icereed/paperless-gpt
GitHub: icereed/paperless-gpt
基于大语言模型的 paperless-ngx 增强工具,提供智能 OCR 和自动元数据生成能力,让文档数字化归档更高效。
Stars: 2432 | Forks: 172
# paperless-gpt
[](LICENSE)
[](https://discord.gg/fJQppDH2J7)
[](https://hub.docker.com/r/icereed/paperless-gpt)
[](https://github.com/icereed/paperless-gpt/pkgs/container/paperless-gpt)
[](CODE_OF_CONDUCT.md)
[](https://github.com/sponsors/icereed)
💡 由 [Icereed](https://github.com/icereed) 维护。由 [BubbleTax.de](https://bubbletax.de/?utm_source=github&utm_medium=readme&utm_campaign=paperless) 荣誉支持 – 为德国的 Interactive Brokers 交易者提供自动化、符合 BMF 标准的税务报告。
**paperless-gpt** 与 [paperless-ngx][paperless-ngx] 无缝集成,生成 **AI 驱动的文档标题**和**标签**,为您节省数小时的手动整理时间。虽然其他工具可能提供 AI 聊天功能,但 **paperless-gpt** 的独特之处在于**利用 LLM 增强 OCR**——即使面对棘手的扫描件也能确保高准确度。如果您渴望更高级的文本提取和轻松的文档管理,这就是您的解决方案。
https://github.com/user-attachments/assets/bd5d38b9-9309-40b9-93ca-918dfa4f3fd4
## 关键亮点
1. **LLM 增强型 OCR**
利用大型语言模型(OpenAI 或 Ollama)实现**超越传统**的 OCR——将混乱或低质量的扫描件转化为具有上下文感知、高保真的文本。
2. **使用专门的 AI OCR 服务**
- **LLM OCR**:使用 OpenAI 或 Ollama 从图像中提取文本。
- **Google Document AI**:利用 Google 强大的 Document AI 执行 OCR 任务。
- **Azure Document Intelligence**:使用 Microsoft 的企业级 OCR 解决方案。
- **Docling Server**:自托管的 OCR 和文档转换服务。
3. **自动生成标题、标签和创建日期**
不再猜测。让 AI 完成命名和分类。您可以轻松查看建议并根据需要进行调整。
4. **支持 Ollama 中的推理模型**
通过使用像 `qwen3:8b` 这样的推理模型,极大地提高准确性。这是隐私与性能的完美平衡!当然,如果您有足够的 GPU 或 NPU,更大的模型将提升体验。
5. **自动生成通信者**
自动识别并从您的文档中生成通信者,使跟踪和组织您的通信变得更加容易。
6. **自动生成自定义字段**
从文档中提取并填充自定义字段。配置要针对的字段及其填充方式。此功能必须在设置中启用,并且您必须至少选择一个自定义字段才能使其生效。提供三种写入模式:
- **Append(追加)**:这是最安全的选项:它只添加文档中尚不存在的新字段。它永远不会覆盖现有字段,即使该字段为空。
- **Update(更新)**:添加新字段并用新建议覆盖现有字段。文档中没有新建议的字段将保持不变。
- **Replace(替换)**:删除文档上的所有现有自定义字段,并完全替换为建议的字段。
7. **可搜索和可选择的 PDF**
生成带有透明文本层的 PDF,这些文本层精确定位在每个单词上,使您的文档既可搜索又可选择,同时保留原始外观。
8. **广泛的定制化**
- **通过 Web UI 定制提示词**:直接在 Web 界面的“Settings”菜单下调整和管理所有用于标题、标签、通信者等的 AI 提示词。应用程序使用安全的 `default_prompts` 和 `prompts` 目录结构,确保您的定制化设置持久保存。
- **标签**:决定文档如何被标记——手动、自动或通过基于 OCR 的流程。
- **PDF 处理**:配置如何处理 OCR 增强的 PDF,可选择保存到本地或上传到 paperless-ngx。
9. **简单的 Docker 部署**
只需几个环境变量,即可启动!与 paperless-ngx 一起轻松编排。
10. **统一的 Web UI**
- **手动审查**:批准或调整 AI 的建议。
- **自动处理**:只关注边缘情况,其余的由系统为您分类。
11. **临时文档分析**
使用自定义提示词对选定的文档执行临时分析。快速获取见解、摘要,或一次从多个文档中提取特定信息。
## 目录
- [paperless-gpt](#paperless-gpt)
- [关键亮点](#key-highlights)
- [目录](#table-of-contents)
- [入门指南](#getting-started)
- [前置条件](#prerequisites)
- [安装](#installation)
- [Docker Compose](#docker-compose)
- [手动设置](#manual-setup)
- [OCR 提供商](#ocr-providers)
- [1. 基于 LLM 的 OCR(默认)](#1-llm-based-ocr-default)
- [2. Azure Document Intelligence](#2-azure-document-intelligence)
- [3. Google Document AI](#3-google-document-ai)
- [4. Docling Server](#4-docling-server)
- [OCR 处理模式](#ocr-processing-modes)
- [图像模式(默认)](#image-mode-default)
- [PDF 模式](#pdf-mode)
- [整份 PDF 模式](#whole-pdf-mode)
- [提供商兼容性](#provider-compatibility)
- [现有 OCR 检测](#existing-ocr-detection)
- [增强的 OCR 功能](#enhanced-ocr-features)
- [PDF 文本层生成](#pdf-text-layer-generation)
- [本地文件保存](#local-file-saving)
- [PDF 上传至 paperless-ngx](#pdf-upload-to-paperless-ngx)
- [元数据复制限制](#metadata-copying-limitations)
- [安全功能](#safety-features)
- [使用建议](#usage-recommendations)
- [配置](#configuration)
- [环境变量](#environment-variables)
- [自定义提示词模板](#custom-prompt-templates)
- [模板变量](#template-variables)
- [基于 LLM 的 OCR:亲自对比](#llm-based-ocr-compare-for-yourself)
- [示例 1](#example-1)
- [示例 2](#example-2)
- [工作原理](#how-it-works)
- [使用方法](#usage)
- [故障排除](#troubleshooting)
- [使用本地 LLM](#working-with-local-llms)
- [Token 管理](#token-management)
- [PDF 处理问题](#pdf-processing-issues)
- [自定义字段生成问题](#custom-field-generation-issues)
- [贡献](#contributing)
- [支持项目](#support-the-project)
- [许可证](#license)
- [Star 历史](#star-history)
- [免责声明](#disclaimer)
## 入门指南
### 前置条件
- 已安装 [Docker][docker-install]。
- 运行中的 [paperless-ngx][paperless-ngx] 实例。
- 访问 LLM 提供商的权限:
- **OpenAI**:拥有 `gpt-4o` 或 `gpt-3.5-turbo` 等模型的 API key。
- **Ollama**:运行中的 Ollama 服务器,并包含 `qwen3:8b` 等模型。
### 安装
#### Docker Compose
这是一个启动 **paperless-gpt** 并与 paperless-ngx 配合使用的 `docker-compose.yml` 示例:
```
services:
paperless-ngx:
image: ghcr.io/paperless-ngx/paperless-ngx:latest
# ... (your existing paperless-ngx config)
paperless-gpt:
# Use one of these image sources:
image: icereed/paperless-gpt:latest # Docker Hub
# image: ghcr.io/icereed/paperless-gpt:latest # GitHub Container Registry
environment:
PAPERLESS_BASE_URL: "http://paperless-ngx:8000"
PAPERLESS_API_TOKEN: "your_paperless_api_token"
PAPERLESS_PUBLIC_URL: "http://paperless.mydomain.com" # Optional
MANUAL_TAG: "paperless-gpt" # Optional, default: paperless-gpt
AUTO_TAG: "paperless-gpt-auto" # Optional, default: paperless-gpt-auto
# LLM Configuration - Choose one:
# Option 1: Standard OpenAI
LLM_PROVIDER: "openai"
LLM_MODEL: "gpt-4o"
OPENAI_API_KEY: "your_openai_api_key"
# Option 2: Mistral
# LLM_PROVIDER: "mistral"
# LLM_MODEL: "mistral-large-latest"
# MISTRAL_API_KEY: "your_mistral_api_key"
# Option 3: Azure OpenAI
# LLM_PROVIDER: "openai"
# LLM_MODEL: "your-deployment-name"
# OPENAI_API_KEY: "your_azure_api_key"
# OPENAI_API_TYPE: "azure"
# OPENAI_BASE_URL: "https://your-resource.openai.azure.com"
# Option 4: Ollama (Local)
# LLM_PROVIDER: "ollama"
# LLM_MODEL: "qwen3:8b"
# OLLAMA_HOST: "http://host.docker.internal:11434"
# OLLAMA_CONTEXT_LENGTH: "8192" # Sets Ollama NumCtx (context window)
# TOKEN_LIMIT: 1000 # Recommended for smaller models
# Option 5: Anthropic/Claude
# LLM_PROVIDER: "anthropic"
# LLM_MODEL: "claude-sonnet-4-5"
# ANTHROPIC_API_KEY: "your_anthropic_api_key"
# Optional LLM Settings
# LLM_LANGUAGE: "English" # Optional, default: English
# OCR Configuration - Choose one:
# Option 1: LLM-based OCR
OCR_PROVIDER: "llm" # Default OCR provider
VISION_LLM_PROVIDER: "ollama" # openai, ollama, mistral, or anthropic
VISION_LLM_MODEL: "minicpm-v" # minicpm-v (ollama) or gpt-4o (openai) or claude-sonnet-4-5 (anthropic/claude)
OLLAMA_HOST: "http://host.docker.internal:11434" # If using Ollama
# OCR Processing Mode
OCR_PROCESS_MODE: "image" # Optional, default: image, other options: pdf, whole_pdf
PDF_SKIP_EXISTING_OCR: "false" # Optional, skip OCR for PDFs with existing OCR
# Option 2: Google Document AI
# OCR_PROVIDER: 'google_docai' # Use Google Document AI
# GOOGLE_PROJECT_ID: 'your-project' # Your GCP project ID
# GOOGLE_LOCATION: 'us' # Document AI region
# GOOGLE_PROCESSOR_ID: 'processor-id' # Your processor ID
# GOOGLE_APPLICATION_CREDENTIALS: '/app/credentials.json' # Path to service account key
# Option 3: Azure Document Intelligence
# OCR_PROVIDER: 'azure' # Use Azure Document Intelligence
# AZURE_DOCAI_ENDPOINT: 'your-endpoint' # Your Azure endpoint URL
# AZURE_DOCAI_KEY: 'your-key' # Your Azure API key
# AZURE_DOCAI_MODEL_ID: 'prebuilt-read' # Optional, defaults to prebuilt-read
# AZURE_DOCAI_TIMEOUT_SECONDS: '120' # Optional, defaults to 120 seconds
# AZURE_DOCAI_OUTPUT_CONTENT_FORMAT: 'text' # Optional, defaults to 'text', other valid option is 'markdown'
# 'markdown' requires the 'prebuilt-layout' model
# Enhanced OCR Features
CREATE_LOCAL_HOCR: "false" # Optional, save hOCR files locally
LOCAL_HOCR_PATH: "/app/hocr" # Optional, path for hOCR files
CREATE_LOCAL_PDF: "false" # Optional, save enhanced PDFs locally
LOCAL_PDF_PATH: "/app/pdf" # Optional, path for PDF files
PDF_UPLOAD: "false" # Optional, upload enhanced PDFs to paperless-ngx
PDF_REPLACE: "false" # Optional and DANGEROUS, delete original after upload
PDF_COPY_METADATA: "true" # Optional, copy metadata from original document
PDF_OCR_TAGGING: "true" # Optional, add tag to processed documents
PDF_OCR_COMPLETE_TAG: "paperless-gpt-ocr-complete" # Optional, tag name
# Option 4: Docling Server
# OCR_PROVIDER: 'docling' # Use a Docling server
# DOCLING_URL: 'http://your-docling-server:port' # URL of your Docling instance
# DOCLING_IMAGE_EXPORT_MODE: "placeholder" # Optional, defaults to "embedded"
# DOCLING_OCR_PIPELINE: "standard" # Optional, defaults to "vlm"
# DOCLING_OCR_ENGINE: "easyocr" # Optional, defaults to "easyocr" (only used when `DOCLING_OCR_PIPELINE is set to 'standard')
AUTO_OCR_TAG: "paperless-gpt-ocr-auto" # Optional, default: paperless-gpt-ocr-auto
OCR_LIMIT_PAGES: "5" # Optional, default: 5. Set to 0 for no limit.
