mostlygeek/llama-swap
GitHub: mostlygeek/llama-swap
Go语言构建的本地AI模型热切换代理,让你用单一API入口按需调用多个推理后端。
Stars: 4551 | Forks: 348




# llama-swap
在你的机器上运行多个生成式 AI 模型,并按需在它们之间热切换。llama-swap 适用于任何兼容 OpenAI 和 Anthropic API 的服务器,已被数千人用于支持其本地 AI 工作流。
llama-swap 使用 Go 语言构建,注重性能和简洁性,零依赖且设置极其简单。只需一个二进制文件和一个配置文件,即可在几分钟内开始使用。
## 功能:
- ✅ 易于部署和配置:一个二进制文件,一个配置文件,无外部依赖
- ✅ 按需切换模型
- ✅ 使用任何本地 OpenAI 兼容服务器 (llama.cpp, vllm, tabbyAPI, stable-diffusion.cpp 等)
- 面向未来,随时升级你的推理服务器。
- ✅ 支持的 OpenAI API 端点:
- `v1/completions`
- `v1/chat/completions`
- `v1/responses`
- `v1/embeddings`
- `v1/audio/speech` ([#36](https://github.com/mostlygeek/llama-swap/issues/36))
- `v1/audio/transcriptions` ([文档](https://github.com/mostlygeek/llama-swap/issues/41#issuecomment-2722637867))
- `v1/audio/voices`
- `v1/images/generations`
- `v1/images/edits`
- ✅ 支持的 Anthropic API 端点:
- `v1/messages`
- `v1/messages/count_tokens`
- ✅ llama-server (llama.cpp) 支持的端点
