rishikanthc/Scriberr
GitHub: rishikanthc/Scriberr
一款开源自托管的离线 AI 音频转录应用,提供说话人识别、LLM 对话集成和自动化 API 支持。
Stars: 2770 | Forks: 214
Scriberr is an open-source, and completely offline audio transcription application designed for self-hosters who value privacy and performance.
网站 •
文档 •
API 参考

## 简介
Scriberr 的核心功能是允许你在本地机器上转录音频和视频,确保没有任何数据被发送到第三方云服务商。
它利用业界领先的机器学习模型(例如 **NVIDIA Parakeet** 和 **Canary**)或更早且流行的 **Whisper** 模型,提供具有词级时间戳的高精度文本。
Scriberr 远不止简单的转录,还提供了各种高级功能。
它将强大的底层 AI 与流畅精美的用户界面相结合,让管理录音变得轻松自如。无论你是整理语音备忘录还是分析冗长的会议,Scriberr 都提供了一个绝佳的工作环境:
- **智能说话人检测**:Scriberr 自动检测不同的说话人(Diarization/说话人分离),并精确标记谁说了什么。
- **与你的音频对话**:无缝连接 Ollama 或兼容 OpenAI API 的服务商。你可以直接在应用内生成摘要、提出问题,或与你的转录文本进行完整对话。
- **为你的工作流而生**:凭借丰富的 API 和能自动处理文件夹中新文件的 Folder Watcher 功能,Scriberr 可以完美融入你现有的自动化流程(如 n8n)。
- **捕捉与整理**:使用内置的录音机随时随地捕捉想法,并利用集成的笔记功能在收听时为转录内容添加注释。
- **无处不在的原生体验**:Scriberr 支持 PWA(渐进式 Web 应用)安装,让你在桌面或移动设备上都能获得原生应用般的体验。
- **精致的 UI**:我专注于那些让应用响应灵敏且令人愉悦的 UI 细节。
[查看完整功能列表 →](https://scriberr.app/docs/features)
### 为什么开发这个工具
Scriberr 的灵感源于对隐私的担忧以及不想支付订阅费用的想法。
大约一年前,我购买了一台 [Plaud Note](https://www.plaud.ai/) 用于录制语音备忘录。我很喜欢这个设备本身;它的外形设计、麦克风质量和工作流程都非常出色。
然而,转录是在他们的云服务器上完成的。作为一个对隐私非常敏感的人,我不愿意将我的录音上传给第三方服务商。
此外,我还面临订阅费用的问题:每年 100 美元每月可转录 20 小时,或者每年 240 美元享受无限使用。作为一个热衷于自托管并拥有 ML 和 AI 背景的人,为一个我深知自己能搞定的服务支付如此高昂的费用感觉很不值得。
我决定开发 Scriberr 来填补这一空白,为所有人创建一个强大、私密且免费的替代方案。
## 截图
点击展开
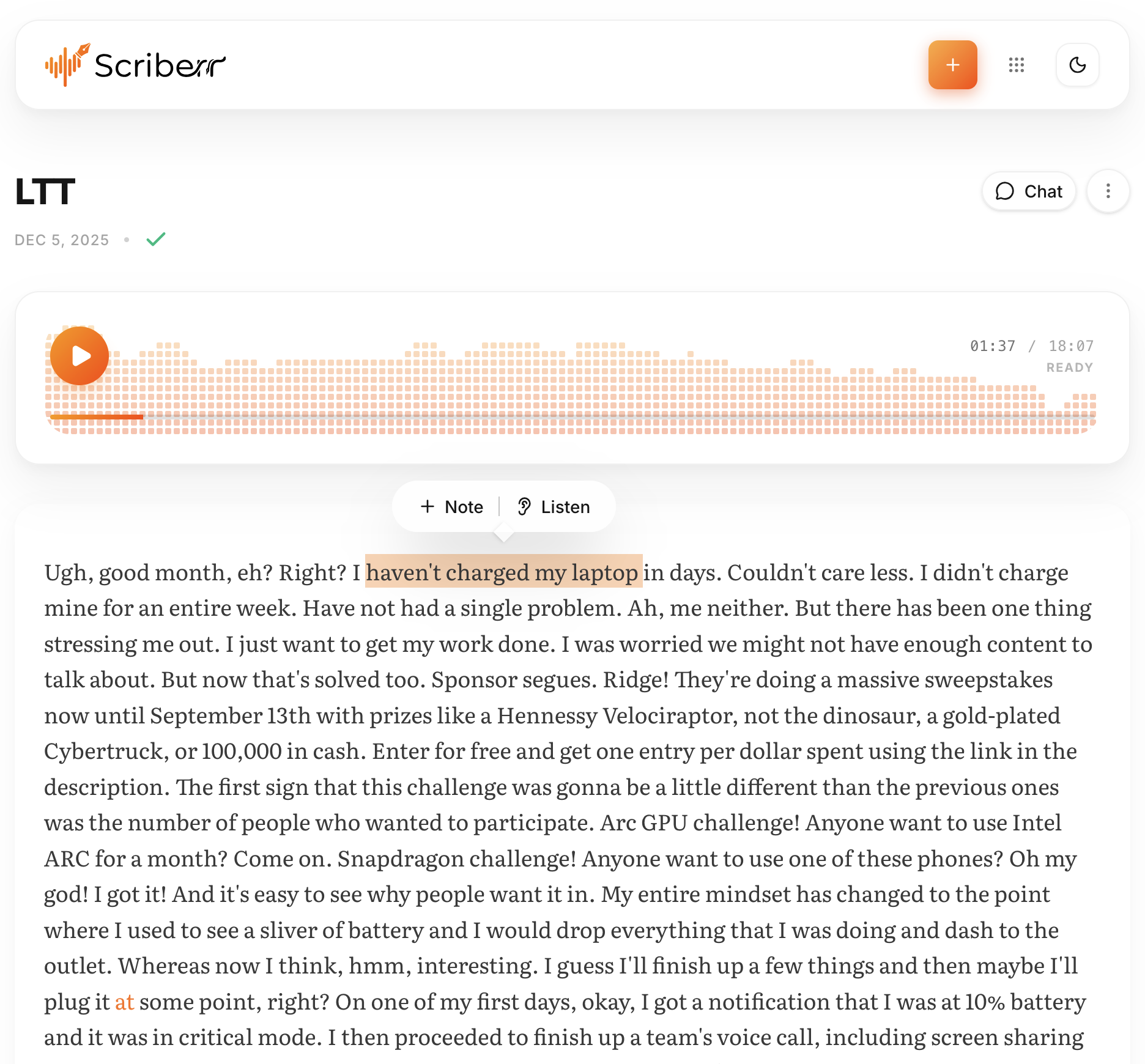
Transcript reader with playback follow‑along and seek‑from‑text.
