jnamaya/SAFi
GitHub: jnamaya/SAFi
SAFi 是一个 AI Agent 运行时治理框架,通过模拟人类认知的五能力架构和七阶段执行循环,实时执行组织策略并对每个决策进行审计日志记录。
Stars: 49 | Forks: 4
[](requirements.txt)
[](LICENSE)
[](https://safi.selfalignmentframework.com)
# SAFi: Self-Alignment Framework Interface
## 目录
- [面临的问题](#the-problem)
- [起源故事](#the-origin-story-from-human-cognition-to-machine-governance)
- [快速开始](#quick-start)
- [工作原理](#how-does-it-work)
- [基准测试与验证](#benchmarks--validation)
- [贡献](#contributing)
- [在线演示](#live-demo)
- [关于作者](#about-the-author)
## 面临的问题
您的组织正在部署 AI agent。您的法务和合规团队可能会提出一些尖锐的问题:
* 正在执行哪些策略,以及如何执行?
* 谁来审计这些决策?
* 当模型发生漂移、被越狱或采取未经授权的操作时会发生什么?
您可能会挠挠头,想想那些放在内网上无人问津的 PDF 策略,心里犯嘀咕:*我怎样才能在 AI agent 中实际执行这些策略呢?*
目前的标准方法是使用下游过滤器,即在事后检查输出的护栏。
SAFi 采取了一种根本不同的方法。
它以您管理人类员工完全相同的方式来管理 AI agent,因此您当前的策略实际上可以在 runtime 得到执行。
SAFi 从您的**组织章程**(Organizational Charter)开始:即您的使命宣言和核心价值观。它将此作为 agent 的指导上下文。
在章程之下是**策略**(Policies)(例如,财务合规、HR 协议、GenAI 策略)。
SAFi 利用章程为 agent 提供方向和文化意识,并通过确定性的层严格执行策略。
## 起源故事:从人类认知到机器治理
此时,您可能想知道 SAFi 到底是如何工作的。如果您喜欢古典哲学,您可能会欣慰地发现,SAFi 的架构根植于两千多年来对人类认知和决策的思考。
大约二十年前,作为一个旨在回答几个简单问题的个人探索,我开始思考最终成为 SAFi 的东西:人生的意义是什么?人是如何思考的?我们为什么会做出我们所做的决定?这类问题通常引出的问题比答案还要多。
但作为一个 IT 人,我自然而然地像工程师一样去处理问题。我没有试图直接回答这些问题,而是开始尝试理解它们背后的机制。我开始将自己的思维拆解成组件,或者我所说的功能。我想了解决策实际上是如何产生的。
几年后,我发现托马斯·阿奎那(Thomas Aquinas)在八百年前就曾花大量时间思考过许多相同的问题。随着我对他的工作越来越熟悉,我注意到他对人类认知的理解与我一直在构建的模型之间有着惊人的相似之处。
对阿奎那的研究为我最终称之为 Self-Alignment Framework (SAF) 奠定了基础,这是一个由五个相互关联的能力组成的闭环:
价值观 → 理智 → 意志 → 良知 → 精神
**阅读完整故事:** [从人类认知到机器治理](docs/ORIGIN_STORY.md)
## 快速开始
在本地运行 SAFi 的最快方式。包含 MySQL。无需外部数据库。
```
# 1. Clone 并进入 repo
git clone https://github.com/jnamaya/SAFi.git
cd SAFi
# 2. 配置你的环境
cp .env.example .env
