Ghassan-elsman/Crow-Eye
GitHub: Ghassan-elsman/Crow-Eye
集成化 Windows 取证分析平台,通过友好的 GUI 界面和双模式关联引擎,一站式收集、解析和关联十余种 Windows 系统痕迹,助力事件响应与数字调查。
Stars: 97 | Forks: 6
# Crow Eye - Windows 取证引擎
\NTUSER.DAT` 的 `NTUSER.DAT`
- 来自 `C:\Windows\System32\config\SOFTWARE` 的 `SOFTWARE`
- 来自 `C:\Windows\System32\config\SYSTEM` 的 `SYSTEM`
**重要提示:**
- Windows 在运行期间会锁定这些注册表文件。
- 要对实时系统进行自定义注册表分析,您必须:
- 从外部媒体启动(WinPE/Live CD)。
- 使用取证采集工具。
- 分析磁盘镜像。
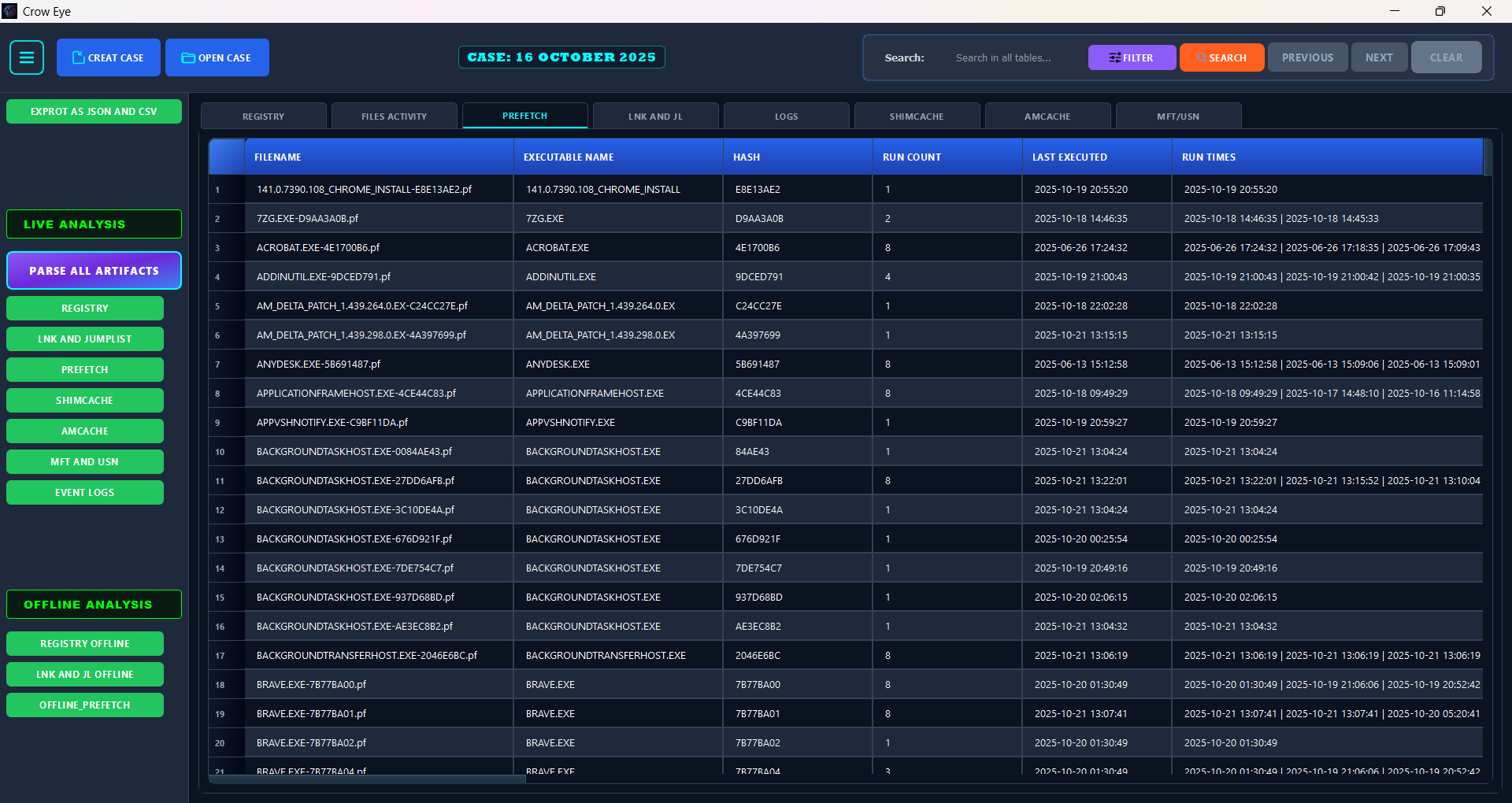
### Prefetch 文件分析
- 自动从 `C:\Windows\Prefetch` 解析 prefetch 文件。
- 提取执行历史记录和其他取证元数据。
### Event Logs 分析
- 自动解析 Windows 事件日志。
- 日志被保存到数据库中以进行全面分析。
### ShellBags 分析
- 解析 ShellBags 痕迹以揭示文件夹访问历史和用户导航模式。
### Recycle Bin 解析器
- 解析 Recycle Bin ($RECYCLE.BIN) 以恢复已删除文件的元数据。
- 提取原始文件名、路径、删除时间和大小。
- 支持从实时系统和磁盘镜像中恢复。
### MFT 解析器
- 解析 Master File Table (MFT) 以获取文件系统元数据。
- 提取文件属性、时间戳和已删除文件信息。
- 支持 Windows 7/10/11 上的 NTFS 文件系统。
### USN Journal 解析器
- 解析 USN (Update Sequence Number) Journal 以获取文件更改事件。
- 跟踪带有时间戳的文件创建、删除和修改。
- 与其他痕迹关联以进行时间轴重建。
存储取证分析器
- 每个物理磁盘及其分区的完整树状视图
- 颜色编码的分区类型(EFI=蓝色,Linux=紫色,Recovery=橙色,Hidden=交换区/红色等)
- 针对可启动 USB、隐藏的 Linux 根目录和 Intel Rapid Start 的警告
- 原始扇区 magic 扫描回退机制
## 文档与贡献
### 常规文档
- **[README.md](README.md)**:项目概述、愿景、功能和使用指南(本文档)
- **[TECHNICAL_DOCUMENTATION.md](TECHNICAL_DOCUMENTATION.md)**:完整的技术文档,包括架构、组件和开发指南
- **[CONTRIBUTING.md](CONTRIBUTING.md)**:贡献指南、编码规范和开发工作流
- **[timeline/ARCHITECTURE.md](timeline/ARCHITECTURE.md)**:详细的时间轴模块架构
### 🔥 关联引擎文档与贡献
关联引擎是我们最活跃的开发领域,拥有详尽的文档:
