lechmazur/nyt-connections
GitHub: lechmazur/nyt-connections
这是一个用于评估大型语言模型在扩展版《纽约时报》Connections谜题上表现的基准测试工具。
Stars: 229 | Forks: 8
# 扩展版本
该基准测试使用940道《纽约时报》Connections谜题评估大型语言模型(LLMs),并额外增加了词汇以提高难度。
截至2025年2月4日,基准测试推出了新版本。标准的《纽约时报》Connections基准测试已接近饱和,其中o1得分为90.7分,而o3及其他推理模型预计将于今年推出。当前规则仅要求知晓三个类别,第四个类别可自然推断。为增加难度,扩展版Connections在每个谜题中增加了最多四个额外的干扰词。我们经过仔细核实,确保添加的词汇均不属于对应谜题中的任何类别。截至2026年2月2日,新谜题使总数从436道增加到940道。
### 图表:扩展版
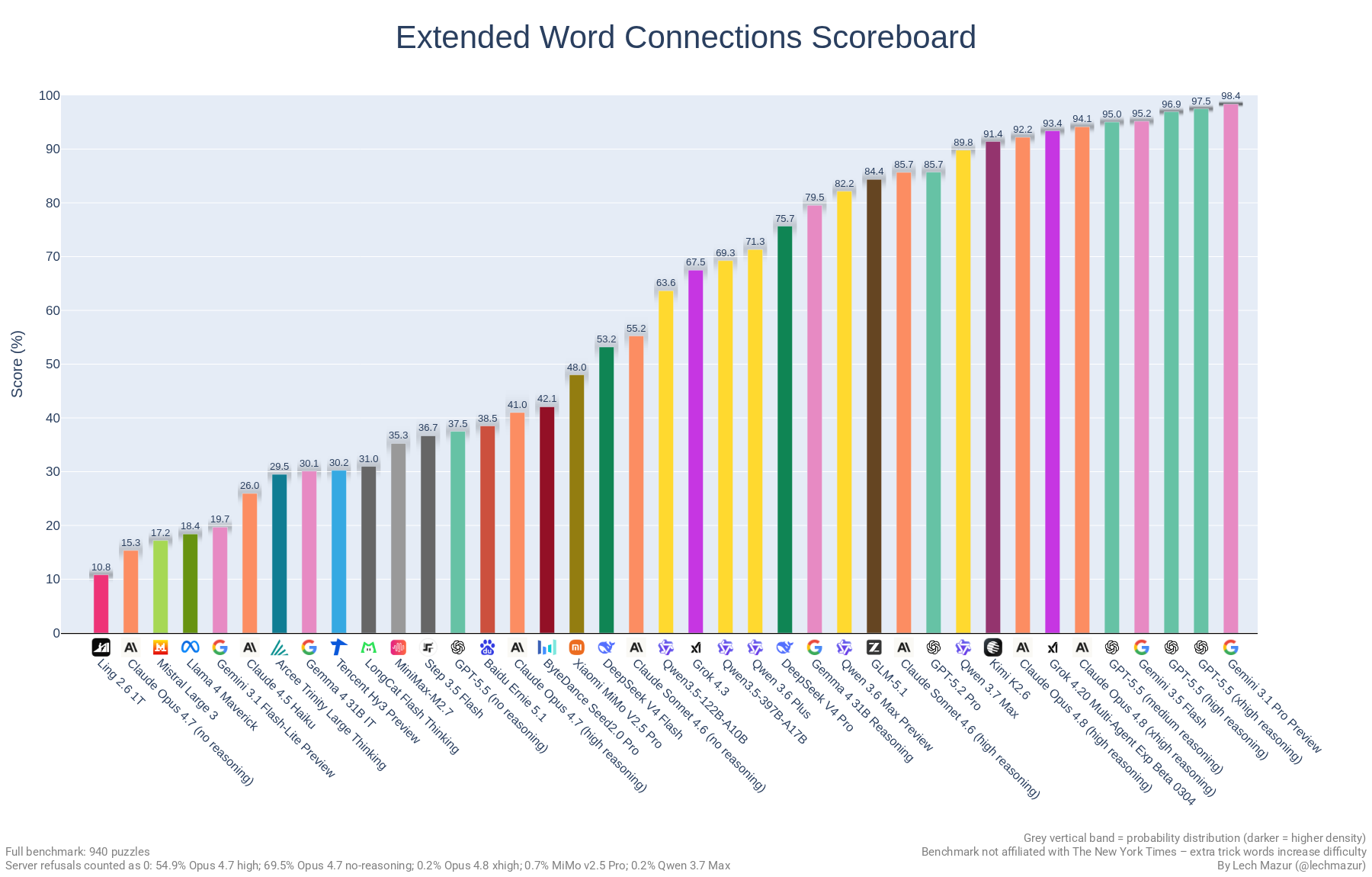
## 模型对比散点图
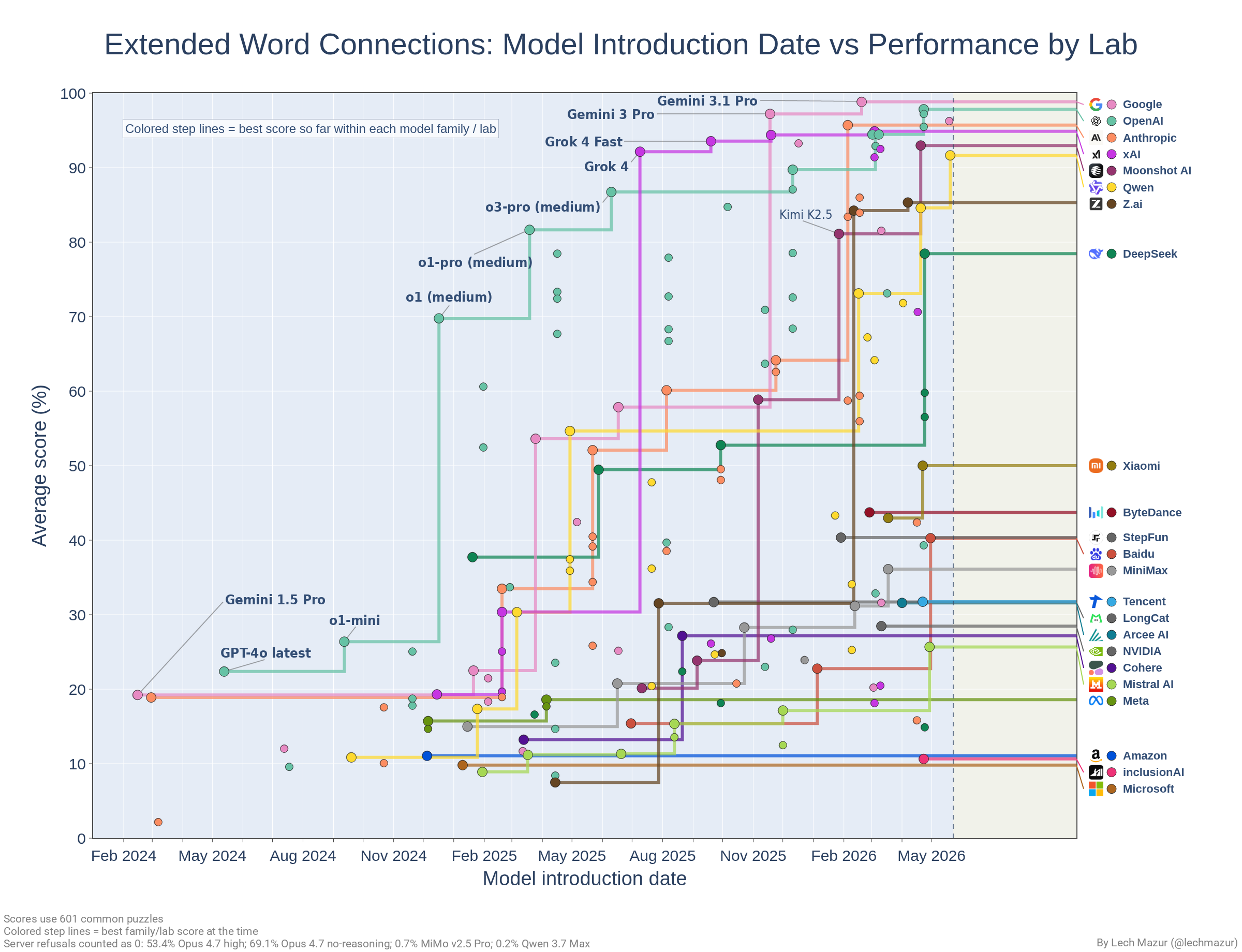
### 模型家族进展
此图表展示了在共享的601道谜题比较集上,各模型家族随时间推移的得分进展。
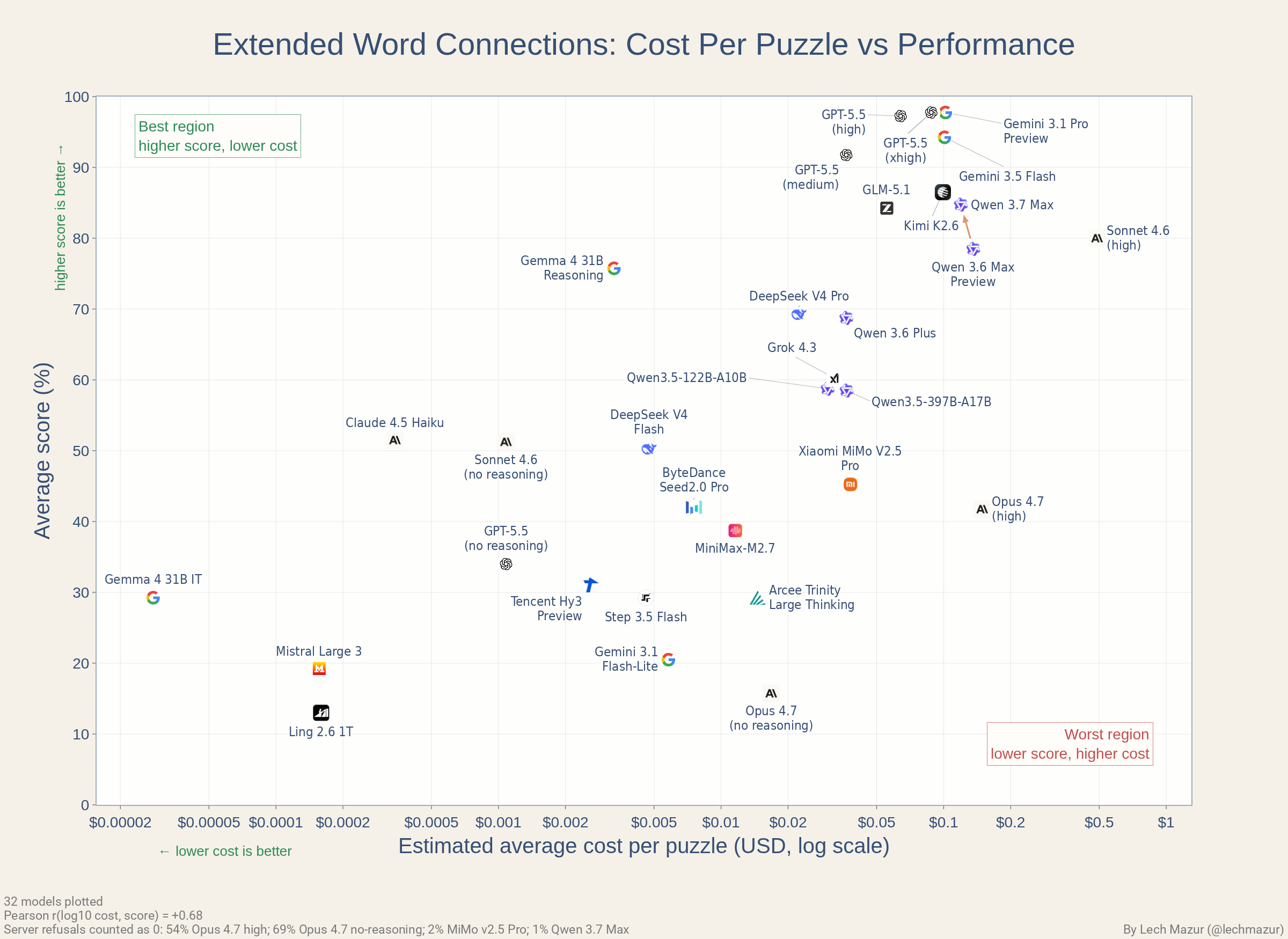
### 成本与性能
此图表比较了每个谜题的估算平均成本与基准测试得分。
### 谜题层面结果的相关性:热力图
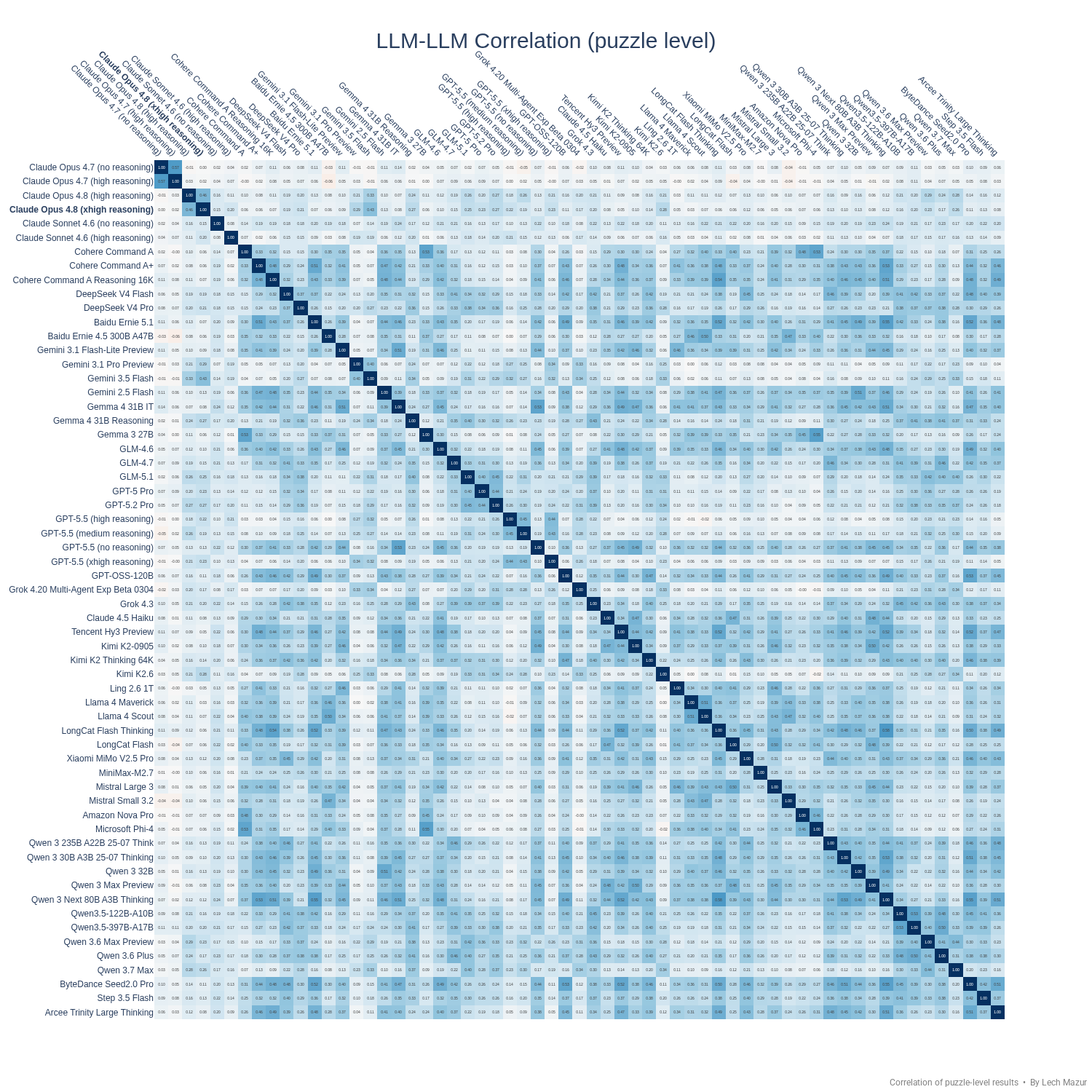
## 最新的100道谜题
为抵消LLM的训练数据可能包含解决方案的可能性,我们还单独测试了最新的100道谜题。请注意,较低的分数并不一定表明《纽约时报》Connections的解决方案存在于训练数据中,因为早期谜题的难度较低。
### 图表:最新100道谜题,扩展版
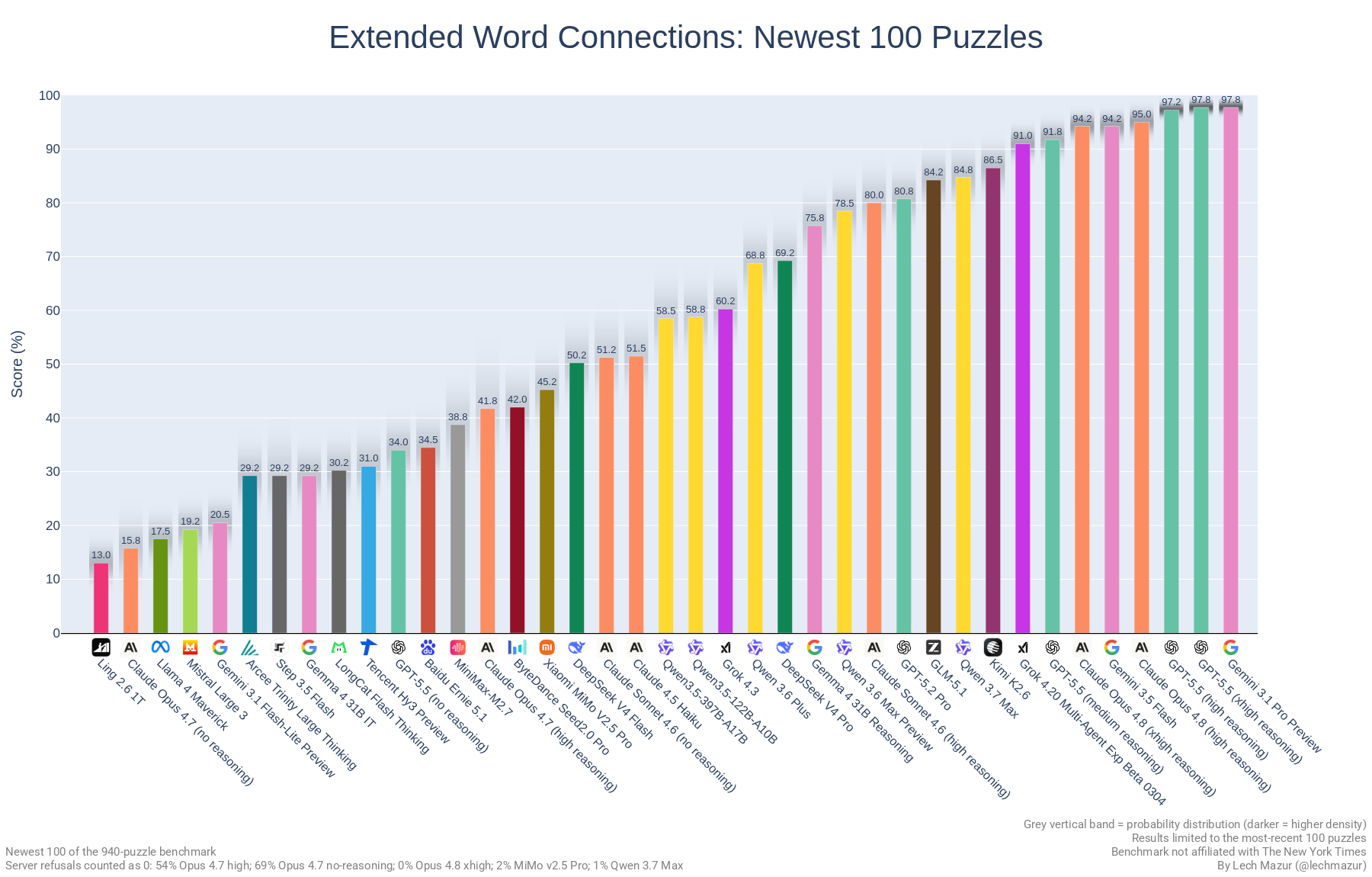
### 排行榜:最新100道谜题,扩展版
| 排名 | 模型 | 得分百分比 | 谜题数量 |
| ---: | --- | ---: | ---: |
| 1 | Gemini 3.1 Pro Preview | 97.8 | 100 |
| 2 | GPT-5.5 (xhigh reasoning) | 97.8 | 100 |
| 3 | GPT-5.5 (high reasoning) | 97.2 | 100 |
| 4 | GPT-5.4 (xhigh reasoning) | 96.0 | 100 |
| 5 | Gemini 3 Pro Preview | 95.2 | 100 |
| 6 | Claude Opus 4.8 (high reasoning) | 95.0 | 100 |
| 7 | Gemini 3.5 Flash | 94.2 | 100 |
| 8 | Claude Opus 4.8 (xhigh reasoning) | 94.2 | 100 |
| 9 | GPT-5.4 (high reasoning) | 93.0 | 100 |
| 10 | GPT-5.5 (medium reasoning) | 91.8 | 100 |
| 11 | Claude Opus 4.6 (high reasoning) | 91.5 | 100 |
| 12 | Grok 4.20 Multi-Agent Exp Beta 0304 | 91.0 | 100 |
| 13 | GPT-5.4 (medium reasoning) | 90.2 | 100 |
| 14 | Kimi K2.6 | 86.5 | 100 |
| 15 | Grok 4.20 0309 (Reasoning) | 85.5 | 100 |
| 16 | Grok 4.20 Reasoning Exp Beta 0304 | 85.2 | 100 |
| 17 | GPT-5.2 (xhigh reasoning) | 85.0 | 100 |
| 18 | Qwen 3.7 Max | 84.8 | 100 |
| 19 | GLM-5.1 | 84.2 | 100 |
| 20 | Grok 4.1 Fast Reasoning | 83.8 | 100 |
| 21 | Claude Opus 4.6 Thinking 16K | 82.8 | 100 |
| 22 | GPT-5.2 Pro | 80.8 | 100 |
| 23 | Claude Sonnet 4.6 (high reasoning) | 80.0 | 100 |
| 24 | Qwen 3.6 Max Preview | 78.5 | 100 |
| 25 | Claude Sonnet 4.6 Thinking 32K | 77.2 | 100 |
| 26 | GPT-5.2 (high reasoning) | 77.0 | 100 |
| 27 | Gemma 4 31B Reasoning | 75.8 | 100 |
| 28 | GLM-5 | 75.5 | 100 |
| 29 | Kimi K2.5 Thinking | 73.2 | 100 |
| 30 | GPT-5.4 Mini (xhigh reasoning) | 72.0 | 100 |
| 31 | Gemini 3 Flash Preview | 71.8 | 100 |
| 32 | DeepSeek V4 Pro | 69.2 | 100 |
| 33 | Qwen 3.6 Plus | 68.8 | 100 |
| 34 | GPT-5.2 (medium reasoning) | 67.0 | 100 |
| 35 | Claude Opus 4.5 Thinking 16K | 62.5 | 100 |
| 36 | GPT-5.2 (low reasoning) | 61.3 | 100 |
| 37 | Grok 4.3 | 60.2 | 100 |
| 38 | Qwen3.5-122B-A10B | 58.8 | 100 |
| 39 | Qwen3.5-397B-A17B | 58.5 | 100 |
| 40 | Qwen3.5-27B | 58.2 | 100 |
| 41 | Claude Sonnet 4.6 Thinking 16K | 54.8 | 100 |
| 42 | Claude Opus 4.5 (no reasoning) | 54.5 | 100 |
| 43 | Claude Sonnet 4.5 Thinking 16K | 54.0 | 100 |
| 44 | Claude Sonnet 4.5 (no reasoning) | 53.2 | 100 |
| 45 | Claude 4.5 Haiku | 51.5 | 100 |
| 46 | Claude Sonnet 4.6 (no reasoning) | 51.2 | 100 |
| 47 | DeepSeek V4 Flash | 50.2 | 100 |
| 48 | Claude Opus 4.6 (no reasoning) | 50.0 | 100 |
| 49 | Xiaomi MiMo V2.5 Pro | 45.2 | 100 |
| 50 | Qwen3 Max (2026-01-23) | 42.5 | 100 |
| 51 | DeepSeek V3.2 | 42.2 | 100 |
| 52 | ByteDance Seed2.0 Pro | 42.0 | 100 |
| 53 | Claude Opus 4.7 (high reasoning) | 41.8 | 100 |
| 54 | MiniMax-M2.7 | 38.8 | 100 |
| 55 | Xiaomi MiMo V2 Pro | 38.0 | 100 |
| 56 | Baidu Ernie 5.1 | 34.5 | 100 |
| 57 | GPT-5.5 (no reasoning) | 34.0 | 100 |
| 58 | GPT-5.4 (no reasoning) | 33.8 | 100 |
| 59 | Tencent Hy3 Preview | 31.0 | 100 |
| 60 | LongCat Flash Thinking | 30.2 | 100 |
| 61 | MiniMax-M2.5 | 29.8 | 100 |
| 62 | Gemma 4 31B IT | 29.2 | 100 |
| 63 | Step 3.5 Flash | 29.2 | 100 |
| 64 | Arcee Trinity Large Thinking | 29.2 | 100 |
| 65 | GPT-5.2 (no reasoning) | 29.0 | 100 |
| 66 | Mistral Medium 3.5 (high) | 27.8 | 100 |
| 67 | MiniMax-M2.1 | 24.0 | 100 |
| 68 | Qwen 3 Max Thinking | 23.8 | 100 |
| 69 | Nemotron 3 Super | 22.2 | 100 |
| 70 | MiniMax-M2 | 22.0 | 100 |
| 71 | Grok 4.1 Fast Non-Reasoning | 21.0 | 100 |
| 72 | Gemini 3.1 Flash-Lite Preview | 20.5 | 100 |
| 73 | Baidu Ernie 5.0 | 20.2 | 100 |
| 74 | Grok 4.20 0309 (Non-Reasoning) | 20.0 | 100 |
| 75 | Mistral Large 3 | 19.2 | 100 |
| 76 | Grok 4.20 Non-Reasoning Exp Beta 0304 | 17.8 | 100 |
| 77 | Llama 4 Maverick | 17.5 | 100 |
| 78 | DeepSeek V3.2 (no reasoning) | 16.8 | 100 |
| 79 | Mistral Medium 3.1 | 16.8 | 100 |
| 80 | Claude Opus 4.7 (no reasoning) | 15.8 | 100 |
| 81 | Ling 2.6 1T | 13.0 | 100 |
# 人类 vs. LLMs
为探究顶尖语言模型(LLMs)在《纽约时报》Connections谜题上与人类相比表现如何,我们使用了2024年12月至2025年2月期间由用户/Bryschien1996分析的官方《纽约时报》表现数据,并辅以一个模拟人类体验的游戏设置。该设置包含一个迭代过程:求解者逐步提出分组,获得反馈(“正确”、“差一个”、“错误”),并在失败前允许犯四次错误。根据《纽约时报》的数据,在2024年12月至2025年2月的这三个月期间,普通人类玩家平均解开了大约71%的谜题,解开率从最难日子(例如2025年2月2日)的39%到最简单日子(例如2025年2月26日)的98%不等。值得注意的是,《纽约时报》Connections的玩家是自选择的,其表现可能优于普通人群。我们收集了九个LLM的数据,这些模型在扩展版Connections基准测试中的得分跨度较大。
