NVlabs/Sana
GitHub: NVlabs/Sana
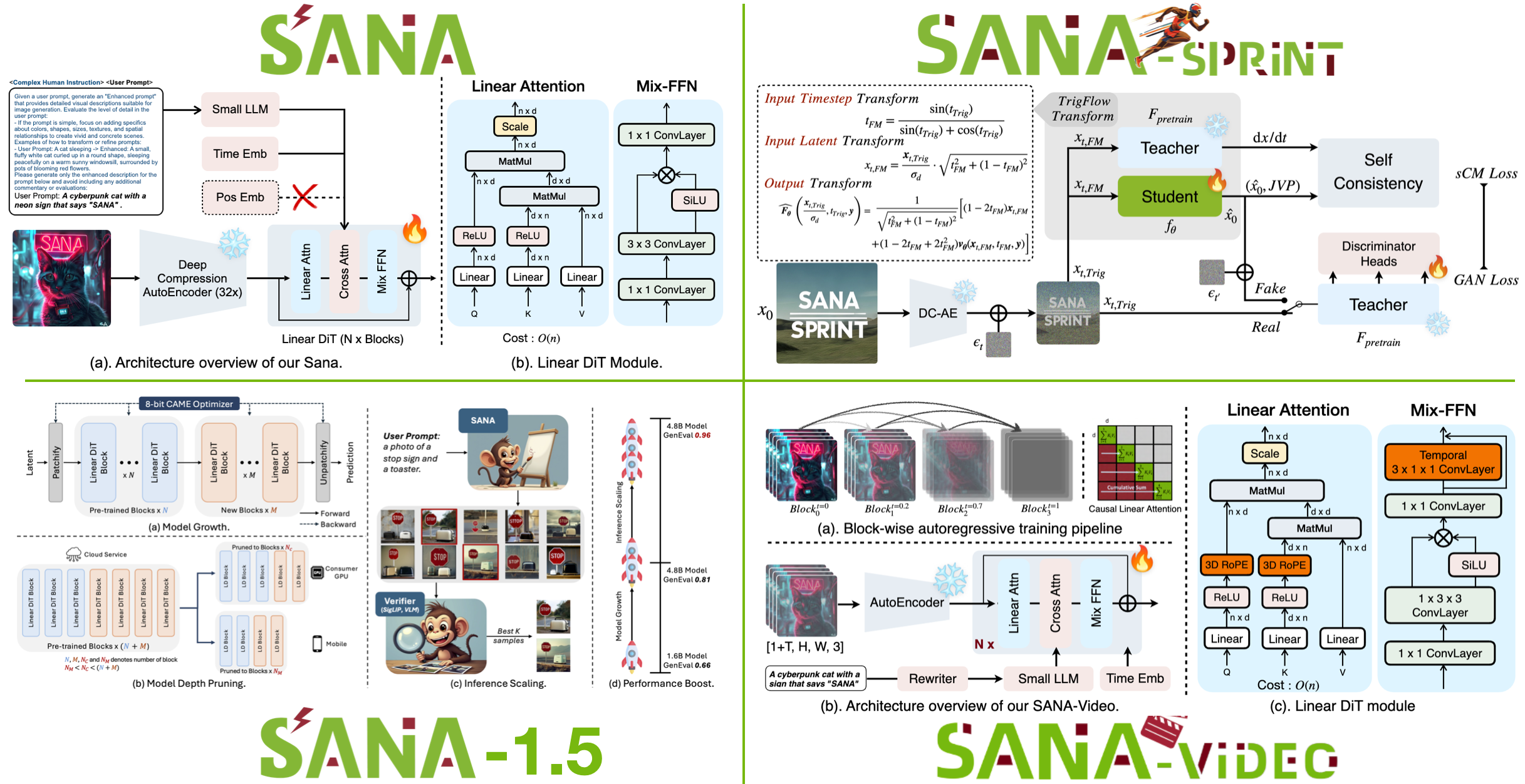
SANA是一个基于线性扩散Transformer的高效框架,用于解决高分辨率图像和视频生成中的计算效率和资源限制问题。
Stars: 8493 | Forks: 680

📚 文档 | SANA | SANA-1.5 | SANA-Sprint | SANA-Video | SANA-WM | Sol-RL 演示 | 🤗 HuggingFace | ComfyUI | SGLang | Cosmos-RL







ICLR 2025 口头报告 | ICML 2025 | ICCV 2025 亮点 | ICLR 2026 口头报告
**SANA** 是一个面向效率的高分辨率图像和视频生成代码库,提供完整的训练和推理流程。本仓库包含 [SANA](https://nvlabs.github.io/Sana/)、[SANA-1.5](https://nvlabs.github.io/Sana/Sana-1.5/)、[SANA-Sprint](https://nvlabs.github.io/Sana/Sprint/)、[SANA-Video](https://nvlabs.github.io/Sana/Video/)、[SANA-WM](https://nvlabs.github.io/Sana/WM/) 和 [Sol-RL](https://nvlabs.github.io/Sana/Sol-RL/) 的代码。更多详情可在我们的 [📚 文档](https://nvlabs.github.io/Sana/docs/) 中找到。 加入我们的 [Discord](https://discord.gg/rde6eaE5Ta) 与社区进行讨论!如有任何问题、遇到困难或有兴趣贡献,请随时联系我们!