- `v1/rerank`, `v1/reranking`, `/rerank`
- `/infill` - 用于代码填充
- `/completion` - 用于补全端点
- ✅ llama-swap API
- `/ui` - Web UI
- `/upstream/:model_id` - 直接访问上游服务器 ([演示](https://github.com/mostlygeek/llama-swap/pull/31))
- `/models/unload` - 手动卸载正在运行的模型 ([#58](https://github.com/mostlygeek/llama-swap/issues/58))
- `/running` - 列出当前正在运行的模型 ([#61](https://github.com/mostlygeek/llama-swap/issues/61))
- `/log` - 远程日志监控
- `/health` - 仅返回 "OK"
- ✅ API Key 支持 - 定义密钥以限制对 API 端点的访问
- ✅ 可定制化
- 使用 `Groups` 同时运行多个模型 ([#107](https://github.com/mostlygeek/llama-swap/issues/107))
- 通过设置 `ttl` 在超时后自动卸载模型
- 结合使用 `cmd` 和 `cmdStop` 提供可靠的 Docker 和 Podman 支持
- 使用 `hooks` 在启动时预加载模型 ([#235](https://github.com/mostlygeek/llama-swap/pull/235))
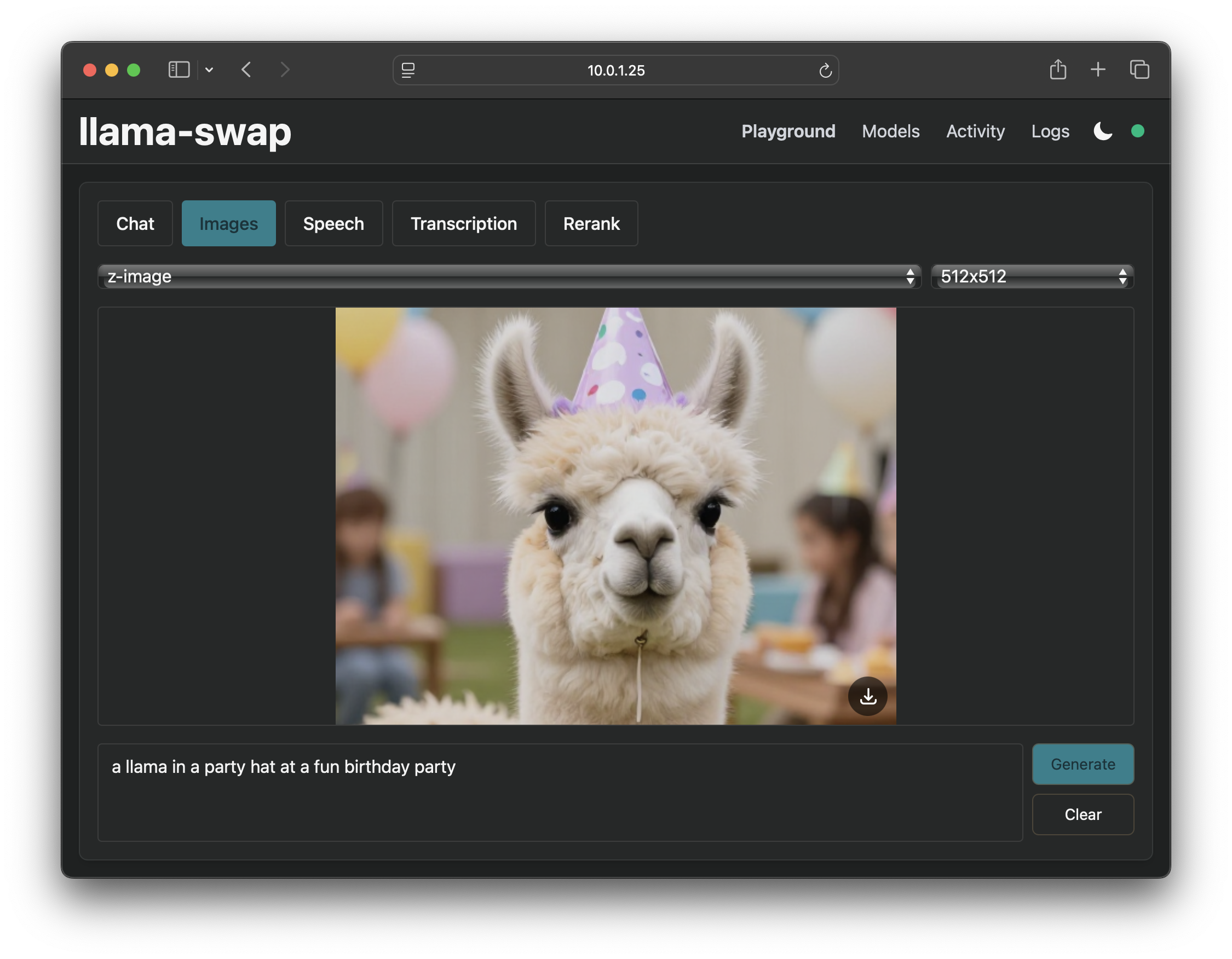
### Web UI
llama-swap 包含一个实时 Web 界面,带有一个 Playground,用于测试各种本地模型:
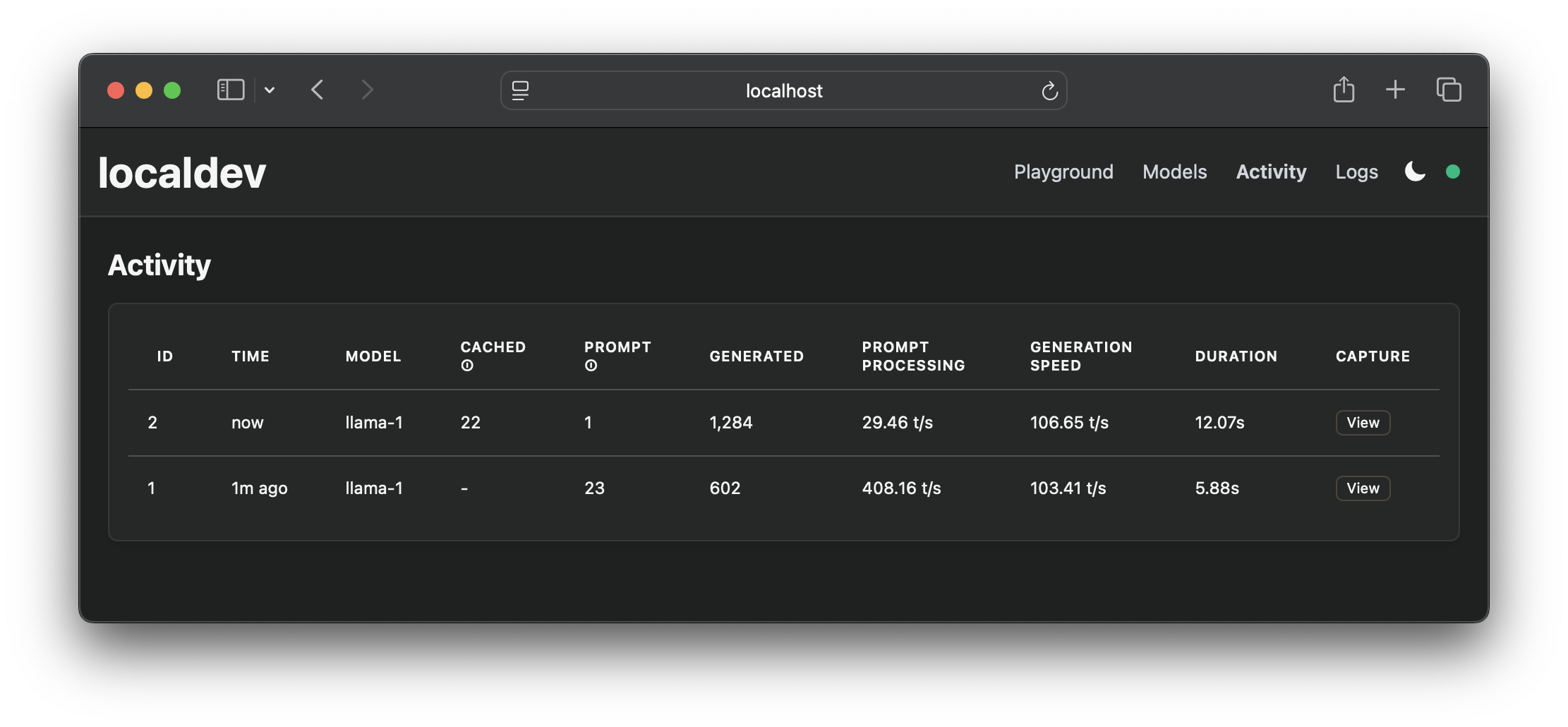
 查看详细的 token 指标:
查看详细的 token 指标:
 检查请求和响应:
检查请求和响应:
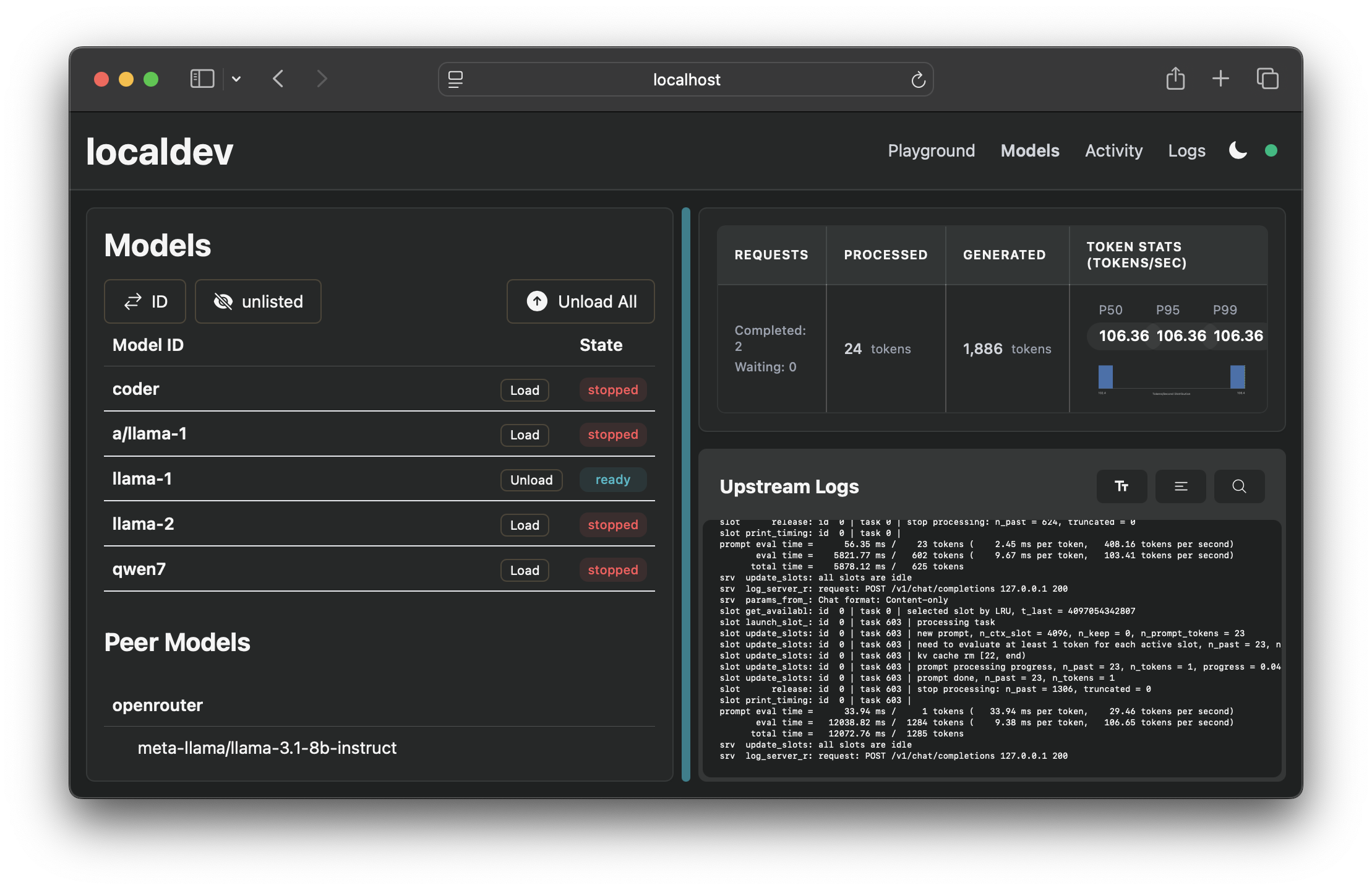
 手动加载和卸载模型:
手动加载和卸载模型:
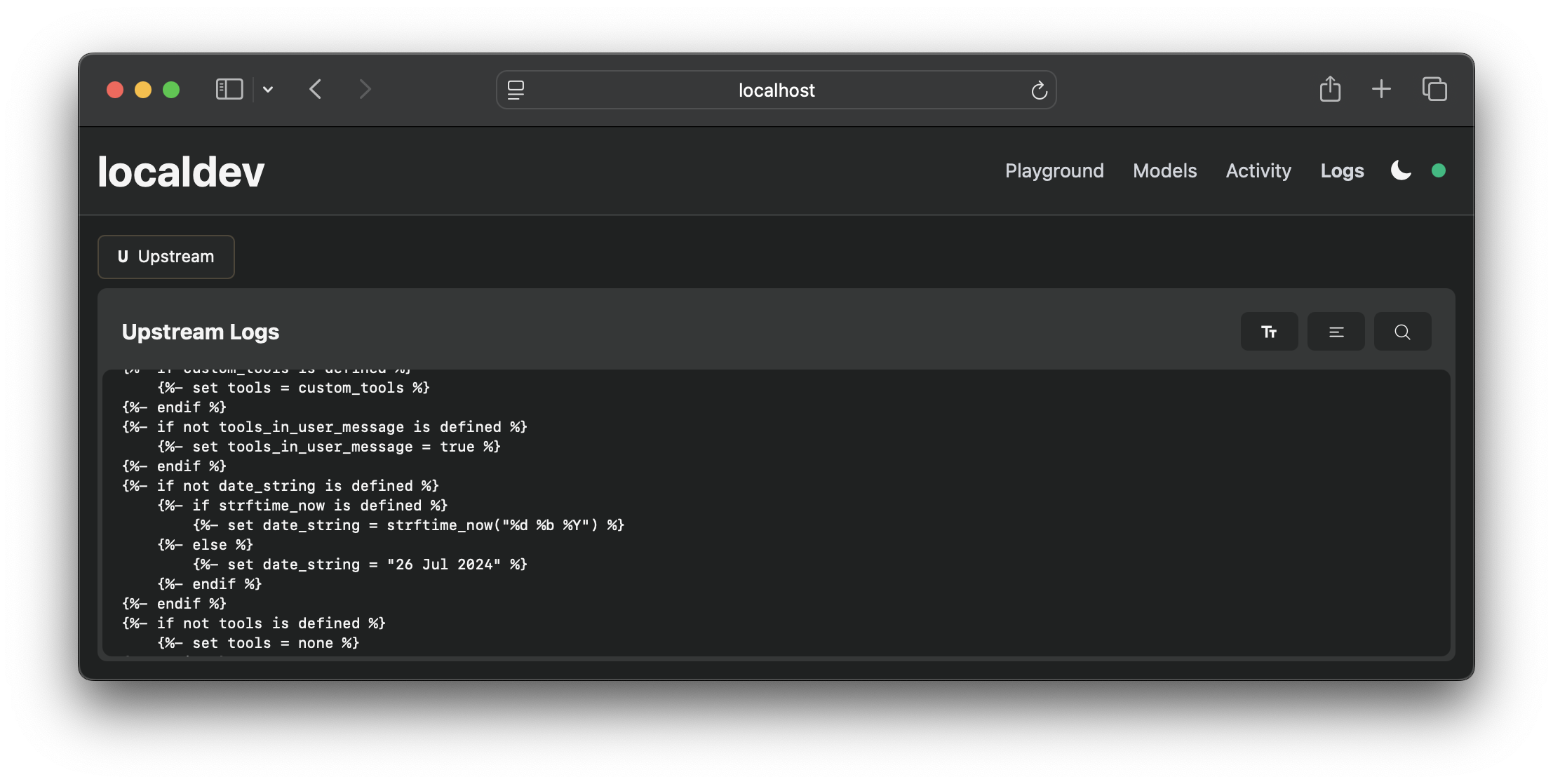
 实时日志流:
实时日志流:
 ## 安装
可以通过多种方式安装 llama-swap
1. Docker
2. Homebrew (OSX 和 Linux)
3. WinGet
4. 从发布版二进制文件
5. 从源代码
### Docker 安装 ([下载镜像](https://github.com/mostlygeek/llama-swap/pkgs/container/llama-swap))
每晚构建的包含 llama-swap 和 llama-server 的容器镜像支持多种平台 (cuda, vulkan, intel 等),包括[安全性更高的非 root 变体](docs/container-security.md)。
stable-diffusion.cpp 服务器也包含在 musa 和 vulkan 平台中。
```
$ docker pull ghcr.io/mostlygeek/llama-swap:cuda
# run with a custom configuration and models directory
$ docker run -it --rm --runtime nvidia -p 9292:8080 \
-v /path/to/models:/models \
-v /path/to/custom/config.yaml:/app/config.yaml \
ghcr.io/mostlygeek/llama-swap:cuda
# configuration hot reload supported with a
# directory volume mount
$ docker run -it --rm --runtime nvidia -p 9292:8080 \
-v /path/to/models:/models \