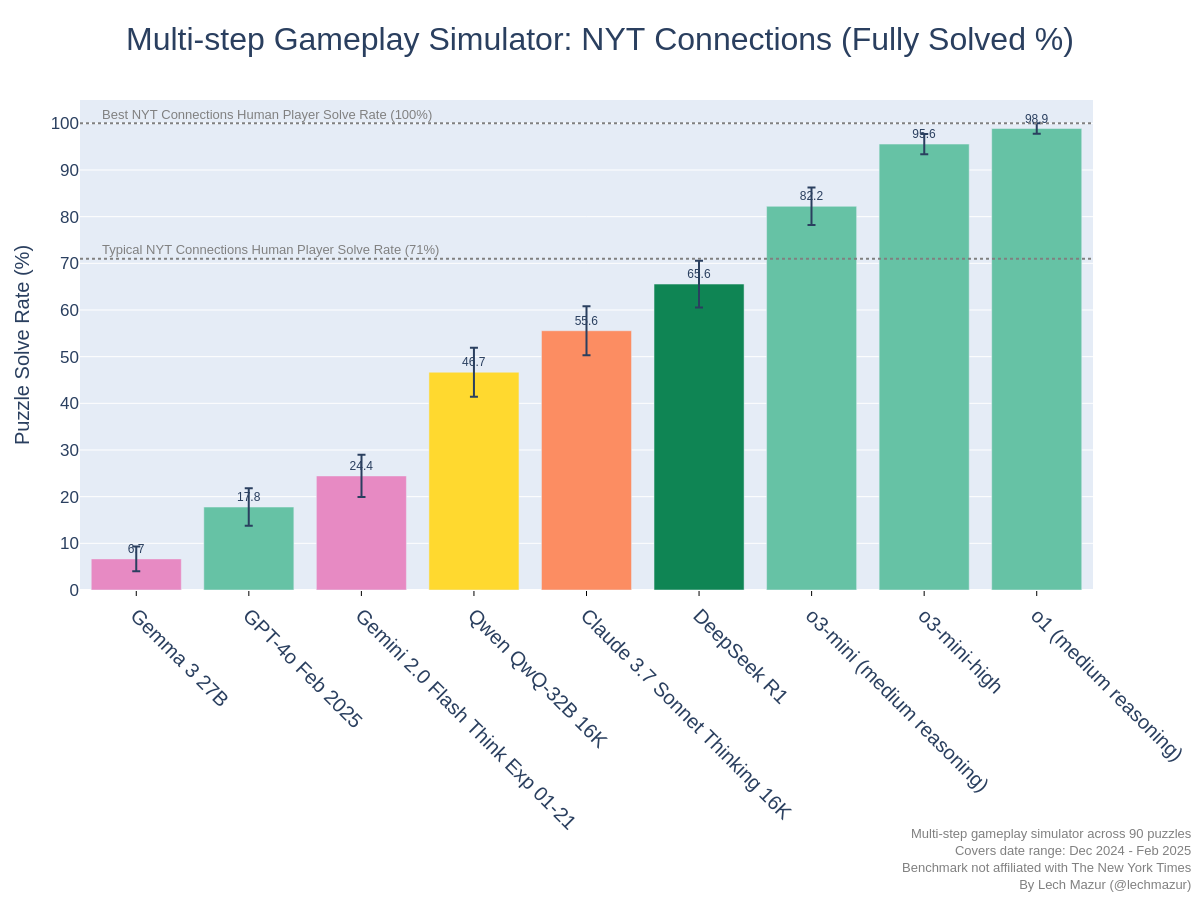
结果显示,来自OpenAI的顶尖推理LLM consistently outperform the average human player. DeepSeek R1 performs closest to the level of an average NYT Connections player.
精英人类玩家则设定了更高的标准,在同期达到了100%的胜率:
 o1的胜率为98.9%,接近这一精英水平。o1-pro尚未在此游戏模拟设置中测试,或许能够匹配这些顶尖人类。因此,直接判断AI在《纽约时报》Connections上是否实现了超人表现,可能取决于比较在完全解决每个谜题之前所犯错误的数量。
# 原版《纽约时报》Connections LLM基准测试
该基准测试使用436道《纽约时报》Connections谜题评估大型语言模型(LLMs)。使用了三种不同的提示,这些提示没有经过针对LLM的提示工程优化。同时评估了大写和小写谜题。更简单 - 未添加额外词汇。
### 图表:原版
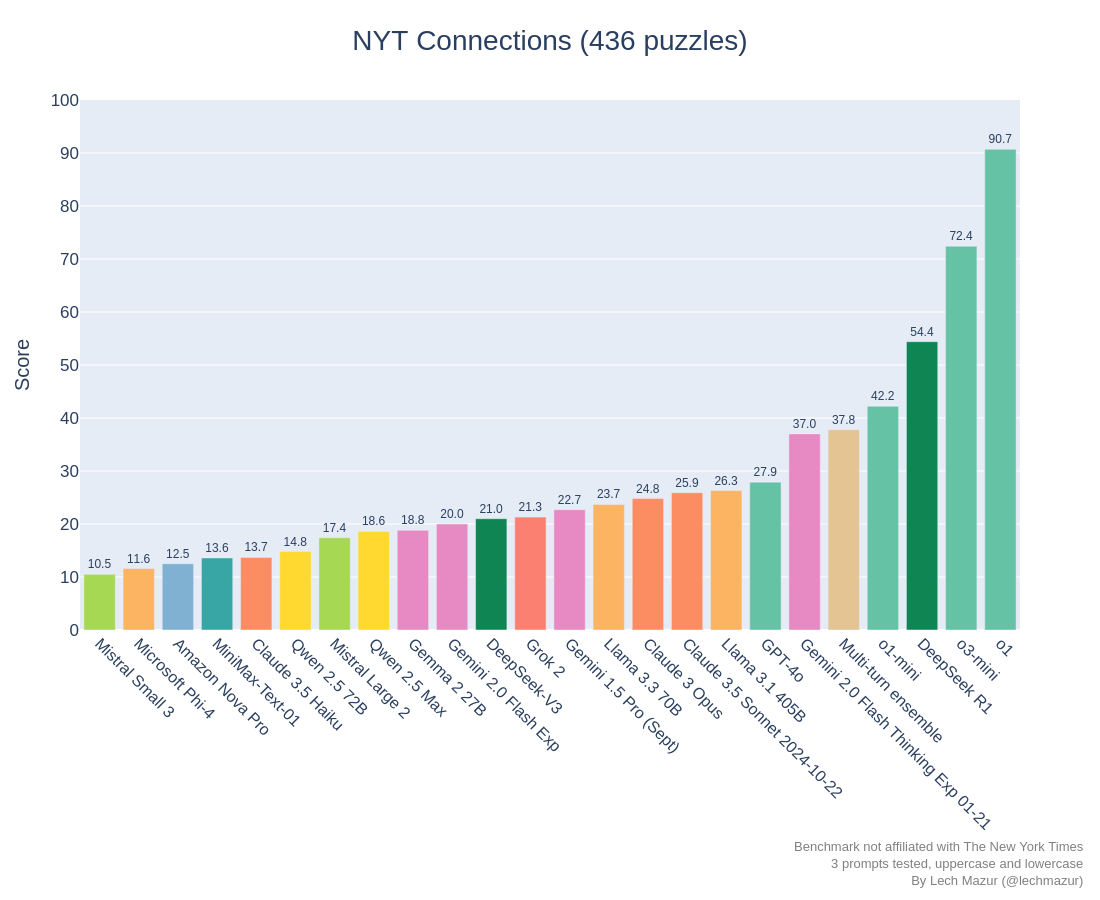
### 排行榜:原版
| 模型 | 得分 |
| --- | --- |
| o1 | 90.7 |
| o1-preview | 87.1 |
| o3-mini | 72.4 |
| DeepSeek R1 | 54.4 |
| o1-mini | 42.2 |
| Multi-turn ensemble | 37.8 |
| Gemini 2.0 Flash Thinking Exp 01-21 | 37.0 |
| GPT-4 Turbo | 28.3 |
| GPT-4o 2024-11-20 | 27.9 |
| GPT-4o 2024-08-06 | 26.5 |
| Llama 3.1 405B | 26.3 |
| Claude 3.5 Sonnet (2024-10-22) | 25.9 |
| Claude 3 Opus | 24.8 |
| Grok Beta | 23.7 |
| Llama 3.3 70B | 23.7 |
| Gemini 1.5 Pro (Sept) | 22.7 |
| Deepseek-V3 | 21.0 |
| Gemini 2.0 Flash Exp | 20.0 |
| Gemma 2 27B | 18.8 |
| Qwen 2.5 Max | 18.6 |
| Gemini 2.0 Flash Thinking Exp | 18.6 |
| Mistral Large 2 | 17.4 |
| Qwen 2.5 72B | 14.8 |
| Claude 3.5 Haiku | 13.7 |
| MiniMax-Text-01 | 13.6 |
| Nova Pro | 12.5 |
| Phi-4 | 11.6 |
| Mistral Small 3 | 10.5 |
| DeepSeek-V2.5 | 9.9 |
### 排行榜:旧版模型
这些模型因运行的谜题总数少于940道而被排除在主榜之外。
| 排名 | 模型 | 得分百分比 | 谜题数量(窗口) | 总覆盖范围 |
| ---: | --- | ---: | ---: | ---: |
| 1 | Sherlock Think Alpha | 92.5 | 759 | 759/940 |
| 2 | Grok 4 Fast Reasoning | 92.2 | 759 | 759/940 |
| 3 | Grok 4 | 91.8 | 759 | 759/940 |
| 4 | Sonoma Sky Alpha | 90.8 | 759 | 759/940 |
| 5 | o3-pro (medium reasoning) | 87.3 | 759 | 759/940 |
| 6 | GPT-5 Pro | 83.9 | 759 | 759/940 |
| 7 | o1-pro (medium reasoning) | 82.4 | 651 | 651/940 |
| 8 | o3 (high reasoning) | 78.6 | 759 | 759/940 |
| 9 | GPT-5 (high reasoning) | 77.1 | 759 | 759/940 |
| 10 | o4-mini (high reasoning) | 73.6 | 759 | 759/940 |
| 11 | o3 (medium reasoning) | 73.0 | 759 | 759/940 |
| 12 | GPT-5 (medium reasoning) | 72.2 | 759 | 759/940 |
| 13 | o1 (medium reasoning) | 70.9 | 651 | 651/940 |
| 14 | GPT-5.1 (high reasoning) | 70.0 | 759 | 759/940 |
| 15 | o4-mini (medium reasoning) | 68.8 | 651 | 651/940 |
| 16 | GPT-5 mini (medium reasoning) | 67.0 | 759 | 759/940 |
| 17 | GPT-5 (low reasoning) | 65.4 | 759 | 759/940 |
| 18 | GPT-5.1 (medium reasoning) | 62.7 | 759 | 759/940 |
| 19 | o3-mini (high reasoning) | 61.4 | 651 | 651/940 |
| 20 | GLM-4.7 | 59.5 | 767 | 767/940 |
| 21 | Claude Opus 4.1 Thinking 16K | 58.8 | 759 | 759/940 |
| 22 | DeepSeek V4 Flash (thinking) | 57.7 | 759 | 759/940 |
| 23 | Gemini 2.5 Pro | 57.7 | 759 | 759/940 |
| 24 | Kimi K2 Thinking 64K | 57.4 | 924 | 924/940 |
| 25 | Qwen 3 235B A22B | 54.6 | 759 | 759/940 |
| 26 | Gemini 2.5 Pro Exp 03-25 | 54.1 | 651 | 651/940 |
| 27 | o3-mini (medium reasoning) | 53.6 | 651 | 651/940 |
| 28 | Claude Opus 4 Thinking 16K | 49.7 | 759 | 759/940 |
| 29 | DeepSeek R1 05/28 | 48.9 | 759 | 759/940 |
| 30 | Qwen 3 235B A22B 25-07 Think | 46.2 | 759 | 759/940 |
| 31 | Gemini 2.5 Pro Preview 05-06 | 42.5 | 651 | 651/940 |
| 32 | Claude Sonnet 4 Thinking 16K | 40.3 | 759 | 759/940 |
| 33 | Claude Sonnet 4 Thinking 64K | 39.6 | 651 | 651/940 |
| 34 | GPT-OSS-120B | 38.7 | 759 | 759/940 |
| 35 | DeepSeek R1 | 38.6 | 651 | 651/940 |
| 36 | Claude Opus 4.1 (no reasoning) | 37.1 | 759 | 759/940 |
| 37 | Qwen 3 30B A3B | 36.7 | 759 | 759/940 |
| 38 | Qwen 3 32B | 35.8 | 759 | 759/940 |
| 39 | Qwen 3 30B A3B 25-07 Thinking | 35.5 | 759 | 759/940 |
| 40 | Claude Opus 4 (no reasoning) | 34.4 | 759 | 759/940 |
| 41 | GPT-4.5 Preview | 34.2 | 651 | 651/940 |
| 42 | Claude 3.7 Sonnet Thinking 16K | 33.6 | 651 | 651/940 |
| 43 | Qwen 3 Next 80B A3B Thinking | 32.9 | 759 | 759/940 |
| 44 | Qwen QwQ-32B 16K | 31.4 | 651 | 651/940 |
| 45 | Grok 3 Mini Beta (high) | 30.2 | 759 | 759/940 |
| 46 | GLM-4.5 | 30.2 | 759 | 759/940 |
| 47 | Claude Opus 4.6 Thinking 32K | 28.1 | 98 | 98/940 |
| 48 | GPT-5 (minimal reasoning) | 27.3 | 759 | 759/940 |
| 49 | o1-mini | 27.0 | 651 | 651/940 |
| 50 | Claude Sonnet 4 (no reasoning) | 26.6 | 759 | 759/940 |
| 51 | Grok 3 Mini Beta (low) | 26.0 | 651 | 651/940 |
| 52 | Cohere Command A Reasoning 16K | 26.0 | 759 | 759/940 |
| 53 | Quasar Alpha | 25.4 | 651 | 651/940 |
| 54 | Gemini 2.5 Flash | 25.2 | 759 | 759/940 |
| 55 | Sherlock Dash Alpha | 25.2 | 759 | 759/940 |
| 56 | Grok 4 Fast Non-Reasoning | 25.0 | 759 | 759/940 |
| 57 | GPT-4o Mar 2025 | 24.5 | 759 | 759/940 |
| 58 | GLM-4.6 | 24.2 | 759 | 759/940 |
| 59 | Qwen 3 Max Preview | 23.9 | 759 | 759/940 |
| 60 | Kimi K2-0905 | 23.6 | 759 | 759/940 |
| 61 | Cohere Command A+ | 23.5 | 898 | 898/940 |
| 62 | Gemini 2.0 Flash Think Exp 01-21 | 23.1 | 649 | 649/940 |
| 63 | Sonoma Dusk Alpha | 22.9 | 759 | 759/940 |
| 64 | GPT-4.1 | 22.8 | 759 | 759/940 |
| 65 | GPT-4o Feb 2025 | 22.7 | 651 | 651/940 |
