wearetyomsmnv/Awesome-LLMSecOps
GitHub: wearetyomsmnv/Awesome-LLMSecOps
一个系统整理大语言模型安全运营(LLMSecOps)相关工具、框架、研究论文和学习资源的精选导航列表,帮助安全从业者快速掌握 LLM 攻防全景。
Stars: 145 | Forks: 54

# 🚀 Awesome LLMSecOps
[](https://awesome.re)



🔐 精选的 LLMSecOps(大语言模型安全运营)绝佳资源列表 🧠
### 由 @wearetyomsmnv 及社区成员提供
**架构风险 | 漏洞 | 工具 | 防御 | 威胁建模 | 越狱 | RAG 安全 | PoC | 学习资源 | 书籍 | 博客 | 测试数据集 | 运维安全 | 框架 | 最佳实践 | 研究 | 教程 | 公司 | 社区资源**
## 架构风险
- [OWASP Agent Memory Guard](https://github.com/OWASP/www-project-agent-memory-guard) – 用于保护 AI 代理内存免受投毒、注入和渗透攻击的官方 OWASP 安全框架。提供检测中间件、过滤钩子和审计日志,适用于 LangChain、LlamaIndex 和自定义代理 pipeline。
*LLM 系统中基本架构风险和挑战的概述。*
| 风险 | 描述 |
|------|-------------|
| 递归污染 | LLM 可能会以高置信度产生错误的输出。如果这些输出被用于训练数据,可能会导致未来的 LLM 在受污染的数据上进行训练,从而引发反馈循环问题。 |
| 数据债务 | LLM 依赖海量数据集,这些数据集通常大到无法彻底审查。这种对数据质量缺乏透明度和控制的情况构成了重大风险。 |
| 黑盒不透明性 | LLM 的许多关键组件隐藏在由基础模型提供商控制的“黑盒”中,使得用户难以有效管理和缓解风险。 |
| 提示词操纵 | 操纵输入提示词可能会导致 LLM 出现不稳定和不可预测的行为。这种风险类似于其他 ML 系统中的对抗性输入。 |
| 数据投毒 | 训练数据可能会被有意或无意地污染,从而导致模型完整性受损。鉴于 LLM 所使用数据的规模和范围,这个问题尤为棘手。 |
| 可复现性经济学 | 训练 LLM 的高昂成本限制了可复现性和独立验证,导致只能依赖商业实体和可能未经审查的模型。 |
| 模型可信度 | LLM 固有的随机性及其缺乏真正的理解能力,使其输出变得不可靠。这引发了关于它们是否应该被信任用于关键应用的疑问。 |
| 编码完整性 | 数据在处理和重新表示的过程中,往往会引入偏见和其他问题。由于 LLM 具有无监督学习的特性,这一点尤其具有挑战性。 |
**摘自 [Berryville Institute of Machine Learning (BIML)](https://berryvilleiml.com/docs/BIML-LLM24.pdf) 论文**
## 漏洞描述
#### 作者:Giskard
*LLM 应用中常见的漏洞和安全问题。*
| 漏洞 | 描述 |
|---------------|-------------|
| 幻觉与错误信息 | 这些漏洞通常表现为生成捏造的内容或传播虚假信息,这可能会产生深远的后果,例如传播误导性内容或恶意叙事。 |
| 有害内容生成 | 此漏洞涉及创建有害或恶意内容,包括暴力、仇恨言论或带有恶意意图的错误信息,对个人或社区构成威胁。 |
| 提示词注入 | 用户操纵输入提示词以绕过内容过滤器或覆盖模型指令,可能导致生成不当或有偏见的内容,从而规避既定的安全防护。 |
| 鲁棒性 | 模型输出缺乏鲁棒性,使其对微小的扰动十分敏感,导致不一致或不可预测的响应,可能会引起混淆或不良行为。 |
| 输出格式 | 当模型输出不符合指定的格式要求时,响应可能会出现结构不佳或格式错误,从而无法满足所需的输出格式。 |
| 信息泄露 | 当模型无意中泄露有关个人、组织或实体的敏感或私有数据时,就会出现此漏洞,从而构成重大的隐私风险和伦理问题。 |
| 刻板印象与歧视 | 如果模型的输出持续带有偏见、刻板印象或歧视性内容,将导致有害的社会后果,破坏促进公平、多样性和包容性的努力。 |
## LLMSecOps 生命周期
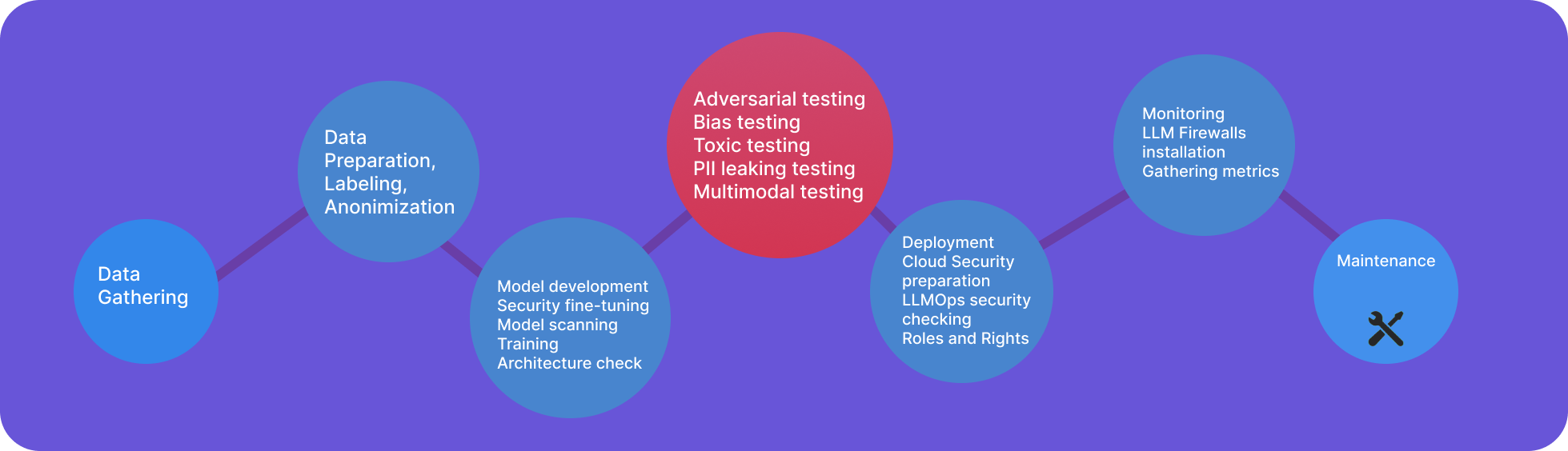
🛠 扫描工具
*用于 LLM 应用的安全扫描和漏洞评估工具。*| Tool | Description | Stars |