-v /path/to/custom/config.yaml:/app/config.yaml \
-v /path/to/config:/config \
ghcr.io/mostlygeek/llama-swap:cuda -config /config/config.yaml -watch-config
```
### Homebrew 安装 (macOS/Linux)
```
brew tap mostlygeek/llama-swap
brew install llama-swap
llama-swap --config path/to/config.yaml --listen localhost:8080
```
### WinGet 安装 (Windows)
```
# install
C:\> winget install llama-swap
# upgrade
C:\> winget upgrade llama-swap
```
### 预构建二进制文件
Linux, Mac, Windows 和 FreeBSD 的二进制文件可在 [发布](https://github.com/mostlygeek/llama-swap/releases) 页面找到。
### 从源代码构建
1. 构建需要 Go 和 Node.js (用于 UI)。
2. `git clone https://github.com/mostlygeek/llama-swap.git`
3. `make clean all`
4. 在 `build/` 子目录中查找 llama-swap 二进制文件
## 配置
```
# minimum viable config.yaml
models:
model1:
cmd: llama-server --port ${PORT} --model /path/to/model.gguf
```
这就是开始使用所需的全部:
1. `models` - 保存所有模型配置
2. `model1` - API 调用中使用的 ID
3. `cmd` - 用于启动服务器的命令。
