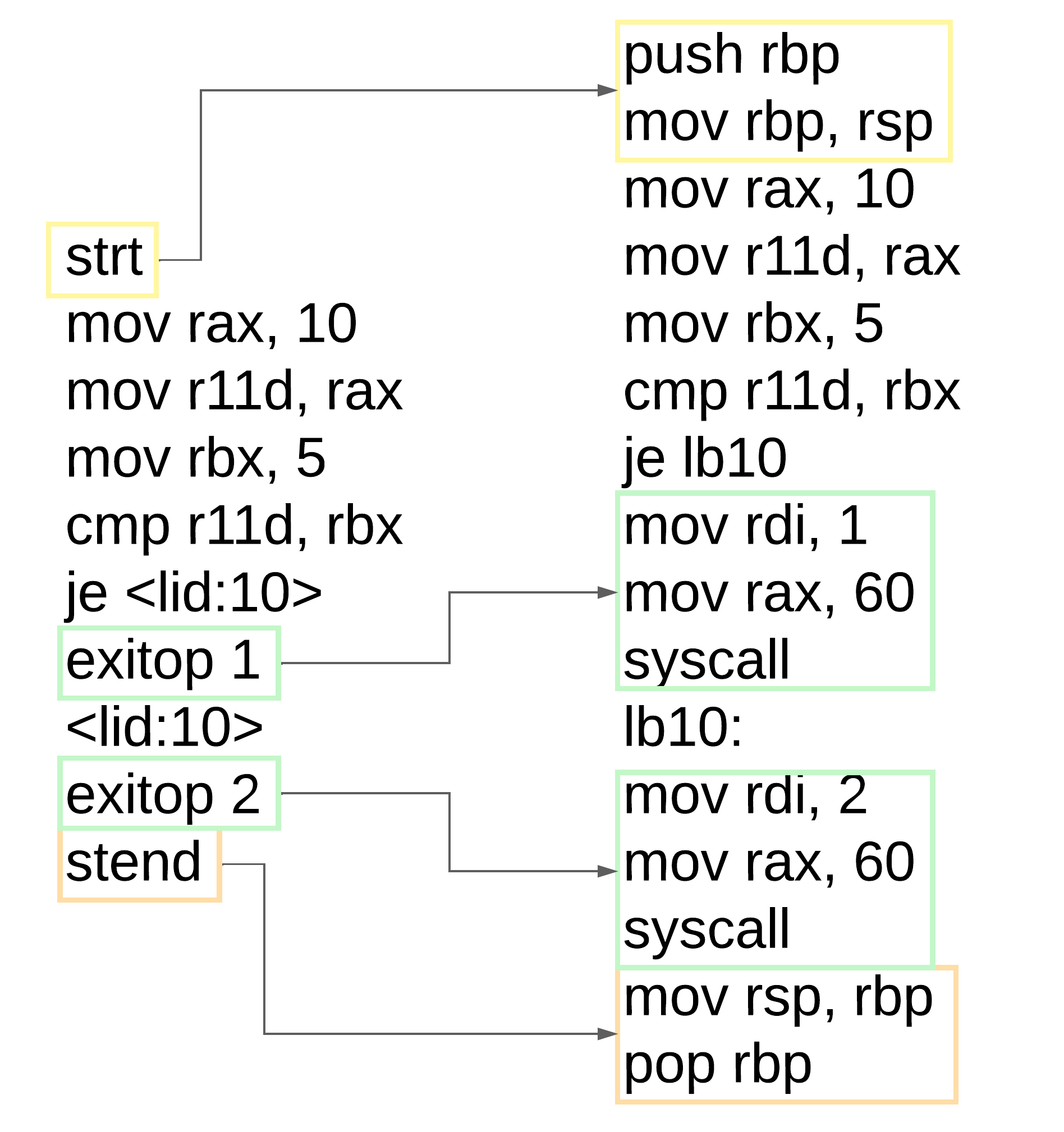
## 代码生成 阶段
完成完整的代码转换流水线后,我们可以安全地将我们的 `LIR` 形式转换为 `ASM` 形式,并在展开特殊 `LIR` 指令(如 `EXITOP`、`STRT` 等)的过程中应用一些小技巧。
# 使用的链接和文献
- Aarne Ranta. *Implementing Programming Languages. An Introduction to Compilers and Interpreters*
- Aho, Lam, Sethi, Ullman. *Compilers: Principles, Techniques, and Tools (Dragon Book)*
- Andrew W. Appel. *Modern Compiler Implementation in C (Tiger Book)*
- Cytron et al. *Efficiently Computing Static Single Assignment Form and the Control Dependence Graph* (1991)
- Daniel Kusswurm. *Modern x86 Assembly Language Programming. Covers x86 64-bit, AVX, AVX2 and AVX-512. Third Edition*
- Jason Robert, Carey Patterson. *Basic Instruction Scheduling (and Software Pipelining)* (2001)
基本的 "Hello World" 程序
``` #include "print_h.cpl" @[entry("_main")] function main(i32 argc, ptr ptr i8 argv) { str msg = "Hello world!"; print(ref msg); exit 0; } ```

Figure 1 — Compiler pipeline
Figure 2 — Basic token generation
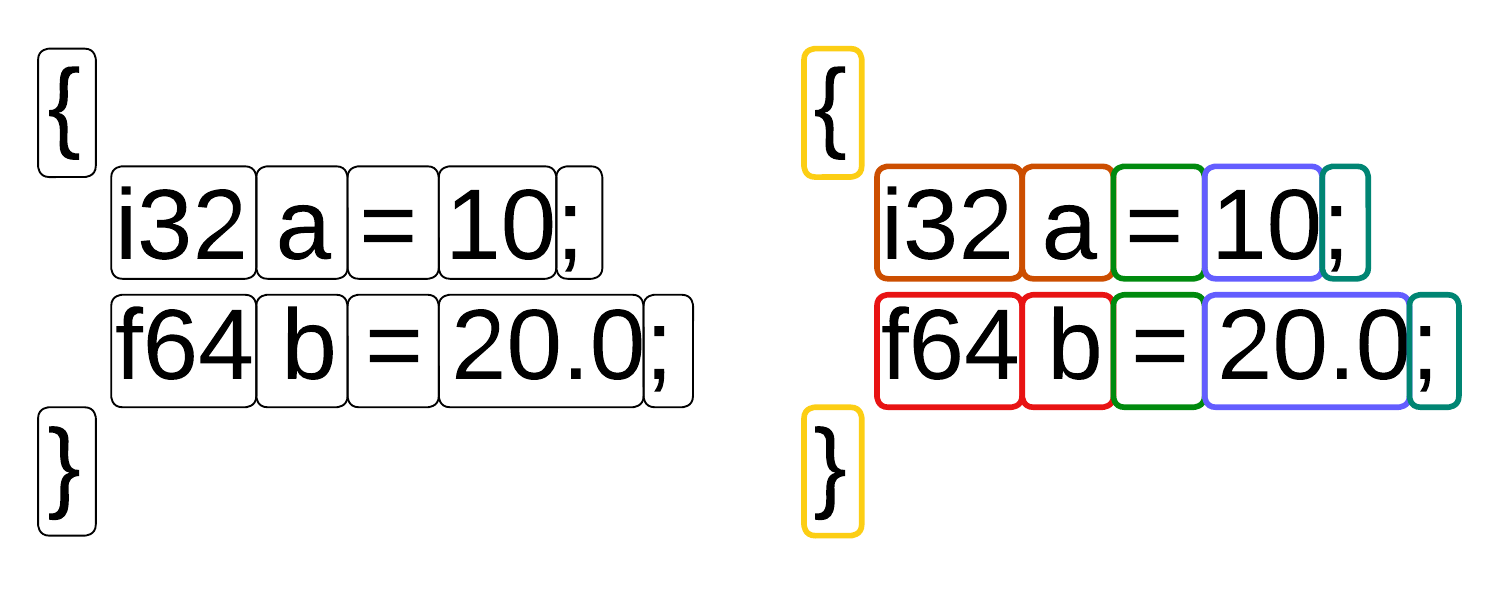
Figure 3 — Token markup
Token 列表