|---|---|---|
| 🔧 Garak | LLM vulnerability scanner |  |
| 🔧 ps-fuzz 2 | Make your GenAI Apps Safe & Secure 🚀 Test & harden your system prompt |  |
| 🗺️ LLMmap | Tool for mapping LLM vulnerabilities |  |
| 🛡️ Agentic Security | Security toolkit for AI agents |  |
| 🔒 LLM Confidentiality | Tool for ensuring confidentiality in LLMs |  |
| 🔒 PyRIT | The Python Risk Identification Tool for generative AI (PyRIT) is an open access automation framework to empower security professionals and machine learning engineers to proactively find risks in their generative AI systems. |  |
| 🔧 promptfoo | LLM red teaming and evaluation framework. Test for jailbreaks, prompt injection, and other vulnerabilities with adversarial attacks (PAIR, tree-of-attacks, crescendo). CI/CD integration. |  |
| 🔧 LLaMator | Framework for testing vulnerabilities of large language models with support for Russian language |  |
| 🔧 Spikee | ||
| 🔧 Prefactor | AI agent runtime control plane with observability, governance, and security features for regulated industries |  | Comprehensive testing framework for LLM applications. Tests prompt injection, jailbreaks, and other vulnerabilities. Supports custom targets, attacks, judges, and guardrail evaluation |  |
| 🛡️ LocalMod | Self-hosted content moderation API with prompt injection detection, toxicity filtering, PII detection, and NSFW filtering. Runs 100% offline. |  |
| 🔐 Black Vault | Open-source proxy gateway for AI API keys with AES-256-GCM encryption and instant kill switches. Protects against credential theft in agentic workflows. |  |
🛡️防御
*用于保护 LLM 应用的防御机制、安全护栏和安全控制措施。*
## 安全设计
| 类别 | 方法 / 技术 | 运行原理(机制) | 使用示例 / 开发者 |
|----------|---------------------|-----------------------------------|------------------------------|
| **1. 基础对齐** | **RLHF (基于人类反馈的强化学习)** | 基于人类评估训练的奖励模型,使用强化学习训练模型。它针对“有用性”和“安全性”进行优化。 | OpenAI (GPT-4), Yandex (YandexGPT) |
| | **DPO (直接偏好优化)** | 基于偏好对直接优化响应概率,绕过创建单独奖励模型的过程。被描述为更稳定和有效。 | Meta (Llama 3), Mistral, 开源模型 |