| 66 | GPT-5.1 (no reasoning) | 22.1 | 759 | 759/940 |
| 67 | Gemini 2.0 Pro Exp 02-05 | 21.9 | 651 | 651/940 |
| 68 | Polaris Alpha | 21.8 | 759 | 759/940 |
| 69 | DeepSeek V3.1 Non-Think | 21.6 | 759 | 759/940 |
| 70 | MiniMax-M1 | 21.3 | 688 | 688/940 |
| 71 | Kimi K2 | 19.8 | 759 | 759/940 |
| 72 | Qwen 3 235B A22B 25-07 Instruct | 19.8 | 759 | 759/940 |
| 73 | Grok 3 Beta (no reasoning) | 19.7 | 759 | 759/940 |
| 74 | Grok 2 12-12 | 19.2 | 651 | 651/940 |
| 75 | Gemini 1.5 Pro (Sept) | 19.2 | 601 | 601/940 |
| 76 | Claude 3 Opus | 19.2 | 650 | 650/940 |
| 77 | Claude 3.7 Sonnet | 19.2 | 651 | 651/940 |
| 78 | Gemini 2.0 Flash | 18.8 | 651 | 651/940 |
| 79 | GPT-4o 2024-11-20 | 18.7 | 601 | 601/940 |
| 80 | Qwen 2.5 Max | 18.0 | 651 | 651/940 |
| 81 | GPT-4o 2024-08-06 | 17.8 | 601 | 601/940 |
| 82 | Claude 3.5 Sonnet 2024-10-22 | 17.7 | 651 | 651/940 |
| 83 | Llama 4 Scout | 17.4 | 759 | 759/940 |
| 84 | DeepSeek V3-0324 | 16.8 | 759 | 759/940 |
| 85 | Llama 3.1 405B | 16.2 | 651 | 651/940 |
| 86 | Baidu Ernie 4.5 300B A47B | 15.3 | 759 | 759/940 |
| 87 | DeepSeek V4 Flash | 15.1 | 651 | 651/940 |
| 88 | Llama 3.3 70B | 15.1 | 651 | 651/940 |
| 89 | GPT-4.1 mini | 14.4 | 759 | 759/940 |
| 90 | MiniMax-Text-01 | 14.3 | 759 | 759/940 |
| 91 | LongCat Flash | 13.9 | 660 | 660/940 |
| 92 | Mistral Medium 3.1 | 13.3 | 759 | 759/940 |
| 93 | Cohere Command A | 13.1 | 759 | 759/940 |
| 94 | Mistral Large 2 | 12.4 | 759 | 759/940 |
| 95 | Gemma 2 27B | 12.2 | 651 | 651/940 |
| 96 | Gemma 3 27B | 11.6 | 759 | 759/940 |
| 97 | Mistral Small 3.1 | 11.4 | 651 | 651/940 |
| 98 | Mistral Small 3.2 | 11.4 | 759 | 759/940 |
| 99 | Amazon Nova Pro | 10.9 | 759 | 759/940 |
| 100 | Qwen 2.5 72B | 10.5 | 759 | 759/940 |
| 101 | Claude 3.5 Haiku | 10.0 | 759 | 759/940 |
| 102 | Microsoft Phi-4 | 9.9 | 759 | 759/940 |
| 103 | GPT-4o mini | 9.7 | 759 | 759/940 |
| 104 | Mistral Small 3 | 8.9 | 601 | 601/940 |
| 105 | GPT-4.1 nano | 8.1 | 759 | 759/940 |
| 106 | GLM4-32B-0414 | 7.6 | 759 | 759/940 |
| 107 | Claude 3 Haiku | 2.2 | 601 | 601/940 |
## 备注
- Claude Opus 4.7、Claude Opus 4.8 xhigh 和 Qwen 3.7 Max 已计算了拒绝/内容屏蔽的情况;被拒绝或被屏蔽的谜题按 0/4 计分。
- 如果谜题未完全解开,将获得部分分数。
- 每个谜题只允许尝试一次。在《纽约时报》网站上解谜的人类玩家有四次尝试机会,并在接近解决方案时收到通知。
- 此基准测试与《纽约时报》无关
## 其他多智能体基准测试
- [PACT - 在多轮买卖谈判中评估LLM谈判技巧的基准测试](https://github.com/lechmazur/pact)
- [BAZAAR - 在竞争性模拟市场中评估LLM的经济决策能力](https://github.com/lechmazur/bazaar)
- [公共物品游戏基准测试:贡献与惩罚](https://github.com/lechmazur/pgg_bench/)
- [淘汰游戏:多智能体LLM中的社会推理与欺骗](https://github.com/lechmazur/elimination_game/)
- [竞速赛:压力与误导](https://github.com/lechmazur/step_game/)
## 其他基准测试
- [LLM 主题泛化基准测试](https://github.com/lechmazur/generalization/)
- [LLM 创意故事写作基准测试](https://github.com/lechmazur/writing/)
- [LLM 往返翻译基准测试](https://github.com/lechmazur/translation/)
- [在微型小说中描绘LLM的风格与范围](https://github.com/lechmazur/writing_styles)
- [LLM 虚构/幻觉基准测试](https://github.com/lechmazur/confabulations/)
- [LLM 欺骗性与轻信度](https://github.com/lechmazur/deception/)
- [LLM 发散性思维创造力基准测试](https://github.com/lechmazur/divergent/)
## 更新日志
- 2026年5月28日:添加 Claude Opus 4.8。
- 2026年5月22日:添加 Qwen 3.7 Max。
- 2026年5月19日:添加 Gemini 3.5 Flash。
- 2026年5月12日:添加 Baidu ERNIE 5.1。
- 2026年5月1日:添加 Grok 4.3。
- 2026年4月29日:添加 Mistral Medium 3.5、Nemotron 3 Super。
- 2026年4月25日:添加 GPT-5.5、Kimi K2.6、Ling 2.6 1T、Tencent Hy3 Preview、DeepSeek V4 Pro、DeepSeek V4 Flash、Qwen 3.6 Max Preview。
- 2026年4月16日:添加 Claude Opus 4.7。
- 2026年4月15日:添加 GLM-5.1、Step 3.5 Flash、Qwen3.5-27B。
- 2026年4月6日:添加 GPT 5.4 (high)、Gemma 4 31B Reasoning、Qwen3.5-122B-A10B。
- 2026年4月4日:添加 MiniMax-M2.7。
- 2026年4月3日:添加 Arcee Trinity Large Thinking、Qwen 3.6 Plus、Gemma 4 31B。
- 2026年3月6日:添加 Grok 4.20 Beta Experimental、Gemini 3.1 Flash-Lite Preview。
- 2026年3月5日:添加 GPT-5.4。
- 2026年2月23日:添加 GLM-5。
- 2026年2月20日:添加 Gemini 3.1 Pro Preview、ByteDance Seed2.0 Pro、Baidu Ernie 5.0。
- 2026年2月17日:添加 Claude Sonnet 4.6、Qwen3.5-397B-A17B、MiniMax-M2.5。
- 2026年2月6日:添加 Claude Opus 4.6。
- 2026年2月2日:谜题总数达到940道。添加 Kimi K2.5 Thinking、Qwen3 Max (2026-01-23)、MiniMax-M2.1、DeepSeek V3.2。
- 2025年12月17日:添加 Gemini 3 Flash Preview。
- 2025年12月12日:添加 GPT 5.2 xhigh、GPT 5.2 Pro。
- 2025年12月11日:添加 GPT 5.2。
- 2025年12月2日:添加 Mistral Large 3。
- 2025年11月24日:添加 Claude Opus 4.5。
- 2025年11月21日:添加 Grok 4.1 Fast。
- 2025年11月18日:添加 Gemini 3 Pro Preview、GPT 5.1。
- 2025年11月12日:添加 Kimi K2 Thinking。
- 2025年10月15日:添加 Claude Haiku 4.5。
- 2025年10月14日:添加 Claude Sonnet 4.5、Deepseek V3.2 Exp、GLM-4.6。
- 2025年9月19日:添加 Grok 4 Fast、Qwen 3 Next 80B A3B Thinking、LongCat Flash Chat。
- 2025年9月6日:添加 Kimi K2-0905。
- 2025年9月5日:添加 Qwen 3 Max Preview、Qwen 3 235B A22B 25-07 Instruct。
- 2025年8月23日:添加 GPT-5 high reasoning 和 Cohere Command A Reasoning (16K)。
- 2025年8月22日:添加 DeepSeek 3.1、Qwen 3 30B A3B 25-07、Mistral Medium 3.1、GPT-5 minimal and low reasoning。
- 2025年8月7日:添加 GPT-5。
- 2025年8月5日:添加 Claude Opus 4.1、GPT-OSS-120B。
- 2025年7月28日:添加 GLM-4.5、Qwen 3 235B A22B 25-07 Thinking。