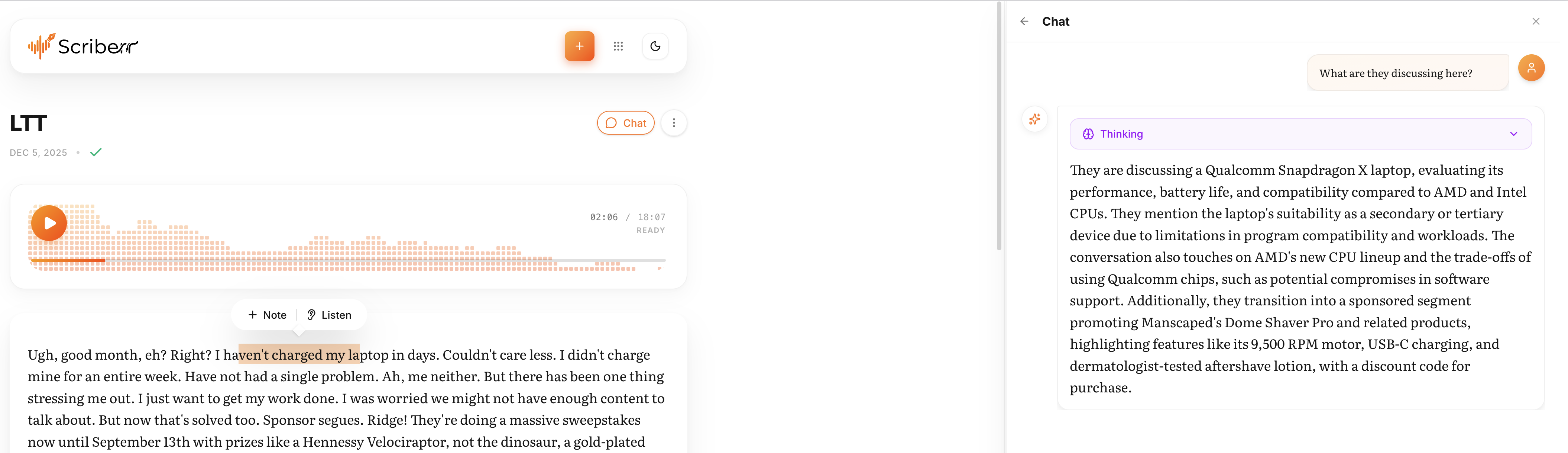
Chat with your transcripts using local LLMs or OpenAI.
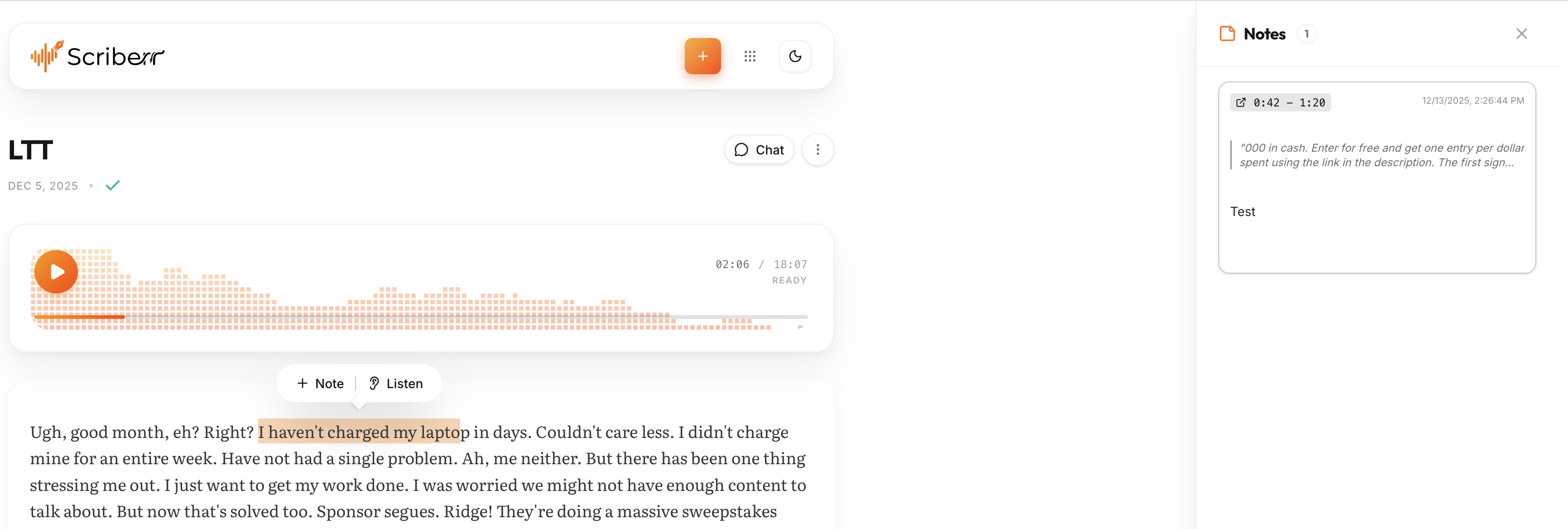
Highlight key moments and take notes while listening.
