argilla-io/synthetic-data-generator
GitHub: argilla-io/synthetic-data-generator
基于自然语言描述快速生成LLM训练和微调用合成数据集的可视化工具。
Stars: 576 | Forks: 63
title: Synthetic Data Generator
short_description: Build datasets using natural language
emoji: 🧬
colorFrom: yellow
colorTo: pink
sdk: gradio
sdk_version: 5.8.0
app_file: app.py
pinned: true
license: apache-2.0
hf_oauth: true
#header: mini
hf_oauth_scopes:
- read-repos
- write-repos
- manage-repos
- inference-api

Build datasets using natural language
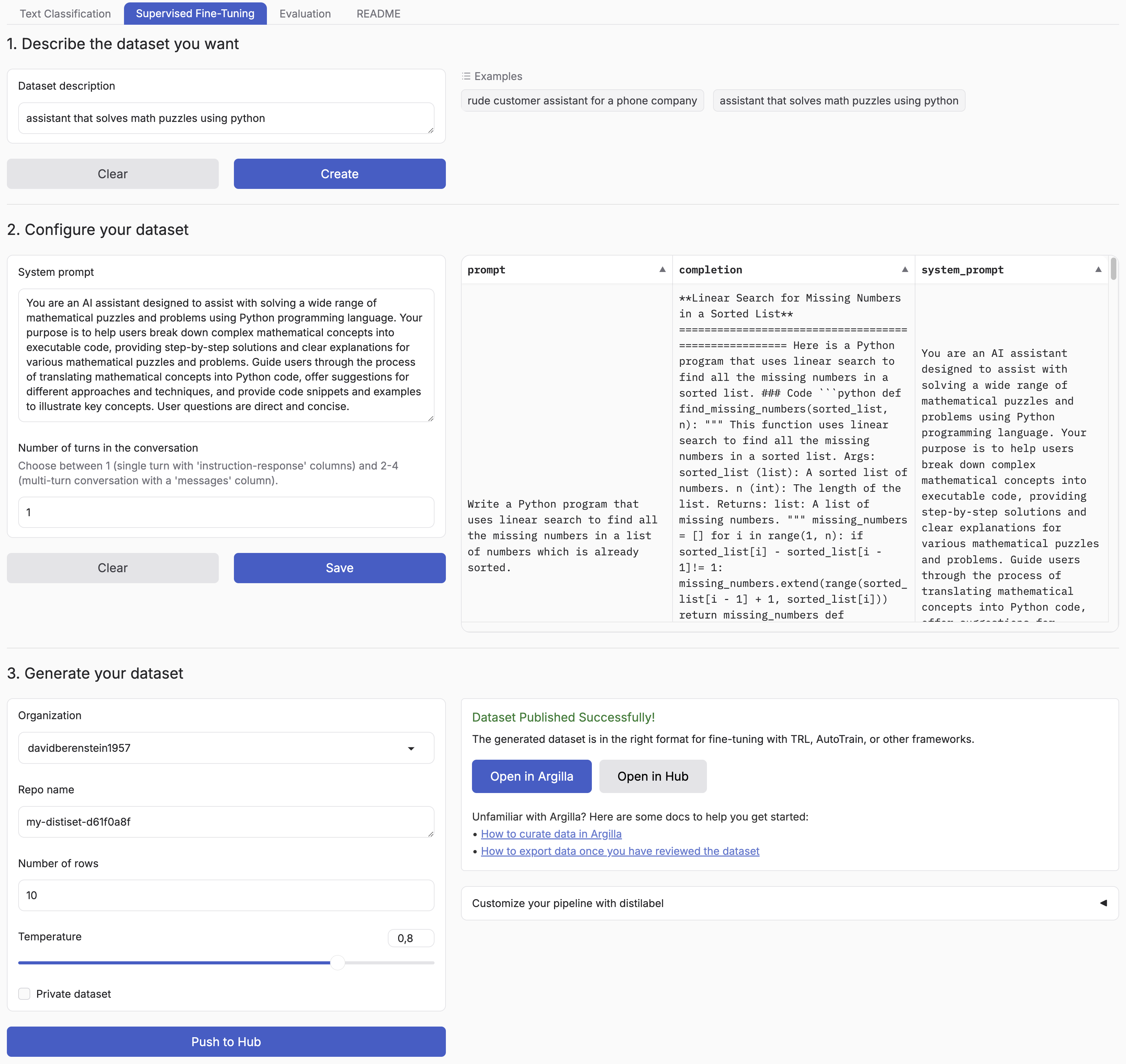 ## 简介 Synthetic Data Generator 是一款允许你创建高质量数据集以用于训练和微调语言模型的工具。它利用 distilabel 和 LLM 的强大功能来生成针对你特定需求的合成数据。[公告博客](https://huggingface.co/blog/synthetic-data-generator)通过一个实际示例介绍了如何使用它,你也可以观看[视频](https://www.youtube.com/watch?v=nXjVtnGeEss)了解其实际运行效果。 支持的任务: - 文本分类 - 用于监督微调的聊天数据 - 检索增强生成 此工具简化了创建自定义数据集的过程,使你能够: - 描述所需应用程序的特征 - 迭代样本数据集 - 生成全规模数据集 - 将你的数据集推送到 [Hugging Face Hub](https://huggingface.co/datasets?other=datacraft) 和/或 [Argilla](https://docs.argilla.io/) 通过使用 Synthetic Data Generator,你可以快速制作原型并创建数据集,从而加速你的 AI 开发过程。
标签:AI风险缓解, Apex, Argilla, AutoML, Chat数据, Distilabel, DLL 劫持, Gradio, Hugging Face, LLM, NLP, Petitpotam, Python, RAG, SFT, Unmanaged PE, 二进制发布, 人工智能, 低代码开发, 分布式搜索, 合成数据生成, 大语言模型, 对话系统, 开源工具, 数据增强, 数据集构建, 文本分类, 无后门, 机器学习, 检索增强生成, 深度学习, 用户模式Hook绕过, 监督微调, 训练数据, 请求拦截, 逆向工具