NVIDIA-NeMo/RL
GitHub: NVIDIA-NeMo/RL
NVIDIA 开源的可扩展强化学习训练后库,为大型语言和多模态模型提供高效的 RL、对齐及蒸馏训练能力。
Stars: 1860 | Forks: 490
# NeMo RL:一个可扩展且高效的训练后(Post-Training)库
[](https://github.com/NVIDIA-NeMo/RL/actions/workflows/cicd-main.yml)
[](https://github.com/NVIDIA-NeMo/RL/stargazers/)
[文档](https://docs.nvidia.com/nemo/rl/latest/index.html) | [讨论](https://github.com/NVIDIA-NeMo/RL/discussions/categories/announcements) | [贡献](https://github.com/NVIDIA-NeMo/RL/blob/main/CONTRIBUTING.md)
## 📣 新闻
* [06/04/2026] [Nemotron-3-Ultra](https://research.nvidia.com/labs/nemotron/Nemotron-3-Ultra/) 是使用 NeMo-RL 训练的!请按照[此指南](https://github.com/NVIDIA-NeMo/RL/blob/ultra-v3/docs/guides/nemotron-3-ultra.md)探索该训练后方案。
* [04/30/2026] [发布 v0.6.0!](https://github.com/NVIDIA-NeMo/RL/releases/tag/v0.6.0)
* Sglang 后端、Muon Optimizer、Speculative Decoding、Yarn 长上下文训练、Chunked Cross Entropy Loss、top-p/top-k 训练
* 新发布的 SWE RL release 基准测试展示了长上下文、多步骤 RL rollout。请参见[此处](https://docs.nvidia.com/nemo/rl/latest/about/performance-summary.html#gb200-bf16-benchmarks)的性能数据,以及[此处](https://github.com/NVIDIA-NeMo/RL/pull/2327)的配套方案和脚本。
* 发布版本即将推出!
* [04/06/2026] 支持新模型
* 增加了对 [Qwen3.5](https://huggingface.co/collections/Qwen/qwen35) dense 和 MoE 模型(LLM 和 VLM)的 GRPO 训练支持。
* 增加了对 [GLM-4.7-Flash](https://huggingface.co/zai-org/GLM-4.7-Flash) 的 GRPO 训练支持。
* 方案:[grpo-qwen3.5-9b-1n8g-megatron.yaml](/examples/configs/recipes/llm/grpo-qwen3.5-9b-1n8g-megatron.yaml), [grpo-qwen3.5-35ba3b-2n8g-megatron-ep16tp2cp2.yaml](/examples/configs/recipes/llm/grpo-qwen3.5-35ba3b-2n8g-megatron-ep16tp2cp2.yaml), [grpo-glm47-flash-4n8g-automodel.yaml](/examples/configs/recipes/llm/grpo-glm47-flash-4n8g-automodel.yaml)
* [03/12/2026] 支持 GDPO
* 现已支持为多奖励 RL 训练启用 [Group reward-Decoupled Normalization Policy Optimization](https://arxiv.org/abs/2601.05242) (GDPO)。
* 示例:[gdpo_math_1B.yaml](/examples/configs/gdpo_math_1B.yaml)
* 支持异步 RL 训练
* WIP:Nemo-gym 兼容性
* [03/11/2026] [Nemotron-3-Super](https://research.nvidia.com/labs/nemotron/Nemotron-3-Super/) 是使用 NeMo-RL 进行训练后的!请按照[此指南](https://github.com/NVIDIA-NeMo/RL/blob/super-v3/docs/guides/nemotron-3-super.md)复现完整的 RL 训练方案。
* [02/04/2026] 支持 LoRA
* 在 [DTensor](https://github.com/NVIDIA-NeMo/RL/pull/1556) 和 [Megatron Core](https://github.com/NVIDIA-NeMo/RL/pull/1629) 后端上均支持 LoRA SFT。
* 在 [DTensor](https://github.com/NVIDIA-NeMo/RL/pull/1797) 和 [Megatron Core](https://github.com/NVIDIA-NeMo/RL/pull/1889) 后端上均支持 LoRA GRPO。
* 在 [DTensor](https://github.com/NVIDIA-NeMo/RL/pull/1826) 和 [Megatron Core](https://github.com/NVIDIA-NeMo/RL/pull/2125) 后端上均支持 LoRA DPO。
* Nano v3 LoRA 方案:
* [sft-nanov3-30BA3B-2n8g-fsdp2-lora.yaml](examples/configs/recipes/llm/sft-nanov3-30BA3B-2n8g-fsdp2-lora.yaml)
* [grpo-nanov3-30BA3B-2n8g-fsdp2-lora.yaml](examples/configs/recipes/llm/grpo-nanov3-30BA3B-2n8g-fsdp2-lora.yaml)
* [grpo-nanov3-30BA3B-2n8g-megatron-lora.yaml](examples/configs/recipes/llm/grpo-nanov3-30BA3B-2n8g-megatron-lora.yaml)
以往新闻
