fabriziosalmi/csv-anonymizer
GitHub: fabriziosalmi/csv-anonymizer
一款纯客户端运行的静态Web应用,通过对CSV文件中的敏感数据进行类型感知的模糊处理或隐藏来保护隐私。
Stars: 10 | Forks: 0
# CSV 匿名器
使用此静态 Web 应用直接在您的浏览器中对 CSV 文件进行匿名化处理。在智能地对敏感信息进行模糊处理或隐藏以保护隐私的同时,保留有价值的数据结构。
[](https://fabriziosalmi.github.io/csv-anonymizer/)
## 截图
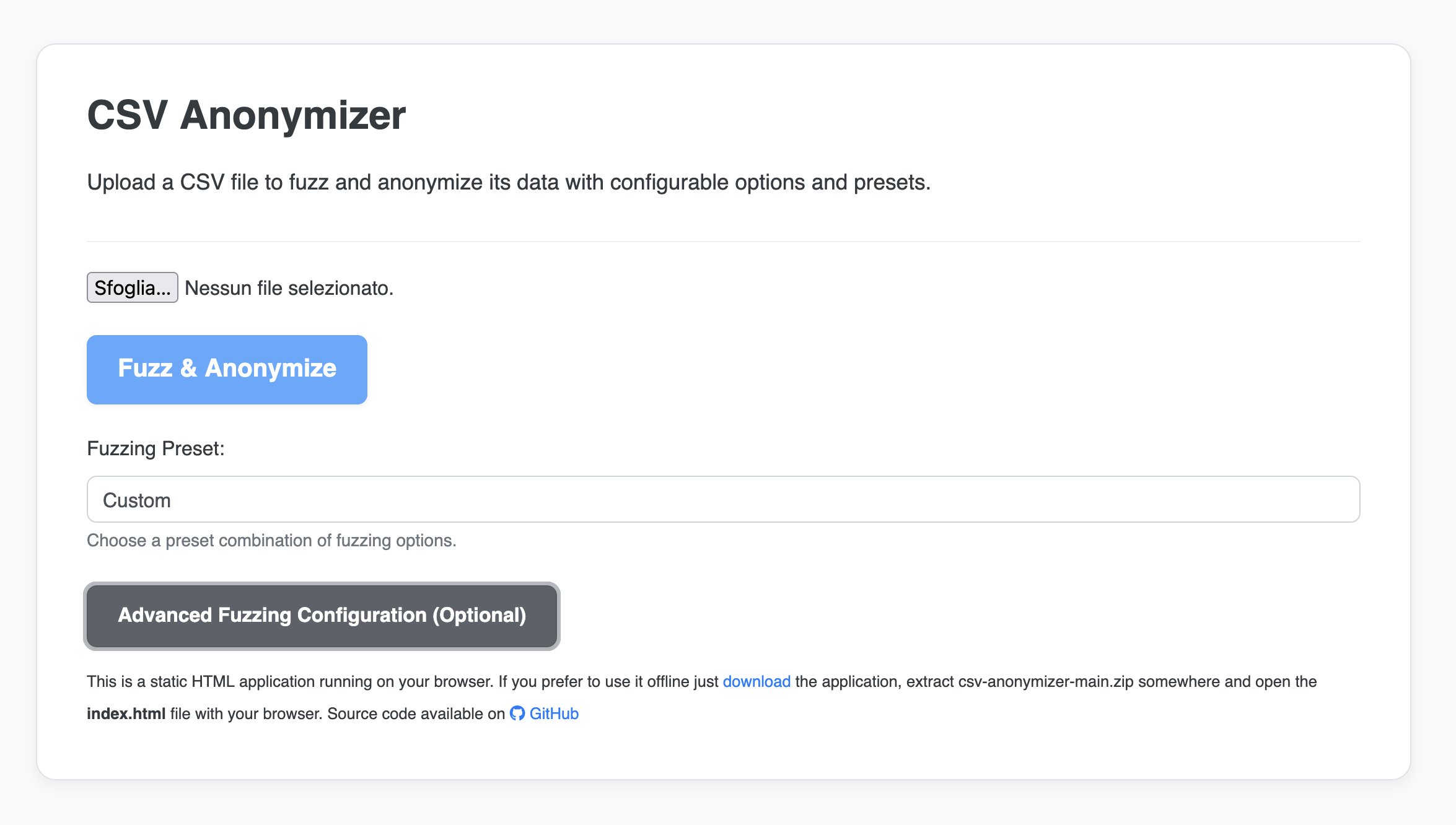
## ✨ 核心功能
* **🔒 客户端隐私:** 您的数据将完全保持私密。所有 CSV 处理和匿名化过程直接在您的 Web 浏览器中完成,确保不会将任何数据传输到服务器。
* **🗂️ 保持结构完整:** 维护 CSV 文件的完整性。该匿名化工具智能地修改现有结构*内部*的数据,保持列和格式一致。
* **🤩 类型感知的模糊处理与隐藏:** 超越简单的字符串替换。该工具理解不同的数据类型(数字、日期、电子邮件、URL、YouTube URL、地理坐标、地址、ID 和常规字符串),并对每种类型应用适当的匿名化技术。
* **🛠️ 高度可配置的匿名化:**
* **便捷预设:** 从“轻度”、“中度”或“激进”预设中进行选择,实现快速简便的匿名化级别。
* **高级自定义:** 通过“高级模糊配置”面板解锁细粒度控制。针对每种数据类型微调隐藏和模糊参数,以满足您特定的匿名化需求。
* **🛡️ 静态与无服务器应用:** 享受安全可靠的工具优势。作为静态 Web 应用程序,它完全在您的浏览器中运行,不依赖任何后端服务器,消除了数据传输和服务器端漏洞。
* **🚀 快速高效:** 直接在您的浏览器中体验快速的匿名化处理,无需承受将数据上传和下载到外部服务器所带来的延迟。
## 🚀 使用方法
1. **访问 CSV Anonymizer:**
* **在线打开:** 只需使用您喜欢的 Web 浏览器访问 [https://fabriziosalmi.github.io/csv-anonymizer/](https://fabriziosalmi.github.io/csv-anonymizer/)。
* **离线使用(本地执行):** 为了增强隐私或离线使用,您可以[以 ZIP 压缩包格式下载应用程序](https://github.com/fabriziosalmi/csv-anonymizer/archive/refs/heads/main.zip)。将 `csv-anonymizer-main.zip` 压缩包解压到您电脑上的一个文件夹中。然后,直接在您的浏览器中打开 `index.html` 文件(例如,通过双击该文件,或从浏览器的菜单中选择“文件 > 打开”)。
2. **上传您的 CSV 文件:** 在应用程序中找到“选择文件”按钮。点击它并从您的本地计算机中选择您打算进行匿名化处理的 `.csv` 文件。该工具接受标准的逗号分隔 CSV 文件。
3. **配置匿名化处理(推荐):**