| | **Constitutional AI / RLAIF** | 使用模型本身根据一套规则(“宪法”)来批评和纠正其响应。AI 取代了人类标注 (RLAIF)。 | Anthropic (Claude 3) |
| **2. 内部控制(可解释性)** | **表示工程** | 实时检测和抑制负责不良概念(例如,虚假、权力欲)的神经元激活向量。 | Center for AI Safety (CAIS) |
| | **断路器** | 将恶意查询的内部表示重定向(“短路”)到正交空间,导致失败或输出无意义内容。 | GraySwan AI, 研究人员 |
| | **机器遗忘** | 通过算法从模型权重中“擦除”危险知识或受保护的数据(例如,通过梯度上升),使模型在物理上“忘记”它们。 | 研究小组, Microsoft |
| **3. 外部过滤器(护栏)** | **Llama Guard** | 专门的 LLM 分类器,用于检查传入的提示词和传出的响应是否符合风险分类法。 | Meta |
| | **NeMo Guardrails** | 可编程的对话管理系统。它使用 Colang 语言来严格遵守主题并阻止攻击。 | NVIDIA |
| | **Prompt Guard / Shields** | 用于在越狱和提示词注入到达 LLM 之前检测它们的轻量级模型(基于 BERT/DeBERTA)。 | Meta, Azure AI |
| | **[Omega Walls (Ω)](https://github.com/synqratech/omega-walls)** | 用于 RAG/代理的确定性运行时信任边界:将不受信任的内容投射到墙体压力中,累积会话疤痕质量,触发可审计的关闭;实现文档阻止 + 工具冻结。 | SynqraTech (OSS) |
| | **SmoothLLM** | 随机平滑方法:创建带有符号扰动的提示词副本,以破坏对抗性攻击的结构(例如,GCG 后缀)。 | 研究人员 (SmoothLLM 作者) |
| | **Google 安全过滤器** | 具有可自定义灵敏度阈值和语义向量分析的多级内容过滤。 | Google (Gemini API) |
| **4. 系统指令** | **系统提示词 / 标签** | 使用特殊令牌(例如,``)来分离系统和用户指令。 | OpenAI, Meta, Anthropic |
| | **指令层级** | 将系统指令优先于用户指令,以防止提示词注入,尤其是当模型学会忽略“忘记过去的指令”命令时。 | OpenAI (GPT-4o Mini) |
| **5. 测试(红队)** | **自动化攻击 (GCG, AutoDAN)** | 使用算法和其他 LLM 生成数十万个对抗性提示词以查找漏洞。 | 研究小组 |
| Tool | Description | Stars |
|---|---|---|
| 🛡️ ai-injection-guard | Regex-based prompt injection detector + output scanner (secrets, PII, system prompt leakage). 75 patterns, zero dependencies, <1ms. |  |
| 🛡️ PurpleLlama | Set of tools to assess and improve LLM security. |  |
| 🛡️ Rebuff | API with built-in rules for identifying prompt injection and detecting data leakage through canary words. (ProtectAI is now part of Palo Alto Networks) |  |
| 🔒 LLM Guard | Self-hostable tool with multiple prompt and output scanners for various security issues. |  |
| 🚧 NeMo Guardrails | Tool that protects against jailbreak and hallucinations with customizable rulesets. |  |