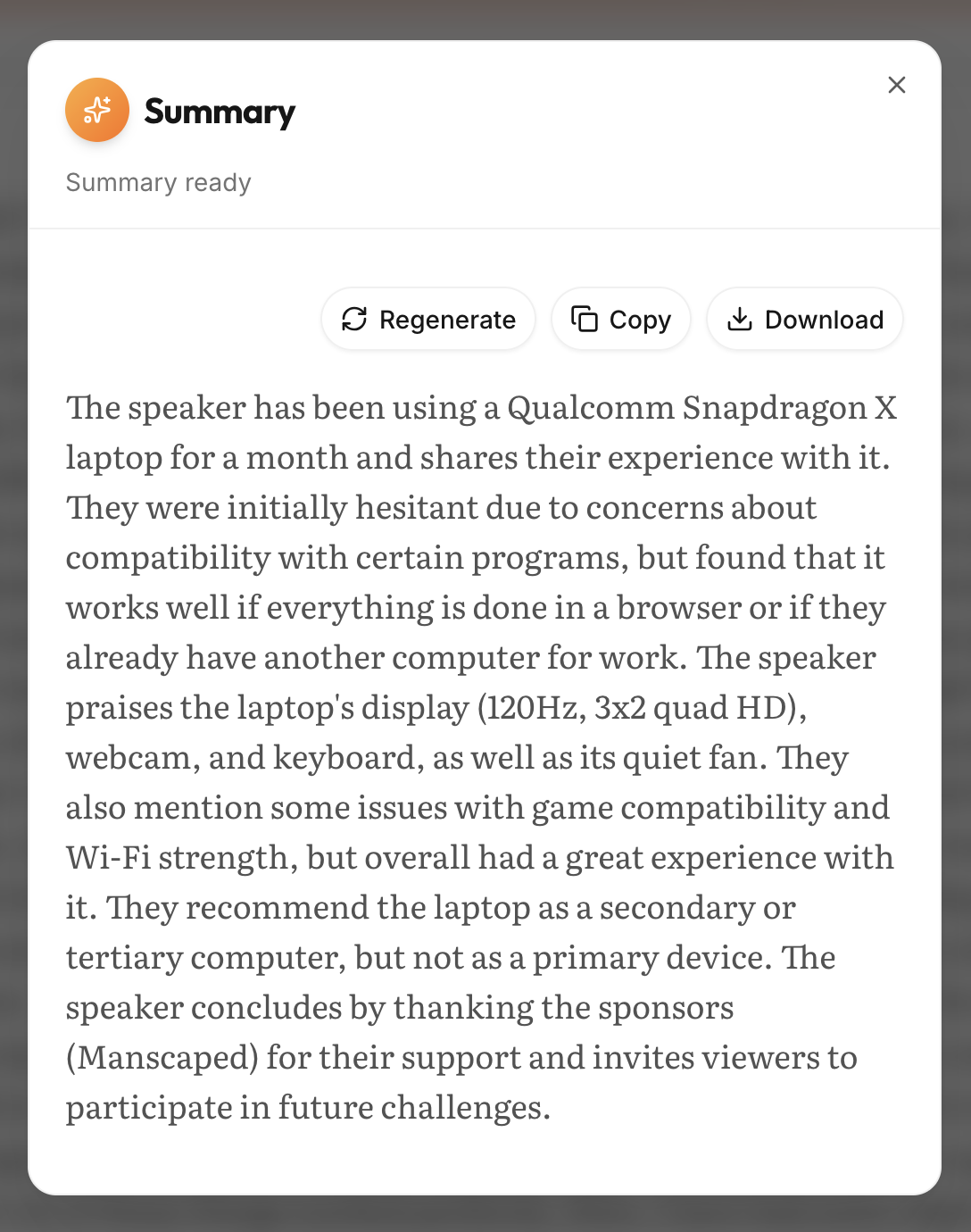
Generate comprehensive summaries of your recordings.
深色模式
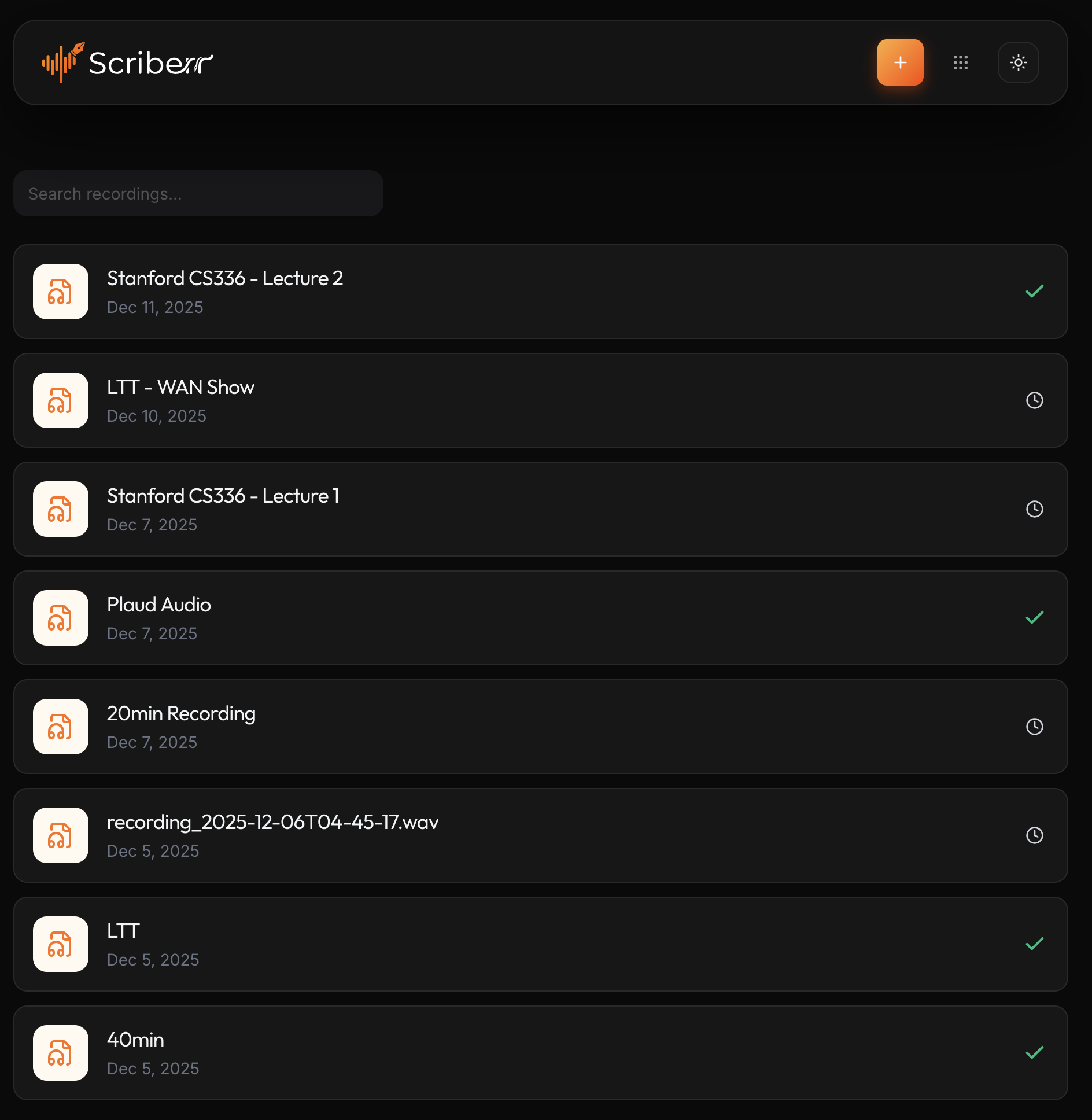
Homepage in Dark Mode.
