xie-lab-ml/Zigzag-Diffusion-Sampling
GitHub: xie-lab-ml/Zigzag-Diffusion-Sampling
这是一个用于扩散模型的自反思采样方法,通过累积语义信息提升文本到图像生成的质量和提示词对齐度。
Stars: 103 | Forks: 3
# Zigzag 扩散采样(Z 采样)
## 新闻 🚀️
我们的论文 ***Z-Sampling*** 已被 ICLR 2025 接收。🎉🌸🎉
升级版 "[Weak-to-Strong Diffusion](https://github.com/xie-lab-ml/Weak-to-Strong-Diffusion-with-Reflection)" 已被 ICLR 2026 接收。🎉🌸🎉
## 概述
本指南提供如何使用 Z-Sampling 的说明,这是一种新颖的采样方法,它利用引导间隙在整个生成过程中逐步累积语义信息。
这里我们提供了支持 ***Stable Diffusion XL*** 的推理代码。更多架构将在后续发布。
Z-Sampling 的升级版本已作为我们的新工作 Weak-to-Strong Diffusion (W2SD) 发布,公开可用地址为 https://github.com/xie-lab-ml/Weak-to-Strong-Diffusion-with-Reflection。
## 摘要
扩散模型是目前最流行的生成范式,它能够将条件信息注入生成路径,引导潜在向量朝向期望的方向。然而,现有的文本到图像扩散模型在处理那些具有挑战性的提示词时,往往难以同时保持高图像质量和高提示词-图像对齐度。为了缓解这一问题并增强现有的预训练扩散模型,我们在本文中主要做出了三项贡献。首先,我们提出了扩散自反思,它交替执行去噪和反演过程,并通过理论和实证证据证明,这种扩散自反利用用去噪和反演之间的引导间隙来捕获与提示词相关的语义信息。其次,受理论分析启发,我们推导出了 Zigzag Diffusion Sampling(Z-Sampling),这是一种基于自反思的新型扩散采样方法,它利用去噪和反演之间的引导间隙,沿着采样路径逐步累积语义信息,从而产生更好的采样结果。此外,作为一种即插即用方法,Z-Sampling 可以以极少的编码和计算成本,普遍应用于各种扩散模型(例如,加速模型和基于 Transformer 的模型)。第三,我们广泛的实验表明,Z-Sampling 能够普遍且显著地在各种基准数据集、扩散模型和性能评估指标上提升生成质量。例如,结合 Z-Sampling 的 DreamShaper 能够以高达 94% 的 HPSv2 胜率自我提升,优于原始结果。此外,Z-Sampling 可以与其他正交方法(包括 Diffusion-DPO)进一步结合,以增强现有扩散模型。
## 结果
 **The qualitative results of Z-Sampling demonstrate the effectiveness of our method in various aspects, such as style, position, color, counting, text rendering, and object co-occurrence.**
**The qualitative results of Z-Sampling demonstrate the effectiveness of our method in various aspects, such as style, position, color, counting, text rendering, and object co-occurrence.**
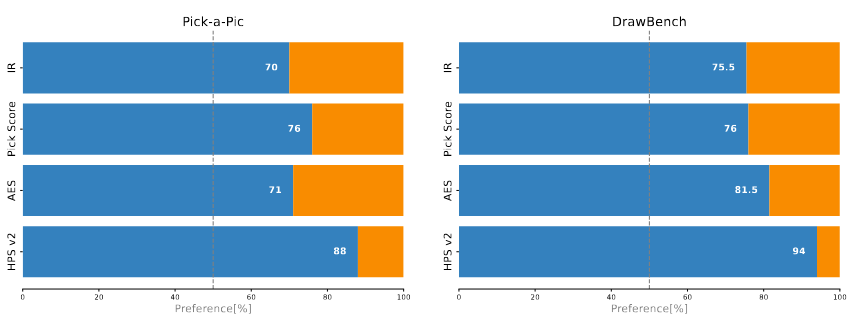 **The winning rates of Z-Sampling over standard sampling. The blue bars represent the side of our method. The orange bars represent the side of the standard sampling**
## 环境要求
- `python 版本 == 3.10.14`
- `pytorch (CUDA 版本)`
- `diffusers == 0.22.3`
- `PIL`
- `numpy`
- `timm`
- `tqdm`
- `argparse`
- `einops`
## 安装
请确保你已成功构建 `python` 环境并安装了带 CUDA 版本的 `pytorch`。在运行脚本前,请确保已安装所有必需的包。具体来说,你需要安装特定版本的 `diffusers` 库。
```
pip install diffusers == 0.22.3
```
## 使用方法👀️
要使用 Z-Sampling 流程,你需要使用适当的命令行参数运行 `infer.py`。以下是可用选项:
### 命令行参数
- `--gamma_1`:去噪过程中使用的无分类器引导尺度。默认值为 5.5。
- `--gamma_2`:反演过程中使用的无分类器引导尺度。默认值为 0。
- `--infer_step`:扩散过程的推理步数。默认值为 50。
- `--lambda_step`:扩散过程的锯齿形迭代步数。默认值为 49。
- `--image_size`:生成图像的尺寸(高度和宽度)。默认值为 1024。
- `--T_max`:每个锯齿形迭代步骤的轮数。默认值为 1。
- `--seed`:用于确定初始潜在向量的随机种子。默认值为 42。
- `--device`:执行模型推理的设备。默认值为 `cuda`。
- `--save_dir`:保存生成图像的路径。默认值为 `./res`。
### 运行脚本
你可以通过运行以下命令执行推理步骤:
```
python ./infer.py
```
此命令将执行生成过程,在“标准采样”和“Z-Sampling”两种模式下生成与“预定义提示词”对应的图像。
“预定义提示词”如下
```
prompt_list = ["A Man on a Bicycle, MineScaft Style",
"A small yellow dog.",
"A Man on a Bicycle, in the style of Van Gogh's Starry Night."]