LOG_LEVEL: "info" # Optional: debug, warn, error
volumes:
- ./prompts:/app/prompts # Mount the prompts directory
# For Google Document AI:
- ${HOME}/.config/gcloud/application_default_credentials.json:/app/credentials.json
# For local hOCR and PDF saving:
- ./hocr:/app/hocr # Only if CREATE_LOCAL_HOCR is true
- ./pdf:/app/pdf # Only if CREATE_LOCAL_PDF is true
ports:
- "8080:8080"
depends_on:
- paperless-ngx
```
**专业提示**:将占位符替换为实际值,如果出现异常,请阅读日志。
#### 手动设置
1. **克隆仓库**
git clone https://github.com/icereed/paperless-gpt.git
cd paperless-gpt
2. **创建 `prompts` 目录**
mkdir prompts
3. **构建 Docker 镜像**
docker build -t paperless-gpt .
4. **运行容器**
docker run -d \
-e PAPERLESS_BASE_URL='http://your_paperless_ngx_url' \
-e PAPERLESS_API_TOKEN='your_paperless_api_token' \
-e LLM_PROVIDER='openai' \
-e LLM_MODEL='gpt-4o' \
-e OPENAI_API_KEY='your_openai_api_key' \
-e LLM_LANGUAGE='English' \
-e VISION_LLM_PROVIDER='ollama' \
-e VISION_LLM_MODEL='minicpm-v' \
-e LOG_LEVEL='info' \
-v $(pwd)/prompts:/app/prompts \
-p 8080:8080 \
paperless-gpt
## OCR 提供商
有关特定提供商的详细文档:
- [Mistral AI 集成](docs/mistral_llm.md)
paperless-gpt 支持四种不同的 OCR 提供商,每种都有独特的优势和功能:
### 1. 基于 LLM 的 OCR(默认)
- **主要功能**:
- 使用具有视觉能力的 LLM,如 gpt-4o 或 MiniCPM-V
- 对复杂布局和难以辨认的扫描件具有高准确度
- 具有上下文感知的文本识别
- 对 OCR 错误的自我纠正能力
- **适用于**:
- 复杂或不寻常的文档布局
- 质量较差的扫描件
- 混合语言的文档
- **配置**:
OCR_PROVIDER: "llm"
VISION_LLM_PROVIDER: "openai" # 或 "ollama"
VISION_LLM_MODEL: "gpt-4o" # 或 "minicpm-v"
### 2. Azure Document Intelligence
- **主要功能**:
- 企业级 OCR 解决方案
- 针对常见文档类型的预构建模型
- 布局保留和表格检测
- 快速的处理速度
- **适用于**:
- 商业文档和表单
- 大批量处理
- 需要布局分析的文档
- **配置**:
OCR_PROVIDER: "azure"
AZURE_DOCAI_ENDPOINT: "https://your-endpoint.cognitiveservices.azure.com/"
AZURE_DOCAI_KEY: "your-key"
AZURE_DOCAI_MODEL_ID: "prebuilt-read" # 可选
AZURE_DOCAI_TIMEOUT_SECONDS: "120" # 可选
AZURE_DOCAI_OUTPUT_CONTENT_FORMAT:
"text" # 可选,默认为 text,另一个有效选项是 'markdown'
# 'markdown' 需要 'prebuilt-layout' 模型
### 3. Google Document AI
- **主要功能**:
- 企业级 OCR/HTR 解决方案
- 专门的文档处理器
- 强大的表单字段检测
- 多语言支持
- 对结构化文档具有高准确度
- **独家生成 hOCR**,用于创建带有文本层的可搜索 PDF
- **唯一支持**增强 PDF 生成功能的提供商
- **适用于**:
- 表单和结构化文档
- 带有表格的文档
- 多语言文档
- 手写文本 (HTR)
- **配置**:
OCR_PROVIDER: "google_docai"
GOOGLE_PROJECT_ID: "your-project"
GOOGLE_LOCATION: "us"
GOOGLE_PROCESSOR_ID: "processor-id"
CREATE_LOCAL_HOCR: "true" # 可选,用于生成 hOCR
LOCAL_HOCR_PATH: "/app/hocr" # 可选,默认路径
CREATE_LOCAL_PDF: "true" # 可选,用于将 OCR 应用于 PDF
LOCAL_PDF_PATH: "/app/pdf" # 可选,默认路径
### 4. Docling Server
- **主要功能**:
- 自托管的 OCR 和文档转换服务
- 支持各种输入和输出格式(包括文本)
- 利用多个 OCR 引擎(EasyOCR, Tesseract 等)
- 可以在本地或私有网络中运行
- **适用于**:
- 偏好自托管解决方案的用户
- 数据隐私至关重要的环境
- 处理各种各样的文档类型
- **配置**:
OCR_PROVIDER: "docling"
DOCLING_URL: "http://your-docling-server:port"
DOCLING_IMAGE_EXPORT_MODE: "placeholder" # 可选,默认为 "embedded"
DOCLING_OCR_PIPELINE: "standard" # 可选,默认为 "vlm"
DOCLING_OCR_ENGINE: "macocr" # 可选,默认为 "easyocr"(仅当 `DOCLING_OCR_PIPELINE 设置为 'standard' 时使用)
## OCR 处理模式
paperless-gpt 提供不同的文档处理方法,根据您的需求和 OCR 提供商的能力提供灵活性:
### 图像模式(默认)
- **工作原理**:在处理之前将 PDF 页面转换为
- **适用于**:兼容所有 OCR 提供商。
- **配置**:`OCR_PROCESS_MODE: "image"`
### PDF 模式
- **工作原理**:直接处理 PDF 页面,无需图像转换
- **适用于**:保留 PDF 功能,某些提供商可能处理速度更快且准确度更高
- **配置**:`OCR_PROCESS_MODE: "pdf"`
### 整份 PDF 模式
- **工作原理**:在单个操作中处理整个 PDF 文档
- **适用于**:能够高效处理多页文档的提供商,减少 API 调用
- **配置**:`OCR_PROCESS_MODE: "whole_pdf"`
- **注意**:处理大型 PDF 可能会导致您达到 OCR 提供商的 API 限制。如果您在使用大型文档时遇到问题,请考虑切换到 `pdf` 模式,该模式会逐页处理。
### 提供商兼容性
不同的 OCR 提供商支持不同的处理模式:
| Provider | Image Mode | PDF Mode | Whole PDF Mode |
|----------|------------|----------|----------------|
| **LLM-based OCR** (OpenAI/Ollama) | ✅ | ❌ | ❌ |
| **Azure Document Intelligence** | ✅ | ❌ | ❌ |
| **Google Document AI** | ✅ | ✅ | ✅ |
| **Mistral OCR** | ✅ | ✅ | ✅ |
| **Docling Server** | ✅ | ✅ | ✅ |
### 现有 OCR 检测
使用 PDF 或整份 PDF 模式时,您可以启用对现有 OCR 的自动检测:
```
environment:
OCR_PROCESS_MODE: "pdf" # or "whole_pdf"
PDF_SKIP_EXISTING_OCR: "true" # Skip processing if existing OCR is detected in the PDF
```
## 增强的 OCR 功能
paperless-gpt 包含强大的 OCR 增强功能,超越了基本的文本提取:
### PDF 文本层生成
- **可搜索和可选择的 PDF**:创建带有透明文本覆盖层的 PDF,精确地定位在文档中的每个单词上
- **hOCR 集成**:利用 hOCR 格式(基于 HTML 的 OCR 表示)来保持精确的文本定位
- **文档质量改进**:使文档既可搜索又可选择,同时保留原始外观
- **需要 Google Document AI**:这些功能依赖于 Google Document AI 生成具有准确单词位置的 hOCR 数据的能力
### 本地文件保存
paperless-gpt 可以在本地保存 hOCR 文件和增强的 PDF:
```
environment:
# Enable local file saving
CREATE_LOCAL_HOCR: "true" # Save hOCR files locally
CREATE_LOCAL_PDF: "true" # Save generated PDFs locally
LOCAL_HOCR_PATH: "/app/hocr" # Path to save hOCR files
LOCAL_PDF_PATH: "/app/pdf" # Path to save PDF files
volumes:
# Mount volumes to access the files from your host
- ./hocr_files:/app/hocr
- ./pdf_files:/app/pdf
```
### PDF 上传至 paperless-ngx
由于 paperless-ngx API 的限制,无法直接用 OCR 增强版本更新现有文档。作为一种变通方法,paperless-gpt 可以:
1. 将增强的 PDF 作为新文档上传
2. 将元数据从原始文档复制到新文档
3. 可选择删除原始文档
```
environment:
# PDF upload configuration
PDF_UPLOAD: "true" # Upload processed PDFs to paperless-ngx
PDF_COPY_METADATA: "true" # Copy metadata from original to new document
PDF_REPLACE: "false" # Whether to delete the original document (use with caution!)