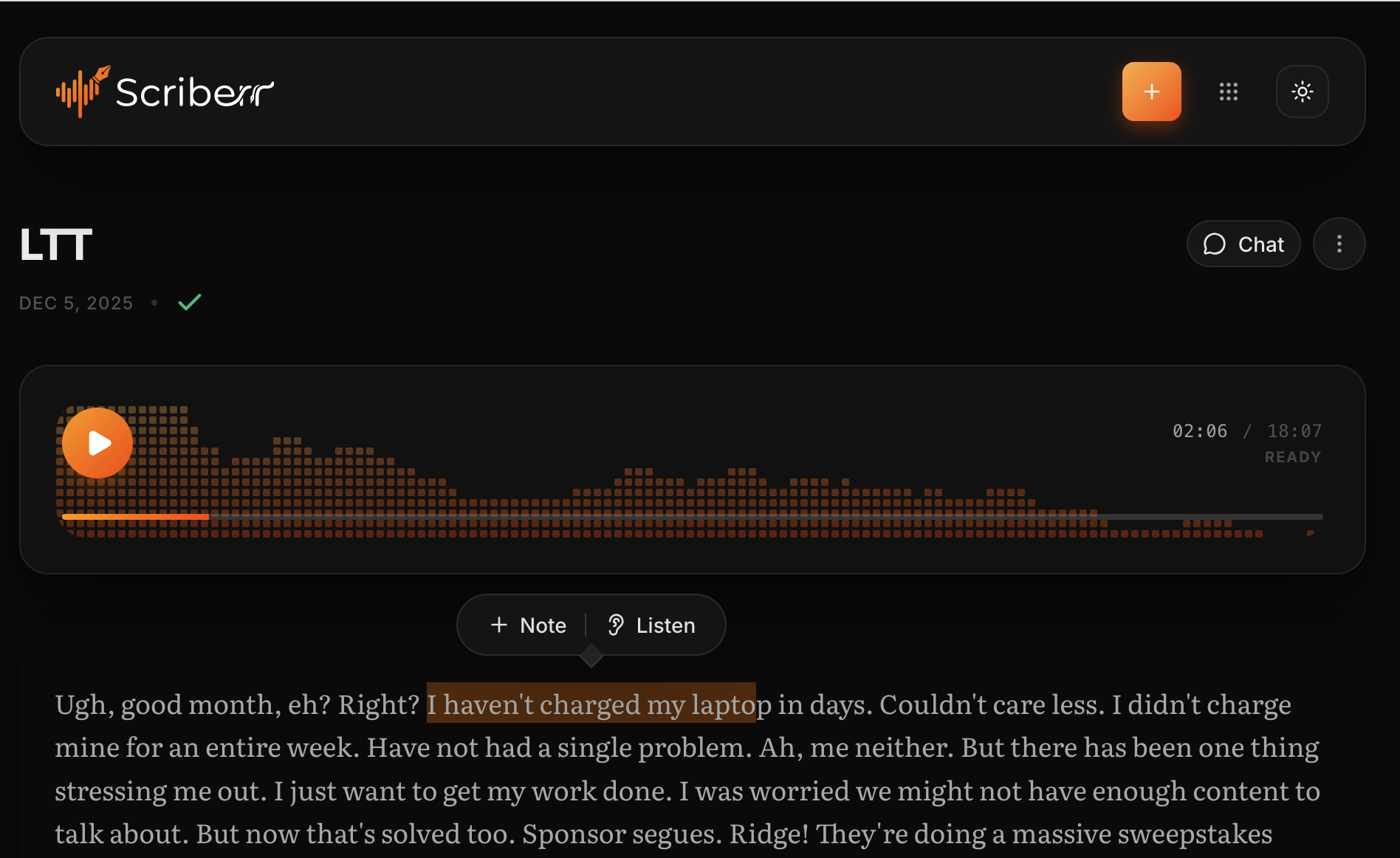
Transcript view in Dark Mode.