**文档**(约 10,000 行):
- **[关联引擎概述](correlation_engine/docs/CORRELATION_ENGINE_OVERVIEW.md)** - 带有架构图的系统概述
- **[引擎文档](correlation_engine/docs/engine/ENGINE_DOCUMENTATION.md)** - 双引擎架构、引擎选择指南、性能优化
- **[架构文档](correlation_engine/ARCHITECTURE.md)** - 组件集成和数据流
**[Feather 文档](correlation_engine/docs/feather/FEATHER_DOCUMENTATION.md)** - 数据规范化系统
- **[Wings 文档](correlation_engine/docs/wings/WINGS_DOCUMENTATION.md)** - 关联规则
- **[Pipeline 文档](correlation_engine/docs/pipeline/PIPELINE_DOCUMENTATION.md)** - 工作流编排
- **[痕迹类型注册表](correlation_engine/docs/config/ARTIFACT_TYPE_REGISTRY.md)** - 集中式痕迹类型定义
- **[权重优先级](correlation_engine/docs/config/WEIGHT_PRECEDENCE.md)** - 权重解析层级
- **[配置重载](correlation_engine/docs/config/CONFIGURATION_RELOAD.md)** - 实时配置更新
- **[集成接口](correlation_engine/docs/integration/INTEGRATION_INTERFACES.md)** - 依赖注入和测试
**贡献**:
- **[关联引擎贡献指南](correlation_engine/CONTRIBUTING.md)** - 优先领域、开发状态以及如何贡献
**快速链接**:
- [引擎选择指南](correlation_engine/docs/engine/ENGINE_DOCUMENTATION.md#engine-selection-guide) - 选择合适的引擎
- [故障排除指南](correlation_engine/docs/engine/ENGINE_DOCUMENTATION.md#troubleshooting) - 常见问题及解决方案
- [性能优化](correlation_engine/docs/engine/ENGINE_DOCUMENTATION.md#performance-and-optimization) - 优化关联
### 致贡献者
面向开发者和贡献者:
- **常规贡献**:请查阅[主贡献指南](CONTRIBUTING.md)
- **关联引擎贡献**(优先领域):请参阅[关联引擎贡献指南](correlation_engine/CONTRIBUTING.md)
- 在提交 pull request 之前,请先查阅技术文档
## 技术说明
- 该工具结合了 JumpList_Lnk_Parser Python 模块的修改版本。
- 注册表解析需要完整的注册表配置单元文件。
- 由于 Windows 的文件锁定机制,某些痕迹需要特殊处理。
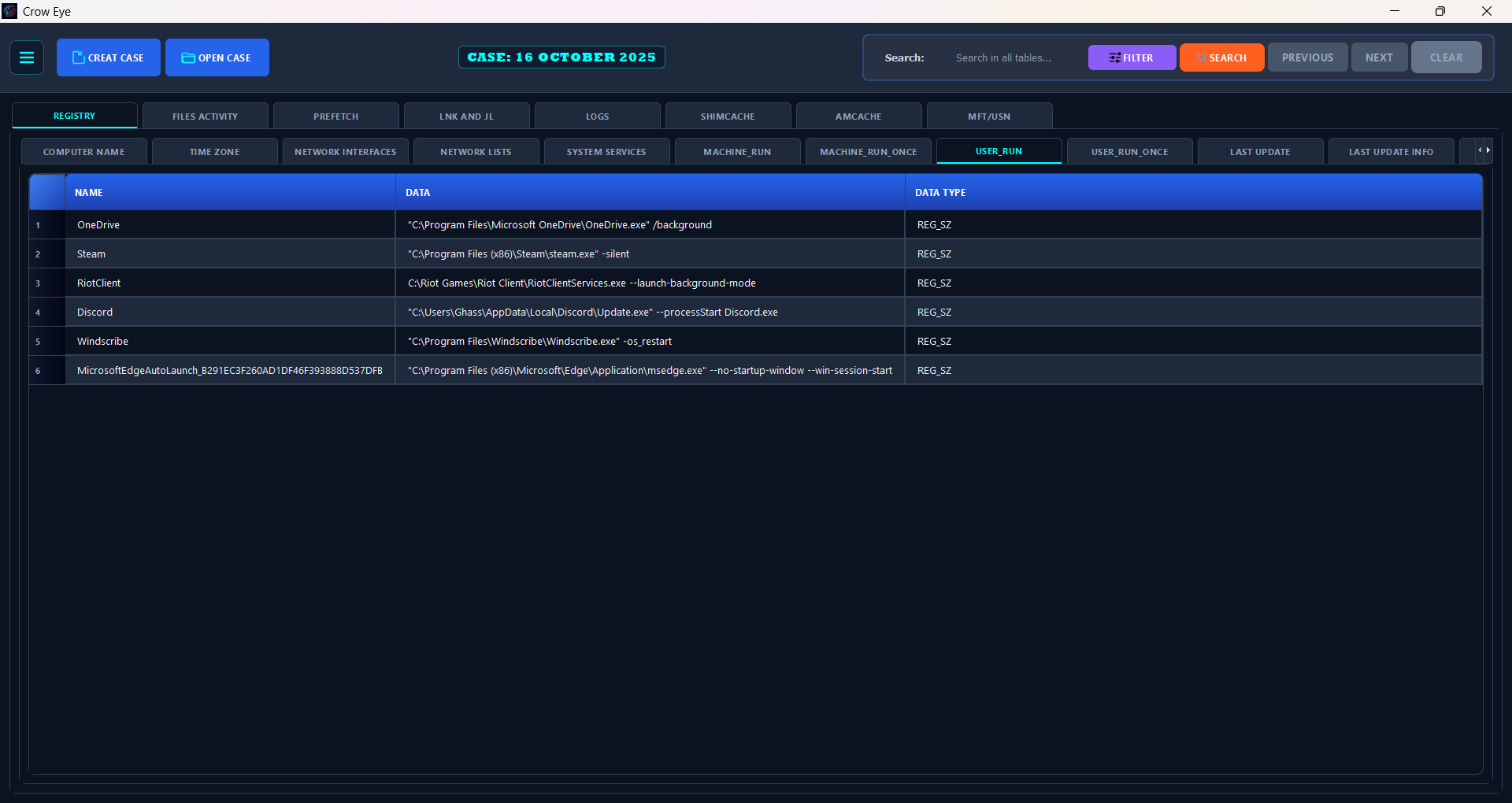