4. `${PORT}` - 自动分配的端口号
几乎所有配置设置都是可选的,可以一步步添加:
- 高级功能
- `groups` 用于同时运行多个模型
- `hooks` 用于在启动时运行任务
- `macros` 可复用的代码片段
- 模型定制
- `ttl` 用于自动卸载模型
- `aliases` 用于使用熟悉的模型名称 (例如 "gpt-4o-mini")
- `env` 用于将自定义环境变量传递给推理服务器
- `cmdStop` 优雅地停止 Docker/Podman 容器
- `useModelName` 覆盖发送到上游服务器的模型名称
- `${PORT}` 用于动态端口分配的自动端口变量
- `filters` 在发送到上游服务器之前重写请求的某些部分
查看 [配置文档](docs/configuration.md) 了解所有选项。
## llama-swap 是如何工作的?
当向 OpenAI 兼容端点发出请求时,llama-swap 会提取 `model` 值并加载适当的服务器配置来为其服务。如果运行的上游服务器不正确,它将被替换为正确的服务器。这就是“swap”(交换)部分的由来。上游服务器会自动交换以正确处理请求。
在最基本的配置中,llama-swap 一次处理一个模型。对于更高级的用例,`groups` 功能允许同时加载多个模型。你可以完全控制如何使用系统资源。
## 反向代理配置
如果你将 llama-swap 部署在 nginx 后面,请禁用流式传输端点的响应缓冲。默认情况下,nginx 会缓冲响应,这会破坏 Server-Sent Events (SSE) 和流式聊天补全。([#236](https://github.com/mostlygeek/llama-swap/issues/236))
推荐的 nginx 配置片段:
```
# SSE for UI events/logs
location /api/events {
proxy_pass http://your-llama-swap-backend;
proxy_buffering off;
proxy_cache off;
}
# Streaming chat completions (stream=true)
location /v1/chat/completions {
proxy_pass http://your-llama-swap-backend;
proxy_buffering off;
proxy_cache off;
}
```
作为一种保障措施,llama-swap 还会在 SSE 响应上设置 `X-Accel-Buffering: no`。但是,仍然建议在你的反向代理上显式禁用 `proxy_buffering`,以确保可靠的流式传输行为。
## 在 CLI 上监控日志
```
# sends up to the last 10KB of logs
$ curl http://host/logs
# streams combined logs
curl -Ns http://host/logs/stream
# stream llama-swap's proxy status logs
curl -Ns http://host/logs/stream/proxy
# stream logs from upstream processes that llama-swap loads
curl -Ns http://host/logs/stream/upstream
# stream logs only from a specific model
curl -Ns http://host/logs/stream/{model_id}
# stream and filter logs with linux pipes
curl -Ns http://host/logs/stream | grep 'eval time'
# appending ?no-history will disable sending buffered history first
curl -Ns 'http://host/logs/stream?no-history'