``` line=1, type=17, data=[{], line=3, type=1, data=[code_utesting/prep/print_h.cpl], line=3, type=1, data=[/Users/nikolaj/Documents/Repositories/CordellCompiler/tests/code_utesting/prep/string_h.cpl], line=3, type=65, data=[function], line=3, type=66, data=[strlen], line=3, type=15, data=[(], line=3, type=44, data=[i8], ptr line=3, type=108, data=[s], ptr line=3, type=16, data=[)], line=3, type=58, data=[->], line=3, type=41, data=[i64], line=3, type=9, data=[;], line=7, type=1, data=[code_utesting/prep/print_h.cpl], line=7, type=65, data=[function], line=7, type=66, data=[print], line=7, type=15, data=[(], line=7, type=49, data=[str], ptr line=7, type=108, data=[msg], ptr line=7, type=16, data=[)], line=7, type=58, data=[->], line=7, type=38, data=[i0], line=7, type=9, data=[;], line=11, type=1, data=[/private/var/folders/74/d7gcqwxd1x9__83fh6m_lb6c0000gn/T/tmpmx4fkhq_.cpl], line=4, type=55, data=[start], line=4, type=15, data=[(], line=4, type=41, data=[i64], line=4, type=108, data=[argc], line=4, type=10, data=[,], line=4, type=45, data=[u64], ptr line=4, type=108, data=[argv], ptr