PDF_OCR_TAGGING: "true" # Add a tag to mark documents as OCR-processed
PDF_OCR_COMPLETE_TAG: "paperless-gpt-ocr-complete" # Tag used to mark OCR-processed documents
```
### 元数据复制限制
将元数据从原始文档复制到新文档时,paperless-gpt 会尝试复制:
- 文档标题
- 标签(包括添加 OCR 完成标签)
- 通信者信息
- 创建日期
然而,由于 paperless-ngx API 的限制,某些元数据**无法**被复制:
- 文档 ID(新文档总是获得新 ID)
- 添加日期(将反映当前上传日期)
- 修改日期
- 可能由其他 paperless-ngx 插件添加的自定义字段
- 注释和标注
### 安全功能
为了防止意外创建不完整的文档,paperless-gpt 包含多项安全功能:
1. **页数检查**:如果使用 `OCR_LIMIT_PAGES` 仅处理页面子集(出于速度或资源原因),如果要处理的页数少于原始文档中的现有页数,则将完全跳过 PDF 生成。
```
environment:
OCR_LIMIT_PAGES: "5" # Limit OCR to first 5 pages, set to 0 for no limit
```
2. **OCR 完成标记**:已完全通过 OCR 处理的文档可以自动标记一个特殊标签,防止重复处理。
3. **处理跳过**:如果文档已有 OCR 完成标签,处理将自动跳过。
### 使用建议
为了获得增强 OCR 功能的最佳效果:
1. **初始测试**:从 `PDF_REPLACE: "false"` 开始,直到您确认该过程适用于您的文档。
2. **定期备份**:在启用文档替换之前,确保您已备份 paperless-ngx 数据库和文档。
3. **流程管理**:对于大型文档,请考虑使用 `OCR_LIMIT_PAGES: "0"` 以确保处理所有页面,尽管这会花费更长时间。
4. **本地副本**:启用本地文件保存(`CREATE_LOCAL_HOCR` 和 `CREATE_LOCAL_PDF`)作为额外的预防措施,保留增强文件的副本。
5. **标记策略**:使用 OCR 完成标签(`PDF_OCR_COMPLETE_TAG`)来跟踪哪些文档已经被处理。
## 配置
### 环境变量
| Variable | Description | Required | Default |
| ----------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------- | -------------------------- |
| `PAPERLESS_BASE_URL` | 您的 paperless-ngx 实例的 URL(例如 `http://paperless-ngx:8000`)。 | Yes | |
| `PAPERLESS_API_TOKEN` | paperless-ngx 的 API token。在 paperless-ngx 管理后台生成一个。 | Yes | |
| `PAPERLESS_PUBLIC_URL` | Paperless 的公共 URL(如果与 `PAPERLESS_BASE_URL` 不同)。 | No | |
| `MANUAL_TAG` | 用于手动处理的标签。 | No | paperless-gpt |
| `AUTO_TAG` | 用于自动处理的标签。 | No | paperless-gpt-auto |
| `LLM_PROVIDER` | AI 后端(`openai`, `ollama`, `googleai`, `mistral`, 或 `anthropic`)。 | Yes | |
| `LLM_MODEL` | AI 模型名称(例如 `gpt-4o`, `mistral-large-latest`, `qwen3:8b`, `claude-sonnet-4-5`)。 | Yes | |
| `OPENAI_API_KEY` | OpenAI API key(如果使用 OpenAI 则为必需)。 | Cond. | |
| `MISTRAL_API_KEY` | Mistral API key(如果使用 Mistral 则为必需)。 | Cond. | |
| `ANTHROPIC_API_KEY` | Anthropic API key(如果使用 Anthropic/Claude 则为必需)。 | Cond. | |
| `OPENAI_API_TYPE` | 设置为 `azure` 以使用 Azure OpenAI Service。 | No | |
| `OPENAI_BASE_URL` | OpenAI API 的 Base URL。对于 Azure OpenAI,设置为您的部署 URL(例如 `https://your-resource.openai.azure.com`)。 | No | |
| `LLM_LANGUAGE` | 文档的可能语言(例如 `English`)。出现在提示词中以帮助 LLM。 | No | English |
| `GOOGLEAI_API_KEY` | Google Gemini API key(如果使用 `LLM_PROVIDER=googleai` 则为必需)。 | Cond. | |
| `GOOGLEAI_THINKING_BUDGET` | (可选,仅限 googleai)整数。控制 Gemini “thinking”预算。如果未设置,则使用模型默认值(如果支持则启用 thinking)。设置为 `0` 以禁用 thinking(如果模型支持)。 | No | |
| `OLLAMA_HOST` | Ollama 服务器 URL(例如 `http://host.docker.internal:11434`)。 | No | |
| `LLM_REQUESTS_PER_MINUTE` | 主 LLM 的每分钟最大请求数。用于管理 API 成本或本地 LLM 负载。 | No | 120 |
| `LLM_MAX_RETRIES` | 失败的主 LLM 请求的最大重试次数。 | No | 3 |
| `LLM_BACKOFF_MAX_WAIT` | 主 LLM 重试之间的最大等待时间(例如 `30s`)。 | No | 30s |
| `OCR_PROVIDER` | 要使用的 OCR 提供商(`llm`, `azure`, 或 `google_docai`)。 | No | llm |
| `OCR_PROCESS_MODE` | 处理文档的方法:`image`(先转换为图像),`pdf`(直接处理 PDF 页面),或 `whole_pdf`(一次性处理整个 PDF)。 | No | image |
| `VISION_LLM_PROVIDER` | 用于 LLM OCR 的 AI 后端(`openai`, `ollama`, `mistral`, 或 `anthropic`)。如果 OCR_PROVIDER 是 `llm` 则为必需。 | Cond. | |
| `VISION_LLM_MODEL` | 用于 LLM OCR 的模型名称(例如 `minicpm-v`)。如果 OCR_PROVIDER 是 `llm` 则为必需。 | Cond. | |
| `VISION_LLM_REQUESTS_PER_MINUTE` | Vision LLM 的每分钟最大请求数。用于管理 API 成本或本地 LLM 负载。 | No | 120 |
| `VISION_LLM_MAX_RETRIES` | 失败的 Vision LLM 请求的最大重试次数。 | No | 3 |
| `VISION_LLM_BACKOFF_MAX_WAIT` | Vision LLM 重试之间的最大等待时间(例如 `30s`)。 | No | 30s |
| `VISION_LLM_MAX_TOKENS` | Vision LLM OCR 输出的最大 token 数。 | No | |
| `VISION_LLM_TEMPERATURE` | Vision OCR 生成的采样温度。越低越确定。重要:对于 OpenAI GPT-5,必须显式设置为 `1.0`。 | No | |
| `OLLAMA_CONTEXT_LENGTH` | (仅限 Ollama)整数。为 Ollama runner 设置 NumCtx(上下文窗口)。如果未设置或为 0,则使用模型默认值。 | No | |
| `OLLAMA_OCR_TOP_K` | (仅限 Ollama)用于 Vision OCR 的 Top-k token 采样。较低值倾向于更可能的 token;较高值增加多样性。 | No | |
| `AZURE_DOCAI_ENDPOINT` | Azure Document Intelligence endpoint。如果 OCR_PROVIDER 是 `azure` 则为必需。 | Cond. | |
| `AZURE_DOCAI_KEY` | Azure Document Intelligence API key。如果 OCR_PROVIDER 是 `azure` 则为必需。 | Cond. | |
| `AZURE_DOCAI_MODEL_ID` | Azure Document Intelligence model ID。如果使用 `azure` 提供商则为可选。 | No | prebuilt-read |
| `AZURE_DOCAI_TIMEOUT_SECONDS` | Azure Document Intelligence 超时(以秒为单位)。 | No | 120 |
| `AZURE_DOCAI_OUTPUT_CONTENT_FORMAT` | Azure Document Intelligence 输出内容格式。如果使用 `azure` 提供商则为可选。默认为 `text`。另一个选项是 'markdown',它需要 'prebuild-layout' 模型 ID。 | No | text |
| `GOOGLE_PROJECT_ID` | Google Cloud 项目 ID。如果 OCR_PROVIDER 是 `google_docai` 则为必需。 | Cond. | |
| `GOOGLE_LOCATION` | Google Cloud 区域(例如 `us`, `eu`)。如果 OCR_PROVIDER 是 `google_docai` 则为必需。 | Cond. | |
| `GOOGLE_PROCESSOR_ID` | Document AI processor ID。如果 OCR_PROVIDER 是 `google_docai` 则为必需。 | Cond. | |
| `GOOGLE_APPLICATION_CREDENTIALS` | 挂载的 Google 服务帐号密钥路径。如果 OCR_PROVIDER 是 `google_docai` 则为必需。 | Cond. | |
| `DOCLING_URL` | Docling 服务器实例的 URL。如果 OCR_PROVIDER 是 `docling` 则为必需。 | Cond. | |
| `DOCLING_IMAGE_EXPORT_MODE` | 图像导出模式。可选;如果未设置则默认为 `embedded`。 | No | embedded |
| `DOCLING_OCR_PIPELINE` | 设置管道类型。可选;如果未设置则默认为 `vlm`。 | No | vlm |
| `DOCLING_OCR_ENGINE` | 设置 OCR 引擎,如果 `DOCLING_OCR_PIPELINE` 设置为 `standard`。可选;默认为 `easyocr` | No | easyocr |
| `CREATE_LOCAL_HOCR` | 是否在本地保存 hOCR 文件。 | No | false |
| `LOCAL_HOCR_PATH` | 启用 hOCR 生成时保存 hOCR 文件的路径。 | No | /app/hocr |
| `CREATE_LOCAL_PDF` | 是否在本地保存增强的 PDF。 | No | false |
| `LOCAL_PDF_PATH` | 启用 PDF 生成时保存 PDF 文件的路径。 | No | /app/pdf |
| `PDF_UPLOAD` | 是否将增强的 PDF 上传到 paperless-ngx。 | No | false |
| `PDF_REPLACE` | 是否在上传增强版本后删除原始文档(危险)。 | No | false |
| `PDF_COPY_METADATA` | 是否将元数据从原始文档复制到上传的 PDF。仅在使用 PDF_UPLOAD 时适用。 | No | true |
| `PDF_OCR_TAGGING` | 是否添加标签以将文档标记为已进行 OCR 处理。 | No | true |
| `PDF_OCR_COMPLETE_TAG` | 用于将文档标记为已进行 OCR 处理的标签。 | No | paperless-gpt-ocr-complete |
| `PDF_SKIP_EXISTING_OCR` | 是否跳过对已有 OCR 的 PDF 进行 OCR 处理。与 `pdf` 和 `whole_pdf` 处理模式(`OCR_PROCESS_MODE`)配合使用。 | No | false |
| `AUTO_OCR_TAG` | 用于自动处理带有 OCR 的文档的标签。 | No | paperless-gpt-ocr-auto |
|OCR_LIMIT_PAGES` | 限制用于 OCR 的页数。设置为 `0` 表示无限制。 | No | 5 |
| `LOG_LEVEL` | 应用程序日志级别(`info`, `debug`, `warn`, `error`)。 | No | info |
| `LISTEN_INTERFACE` | 要监听的网络接口。 | No | 8080 |
| `AUTO_GENERATE_TITLE` | 如果使用 `paperless-gpt-auto`,则自动生成标题。 | No | true |
| `AUTO_GENERATE_TAGS` | 如果使用 `paperless-gpt-auto`,则自动生成标签。 | No | true |
| `AUTO_GENERATE_CORRESPONDENTS` | 如果使用 `paperless-gpt-auto`,则自动生成通信者。 | No | true |
| `AUTO_GENERATE_DOCUMENT_TYPE` | 如果使用 `paperless-gpt-auto`,则自动生成文档类型。仅使用 paperless-ngx 中现有的文档类型。 | No | true |
| `AUTO_GENERATE_CREATED_DATE` | 如果使用 `paperless-gpt-auto`,则自动生成创建日期。 | No | true |
| `TOKEN_LIMIT` | 提示词/内容允许的最大 token 数。设置为 `0` 以禁用限制。对较小的 LLM 有用。 | No | |
| `IMAGE_MAX_PIXEL_DIMENSION` | 将文档页面渲染为图像时任意边的最大像素数。 | No | 10000 |
| `IMAGE_MAX_TOTAL_PIXELS` | 将文档页面渲染为图像时的最大总像素数(宽 × 高)。 | No | 40000000 |
| `IMAGE_MAX_RENDER_DPI` | 将文档页面渲染为图像时使用的最大 DPI。 | No | 600 |
| `IMAGE_MAX_FILE_BYTES` | 渲染页面图像的最大 JPEG 文件大小(以字节为单位)。超过此大小的图像将被压缩或调整大小。 | No | 10485760 |
| `CORRESPONDENT_BLACK_LIST` | 以逗号分隔的名称列表,用于从通信者建议中排除。例如:`John Doe, Jane Smith`。 | No | |
### 自定义提示词模板
paperless-gpt 灵活的**提示词模板**让您可以塑造 AI 的响应方式。虽然您仍然可以手动管理文件,但自定义提示词的推荐方法是通过 Web UI 中的 **Settings** 页面。
应用程序使用两个目录进行管理:
- **`default_prompts/`**:包含内置的默认模板。不应修改这些模板。
- **`prompts/`**:您的工作目录。首次运行时,默认模板会被复制到这里。在 UI 中所做的所有编辑都会保存到此目录的文件中。
为了确保您的自定义提示词在容器重启后仍然存在,您必须在 `docker-compose.yml` 中将 `prompts` 目录挂载为卷:
```
volumes:
# This is crucial to save your custom prompts!
- ./prompts:/app/prompts
```
应用程序在您于 UI 中保存模板后以及启动时都会立即重新加载模板,因此无需重启即可应用更改。
#### 模板变量
每个模板都可以访问特定的变量:
**title_prompt.tmpl**:
- `{{.Language}}` - 目标语言(例如 "English")
- `{{.Content}}` - 文档内容文本
- `{{.Title}}` - 原始文档标题
**tag_prompt.tmpl**:
- `{{.Language}}` - 目标语言
- `{{.AvailableTags}}` - paperless-ngx 中现有标签的列表
- `{{.OriginalTags}}` - 文档的当前标签
- `{{.Title}}` - 文档标题
- `{{.Content}}` - 文档内容文本
**ocr_prompt.tmpl**:
- `{{.Language}}` - 目标语言
**correspondent_prompt.tmpl**:
- `{{.Language}}` - 目标语言
- `{{.AvailableCorrespondents}}` - 现有通信者列表
- `{{.BlackList}}` - 黑名单通信者名称列表
- `{{.Title}}` - 文档标题
- `{{.Content}}` - 文档内容文本
**created_date_prompt.tmpl**:
- `{{.Language}}` - 目标语言
- `{{.Content}}` - 文档内容文本
**custom_field_prompt.tmpl**:
- `{{.DocumentType}}` - 文档在 paperless-ngx 中的类型名称。
- `{{.CustomFieldsXML}}` - 列出设置中选定进行处理的的自定义字段的 XML 字符串。
- `{{.Title}}` - 文档标题
- `{{.CreatedDate}}` - 文档的创建日期
- `{{.Content}}` - 文档内容文本
模板使用 Go 的 text/template 语法。paperless-gpt 会在 UI 保存后和启动时自动重新加载模板更改。
## 基于 LLM 的 OCR:亲自对比
**为什么这很重要?**
- 传统 OCR 经常混淆来自复杂或低质量扫描件的文本。
- 大型语言模型能够解释上下文并纠正可能的错误,从而产生更精确和可读的结果。
- 您可以将这些清理后的文本集成到您的 **paperless-ngx** 流程中,以实现更好的标记、搜索和归档。
### 工作原理
- **普通 OCR** 通常使用传统方法或类似 Tesseract 的引擎来提取文本,这可能会导致复杂字体或低质量扫描件的输出混乱。
- **LLM 驱动的 OCR** 使用您选择的 AI 后端——OpenAI 或 Ollama——以更具上下文感知的方式解释图像文本。这会减少错误并产生更连贯的文本。
- **Google Document AI 和 Azure Document Intelligence** 提供具有高级布局分析的高准确度 OCR。
- **增强的 PDF 生成** 将 OCR 结果与原始文档结合,创建具有正确定位文本层的可搜索 PDF。
## 使用方法
1. **标记文档**
- 为文档添加 `paperless-gpt` 标签以进行手动处理
- 添加 `paperless-gpt-auto` 以进行自动处理
- 添加 `paperless-gpt-ocr-auto` 以进行自动 OCR 处理
2. **访问 Web UI**
- 在浏览器中访问 `http://localhost:8080`(或您的主机)
- 查看标记为处理的文档
3. **生成并应用建议**
- 点击 "Generate Suggestions" 查看 AI 提议的标题/标签/通信者
- 查看并批准或编辑建议
- 点击 "Apply" 将更改保存到 paperless-ngx
4. **OCR 处理**
- 用适当的 OCR 标签标记文档以进行处理
- 如果启用了增强 PDF 功能,文档将被相应处理:
- 对于本地文件保存,检查配置的目录以获取输出文件
- 对于 PDF 上传,新文档将出现在 paperless-ngx 中并带有复制的元数据
- 在 Web UI 中监控进度
- 查看结果并应用更改
## 故障排除
### 使用本地 LLM
使用本地 LLM(如通过 Ollama)时,您可能需要调整某些设置以优化性能:
#### Token 管理
- 使用 `TOKEN_LIMIT` 环境变量控制发送到 LLM 的最大 token 数
- 对于 Ollama,设置 `OLLAMA_CONTEXT_LENGTH` 以控制模型的上下文窗口 (NumCtx)。这独立于 `TOKEN_LIMIT`,并配置服务器端的 KV cache 大小。如果未设置或为 0,则使用模型默认值。在模型支持的窗口内选择一个值(例如 8192)。
- 如果给定过多文本,较小的模型可能会意外截断内容
- 从保守的限制开始(例如 1000 个 token),并根据模型的能力进行调整
- 设置为 `0` 以禁用限制(谨慎使用)
针对较小模型的示例配置:
```
environment:
TOKEN_LIMIT: "2000" # Adjust based on your model's context window
OLLAMA_CONTEXT_LENGTH: "4096" # Controls Ollama NumCtx (context window); if unset, model default is used
LLM_PROVIDER: "ollama"
LLM_MODEL: "qwen3:8b" # Or other local model
```
常见问题及解决方案:
- 如果您看到截断或不完整的响应,请尝试降低 `TOKEN_LIMIT`
- 在 Ollama 上,如果您遇到“context length exceeded”或内存问题,请减少 `OLLAMA_CONTEXT_LENGTH` 或选择较小的模型/上下文大小。
- 如果处理过于受限,请在监控性能的同时逐渐增加限制
- 对于具有较大上下文窗口的模型,您可以增加限制或完全禁用它
### PDF 处理问题
- 如果未生成 PDF,请检查 `OCR_LIMIT_PAGES` 设置是否与您的文档页数相比过低
- 如果使用 `CREATE_LOCAL_PDF` 或 `CREATE_LOCAL_HOCR`,请确保卷已正确挂载
- 当使用 `PDF_REPLACE: "true"` 时,请验证您是否有最近的 paperless-ngx 数据备份
### 自定义字段生成问题
- **功能不起作用**:如果即使启用了该功能也未生成自定义字段建议,请确保您在设置中至少选择了一个自定义字段。该功能需要至少选择一个字段才能知道要处理什么。
## 贡献
欢迎提交 **Pull requests** 和 **issues**!
1. Fork 本仓库
2. 创建一个分支 (`feature/my-awesome-update`)
3. 提交更改 (`git commit -m "Improve X"`)
4. 打开一个 PR
查看我们的 [贡献指南](CONTRIBUTING.md) 了解详情。
## 支持项目
如果 paperless-gpt 为您节省了时间并使您的文档管理更轻松,请考虑支持其持续开发:
- **[GitHub Sponsors](https://github.com/sponsors/icereed)**:帮助资助持续的开发和维护
- **分享**您的成功案例和用例
- 在 GitHub 上给项目加 **Star**
- **贡献**代码、文档或错误报告
您的支持有助于确保 paperless-gpt 保持积极维护并持续改进!
## 维护者说明
本项目完全开源并将保持免费使用。
它由 [Icereed](https://github.com/icereed) 维护,并部分得到我另一个项目的支持:
👉 [BubbleTax.de](https://bubbletax.de/?utm_source=github&utm_medium=footer&utm_campaign=paperless) — 为德国的 IBKR 交易者提供自动化税务报告。
如果您是也是交易者的开发者,请查看它。如果不是 – 也没关系 😊
## 许可证
paperless-gpt 根据 [MIT 许可证](LICENSE) 授权。请随意改编和分享!