- 2025年7月14日:新增108道谜题。添加 Kimi K2。
- 2025年7月10日:添加 Grok 4。
- 2025年7月3日:添加 Qwen 3 32B、GLM4-32B-0414。
- 2025年7月2日:添加 Baidu Ernie 4.5 300B A47B、MiniMax-M1、Mistral Small 3.2。
- 2025年6月10日:添加 o3-pro。
- 2025年6月5日:添加 Gemini 2.5 Pro Preview 06-05。
- 2025年5月28日:添加 DeepSeek R1 05/28。
- 2025年5月22日:添加 Claude 4 系列模型。
- 2025年5月7日:添加 Gemini 2.5 Pro Preview 05-06。添加 Mistral Medium 3。
- 2025年4月30日:添加 Qwen 3。
- 2025年4月18日:添加 o3、o4-mini、Gemini 2.5 Flash Preview。
- 2025年4月15日:添加 GPT-4.1。
- 2025年4月10日:添加 Grok 3。
- 2025年4月5日:添加 Llama 4 Maverick、Llama 4 Scout。
- 2025年3月28日:添加 GPT-4o March 2025。
- 2025年3月25日:新增50道问题。添加 Gemini 2.5 Pro Exp 03-25 和 DeepSeek V3-0324。
- 2025年3月23日:添加“人类 vs. LLMs”部分。
- 2025年3月21日:添加 o1-pro。添加 o3-mini-high。
- 2025年3月17日:添加 Cohere Command A 和 Mistral Small 3.1。
- 2025年3月12日:添加 Gemma 3 27B。
- 2025年3月7日:添加 Qwen QwQ。
- 2025年2月27日:添加 GPT-4.5 Preview。
- 2025年2月24日:添加 Claude 3.7 Sonnet Thinking、Claude 3.7 Sonnet、GPT-4o Feb 2025、Qwen 2.5 Max、GPT-4o 2024-11-20。
- 2025年2月6日:添加 Gemini 2.0 Pro Exp 02-05。
- 2025年2月4日:推出带有额外词汇的更具挑战性的新版本。为最新的100道问题单独计分。相关性热力图。
- 2025年1月31日:添加 o3-mini (72.4)。
- 2025年1月30日:添加 Mistral Small 3 (10.5)。
- 2025年1月29日:添加 DeepSeek R1 (54.5)。
- 2025年1月28日:添加 Qwen 2.5 Max (18.6)。
- 2025年1月22日:添加 Phi-4 (11.6)、Nova Pro (12.5)、Gemini 2.0 Flash Thinking Exp 01-21 (37.0)。
- 2025年1月16日:添加 Gemini 2.0 Flash Thinking Exp、o1、MiniMax-Text-01。Gemini 2.0 Flash Thinking Exp 有时会达到输出 token 限制。
- 2024年12月27日:添加 GPT-4o 2024-11-20、Llama 3.3 70B、Gemini 2.0 Flash Exp、Deepseek-V3。Gemini 2.0 Flash Thinking Exp 因其输出在某些谜题上被截断而无法进行基准测试。
- 添加 Claude 3.5 Haiku。得分 13.7。
- 添加 Claude 3.5 Sonnet (2024-10-22)。得分从 25.9 提升至 24.4。
- 添加 Grok Beta。得分从 21.3 提升至 23.7。它被描述为“具有最先进推理能力的实验性语言模型,最适合复杂和多步骤用例。它是 Grok 2 的继承者,具有增强的上下文长度。”
- 在 X (Twitter) 上关注 [@lechmazur](https://x.com/LechMazur) 以获取其他即将推出的基准测试及更多信息。
o1的胜率为98.9%,接近这一精英水平。o1-pro尚未在此游戏模拟设置中测试,或许能够匹配这些顶尖人类。因此,直接判断AI在《纽约时报》Connections上是否实现了超人表现,可能取决于比较在完全解决每个谜题之前所犯错误的数量。
# 原版《纽约时报》Connections LLM基准测试
该基准测试使用436道《纽约时报》Connections谜题评估大型语言模型(LLMs)。使用了三种不同的提示,这些提示没有经过针对LLM的提示工程优化。同时评估了大写和小写谜题。更简单 - 未添加额外词汇。
### 图表:原版

### 排行榜:原版
| 模型 | 得分 |
| --- | --- |
| o1 | 90.7 |
| o1-preview | 87.1 |
| o3-mini | 72.4 |
| DeepSeek R1 | 54.4 |
| o1-mini | 42.2 |
| Multi-turn ensemble | 37.8 |
| Gemini 2.0 Flash Thinking Exp 01-21 | 37.0 |
| GPT-4 Turbo | 28.3 |
| GPT-4o 2024-11-20 | 27.9 |
| GPT-4o 2024-08-06 | 26.5 |
| Llama 3.1 405B | 26.3 |
| Claude 3.5 Sonnet (2024-10-22) | 25.9 |
| Claude 3 Opus | 24.8 |
| Grok Beta | 23.7 |
| Llama 3.3 70B | 23.7 |
| Gemini 1.5 Pro (Sept) | 22.7 |
| Deepseek-V3 | 21.0 |
| Gemini 2.0 Flash Exp | 20.0 |
| Gemma 2 27B | 18.8 |
| Qwen 2.5 Max | 18.6 |
| Gemini 2.0 Flash Thinking Exp | 18.6 |
| Mistral Large 2 | 17.4 |
| Qwen 2.5 72B | 14.8 |
| Claude 3.5 Haiku | 13.7 |
| MiniMax-Text-01 | 13.6 |
| Nova Pro | 12.5 |
| Phi-4 | 11.6 |
| Mistral Small 3 | 10.5 |
| DeepSeek-V2.5 | 9.9 |
### 排行榜:旧版模型
这些模型因运行的谜题总数少于940道而被排除在主榜之外。
| 排名 | 模型 | 得分百分比 | 谜题数量(窗口) | 总覆盖范围 |
| ---: | --- | ---: | ---: | ---: |
| 1 | Sherlock Think Alpha | 92.5 | 759 | 759/940 |
| 2 | Grok 4 Fast Reasoning | 92.2 | 759 | 759/940 |
| 3 | Grok 4 | 91.8 | 759 | 759/940 |
| 4 | Sonoma Sky Alpha | 90.8 | 759 | 759/940 |
| 5 | o3-pro (medium reasoning) | 87.3 | 759 | 759/940 |
| 6 | GPT-5 Pro | 83.9 | 759 | 759/940 |
| 7 | o1-pro (medium reasoning) | 82.4 | 651 | 651/940 |
| 8 | o3 (high reasoning) | 78.6 | 759 | 759/940 |
| 9 | GPT-5 (high reasoning) | 77.1 | 759 | 759/940 |
| 10 | o4-mini (high reasoning) | 73.6 | 759 | 759/940 |
| 11 | o3 (medium reasoning) | 73.0 | 759 | 759/940 |
| 12 | GPT-5 (medium reasoning) | 72.2 | 759 | 759/940 |
| 13 | o1 (medium reasoning) | 70.9 | 651 | 651/940 |
| 14 | GPT-5.1 (high reasoning) | 70.0 | 759 | 759/940 |
| 15 | o4-mini (medium reasoning) | 68.8 | 651 | 651/940 |
| 16 | GPT-5 mini (medium reasoning) | 67.0 | 759 | 759/940 |
| 17 | GPT-5 (low reasoning) | 65.4 | 759 | 759/940 |
| 18 | GPT-5.1 (medium reasoning) | 62.7 | 759 | 759/940 |
| 19 | o3-mini (high reasoning) | 61.4 | 651 | 651/940 |
| 20 | GLM-4.7 | 59.5 | 767 | 767/940 |
| 21 | Claude Opus 4.1 Thinking 16K | 58.8 | 759 | 759/940 |
| 22 | DeepSeek V4 Flash (thinking) | 57.7 | 759 | 759/940 |
| 23 | Gemini 2.5 Pro | 57.7 | 759 | 759/940 |
| 24 | Kimi K2 Thinking 64K | 57.4 | 924 | 924/940 |
| 25 | Qwen 3 235B A22B | 54.6 | 759 | 759/940 |
| 26 | Gemini 2.5 Pro Exp 03-25 | 54.1 | 651 | 651/940 |
| 27 | o3-mini (medium reasoning) | 53.6 | 651 | 651/940 |
| 28 | Claude Opus 4 Thinking 16K | 49.7 | 759 | 759/940 |
| 29 | DeepSeek R1 05/28 | 48.9 | 759 | 759/940 |
| 30 | Qwen 3 235B A22B 25-07 Think | 46.2 | 759 | 759/940 |
| 31 | Gemini 2.5 Pro Preview 05-06 | 42.5 | 651 | 651/940 |
| 32 | Claude Sonnet 4 Thinking 16K | 40.3 | 759 | 759/940 |
| 33 | Claude Sonnet 4 Thinking 64K | 39.6 | 651 | 651/940 |
| 34 | GPT-OSS-120B | 38.7 | 759 | 759/940 |
| 35 | DeepSeek R1 | 38.6 | 651 | 651/940 |
| 36 | Claude Opus 4.1 (no reasoning) | 37.1 | 759 | 759/940 |