line=4, type=16, data=[)], line=4, type=17, data=[{], line=5, type=49, data=[str], line=5, type=108, data=[msg], line=5, type=94, data=[=], line=5, type=122, data=[Hello world!], line=5, type=9, data=[;], line=6, type=67, data=[print], line=6, type=15, data=[(], line=6, type=20, data=[ref], line=6, type=108, data=[msg], line=6, type=16, data=[)], line=6, type=9, data=[;], line=7, type=57, data=[exit], line=7, type=5, data=[0], line=7, type=9, data=[;], line=8, type=18, data=[}], line=9, type=18, data=[}], ```
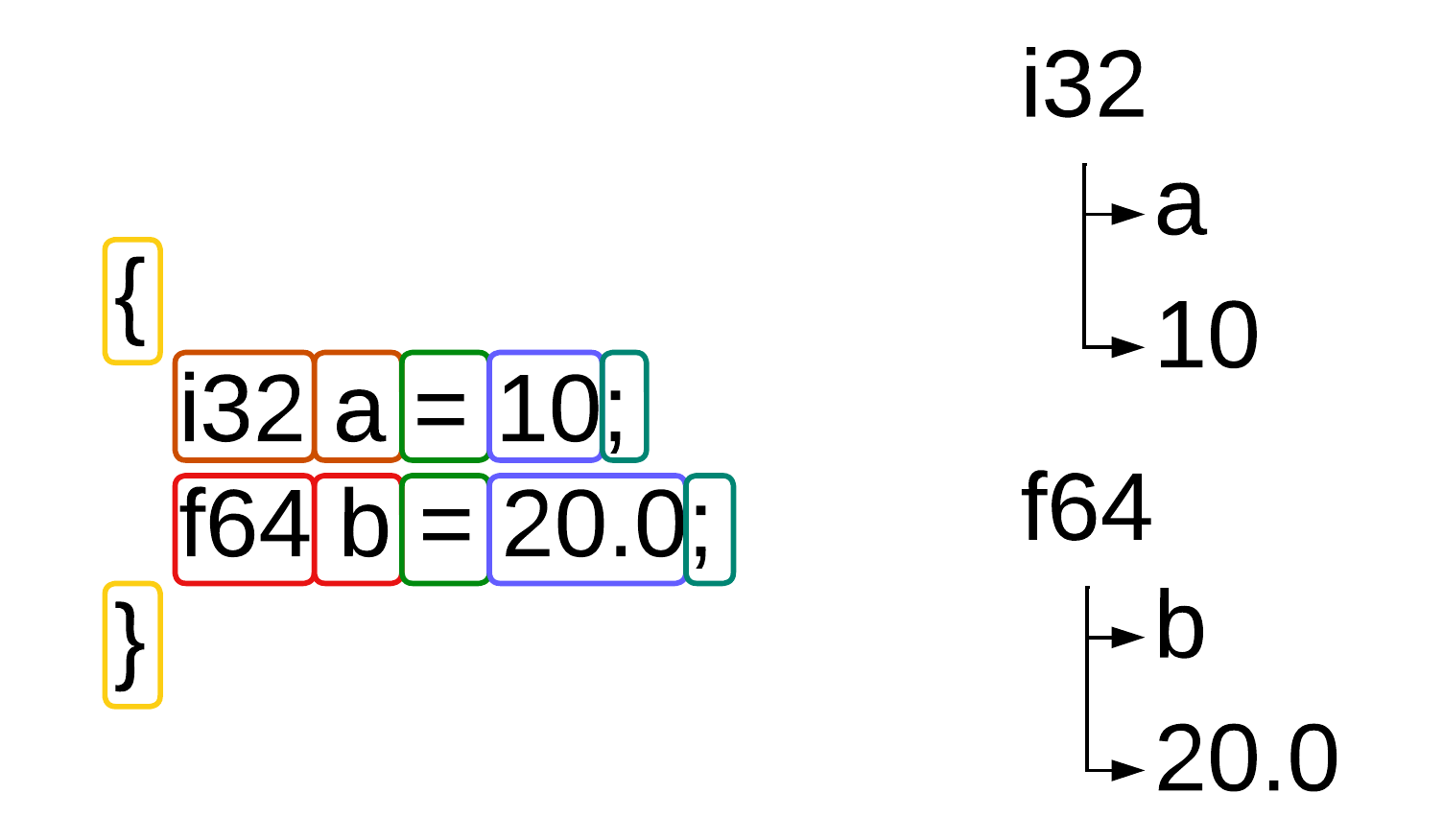
Figure 4 — Basic AST generation
Cordell Compiler 的 AST 转储
``` { scope, id=0 } { scope, id=1 } [function] (t=55, v_id=-1, s_id=0) [strlen] (t=56, v_id=0, s_id=0) [i64] (t=34, v_id=-1, s_id=0) { scope, id=2 } [i8] (t=37, ptr, v_id=-1, s_id=0) [s] (t=92, ptr, v_id=0, s_id=2) { scope, id=3 } [i64] (t=34, v_id=-1, s_id=0) [l] (t=89, v_id=1, s_id=3) [0] (t=3, v_id=-1, s_id=0, glob) [while] (t=61, v_id=0, s_id=3) [s] (t=92, ptr, dref, v_id=0, s_id=2) { scope, id=4 } [+=] (t=69, v_id=-1, s_id=0) [s] (t=92, ptr, v_id=0, s_id=2) [1] (t=3, v_id=-1, s_id=0, glob) [+=] (t=69, v_id=-1, s_id=0) [l] (t=89, v_id=1, s_id=3) [1] (t=3, v_id=-1, s_id=0, glob) [return] (t=48, v_id=0, s_id=3) [l] (t=89, v_id=1, s_id=3) [start] (t=47, v_id=1, s_id=0) [i64] (t=34, v_id=-1, s_id=0) [argc] (t=89, v_id=2, s_id=1) [u64] (t=38, ptr, v_id=-1, s_id=0) [argv] (t=93, ptr, v_id=3, s_id=1) { scope, id=0 } { scope, id=5 } [str] (t=42, v_id=-1, s_id=0) [msg] (t=97, v_id=4, s_id=5) [Hello world!] (t=99, v_id=0, s_id=0, glob) [syscall] (t=53, v_id=-1, s_id=0) [0] (t=3, v_id=-1, s_id=0, glob) [1] (t=3, v_id=-1, s_id=0, glob) [msg] (t=97, ref, v_id=4, s_id=5) [strlen] (t=57, v_id=0, s_id=0) [msg] (t=97, ref, v_id=4, s_id=5) [exit] (t=49, v_id=0, s_id=5) [0] (t=3, v_id=-1, s_id=0, glob) ```

Figure 5 — AST to HIR
Cordell Compiler 的 HIR 转储
``` { fn _main(i32 argc, i8** argv) { i32s %2 = alloc; i32s %2 = load_starg(); i8s** %3 = alloc; i8s** %3 = load_starg(); { strs %4 = str_alloc(Hello world!); i8t* %5 = &(strs %4); use i8t* %5; call print1(str* msg) -> i0, argc args(i8t* %5,); exit num? 0; } } } ```
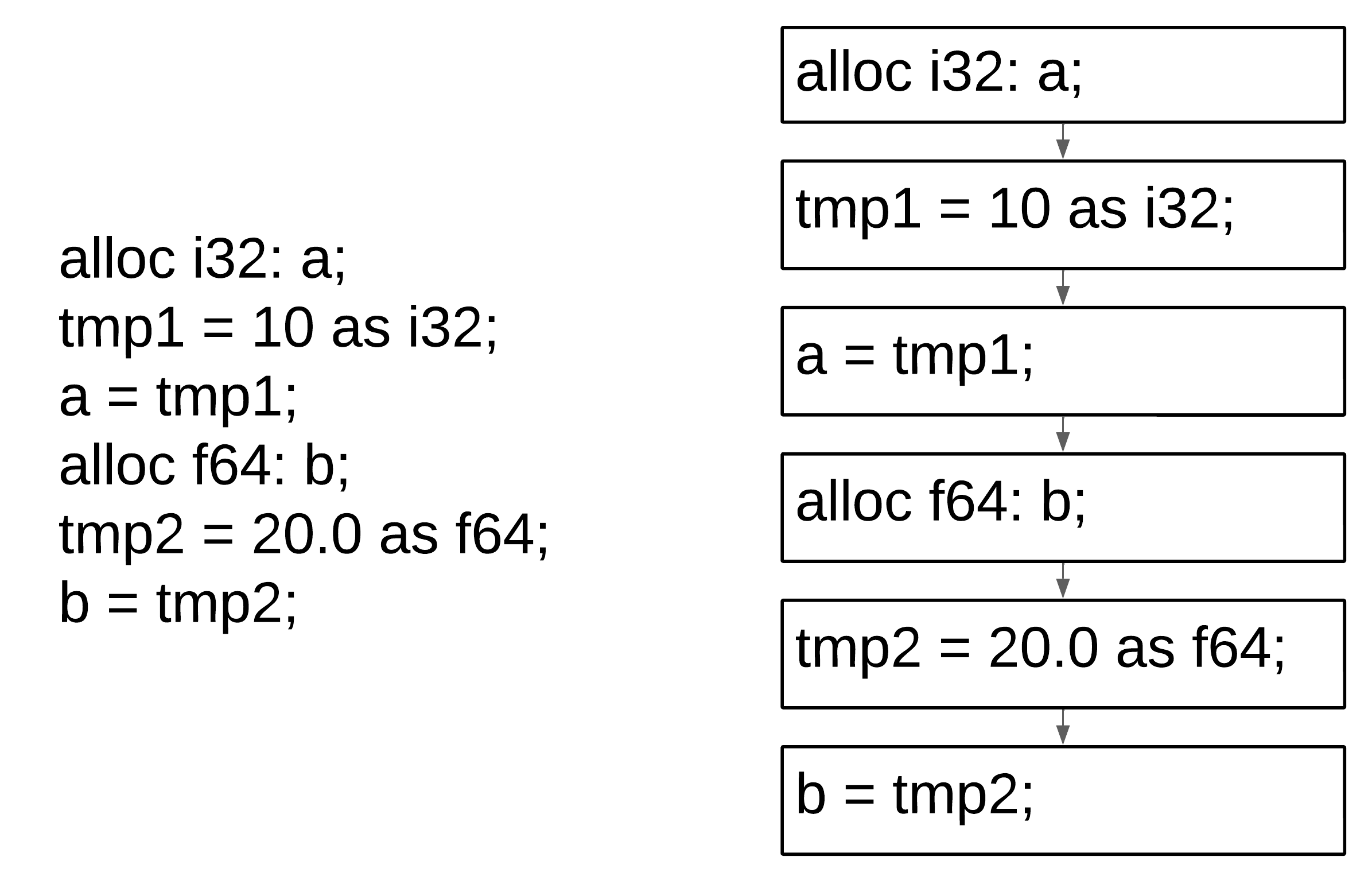
Figure 6 — CFG from HIR
Cordell Compiler 的 CFG 转储示例