| 👁️ Vigil | Offers dockerized and local setup options, using proprietary HuggingFace datasets for security detection. |  |
| 🧰 LangKit | Provides functions for jailbreak detection, prompt injection, and sensitive information detection. |  |
| 🛠️ GuardRails AI | Focuses on functionality, detects presence of secrets in responses. |  |
| 🦸 Hyperion Alpha | Detects prompt injections and jailbreaks. | N/A |
| 🛡️ LLM-Guard | Tool for securing LLM interactions. (ProtectAI is now part of Palo Alto Networks) |  |
| 🚨 Whistleblower | Tool for detecting and preventing LLM vulnerabilities. |  |
| 🔍 Plexiglass | Security tool for LLM applications. |  |
| 🛡️ Omega Walls | Deterministic Ω trust boundary for RAG/agents: wall-pressures + accumulation (scar-mass) + auditable Off; supports doc soft-block + tool-freeze. |  |
| 🔍 Prompt Injection defenses | Rules for protected LLM |  |
| 🔍 LLM Data Protector | Tools for protected LLM in chatbots | N/A |
| 🔍 Gen AI & LLM Security for developers: Prompt attack mitigations on Gemini | Security tool for LLM applications. |  |
| 🔍 TrustGate | Generative Application Firewall that detects and blocks attacks against GenAI Applications. |  |
| 🛡️ Tenuo | Capability tokens for AI agents with task-scoped TTLs, offline verification and proof-of-possession binding. | ) |
| 🛡️ AIDEFEND | Practical knowledge base for AI security defenses. Based on MAESTRO framework, MITRE D3FEND, ATLAS, ATT&CK, Google Secure AI Framework, and OWASP Top 10 LLM 2025/ML Security 2023. | N/A |
| 🛡️ semantix-ai | Deterministic semantic validation of LLM outputs via local quantized NLI. Catches policy violations and negated intents ("must NOT give medical advice"), emits hash-chained JSON-LD audit certificates. ~15 ms/call, no API keys. |  |
| 🛡️ TealTiger | Deterministic runtime governance for AI agents. 7 parallel modules (secrets, registry, reliability, memory, audit, dashboard, evidence). 500+ secret patterns, tool allowlisting, SARIF export, Docker sidecar. No LLM in the decision path. |  |