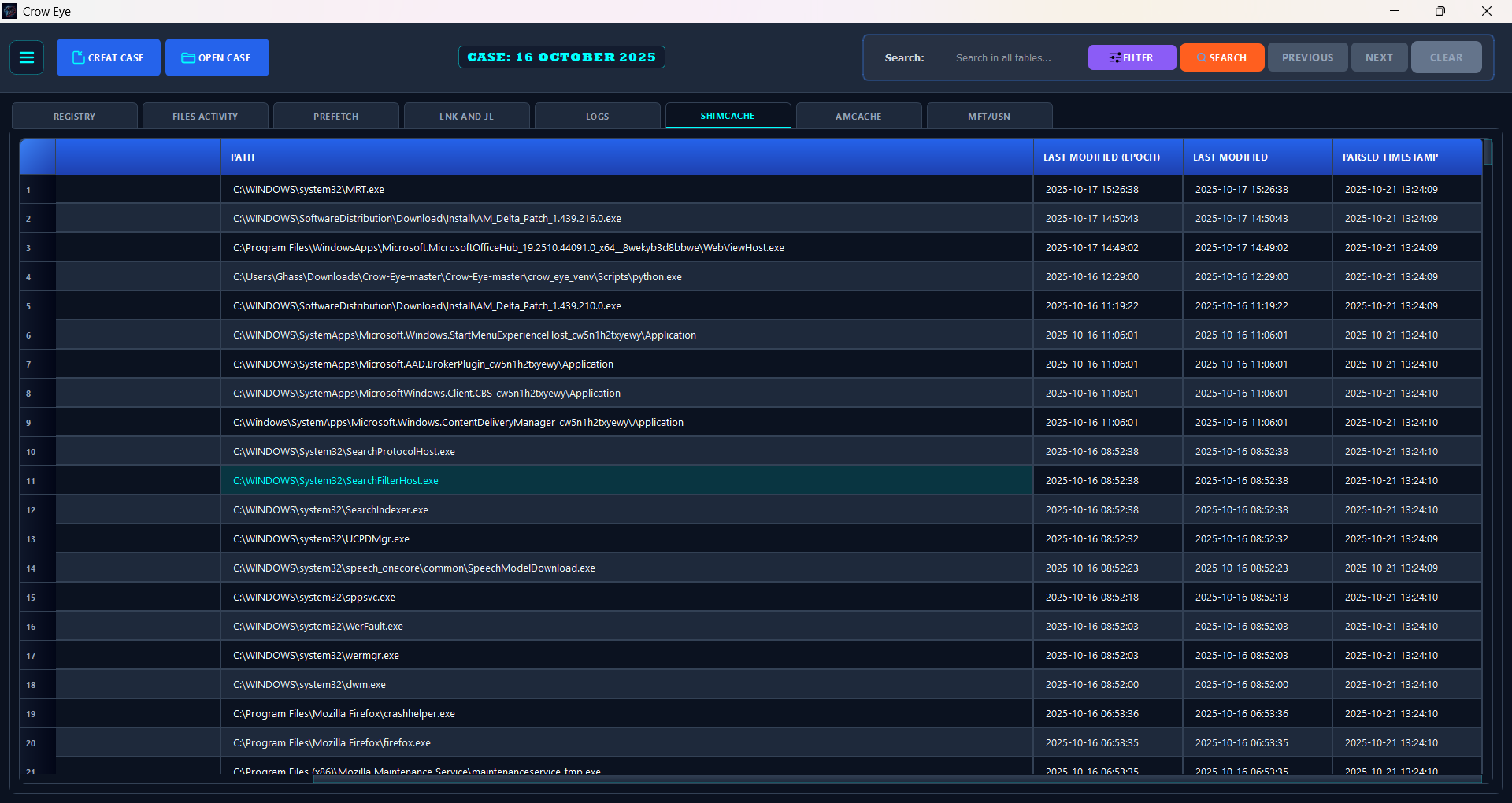
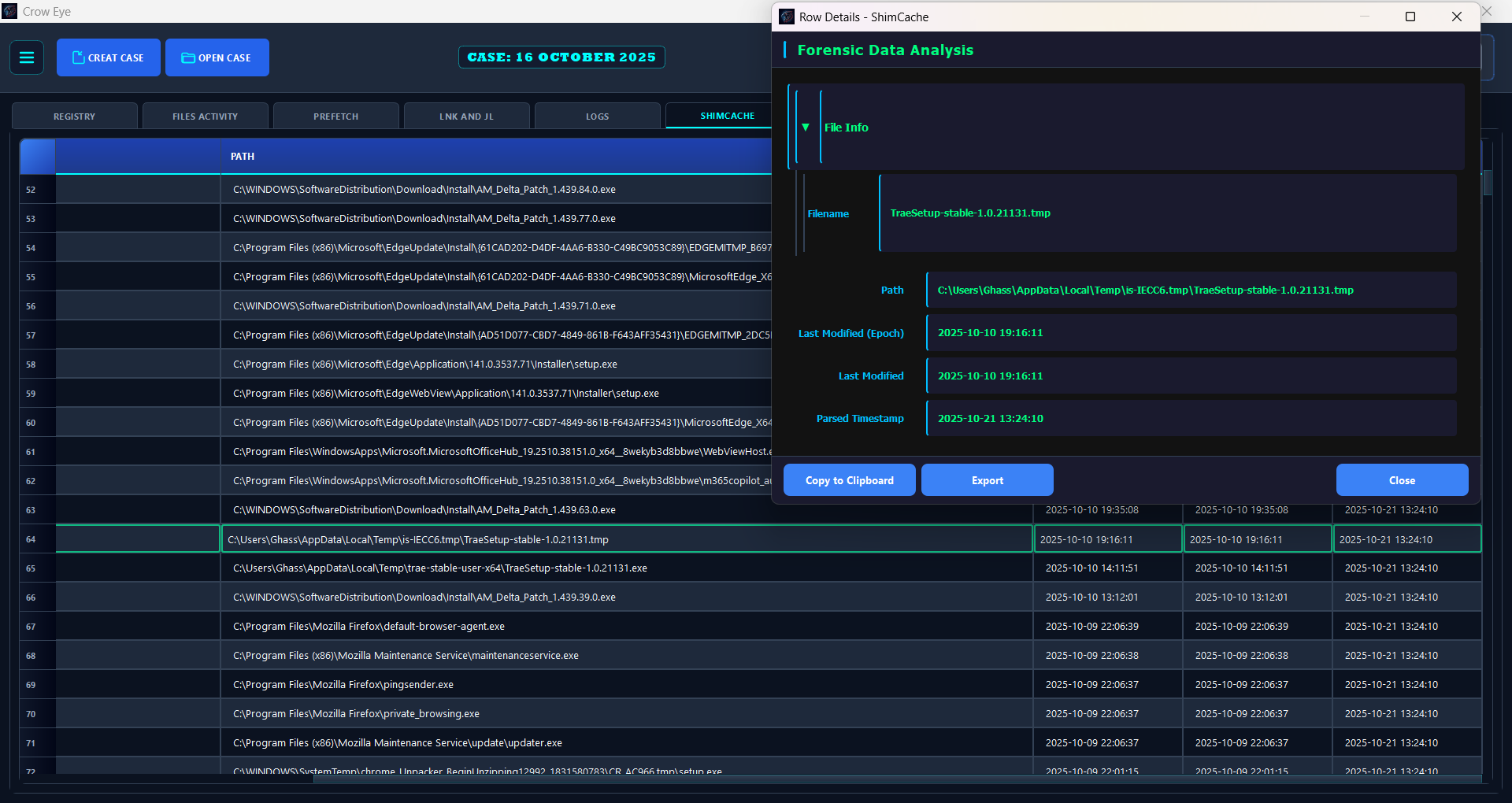
## 截图


## 🌐 官方网站
访问我们的官方网站:[https://crow-eye.com/](https://crow-eye.com/)
如需更多资源、文档和更新,请查看我们的专属网站。
## 🧩 关联引擎
**Crow-Eye 关联引擎**是一个关联系统,旨在收集各种痕迹并将它们关联成有意义的联系。它开箱即用,带有默认的关联规则,同时也允许用户根据自己的具体调查需求构建自定义规则。
### 🎥 用户指南
[](https://youtu.be/NxuoFrZvVHE?si=VWlQgFicIqzwxQd2)
该引擎在不同类型的取证痕迹之间寻找时间和语义上的关系,通过关联来自多个来源的数据,帮助调查人员发现系统上发生的事件之间的联系。
**通用数据导入**:关联引擎可以接收**任何取证工具**以 CSV、JSON 或 SQLite 格式输出的数据,并将其转换为 Feather 数据库。这意味着您可以将来自第三方工具(Plaso、Autopsy、Volatility 等)的数据与 Crow-Eye 的原生痕迹进行关联,从而跨所有取证数据源创建统一的关联分析。
### ✅ 生产就绪状态
关联引擎已经**生产就绪**,并正积极应用于取证调查中:
**当前状态**:
- ✅ **Feather Builder**:生产就绪 - 从任何工具导入 CSV/JSON/SQLite
- ✅ **Wings 系统**:生产就绪 - 创建和管理关联规则
- ✅ **Pipeline 编排**:生产就绪 - 自动化关联工作流
- ✅ **基于身份的引擎**:生产就绪 - 推荐用于身份追踪 (O(N log N))
- ⭐ **时间窗口扫描引擎**:生产就绪 - 推荐用于基于时间的分析 (O(N log N))
- 🔄 **身份提取器**:正在运行,并正在改进以提高准确性
- 🔄 **语义映射**:正在积极实现中
- 🔄 **关联评分**:正在积极实现中
**建议**:
- ⭐ **使用时间窗口扫描引擎**进行基于时间的痕迹分析(生产就绪,O(N log N))
- ✅ **使用基于身份的引擎**进行身份追踪和过滤(生产就绪,O(N log N))
- 📊 **Feather Builder** 稳定且满足所有数据导入需求
- 🎯 **Wings 和 Pipelines** 已生产就绪
**我们正在努力的方向**:
- 提高跨更多痕迹类型的身份提取准确性
- 实施全面的语义字段映射
- 完善关联评分算法
- 改善性能和优化
该系统已生产就绪并正在不断改进中。欢迎反馈和贡献!
### 核心功能
- **🔄 双引擎架构**:在时间窗口扫描 (O(N log N)) 和基于身份的 (O(N log N)) 关联策略之间进行选择
- **📊 多痕迹支持**:关联 Prefetch、ShimCache、AmCache、Event Logs、LNK 文件、Jumplists、MFT、SRUM、Registry 等
- **🔌 通用导入**:从任何取证工具导入 CSV/JSON/SQLite 输出并转换为 Feather 数据库
- **🎯 身份追踪**:跨多个痕迹追踪应用程序和文件
- **⚡ 高性能**:以流式模式处理数百万条记录
- **🔍 灵活的规则**:使用可配置参数定义自定义关联规则
- **🎨 专业的 UI**:带有时间轴可视化的赛博朋克风格界面