点击展开所有更新
- ✅ [2025/8/20] 我们发布了新的 DC-AE-Lite,以实现更快的推理和更小的内存占用。 [[如何配置]](https://github.com/NVlabs/Sana/blob/main/configs/sana_sprint_config/1024ms/SanaSprint_1600M_1024px_allqknorm_bf16_scm_ladd_dc_ae_lite.yaml#L52) | [[diffusers PR]](https://github.com/huggingface/diffusers/pull/12169) | [[权重]](https://huggingface.co/mit-han-lab/dc-ae-lite-f32c32-sana-1.1-diffusers) - ✅ [2025/6/25] [SANA-Sprint](https://nvlabs.github.io/Sana/Sprint/) 被 ICCV'25 接收 🏖️ - ✅ [2025/6/4] SANA-Sprint [ComfyUI 节点](https://github.com/lawrence-cj/ComfyUI_ExtraModels) 发布 [[示例]](docs/ComfyUI/SANA-Sprint.json)。 - ✅ [2025/5/8] SANA-Sprint(单步扩散)diffusers 训练代码发布 [[指南]](https://github.com/huggingface/diffusers/blob/main/examples/research_projects/sana/README.md)。 - ✅ [2025/5/4] **SANA-1.5(推理时计算缩放)被 ICML-2025 接收。** 🎉🎉🎉 - ✅ [2025/3/22] 🔥**SANA-Sprint 演示托管在 Huggingface 上,快来试试吧!** 🎉 [[演示链接]](https://huggingface.co/spaces/Efficient-Large-Model/SanaSprint) - ✅ [2025/3/22] 🔥**SANA-1.5 已在 ComfyUI 中获得支持!** 🎉: [ComfyUI 指南](https://nvlabs.github.io/Sana/docs/ComfyUI/comfyui/) | [ComfyUI 工作流 SANA-1.5 4.8B](https://nvlabs.github.io/Sana/docs/ComfyUI/SANA-1.5_FlowEuler.json) - ✅ [2025/3/22] 🔥**SANA-Sprint 代码与权重发布!** 🎉 包括:[训练与推理](https://nvlabs.github.io/Sana/docs/sana_sprint/) 代码和 [权重](https://nvlabs.github.io/Sana/docs/model_zoo/#sana-sprint) / [HF](https://huggingface.co/collections/Efficient-Large-Model/sana-sprint) 均已发布。[[指南]](https://nvlabs.github.io/Sana/docs/sana_sprint/) - ✅ [2025/3/21] 🚀Sana + **推理缩放** 发布。[[指南]](https://nvlabs.github.io/Sana/docs/inference_scaling/) - ✅ [2025/3/16] 🔥**SANA-1.5 代码与权重发布!** 🎉 包括:[DDP/FSDP](https://nvlabs.github.io/Sana/docs/sana/#training) | [TAR 文件 WebDataset](https://nvlabs.github.io/Sana/docs/sana/#multi-scale-webdataset) | [多尺度](https://nvlabs.github.io/Sana/docs/sana/#training-with-fsdp) 训练代码和 [权重](https://nvlabs.github.io/Sana/docs/model_zoo/#sana-15) | [HF](https://huggingface.co/collections/Efficient-Large-Model/sana-15) 均已发布。 - ✅ [2025/3/14] 🏃**SANA-Sprint 来啦!** 🎉 Sana 的新单步/少步生成器。在 H100 上每 1024px 图像 0.1 秒,在 RTX 4090 上 0.3 秒。了解更多详情:[[页面]](https://nvlabs.github.io/Sana/Sprint/) | [[Arxiv]](https://arxiv.org/abs/2503.09641)。代码将随 `diffusers` 很快发布 - ✅ [2025/2/10] 🚀Sana + ControlNet 发布。[[指南]](https://nvlabs.github.io/Sana/docs/sana_controlnet/) | [[模型]](https://nvlabs.github.io/Sana/docs/model_zoo/#sana) | [[演示]](https://nv-sana.mit.edu/ctrlnet/) - ✅ [2025/1/30] 发布 CAME-8bit 优化器代码。训练期间节省更多 GPU 内存。[[如何配置]](https://github.com/NVlabs/Sana/blob/main/configs/sana_config/1024ms/Sana_1600M_img1024_CAME8bit.yaml#L86) - ✅ [2025/1/29] 🎉 🎉 🎉**SANA 1.5 发布!探索如何进行高效的训练与推理缩放!** 🚀[[技术报告]](https://arxiv.org/abs/2501.18427) - ✅ [2025/1/24] 4bit-Sana 发布,由 [SVDQuant 和 Nunchaku](https://github.com/mit-han-lab/nunchaku) 推理引擎驱动。现在可以在 **8GB** GPU 显存内运行您的 Sana。[[指南]](https://nvlabs.github.io/Sana/docs/4bit_sana/) [[演示]](https://svdquant.mit.edu/) [[模型]](https://nvlabs.github.io/Sana/docs/model_zoo/#sana) - ✅ [2025/1/24] DCAE-1.1 发布,重建质量更好。