## 威胁建模
*用于识别和建模 LLM 系统中威胁的框架和方法论。*
| 工具 | 描述 |
|------|-------------|
| [安全的 LLM 部署:应对和缓解安全风险](https://arxiv.org/pdf/2406.11007) | 关于 LLM 安全的研究论文 [抱歉,但这确实很酷] |
| [ThreatModels](https://github.com/jsotiro/ThreatModels/tree/main) | LLM 威胁模型代码库 |
| [LLM 威胁建模](https://aivillage.org/large%20language%20models/threat-modeling-llm/) | AI Village 提供的关于 LLM 威胁建模的资源 |
| [Sberbank AI 网络安全威胁模型](https://www.sberbank.ru/ru/person/kibrary/experts/model-ugroz-kiberbezopasnosti-ai) | Sberbank 针对网络安全的 AI 威胁模型 |
| [Pangea 攻击分类法](https://pangea.cloud/resources/taxonomy/) | 全面的 AI/LLM 攻击和漏洞分类法 | Pangea |
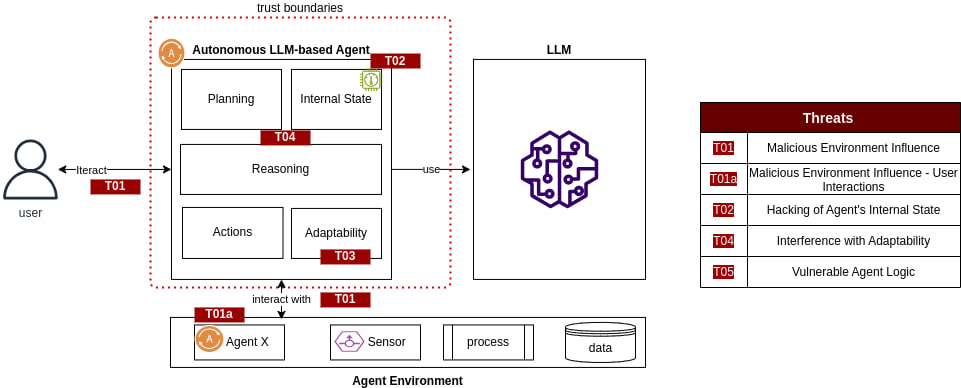
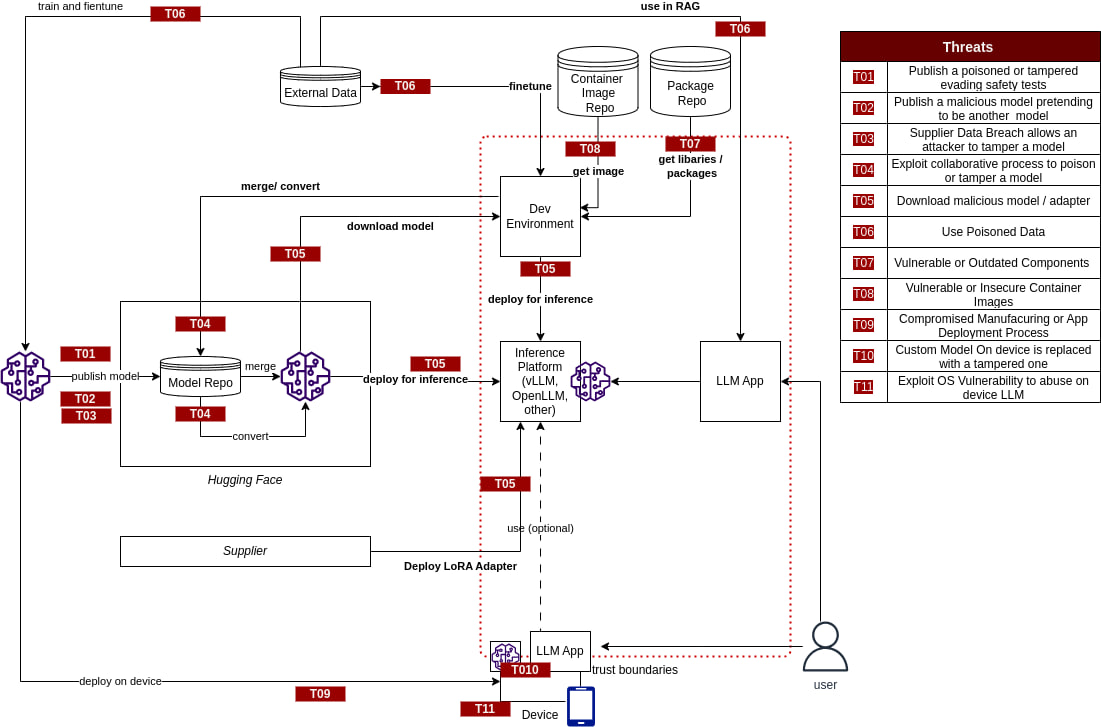
## 监控
*用于监控 LLM 应用、检测异常和跟踪安全事件的工具和平台。*
| 工具 | 描述 |
|------|-------------|
|[Langfuse](https://langfuse.com/) | 具备安全能力的开源 LLM 工程平台。 |
|[Opik](https://github.com/comet-ml/opik) | 用于 LLM 可观察性、评估和提示词优化的开源平台。 |
|[HiveTrace](https://hivetrace.ru/preview/) | 用于 GenAI 应用的 LLM 监控和安全平台。检测提示词注入、越狱、恶意 HTML/Markdown 元素以及 PII。提供实时异常检测和安全警报。 |
## 水印
*用于对 LLM 生成的内容加水印以检测 AI 生成文本的工具和技术。*
| 工具 | 描述 |
|------|-------------|
| [MarkLLM](https://github.com/THU-BPM/MarkLLM) | 用于 LLM 水印的开源工具包。 |
## 越狱
*用于理解和测试针对 LLM 的越狱技术的资源、数据库和基准。*
| 资源 | 描述 | 星标数 |
|----------|-------------|-------|
| [JailbreakBench](https://jailbreakbench.github.io/) | 专门用于评估和分析语言模型越狱方法的网站 | N/A |
| [L1B3RT45](https://github.com/elder-plinius/L1B3RT45/) | 包含与 AI 越狱相关的信息和工具的 GitHub 代码库 |  |
| [llm-hacking-database](https://github.com/pdparchitect/llm-hacking-database)| 此代码库包含针对大语言模型的各种攻击 |  |
| [HaizeLabs 越狱数据库](https://launch.haizelabs.com/)| 该数据库包含针对多模态语言模型的越狱方法 | N/A |
| [Lakera PINT 基准](https://github.com/lakeraai/pint-benchmark) | 用于提示词注入检测系统的综合基准。跨多个类别(提示词注入、越狱、强负样本、聊天、文档)评估检测系统,并支持 20 多种语言的评估。带有用于自定义评估的 Jupyter notebook 的开源基准。 |  |
| [EasyJailbreak](https://github.com/EasyJailbreak/EasyJailbreak) | 一个用于生成对抗性越狱提示词的易用 Python 框架 |  |
## LLM 可解释性
*用于理解和解释 LLM 行为、决策制定和内部机制的资源。*
| 资源 | 描述 |