### 系统架构
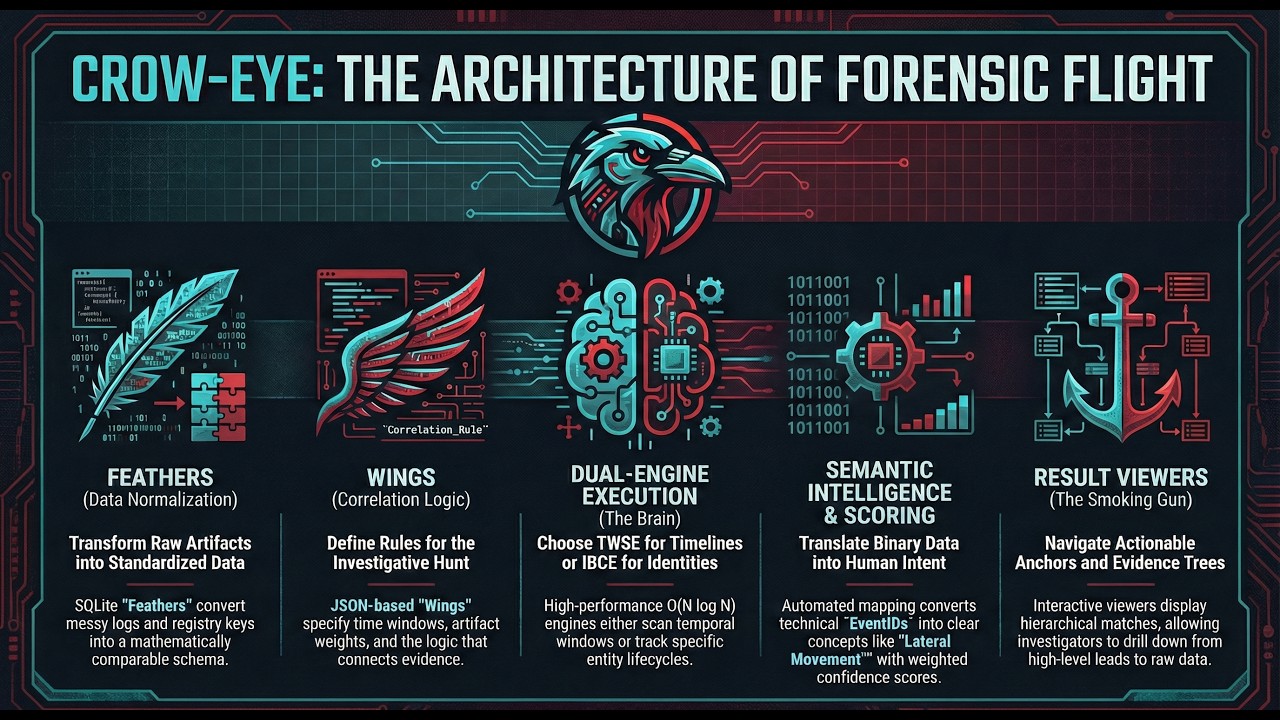
关联引擎由四个主要组件组成:
#### 1. 🗄️ Feathers(数据规范化)
**目的**:将原始取证痕迹转换为标准化、可查询的格式。
**它们是什么**:
- 包含规范化取证痕迹数据的 SQLite 数据库
- 每个 feather 代表一种痕迹类型(例如,Prefetch、ShimCache、Event Logs)
- 具有用于高效查询的元数据标准化 schema
- 接受来自任何取证工具数据的**通用格式**
**它们如何工作**:
```
Any Tool Output → Feather Builder → Normalized Feather Database
(CSV/JSON/SQLite) (SQLite with standard schema)
Examples:
- Plaso CSV → Feather Builder → timeline.db
- Autopsy JSON → Feather Builder → autopsy_artifacts.db
- Volatility CSV → Feather Builder → memory_artifacts.db
- Custom Tool Output → Feather Builder → custom.db
```
**核心特性**:
- **多源导入**:来自任何工具的 SQLite 数据库、CSV 文件、JSON 文件
- 自动列映射和数据类型检测
- 时间戳规范化为 ISO 格式
- 数据验证和错误处理
- 用于快速关联的优化索引
**支持的导入格式**:
- **CSV**:任何带有标题的 CSV 文件(来自 Plaso、Excel 导出、自定义脚本等)
- **JSON**:来自任何取证工具的扁平或嵌套 JSON
- **SQLite**:直接从其他 SQLite 数据库导入
**示例**:
```
prefetch.db (Feather)
├── feather_metadata (artifact type, source, record count)
├── prefetch_data (executable_name, path, last_executed, hash)
└── Indexes (timestamp, name, path)
```
#### 2. 🎯 Wings(关联规则)
**目的**:定义要关联哪些痕迹以及如何关联它们。
**它们是什么**:
- 指定关联规则的 JSON/YAML 配置文件
- 定义时间窗口、最小匹配数和 feather 关系
- 可跨不同案件和数据集重用
**核心组件**:
- **关联规则**:时间窗口、最小匹配数、锚点优先级
- **Feather 规格**:要关联哪些 feathers、权重、要求
- **过滤器**:可选的时间段或身份过滤器
**Wing 示例**:
```
{
"wing_id": "execution-proof",
"wing_name": "Execution Proof",
"correlation_rules": {
"time_window_minutes": 5,
"minimum_matches": 2,
"anchor_priority": ["Prefetch", "SRUM", "AmCache"]
},
"feathers": [