## Star 历史
[](https://www.star-history.com/#icereed/paperless-gpt&Date)
## 免责声明
本项目**未**正式隶属于 [paperless-ngx][paperless-ngx]。使用风险自负。
**paperless-gpt**:您的文档管理一直在等待的 **基于 LLM** 的伴侣。享受轻松、智能的文档标题、标签和下一代 OCR。

💡 由 [Icereed](https://github.com/icereed) 维护。由 [BubbleTax.de](https://bubbletax.de/?utm_source=github&utm_medium=readme&utm_campaign=paperless) 荣誉支持 – 为德国的 Interactive Brokers 交易者提供自动化、符合 BMF 标准的税务报告。
**paperless-gpt** 与 [paperless-ngx][paperless-ngx] 无缝集成,生成 **AI 驱动的文档标题**和**标签**,为您节省数小时的手动整理时间。虽然其他工具可能提供 AI 聊天功能,但 **paperless-gpt** 的独特之处在于**利用 LLM 增强 OCR**——即使面对棘手的扫描件也能确保高准确度。如果您渴望更高级的文本提取和轻松的文档管理,这就是您的解决方案。
https://github.com/user-attachments/assets/bd5d38b9-9309-40b9-93ca-918dfa4f3fd4
## 关键亮点
1. **LLM 增强型 OCR**
利用大型语言模型(OpenAI 或 Ollama)实现**超越传统**的 OCR——将混乱或低质量的扫描件转化为具有上下文感知、高保真的文本。
2. **使用专门的 AI OCR 服务**
- **LLM OCR**:使用 OpenAI 或 Ollama 从图像中提取文本。
- **Google Document AI**:利用 Google 强大的 Document AI 执行 OCR 任务。
- **Azure Document Intelligence**:使用 Microsoft 的企业级 OCR 解决方案。
- **Docling Server**:自托管的 OCR 和文档转换服务。
3. **自动生成标题、标签和创建日期**
不再猜测。让 AI 完成命名和分类。您可以轻松查看建议并根据需要进行调整。
4. **支持 Ollama 中的推理模型**
通过使用像 `qwen3:8b` 这样的推理模型,极大地提高准确性。这是隐私与性能的完美平衡!当然,如果您有足够的 GPU 或 NPU,更大的模型将提升体验。
5. **自动生成通信者**
自动识别并从您的文档中生成通信者,使跟踪和组织您的通信变得更加容易。
6. **自动生成自定义字段**
从文档中提取并填充自定义字段。配置要针对的字段及其填充方式。此功能必须在设置中启用,并且您必须至少选择一个自定义字段才能使其生效。提供三种写入模式:
- **Append(追加)**:这是最安全的选项:它只添加文档中尚不存在的新字段。它永远不会覆盖现有字段,即使该字段为空。
- **Update(更新)**:添加新字段并用新建议覆盖现有字段。文档中没有新建议的字段将保持不变。
- **Replace(替换)**:删除文档上的所有现有自定义字段,并完全替换为建议的字段。
7. **可搜索和可选择的 PDF**
生成带有透明文本层的 PDF,这些文本层精确定位在每个单词上,使您的文档既可搜索又可选择,同时保留原始外观。
8. **广泛的定制化**
- **通过 Web UI 定制提示词**:直接在 Web 界面的“Settings”菜单下调整和管理所有用于标题、标签、通信者等的 AI 提示词。应用程序使用安全的 `default_prompts` 和 `prompts` 目录结构,确保您的定制化设置持久保存。
- **标签**:决定文档如何被标记——手动、自动或通过基于 OCR 的流程。
- **PDF 处理**:配置如何处理 OCR 增强的 PDF,可选择保存到本地或上传到 paperless-ngx。
9. **简单的 Docker 部署**
只需几个环境变量,即可启动!与 paperless-ngx 一起轻松编排。
10. **统一的 Web UI**
- **手动审查**:批准或调整 AI 的建议。
- **自动处理**:只关注边缘情况,其余的由系统为您分类。
11. **临时文档分析**
使用自定义提示词对选定的文档执行临时分析。快速获取见解、摘要,或一次从多个文档中提取特定信息。
## 目录
- [paperless-gpt](#paperless-gpt)
- [关键亮点](#key-highlights)
- [目录](#table-of-contents)
- [入门指南](#getting-started)
- [前置条件](#prerequisites)
- [安装](#installation)
- [Docker Compose](#docker-compose)
- [手动设置](#manual-setup)
- [OCR 提供商](#ocr-providers)
- [1. 基于 LLM 的 OCR(默认)](#1-llm-based-ocr-default)
- [2. Azure Document Intelligence](#2-azure-document-intelligence)
- [3. Google Document AI](#3-google-document-ai)
- [4. Docling Server](#4-docling-server)
- [OCR 处理模式](#ocr-processing-modes)
- [图像模式(默认)](#image-mode-default)
- [PDF 模式](#pdf-mode)
- [整份 PDF 模式](#whole-pdf-mode)
- [提供商兼容性](#provider-compatibility)
- [现有 OCR 检测](#existing-ocr-detection)
- [增强的 OCR 功能](#enhanced-ocr-features)
- [PDF 文本层生成](#pdf-text-layer-generation)
- [本地文件保存](#local-file-saving)
- [PDF 上传至 paperless-ngx](#pdf-upload-to-paperless-ngx)
- [元数据复制限制](#metadata-copying-limitations)
- [安全功能](#safety-features)
- [使用建议](#usage-recommendations)
- [配置](#configuration)
- [环境变量](#environment-variables)
- [自定义提示词模板](#custom-prompt-templates)
- [模板变量](#template-variables)
- [基于 LLM 的 OCR:亲自对比](#llm-based-ocr-compare-for-yourself)
- [示例 1](#example-1)
- [示例 2](#example-2)
- [工作原理](#how-it-works)
- [使用方法](#usage)
- [故障排除](#troubleshooting)
- [使用本地 LLM](#working-with-local-llms)
- [Token 管理](#token-management)
- [PDF 处理问题](#pdf-processing-issues)
- [自定义字段生成问题](#custom-field-generation-issues)
- [贡献](#contributing)
- [支持项目](#support-the-project)
- [许可证](#license)
- [Star 历史](#star-history)
- [免责声明](#disclaimer)
## 入门指南
### 前置条件
- 已安装 [Docker][docker-install]。
- 运行中的 [paperless-ngx][paperless-ngx] 实例。
- 访问 LLM 提供商的权限:
- **OpenAI**:拥有 `gpt-4o` 或 `gpt-3.5-turbo` 等模型的 API key。
- **Ollama**:运行中的 Ollama 服务器,并包含 `qwen3:8b` 等模型。
### 安装
#### Docker Compose
这是一个启动 **paperless-gpt** 并与 paperless-ngx 配合使用的 `docker-compose.yml` 示例:
```
services:
paperless-ngx:
image: ghcr.io/paperless-ngx/paperless-ngx:latest
# ... (your existing paperless-ngx config)
paperless-gpt:
# Use one of these image sources:
image: icereed/paperless-gpt:latest # Docker Hub
# image: ghcr.io/icereed/paperless-gpt:latest # GitHub Container Registry
environment:
PAPERLESS_BASE_URL: "http://paperless-ngx:8000"
PAPERLESS_API_TOKEN: "your_paperless_api_token"
PAPERLESS_PUBLIC_URL: "http://paperless.mydomain.com" # Optional
MANUAL_TAG: "paperless-gpt" # Optional, default: paperless-gpt
AUTO_TAG: "paperless-gpt-auto" # Optional, default: paperless-gpt-auto
# LLM Configuration - Choose one:
# Option 1: Standard OpenAI
LLM_PROVIDER: "openai"
LLM_MODEL: "gpt-4o"
OPENAI_API_KEY: "your_openai_api_key"
# Option 2: Mistral
# LLM_PROVIDER: "mistral"
# LLM_MODEL: "mistral-large-latest"
# MISTRAL_API_KEY: "your_mistral_api_key"
# Option 3: Azure OpenAI
# LLM_PROVIDER: "openai"
# LLM_MODEL: "your-deployment-name"
# OPENAI_API_KEY: "your_azure_api_key"
# OPENAI_API_TYPE: "azure"
# OPENAI_BASE_URL: "https://your-resource.openai.azure.com"
# Option 4: Ollama (Local)
# LLM_PROVIDER: "ollama"
# LLM_MODEL: "qwen3:8b"
# OLLAMA_HOST: "http://host.docker.internal:11434"
# OLLAMA_CONTEXT_LENGTH: "8192" # Sets Ollama NumCtx (context window)
# TOKEN_LIMIT: 1000 # Recommended for smaller models
# Option 5: Anthropic/Claude
# LLM_PROVIDER: "anthropic"
# LLM_MODEL: "claude-sonnet-4-5"
# ANTHROPIC_API_KEY: "your_anthropic_api_key"
# Optional LLM Settings
# LLM_LANGUAGE: "English" # Optional, default: English
# OCR Configuration - Choose one:
# Option 1: LLM-based OCR
OCR_PROVIDER: "llm" # Default OCR provider
VISION_LLM_PROVIDER: "ollama" # openai, ollama, mistral, or anthropic
VISION_LLM_MODEL: "minicpm-v" # minicpm-v (ollama) or gpt-4o (openai) or claude-sonnet-4-5 (anthropic/claude)
OLLAMA_HOST: "http://host.docker.internal:11434" # If using Ollama
# OCR Processing Mode
OCR_PROCESS_MODE: "image" # Optional, default: image, other options: pdf, whole_pdf
PDF_SKIP_EXISTING_OCR: "false" # Optional, skip OCR for PDFs with existing OCR
# Option 2: Google Document AI
# OCR_PROVIDER: 'google_docai' # Use Google Document AI
# GOOGLE_PROJECT_ID: 'your-project' # Your GCP project ID
# GOOGLE_LOCATION: 'us' # Document AI region
# GOOGLE_PROCESSOR_ID: 'processor-id' # Your processor ID
# GOOGLE_APPLICATION_CREDENTIALS: '/app/credentials.json' # Path to service account key
# Option 3: Azure Document Intelligence
# OCR_PROVIDER: 'azure' # Use Azure Document Intelligence
# AZURE_DOCAI_ENDPOINT: 'your-endpoint' # Your Azure endpoint URL
# AZURE_DOCAI_KEY: 'your-key' # Your Azure API key
# AZURE_DOCAI_MODEL_ID: 'prebuilt-read' # Optional, defaults to prebuilt-read
# AZURE_DOCAI_TIMEOUT_SECONDS: '120' # Optional, defaults to 120 seconds
# AZURE_DOCAI_OUTPUT_CONTENT_FORMAT: 'text' # Optional, defaults to 'text', other valid option is 'markdown'
# 'markdown' requires the 'prebuilt-layout' model
# Enhanced OCR Features
CREATE_LOCAL_HOCR: "false" # Optional, save hOCR files locally
LOCAL_HOCR_PATH: "/app/hocr" # Optional, path for hOCR files
CREATE_LOCAL_PDF: "false" # Optional, save enhanced PDFs locally
LOCAL_PDF_PATH: "/app/pdf" # Optional, path for PDF files
PDF_UPLOAD: "false" # Optional, upload enhanced PDFs to paperless-ngx
PDF_REPLACE: "false" # Optional and DANGEROUS, delete original after upload
PDF_COPY_METADATA: "true" # Optional, copy metadata from original document
PDF_OCR_TAGGING: "true" # Optional, add tag to processed documents
PDF_OCR_COMPLETE_TAG: "paperless-gpt-ocr-complete" # Optional, tag name
# Option 4: Docling Server
# OCR_PROVIDER: 'docling' # Use a Docling server
# DOCLING_URL: 'http://your-docling-server:port' # URL of your Docling instance
# DOCLING_IMAGE_EXPORT_MODE: "placeholder" # Optional, defaults to "embedded"
# DOCLING_OCR_PIPELINE: "standard" # Optional, defaults to "vlm"
# DOCLING_OCR_ENGINE: "easyocr" # Optional, defaults to "easyocr" (only used when `DOCLING_OCR_PIPELINE is set to 'standard')
AUTO_OCR_TAG: "paperless-gpt-ocr-auto" # Optional, default: paperless-gpt-ocr-auto
OCR_LIMIT_PAGES: "5" # Optional, default: 5. Set to 0 for no limit.
LOG_LEVEL: "info" # Optional: debug, warn, error
volumes:
- ./prompts:/app/prompts # Mount the prompts directory
# For Google Document AI:
- ${HOME}/.config/gcloud/application_default_credentials.json:/app/credentials.json
# For local hOCR and PDF saving:
- ./hocr:/app/hocr # Only if CREATE_LOCAL_HOCR is true
- ./pdf:/app/pdf # Only if CREATE_LOCAL_PDF is true
ports:
- "8080:8080"
depends_on:
- paperless-ngx
```
**专业提示**:将占位符替换为实际值,如果出现异常,请阅读日志。
#### 手动设置
1. **克隆仓库**
git clone https://github.com/icereed/paperless-gpt.git
cd paperless-gpt
2. **创建 `prompts` 目录**
mkdir prompts
3. **构建 Docker 镜像**
docker build -t paperless-gpt .