|----------|-------------|
| [Интерпретируемость LLM](https://kolodezev.ru/interpretable_llm.html)| Dmitry Kolodezev 的网页,提供了有关 LLM 解释技术的实用资源 |
## PINT 基准分数 (由 lakera 提供*提示词注入测试 (PINT) 基准分数,用于比较不同的提示词注入检测系统。*
| 名称 | PINT 分数 | 测试日期 |
| ---- | ---------- | --------- |
| [Lakera Guard](https://lakera.ai/) | 95.2200% | 2025-05-02 |
| [Azure AI Prompt Shield for Documents](https://learn.microsoft.com/en-us/azure/ai-services/content-safety/concepts/jailbreak-detection#prompt-shields-for-documents) | 89.1241% | 2025-05-02 |
| [protectai/deberta-v3-base-prompt-injection-v2](https://huggingface.co/protectai/deberta-v3-base-prompt-injection-v2) | 79.1366% | 2025-05-02 |
| [Llama Prompt Guard 2 (86M)](https://huggingface.co/meta-llama/Llama-Prompt-Guard-2-86M) | 78.7578% | 2025-05-05 |
| [Google Model Armor](https://cloud.google.com/security-command-center/docs/model-armor-overview) | 70.0664% | 2025-08-27 |
| [Aporia Guardrails](https://www.aporia.com/) | 66.4373% | 2025-05-02 |
| [Llama Prompt Guard](https://huggingface.co/meta-llama/Prompt-Guard-86M) | 61.8168% | 2025-05-02 |
# 幻觉排行榜
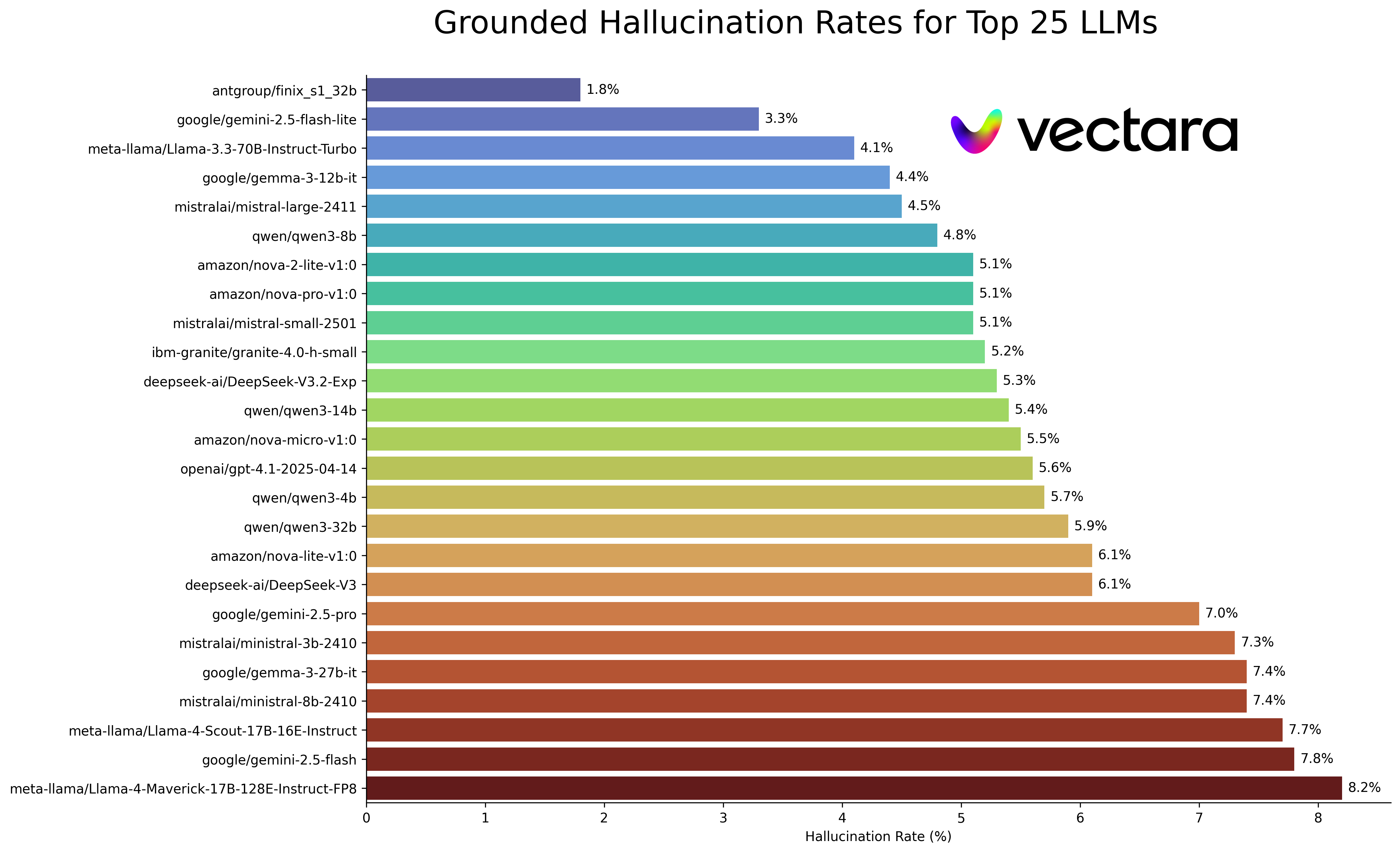
**来自[此](https://github.com/vectara/hallucination-leaderboard)代码库 (最后更新:2025 年 12 月 18 日)**
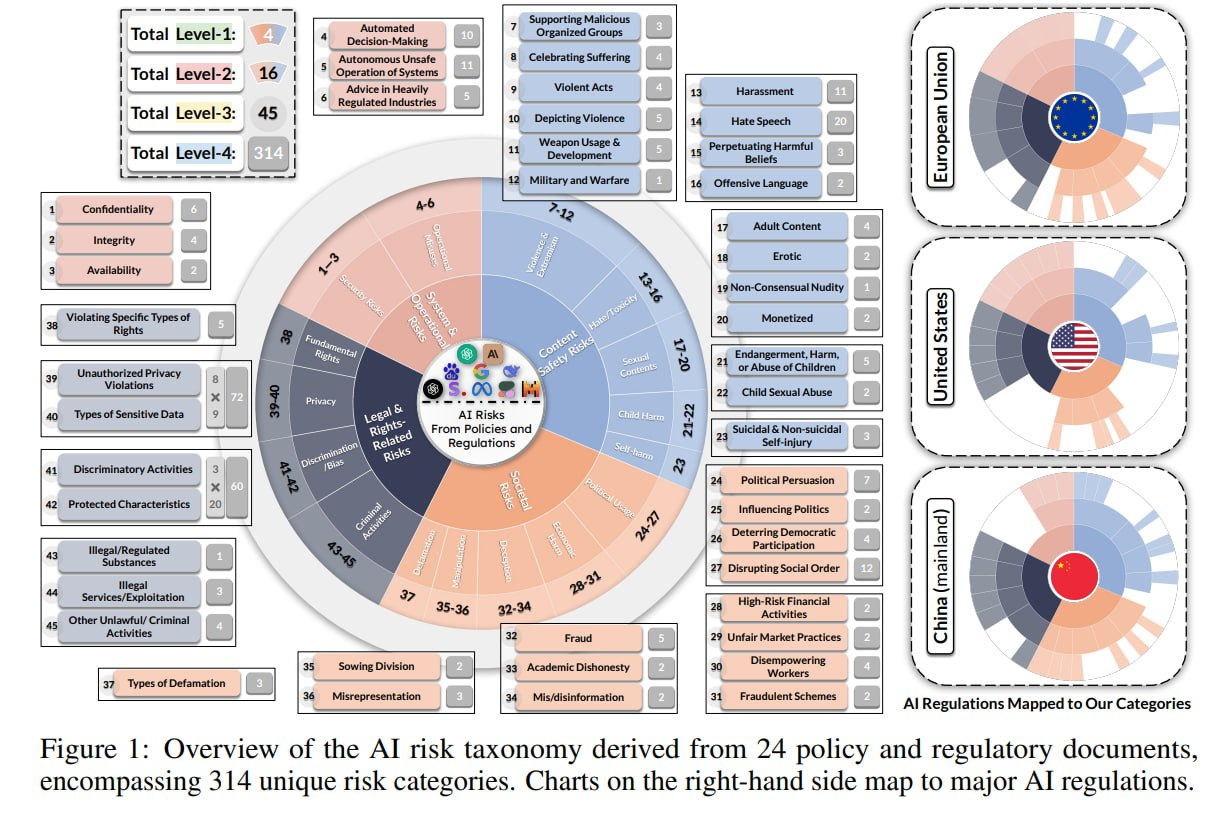
**这是来自 [Stanford University](https://crfm.stanford.edu/helm/air-bench/latest/) 的安全基准**
## RAG 安全 *检索增强生成 (RAG) 系统的安全注意事项、攻击和防御。* | 资源 | 描述 | |----------|-------------| | [RAG 中的安全风险](https://ironcorelabs.com/security-risks-rag/) | 关于检索增强生成 (RAG) 中安全风险的文章 | | [RAG 投毒如何让 LLaMA3 变得具有种族歧视](https://medium.com/m/global-identity-2?redirectUrl=https%3A%2F%2Fblog.repello.ai%2Fhow-rag-poisoning-made-llama3-racist-1c5e390dd564) | 关于 RAG 投毒及其对 LLaMA3 影响的博客文章 | | [对抗性 AI - RAG 攻击与缓解](https://github.com/wearetyomsmnv/Adversarial-AI---Attacks-Mitigations-and-Defense-Strategies/tree/main/ch15/RAG) | 关于 RAG 攻击、缓解和防御策略的 GitHub 代码库 | | [PoisonedRAG](https://github.com/sleeepeer/PoisonedRAG) | 关于被投毒的 RAG 系统的 GitHub 代码库 | | [ConfusedPilot: 危及 Microsoft 365 Copilot 的企业信息完整性和机密性](https://arxiv.org/html/2408.04870v1) | 关于 RAG 漏洞的文章 | | [LLM 的绝妙越狱 - RAG 攻击](https://github.com/yueliu1999/Awesome-Jailbreak-on-LLMs?tab=readme-ov-file#attack-on-rag-based-llm) | 基于 RAG 的 LLM 攻击技术合集 | 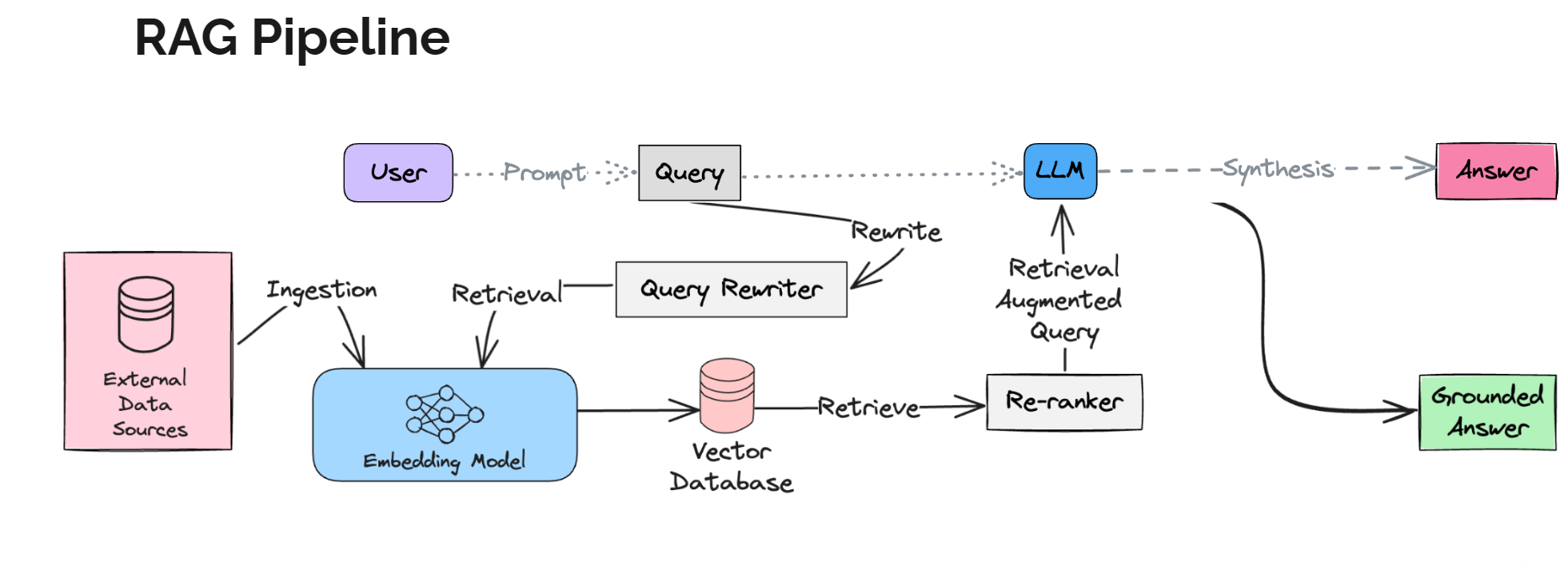 ## 代理安全 *专注于自主 AI 代理及其漏洞的安全工具、基准和研究。* | 工具 | 描述 | 星标数 | |------|-------------|-------| | [invariant](https://github.com/invariantlabs-ai/invariant) | 用于 AI 代理的 trace 分析工具。 |  | | [AgentBench](https://github.com/THUDM/AgentBench) | 用于评估 LLM 作为代理的综合基准 (ICLR'24) |  | | [代理劫持,提示词注入的真实影响](https://dev.to/snyk/agent-hijacking-the-true-impact-of-prompt-injection-attacks-983) | 攻击 langchain 代理的指南 | 文章 | | [破坏代理:通过故障放大危及自主 LLM 代理](https://arxiv.org/pdf/2407.20859v1) | 关于典型代理漏洞的研究 | 文章 | | [初探模型上下文协议 (MCP):研究 MCP 服务器的安全性与可维护性](https://arxiv.org/html/2506.13538v2) | 首个针对 MCP 服务器安全性和可维护性的大规模实证研究 | 文章 | | [Awesome MCP 安全](https://github.com/Puliczek/awesome-mcp-security) | MCP 安全资源精选列表 |  | | [Awesome LLM 代理安全](https://github.com/wearetyomsmnv/Awesome-LLM-agent-Security) | LLM 代理安全资源、攻击、漏洞的全面合集 |  | | [MCP 安全分析](https://arxiv.org/pdf/2511.03841) | 关于 MCP 漏洞和分析的研究论文 | 文章 | | [Tenuo](https://github.com/tenuo-ai/tenuo) | 用于 AI 代理的基于能力的授权框架。带有密码衰减、PoP 绑定和离线验证的任务范围授权。支持 LangChain/LangGraph/MCP 集成。 |  | | [APort](https://aport.io) | 用于 LLM 工具调用的代理身份验证和策略执行,在代理执行敏感操作之前添加行动前授权护栏。 | 网站 | | [AgentLeak](https://github.com/Privatris/AgentLeak) | 用于多代理系统中隐私泄露的全栈基准。监控 7 个通道,包括工具调用、RAG 查询和代理间消息。 |  | | [Agent-Wiz](https://github.com/Repello-AI/Agent-Wiz) | Repello AI 的 CLI,用于从 LangChain/LangGraph/CrewAI/AutoGen 中提取代理工作流并运行自动威胁建模。 |  | | [TealTiger](https://github.com/agentguard-ai/tealtiger) | 用于 AI 代理的确定性治理引擎——策略执行、工具白名单、内存治理、成本跟踪和结构化审计证据 (SARIF, JUnit XML, JSON)。适用于任何语言的 Docker sidecar。 |  | ## 代理浏览器安全 *关于 AI 驱动的浏览器代理及其独特攻击向量的安全研究和分析。