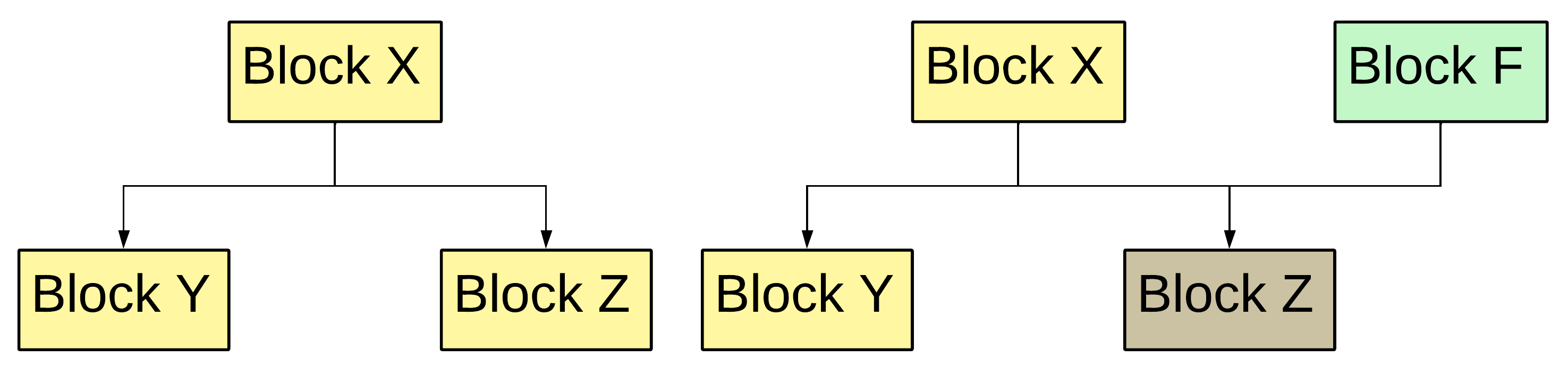
Figure 7 — How we find a dominator
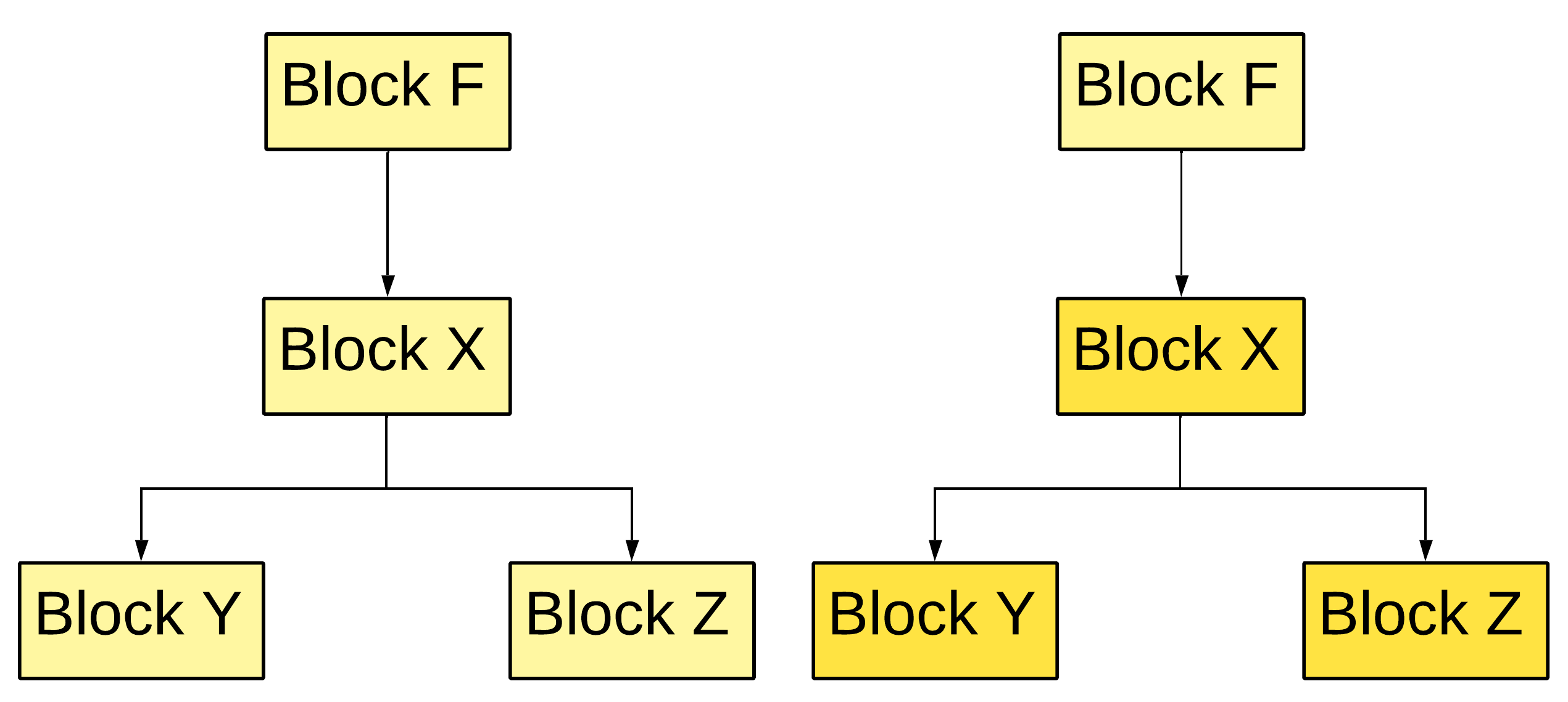
Figure 8 — How we find a strict dominator
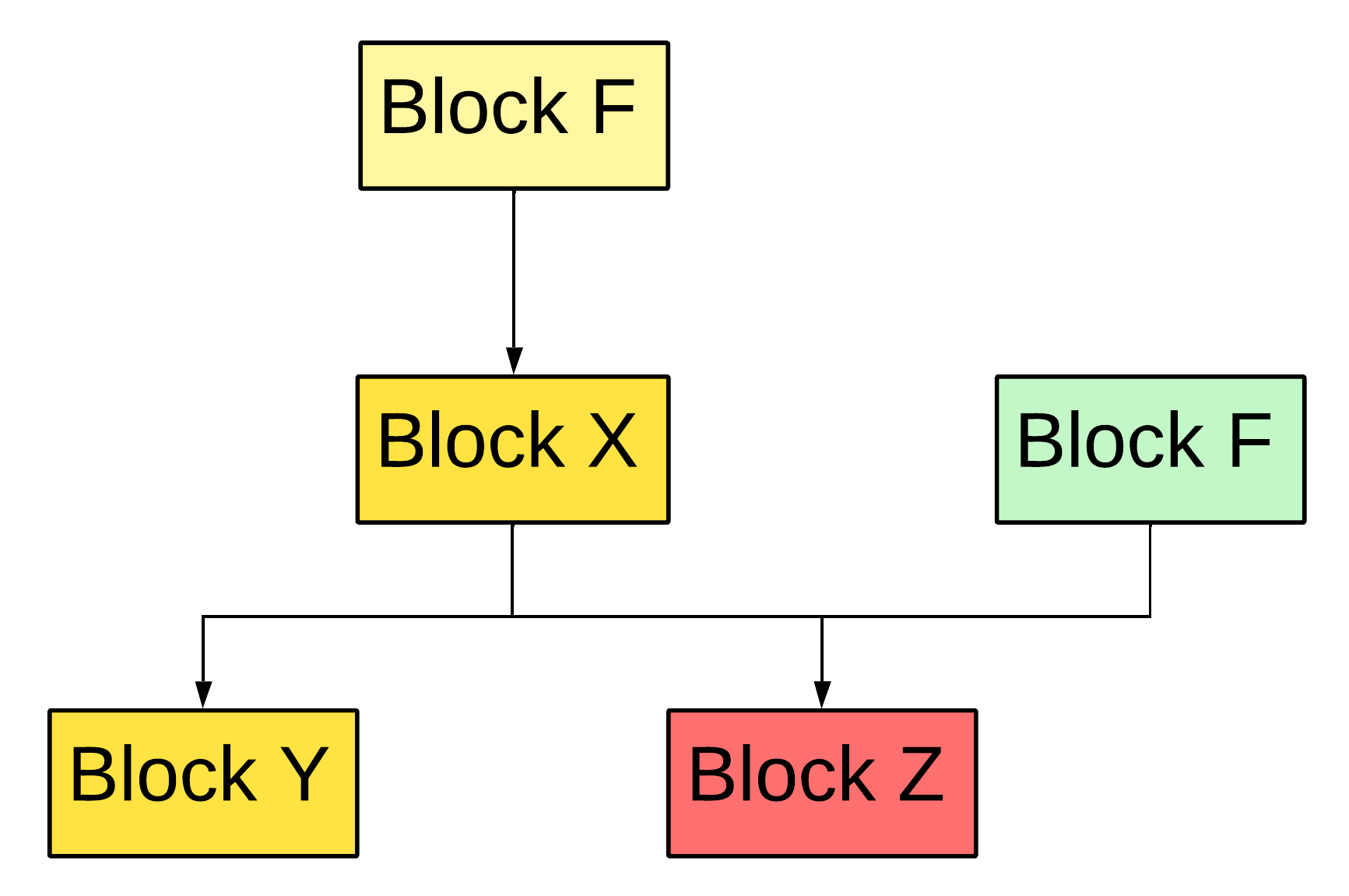
Figure 9 — Find dominance frontier

Figure 10 — "Basic" SSA form

Figure 11 — The "phi" problem

Figure 12 — Phi function
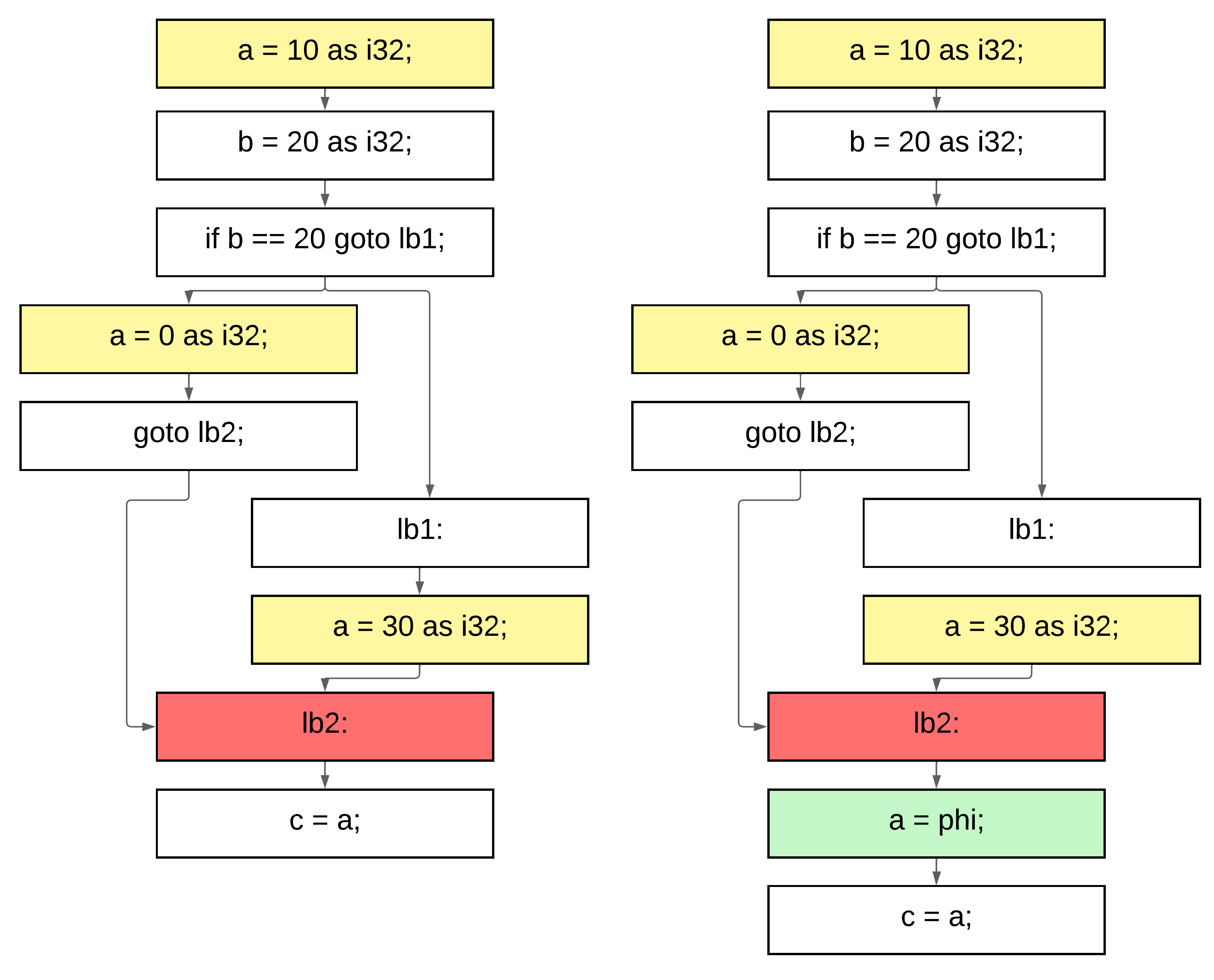
Figure 13 — Phi function placement
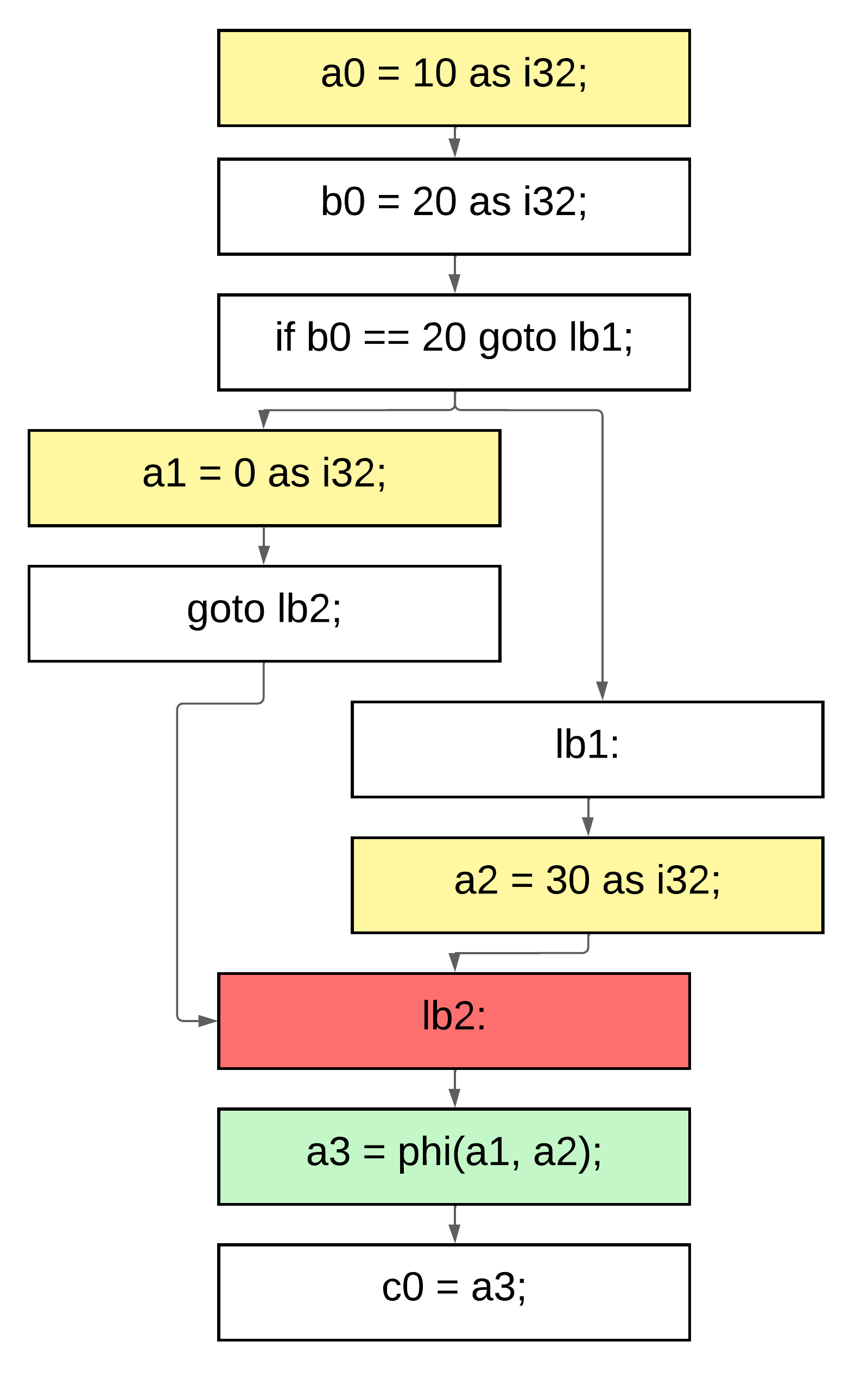
Figure 14 — Final phi function
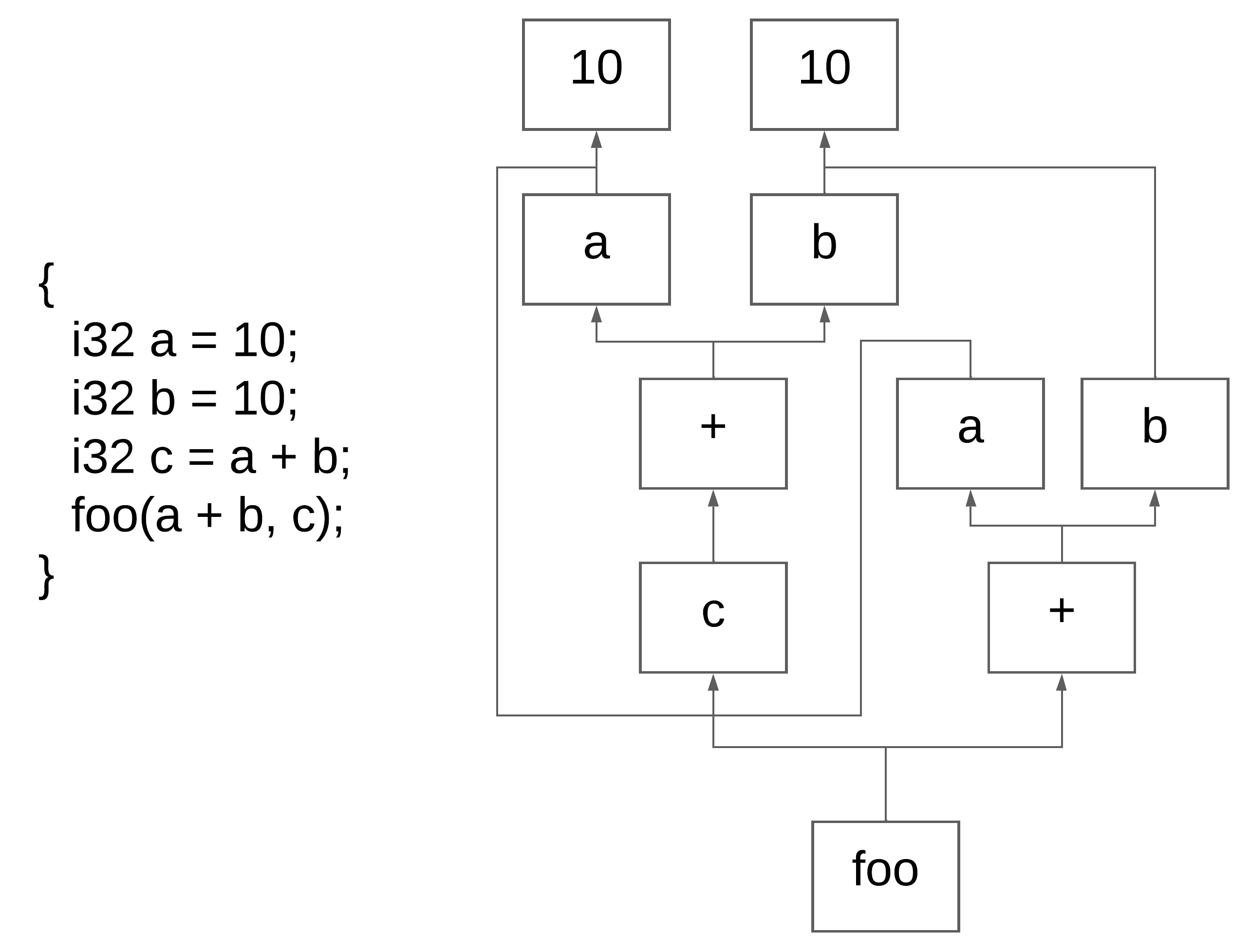
Figure 15 — DAG
DAG 在 HIR 优化中的应用
``` { start(i64 argc, ptr u64 argv) { i32 a = 10; ptr i32 b = ref a; dref b = 11; i32 c = 10; exit c; } } ``` -> ``` { start { { i64s %0 = alloc; i64s %0 = load_starg(); u64s %1 = alloc; u64s %1 = load_starg(); { i32s %2 = alloc; i32t %5 = num?: 10 as i32; i32s %2 = i32t %5; u64s %3 = alloc; u64t %6 = &(i32s %2); u64s %3 = u64t %6; u64t %7 = num?: 11 as u64; *(u64s %3) = u64t %7; i32s %4 = alloc; i32t %8 = num?: 10 as i32; i32s %4 = i32t %8; exit i32s %4; } } } } ```从 HIR 到 LIR 示例