```
## 我需要使用 llama.cpp 的服务器 吗?
任何 OpenAI 兼容的服务器都可以。llama-swap 最初是为 llama-server 设计的,因此它是支持最好的。
对于像 vllm 或 tabbyAPI 这样基于 Python 的推理服务器,建议通过 podman 或 docker 运行它们。这提供了干净的环境隔离,并能正确响应 `SIGTERM` 信号以进行适当关闭。
## Star 历史
[](https://www.star-history.com/#mostlygeek/llama-swap&Date)
## 安装
可以通过多种方式安装 llama-swap
1. Docker
2. Homebrew (OSX 和 Linux)
3. WinGet
4. 从发布版二进制文件
5. 从源代码
### Docker 安装 ([下载镜像](https://github.com/mostlygeek/llama-swap/pkgs/container/llama-swap))
每晚构建的包含 llama-swap 和 llama-server 的容器镜像支持多种平台 (cuda, vulkan, intel 等),包括[安全性更高的非 root 变体](docs/container-security.md)。
stable-diffusion.cpp 服务器也包含在 musa 和 vulkan 平台中。
```
$ docker pull ghcr.io/mostlygeek/llama-swap:cuda
# run with a custom configuration and models directory
$ docker run -it --rm --runtime nvidia -p 9292:8080 \
-v /path/to/models:/models \
-v /path/to/custom/config.yaml:/app/config.yaml \
ghcr.io/mostlygeek/llama-swap:cuda
# configuration hot reload supported with a
# directory volume mount
$ docker run -it --rm --runtime nvidia -p 9292:8080 \
-v /path/to/models:/models \
-v /path/to/custom/config.yaml:/app/config.yaml \
-v /path/to/config:/config \
ghcr.io/mostlygeek/llama-swap:cuda -config /config/config.yaml -watch-config
```
### Homebrew 安装 (macOS/Linux)
```
brew tap mostlygeek/llama-swap
brew install llama-swap
llama-swap --config path/to/config.yaml --listen localhost:8080
```
### WinGet 安装 (Windows)
```
# install
C:\> winget install llama-swap
# upgrade
C:\> winget upgrade llama-swap
```
### 预构建二进制文件
Linux, Mac, Windows 和 FreeBSD 的二进制文件可在 [发布](https://github.com/mostlygeek/llama-swap/releases) 页面找到。
### 从源代码构建
1. 构建需要 Go 和 Node.js (用于 UI)。
2. `git clone https://github.com/mostlygeek/llama-swap.git`
3. `make clean all`
4. 在 `build/` 子目录中查找 llama-swap 二进制文件
## 配置
```
# minimum viable config.yaml
models:
model1:
cmd: llama-server --port ${PORT} --model /path/to/model.gguf
```
这就是开始使用所需的全部:
1. `models` - 保存所有模型配置
2. `model1` - API 调用中使用的 ID
3. `cmd` - 用于启动服务器的命令。
4. `${PORT}` - 自动分配的端口号
几乎所有配置设置都是可选的,可以一步步添加:
- 高级功能
- `groups` 用于同时运行多个模型
- `hooks` 用于在启动时运行任务
- `macros` 可复用的代码片段
- 模型定制
- `ttl` 用于自动卸载模型
- `aliases` 用于使用熟悉的模型名称 (例如 "gpt-4o-mini")