{"feather_id": "prefetch", "weight": 0.4},
{"feather_id": "shimcache", "weight": 0.3},
{"feather_id": "amcache", "weight": 0.3}
]
}
```
#### 3. ⚙️ 引擎(关联策略)
**目的**:执行关联逻辑以查找痕迹之间的关系。
关联引擎提供两种不同的策略:
##### 时间窗口扫描引擎
**最适用于**:基于时间的痕迹分析、系统性的时间关联、生产环境
**工作原理**:
1. 从 2000 年开始以固定间隔系统地扫描时间
2. 对于每个时间窗口,收集所有 feathers 的记录
3. 应用语义字段匹配和加权评分
4. 使用 MatchSet 跟踪防止重复
5. 返回带有置信度分数的关联匹配
**复杂度**:O(N log N),其中 N = 记录数(已索引的时间戳查询)
**核心特性**:
- 具有固定时间窗口的系统时间分析
- 支持带有强大索引的通用时间戳格式
- 用于高性能的批处理(2,567 个窗口/秒)
- 智能缓存的内存高效管理
- 针对基于时间的调查已生产就绪
##### 基于身份的关联引擎
**最适用于**:大型数据集(> 1,000 条记录)、生产环境、身份追踪
**工作原理**:
1. 从所有记录中提取并规范化身份信息
2. 按身份(应用程序/文件)对记录进行分组
3. 在每个身份集群内创建时间锚点
4. 将证据分类为主要、次要或支持性证据
5. 返回以身份为中心的关联结果
**复杂度**:O(N log N),其中 N = 记录数
**核心特性**:
- 每种类型具有 40 多种字段模式的身份提取
- 多 feather 身份分组
- 时间锚点聚类
- 针对大型数据集的流式模式(> 5,000 个锚点)
- 流式模式下的恒定内存使用
- 身份过滤支持
**引擎选择**:
- **基于时间的分析**:使用时间窗口扫描引擎(生产就绪,O(N log N))
- **身份追踪**:使用基于身份的引擎(生产就绪,O(N log N))
- 两个引擎均针对带有索引查询的大型数据集进行了优化
#### 4. 🔄 Pipelines(工作流编排)
**目的**:自动化从 feather 创建到生成结果的完整分析工作流。
**它们是什么**:
- 将所有内容连接在一起的编排层
- 自动化 feather 创建、wing 执行和报告生成
- 支持多个 wings 和复杂的工作流
**Pipeline 工作流**:
1. **加载配置**:读取带有引擎类型、wings、feathers 的 pipeline 配置
2. **创建引擎**:使用 EngineSelector 实例化适当的引擎
3. **执行 Wings**:针对指定的 feathers 运行每个 wing
4. **收集结果**:聚合来自所有 wings 的关联匹配
5. **生成报告**:将结果保存到数据库和 JSON 文件中
6. **显示结果**:在 GUI 中展示,并提供过滤和可视化功能
**Pipeline 示例**:
```
{
"pipeline_name": "Investigation Pipeline",
"engine_type": "identity_based",
"wings": [
{"wing_id": "execution-proof"},
{"wing_id": "file-access"}
],
"feathers": [