* [01/30/2026] [发布 v0.5.0!](https://github.com/NVIDIA-NeMo/RL/releases/tag/v0.5.0)
* linux/amd64 和 linux/arm64 Docker 容器现已在 NGC 上提供 [nvcr.io/nvidia/nemo-rl:v0.5.0](https://registry.ngc.nvidia.com/orgs/nvidia/containers/nemo-rl/tags)。
* 支持 NeMo-Gym + NeMo-RL
* 📊 在 [Google Colab](https://colab.research.google.com/drive/1Xgg8D7mNkWnz6t2uL8BbPfPb7UTkN1H0?usp=sharing) 上查看发布运行的指标,以便抢先开始您的实验。
* [12/15/2025] NeMo-RL 是训练 [NVIDIA-NeMotron-3-Nano-30B-A3B-FP8](https://huggingface.co/nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-FP8) 的框架提供了训练后过程的可复现说明。
* [10/10/2025] **支持 DAPO 算法**
NeMo RL 现已支持 [Decoupled Clip and Dynamic Sampling Policy Optimization (DAPO)](https://arxiv.org/pdf/2503.14476) 算法,该算法通过 **Clip-Higher**、**Dynamic Sampling**、**Token-Level Policy Gradient Loss** 和 **Overlong Reward Shaping** 扩展了 GRPO,以实现更稳定、更高效的 RL 训练。详情请参阅 [DAPO 指南](docs/guides/dapo.md)。
* [9/27/2025] [NeMo RL 中的 FP8 量化](https://github.com/NVIDIA-NeMo/RL/discussions/1216)
* [9/25/2025] On-policy Distillation
* 学生模型生成 on-policy 序列,并通过 KL 对齐到更大的教师模型,以比 RL 更低的成本实现接近大模型的质量。请参见 [On-policy Distillation](#on-policy-distillation)。
* [12/1/2025] [发布 v0.4.0!](https://github.com/NVIDIA-NeMo/RL/releases/tag/v0.4.0)
* 首个提供官方 NGC 容器 [nvcr.io/nvidia/nemo-rl:v0.4.0](https://registry.ngc.nvidia.com/orgs/nvidia/containers/nemo-rl/tags) 的版本。
* 📊 在 [Google Colab](https://colab.research.google.com/drive/1u5lmjHOsYpJqXaeYstjw7Qbzvbo67U0v?usp=sharing) 上查看发布运行的指标,以便抢先开始您的实验。
* [9/30/2025] [在 GCP 上使用 NeMo RL 加速 RL!](https://discuss.google.dev/t/accelerating-reinforcement-learning-on-google-cloud-using-nvidia-nemo-rl/269579/4)
* [8/15/2025] [NeMo-RL:将大型 MoE 模型中权重传输优化 10 倍的旅程](https://github.com/NVIDIA-NeMo/RL/discussions/1189)
* [7/31/2025] [NeMo-RL V0.3:通过 Megatron-Core 使用 Nemo-RL 实现可扩展且高性能的训练后](https://github.com/NVIDIA-NeMo/RL/discussions/1161)
* [7/25/2025] [发布 v0.3.0!](https://github.com/NVIDIA-NeMo/RL/releases/tag/v0.3.0)
* 📝 [v0.3.0 公告](https://github.com/NVIDIA-NeMo/RL/discussions/1161)
* 📊 在 [Google Colab](https://colab.research.google.com/drive/15kpesCV1m_C5UQFStssTEjaN2RsBMeZ0?usp=sharing) 上查看发布运行的指标,以便抢先开始您的实验。
* [5/14/2025] [使用 NeMo RL 复现 DeepscaleR!](docs/guides/grpo-deepscaler.md)
* [5/14/2025] [发布 v0.2.1!](https://github.com/NVIDIA-NeMo/RL/releases/tag/v0.2.1)
* 📊 在 [Google Colab](https://colab.research.google.com/drive/1o14sO0gj_Tl_ZXGsoYip3C0r5ofkU1Ey?usp=sharing) 上查看发布运行的指标,以便抢先开始您的实验。
## 概述
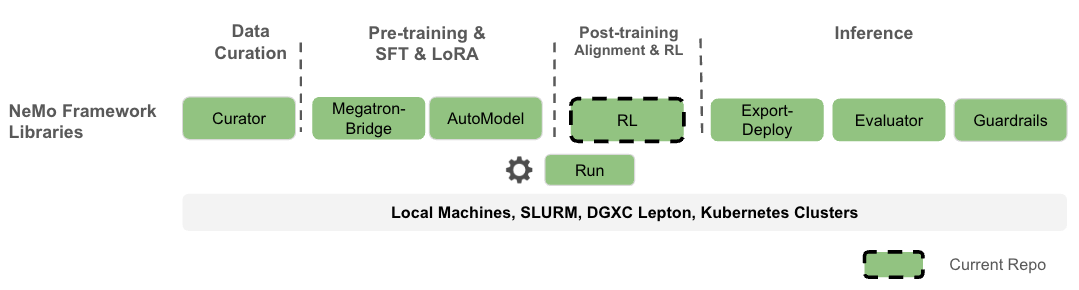
**NeMo RL** 是 [NVIDIA NeMo Framework](https://github.com/NVIDIA-NeMo) 下的一个开源训练后库,旨在为多模态模型(LLM、VLM 等)简化和扩展强化学习方法。NeMo RL 专为灵活性、可复现性和规模化而设计,支持小规模实验以及大规模多 GPU、多节点部署,从而在研究和生产环境中实现快速实验。
您可以期待:
- **灵活性**:采用模块化设计,允许轻松集成和自定义。
- **使用 Ray 进行高效的资源管理**:支持跨不同硬件配置的可扩展和灵活部署。
- **高可塑性 (Hackable)**:提供原生的纯 PyTorch 路径,适合快速的研究原型设计。
- **结合 Megatron Core 的高性能**:支持适用于大模型和长上下文长度的各种并行技术。
- **与 Hugging Face 无缝集成**:易于使用,允许用户利用广泛的预训练模型和工具。
- **详尽的文档**:详细且用户友好,并提供实用示例。