```
你也可以在 `infer.py` 中将这些提示词修改为你想要的内容。
### 输出🎉️
该脚本将保存两张图像:
- 一张由“标准采样”生成的标准图像。
- 一张由“Z-Sampling”生成的优化图像。
两张图像都将保存在 `--save_dir` 指定的路径中,文件名基于方法和提示词生成。
## 引用
```
@inproceedings{bai2024zigzag,
title={Zigzag Diffusion Sampling: Diffusion Models Can Self-Improve via Self-Reflection},
author={Bai, Lichen and Shao, Shitong and Zhou, Zikai and Qi, Zipeng and Xu, Zhiqiang and Xiong, Haoyi and Xie, Zeke},
booktitle={The Thirteenth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=MKvQH1ekeY}
}
```
## 预训练权重下载❤️
你需要通过 Hugging Face 手动或自动下载 SDXL 模型。请确保网络连接稳定且版本正确。
如果在部署和操作过程中遇到任何问题,欢迎与我们联系,非常感谢!
**The winning rates of Z-Sampling over standard sampling. The blue bars represent the side of our method. The orange bars represent the side of the standard sampling**
## 环境要求
- `python 版本 == 3.10.14`
- `pytorch (CUDA 版本)`
- `diffusers == 0.22.3`
- `PIL`
- `numpy`
- `timm`
- `tqdm`
- `argparse`
- `einops`
## 安装
请确保你已成功构建 `python` 环境并安装了带 CUDA 版本的 `pytorch`。在运行脚本前,请确保已安装所有必需的包。具体来说,你需要安装特定版本的 `diffusers` 库。
```
pip install diffusers == 0.22.3
```
## 使用方法👀️
要使用 Z-Sampling 流程,你需要使用适当的命令行参数运行 `infer.py`。以下是可用选项:
### 命令行参数
- `--gamma_1`:去噪过程中使用的无分类器引导尺度。默认值为 5.5。
- `--gamma_2`:反演过程中使用的无分类器引导尺度。默认值为 0。
- `--infer_step`:扩散过程的推理步数。默认值为 50。
- `--lambda_step`:扩散过程的锯齿形迭代步数。默认值为 49。
- `--image_size`:生成图像的尺寸(高度和宽度)。默认值为 1024。
- `--T_max`:每个锯齿形迭代步骤的轮数。默认值为 1。
- `--seed`:用于确定初始潜在向量的随机种子。默认值为 42。
- `--device`:执行模型推理的设备。默认值为 `cuda`。
- `--save_dir`:保存生成图像的路径。默认值为 `./res`。
### 运行脚本
你可以通过运行以下命令执行推理步骤:
```
python ./infer.py
```
此命令将执行生成过程,在“标准采样”和“Z-Sampling”两种模式下生成与“预定义提示词”对应的图像。
“预定义提示词”如下
```
prompt_list = ["A Man on a Bicycle, MineScaft Style",
"A small yellow dog.",
"A Man on a Bicycle, in the style of Van Gogh's Starry Night."]
```
你也可以在 `infer.py` 中将这些提示词修改为你想要的内容。
### 输出🎉️
该脚本将保存两张图像:
- 一张由“标准采样”生成的标准图像。
- 一张由“Z-Sampling”生成的优化图像。
两张图像都将保存在 `--save_dir` 指定的路径中,文件名基于方法和提示词生成。
## 引用
```
@inproceedings{bai2024zigzag,
title={Zigzag Diffusion Sampling: Diffusion Models Can Self-Improve via Self-Reflection},
author={Bai, Lichen and Shao, Shitong and Zhou, Zikai and Qi, Zipeng and Xu, Zhiqiang and Xiong, Haoyi and Xie, Zeke},
booktitle={The Thirteenth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=MKvQH1ekeY}
}
```
## 预训练权重下载❤️
你需要通过 Hugging Face 手动或自动下载 SDXL 模型。请确保网络连接稳定且版本正确。
如果在部署和操作过程中遇到任何问题,欢迎与我们联系,非常感谢!
标签:Apex, DNS解析, ICLR, SDXL, Stable Diffusion, 人工智能, 凭据扫描, 图像质量提升, 域名侦查, 学术研究, 开源项目, 引导差距, 扩散模型, 推理代码, 提示对齐, 插件式方法, 文本到图像生成, 机器学习, 深度学习, 生成模型, 用户模式Hook绕过, 自我反思, 自改进, 计算机视觉, 语义信息, 逆向工具, 采样方法