deepseek-ai/DeepSeek-V3
GitHub: deepseek-ai/DeepSeek-V3
DeepSeek-V3 是一个拥有 671B 参数的开源混合专家大语言模型,在多项基准测试中达到或超越顶尖闭源模型水平,以较低的训练成本提供了强大的通用推理、代码与数学能力。
Stars: 104025 | Forks: 16709

## 目录 1. [简介](#1-introduction) 2. [模型摘要](#2-model-summary) 3. [模型下载](#3-model-downloads) 4. [评估结果](#4-evaluation-results) 5. [对话网站与 API 平台](#5-chat-website--api-platform) 6. [如何在本地运行](#6-how-to-run-locally) 7. [许可证](#7-license) 8. [引用](#8-citation) 9. [联系方式](#9-contact) ## 1. 简介 我们推出了 DeepSeek-V3,这是一个强大的混合专家 语言模型,总参数量为 671B,每个 token 激活 37B 参数。 为了实现高效的推理和具有成本效益的训练,DeepSeek-V3 采用了在 DeepSeek-V2 中得到全面验证的多头潜在注意力 (MLA) 和 DeepSeekMoE 架构。 此外,DeepSeek-V3 首创了无辅助损失 的负载均衡策略,并设定了多 token 预测训练目标以实现更强的性能。 我们在 14.8 万亿个多样且高质量的 token 上对 DeepSeek-V3 进行了预训练,随后通过监督微调 和强化学习 阶段充分挖掘其能力。 全面评估表明,DeepSeek-V3 超越了其他开源模型,并取得了与领先的闭源模型相媲美的性能。 尽管性能卓越,DeepSeek-V3 的完整训练仅需 2.788M H800 GPU 小时。 此外,其训练过程非常稳定。 在整个训练过程中,我们没有经历任何不可恢复的损失峰值,也没有执行任何回滚操作。


| **模型** | **总参数量** | **激活参数量** | **上下文长度** | **下载** |
| :------------: | :------------: | :------------: | :------------: | :------------: |
| DeepSeek-V3-Base | 671B | 37B | 128K | [🤗 Hugging Face](https://huggingface.co/deepseek-ai/DeepSeek-V3-Base) |
| DeepSeek-V3 | 671B | 37B | 128K | [🤗 Hugging Face](https://huggingface.co/deepseek-ai/DeepSeek-V3) |
为了确保最佳的性能和灵活性,我们与开源社区和硬件供应商合作,提供了多种在本地运行模型的方法。 如需分步指南,请查看第 6 节:[如何在本地运行](#6-how-to-run-locally)。
对于希望深入研究的开发者,我们建议查看 [README_WEIGHTS.md](./README_WEIGHTS.md),了解有关主模型权重和多 token 预测 (MTP) 模块的详细信息。 请注意,社区目前正在积极开发 MTP 支持,我们欢迎您的贡献和反馈。
## 4. 评估结果
### 基座模型
#### 标准基准测试
| | 基准测试 (指标) | # Shots | DeepSeek-V2 | Qwen2.5 72B | LLaMA3.1 405B | DeepSeek-V3 |
|---|-------------------|----------|--------|-------------|---------------|---------|
| | 架构 | - | MoE | Dense | Dense | MoE |
| | # 激活参数量 | - | 21B | 72B | 405B | 37B |
| | # 总参数量 | - | 236B | 72B | 405B | 671B |
| 英语 | Pile-test (BPB) | - | 0.606 | 0.638 | **0.542** | 0.548 |
| | BBH (EM) | 3-shot | 78.8 | 79.8 | 82.9 | **87.5** |