从 HIR 我们可以生成高层的 LIR: ``` fn strlen(i8* s) -> i64 { %12 = ldparam(); { kill(cnst: 0); kill(cnst: 1); %13 = num: 0; %14 = %13; %8 = num: 1 as u64; lb10: %6 = *(%15); cmp %6, cnst: 0; jne lb11; je lb12; lb11: { %7 = %15 + %8; %16 = %7; %9 = %14 + num: 1; %17 = %9; } %14 = %17; %15 = %16; jmp lb10; lb12: return %14; } } kill(cnst: 14); start { { %18 = strt_loadarg(); %19 = strt_loadarg(); { %4 = str_alloc(str(Hello world!)); %5 = arr_alloc(X); %10 = &(%5); kill(cnst: 3); kill(cnst: 18); kill(cnst: 4); kill(cnst: 19); kill(cnst: 10); kill(cnst: 5); kill(cnst: 2); stparam(%10); call strlen(i8* s) -> i64; %11 = fret(); exit %11; } } kill(cnst: 11); } ```LIR 选择的指令
``` fn strlen(i8* s) -> i64 { { r11 = num: 0; r9 = r11; rdi = rdi; rbx = num: 1 as u64; lb10: r8 = *(rsi); cmp r8, cnst: 0; je lb12; jne lb11; lb11: { rax = rsi; rax = rax + rbx; rax = rax; rdx = rax; rsi = rdx; rax = r9; rax = rax + rbx; r10 = rax; rcx = r10; r9 = rcx; rbx = num: 1; rbx = rbx; } jmp lb10; lb12: return r9; } } start { { rbx = [rbp + 16]; rax = rax; rbx = [rbp + 8]; [rbp - 16] = num: 0; [rbp - 15] = num: 1; rdx = &([rbp - 16]); rdi = rdx; { [rbp - 29] = cnst: 72; [rbp - 28] = cnst: 101; [rbp - 27] = cnst: 