| 37 | Qwen 3 30B A3B | 36.7 | 759 | 759/940 |
| 38 | Qwen 3 32B | 35.8 | 759 | 759/940 |
| 39 | Qwen 3 30B A3B 25-07 Thinking | 35.5 | 759 | 759/940 |
| 40 | Claude Opus 4 (no reasoning) | 34.4 | 759 | 759/940 |
| 41 | GPT-4.5 Preview | 34.2 | 651 | 651/940 |
| 42 | Claude 3.7 Sonnet Thinking 16K | 33.6 | 651 | 651/940 |
| 43 | Qwen 3 Next 80B A3B Thinking | 32.9 | 759 | 759/940 |
| 44 | Qwen QwQ-32B 16K | 31.4 | 651 | 651/940 |
| 45 | Grok 3 Mini Beta (high) | 30.2 | 759 | 759/940 |
| 46 | GLM-4.5 | 30.2 | 759 | 759/940 |
| 47 | Claude Opus 4.6 Thinking 32K | 28.1 | 98 | 98/940 |
| 48 | GPT-5 (minimal reasoning) | 27.3 | 759 | 759/940 |
| 49 | o1-mini | 27.0 | 651 | 651/940 |
| 50 | Claude Sonnet 4 (no reasoning) | 26.6 | 759 | 759/940 |
| 51 | Grok 3 Mini Beta (low) | 26.0 | 651 | 651/940 |
| 52 | Cohere Command A Reasoning 16K | 26.0 | 759 | 759/940 |
| 53 | Quasar Alpha | 25.4 | 651 | 651/940 |
| 54 | Gemini 2.5 Flash | 25.2 | 759 | 759/940 |
| 55 | Sherlock Dash Alpha | 25.2 | 759 | 759/940 |
| 56 | Grok 4 Fast Non-Reasoning | 25.0 | 759 | 759/940 |
| 57 | GPT-4o Mar 2025 | 24.5 | 759 | 759/940 |
| 58 | GLM-4.6 | 24.2 | 759 | 759/940 |
| 59 | Qwen 3 Max Preview | 23.9 | 759 | 759/940 |
| 60 | Kimi K2-0905 | 23.6 | 759 | 759/940 |
| 61 | Cohere Command A+ | 23.5 | 898 | 898/940 |
| 62 | Gemini 2.0 Flash Think Exp 01-21 | 23.1 | 649 | 649/940 |
| 63 | Sonoma Dusk Alpha | 22.9 | 759 | 759/940 |
| 64 | GPT-4.1 | 22.8 | 759 | 759/940 |
| 65 | GPT-4o Feb 2025 | 22.7 | 651 | 651/940 |
| 66 | GPT-5.1 (no reasoning) | 22.1 | 759 | 759/940 |
| 67 | Gemini 2.0 Pro Exp 02-05 | 21.9 | 651 | 651/940 |
| 68 | Polaris Alpha | 21.8 | 759 | 759/940 |
| 69 | DeepSeek V3.1 Non-Think | 21.6 | 759 | 759/940 |
| 70 | MiniMax-M1 | 21.3 | 688 | 688/940 |
| 71 | Kimi K2 | 19.8 | 759 | 759/940 |
| 72 | Qwen 3 235B A22B 25-07 Instruct | 19.8 | 759 | 759/940 |
| 73 | Grok 3 Beta (no reasoning) | 19.7 | 759 | 759/940 |
| 74 | Grok 2 12-12 | 19.2 | 651 | 651/940 |
| 75 | Gemini 1.5 Pro (Sept) | 19.2 | 601 | 601/940 |
| 76 | Claude 3 Opus | 19.2 | 650 | 650/940 |
| 77 | Claude 3.7 Sonnet | 19.2 | 651 | 651/940 |
| 78 | Gemini 2.0 Flash | 18.8 | 651 | 651/940 |
| 79 | GPT-4o 2024-11-20 | 18.7 | 601 | 601/940 |
| 80 | Qwen 2.5 Max | 18.0 | 651 | 651/940 |
| 81 | GPT-4o 2024-08-06 | 17.8 | 601 | 601/940 |
| 82 | Claude 3.5 Sonnet 2024-10-22 | 17.7 | 651 | 651/940 |
| 83 | Llama 4 Scout | 17.4 | 759 | 759/940 |
| 84 | DeepSeek V3-0324 | 16.8 | 759 | 759/940 |
| 85 | Llama 3.1 405B | 16.2 | 651 | 651/940 |
| 86 | Baidu Ernie 4.5 300B A47B | 15.3 | 759 | 759/940 |
| 87 | DeepSeek V4 Flash | 15.1 | 651 | 651/940 |
| 88 | Llama 3.3 70B | 15.1 | 651 | 651/940 |
| 89 | GPT-4.1 mini | 14.4 | 759 | 759/940 |
| 90 | MiniMax-Text-01 | 14.3 | 759 | 759/940 |
| 91 | LongCat Flash | 13.9 | 660 | 660/940 |
| 92 | Mistral Medium 3.1 | 13.3 | 759 | 759/940 |
| 93 | Cohere Command A | 13.1 | 759 | 759/940 |
| 94 | Mistral Large 2 | 12.4 | 759 | 759/940 |
| 95 | Gemma 2 27B | 12.2 | 651 | 651/940 |
| 96 | Gemma 3 27B | 11.6 | 759 | 759/940 |
| 97 | Mistral Small 3.1 | 11.4 | 651 | 651/940 |
| 98 | Mistral Small 3.2 | 11.4 | 759 | 759/940 |
| 99 | Amazon Nova Pro | 10.9 | 759 | 759/940 |
| 100 | Qwen 2.5 72B | 10.5 | 759 | 759/940 |
| 101 | Claude 3.5 Haiku | 10.0 | 759 | 759/940 |
| 102 | Microsoft Phi-4 | 9.9 | 759 | 759/940 |
| 103 | GPT-4o mini | 9.7 | 759 | 759/940 |
| 104 | Mistral Small 3 | 8.9 | 601 | 601/940 |
| 105 | GPT-4.1 nano | 8.1 | 759 | 759/940 |
| 106 | GLM4-32B-0414 | 7.6 | 759 | 759/940 |
| 107 | Claude 3 Haiku | 2.2 | 601 | 601/940 |
## 备注
- Claude Opus 4.7、Claude Opus 4.8 xhigh 和 Qwen 3.7 Max 已计算了拒绝/内容屏蔽的情况;被拒绝或被屏蔽的谜题按 0/4 计分。
- 如果谜题未完全解开,将获得部分分数。
- 每个谜题只允许尝试一次。在《纽约时报》网站上解谜的人类玩家有四次尝试机会,并在接近解决方案时收到通知。
- 此基准测试与《纽约时报》无关
## 其他多智能体基准测试
- [PACT - 在多轮买卖谈判中评估LLM谈判技巧的基准测试](https://github.com/lechmazur/pact)
- [BAZAAR - 在竞争性模拟市场中评估LLM的经济决策能力](https://github.com/lechmazur/bazaar)
- [公共物品游戏基准测试:贡献与惩罚](https://github.com/lechmazur/pgg_bench/)
- [淘汰游戏:多智能体LLM中的社会推理与欺骗](https://github.com/lechmazur/elimination_game/)
- [竞速赛:压力与误导](https://github.com/lechmazur/step_game/)
## 其他基准测试
- [LLM 主题泛化基准测试](https://github.com/lechmazur/generalization/)
- [LLM 创意故事写作基准测试](https://github.com/lechmazur/writing/)
- [LLM 往返翻译基准测试](https://github.com/lechmazur/translation/)
- [在微型小说中描绘LLM的风格与范围](https://github.com/lechmazur/writing_styles)
- [LLM 虚构/幻觉基准测试](https://github.com/lechmazur/confabulations/)
- [LLM 欺骗性与轻信度](https://github.com/lechmazur/deception/)
- [LLM 发散性思维创造力基准测试](https://github.com/lechmazur/divergent/)
## 更新日志
- 2026年5月28日:添加 Claude Opus 4.8。
- 2026年5月22日:添加 Qwen 3.7 Max。
- 2026年5月19日:添加 Gemini 3.5 Flash。
- 2026年5月12日:添加 Baidu ERNIE 5.1。
- 2026年5月1日:添加 Grok 4.3。
- 2026年4月29日:添加 Mistral Medium 3.5、Nemotron 3 Super。
- 2026年4月25日:添加 GPT-5.5、Kimi K2.6、Ling 2.6 1T、Tencent Hy3 Preview、DeepSeek V4 Pro、DeepSeek V4 Flash、Qwen 3.6 Max Preview。
- 2026年4月16日:添加 Claude Opus 4.7。