| | MMLU (Acc.) | 5-shot | 78.4 | 85.0 | 84.4 | **87.1** |
| | MMLU-Redux (Acc.) | 5-shot | 75.6 | 83.2 | 81.3 | **86.2** |
| | MMLU-Pro (Acc.) | 5-shot | 51.4 | 58.3 | 52.8 | **64.4** |
| | DROP (F1) | 3-shot | 80.4 | 80.6 | 86.0 | **89.0** |
| | ARC-Easy (Acc.) | 25-shot | 97.6 | 98.4 | 98.4 | **98.9** |
| | ARC-Challenge (Acc.) | 25-shot | 92.2 | 94.5 | **95.3** | **95.3** |
| | HellaSwag (Acc.) | 10-shot | 87.1 | 84.8 | **89.2** | 88.9 |
| | PIQA (Acc.) | 0-shot | 83.9 | 82.6 | **85.9** | 84.7 |
| | WinoGrande (Acc.) | 5-shot | **86.3** | 82.3 | 85.2 | 84.9 |
| | RACE-Middle (Acc.) | 5-shot | 73.1 | 68.1 | **74.2** | 67.1 |
| | RACE-High (Acc.) | 5-shot | 52.6 | 50.3 | **56.8** | 51.3 |
| | TriviaQA (EM) | 5-shot | 80.0 | 71.9 | 82.7 | **82.9** |
| | NaturalQuestions (EM) | 5-shot | 38.6 | 33.2 | **41.5** | 40.0 |
| | AGIEval (Acc.) | 0-shot | 57.5 | 75.8 | 60.6 | **79.6** |
| 代码 | HumanEval (Pass@1) | 0-shot | 43.3 | 53.0 | 54.9 | **65.2** |
| | MBPP (Pass@1) | 3-shot | 65.0 | 72.6 | 68.4 | **75.4** |
| | LiveCodeBench-Base (Pass@1) | 3-shot | 11.6 | 12.9 | 15.5 | **19.4** |
| | CRUXEval-I (Acc.) | 2-shot | 52.5 | 59.1 | 58.5 | **67.3** |
| | CRUXEval-O (Acc.) | 2-shot | 49.8 | 59.9 | 59.9 | **69.8** |
| 数学 | GSM8K (EM) | 8-shot | 81.6 | 88.3 | 83.5 | **89.3** |
| | MATH (EM) | 4-shot | 43.4 | 54.4 | 49.0 | **61.6** |
| | MGSM (EM) | 8-shot | 63.6 | 76.2 | 69.9 | **79.8** |
| | CMath (EM) | 3-shot | 78.7 | 84.5 | 77.3 | **90.7** |
| 中文 | CLUEWSC (EM) | 5-shot | 82.0 | 82.5 | **83.0** | 82.7 |
| | C-Eval (Acc.) | 5-shot | 81.4 | 89.2 | 72.5 | **90.1** |
| | CMMLU (Acc.) | 5-shot | 84.0 | **89.5** | 73.7 | 88.8 |
| | CMRC (EM) | 1-shot | **77.4** | 75.8 | 76.0 | 76.3 |
| | C3 (Acc.) | 0-shot | 77.4 | 76.7 | **79.7** | 78.6 |
| | CCPM (Acc.) | 0-shot | **93.0** | 88.5 | 78.6 | 92.0 |
| 多语言 | MMMLU-non-English (Acc.) | 5-shot | 64.0 | 74.8 | 73.8 | **79.4** |
#### 上下文窗口
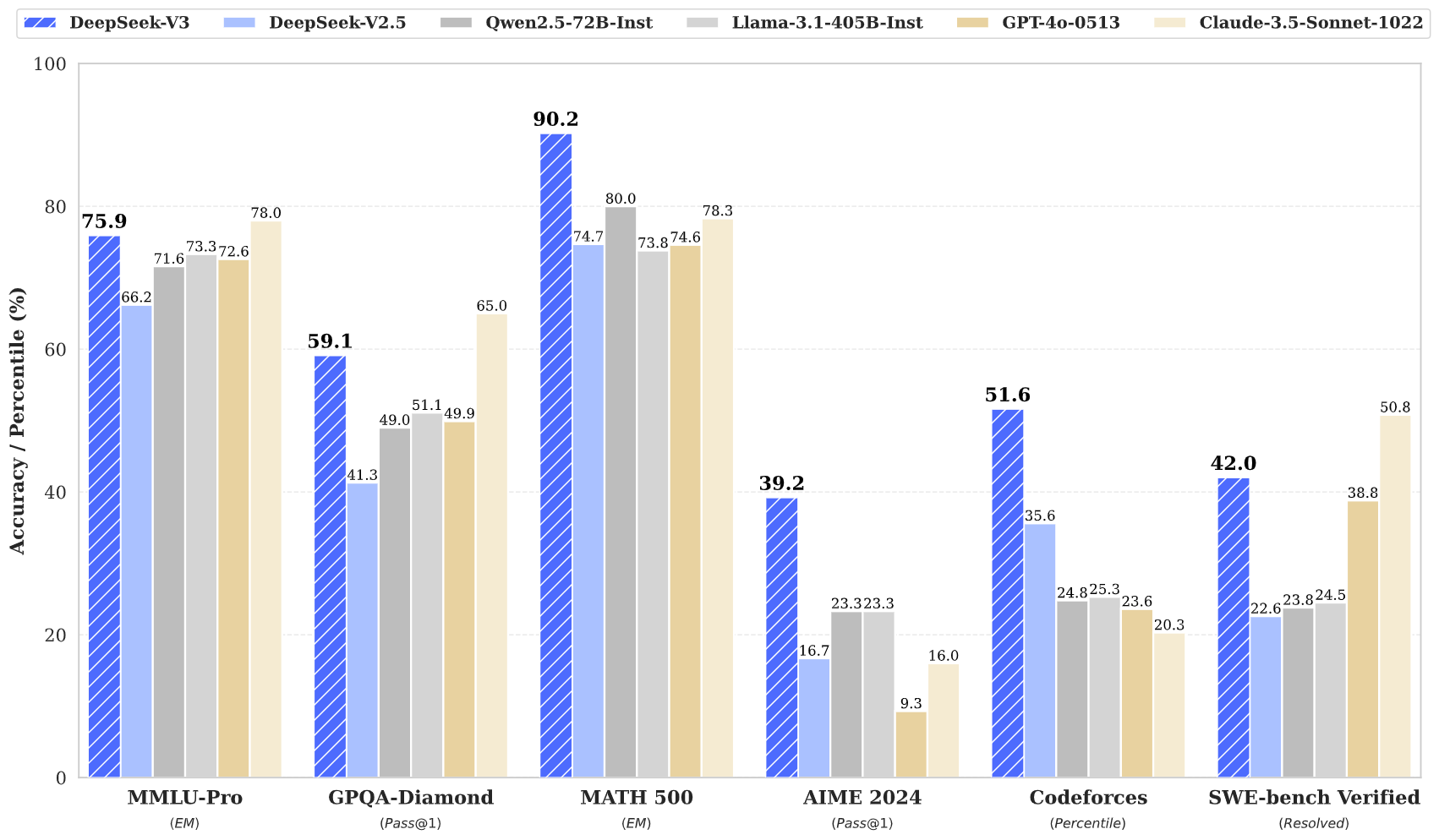