108; [rbp - 26] = cnst: 108; [rbp - 25] = cnst: 111; [rbp - 24] = cnst: 32; [rbp - 23] = cnst: 119; [rbp - 22] = cnst: 111; [rbp - 21] = cnst: 114; [rbp - 20] = cnst: 108; [rbp - 19] = cnst: 100; [rbp - 18] = cnst: 33; [rbp - 17] = cnst: 0; kill(cnst: 4); kill(cnst: 5); call strlen(i8* s) -> i64; exit rax; } } } ```最终的 ASM
``` ; Compiled .asm file. File generated by CordellCompiler! section .data section .rodata section .bss section .text global _main ; BB20: _cpl_strlen: push rbp mov rbp, rsp mov rcx, rdi mov rsp, rdi xor rbx, rbx mov rbp, rbx ; BB27: mov rdi, rsp mov rbx, rsp mov rsi, rbp mov rcx, rbp mov rdx, 1 ; BB21: lb11: mov r11, rbx mov r10b, [r11] cmp r10b, 0 je lb13 jne lb12 ; BB22: lb12: mov r12, rbx mov rax, rbx add rax, rdx mov rsi, rax mov rbp, rax mov r8, rax mov r14, rax mov rax, r14 shr rax, rax mov r13, rax mov rsp, rax mov rax, rsp mov r15, rsp mov rcx, rsp mov r9, rsp mov rbx, rsp jmp lb11 ; BB23: lb13: mov rdi, rcx mov rax, rcx mov rsp, rbp pop rbp ret ; BB24: ; BB25: _main: push rbp mov rbp, rsp sub rsp, 16 mov byte [rbp - 13], 72 mov byte [rbp - 12], 101 mov