有关架构和设计理念的更多详细信息,请参阅我们的[设计文档](https://github.com/NVIDIA-NeMo/RL/tree/main/docs/design-docs)。
### 训练后端
NeMo RL 支持多种训练后端,以适应不同的模型大小和硬件配置:
- **DTensor** - PyTorch 的下一代分布式训练,具有更高的内存效率(原生支持 PyTorch TP、SP、PP、CP 和 FSDP2)。
- [**Megatron**](https://github.com/NVIDIA-NeMo/Megatron-Bridge) - NVIDIA 的高性能训练框架,通过 6D 并行扩展至大型模型。
训练后端将根据您的 YAML 配置设置自动确定。有关后端选择、配置和示例的详细信息,请参阅[训练后端文档](docs/design-docs/training-backends.md)。
### 生成后端
NeMo RL 支持多种生成/rollout 后端,以适应不同的模型大小和硬件配置:
- [**vLLM**](https://github.com/vllm-project/vllm) - 一个高吞吐量且内存高效的流行推理和服务引擎。
- [**Megatron**](https://github.com/NVIDIA/Megatron-LM/tree/main/megatron/core/inference) - 一个高性能的 Megatron 原生推理后端,消除了训练和推理之间的权重转换。
有关后端选择、配置和示例的详细信息,请参阅[生成后端文档](docs/design-docs/generation.md)。
## 功能
✅ _现已提供_ | 🔜 _即将在 v0.7 中推出_
- 🔜 **提升原生性能** - 提高原生 PyTorch 模型的训练速度。
- 🔜 **提升大型 MoE 性能** - 改善 Megatron Core 的训练性能和生成性能。
- 🔜 **弹性恢复** - 支持容错和自动缩放
- 🔜 **On-Policy Distillation** - 支持多教师和跨 tokenizer 的蒸馏
- 🔜 **新模型** - Qwen3-Next, Minimax
- ✅ **X-Token Off-Policy Distillation** - 通过预计算的投影矩阵在不匹配的(学生、教师)tokenizer 之间进行 off-policy 蒸馏。
- ✅ **Muon Optimizer** - 支持 SFT/RL 的新兴 Optimizer
- ✅ **Megatron Inference** - 改善了 Megatron Inference 的性能(避免权重转换)。
- ✅ **SGLang Inference** - 提供用于优化推理的 SGLang rollout 支持。
- ✅ **Speculative Decoding** - 提供用于加速 rollout 和训练的 Speculative Decoding 支持。
- ✅ **新模型** - Nemotron-Super, Qwen3.5, GLM Flash-4.7
- ✅ **扩展算法** - GDPO,支持用于 RL(GRPO) 和 DPO 的 LoRA
- ✅ **分布式训练** - 基于 Ray 的基础架构。
- ✅ **环境支持和隔离** - 支持多环境训练以及组件之间的依赖隔离。
- ✅ **Worker 隔离** - RL Actor 之间的进程隔离(无需担心全局状态)。
- ✅ **学习算法** - GRPO/GSPO/DAPO、SFT(带 LoRA)、DPO 和 On-policy distillation。
- ✅ **Multi-Turn RL** - 支持带有工具使用、游戏等的多轮 RL 生成和训练。
- ✅ **结合 DTensor 的高级并行技术** - 用于高效训练的 PyTorch FSDP2、TP、CP 和 SP(通过 NeMo AutoModel)。
- ✅ **支持具有更长序列的更大模型** - 结合 Megatron Core 的高性能并行技术(TP/PP/CP/SP/EP/FSDP)(通过 NeMo Megatron Bridge)。
- ✅ **Sequence Packing** - 在 DTensor 和 Megatron Core 中均提供 Sequence Packing,带来巨大的训练性能提升。
- ✅ **快速生成** - 用于优化推理的 vLLM 后端。
- ✅ **Hugging Face 集成** - 在 DTensor 路径中提供 OOB 支持,通过 Megatron Bridge 中间件提供用于 Megatron 路径的 CKPT 转换。
- ✅ **端到端 FP8 低精度训练** - 支持 Megatron Core FP8 训练和 FP8 vLLM 生成。
- ✅ **视觉语言模型 (VLM)** - 支持 VLM 上的 SFT 和 GRPO。
- ✅ **Megatron Inference** - 提供快速 Day-0 的 Megatron Inference 支持新 Megatron 模型(避免权重转换)。
- ✅ **异步 RL** - 支持 off-policy 训练的异步 rollout 和重放缓冲区,并启用完全异步的 GRPO。
- ✅ **Nemo-Gym 集成** - RL 环境集成。
- ✅ **GB200** - 为 GB200 提供容器支持。
## 目录
- [前置条件](#prerequisites)
- [快速入门](#quick-start)
- 支持矩阵
- [评估](#evaluation)
- [转换模型格式(可选)](#convert-model-format-optional)
- [运行评估](#run-evaluation)
- [设置集群](#set-up-clusters)
- [技巧与窍门](#tips-and-tricks)
- [引用](#citation)
- [贡献](#contributing)
- [许可证](#licenses)
## 快速入门
使用此快速入门指南,您可以通过原生的 PyTorch DTensor 或 Megatron Core 训练后端开始操作。
有关更多示例和设置详细信息,请继续阅读[前置条件](#prerequisites)部分。
| 原生 PyTorch (DTensor) |
Megatron Core |
克隆并创建环境
git clone git@github.com:NVIDIA-NeMo/RL.git nemo-rl --recursive
cd nemo-rl
uv venv
注意: 如果您之前运行时未检出子模块,您可能需要通过设置 NRL_FORCE_REBUILD_VENVS=true 来重建虚拟环境。请参见 技巧与窍门。
|
运行 GRPO (DTensor)