| | **基准测试 (指标)** | **DeepSeek V2-0506** | **DeepSeek V2.5-0905** | **Qwen2.5 72B-Inst.** | **Llama3.1 405B-Inst.** | **Claude-3.5-Sonnet-1022** | **GPT-4o 0513** | **DeepSeek V3** |
|---|---------------------|---------------------|----------------------|---------------------|----------------------|---------------------------|----------------|----------------|
| | 架构 | MoE | MoE | Dense | Dense | - | - | MoE |
| | # 激活参数量 | 21B | 21B | 72B | 405B | - | - | 37B |
| | # 总参数量 | 236B | 236B | 72B | 405B | - | - | 671B |
| 英语 | MMLU (EM) | 78.2 | 80.6 | 85.3 | **88.6** | **88.3** | 87.2 | **88.5** |
| | MMLU-Redux (EM) | 77.9 | 80.3 | 85.6 | 86.2 | **88.9** | 88.0 | **89.1** |
| | MMLU-Pro (EM) | 58.5 | 66.2 | 71.6 | 73.3 | **78.0** | 72.6 | 75.9 |
| | DROP (3-shot F1) | 83.0 | 87.8 | 76.7 | 88.7 | 88.3 | 83.7 | **91.6** |
| | IF-Eval (Prompt Strict) | 57.7 | 80.6 | 84.1 | 86.0 | **86.5** | 84.3 | 86.1 |
| | GPQA-Diamond (Pass@1) | 35.3 | 41.3 | 49.0 | 51.1 | **65.0** | 49.9 | 59.1 |
| | SimpleQA (Correct) | 9.0 | 10.2 | 9.1 | 17.1 | 28.4 | **38.2** | 24.9 |
| | FRAMES (Acc.) | 66.9 | 65.4 | 69.8 | 70.0 | 72.5 | **80.5** | 73.3 |
| LongBench v2 (Acc.) | 31.6 | 35.4 | 39.4 | 36.1 | 41.0 | 48.1 | **48.7** |
| 代码 | HumanEval-Mul (Pass@1) | 69.3 | 77.4 | 77.3 | 77.2 | 81.7 | 80.5 | **82.6** |
| | LiveCodeBench (Pass@1-COT) | 18.8 | 29.2 | 31.1 | 28.4 | 36.3 | 33.4 | **40.5** |
| | LiveCodeBench (Pass@1) | 20.3 | 28.4 | 28.7 | 30.1 | 32.8 | 34.2 | **37.6** |
| | Codeforces (Percentile) | 17.5 | 35.6 | 24.8 | 25.3 | 20.3 | 23.6 | **51.6** |
| | SWE Verified (Resolved) | - | 22.6 | 23.8 | 24.5 | **50.8** | 38.8 | 42.0 |
| | Aider-Edit (Acc.) | 60.3 | 71.6 | 65.4 | 63.9 | **84.2** | 72.9 | 79.7 |
| | Aider-Polyglot (Acc.) | - | 18.2 | 7.6 | 5.8 | 45.3 | 16.0 | **49.6** |
| 数学 | AIME 2024 (Pass@1) | 4.6 | 16.7 | 23.3 | 23.3 | 16.0 | 9.3 | **39.2** |