### 移动端
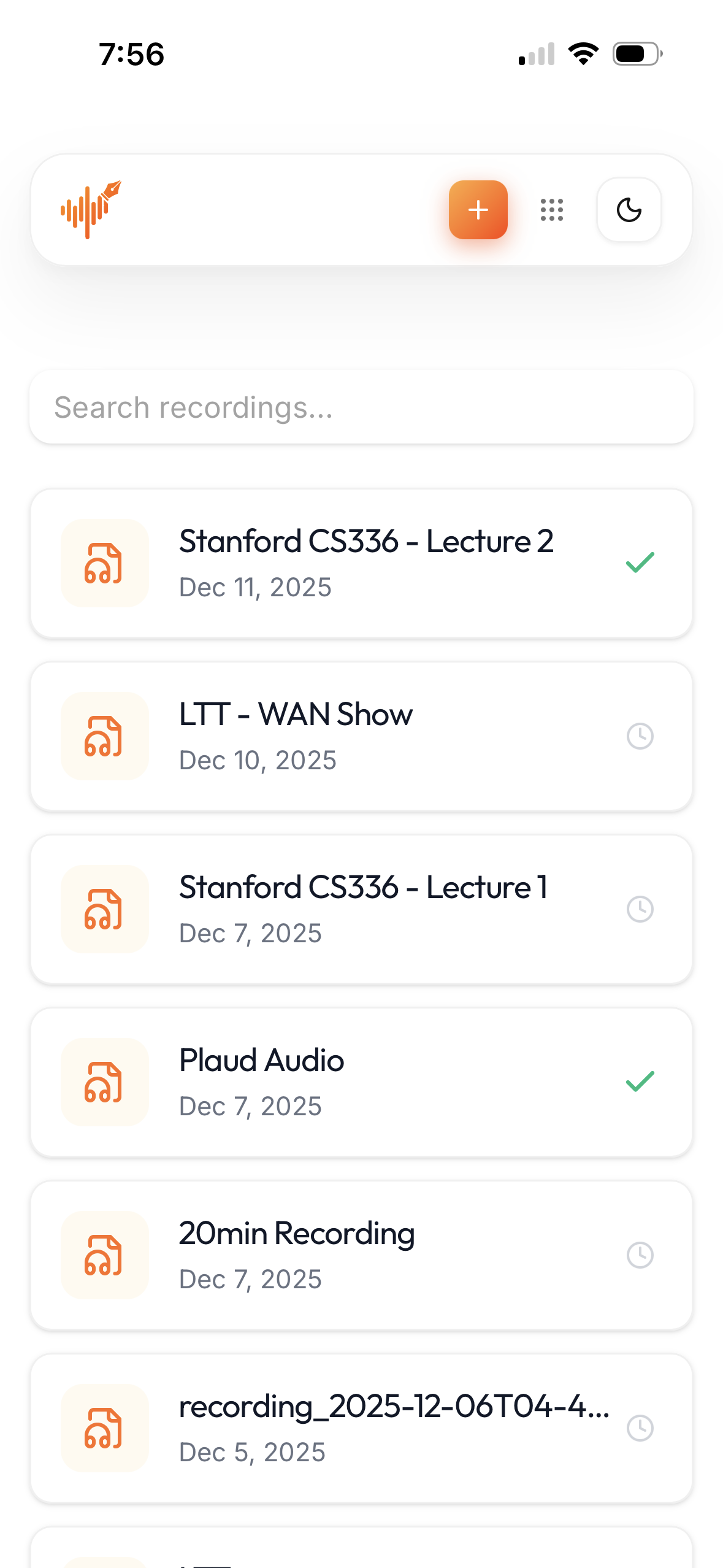
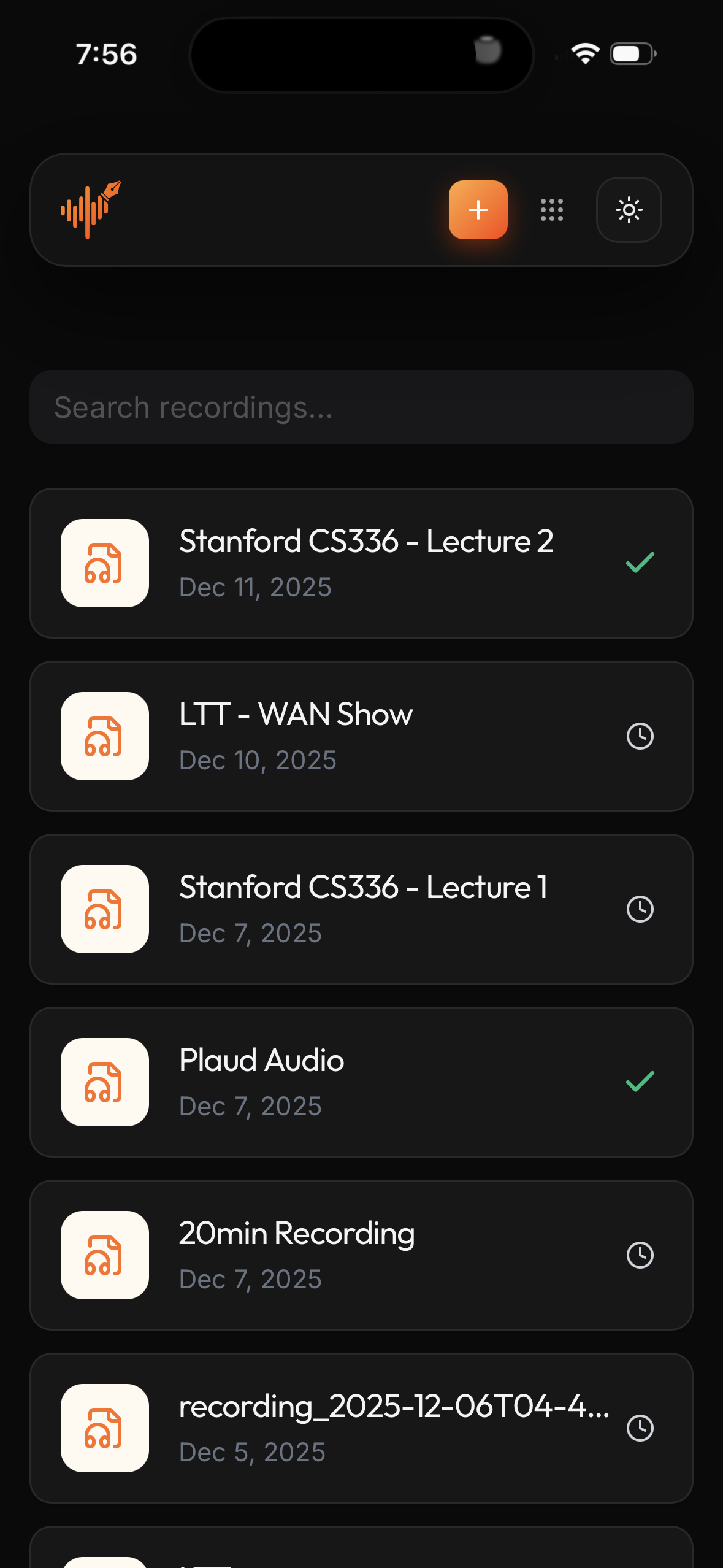
PWA mobile app (Light & Dark).