uv run python examples/run_grpo.py
|
运行 GRPO (Megatron)
uv run examples/run_grpo.py \
--config examples/configs/grpo_math_1B_megatron.yaml
|
## 前置条件
克隆 **NeMo RL**。
```
git clone git@github.com:NVIDIA-NeMo/RL.git nemo-rl --recursive
cd nemo-rl
# 如果你在 clone 时没有使用 recursive 选项,你可以递归地初始化 submodules
git submodule update --init --recursive
# repo 的不同分支可能会有这些第三方 submodules 的不同固定版本。请确保
# 通过以下配置 git,在切换分支或拉取更新后 submodules 会自动更新:
# git config submodule.recurse true
# **注意**:此设置不会随着分支的更改下载**新**的或移除**旧**的 submodules。
# 在这些情况下,你必须运行完整的 `git submodule update --init --recursive` 命令。
```
如果您在裸机(容器外部)上使用 Megatron 后端,您可能还需要安装 cuDNN 头文件。以下是检查和安装它们的方法:
```
# 检查你是否已安装 libcudnn
dpkg -l | grep cudnn.*cuda
# 在此处查找你需要的版本:https://developer.nvidia.com/cudnn-downloads?target_os=Linux&target_arch=x86_64&Distribution=Ubuntu&target_version=20.04&target_type=deb_network
# 举个例子,以下是“Linux Ubuntu 20.04 x86_64”的说明
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt update
sudo apt install cudnn # Will install cuDNN meta packages which points to the latest versions
# sudo apt install cudnn9-cuda-12 # 将安装为 cuda 12.x 编译的 cuDNN 9.x.x 版本
# sudo apt install cudnn9-cuda-12-8 # 将安装为 cuda 12.8 编译的 cuDNN 9.x.x 版本
```
如果您在裸机(容器外部)上安装 vllm 的依赖项 deep_ep 时遇到问题,您可能还需要安装 libibverbs-dev。以下是安装它的方法:
```
sudo apt-get update
sudo apt-get install libibverbs-dev
```
为了实现更快的设置和环境隔离,我们使用了 [uv](https://docs.astral.sh/uv/)。
请按照[此说明](https://docs.astral.sh/uv/getting-started/installation/)安装 uv。
然后,通过以下命令初始化 NeMo RL 项目虚拟环境:
```
uv venv
```
使用 `uv run` 来启动所有命令。它会隐式地处理 pip 安装,并确保您的环境根据我们的锁定文件保持最新状态。
## GRPO
我们提供了一个使用 [OpenInstructMath2](https://huggingface.co/datasets/nvidia/OpenMathInstruct-2) 数据集针对数学基准测试的参考 GRPO 配置。
您可以在此处阅读有关 GRPO 实现的详细信息[链接](docs/guides/grpo.md)
### GRPO 单节点
要在单个 GPU 上运行 `Qwen/Qwen2.5-1.5B` 的 GRPO:
```
# 使用 1B 参数模型运行 GRPO 数学示例
uv run python examples/run_grpo.py
```
默认情况下,这会使用 `examples/configs/grpo_math_1B.yaml` 中的配置。您可以使用命令行覆盖来自定义参数。例如,要在 8 个 GPU 上运行,
```
# 使用 8 个 GPU 运行使用 1B 参数模型的 GRPO 数学示例
uv run python examples/run_grpo.py \
cluster.gpus_per_node=8
```
您可以覆盖 YAML 配置文件中列出的任何参数。例如,
```
uv run python examples/run_grpo.py \
policy.model_name="meta-llama/Llama-3.2-1B-Instruct" \
checkpointing.checkpoint_dir="results/llama1b_math" \
logger.wandb_enabled=True \
logger.wandb.name="grpo-llama1b_math" \
logger.num_val_samples_to_print=10
```
默认配置使用 DTensor 训练后端。我们还提供了一个配置 `examples/configs/grpo_math_1B_megatron.yaml`,该配置被设置为直接使用 Megatron 后端。
要在单个 GPU 上使用此配置进行训练:
```
# 使用 Megatron backend 在 1 个 GPU 上运行 GRPO 数学示例
uv run python examples/run_grpo.py \
--config examples/configs/grpo_math_1B_megatron.yaml
```
有关支持的后端的更多详细信息以及如何配置训练后端以适合您的设置,请参阅[训练后端文档](docs/design-docs/training-backends.md)。
### GRPO 多节点
```
# 从 NeMo RL repo 的根目录运行
NUM_ACTOR_NODES=2
# grpo_math_8b 使用 Llama-3.1-8B-Instruct 模型
COMMAND="uv run ./examples/run_grpo.py --config examples/configs/grpo_math_8B.yaml cluster.num_nodes=2 checkpointing.checkpoint_dir='results/llama8b_2nodes' logger.wandb_enabled=True logger.wandb.name='grpo-llama8b_math'" \