| | MATH-500 (EM) | 56.3 | 74.7 | 80.0 | 73.8 | 78.3 | 74.6 | **90.2** |
| | CNMO 2024 (Pass@1) | 2.8 | 10.8 | 15.9 | 6.8 | 13.1 | 10.8 | **43.2** |
| 中文 | CLUEWSC (EM) | 89.9 | 90.4 | **91.4** | 84.7 | 85.4 | 87.9 | 90.9 |
| | C-Eval (EM) | 78.6 | 79.5 | 86.1 | 61.5 | 76.7 | 76.0 | **86.5** |
| | C-SimpleQA (Correct) | 48.5 | 54.1 | 48.4 | 50.4 | 51.3 | 59.3 | **64.8** |
#### 开放式生成评估
| 模型 | Arena-Hard | AlpacaEval 2.0 |
|-------|------------|----------------|
| DeepSeek-V2.5-0905 | 76.2 | 50.5 |
| Qwen2.5-72B-Instruct | 81.2 | 49.1 |
| LLaMA-3.1 405B | 69.3 | 40.5 |
| GPT-4o-0513 | 80.4 | 51.1 |
| Claude-Sonnet-3.5-1022 | 85.2 | 52.0 |
| DeepSeek-V3 | **85.5** | **70.0** |
## 5. 对话网站与 API 平台
您可以在 DeepSeek 官方网站与 DeepSeek-V3 进行对话:[chat.deepseek.com](https://chat.deepseek.com/sign_in)
我们还在 DeepSeek 平台提供了兼容 OpenAI 的 API:[platform.deepseek.com](https://platform.deepseek.com/)
## 6. 如何在本地运行
DeepSeek-V3 可以使用以下硬件和开源社区软件在本地部署:
1. **DeepSeek-Infer Demo**:我们提供了一个简单轻量的 FP8 和 BF16 推理演示。
2. **SGLang**:完全支持在 BF16 和 FP8 推理模式下运行 DeepSeek-V3 模型,多 token 预测支持即将[推出](https://github.com/sgl-project/sglang/issues/2591)。
3. **LMDeploy**:支持高效的 FP8 和 BF16 推理,适用于本地和云端部署。
4. **TensorRT-LLM**:目前支持 BF16 推理和 INT4/8 量化,即将支持 FP8。
5. **vLLM**:支持具有 FP8 和 BF16 模式的 DeepSeek-V3 模型,适用于张量并行和流水线并行。
6. **LightLLM**:支持 FP8 和 BF16 的高效单节点或多节点部署。
7. **AMD GPU**:支持通过 SGLang 在 AMD GPU 上以 BF16 和 FP8 模式运行 DeepSeek-V3 模型。
8. **Huawei Ascend NPU**:支持在华为昇腾设备上以 INT8 和 BF16 运行 DeepSeek-V3。
由于我们的框架原生采用了 FP8 训练,因此我们仅提供 FP8 权重。 如果您出于实验目的需要 BF16 权重,可以使用提供的转换脚本进行转换。
以下是将 FP8 权重转换为 BF16 的示例:
```
cd inference
python fp8_cast_bf16.py --input-fp8-hf-path /path/to/fp8_weights --output-bf16-hf-path /path/to/bf16_weights
```
### 6.1 使用 DeepSeek-Infer Demo 进行推理(仅作示例)
#### 系统要求
依赖项:
```
torch==2.4.1
triton==3.0.0
transformers==4.46.3
safetensors==0.4.5
```
#### 模型权重与演示代码准备
首先,克隆我们的 DeepSeek-V3 GitHub 仓库:
```
git clone https://github.com/deepseek-ai/DeepSeek-V3.git
```