4. **运行容器**
docker run -d \
-e PAPERLESS_BASE_URL='http://your_paperless_ngx_url' \
-e PAPERLESS_API_TOKEN='your_paperless_api_token' \
-e LLM_PROVIDER='openai' \
-e LLM_MODEL='gpt-4o' \
-e OPENAI_API_KEY='your_openai_api_key' \
-e LLM_LANGUAGE='English' \
-e VISION_LLM_PROVIDER='ollama' \
-e VISION_LLM_MODEL='minicpm-v' \
-e LOG_LEVEL='info' \
-v $(pwd)/prompts:/app/prompts \
-p 8080:8080 \
paperless-gpt
## OCR 提供商
有关特定提供商的详细文档:
- [Mistral AI 集成](docs/mistral_llm.md)
paperless-gpt 支持四种不同的 OCR 提供商,每种都有独特的优势和功能:
### 1. 基于 LLM 的 OCR(默认)
- **主要功能**:
- 使用具有视觉能力的 LLM,如 gpt-4o 或 MiniCPM-V
- 对复杂布局和难以辨认的扫描件具有高准确度
- 具有上下文感知的文本识别
- 对 OCR 错误的自我纠正能力
- **适用于**:
- 复杂或不寻常的文档布局
- 质量较差的扫描件
- 混合语言的文档
- **配置**:
OCR_PROVIDER: "llm"
VISION_LLM_PROVIDER: "openai" # 或 "ollama"
VISION_LLM_MODEL: "gpt-4o" # 或 "minicpm-v"
### 2. Azure Document Intelligence
- **主要功能**:
- 企业级 OCR 解决方案
- 针对常见文档类型的预构建模型
- 布局保留和表格检测
- 快速的处理速度
- **适用于**:
- 商业文档和表单
- 大批量处理
- 需要布局分析的文档
- **配置**:
OCR_PROVIDER: "azure"
AZURE_DOCAI_ENDPOINT: "https://your-endpoint.cognitiveservices.azure.com/"
AZURE_DOCAI_KEY: "your-key"
AZURE_DOCAI_MODEL_ID: "prebuilt-read" # 可选
AZURE_DOCAI_TIMEOUT_SECONDS: "120" # 可选
AZURE_DOCAI_OUTPUT_CONTENT_FORMAT:
"text" # 可选,默认为 text,另一个有效选项是 'markdown'
# 'markdown' 需要 'prebuilt-layout' 模型
### 3. Google Document AI
- **主要功能**:
- 企业级 OCR/HTR 解决方案
- 专门的文档处理器
- 强大的表单字段检测
- 多语言支持
- 对结构化文档具有高准确度
- **独家生成 hOCR**,用于创建带有文本层的可搜索 PDF
- **唯一支持**增强 PDF 生成功能的提供商
- **适用于**:
- 表单和结构化文档
- 带有表格的文档
- 多语言文档
- 手写文本 (HTR)
- **配置**:
OCR_PROVIDER: "google_docai"
GOOGLE_PROJECT_ID: "your-project"
GOOGLE_LOCATION: "us"
GOOGLE_PROCESSOR_ID: "processor-id"
CREATE_LOCAL_HOCR: "true" # 可选,用于生成 hOCR
LOCAL_HOCR_PATH: "/app/hocr" # 可选,默认路径
CREATE_LOCAL_PDF: "true" # 可选,用于将 OCR 应用于 PDF
LOCAL_PDF_PATH: "/app/pdf" # 可选,默认路径
### 4. Docling Server
- **主要功能**:
- 自托管的 OCR 和文档转换服务
- 支持各种输入和输出格式(包括文本)
- 利用多个 OCR 引擎(EasyOCR, Tesseract 等)
- 可以在本地或私有网络中运行
- **适用于**:
- 偏好自托管解决方案的用户
- 数据隐私至关重要的环境
- 处理各种各样的文档类型
- **配置**:
OCR_PROVIDER: "docling"
DOCLING_URL: "http://your-docling-server:port"
DOCLING_IMAGE_EXPORT_MODE: "placeholder" # 可选,默认为 "embedded"
DOCLING_OCR_PIPELINE: "standard" # 可选,默认为 "vlm"
DOCLING_OCR_ENGINE: "macocr" # 可选,默认为 "easyocr"(仅当 `DOCLING_OCR_PIPELINE 设置为 'standard' 时使用)
## OCR 处理模式
paperless-gpt 提供不同的文档处理方法,根据您的需求和 OCR 提供商的能力提供灵活性:
### 图像模式(默认)
- **工作原理**:在处理之前将 PDF 页面转换为
- **适用于**:兼容所有 OCR 提供商。
- **配置**:`OCR_PROCESS_MODE: "image"`
### PDF 模式
- **工作原理**:直接处理 PDF 页面,无需图像转换
- **适用于**:保留 PDF 功能,某些提供商可能处理速度更快且准确度更高
- **配置**:`OCR_PROCESS_MODE: "pdf"`
### 整份 PDF 模式
- **工作原理**:在单个操作中处理整个 PDF 文档
- **适用于**:能够高效处理多页文档的提供商,减少 API 调用
- **配置**:`OCR_PROCESS_MODE: "whole_pdf"`
- **注意**:处理大型 PDF 可能会导致您达到 OCR 提供商的 API 限制。如果您在使用大型文档时遇到问题,请考虑切换到 `pdf` 模式,该模式会逐页处理。
### 提供商兼容性
不同的 OCR 提供商支持不同的处理模式:
| Provider | Image Mode | PDF Mode | Whole PDF Mode |
|----------|------------|----------|----------------|
| **LLM-based OCR** (OpenAI/Ollama) | ✅ | ❌ | ❌ |
| **Azure Document Intelligence** | ✅ | ❌ | ❌ |
| **Google Document AI** | ✅ | ✅ | ✅ |
| **Mistral OCR** | ✅ | ✅ | ✅ |
| **Docling Server** | ✅ | ✅ | ✅ |
### 现有 OCR 检测
使用 PDF 或整份 PDF 模式时,您可以启用对现有 OCR 的自动检测:
```
environment:
OCR_PROCESS_MODE: "pdf" # or "whole_pdf"
PDF_SKIP_EXISTING_OCR: "true" # Skip processing if existing OCR is detected in the PDF
```
## 增强的 OCR 功能
paperless-gpt 包含强大的 OCR 增强功能,超越了基本的文本提取:
### PDF 文本层生成
- **可搜索和可选择的 PDF**:创建带有透明文本覆盖层的 PDF,精确地定位在文档中的每个单词上
- **hOCR 集成**:利用 hOCR 格式(基于 HTML 的 OCR 表示)来保持精确的文本定位
- **文档质量改进**:使文档既可搜索又可选择,同时保留原始外观
- **需要 Google Document AI**:这些功能依赖于 Google Document AI 生成具有准确单词位置的 hOCR 数据的能力
### 本地文件保存
paperless-gpt 可以在本地保存 hOCR 文件和增强的 PDF:
```
environment:
# Enable local file saving
CREATE_LOCAL_HOCR: "true" # Save hOCR files locally
CREATE_LOCAL_PDF: "true" # Save generated PDFs locally
LOCAL_HOCR_PATH: "/app/hocr" # Path to save hOCR files
LOCAL_PDF_PATH: "/app/pdf" # Path to save PDF files
volumes:
# Mount volumes to access the files from your host
- ./hocr_files:/app/hocr
- ./pdf_files:/app/pdf
```
### PDF 上传至 paperless-ngx
由于 paperless-ngx API 的限制,无法直接用 OCR 增强版本更新现有文档。作为一种变通方法,paperless-gpt 可以:
1. 将增强的 PDF 作为新文档上传
2. 将元数据从原始文档复制到新文档
3. 可选择删除原始文档
```
environment:
# PDF upload configuration
PDF_UPLOAD: "true" # Upload processed PDFs to paperless-ngx
PDF_COPY_METADATA: "true" # Copy metadata from original to new document
PDF_REPLACE: "false" # Whether to delete the original document (use with caution!)
PDF_OCR_TAGGING: "true" # Add a tag to mark documents as OCR-processed
PDF_OCR_COMPLETE_TAG: "paperless-gpt-ocr-complete" # Tag used to mark OCR-processed documents
```
### 元数据复制限制
将元数据从原始文档复制到新文档时,paperless-gpt 会尝试复制:
- 文档标题
- 标签(包括添加 OCR 完成标签)
- 通信者信息
- 创建日期
然而,由于 paperless-ngx API 的限制,某些元数据**无法**被复制:
- 文档 ID(新文档总是获得新 ID)
- 添加日期(将反映当前上传日期)
- 修改日期
- 可能由其他 paperless-ngx 插件添加的自定义字段
- 注释和标注
### 安全功能
为了防止意外创建不完整的文档,paperless-gpt 包含多项安全功能:
1. **页数检查**:如果使用 `OCR_LIMIT_PAGES` 仅处理页面子集(出于速度或资源原因),如果要处理的页数少于原始文档中的现有页数,则将完全跳过 PDF 生成。
```
environment:
OCR_LIMIT_PAGES: "5" # Limit OCR to first 5 pages, set to 0 for no limit
```
2. **OCR 完成标记**:已完全通过 OCR 处理的文档可以自动标记一个特殊标签,防止重复处理。
3. **处理跳过**:如果文档已有 OCR 完成标签,处理将自动跳过。
### 使用建议
为了获得增强 OCR 功能的最佳效果:
1. **初始测试**:从 `PDF_REPLACE: "false"` 开始,直到您确认该过程适用于您的文档。
2. **定期备份**:在启用文档替换之前,确保您已备份 paperless-ngx 数据库和文档。
3. **流程管理**:对于大型文档,请考虑使用 `OCR_LIMIT_PAGES: "0"` 以确保处理所有页面,尽管这会花费更长时间。
4. **本地副本**:启用本地文件保存(`CREATE_LOCAL_HOCR` 和 `CREATE_LOCAL_PDF`)作为额外的预防措施,保留增强文件的副本。
5. **标记策略**:使用 OCR 完成标签(`PDF_OCR_COMPLETE_TAG`)来跟踪哪些文档已经被处理。
## 配置
### 环境变量
| Variable | Description | Required | Default |
| ----------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------- | -------------------------- |
| `PAPERLESS_BASE_URL` | 您的 paperless-ngx 实例的 URL(例如 `http://paperless-ngx:8000`)。 | Yes | |
| `PAPERLESS_API_TOKEN` | paperless-ngx 的 API token。在 paperless-ngx 管理后台生成一个。 | Yes | |
| `PAPERLESS_PUBLIC_URL` | Paperless 的公共 URL(如果与 `PAPERLESS_BASE_URL` 不同)。 | No | |