* **选择模糊处理预设(快速设置):** 对于寻求快速直接方法的用户,请使用“模糊处理预设”下拉菜单。从三个预定义级别中进行选择:
* **轻度匿名化:** 应用细微的模糊处理,适用于数据效用至关重要且只需最少程度匿名化的场景。
* **中度匿名化:** 一种平衡的方法,在保护合理数据准确性的同时提供良好的隐私保护级别。适用于常规匿名化需求。
* **激进匿名化:** 通过应用更强的模糊处理和隐藏来最大化隐私。当匿名性至关重要时,请针对高度敏感的数据使用此选项,即使这会牺牲部分数据粒度。
* **自定义:** 如果您希望手动配置所有匿名化参数,请选择“自定义”。
* **高级模糊配置(细粒度控制):** 要对匿名化过程进行细粒度控制,请点击“高级模糊配置(可选)”按钮以展开高级设置面板。在这里,您可以自定义:
* **隐藏数字:** 勾选“隐藏数字”复选框,将 CSV 中所有检测到的数字值替换为文本 `REDACTED`。取消勾选则对数字应用模糊处理。
* **数字模糊因子:** 当禁用数字隐藏时,使用“数字模糊因子”滑块控制数字模糊处理的强度。较高的值会为原始数字引入更大的偏差。
* **隐藏日期:** 勾选“隐藏日期”以将日期值替换为 `REDACTED`。取消勾选则启用日期模糊处理。
* **日期变化范围(天):** 如果关闭了日期隐藏,请设置“日期变化范围(天)”,以定义日期可以随机变化的最大天数(包括 +/-)。
* **隐藏字符串(常规):** 启用“隐藏字符串(常规)”以将所有常规字符串值替换为 `REDACTED`。取消勾选则对常规字符串应用模糊处理。
* **字符串模糊概率(常规):** 当禁用常规字符串隐藏时,使用“字符串模糊概率(常规)”滑块调整常规文本字符串的模糊处理概率。较高的概率意味着字符串中会有更多的字符被模糊(修改)处理。
* **隐藏字符串(轻度):** 勾选“隐藏字符串(轻度)”以使用 `REDACTED` 隐藏被识别为“轻度字符串”(例如 ID、代码)的值。取消勾选则对这些字符串应用轻度模糊处理。
* **字符串模糊概率(轻度):** 当关闭轻度字符串隐藏时,使用“字符串模糊概率(轻度)”滑块控制轻度字符串的模糊处理概率。轻度模糊处理旨在减少干扰,适用于需要保留格式的 ID 和代码。
4. **启动匿名化:** 一旦您上传了 CSV 文件并根据自己的喜好配置了匿名化设置(或选择了预设),请点击显眼的“模糊与匿名化”按钮。应用程序将开始在您的浏览器中处理您的 CSV 数据。系统会临时显示一条“正在处理……请稍候。”的消息。
5. **下载您的匿名化 CSV:** 匿名化过程完成后,“正在处理……”消息将消失,并出现一个“下载模糊处理后的 CSV”按钮。点击此按钮下载您 CSV 文件的匿名化版本。下载的文件将被命名为 `fuzzed_data.csv`,并保存到您计算机的默认下载位置。
6. **安全分享您的数据:** 下载的 `fuzzed_data.csv` 文件现在包含您数据的匿名化版本。您可以放心地分享此文件,因为您知道敏感信息已根据您选择的设置进行了处理,在保留数据集的结构和分析价值的同时保护了个人隐私。
## ⚙️ 自定义选项 - 详细说明
* **模糊处理预设:** 对于需要快速入门或想要应用标准匿名化级别的用户,预设是最简单的选择。请选择:
* **轻度:** 应用最小的模糊处理,主要针对轻度字符串和微小的数字变化。通常禁用隐藏。最适用于低敏感度数据或数据效用至上的情况。
* **中度:** 一个平衡的预设,对数字、日期和字符串应用中等程度的模糊处理。默认情况下不进行隐藏。一种良好的通用匿名化级别。
* **激进:** 应用重度模糊处理,并对数字、日期和字符串启用隐藏。适用于需要强匿名化处理的高度敏感数据。
* **自定义:** 选择“自定义”以禁用预设并手动配置所有单独设置。这提供了最大的灵活性,可根据需求定制匿名化过程。
* **高级配置参数:** 对于需要精确控制的用户,“高级模糊配置”区域为每种数据类型提供了单独的参数:
* **隐藏数字(复选框):** 全局启用或禁用所有检测到的数字值的隐藏。勾选时,数字将被替换为 `REDACTED`。取消勾选时,数字将根据“数字模糊因子”进行模糊处理。
* **数字模糊因子(滑块):** 控制数字模糊处理的强度。值的范围从 0(无模糊)到 1(高模糊)。较高的值会为数字引入更大的随机偏差。
* **隐藏日期(复选框):** 启用或禁用所有检测到的日期的隐藏。勾选时,日期将被替换为 `REDACTED`。取消勾选时,日期将根据“日期变化范围(天)”进行模糊处理。
* **日期变化范围(天)(数字输入):** 定义日期可以随机变化的最大范围(以天为单位,包括向过去和向未来的时间)。
* **隐藏字符串(常规)(复选框):** 启用或禁用常规文本字符串(未识别为特定类型如电子邮件或 URL 的字符串)的隐藏。勾选时,常规字符串将被替换为 `REDACTED`。取消勾选时,常规字符串将根据“字符串模糊概率(常规)”进行模糊处理。
* **字符串模糊概率(常规)(滑块):** 控制对常规文本字符串应用模糊操作(插入、删除、替换、换位、重复)的概率。值越高,进行模糊处理的可能性就越大。
* **隐藏字符串(轻度)(复选框):** 启用或禁用“轻度字符串”的隐藏,这些字符串通常是较短的、类似标识符的字符串(例如 ID、代码)。勾选时,轻度字符串将被替换为 `REDACTED`。取消勾选时,轻度字符串将使用“字符串模糊概率(轻度)”进行模糊处理。
* **字符串模糊概率(轻度)(滑块):** 控制对轻度字符串应用*轻度*模糊操作(替换、换位、大小写翻转 - 保持长度不变)的概率。旨在比常规字符串模糊处理减少干扰,保留标识符的格式和长度。
* **隐藏与模糊处理策略:**
* **隐藏:** 完全移除原始数据值,将其替换为 `REDACTED`。这提供了强大的匿名化效果,但牺牲了这些特定字段的数据效用。当泄露原始数据的任何变体都是不可接受的时候,请对高度敏感的列使用隐藏。
* **模糊处理:** 通过引入微小的、受控的随机偏差来修改原始数据值。模糊处理旨在保留数据的统计属性和整体分布,同时降低单个值的可识别性。当您需要维持数据以进行分析和报告但同时又想对数据集进行匿名化处理时,请选择模糊处理。
## 📜 许可证
本项目是开源的,并在宽松的 [AGPL-3.0 许可证](https://www.gnu.org/licenses/agpl-3.0.en.html)下发布。您可以根据该许可证的条款自由使用、修改和分发本软件。
标签:CSV, 前端, 多模态安全, 数据可视化, 数据脱敏, 网络安全, 自定义脚本, 隐私保护, 静态网站