CONTAINER=YOUR_CONTAINER \
MOUNTS="$PWD:$PWD" \
sbatch \
--nodes=${NUM_ACTOR_NODES} \
--account=YOUR_ACCOUNT \
--job-name=YOUR_JOBNAME \
--partition=YOUR_PARTITION \
--time=4:0:0 \
--gres=gpu:8 \
ray.sub
```
所需的 `CONTAINER` 可以按照 [Docker 文档](docs/docker.md)中的说明进行构建。
#### GRPO Qwen2.5-32B
本节概述了如何在序列长度为 16k 的情况下运行 Qwen2.5-32B 的 GRPO。
```
# 从 NeMo RL repo 的根目录运行
NUM_ACTOR_NODES=32
# 在作业开始前下载 Qwen,以避免在训练循环中花费时间下载
HF_HOME=/path/to/hf_home huggingface-cli download Qwen/Qwen2.5-32B
# 确保 HF_HOME 包含在你的 MOUNTS 中
HF_HOME=/path/to/hf_home \
COMMAND="uv run ./examples/run_grpo.py --config examples/configs/grpo_math_8B.yaml policy.model_name='Qwen/Qwen2.5-32B' policy.generation.vllm_cfg.tensor_parallel_size=4 policy.max_total_sequence_length=16384 cluster.num_nodes=${NUM_ACTOR_NODES} policy.dtensor_cfg.enabled=True policy.dtensor_cfg.tensor_parallel_size=8 policy.dtensor_cfg.sequence_parallel=True policy.dtensor_cfg.activation_checkpointing=True checkpointing.checkpoint_dir='results/qwen2.5-32b' logger.wandb_enabled=True logger.wandb.name='qwen2.5-32b'" \
CONTAINER=YOUR_CONTAINER \
MOUNTS="$PWD:$PWD" \
sbatch \
--nodes=${NUM_ACTOR_NODES} \
--account=YOUR_ACCOUNT \
--job-name=YOUR_JOBNAME \
--partition=YOUR_PARTITION \
--time=4:0:0 \
--gres=gpu:8 \
ray.sub
```
#### GRPO 多轮对话
我们还支持多轮生成和训练(工具使用、游戏等)。
训练玩滑块拼图游戏的参考示例:
```
uv run python examples/run_grpo_sliding_puzzle.py
```
## On-policy Distillation
我们提供了一个使用 [DeepScaler 数据集](https://huggingface.co/agentica-org/DeepScaleR-1.5B-Preview)的 On-policy Distillation 示例实验。
### On-policy Distillation 单节点
要在单个 GPU 上使用 `Qwen/Qwen3-1.7B-Base` 作为学生模型和 `Qwen/Qwen3-4B` 作为教师模型运行 On-policy Distillation:
```
uv run python examples/run_distillation.py
```
使用命令行覆盖来自定义参数。例如:
```
uv run python examples/run_distillation.py \
policy.model_name="Qwen/Qwen3-1.7B-Base" \
teacher.model_name="Qwen/Qwen3-4B" \
cluster.gpus_per_node=8
```
### On-policy Distillation 多节点
```
# 从 NeMo RL repo 的根目录运行
NUM_ACTOR_NODES=2
COMMAND="uv run ./examples/run_distillation.py --config examples/configs/distillation_math.yaml cluster.num_nodes=2 cluster.gpus_per_node=8 checkpointing.checkpoint_dir='results/distill_2nodes' logger.wandb_enabled=True logger.wandb.name='distill-2nodes'" \
CONTAINER=YOUR_CONTAINER \
MOUNTS="$PWD:$PWD" \
sbatch \
--nodes=${NUM_ACTOR_NODES} \
--account=YOUR_ACCOUNT \
--job-name=YOUR_JOBNAME \
--partition=YOUR_PARTITION \
--time=4:0:0 \
--gres=gpu:8 \
ray.sub
```
## X-Token Off-Policy Distillation
我们支持在学生模型和教师模型之间(**不共享 tokenizer**)进行 off-policy distillation(跨 tokenizer,或称为“x-token”蒸馏)—— 例如,将 `Qwen/Qwen3-4B` 教师模型蒸馏到 `meta-llama/Llama-3.2-1B` 学生模型中。参考方案训练于不受限制、采用 CC-BY-4.0 协议的 [Nemotron-Pretraining-Specialized-v1.1](https://huggingface.co/datasets/nvidia/Nemotron-Pretraining-Specialized-v1.1) 语料库(`Nemotron-Pretraining-Formal-Logic` 子集)。