[[模型]](https://huggingface.co/mit-han-lab/dc-ae-f32c32-sana-1.1) [[diffusers]](https://huggingface.co/mit-han-lab/dc-ae-f32c32-sana-1.1-diffusers) - ✅ [2025/1/23] **Sana 被 ICLR-2025 接收为口头报告。** 🎉🎉🎉 - ✅ [2025/1/12] DC-AE 分块使 Sana-4K 在 22GB GPU 显存内推理 4096x4096px 图像。配合模型卸载和 8bit/4bit 量化。4K Sana 可在 **8GB** GPU 显存内运行。[[指南]](https://nvlabs.github.io/Sana/docs/model_zoo/#3-2k-4k-models) - ✅ [2025/1/11] Sana 代码库许可证变更为 Apache 2.0。 - ✅ [2025/1/10] 使用 8bit 量化推理 Sana。[[指南]](https://nvlabs.github.io/Sana/docs/8bit_sana/#quantization) - ✅ [2025/1/8] 4K 分辨率 [Sana 模型](https://nvlabs.github.io/Sana/docs/model_zoo/#sana) 在 [Sana-ComfyUI](https://github.com/lawrence-cj/ComfyUI_ExtraModels) 中获得支持,[工作流](https://nvlabs.github.io/Sana/docs/ComfyUI/Sana_FlowEuler_4K.json) 也已准备好。[[4K 指南]](https://nvlabs.github.io/Sana/docs/ComfyUI/comfyui/#a-sample-workflow-for-sana-4096x4096-image-18gb-gpu-is-needed) - ✅ [2025/1/8] 1.6B 4K 分辨率 [Sana 模型](https://nvlabs.github.io/Sana/docs/model_zoo/#sana) 发布:[[BF16 pth]](https://huggingface.co/Efficient-Large-Model/Sana_1600M_4Kpx_BF16) 或 [[BF16 diffusers]](https://huggingface.co/Efficient-Large-Model/Sana_1600M_4Kpx_BF16_diffusers)。🚀 在 20 秒内获取您的 4096x4096 分辨率图像!在 [Sana 页面](https://nvlabs.github.io/Sana/) 查找更多示例。感谢 [SUPIR](https://github.com/Fanghua-Yu/SUPIR) 的出色工作和支持。 - ✅ [2025/1/2] `diffusers` 管道中的错误已解决。[已解决的 PR](https://github.com/huggingface/diffusers/pull/10431) - ✅ [2025/1/2] 2K 分辨率 [Sana 模型](asset/docs/model_zoo.md) 在 [Sana-ComfyUI](https://github.com/lawrence-cj/ComfyUI_ExtraModels) 中获得支持,[工作流](asset/docs/ComfyUI/Sana_FlowEuler_2K.json) 也已准备好。 - ✅ [2024/12] 1.6B 2K 分辨率 [Sana 模型](asset/docs/model_zoo.md) 发布:[[BF16 pth]](https://huggingface.co/Efficient-Large-Model/Sana_1600M_2Kpx_BF16) 或 [[BF16 diffusers]](https://huggingface.co/Efficient-Large-Model/Sana_1600M_2Kpx_BF16_diffusers)。🚀 在 4 秒内获取您的 2K 分辨率图像!在 [Sana 页面](https://nvlabs.github.io/Sana/) 查找更多示例。感谢 [SUPIR](https://github.com/Fanghua-Yu/SUPIR) 的出色工作和支持。 - ✅ [2024/12] `diffusers` 支持 Sana-LoRA 微调!Sana-LoRA 的训练和收敛速度非常快。[[指南]](https://nvlabs.github.io/Sana/docs/sana_lora_dreambooth/) 或 [[diffusers 文档]](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/README_sana.md)。 - ✅ [2024/12] `diffusers` 已包含 Sana 已发布,diffusers 管道 `SanaPipeline`、`SanaPAGPipeline`、`DPMSolverMultistepScheduler(带 FlowMatching)` 现均已支持。我们为您准备了 [模型卡](https://nvlabs.github.io/Sana/docs/model_zoo/#sana) 供选择。 - ✅ [2024/12] 1.6B BF16 [Sana 模型](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_BF16) 发布,用于稳定微调。 - ✅ [2024/12] 我们发布了 Sana 的 [ComfyUI 节点](https://github.com/lawrence-cj/ComfyUI_ExtraModels)。[[指南]](https://nvlabs.github.io/Sana/docs/ComfyUI/comfyui/) - ✅ [2024/11] 所有多语言(表情符号和中文和英文)SFT 模型已发布:[1.6B-512px](https://huggingface.co/Efficient-Large-Model/Sana_1600M_512px_MultiLing)、[1.6B-1024px](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_MultiLing)、[600M-512px](https://huggingface.co/Efficient-Large-Model/Sana_600M_512px)、[600M-1024px](https://huggingface.co/Efficient-Large-Model/Sana_600M_1024px)。