- 2026年4月15日:添加 GLM-5.1、Step 3.5 Flash、Qwen3.5-27B。
- 2026年4月6日:添加 GPT 5.4 (high)、Gemma 4 31B Reasoning、Qwen3.5-122B-A10B。
- 2026年4月4日:添加 MiniMax-M2.7。
- 2026年4月3日:添加 Arcee Trinity Large Thinking、Qwen 3.6 Plus、Gemma 4 31B。
- 2026年3月6日:添加 Grok 4.20 Beta Experimental、Gemini 3.1 Flash-Lite Preview。
- 2026年3月5日:添加 GPT-5.4。
- 2026年2月23日:添加 GLM-5。
- 2026年2月20日:添加 Gemini 3.1 Pro Preview、ByteDance Seed2.0 Pro、Baidu Ernie 5.0。
- 2026年2月17日:添加 Claude Sonnet 4.6、Qwen3.5-397B-A17B、MiniMax-M2.5。
- 2026年2月6日:添加 Claude Opus 4.6。
- 2026年2月2日:谜题总数达到940道。添加 Kimi K2.5 Thinking、Qwen3 Max (2026-01-23)、MiniMax-M2.1、DeepSeek V3.2。
- 2025年12月17日:添加 Gemini 3 Flash Preview。
- 2025年12月12日:添加 GPT 5.2 xhigh、GPT 5.2 Pro。
- 2025年12月11日:添加 GPT 5.2。
- 2025年12月2日:添加 Mistral Large 3。
- 2025年11月24日:添加 Claude Opus 4.5。
- 2025年11月21日:添加 Grok 4.1 Fast。
- 2025年11月18日:添加 Gemini 3 Pro Preview、GPT 5.1。
- 2025年11月12日:添加 Kimi K2 Thinking。
- 2025年10月15日:添加 Claude Haiku 4.5。
- 2025年10月14日:添加 Claude Sonnet 4.5、Deepseek V3.2 Exp、GLM-4.6。
- 2025年9月19日:添加 Grok 4 Fast、Qwen 3 Next 80B A3B Thinking、LongCat Flash Chat。
- 2025年9月6日:添加 Kimi K2-0905。
- 2025年9月5日:添加 Qwen 3 Max Preview、Qwen 3 235B A22B 25-07 Instruct。
- 2025年8月23日:添加 GPT-5 high reasoning 和 Cohere Command A Reasoning (16K)。
- 2025年8月22日:添加 DeepSeek 3.1、Qwen 3 30B A3B 25-07、Mistral Medium 3.1、GPT-5 minimal and low reasoning。
- 2025年8月7日:添加 GPT-5。
- 2025年8月5日:添加 Claude Opus 4.1、GPT-OSS-120B。
- 2025年7月28日:添加 GLM-4.5、Qwen 3 235B A22B 25-07 Thinking。
- 2025年7月14日:新增108道谜题。添加 Kimi K2。
- 2025年7月10日:添加 Grok 4。
- 2025年7月3日:添加 Qwen 3 32B、GLM4-32B-0414。
- 2025年7月2日:添加 Baidu Ernie 4.5 300B A47B、MiniMax-M1、Mistral Small 3.2。
- 2025年6月10日:添加 o3-pro。
- 2025年6月5日:添加 Gemini 2.5 Pro Preview 06-05。
- 2025年5月28日:添加 DeepSeek R1 05/28。
- 2025年5月22日:添加 Claude 4 系列模型。
- 2025年5月7日:添加 Gemini 2.5 Pro Preview 05-06。添加 Mistral Medium 3。
- 2025年4月30日:添加 Qwen 3。
- 2025年4月18日:添加 o3、o4-mini、Gemini 2.5 Flash Preview。
- 2025年4月15日:添加 GPT-4.1。
- 2025年4月10日:添加 Grok 3。
- 2025年4月5日:添加 Llama 4 Maverick、Llama 4 Scout。
- 2025年3月28日:添加 GPT-4o March 2025。
- 2025年3月25日:新增50道问题。添加 Gemini 2.5 Pro Exp 03-25 和 DeepSeek V3-0324。
- 2025年3月23日:添加“人类 vs. LLMs”部分。
- 2025年3月21日:添加 o1-pro。添加 o3-mini-high。
- 2025年3月17日:添加 Cohere Command A 和 Mistral Small 3.1。
- 2025年3月12日:添加 Gemma 3 27B。
- 2025年3月7日:添加 Qwen QwQ。
- 2025年2月27日:添加 GPT-4.5 Preview。
- 2025年2月24日:添加 Claude 3.7 Sonnet Thinking、Claude 3.7 Sonnet、GPT-4o Feb 2025、Qwen 2.5 Max、GPT-4o 2024-11-20。
- 2025年2月6日:添加 Gemini 2.0 Pro Exp 02-05。
- 2025年2月4日:推出带有额外词汇的更具挑战性的新版本。为最新的100道问题单独计分。相关性热力图。
- 2025年1月31日:添加 o3-mini (72.4)。
- 2025年1月30日:添加 Mistral Small 3 (10.5)。
- 2025年1月29日:添加 DeepSeek R1 (54.5)。
- 2025年1月28日:添加 Qwen 2.5 Max (18.6)。
- 2025年1月22日:添加 Phi-4 (11.6)、Nova Pro (12.5)、Gemini 2.0 Flash Thinking Exp 01-21 (37.0)。
- 2025年1月16日:添加 Gemini 2.0 Flash Thinking Exp、o1、MiniMax-Text-01。Gemini 2.0 Flash Thinking Exp 有时会达到输出 token 限制。
- 2024年12月27日:添加 GPT-4o 2024-11-20、Llama 3.3 70B、Gemini 2.0 Flash Exp、Deepseek-V3。Gemini 2.0 Flash Thinking Exp 因其输出在某些谜题上被截断而无法进行基准测试。
- 添加 Claude 3.5 Haiku。得分 13.7。
- 添加 Claude 3.5 Sonnet (2024-10-22)。得分从 25.9 提升至 24.4。
- 添加 Grok Beta。得分从 21.3 提升至 23.7。它被描述为“具有最先进推理能力的实验性语言模型,最适合复杂和多步骤用例。它是 Grok 2 的继承者,具有增强的上下文长度。”
- 在 X (Twitter) 上关注 [@lechmazur](https://x.com/LechMazur) 以获取其他即将推出的基准测试及更多信息。
o1的胜率为98.9%,接近这一精英水平。o1-pro尚未在此游戏模拟设置中测试,或许能够匹配这些顶尖人类。因此,直接判断AI在《纽约时报》Connections上是否实现了超人表现,可能取决于比较在完全解决每个谜题之前所犯错误的数量。
# 原版《纽约时报》Connections LLM基准测试
该基准测试使用436道《纽约时报》Connections谜题评估大型语言模型(LLMs)。使用了三种不同的提示,这些提示没有经过针对LLM的提示工程优化。同时评估了大写和小写谜题。更简单 - 未添加额外词汇。
### 图表:原版

### 排行榜:原版
| 模型 | 得分 |
| --- | --- |
| o1 | 90.7 |
| o1-preview | 87.1 |
| o3-mini | 72.4 |
| DeepSeek R1 | 54.4 |
| o1-mini | 42.2 |
| Multi-turn ensemble | 37.8 |
| Gemini 2.0 Flash Thinking Exp 01-21 | 37.0 |
| GPT-4 Turbo | 28.3 |
| GPT-4o 2024-11-20 | 27.9 |
| GPT-4o 2024-08-06 | 26.5 |
| Llama 3.1 405B | 26.3 |
| Claude 3.5 Sonnet (2024-10-22) | 25.9 |
| Claude 3 Opus | 24.8 |
| Grok Beta | 23.7 |
| Llama 3.3 70B | 23.7 |
| Gemini 1.5 Pro (Sept) | 22.7 |
| Deepseek-V3 | 21.0 |
| Gemini 2.0 Flash Exp | 20.0 |
| Gemma 2 27B | 18.8 |
| Qwen 2.5 Max | 18.6 |
| Gemini 2.0 Flash Thinking Exp | 18.6 |
| Mistral Large 2 | 17.4 |
| Qwen 2.5 72B | 14.8 |
| Claude 3.5 Haiku | 13.7 |
| MiniMax-Text-01 | 13.6 |
| Nova Pro | 12.5 |
| Phi-4 | 11.6 |
| Mistral Small 3 | 10.5 |
| DeepSeek-V2.5 | 9.9 |
### 排行榜:旧版模型
这些模型因运行的谜题总数少于940道而被排除在主榜之外。
| 排名 | 模型 | 得分百分比 | 谜题数量(窗口) | 总覆盖范围 |
| ---: | --- | ---: | ---: | ---: |
| 1 | Sherlock Think Alpha | 92.5 | 759 | 759/940 |
| 2 | Grok 4 Fast Reasoning | 92.2 | 759 | 759/940 |
| 3 | Grok 4 | 91.8 | 759 | 759/940 |
| 4 | Sonoma Sky Alpha | 90.8 | 759 | 759/940 |
| 5 | o3-pro (medium reasoning) | 87.3 | 759 | 759/940 |
| 6 | GPT-5 Pro | 83.9 | 759 | 759/940 |
| 7 | o1-pro (medium reasoning) | 82.4 | 651 | 651/940 |
| 8 | o3 (high reasoning) | 78.6 | 759 | 759/940 |
| 9 | GPT-5 (high reasoning) | 77.1 | 759 | 759/940 |