{"feather_id": "prefetch", "database_path": "data/prefetch.db"},
{"feather_id": "srum", "database_path": "data/srum.db"},
{"feather_id": "eventlogs", "database_path": "data/eventlogs.db"}
],
"filters": {
"time_period_start": "2024-01-01T00:00:00",
"time_period_end": "2024-12-31T23:59:59"
}
}
```
### 一切如何协同工作
```
1. Data Preparation
Raw Forensic Data → Feather Builder → Feather Databases
2. Configuration
Wing Configs + Feather References → Pipeline Config
3. Execution
Pipeline Executor → Engine Selector → Correlation Engine
4. Correlation
Engine loads Feathers + applies Wing rules → Correlation Results
5. Visualization
Results Database → Results Viewer GUI
```
### 示例用例:查找执行证明
**场景**:证明 `malware.exe` 曾在系统上执行过
**步骤 1:创建 Feathers**
```
# 导入 Prefetch、ShimCache 和 AmCache 数据
python -m correlation_engine.feather.feather_builder
```
**步骤 2:创建 Wing**
```
{
"wing_id": "malware-execution",
"correlation_rules": {
"time_window_minutes": 5,
"minimum_matches": 2
},
"feathers": ["prefetch", "shimcache", "amcache"]
}
```
**步骤 3:执行 Pipeline**
```
from correlation_engine.pipeline import PipelineExecutor
executor = PipelineExecutor(pipeline_config)
results = executor.execute()
```
**步骤 4:查看结果**
```
Identity: malware.exe
Anchor 1 (2024-01-15 10:30:00):
✓ Prefetch: malware.exe executed at 10:30:00
✓ ShimCache: malware.exe modified at 10:30:15
✓ AmCache: malware.exe installed at 10:29:45
Conclusion: Execution proven with 3 corroborating artifacts
```
### 性能基准
**时间窗口扫描引擎**:
- 100 条记录:0.1 秒
- 1,000 条记录:0.5 秒