指标性能见[此处](#performance)。 - ✅ [2024/11] Sana Replicate API 在 [Sana-API](https://replicate.com/chenxwh/sana) 上线。 - ✅ [2024/11] 1.6B [Sana 模型](https://huggingface.co/collections/Efficient-Large-Model/sana) 发布。 - ✅ [2024/11] 训练、推理和评估代码发布。 - ✅ [2024/11] 正在集成 [`diffusers`](https://github.com/huggingface/diffusers/pull/9982)。 - [2024/10] [演示](https://nv-sana.mit.edu/) 发布。 - [2024/10] [DC-AE 代码](https://github.com/mit-han-lab/efficientvit/blob/master/applications/dc_ae/README.md) 和 [权重](https://huggingface.co/collections/mit-han-lab/dc-ae) 发布! - [2024/10] [论文](https://arxiv.org/abs/2410.10629) 在 Arxiv 上发布!

点击展开所有 BibTeX 引用
``` @misc{xie2025sana, title={SANA 1.5: Efficient Scaling of Training-Time and Inference-Time Compute in Linear Diffusion Transformer}, author={Xie, Enze and Chen, Junsong and Zhao, Yuyang rectangle and Yu, Jincheng and Zhu, Ligeng and Lin, Yujun and Zhang, Zhekai and Li, Muyang and Chen, Junyu and Cai, Han and others}, year={2025}, eprint={2501.18427}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2501.18427}, } @misc{chen2025sanasprint, title={SANA-Sprint: One-Step Diffusion with Continuous-Time Consistency Distillation}, author={Junsong Chen and Shuchen Xue and Yuyang Zhao and Jincheng Yu graves and Sayak Paul and Junyu Chen and Han Cai and Song Han and Enze Xie}, year={2025}, eprint={2503.09641}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2503.09641}, } @misc{chen2025sanavideo, title={SANA-Video: Efficient Video Generation with Block Linear Diffusion Transformer}, author={Chen, Junsong and Zhao, Yuyang and Yu, Jincheng and Chu, Ruihang and Chen, Junyu and Yang, Shuai and Wang, Xianbang and Pan, Yicheng and Zhou, Daquan and Ling, Huan and others}, year={2025}, eprint={2509.24695}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2509.24695}, } @misc{li2026fp4, title={FP4 Explore, BF16 Train: Diffusion Reinforcement Learning via Efficient Rollout Scaling}, author={Li, Yitong and Chen, Junsong and Xue, Shuchen and Zeren, Pengcuo and Fu, Siyuan and Yang, Dinghao and Tang, Yangyang and Bai, Junjie and Luo, Ping and Han, Song and others}, year={2026} eprint={2604.06916}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2604.06916}, } @misc{zhu2026sanawm, title={SANA-WM: Efficient Minute-Scale World Modeling with Hybrid Linear Diffusion Transformer}, author={Haoyi Zhu and Haozhe Liu and Yuyang Zhao and Tian Ye and Junsong Chen and Jincheng Yu and Tong He and Song Han and Enze Xie}, year={2026}, eprint={2605.15178}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2605.15178}, } ```标签:Apex, ControlNet, Transformer架构, Vectored Exception Handling, 人工智能, 凭据扫描, 图像合成, 图像处理, 强化学习, 扩散模型, 机器学习, 水印技术, 深度学习, 生成式AI, 用户模式Hook绕过, 索引, 线性扩散Transformer, 视频生成, 计算机视觉, 逆向工具, 量化推理, 高分辨率图像生成, 高效AI, 高效计算