| `MANUAL_TAG` | 用于手动处理的标签。 | No | paperless-gpt |
| `AUTO_TAG` | 用于自动处理的标签。 | No | paperless-gpt-auto |
| `LLM_PROVIDER` | AI 后端(`openai`, `ollama`, `googleai`, `mistral`, 或 `anthropic`)。 | Yes | |
| `LLM_MODEL` | AI 模型名称(例如 `gpt-4o`, `mistral-large-latest`, `qwen3:8b`, `claude-sonnet-4-5`)。 | Yes | |
| `OPENAI_API_KEY` | OpenAI API key(如果使用 OpenAI 则为必需)。 | Cond. | |
| `MISTRAL_API_KEY` | Mistral API key(如果使用 Mistral 则为必需)。 | Cond. | |
| `ANTHROPIC_API_KEY` | Anthropic API key(如果使用 Anthropic/Claude 则为必需)。 | Cond. | |
| `OPENAI_API_TYPE` | 设置为 `azure` 以使用 Azure OpenAI Service。 | No | |
| `OPENAI_BASE_URL` | OpenAI API 的 Base URL。对于 Azure OpenAI,设置为您的部署 URL(例如 `https://your-resource.openai.azure.com`)。 | No | |
| `LLM_LANGUAGE` | 文档的可能语言(例如 `English`)。出现在提示词中以帮助 LLM。 | No | English |
| `GOOGLEAI_API_KEY` | Google Gemini API key(如果使用 `LLM_PROVIDER=googleai` 则为必需)。 | Cond. | |
| `GOOGLEAI_THINKING_BUDGET` | (可选,仅限 googleai)整数。控制 Gemini “thinking”预算。如果未设置,则使用模型默认值(如果支持则启用 thinking)。设置为 `0` 以禁用 thinking(如果模型支持)。 | No | |
| `OLLAMA_HOST` | Ollama 服务器 URL(例如 `http://host.docker.internal:11434`)。 | No | |
| `LLM_REQUESTS_PER_MINUTE` | 主 LLM 的每分钟最大请求数。用于管理 API 成本或本地 LLM 负载。 | No | 120 |
| `LLM_MAX_RETRIES` | 失败的主 LLM 请求的最大重试次数。 | No | 3 |
| `LLM_BACKOFF_MAX_WAIT` | 主 LLM 重试之间的最大等待时间(例如 `30s`)。 | No | 30s |
| `OCR_PROVIDER` | 要使用的 OCR 提供商(`llm`, `azure`, 或 `google_docai`)。 | No | llm |
| `OCR_PROCESS_MODE` | 处理文档的方法:`image`(先转换为图像),`pdf`(直接处理 PDF 页面),或 `whole_pdf`(一次性处理整个 PDF)。 | No | image |
| `VISION_LLM_PROVIDER` | 用于 LLM OCR 的 AI 后端(`openai`, `ollama`, `mistral`, 或 `anthropic`)。如果 OCR_PROVIDER 是 `llm` 则为必需。 | Cond. | |
| `VISION_LLM_MODEL` | 用于 LLM OCR 的模型名称(例如 `minicpm-v`)。如果 OCR_PROVIDER 是 `llm` 则为必需。 | Cond. | |
| `VISION_LLM_REQUESTS_PER_MINUTE` | Vision LLM 的每分钟最大请求数。用于管理 API 成本或本地 LLM 负载。 | No | 120 |
| `VISION_LLM_MAX_RETRIES` | 失败的 Vision LLM 请求的最大重试次数。 | No | 3 |
| `VISION_LLM_BACKOFF_MAX_WAIT` | Vision LLM 重试之间的最大等待时间(例如 `30s`)。 | No | 30s |
| `VISION_LLM_MAX_TOKENS` | Vision LLM OCR 输出的最大 token 数。 | No | |
| `VISION_LLM_TEMPERATURE` | Vision OCR 生成的采样温度。越低越确定。重要:对于 OpenAI GPT-5,必须显式设置为 `1.0`。 | No | |
| `OLLAMA_CONTEXT_LENGTH` | (仅限 Ollama)整数。为 Ollama runner 设置 NumCtx(上下文窗口)。如果未设置或为 0,则使用模型默认值。 | No | |
| `OLLAMA_OCR_TOP_K` | (仅限 Ollama)用于 Vision OCR 的 Top-k token 采样。较低值倾向于更可能的 token;较高值增加多样性。 | No | |
| `AZURE_DOCAI_ENDPOINT` | Azure Document Intelligence endpoint。如果 OCR_PROVIDER 是 `azure` 则为必需。 | Cond. | |
| `AZURE_DOCAI_KEY` | Azure Document Intelligence API key。如果 OCR_PROVIDER 是 `azure` 则为必需。 | Cond. | |
| `AZURE_DOCAI_MODEL_ID` | Azure Document Intelligence model ID。如果使用 `azure` 提供商则为可选。 | No | prebuilt-read |
| `AZURE_DOCAI_TIMEOUT_SECONDS` | Azure Document Intelligence 超时(以秒为单位)。 | No | 120 |
| `AZURE_DOCAI_OUTPUT_CONTENT_FORMAT` | Azure Document Intelligence 输出内容格式。如果使用 `azure` 提供商则为可选。默认为 `text`。另一个选项是 'markdown',它需要 'prebuild-layout' 模型 ID。 | No | text |
| `GOOGLE_PROJECT_ID` | Google Cloud 项目 ID。如果 OCR_PROVIDER 是 `google_docai` 则为必需。 | Cond. | |
| `GOOGLE_LOCATION` | Google Cloud 区域(例如 `us`, `eu`)。如果 OCR_PROVIDER 是 `google_docai` 则为必需。 | Cond. | |
| `GOOGLE_PROCESSOR_ID` | Document AI processor ID。如果 OCR_PROVIDER 是 `google_docai` 则为必需。 | Cond. | |
| `GOOGLE_APPLICATION_CREDENTIALS` | 挂载的 Google 服务帐号密钥路径。如果 OCR_PROVIDER 是 `google_docai` 则为必需。 | Cond. | |
| `DOCLING_URL` | Docling 服务器实例的 URL。如果 OCR_PROVIDER 是 `docling` 则为必需。 | Cond. | |
| `DOCLING_IMAGE_EXPORT_MODE` | 图像导出模式。可选;如果未设置则默认为 `embedded`。 | No | embedded |
| `DOCLING_OCR_PIPELINE` | 设置管道类型。可选;如果未设置则默认为 `vlm`。 | No | vlm |
| `DOCLING_OCR_ENGINE` | 设置 OCR 引擎,如果 `DOCLING_OCR_PIPELINE` 设置为 `standard`。可选;默认为 `easyocr` | No | easyocr |
| `CREATE_LOCAL_HOCR` | 是否在本地保存 hOCR 文件。 | No | false |
| `LOCAL_HOCR_PATH` | 启用 hOCR 生成时保存 hOCR 文件的路径。 | No | /app/hocr |
| `CREATE_LOCAL_PDF` | 是否在本地保存增强的 PDF。 | No | false |
| `LOCAL_PDF_PATH` | 启用 PDF 生成时保存 PDF 文件的路径。 | No | /app/pdf |
| `PDF_UPLOAD` | 是否将增强的 PDF 上传到 paperless-ngx。 | No | false |
| `PDF_REPLACE` | 是否在上传增强版本后删除原始文档(危险)。 | No | false |
| `PDF_COPY_METADATA` | 是否将元数据从原始文档复制到上传的 PDF。仅在使用 PDF_UPLOAD 时适用。 | No | true |
| `PDF_OCR_TAGGING` | 是否添加标签以将文档标记为已进行 OCR 处理。 | No | true |
| `PDF_OCR_COMPLETE_TAG` | 用于将文档标记为已进行 OCR 处理的标签。 | No | paperless-gpt-ocr-complete |
| `PDF_SKIP_EXISTING_OCR` | 是否跳过对已有 OCR 的 PDF 进行 OCR 处理。与 `pdf` 和 `whole_pdf` 处理模式(`OCR_PROCESS_MODE`)配合使用。 | No | false |
| `AUTO_OCR_TAG` | 用于自动处理带有 OCR 的文档的标签。 | No | paperless-gpt-ocr-auto |
|OCR_LIMIT_PAGES` | 限制用于 OCR 的页数。设置为 `0` 表示无限制。 | No | 5 |
| `LOG_LEVEL` | 应用程序日志级别(`info`, `debug`, `warn`, `error`)。 | No | info |
| `LISTEN_INTERFACE` | 要监听的网络接口。 | No | 8080 |
| `AUTO_GENERATE_TITLE` | 如果使用 `paperless-gpt-auto`,则自动生成标题。 | No | true |
| `AUTO_GENERATE_TAGS` | 如果使用 `paperless-gpt-auto`,则自动生成标签。 | No | true |
| `AUTO_GENERATE_CORRESPONDENTS` | 如果使用 `paperless-gpt-auto`,则自动生成通信者。 | No | true |
| `AUTO_GENERATE_DOCUMENT_TYPE` | 如果使用 `paperless-gpt-auto`,则自动生成文档类型。仅使用 paperless-ngx 中现有的文档类型。 | No | true |
| `AUTO_GENERATE_CREATED_DATE` | 如果使用 `paperless-gpt-auto`,则自动生成创建日期。 | No | true |
| `TOKEN_LIMIT` | 提示词/内容允许的最大 token 数。设置为 `0` 以禁用限制。对较小的 LLM 有用。 | No | |
| `IMAGE_MAX_PIXEL_DIMENSION` | 将文档页面渲染为图像时任意边的最大像素数。 | No | 10000 |
| `IMAGE_MAX_TOTAL_PIXELS` | 将文档页面渲染为图像时的最大总像素数(宽 × 高)。 | No | 40000000 |
| `IMAGE_MAX_RENDER_DPI` | 将文档页面渲染为图像时使用的最大 DPI。 | No | 600 |
| `IMAGE_MAX_FILE_BYTES` | 渲染页面图像的最大 JPEG 文件大小(以字节为单位)。超过此大小的图像将被压缩或调整大小。 | No | 10485760 |
| `CORRESPONDENT_BLACK_LIST` | 以逗号分隔的名称列表,用于从通信者建议中排除。例如:`John Doe, Jane Smith`。 | No | |
### 自定义提示词模板
paperless-gpt 灵活的**提示词模板**让您可以塑造 AI 的响应方式。虽然您仍然可以手动管理文件,但自定义提示词的推荐方法是通过 Web UI 中的 **Settings** 页面。
应用程序使用两个目录进行管理:
- **`default_prompts/`**:包含内置的默认模板。不应修改这些模板。
- **`prompts/`**:您的工作目录。首次运行时,默认模板会被复制到这里。在 UI 中所做的所有编辑都会保存到此目录的文件中。
为了确保您的自定义提示词在容器重启后仍然存在,您必须在 `docker-compose.yml` 中将 `prompts` 目录挂载为卷:
```
volumes:
# This is crucial to save your custom prompts!
- ./prompts:/app/prompts
```
应用程序在您于 UI 中保存模板后以及启动时都会立即重新加载模板,因此无需重启即可应用更改。
#### 模板变量
每个模板都可以访问特定的变量:
**title_prompt.tmpl**:
- `{{.Language}}` - 目标语言(例如 "English")
- `{{.Content}}` - 文档内容文本
- `{{.Title}}` - 原始文档标题
**tag_prompt.tmpl**:
- `{{.Language}}` - 目标语言
- `{{.AvailableTags}}` - paperless-ngx 中现有标签的列表
- `{{.OriginalTags}}` - 文档的当前标签
- `{{.Title}}` - 文档标题
- `{{.Content}}` - 文档内容文本
**ocr_prompt.tmpl**:
- `{{.Language}}` - 目标语言
**correspondent_prompt.tmpl**:
- `{{.Language}}` - 目标语言
- `{{.AvailableCorrespondents}}` - 现有通信者列表
- `{{.BlackList}}` - 黑名单通信者名称列表
- `{{.Title}}` - 文档标题
- `{{.Content}}` - 文档内容文本
**created_date_prompt.tmpl**:
- `{{.Language}}` - 目标语言
- `{{.Content}}` - 文档内容文本
**custom_field_prompt.tmpl**:
- `{{.DocumentType}}` - 文档在 paperless-ngx 中的类型名称。
- `{{.CustomFieldsXML}}` - 列出设置中选定进行处理的的自定义字段的 XML 字符串。
- `{{.Title}}` - 文档标题
- `{{.CreatedDate}}` - 文档的创建日期
- `{{.Content}}` - 文档内容文本
模板使用 Go 的 text/template 语法。paperless-gpt 会在 UI 保存后和启动时自动重新加载模板更改。
## 基于 LLM 的 OCR:亲自对比
**为什么这很重要?**
- 传统 OCR 经常混淆来自复杂或低质量扫描件的文本。
- 大型语言模型能够解释上下文并纠正可能的错误,从而产生更精确和可读的结果。
- 您可以将这些清理后的文本集成到您的 **paperless-ngx** 流程中,以实现更好的标记、搜索和归档。
### 工作原理
- **普通 OCR** 通常使用传统方法或类似 Tesseract 的引擎来提取文本,这可能会导致复杂字体或低质量扫描件的输出混乱。
- **LLM 驱动的 OCR** 使用您选择的 AI 后端——OpenAI 或 Ollama——以更具上下文感知的方式解释图像文本。这会减少错误并产生更连贯的文本。
- **Google Document AI 和 Azure Document Intelligence** 提供具有高级布局分析的高准确度 OCR。
- **增强的 PDF 生成** 将 OCR 结果与原始文档结合,创建具有正确定位文本层的可搜索 PDF。
## 使用方法
1. **标记文档**
- 为文档添加 `paperless-gpt` 标签以进行手动处理
- 添加 `paperless-gpt-auto` 以进行自动处理
- 添加 `paperless-gpt-ocr-auto` 以进行自动 OCR 处理
2. **访问 Web UI**
- 在浏览器中访问 `http://localhost:8080`(或您的主机)
- 查看标记为处理的文档
3. **生成并应用建议**
- 点击 "Generate Suggestions" 查看 AI 提议的标题/标签/通信者
- 查看并批准或编辑建议
- 点击 "Apply" 将更改保存到 paperless-ngx
4. **OCR 处理**
- 用适当的 OCR 标签标记文档以进行处理
- 如果启用了增强 PDF 功能,文档将被相应处理:
- 对于本地文件保存,检查配置的目录以获取输出文件
- 对于 PDF 上传,新文档将出现在 paperless-ngx 中并带有复制的元数据
- 在 Web UI 中监控进度
- 查看结果并应用更改
## 故障排除
### 使用本地 LLM
使用本地 LLM(如通过 Ollama)时,您可能需要调整某些设置以优化性能:
#### Token 管理
- 使用 `TOKEN_LIMIT` 环境变量控制发送到 LLM 的最大 token 数
- 对于 Ollama,设置 `OLLAMA_CONTEXT_LENGTH` 以控制模型的上下文窗口 (NumCtx)。这独立于 `TOKEN_LIMIT`,并配置服务器端的 KV cache 大小。如果未设置或为 0,则使用模型默认值。在模型支持的窗口内选择一个值(例如 8192)。
- 如果给定过多文本,较小的模型可能会意外截断内容
- 从保守的限制开始(例如 1000 个 token),并根据模型的能力进行调整
- 设置为 `0` 以禁用限制(谨慎使用)
针对较小模型的示例配置:
```
environment:
TOKEN_LIMIT: "2000" # Adjust based on your model's context window
OLLAMA_CONTEXT_LENGTH: "4096" # Controls Ollama NumCtx (context window); if unset, model default is used
LLM_PROVIDER: "ollama"
LLM_MODEL: "qwen3:8b" # Or other local model
```
常见问题及解决方案:
- 如果您看到截断或不完整的响应,请尝试降低 `TOKEN_LIMIT`
- 在 Ollama 上,如果您遇到“context length exceeded”或内存问题,请减少 `OLLAMA_CONTEXT_LENGTH` 或选择较小的模型/上下文大小。
- 如果处理过于受限,请在监控性能的同时逐渐增加限制
- 对于具有较大上下文窗口的模型,您可以增加限制或完全禁用它
### PDF 处理问题
- 如果未生成 PDF,请检查 `OCR_LIMIT_PAGES` 设置是否与您的文档页数相比过低
- 如果使用 `CREATE_LOCAL_PDF` 或 `CREATE_LOCAL_HOCR`,请确保卷已正确挂载
- 当使用 `PDF_REPLACE: "true"` 时,请验证您是否有最近的 paperless-ngx 数据备份
### 自定义字段生成问题
- **功能不起作用**:如果即使启用了该功能也未生成自定义字段建议,请确保您在设置中至少选择了一个自定义字段。该功能需要至少选择一个字段才能知道要处理什么。
## 贡献
欢迎提交 **Pull requests** 和 **issues**!
1. Fork 本仓库
2. 创建一个分支 (`feature/my-awesome-update`)
3. 提交更改 (`git commit -m "Improve X"`)
4. 打开一个 PR
查看我们的 [贡献指南](CONTRIBUTING.md) 了解详情。
## 支持项目
如果 paperless-gpt 为您节省了时间并使您的文档管理更轻松,请考虑支持其持续开发:
- **[GitHub Sponsors](https://github.com/sponsors/icereed)**:帮助资助持续的开发和维护
- **分享**您的成功案例和用例
- 在 GitHub 上给项目加 **Star**
- **贡献**代码、文档或错误报告
您的支持有助于确保 paperless-gpt 保持积极维护并持续改进!
## 维护者说明
本项目完全开源并将保持免费使用。
它由 [Icereed](https://github.com/icereed) 维护,并部分得到我另一个项目的支持:
👉 [BubbleTax.de](https://bubbletax.de/?utm_source=github&utm_medium=footer&utm_campaign=paperless) — 为德国的 IBKR 交易者提供自动化税务报告。
如果您是也是交易者的开发者,请查看它。如果不是 – 也没关系 😊
## 许可证
paperless-gpt 根据 [MIT 许可证](LICENSE) 授权。请随意改编和分享!
## Star 历史
[](https://www.star-history.com/#icereed/paperless-gpt&Date)
## 免责声明
本项目**未**正式隶属于 [paperless-ngx][paperless-ngx]。使用风险自负。
**paperless-gpt**:您的文档管理一直在等待的 **基于 LLM** 的伴侣。享受轻松、智能的文档标题、标签和下一代 OCR。
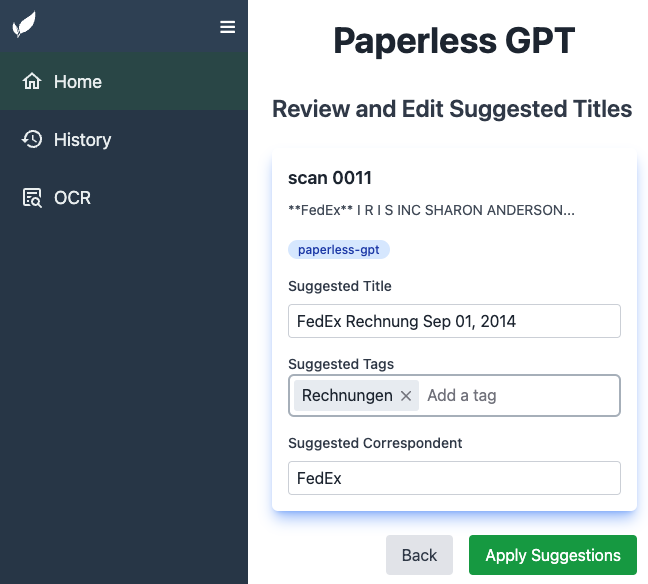
点击展开普通 OCR 与 AI 驱动的 OCR 对比
### 示例 1 **图像**:  **普通 Paperless-ngx OCR**: ``` La Grande Recre Gentre Gommercial 1'Esplanade 1349 LOLNAIN LA NEWWE TA BERBOGAAL Tel =. 010 45,96 12 Ticket 1440112 03/11/2006 a 13597: 4007176614518. DINOS. TYRAMNESA TOTAET.T.LES ReslE par Lask-Euron Rencu en Cash Euro V.14.6 -Hotgese = VALERTE TICKET A-GONGERVER PORR TONT. EEHANGE HERET ET A BIENTOT ``` **LLM 驱动的 OCR (OpenAI gpt-4o)**: ``` La Grande Récré Centre Commercial l'Esplanade 1348 LOUVAIN LA NEUVE TVA 860826401 Tel : 010 45 95 12 Ticket 14421 le 03/11/2006 à 15:27:18 4007176614518 DINOS TYRANNOSA 14.90 TOTAL T.T.C. 14.90 Réglé par Cash Euro 50.00 Rendu en Cash Euro 35.10 V.14.6 Hôtesse : VALERIE TICKET A CONSERVER POUR TOUT ECHANGE MERCI ET A BIENTOT ``` ### 示例 2 **图像**:  **普通 Paperless-ngx OCR**: ``` Invoice Number: 1-996-84199 Fed: Invoica Date: Sep01, 2014 Accaunt Number: 1334-8037-4 Page: 1012 Fod£x Tax ID 71.0427007 IRISINC SHARON ANDERSON 4731 W ATLANTIC AVE STE BI DELRAY BEACH FL 33445-3897 ’ a Invoice Questions? Bing, ‚Account Shipping Address: Contact FedEx Reı ISINC 4731 W ATLANTIC AVE Phone: (800) 622-1147 M-F 7-6 (CST) DELRAY BEACH FL 33445-3897 US Fax: (800) 548-3020 Internet: www.fedex.com Invoice Summary Sep 01, 2014 FodEx Ground Services Other Charges 11.00 Total Charges 11.00 Da £ > polo) Fz// /G TOTAL THIS INVOICE .... usps 11.00 P 2/1 f ‘The only charges accrued for this period is the Weekly Service Charge. The Fedix Ground aceounts teferencedin his involce have been transteired and assigned 10, are owned by,andare payable to FedEx Express: To onsurs propor credit, plasa raturn this portion wirh your payment 10 FodEx ‚Please do not staple or fold. Ploase make your chack payablı to FedEx. [TI For change ol address, hc har and camphat lrm or never ide Remittance Advice Your payment is due by Sep 16, 2004 Number Number Dus 1334803719968 41993200000110071 AT 01 0391292 468448196 A**aDGT IRISINC Illallun elalalssollallansdHilalellund SHARON ANDERSON 4731 W ATLANTIC AVE STEBI FedEx DELRAY BEACH FL 334453897 PO. Box 94516 PALATINE IL 60094-4515 ``` **LLM 驱动的 OCR (OpenAI gpt-4o)**: ``` FedEx. Invoice Number: 1-996-84199 Invoice Date: Sep 01, 2014 Account Number: 1334-8037-4 Page: 1 of 2 FedEx Tax ID: 71-0427007 I R I S INC SHARON ANDERSON 4731 W ATLANTIC AVE STE B1 DELRAY BEACH FL 33445-3897 Invoice Questions? Billing Account Shipping Address: Contact FedEx Revenue Services I R I S INC Phone: (800) 622-1147 M-F 7-6 (CST) 4731 W ATLANTIC AVE Fax: (800) 548-3020 DELRAY BEACH FL 33445-3897 US Internet: www.fedex.com Invoice Summary Sep 01, 2014 FedEx Ground Services Other Charges 11.00 Total Charges .......................................................... USD $ 11.00 TOTAL THIS INVOICE .............................................. USD $ 11.00 The only charges accrued for this period is the Weekly Service Charge. RECEIVED SEP _ 8 REC'D BY: _ posted 9/21/14 The FedEx Ground accounts referenced in this invoice have been transferred and assigned to, are owned by, and are payable to FedEx Express. To ensure proper credit, please return this portion with your payment to FedEx. Please do not staple or fold. Please make your check payable to FedEx. ❑ For change of address, check here and complete form on reverse side. Remittance Advice Your payment is due by Sep 16, 2004 Invoice Number 1-996-84199 Account Number 1334-8037-4 Amount Due USD $ 11.00 133480371996841993200000110071 AT 01 031292 468448196 A**3DGT I R I S INC SHARON ANDERSON 4731 W ATLANTIC AVE STE B1 DELRAY BEACH FL 33445-3897 FedEx P.O. Box 94515 ```标签:AI风险缓解, Docker, EVTX分析, GPT-4V, LLM, LLM评估, OCR, Ollama, OpenAI, Paperless-ngx, Petitpotam, RAG, Unmanaged PE, 人工智能, 光学字符识别, 内存规避, 安全防御评估, 开源, 效率工具, 文档数字化, 文档管理, 无纸化办公, 日志审计, 标题生成, 用户模式Hook绕过, 知识管理, 自动化分类, 自动标签, 计算机视觉, 请求拦截