| 10 | o4-mini (high reasoning) | 73.6 | 759 | 759/940 |
| 11 | o3 (medium reasoning) | 73.0 | 759 | 759/940 |
| 12 | GPT-5 (medium reasoning) | 72.2 | 759 | 759/940 |
| 13 | o1 (medium reasoning) | 70.9 | 651 | 651/940 |
| 14 | GPT-5.1 (high reasoning) | 70.0 | 759 | 759/940 |
| 15 | o4-mini (medium reasoning) | 68.8 | 651 | 651/940 |
| 16 | GPT-5 mini (medium reasoning) | 67.0 | 759 | 759/940 |
| 17 | GPT-5 (low reasoning) | 65.4 | 759 | 759/940 |
| 18 | GPT-5.1 (medium reasoning) | 62.7 | 759 | 759/940 |
| 19 | o3-mini (high reasoning) | 61.4 | 651 | 651/940 |
| 20 | GLM-4.7 | 59.5 | 767 | 767/940 |
| 21 | Claude Opus 4.1 Thinking 16K | 58.8 | 759 | 759/940 |
| 22 | DeepSeek V4 Flash (thinking) | 57.7 | 759 | 759/940 |
| 23 | Gemini 2.5 Pro | 57.7 | 759 | 759/940 |
| 24 | Kimi K2 Thinking 64K | 57.4 | 924 | 924/940 |
| 25 | Qwen 3 235B A22B | 54.6 | 759 | 759/940 |
| 26 | Gemini 2.5 Pro Exp 03-25 | 54.1 | 651 | 651/940 |
| 27 | o3-mini (medium reasoning) | 53.6 | 651 | 651/940 |
| 28 | Claude Opus 4 Thinking 16K | 49.7 | 759 | 759/940 |
| 29 | DeepSeek R1 05/28 | 48.9 | 759 | 759/940 |
| 30 | Qwen 3 235B A22B 25-07 Think | 46.2 | 759 | 759/940 |
| 31 | Gemini 2.5 Pro Preview 05-06 | 42.5 | 651 | 651/940 |
| 32 | Claude Sonnet 4 Thinking 16K | 40.3 | 759 | 759/940 |
| 33 | Claude Sonnet 4 Thinking 64K | 39.6 | 651 | 651/940 |
| 34 | GPT-OSS-120B | 38.7 | 759 | 759/940 |
| 35 | DeepSeek R1 | 38.6 | 651 | 651/940 |
| 36 | Claude Opus 4.1 (no reasoning) | 37.1 | 759 | 759/940 |
| 37 | Qwen 3 30B A3B | 36.7 | 759 | 759/940 |
| 38 | Qwen 3 32B | 35.8 | 759 | 759/940 |
| 39 | Qwen 3 30B A3B 25-07 Thinking | 35.5 | 759 | 759/940 |
| 40 | Claude Opus 4 (no reasoning) | 34.4 | 759 | 759/940 |
| 41 | GPT-4.5 Preview | 34.2 | 651 | 651/940 |
| 42 | Claude 3.7 Sonnet Thinking 16K | 33.6 | 651 | 651/940 |
| 43 | Qwen 3 Next 80B A3B Thinking | 32.9 | 759 | 759/940 |
| 44 | Qwen QwQ-32B 16K | 31.4 | 651 | 651/940 |
| 45 | Grok 3 Mini Beta (high) | 30.2 | 759 | 759/940 |
| 46 | GLM-4.5 | 30.2 | 759 | 759/940 |
| 47 | Claude Opus 4.6 Thinking 32K | 28.1 | 98 | 98/940 |
| 48 | GPT-5 (minimal reasoning) | 27.3 | 759 | 759/940 |
| 49 | o1-mini | 27.0 | 651 | 651/940 |
| 50 | Claude Sonnet 4 (no reasoning) | 26.6 | 759 | 759/940 |
| 51 | Grok 3 Mini Beta (low) | 26.0 | 651 | 651/940 |
| 52 | Cohere Command A Reasoning 16K | 26.0 | 759 | 759/940 |
| 53 | Quasar Alpha | 25.4 | 651 | 651/940 |
| 54 | Gemini 2.5 Flash | 25.2 | 759 | 759/940 |
| 55 | Sherlock Dash Alpha | 25.2 | 759 | 759/940 |
| 56 | Grok 4 Fast Non-Reasoning | 25.0 | 759 | 759/940 |
| 57 | GPT-4o Mar 2025 | 24.5 | 759 | 759/940 |
| 58 | GLM-4.6 | 24.2 | 759 | 759/940 |
| 59 | Qwen 3 Max Preview | 23.9 | 759 | 759/940 |
| 60 | Kimi K2-0905 | 23.6 | 759 | 759/940 |
| 61 | Cohere Command A+ | 23.5 | 898 | 898/940 |
| 62 | Gemini 2.0 Flash Think Exp 01-21 | 23.1 | 649 | 649/940 |
| 63 | Sonoma Dusk Alpha | 22.9 | 759 | 759/940 |
| 64 | GPT-4.1 | 22.8 | 759 | 759/940 |
| 65 | GPT-4o Feb 2025 | 22.7 | 651 | 651/940 |
| 66 | GPT-5.1 (no reasoning) | 22.1 | 759 | 759/940 |
| 67 | Gemini 2.0 Pro Exp 02-05 | 21.9 | 651 | 651/940 |
| 68 | Polaris Alpha | 21.8 | 759 | 759/940 |
| 69 | DeepSeek V3.1 Non-Think | 21.6 | 759 | 759/940 |
| 70 | MiniMax-M1 | 21.3 | 688 | 688/940 |
| 71 | Kimi K2 | 19.8 | 759 | 759/940 |
| 72 | Qwen 3 235B A22B 25-07 Instruct | 19.8 | 759 | 759/940 |
| 73 | Grok 3 Beta (no reasoning) | 19.7 | 759 | 759/940 |
| 74 | Grok 2 12-12 | 19.2 | 651 | 651/940 |
| 75 | Gemini 1.5 Pro (Sept) | 19.2 | 601 | 601/940 |
| 76 | Claude 3 Opus | 19.2 | 650 | 650/940 |
| 77 | Claude 3.7 Sonnet | 19.2 | 651 | 651/940 |
| 78 | Gemini 2.0 Flash | 18.8 | 651 | 651/940 |
| 79 | GPT-4o 2024-11-20 | 18.7 | 601 | 601/940 |
| 80 | Qwen 2.5 Max | 18.0 | 651 | 651/940 |
| 81 | GPT-4o 2024-08-06 | 17.8 | 601 | 601/940 |
| 82 | Claude 3.5 Sonnet 2024-10-22 | 17.7 | 651 | 651/940 |
| 83 | Llama 4 Scout | 17.4 | 759 | 759/940 |
| 84 | DeepSeek V3-0324 | 16.8 | 759 | 759/940 |
| 85 | Llama 3.1 405B | 16.2 | 651 | 651/940 |
| 86 | Baidu Ernie 4.5 300B A47B | 15.3 | 759 | 759/940 |
| 87 | DeepSeek V4 Flash | 15.1 | 651 | 651/940 |
| 88 | Llama 3.3 70B | 15.1 | 651 | 651/940 |
| 89 | GPT-4.1 mini | 14.4 | 759 | 759/940 |
| 90 | MiniMax-Text-01 | 14.3 | 759 | 759/940 |
| 91 | LongCat Flash | 13.9 | 660 | 660/940 |
| 92 | Mistral Medium 3.1 | 13.3 | 759 | 759/940 |
| 93 | Cohere Command A | 13.1 | 759 | 759/940 |
| 94 | Mistral Large 2 | 12.4 | 759 | 759/940 |
| 95 | Gemma 2 27B | 12.2 | 651 | 651/940 |
| 96 | Gemma 3 27B | 11.6 | 759 | 759/940 |
| 97 | Mistral Small 3.1 | 11.4 | 651 | 651/940 |
| 98 | Mistral Small 3.2 | 11.4 | 759 | 759/940 |
| 99 | Amazon Nova Pro | 10.9 | 759 | 759/940 |
| 100 | Qwen 2.5 72B | 10.5 | 759 | 759/940 |
| 101 | Claude 3.5 Haiku | 10.0 | 759 | 759/940 |
| 102 | Microsoft Phi-4 | 9.9 | 759 | 759/940 |
| 103 | GPT-4o mini | 9.7 | 759 | 759/940 |
| 104 | Mistral Small 3 | 8.9 | 601 | 601/940 |