导航到 `inference` 文件夹并安装 `requirements.txt` 中列出的依赖项。 最简单的方法是使用像 `conda` 或 `uv` 这样的包管理器来创建一个新的虚拟环境并安装依赖项。
```
cd DeepSeek-V3/inference
pip install -r requirements.txt
```
从 Hugging Face 下载模型权重,并将它们放入 `/path/to/DeepSeek-V3` 文件夹中。
#### 模型权重转换
将 Hugging Face 模型权重转换为特定格式:
```
python convert.py --hf-ckpt-path /path/to/DeepSeek-V3 --save-path /path/to/DeepSeek-V3-Demo --n-experts 256 --model-parallel 16
```
#### 运行
然后您就可以与 DeepSeek-V3 进行对话了:
```
torchrun --nnodes 2 --nproc-per-node 8 --node-rank $RANK --master-addr $ADDR generate.py --ckpt-path /path/to/DeepSeek-V3-Demo --config configs/config_671B.json --interactive --temperature 0.7 --max-new-tokens 200
```
或者对给定文件进行批量推理:
```
torchrun --nnodes 2 --nproc-per-node 8 --node-rank $RANK --master-addr $ADDR generate.py --ckpt-path /path/to/DeepSeek-V3-Demo --config configs/config_671B.json --input-file $FILE
```
### 6.2 使用 SGLang 进行推理(推荐)
[SGLang](https://github.com/sgl-project/sglang) 目前支持 [MLA 优化](https://lmsys.org/blog/2024-09-04-sglang-v0-3/#deepseek-multi-head-latent-attention-mla-throughput-optimizations)、[DP Attention](https://lmsys.org/blog/2024-12-04-sglang-v0-4/#data-parallelism-attention-for-deepseek-models)、FP8 (W8A8)、FP8 KV Cache 和 Torch Compile,在开源框架中提供了最先进的延迟和吞吐量性能。
值得注意的是,[SGLang v0.4.1](https://github.com/sgl-project/sglang/releases/tag/v0.4.1) 完全支持在 **NVIDIA 和 AMD GPU** 上运行 DeepSeek-V3,使其成为一个高度通用且稳健的解决方案。
SGLang 还支持[多节点张量并行](https://github.com/sgl-project/sglang/tree/main/benchmark/deepseek_v3#example-serving-with-2-h208),使您能够在多台通过网络连接的机器上运行此模型。
多 token 预测 (MTP) 正在开发中,可以在[优化计划](https://github.com/sgl-project/sglang/issues/2591)中跟踪进度。
以下是 SGLang 团队提供的启动说明:https://github.com/sgl-project/sglang/tree/main/benchmark/deepseek_v3
### 6.3 使用 LMDeploy 进行推理(推荐)
[LMDeploy](https://github.com/InternLM/lmdeploy) 是一个专为大型语言模型量身定制的灵活且高性能的推理和服务框架,现已支持 DeepSeek-V3。 它提供离线管道处理和在线部署功能,可与基于 PyTorch 的工作流无缝集成。
有关使用 LMDeploy 运行 DeepSeek-V3 的全面分步说明,请参阅此处:https://github.com/InternLM/lmdeploy/issues/2960