- 10,000 条记录:5 秒
- 100,000 条记录:50 秒
- 最适用于:基于时间的痕迹分析(生产就绪)
**基于身份的引擎**:
- 1,000 条记录:2 秒
- 10,000 条记录:15 秒
- 100,000 条记录:2.5 分钟(使用流式处理)
- 1,000,000 条记录:25 分钟(使用流式处理)
- 最适用于:身份追踪和过滤(生产就绪)
### 文档
**综合文档**(约 7,200 行):
- **[关联引擎概述](correlation_engine/docs/CORRELATION_ENGINE_OVERVIEW.md)** - 带有架构图的系统概述
- **[引擎文档](correlation_engine/docs/engine/ENGINE_DOCUMENTATION.md)** - 双引擎架构、引擎选择指南、性能优化
- **[架构文档](correlation_engine/ARCHITECTURE.md)** - 组件集成和数据流
- **[Feather 文档](correlation_engine/docs/feather/FEATHER_DOCUMENTATION.md)** - 数据规范化系统
- **[Wings 文档](correlation_engine/docs/wings/WINGS_DOCUMENTATION.md)** - 关联规则
- **[Pipeline 文档](correlation_engine/docs/pipeline/PIPELINE_DOCUMENTATION.md)** - 工作流编排
**快速链接**:
- [引擎选择指南](correlation_engine/docs/engine/ENGINE_DOCUMENTATION.md#engine-selection-guide) - 选择合适的引擎
- [故障排除指南](correlation_engine/docs/engine/ENGINE_DOCUMENTATION.md#troubleshooting) - 常见问题及解决方案
- [性能优化](correlation_engine/docs/engine/ENGINE_DOCUMENTATION.md#performance-and-optimization) - 优化关联
### 关联引擎入门
1. **启动 Feather Builder**python -m correlation_engine.main
2. **创建 Feathers**:导入您的取证痕迹(Prefetch、ShimCache 等)
3. **创建 Wings**:为您的调查定义关联规则
4. **创建 Pipeline**:配置要使用的 wings 和 feathers
5. **执行**:运行 pipeline 并查看关联结果
6. **分析**:使用 Results Viewer 探索时间关系
**当前状态**:
- ✅ **生产就绪** - 核心系统运行稳定并经过实战检验
- ⭐ **时间窗口扫描引擎** - 生产就绪,用于基于时间的分析 (O(N log N))
- ✅ **基于身份的引擎** - 生产就绪,用于身份追踪 (O(N log N))
- 🔄 **积极开发中** - 正在持续增强语义映射、评分和身份提取
### 📚 关联引擎文档
**综合文档**(约 10,000 行,涵盖所有方面):
- **[关联引擎概述](correlation_engine/docs/CORRELATION_ENGINE_OVERVIEW.md)** - 带有架构图的系统概述