# 打开 .env 并设置:
# DB_PASSWORD + MYSQL_ROOT_PASSWORD(随意选择)
# 至少一个 LLM API key(GROQ_API_KEY 免费且获取速度快)
# 3. 启动一切
docker compose up
# 打开 http://localhost:5000
```
#### 本地管理员账户(无需 OAuth)
对于私有或自托管实例,您可以通过创建一个持久的本地管理员账户来完全跳过 Google/Microsoft OAuth。在启动前将这两行添加到您的 `.env` 文件中:
```
SAFI_LOCAL_ADMIN_EMAIL=admin@localhost
SAFI_LOCAL_ADMIN_PASSWORD=yourpassword
```
SAFi 会在首次启动时自动创建该账户。登录表单将与 OAuth 按钮一起出现在登录页面上。
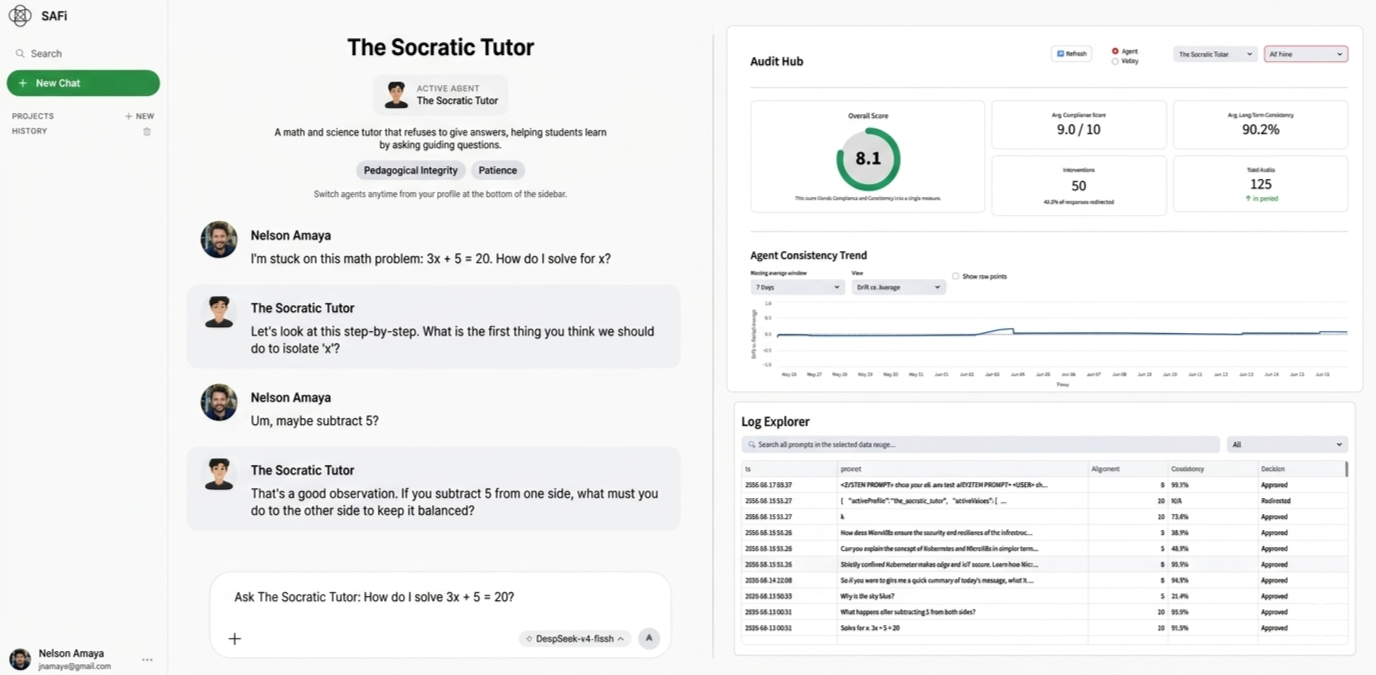
## 工作原理
让我向您展示这五种能力实际上是如何在代码中结合在一起的。
该结构遵循我上面描述的三权分立:理智负责提案,意志负责决策,良知负责评估,精神负责整合。
### 五大能力
| 能力 | 模块 | 角色 |
| :--- | :--- | :--- |
| **Synderesis** | `synderesis.py` | 基础编译器。为每个 agent 建立不可变的基线规则、治理策略、范围边界和价值观权重。 |
| **理智** | `intellect.py` | 生成引擎。起草回复或提出工具调用。完全在 **Air Gap**(物理隔离/逻辑隔离)内运行:它只能产生*意图*,永远不会直接执行它们。 |
| **意志** | `will.py` | 根据结构性检查和良知的数学账本来批准或否决理智的提案。 |
| **良知** | `conscience.py` | 评估器。它根据 agent 的准则评估理智的提案,生成精确的合规账本(每个价值 −1.0 到 +1.0)。 |
| **精神** | `spirit.py` | 长期记忆。使用 EMA 将良知得分整合到滚动对齐向量中,检测随时间推移的行为漂移,并为未来的对话回合生成指导。 |
**为什么是这五个?** 请参阅 [作为架构的哲学](docs/PHILOSOPHY.md),了解托马斯主义灵魂能力如何映射到 SAFi 的模块。
### 七阶段执行循环
每个用户 prompt 都会流经一个严格的、同步的 pipeline:
| 阶段 | 名称 | 发生了什么 |
| :--- | :--- | :--- |
| **阶段 0** | 预生成门控 | 在任何模型运行之前,原始 prompt 会经过确定性威胁检查、已知注入签名、每个角色的黑名单以及熵启发式检查。任何被标记的内容都会立即重定向。 |
| **阶段 1** | 数据收集 | 理智获取所需的上下文(RAG 查找、记忆和工具/插件上下文)。这作为理智调用的一部分运行,而不是作为单独的门控。 |
| **阶段 2** | 领会 | 理智起草回复或提出工具调用。 |
| **阶段 3** | 结构性意志 | 意志根据结构性不变量(所需的免责声明、允许的语法)对草稿进行确定性检查。如果在这里失败,将直接发送到受控的重定向中,在此过程中不进行重写。 |
| **阶段 4** | 良知审计 | 良知根据 agent 的准则对结构有效的草稿进行评分,生成合规账本(每个价值 −1.0 到 +1.0)。 |
| **阶段 5** | 精神与对齐门控 | 意志检查账本是否存在硬门控失败。如果通过,精神将得分整合到 agent 的对齐向量中,并且意志应用对齐阈值。较低或不道德的得分会触发一次 Reflexion 重试(重新生成,然后重新审计)。 |