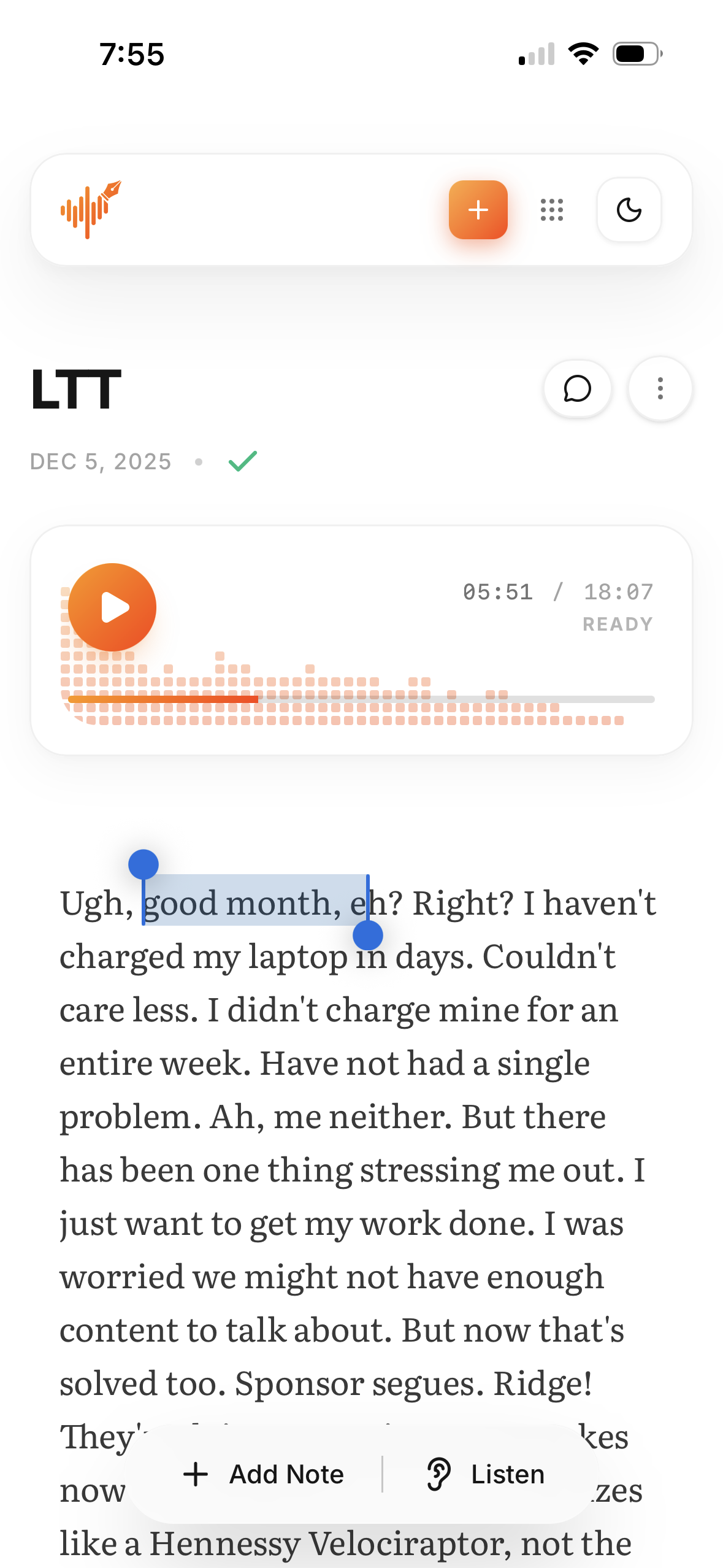
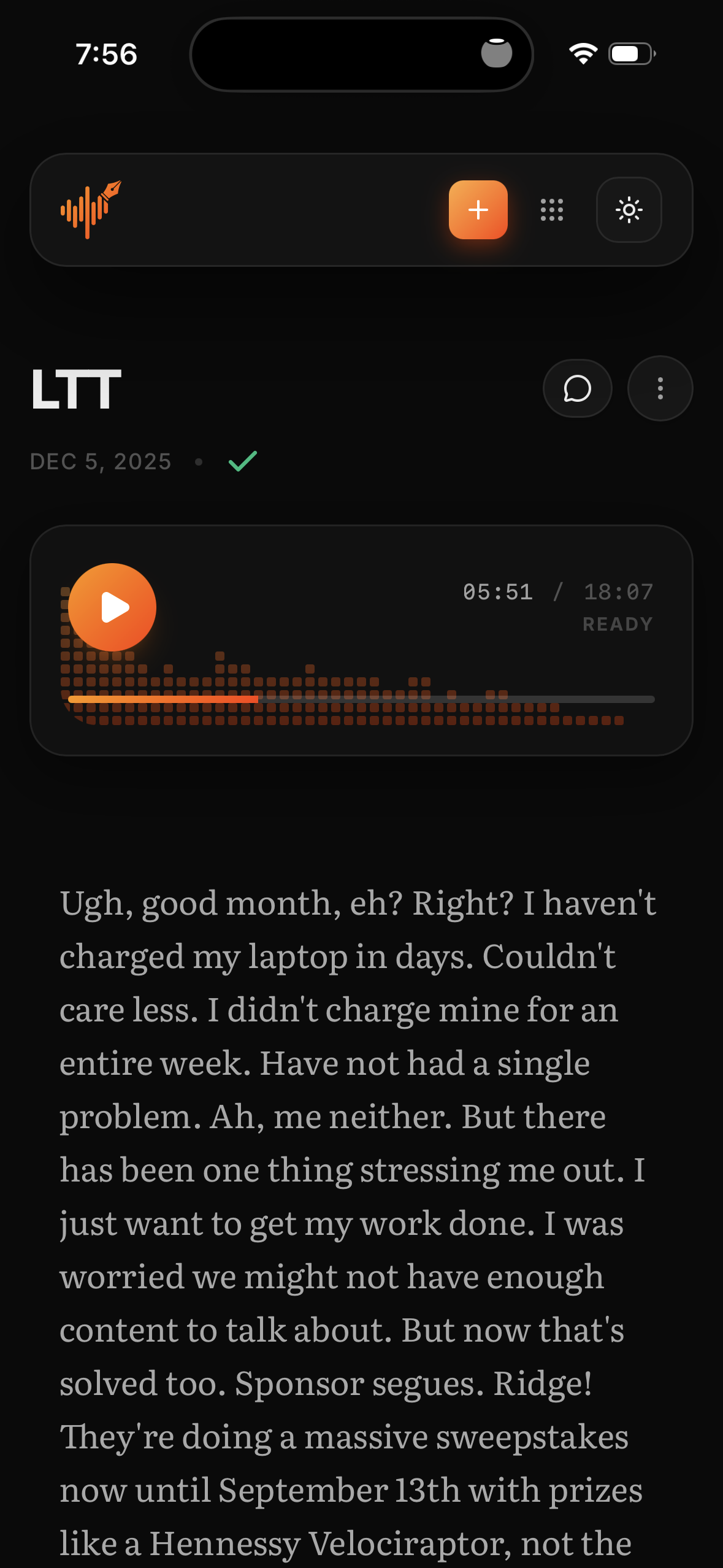
Mobile transcript reading experience.
## 安装
只需几分钟,即可在你的系统上运行 Scriberr。
### 从 v1.1.0 迁移
如果你是从 v1.1.0 升级,请按照以下步骤操作以确保平滑过渡。版本 1.2.0 将应用数据(数据库、上传文件)与模型数据(Python 环境)进行了分离。
#### 1. 更新卷挂载
你需要更新 Docker 卷配置以拆分你的数据:
* **应用数据**:将你现有的数据文件夹(包含 `scriberr.db`、`jwt_secret`、`transcripts/` 和 `uploads/`)绑定到 `/app/data`。
* **模型环境**:创建一个**新的空文件夹**并将其绑定到 `/app/whisperx-env`。
#### 2. 清理旧环境
Python 环境和模型需要为 v1.2.0 重新初始化。如果应用程序检测到旧环境,它可能会尝试使用它,从而导致兼容性错误。从一个全新的 `/app/whisperx-env` 卷开始,可以确保安装正确的依赖项。
### 使用 Homebrew 安装
安装 Scriberr 最简单的方法是使用 Homebrew。如果你还没有安装 Homebrew,请[先在这里获取](https://brew.sh/)。
```
# 添加 Scriberr tap
brew tap rishikanthc/scriberr
# 安装 Scriberr(自动安装 UV 依赖)
brew install scriberr
# 启动服务器
scriberr
```
在浏览器中打开 [http://localhost:8080](http://localhost:8080)。
### 配置
Scriberr 开箱即用。不过,对于 Homebrew 或手动安装,你可以使用环境变量或放置在与二进制文件相同目录(或你运行命令的目录)下的 `.env` 文件来自定义应用程序行为。
#### 环境变量
| 变量 | 描述 | 默认值 |
| :--- | :--- | :--- |
| `PORT` | 服务器监听的端口。 | `8080` |
| `HOST` | 要绑定的网络接口。 | `0.0.0.0` |
| `APP_ENV` | 应用环境(`development` 或 `production`)。 | `development` |
| `ALLOWED_ORIGINS` | CORS 允许的来源(逗号分隔)。 | `http://localhost:5173,http://localhost:8080` |
| `DATABASE_PATH` | SQLite 数据库文件的路径。 | `data/scriberr.db` |
| `UPLOAD_DIR` | 存储上传文件的目录。 | `data/uploads` |
| `TRANSCRIPTS_DIR` | 存储转录文本的目录。 | `data/transcripts` |
| `WHISPERX_ENV` | 用于模型的托管 Python 环境路径。 | `data/whisperx-env` |
| `OPENAI_API_KEY` | OpenAI 的 API Key(可选)。 | `""` |
| `JWT_SECRET` | 用于签名 JWT 的密钥。如果未设置则自动生成。 | 自动生成 |
**示例 `.env` 文件:**
```
# 服务器设置
HOST=localhost
PORT=8080
APP_ENV=production
# 路径
DATABASE_PATH=/var/lib/scriberr/data/scriberr.db
UPLOAD_DIR=/var/lib/scriberr/data/uploads
# 安全
JWT_SECRET=your-super-secret-key-change-this
```
### Docker 部署
对于容器化部署,你可以使用 Docker。我们提供两种配置:一种用于标准 CPU 使用,另一种针对 NVIDIA GPU (CUDA) 进行了优化。
#### 标准部署 (CPU)
如果你没有任何专用 NVIDIA GPU 的机器,请使用此配置运行 Scriberr。
1. 创建一个名为 `docker-compose.yml` 的文件:
```
services:
scriberr:
image: ghcr.io/rishikanthc/scriberr:v1.2.0