byte [rbp - 11], 108 mov byte [rbp - 10], 108 mov byte [rbp - 9], 111 mov byte [rbp - 8], 32 mov byte [rbp - 7], 119 mov byte [rbp - 6], 111 mov byte [rbp - 5], 114 mov byte [rbp - 4], 108 mov byte [rbp - 3], 100 mov byte [rbp - 2], 33 mov byte [rbp - 1], 0 lea rax, qword [rbp - 13] mov r11, rax mov r15, qword [rbp + 16] mov r8, qword [rbp + 8] mov rbx, qword [rbp + 8] mov r9, r11 mov rdi, r9 push rax push rdx push rsp push r14 push r10 push rbp push r11 push r12 push rax call _cpl_strlen pop rax pop r12 pop r11 pop rbp pop r10 pop r14 pop rsp pop rdx pop rax mov r13, rax mov rsp, rax xor rbp, rbp mov rax, rbp mov r14, 1 mov rdi, r14 mov r12, r11 mov rsi, r12 mov r10, rsp mov rdx, r10 syscall xor rax, rax mov rdx, rax mov rax, 0x2000001 syscall ; BB26: ; op=3 ```标签:AST优化, CFG, Cordell, DAG, DNS解析, HIR, LLVM替代, odt, OS开发, Rust语法, SOC Prime, SSA形式, 业余项目, 中间表示, 云安全监控, 代码优化, 代码生成, 优化器, 低级语言, 后端开发, 学习编译器, 常量折叠, 开发工具, 开源项目, 微码生成, 抽象语法树, 控制流图, 教育目的, 死代码消除, 汇编生成, 渗透测试工具, 系统编程语言, 编程工具, 编程语言, 编程语言设计, 编译原理, 编译器, 编译器架构, 编译工具链, 自制操作系统, 解析器, 词法分析, 词法标记化, 语法分析, 跨平台编译, 软件开发, 远程代码执行, 静态分析, 预处理, 风险发现