### 6.4 使用 TRT-LLM 进行推理(推荐)
[TensorRT-LLM](https://github.com/NVIDIA/TensorRT-LLM) 现已支持 DeepSeek-V3 模型,提供 BF16 和 INT4/INT8 仅限权重等精度选项。 对 FP8 的支持目前正在开发中,即将发布。 您可以通过以下链接访问专门用于 DeepSeek-V3 支持的 TRTLLM 自定义分支,以直接体验新功能:https://github.com/NVIDIA/TensorRT-LLM/tree/main/examples/deepseek_v3。
### 6.5 使用 vLLM 进行推理(推荐)
[vLLM](https://github.com/vllm-project/vllm) v0.6.6 支持在 NVIDIA 和 AMD GPU 上以 FP8 和 BF16 模式进行 DeepSeek-V3 推理。 除了标准技术外,vLLM 还提供 _流水线并行_,允许您在通过连接网络的多台机器上运行此模型。 有关详细指南,请参阅 [vLLM 说明](https://docs.vllm.ai/en/latest/serving/distributed_serving.html)。 也欢迎关注[增强计划](https://github.com/vllm-project/vllm/issues/11539)。
### 6.6 使用 LightLLM 进行推理(推荐)
[LightLLM](https://github.com/ModelTC/lightllm/tree/main) v1.0.1 支持 DeepSeek-R1 (FP8/BF16) 的单机多机张量并行部署,并提供混合精度部署,更多量化模式正在不断集成。 更多详情,请参阅 [LightLLM 说明](https://lightllm-en.readthedocs.io/en/latest/getting_started/quickstart.html)。 此外,LightLLM 为 DeepSeek-V2 提供了 PD 分离部署,DeepSeek-V3 的 PD 分离部署正在开发中。
### 6.7 推荐的 AMD GPU 推理功能
我们与 AMD 团队合作,使用 SGLang 实现了对 AMD GPU 的首日支持,完全兼容 FP8 和 BF16 精度。 有关详细指南,请参阅 [SGLang 说明](#63-inference-with-lmdeploy-recommended)。
### 6.8 推荐的华为昇腾 NPU 推理功能
来自华为昇腾社区的 [MindIE](https://www.hiascend.com/en/software/mindie) 框架已成功适配 DeepSeek-V3 的 BF16 版本。 如需昇腾 NPU 的分步指南,请遵循[此处的说明](https://modelers.cn/models/MindIE/deepseekv3)。
## 7. 许可证
此代码仓库根据 [MIT 许可证](LICENSE-CODE) 授权。 DeepSeek-V3 Base/Chat 模型的使用受[模型许可证](LICENSE-MODEL)约束。 DeepSeek-V3 系列(包括 Base 和 Chat)支持商业使用。
## 8. 引用
```
@misc{deepseekai2024deepseekv3technicalreport,
title={DeepSeek-V3 Technical Report},
author={DeepSeek-AI},
year={2024},
eprint={2412.19437},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.19437},
}
```
## 9. 联系方式
如果您有任何问题,请提出 issue 或通过 [service@deepseek.com](service@deepseek.com) 联系我们。标签:AGI, AI技术, AI模型, Apex, DeepSeek, DeepSeek-V3, DLL 劫持, Hugging Face, LLM, MoE架构, NLP, Transformer, Unmanaged PE, 人工智能, 凭据扫描, 大语言模型, 开源大模型, 开源模型, 机器学习, 深度学习, 混合专家模型, 熵值分析, 用户模式Hook绕过, 预训练模型