ports:
- "8080:8080"
volumes:
- scriberr_data:/app/data # volume for data
- env_data:/app/whisperx-env # volume for models and python envs
environment:
- PUID=${PUID:-1000}
- PGID=${PGID:-1000}
- APP_ENV=production # DO NOT CHANGE THIS
# CORS: comma-separated list of allowed origins for production
# - ALLOWED_ORIGINS=https://your-domain.com
# - SECURE_COOKIES=false # Uncomment this ONLY if you are not using SSL
restart: unless-stopped
volumes:
scriberr_data: {}
env_data: {}
```
2. 运行容器:
```
docker compose up -d
```
#### NVIDIA GPU 部署 (CUDA)
如果你有兼容的 NVIDIA GPU,此配置可启用硬件加速,从而显著加快转录速度。
1. 确保已安装 [NVIDIA Container Toolkit](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html)。
2. 创建一个名为 `docker-compose.cuda.yml` 的文件:
```
services:
scriberr:
image: ghcr.io/rishikanthc/scriberr-cuda:v1.2.0
ports:
- "8080:8080"
volumes:
- scriberr_data:/app/data # volume for data
- env_data:/app/whisperx-env # volume for models and python envs
restart: unless-stopped
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities:
- gpu
environment:
- NVIDIA_VISIBLE_DEVICES=all
- NVIDIA_DRIVER_CAPABILITIES=compute,utility
- PUID=${PUID:-1000}
- PGID=${PGID:-1000}
- APP_ENV=production # DO NOT CHANGE THIS
# CORS: comma-separated list of allowed origins for production
# - ALLOWED_ORIGINS=https://your-domain.com
# - SECURE_COOKIES=false # Uncomment this ONLY if you are not using SSL
volumes:
scriberr_data: {}
env_data: {}
```
3. 使用 CUDA 配置运行容器:
```
docker compose -f docker-compose.cuda.yml up -d
```
#### GPU 兼容性
由于 CUDA/PyTorch 兼容性要求,Scriberr 为不同的 NVIDIA GPU 代次提供了单独的 Docker 镜像:
| GPU 代次 | 计算能力 | Docker 镜像 | Docker Compose 文件 |
|:---|:---|:---|:---|
| GTX 10 系列 | sm_61 | `scriberr-cuda` | `docker-compose.cuda.yml` |
| RTX 20 系列 | sm_75 | `scriberr-cuda` | `docker-compose.cuda.yml` |
| RTX 30 系列 | sm_86 | `scriberr-cuda` | `docker-compose.cuda.yml` |
| RTX 40 系列 | sm_89 | `scriberr-cuda` | `docker-compose.cuda.yml` |
| **RTX 50 系列** | sm_120 | `scriberr-cuda-blackwell` | `docker-compose.blackwell.yml` |