您可以在此处阅读有关 x-token 蒸馏实现的详细信息[链接](docs/guides/xtoken-off-policy-distillation.md),包括(学生,教师)投影矩阵是如何构建的以及 loss 模式是如何工作的。
在启动运行之前,请为您的(学生,教师)tokenizer 对构建投影矩阵:
```
./tools/x_token/build_projection_matrix.sh \
--student-model meta-llama/Llama-3.2-1B \
--teacher-model Qwen/Qwen3-4B \
--runtime-top-k 4 \
--final-output cross_tokenizer_data/projection_matrix_llama_qwen_top4.pt
```
### X-Token Off-Policy Distillation 单节点
要在单节点上使用 `meta-llama/Llama-3.2-1B` 作为学生模型和 `Qwen/Qwen3-4B` 作为教师模型运行 x-token off-policy distillation:
```
uv run python examples/run_xtoken_off_policy_distillation.py \
loss_fn.projection_matrix_path=cross_tokenizer_data/projection_matrix_llama_qwen_top4.pt
```
默认情况下,这会使用 `examples/configs/xtoken_off_policy_distillation.yaml` 中的配置。投影矩阵路径是唯一必需的覆盖项。您可以使用命令行覆盖来自定义其他参数。例如:
```
uv run python examples/run_xtoken_off_policy_distillation.py \
loss_fn.projection_matrix_path=cross_tokenizer_data/projection_matrix_llama_qwen_top4.pt \
policy.model_name="meta-llama/Llama-3.2-1B" \
teacher.model_name="Qwen/Qwen3-4B" \
cluster.gpus_per_node=8
```
### X-Token Off-Policy Distillation 多节点
```
# 从 NeMo RL repo 的根目录运行
NUM_ACTOR_NODES=2
COMMAND="uv run ./examples/run_xtoken_off_policy_distillation.py --config examples/configs/xtoken_off_policy_distillation.yaml loss_fn.projection_matrix_path='cross_tokenizer_data/projection_matrix_llama_qwen_top4.pt' cluster.num_nodes=2 cluster.gpus_per_node=8 checkpointing.checkpoint_dir='results/xtoken_distill_2nodes' logger.wandb_enabled=True logger.wandb.name='xtoken-distill-2nodes'" \
CONTAINER=YOUR_CONTAINER \
MOUNTS="$PWD:$PWD" \
sbatch \
--nodes=${NUM_ACTOR_NODES} \
--account=YOUR_ACCOUNT \
--job-name=YOUR_JOBNAME \
--partition=YOUR_PARTITION \
--time=4:0:0 \
--gres=gpu:8 \
ray.sub
```
## 监督微调 (SFT)
我们提供了使用各种数据集的示例 SFT 实验,包括 [SQuAD](https://rajpurkar.github.io/SQuAD-explorer/)、OpenAI 格式数据集(支持工具调用)以及自定义 JSONL 数据集。有关支持的数据集和配置的详细文档,请参阅 [SFT 文档](docs/guides/sft.md)。
### SFT 单节点
默认的 SFT 配置设置为在单个 GPU 上运行。要启动实验:
```
uv run python examples/run_sft.py
```
这将在单个 GPU 上使用 SQuAD 数据集对 `Llama3.2-1B` 模型进行微调。
要在单个节点上使用多个 GPU,您可以修改集群配置。此调整还将允许您潜在地增加模型和 batch size:
```
uv run python examples/run_sft.py \
policy.model_name="meta-llama/Meta-Llama-3-8B" \
policy.train_global_batch_size=128 \
sft.val_global_batch_size=128 \
cluster.gpus_per_node=8
```
有关可被覆盖的完整参数列表,请参阅 `examples/configs/sft.yaml`。
### SFT 多节点
```
# 从 NeMo RL repo 的根目录运行
NUM_ACTOR_NODES=2
COMMAND="uv run ./examples/run_sft.py --config examples/configs/sft.yaml cluster.num_nodes=2 cluster.gpus_per_node=8 checkpointing.checkpoint_dir='results/sft_llama8b_2nodes' logger.wandb_enabled=True logger.wandb.name='sft-llama8b'" \
CONTAINER=YOUR_CONTAINER \
MOUNTS="$PWD:$PWD" \
sbatch \
--nodes=${NUM_ACTOR_NODES} \
--account=YOUR_ACCOUNT \
--job-name=YOUR_JOBNAME \
--partition=YOUR_PARTITION \
--time=4:0:0 \
--gres=gpu:8 \
ray.sub
```
## DPO
我们提供了一个使用 [HelpSteer3 数据集](https://huggingface.co/datasets/nvidia/HelpSteer3)进行偏好训练的示例 DPO 实验。
### DPO 单节点
默认的 DPO 实验配置为在单个 GPU 上运行。要启动实验:
```
uv run python examples/run_dpo.py
```
这将在 1 个 GPU 上训练 `Llama3.2-1B-Instruct`。
如果您有更多 GPU,可以相应地更新实验。要在 8 个 GPU 上运行,我们更新了集群配置,并切换到了 8B Llama3.1 Instruct 模型:
```
uv run python examples/run_dpo.py \
policy.model_name="meta-llama/Llama-3.1-8B-Instruct" \
policy.train_global_batch_size=256 \
cluster.gpus_per_node=8
```
任何 DPO 参数都可以从命令行进行自定义。例如:
```
uv run python examples/run_dpo.py \
dpo.sft_loss_weight=0.1 \
dpo.preference_average_log_probs=True \
checkpointing.checkpoint_dir="results/llama_dpo_sft" \
logger.wandb_enabled=True \
logger.wandb.name="llama-dpo-sft"
```
有关可被覆盖的完整参数列表,请参阅 `examples/configs/dpo.yaml`。有关如何添加您自己的 DPO 数据集的深入说明,请参阅 [DPO 文档](docs/guides/dpo.md)。
### DPO 多节点
对于跨多个节点的分布式 DPO 训练,请根据您的用例修改以下脚本:
```
# 从 NeMo RL repo 的根目录运行
## 用于你的作业的节点数量
NUM_ACTOR_NODES=2
COMMAND="uv run ./examples/run_dpo.py --config examples/configs/dpo.yaml cluster.num_nodes=2 cluster.gpus_per_node=8 dpo.val_global_batch_size=32 checkpointing.checkpoint_dir='results/dpo_llama81_2nodes' logger.wandb_enabled=True logger.wandb.name='dpo-llama1b'" \
CONTAINER=YOUR_CONTAINER \
MOUNTS="$PWD:$PWD" \
sbatch \
--nodes=${NUM_ACTOR_NODES} \
--account=YOUR_ACCOUNT \
--job-name=YOUR_JOBNAME \
--partition=YOUR_PARTITION \
--time=4:0:0 \
--gres=gpu:8 \
ray.sub
```
## RM
我们提供了一个使用 [HelpSteer3 数据集](https://huggingface.co/datasets/nvidia/HelpSteer3)进行偏好训练的示例 RM 实验。
### RM 单节点
默认的 RM 实验配置为在单个 GPU 上运行。要启动实验:
```
uv run python examples/run_rm.py
```
这将在 1 个 GPU 上基于 `meta-llama/Llama-3.2-1B-Instruct` 训练一个 RM。
如果您有更多 GPU,可以相应地更新实验。要在 8 个 GPU 上运行,我们更新集群配置:
```
uv run python examples/run_rm.py cluster.gpus_per_node=8
```
有关更多信息,请参阅 [RM 文档](docs/guides/rm.md)。
### RM 多节点
对于跨多个节点的分布式 RM 训练,请根据您的用例修改以下脚本:
```
# 从 NeMo RL repo 的根目录运行
## 用于你的作业的节点数量
NUM_ACTOR_NODES=2
COMMAND="uv run ./examples/run_rm.py --config examples/configs/rm.yaml cluster.num_nodes=2 cluster.gpus_per_node=8 checkpointing.checkpoint_dir='results/rm_llama1b_2nodes' logger.wandb_enabled=True logger.wandb.name='rm-llama1b-2nodes'" \
CONTAINER=YOUR_CONTAINER \
MOUNTS="$PWD:$PWD" \
sbatch \
--nodes=${NUM_ACTOR_NODES} \
--account=YOUR_ACCOUNT \
--job-name=YOUR_JOBNAME \
--partition=YOUR_PARTITION \
--time=4:0:0 \
--gres=gpu:8 \
ray.sub
```
## 评估
我们提供了评估工具来评估模型能力。
### 转换模型格式(可选)
如果您已经训练了一个模型,并将检查点保存在 PyTorch DCP 格式中,则在运行评估之前,首先需要将其转换为 Hugging Face 格式:
```
# 第 170 步的 GRPO checkpoint 示例
uv run python examples/converters/convert_dcp_to_hf.py \
--config results/grpo/step_170/config.yaml \
--dcp-ckpt-path results/grpo/step_170/policy/weights/ \
--hf-ckpt-path results/grpo/hf
```
如果您的模型以 Megatron 格式保存,您可以在运行评估之前使用以下命令将其转换为 Hugging Face 格式。此脚本需要 Megatron Core,因此请确保您使用 mcore extra 启动它:
```
# 第 170 步的 GRPO checkpoint 示例
uv run --extra mcore python examples/converters/convert_megatron_to_hf.py \
--config results/grpo/step_170/config.yaml \
--megatron-ckpt-path results/grpo/step_170/policy/weights/iter_0000000 \
--hf-ckpt-path results/grpo/hf
```