- **[引擎文档](correlation_engine/docs/engine/ENGINE_DOCUMENTATION.md)** - 双引擎架构、引擎选择指南、性能优化
- **[架构文档](correlation_engine/ARCHITECTURE.md)** - 组件集成和数据流
- **[贡献指南](correlation_engine/CONTRIBUTING.md)** - 如何为关联引擎做出贡献
**快速链接**:
- [引擎选择指南](correlation_engine/docs/engine/ENGINE_DOCUMENTATION.md#engine-selection-guide) - 选择合适的引擎
- [故障排除指南](correlation_engine/docs/engine/ENGINE_DOCUMENTATION.md#troubleshooting) - 常见问题及解决方案
- [性能优化](correlation_engine/docs/engine/ENGINE_DOCUMENTATION.md#performance-and-optimization) - 优化关联
## 🚀 即将推出的功能
### Crow-Eye 核心功能
- 📊 **高级 GUI 视图和报告** - 增强的可视化和报告功能
- 🔄 **增强的搜索对话框** - 支持自然语言的高级过滤
- ⏱️ **增强的可视化时间轴** - 交互式缩放和事件关联
- 🤖 **AI 集成** - 查询结果、总结发现,并使用自然语言问题协助非技术用户
### 关联引擎功能
- 🎯 **增强的语义映射** - 跨所有痕迹类型的全面字段映射
- 📈 **高级关联评分** - 带有可解释性的精细置信度评分算法
如果您有兴趣为这些功能做出贡献,或者对增加其他取证痕迹有建议,请随时:
- 带着您的想法提交 issue
- 提交 pull request
- 直接通过 ghassanelsman@gmail.com 联系我
**关于关联引擎的贡献**:
请参阅[关联引擎贡献指南](correlation_engine/CONTRIBUTING.md)获取详细信息,内容涵盖:
- 开发状态和优先领域
- 如何为特定组件做出贡献
- 代码准则和测试要求
- 文档标准
## 开发致谢
- Jump List/LNK 解析基于 Saleh Muhaysin 的工作
## 💬 社区与支持
加入我们不断壮大的社区,以获得更快的支持,分享您的调查技术,并探讨 Crow-eye 的未来!
[](https://discord.gg/2vag2Udf)
- **更快的支持**:直接从开发者和经验丰富的用户那里获得帮助。
- **讨论**:分享您的取证发现并讨论新的痕迹研究。
- **公告**:随时了解最新的发布版本和实验性功能。
- 由 Ghassan Elsman 创建并维护

标签:DAST, GUI工具, HTTPS请求, OpenCanary, Windows Artifacts, Windows取证, 关联引擎, 取证工具, 域渗透, 子域名变形, 库, 应急响应, 开源安全工具, 恶意软件分析, 数字取证, 数据导出, 数据解析, 电子数据取证, 痕迹分析, 系统取证, 网络安全, 自动化脚本, 证据分析, 证据提取, 逆向工具, 逆向工程平台, 隐私保护