| 105 | GPT-4.1 nano | 8.1 | 759 | 759/940 |
| 106 | GLM4-32B-0414 | 7.6 | 759 | 759/940 |
| 107 | Claude 3 Haiku | 2.2 | 601 | 601/940 |
## 备注
- Claude Opus 4.7、Claude Opus 4.8 xhigh 和 Qwen 3.7 Max 已计算了拒绝/内容屏蔽的情况;被拒绝或被屏蔽的谜题按 0/4 计分。
- 如果谜题未完全解开,将获得部分分数。
- 每个谜题只允许尝试一次。在《纽约时报》网站上解谜的人类玩家有四次尝试机会,并在接近解决方案时收到通知。
- 此基准测试与《纽约时报》无关
## 其他多智能体基准测试
- [PACT - 在多轮买卖谈判中评估LLM谈判技巧的基准测试](https://github.com/lechmazur/pact)
- [BAZAAR - 在竞争性模拟市场中评估LLM的经济决策能力](https://github.com/lechmazur/bazaar)
- [公共物品游戏基准测试:贡献与惩罚](https://github.com/lechmazur/pgg_bench/)
- [淘汰游戏:多智能体LLM中的社会推理与欺骗](https://github.com/lechmazur/elimination_game/)
- [竞速赛:压力与误导](https://github.com/lechmazur/step_game/)
## 其他基准测试
- [LLM 主题泛化基准测试](https://github.com/lechmazur/generalization/)
- [LLM 创意故事写作基准测试](https://github.com/lechmazur/writing/)
- [LLM 往返翻译基准测试](https://github.com/lechmazur/translation/)
- [在微型小说中描绘LLM的风格与范围](https://github.com/lechmazur/writing_styles)
- [LLM 虚构/幻觉基准测试](https://github.com/lechmazur/confabulations/)
- [LLM 欺骗性与轻信度](https://github.com/lechmazur/deception/)
- [LLM 发散性思维创造力基准测试](https://github.com/lechmazur/divergent/)
## 更新日志
- 2026年5月28日:添加 Claude Opus 4.8。
- 2026年5月22日:添加 Qwen 3.7 Max。
- 2026年5月19日:添加 Gemini 3.5 Flash。
- 2026年5月12日:添加 Baidu ERNIE 5.1。
- 2026年5月1日:添加 Grok 4.3。
- 2026年4月29日:添加 Mistral Medium 3.5、Nemotron 3 Super。
- 2026年4月25日:添加 GPT-5.5、Kimi K2.6、Ling 2.6 1T、Tencent Hy3 Preview、DeepSeek V4 Pro、DeepSeek V4 Flash、Qwen 3.6 Max Preview。
- 2026年4月16日:添加 Claude Opus 4.7。
- 2026年4月15日:添加 GLM-5.1、Step 3.5 Flash、Qwen3.5-27B。
- 2026年4月6日:添加 GPT 5.4 (high)、Gemma 4 31B Reasoning、Qwen3.5-122B-A10B。
- 2026年4月4日:添加 MiniMax-M2.7。
- 2026年4月3日:添加 Arcee Trinity Large Thinking、Qwen 3.6 Plus、Gemma 4 31B。
- 2026年3月6日:添加 Grok 4.20 Beta Experimental、Gemini 3.1 Flash-Lite Preview。
- 2026年3月5日:添加 GPT-5.4。
- 2026年2月23日:添加 GLM-5。
- 2026年2月20日:添加 Gemini 3.1 Pro Preview、ByteDance Seed2.0 Pro、Baidu Ernie 5.0。
- 2026年2月17日:添加 Claude Sonnet 4.6、Qwen3.5-397B-A17B、MiniMax-M2.5。
- 2026年2月6日:添加 Claude Opus 4.6。
- 2026年2月2日:谜题总数达到940道。添加 Kimi K2.5 Thinking、Qwen3 Max (2026-01-23)、MiniMax-M2.1、DeepSeek V3.2。
- 2025年12月17日:添加 Gemini 3 Flash Preview。
- 2025年12月12日:添加 GPT 5.2 xhigh、GPT 5.2 Pro。
- 2025年12月11日:添加 GPT 5.2。
- 2025年12月2日:添加 Mistral Large 3。
- 2025年11月24日:添加 Claude Opus 4.5。
- 2025年11月21日:添加 Grok 4.1 Fast。
- 2025年11月18日:添加 Gemini 3 Pro Preview、GPT 5.1。
- 2025年11月12日:添加 Kimi K2 Thinking。
- 2025年10月15日:添加 Claude Haiku 4.5。
- 2025年10月14日:添加 Claude Sonnet 4.5、Deepseek V3.2 Exp、GLM-4.6。
- 2025年9月19日:添加 Grok 4 Fast、Qwen 3 Next 80B A3B Thinking、LongCat Flash Chat。
- 2025年9月6日:添加 Kimi K2-0905。
- 2025年9月5日:添加 Qwen 3 Max Preview、Qwen 3 235B A22B 25-07 Instruct。
- 2025年8月23日:添加 GPT-5 high reasoning 和 Cohere Command A Reasoning (16K)。
- 2025年8月22日:添加 DeepSeek 3.1、Qwen 3 30B A3B 25-07、Mistral Medium 3.1、GPT-5 minimal and low reasoning。
- 2025年8月7日:添加 GPT-5。
- 2025年8月5日:添加 Claude Opus 4.1、GPT-OSS-120B。
- 2025年7月28日:添加 GLM-4.5、Qwen 3 235B A22B 25-07 Thinking。
- 2025年7月14日:新增108道谜题。添加 Kimi K2。
- 2025年7月10日:添加 Grok 4。
- 2025年7月3日:添加 Qwen 3 32B、GLM4-32B-0414。
- 2025年7月2日:添加 Baidu Ernie 4.5 300B A47B、MiniMax-M1、Mistral Small 3.2。
- 2025年6月10日:添加 o3-pro。
- 2025年6月5日:添加 Gemini 2.5 Pro Preview 06-05。
- 2025年5月28日:添加 DeepSeek R1 05/28。
- 2025年5月22日:添加 Claude 4 系列模型。
- 2025年5月7日:添加 Gemini 2.5 Pro Preview 05-06。添加 Mistral Medium 3。
- 2025年4月30日:添加 Qwen 3。
- 2025年4月18日:添加 o3、o4-mini、Gemini 2.5 Flash Preview。
- 2025年4月15日:添加 GPT-4.1。
- 2025年4月10日:添加 Grok 3。
- 2025年4月5日:添加 Llama 4 Maverick、Llama 4 Scout。
- 2025年3月28日:添加 GPT-4o March 2025。
- 2025年3月25日:新增50道问题。添加 Gemini 2.5 Pro Exp 03-25 和 DeepSeek V3-0324。
- 2025年3月23日:添加“人类 vs. LLMs”部分。
- 2025年3月21日:添加 o1-pro。添加 o3-mini-high。
- 2025年3月17日:添加 Cohere Command A 和 Mistral Small 3.1。
- 2025年3月12日:添加 Gemma 3 27B。
- 2025年3月7日:添加 Qwen QwQ。
- 2025年2月27日:添加 GPT-4.5 Preview。
- 2025年2月24日:添加 Claude 3.7 Sonnet Thinking、Claude 3.7 Sonnet、GPT-4o Feb 2025、Qwen 2.5 Max、GPT-4o 2024-11-20。
- 2025年2月6日:添加 Gemini 2.0 Pro Exp 02-05。
- 2025年2月4日:推出带有额外词汇的更具挑战性的新版本。为最新的100道问题单独计分。相关性热力图。
- 2025年1月31日:添加 o3-mini (72.4)。
- 2025年1月30日:添加 Mistral Small 3 (10.5)。
- 2025年1月29日:添加 DeepSeek R1 (54.5)。
- 2025年1月28日:添加 Qwen 2.5 Max (18.6)。
- 2025年1月22日:添加 Phi-4 (11.6)、Nova Pro (12.5)、Gemini 2.0 Flash Thinking Exp 01-21 (37.0)。
- 2025年1月16日:添加 Gemini 2.0 Flash Thinking Exp、o1、MiniMax-Text-01。Gemini 2.0 Flash Thinking Exp 有时会达到输出 token 限制。
- 2024年12月27日:添加 GPT-4o 2024-11-20、Llama 3.3 70B、Gemini 2.0 Flash Exp、Deepseek-V3。Gemini 2.0 Flash Thinking Exp 因其输出在某些谜题上被截断而无法进行基准测试。
- 添加 Claude 3.5 Haiku。得分 13.7。
- 添加 Claude 3.5 Sonnet (2024-10-22)。得分从 25.9 提升至 24.4。
- 添加 Grok Beta。得分从 21.3 提升至 23.7。它被描述为“具有最先进推理能力的实验性语言模型,最适合复杂和多步骤用例。它是 Grok 2 的继承者,具有增强的上下文长度。”
- 在 X (Twitter) 上关注 [@lechmazur](https://x.com/LechMazur) 以获取其他即将推出的基准测试及更多信息。标签:Apex, NYT Connections, 人工智能, 大型语言模型, 干扰词, 性能分析, 成本分析, 扩展版本, 排行榜, 机器学习, 模型比较, 模型评估, 游戏AI, 用户模式Hook绕过, 训练数据影响, 评估工具, 语言模型测试, 谜题求解, 逆向工具