如果您在 **Megatron 后端使用 LoRA 进行训练**,请使用 LoRA 合并器将 adapter 权重折叠到基础模型中,并导出独立的 Hugging Face 检查点:
```
uv run --extra mcore python examples/converters/convert_lora_to_hf.py \
--base-ckpt
/iter_0000000 \
--adapter-ckpt /iter_0000000 \
--hf-model-name \
--hf-ckpt-path results/lora_merged_hf
```
有关检查点 (checkpointing) 的深入说明,请参阅 [Checkpointing 文档](docs/design-docs/checkpointing.md)。
### 运行评估
使用转换后的模型运行评估脚本:
```
uv run python examples/run_eval.py generation.model_name=$PWD/results/grpo/hf
```
使用自定义设置运行评估脚本:
```
# 示例:使用 8 个 GPU 在 MATH-500 上评估 DeepScaleR-1.5B-Preview
# 每个问题在 16 个样本上的 Pass@1 平均准确率
uv run python examples/run_eval.py \
--config examples/configs/evals/math_eval.yaml \
generation.model_name=agentica-org/DeepScaleR-1.5B-Preview \
generation.temperature=0.6 \
generation.top_p=0.95 \
generation.vllm_cfg.max_model_len=32768 \
data.dataset_name=math500 \
eval.num_tests_per_prompt=16 \
cluster.gpus_per_node=8
```
有关可被覆盖的完整参数列表,请参阅 `examples/configs/evals/eval.yaml`。有关评估的深入说明,请参阅 [评估文档](docs/guides/eval.md)。
## 设置集群
有关如何在 Slurm 或 Kubernetes 集群上设置和启动 NeMo RL 的详细说明,请参阅专门的[集群启动](docs/cluster.md)文档。
## 技巧与窍门
- 如果您在克隆 NeMo-RL 仓库时忘记初始化 NeMo 和 Megatron 子,您可能会遇到如下错误:
ModuleNotFoundError: No module named 'megatron'
如果您看到此错误,则您的虚拟环境可能存在问题。要解决此问题,请首先初始化子模块:
git submodule update --init --recursive
然后在下次启动运行时,通过设置 `NRL_FORCE_REBUILD_VENVS=true` 来强制重建虚拟环境:
NRL_FORCE_REBUILD_VENVS=true uv run examples/run_grpo.py ...
- 在运行不支持 FlashAttention2 的模型时,可能会发生大量内存碎片化。
如果在训练几次迭代后发生 OOM,调整分配器设置以减少内存碎片可能会有所帮助。
为此,请指定 [`max_split_size_mb`](https://docs.pytorch.org/docs/stable/notes/cuda.html#optimizing-memory-usage-with-pytorch-alloc-conf)
在以下**任意**位置:
1. 通过以下命令启动训练:
# 这将全局应用于所有 Ray actor
PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:64 uv run python examples/run_dpo.py ...
2. 通过在训练配置中添加此标志,使更改更持久:
policy:
# ...
dtensor_cfg:
env_vars:
PYTORCH_CUDA_ALLOC_CONF: "max_split_size_mb:64"
## 引用
如果您在研究中使用 NeMo RL,请使用以下 BibTeX 条目对其进行引用:
```
@misc{nemo-rl,
title = {NeMo RL: A Scalable and Efficient Post-Training Library},
howpublished = {\url{https://github.com/NVIDIA-NeMo/RL}},
year = {2025},
note = {GitHub repository},
}
```
## 致谢与贡献指南
NeMo RL 衷心感谢以下社区伙伴的采用与贡献 - Google、Argonne National Labs、Atlassian、Camfer、Domyn、Future House、Inflection AI、Lila、Paypal、Pegatron、PyTorch、Radical AI、Samsung、SB Instituition、Shanghai AI Lab、Speakleash、Sword Health、TII、NVIDIA Nemotron 团队以及许多其他机构。
NeMo RL 是 [NeMo Aligner](https://github.com/NVIDIA/NeMo-Aligner) 仓库的重新架构版本,后者是最早的 LLM 强化学习库之一,并启发了诸如 [VeRL](https://github.com/volcengine/verl)、[SkyRL](https://github.com/NovaSky-AI/SkyRL) 和 [ROLL](https://github.com/alibaba/ROLL) 等其他开源库。
我们欢迎对 NeMo RL 的贡献!请参阅我们的[贡献指南](https://github.com/NVIDIA-NeMo/RL/blob/main/CONTRIBUTING.md)以获取有关如何参与的更多信息。
## 许可证
NVIDIA NeMo RL 采用 [Apache License 2.0](https://github.com/NVIDIA-NeMo/RL/blob/main/LICENSE) 授权。标签:DLL 劫持, IaC 扫描, NVIDIA NeMo, 人工智能, 凭据扫描, 分布式计算, 大语言模型, 异常处理, 强化学习, 模型训练, 深度学习, 用户模式Hook绕过, 请求拦截, 逆向工具