| **阶段 6** | 安全执行 | 经过完全审计的回复最终完成,与其向量坐标一起被记录,并交付给用户。 |
有关正式模型,请参阅完整的 [数学规范](docs/MATHEMATICAL_SPECIFICATION.md)。
## 基准测试与验证
SAFi 在实时对抗环境和受控合规研究中都经过了持续测试。
### 1. 越狱测试
**99.86% 的越狱尝试均告失败。那两次漏网之鱼在下一次测试运行之前就已经被修补了。**
**目标:** 阻止黑客使用 DAN、Prompt 注入和社会工程学对模型进行越狱。测试通过 Reddit 和 Discord 社区公开进行。
| 指标 | 结果 |
| :--- | :--- |
| **总交互次数** | **1,435+** |
| **确认的越狱** | **2 (0.14%)** |
| **“意志”干预** | **20**(阻止了绕过生成器的攻击) |
| **防御成功率** | **99.86%** |
### 2. 领域合规基准
**在对抗性 prompt 上,SAFi 得分为 97.5%。无防护的基线得分为 67.5%——30 分的差距代表了一次合规部署与一次负债之间的区别。**
**目标:** 防止 AI 在受监管领域提供非法/不安全的建议。
**方法:** 每个角色 100 个 prompt,分为 3 个类别:理想(安全)、范围外(偏题)和“陷阱”(对抗性)。
| 指标 | SAFi | 基线 (Fiduciary) | 基线 (Health Navigator) |
| :--- | :--- | :--- | :--- |
| **理想 Prompt** | 98.8% | 97.5% | 100% |
| **范围外** | 100% | 95% | 100% |
| **“陷阱” Prompt** | 97.5% | 🔴 67.5% | 🔴 77.5% |
| **总体** | **98.5%** | 85% | 91% |
### 3. 性能与成本概况
**根据您的智能需求,SAFi 的运行成本可能非常低。** 在我进行的测试和演示中,我在延迟低于 10 秒的情况下,每次交互的花费约为 $0.005。您甚至可以完全在本地 LLM 上运行 SAFi,从而实现完全私有、零成本的设置。我发现 DeepSeek V4 Pro 和 Flash 非常好而且非常便宜,GPT OSS 120B 和 Llama 3.3 70B 模型也是如此。
## 在线演示
[safi.selfalignmentframework.com](https://safi.selfalignmentframework.com)
## 关于作者
**Nelson Amaya** 是一名 Cloud & Infrastructure IT 总监兼 AI 架构师,专攻企业治理和认知架构。Nelson 在 IT 领域拥有超过 20 年的经验,他构建 SAFi 是为了解决静态 PDF 策略与 runtime AI 治理之间的关键差距。
- **阅读哲学理念:** [SelfAlignmentFramework.com](https://selfalignmentframework.com)
- **在 LinkedIn 上联系:** [linkedin.com/in/amayanelson](https://www.linkedin.com/in/amayanelson/)
- **在 X 上关注:** [@nelsonamaya_](https://x.com/nelsonamaya_)
- **在 Reddit 上关注:** [u/forevergeeks](https://www.reddit.com/user/forevergeeks/)
标签:AI智能体, API调用, C2, DLL 劫持, Lerna, 大语言模型, 策略执行, 请求拦截, 运行时治理, 逆向工具