**RTX 50 系列用户(RTX 5080、5090 等):** 你必须使用专用的 Blackwell 镜像。由于 PyTorch CUDA 兼容性要求,标准的 CUDA 镜像将无法工作。请使用:
```
docker compose -f docker-compose.blackwell.yml up -d
```
或者用于本地构建:
```
docker compose -f docker-compose.build.blackwell.yml up -d
```
### 应用启动
当你第一次运行 Scriberr 时,可能需要几分钟才能启动。这是正常的!
应用程序需要:
1. 初始化 Python 环境。
2. 下载必要的机器学习模型(Whisper、PyAnnote、NVIDIA NeMo)。
3. 配置数据库。
**后续运行将快得多**,因为所有模型和环境都保留在 `env_data` 卷(或你本地的映射文件夹)中。
当你看到这一行时,就说明应用程序已准备就绪:`msg="Scriberr is ready" url=http://0.0.0.0:8080`。
### 故障排除
#### 1. SQLite OOM 错误 (内存不足)
如果你看到来自 SQLite 的 "out of memory (14)" 错误(特别是 `SQLITE_CANTOPEN`),通常意味着权限问题。数据库引擎无法在数据目录中创建临时文件。
你可以通过在 `docker-compose.yml` 中设置 `PUID` 和 `PGID` 以匹配你主机用户的 UID 和 GID,或者手动更改主机上映射文件夹的所有权来解决这个问题:
```
# 如果您使用了命名卷(例如 'scriberr_scriberr_data'):
sudo chown -R 1000:1000 /var/lib/docker/volumes/scriberr_scriberr_data/_data
# 如果您映射了特定的主机文件夹(例如 ./scriberr_data):
sudo chown -R 1000:1000 ./scriberr_data
sudo chown -R 1000:1000 ./env_data
```
将 `1000` 替换为你为 `PUID`/`PGID` 设置的值(默认为 `1000`)。
#### 2. "无法加载音频流"
如果应用程序已加载,但你无法播放或看到音频波形(收到 "Unable to load audio stream"),这通常是由于 **Secure Cookies** 安全标志导致的。
默认情况下,当 `APP_ENV=production` 时,Scriberr 启用 `SECURE_COOKIES=true`。这可以防止通过不安全(HTTP)连接发送 Cookie。
**解决方案:**
- **推荐:** 将 Scriberr 部署在反向代理(如 Nginx、Caddy 或 Traefik)之后,并使用 SSL/TLS (HTTPS)。
- **替代方案:** 如果你必须通过纯 HTTP 访问,请在 `docker-compose.yml` 中设置以下环境变量:
environment:
- SECURE_COOKIES=false
## 安装后
一旦你启动并运行了 Scriberr:
- **配置 Diarization**:要启用说话人识别,请访问[配置页面](https://scriberr.app/docs/configuration)。
- **使用指南**:有关详细的使用指南,请访问 [https://scriberr.app/docs/usage](https://scriberr.app/docs/usage)。
## LLM 声明
本项目使用 AI 智能体作为结对程序员进行开发。这绝不是那种随心所欲的代码。顺便说一下,我是职业 ML/AI 研究员,拥有超过十年的编程经验。代码库遵循软件工程最佳实践和原则,所有架构决策均由我做出。所有由 LLM 生成的代码都经过了尽我所能的审查和测试。
## 捐赠
标签:AI转录, ASR, Diarization, EVTX分析, EVTX分析, EVTX分析, NVIDIA Parakeet, Ollama集成, Vectored Exception Handling, Whisper模型, 会议记录, 大语言模型对话, 媒体处理, 效率工具, 日志审计, 智能语音助手, 本地部署, 离线AI, 网络安全, 网络测绘, 自动语音识别, 自托管, 视频转文字, 语音识别, 语音转文字, 说话人分离, 请求拦截, 逆向工具, 隐私保护, 隐私计算, 音频转文本