- `env` 用于将自定义环境变量传递给推理服务器
- `cmdStop` 优雅地停止 Docker/Podman 容器
- `useModelName` 覆盖发送到上游服务器的模型名称
- `${PORT}` 用于动态端口分配的自动端口变量
- `filters` 在发送到上游服务器之前重写请求的某些部分
查看 [配置文档](docs/configuration.md) 了解所有选项。
## llama-swap 是如何工作的?
当向 OpenAI 兼容端点发出请求时,llama-swap 会提取 `model` 值并加载适当的服务器配置来为其服务。如果运行的上游服务器不正确,它将被替换为正确的服务器。这就是“swap”(交换)部分的由来。上游服务器会自动交换以正确处理请求。
在最基本的配置中,llama-swap 一次处理一个模型。对于更高级的用例,`groups` 功能允许同时加载多个模型。你可以完全控制如何使用系统资源。
## 反向代理配置
如果你将 llama-swap 部署在 nginx 后面,请禁用流式传输端点的响应缓冲。默认情况下,nginx 会缓冲响应,这会破坏 Server-Sent Events (SSE) 和流式聊天补全。([#236](https://github.com/mostlygeek/llama-swap/issues/236))
推荐的 nginx 配置片段:
```
# SSE for UI events/logs
location /api/events {
proxy_pass http://your-llama-swap-backend;
proxy_buffering off;
proxy_cache off;
}
# Streaming chat completions (stream=true)
location /v1/chat/completions {
proxy_pass http://your-llama-swap-backend;
proxy_buffering off;
proxy_cache off;
}
```
作为一种保障措施,llama-swap 还会在 SSE 响应上设置 `X-Accel-Buffering: no`。但是,仍然建议在你的反向代理上显式禁用 `proxy_buffering`,以确保可靠的流式传输行为。
## 在 CLI 上监控日志
```
# sends up to the last 10KB of logs
$ curl http://host/logs
# streams combined logs
curl -Ns http://host/logs/stream
# stream llama-swap's proxy status logs
curl -Ns http://host/logs/stream/proxy
# stream logs from upstream processes that llama-swap loads
curl -Ns http://host/logs/stream/upstream
# stream logs only from a specific model
curl -Ns http://host/logs/stream/{model_id}
# stream and filter logs with linux pipes
curl -Ns http://host/logs/stream | grep 'eval time'
# appending ?no-history will disable sending buffered history first
curl -Ns 'http://host/logs/stream?no-history'
```
## 我需要使用 llama.cpp 的服务器 吗?
任何 OpenAI 兼容的服务器都可以。llama-swap 最初是为 llama-server 设计的,因此它是支持最好的。
对于像 vllm 或 tabbyAPI 这样基于 Python 的推理服务器,建议通过 podman 或 docker 运行它们。这提供了干净的环境隔离,并能正确响应 `SIGTERM` 信号以进行适当关闭。
## Star 历史
[](https://www.star-history.com/#mostlygeek/llama-swap&Date)
查看详细的 token 指标:
检查请求和响应:
实时日志流:
## 安装
可以通过多种方式安装 llama-swap
1. Docker
2. Homebrew (OSX 和 Linux)
3. WinGet
4. 从发布版二进制文件
5. 从源代码
### Docker 安装 ([下载镜像](https://github.com/mostlygeek/llama-swap/pkgs/container/llama-swap))
每晚构建的包含 llama-swap 和 llama-server 的容器镜像支持多种平台 (cuda, vulkan, intel 等),包括[安全性更高的非 root 变体](docs/container-security.md)。
stable-diffusion.cpp 服务器也包含在 musa 和 vulkan 平台中。
```
$ docker pull ghcr.io/mostlygeek/llama-swap:cuda
# run with a custom configuration and models directory
$ docker run -it --rm --runtime nvidia -p 9292:8080 \
-v /path/to/models:/models \
-v /path/to/custom/config.yaml:/app/config.yaml \
ghcr.io/mostlygeek/llama-swap:cuda
# configuration hot reload supported with a
# directory volume mount
$ docker run -it --rm --runtime nvidia -p 9292:8080 \
-v /path/to/models:/models \
-v /path/to/custom/config.yaml:/app/config.yaml \
-v /path/to/config:/config \
ghcr.io/mostlygeek/llama-swap:cuda -config /config/config.yaml -watch-config
```
更多示例
``` # pull latest images per platform docker pull ghcr.io/mostlygeek/llama-swap:cpu docker pull ghcr.io/mostlygeek/llama-swap:cuda docker pull ghcr.io/mostlygeek/llama-swap:vulkan docker pull ghcr.io/mostlygeek/llama-swap:intel docker pull ghcr.io/mostlygeek/llama-swap:musa # tagged llama-swap, platform and llama-server version images docker pull ghcr.io/mostlygeek/llama-swap:v166-cuda-b6795 # non-root cuda docker pull ghcr.io/mostlygeek/llama-swap:cuda-non-root ```标签:AI 网关, Anthropic API, DLL 劫持, Embedding 向量化, EVTX分析, EVTX分析, Go 语言, GPU 资源管理, llama.cpp, LLM, MITM代理, OpenAI API 兼容, Unmanaged PE, vllm, 反向代理, 大语言模型, 推理服务器, 文生图, 日志审计, 本地推理, 模型服务, 模型热切换, 模型管理, 生成式 AI, 私有化部署, 请求拦截, 防御规避, 零依赖, 音频转写