* | 资源 | 描述 | 来源 | |----------|-------------|--------| | [从收件箱到数据消除:Perplexity Comet 的 AI 浏览器悄悄清除 Google Drive 数据](https://www.straiker.ai/blog/from-inbox-to-wipeout-perplexity-comets-ai-browser-quietly-erasing-google-drive) | 关于通过 Perplexity Comet 发起的零点击 Google Drive 数据清除攻击的研究。展示了礼貌、结构良好的电子邮件如何在代理浏览器中触发破坏性操作。 | Straiker STAR Labs | | [代理浏览器安全分析](https://arxiv.org/html/2506.07153v2) | 关于代理浏览器中安全漏洞的研究论文 | 文章 | | [浏览器 AI 代理:新的最薄弱环节](https://labs.sqrx.com/browser-ai-agents-the-new-weakest-link-22a38a552d7f) | 对基于浏览器的 AI 代理安全风险的分析 | Sqrx Labs | | [Comet 提示词注入漏洞](https://brave.com/blog/comet-prompt-injection/) | Brave 对 Perplexity Comet 浏览器中提示词注入漏洞的分析 | Brave | ## PoC *演示各种 LLM 攻击、漏洞和安全研究的概念验证实现。* | 工具 | 描述 | 星标数 | |------|-------------|-------| | [视觉对抗样本](https://github.com/Unispac/Visual-Adversarial-Examples-Jailbreak-Large-Language-Models) | 使用视觉对抗样本对大语言模型进行越狱 |  | | [弱到强泛化](https://github.com/XuandongZhao/weak-to-strong) | 弱到强泛化:在弱监督下激发强能力 |  | | [图像劫持](https://github.com/euanong/image-hijacks) | 用于基于图像的大语言模型劫持的代码库 |  | | [CipherChat](https://github.com/RobustNLP/CipherChat) | 用于大语言模型的安全通信工具 |  | | [LLMs 微调安全](https://github.com/LLM-Tuning-Safety/LLMs-Finetuning-Safety) | 用于微调大语言模型的安全措施 |  | | [虚拟提示词注入](https://github.com/wegodev2/virtual-prompt-injection) | 用于语言模型中虚拟提示词注入的工具 |  | | [FigStep](https://github.com/ThuCCSLab/FigStep) | 通过排版视觉提示对大型视觉语言模型进行越狱 |  | | [stealing-part-lm-supplementary](https://github.com/dpaleka/stealing-part-lm-supplementary) | “窃取生产语言模型的一部分”的部分代码 |  | | [幻觉攻击](https://github.com/PKU-YuanGroup/Hallucination-Attack) | 诱导 LLM 陷入幻觉的攻击 |  | | [llm-hallucination-survey](https://github.com/HillZhang1999/llm-hallucination-survey) | LLM 幻觉的阅读清单。请查看我们的新调查论文:“Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models” |  | | [LMSanitator](https://github.com/meng-wenlong/LMSanitator) | LMSanitator:防御针对 LLM 的隐蔽提示词注入攻击 |  | | [Imperio](https://github.com/HKU-TASR/Imperio) | Imperio:用于锚定大语言模型的鲁棒提示词工程 |  | | [针对微调 LLaMA 的后门攻击](https://github.com/naimul011/backdoor_attacks_on_fine-tuned_llama) | 针对微调 LLaMA 模型的后门攻击 |  | | [CBA](https://github.com/MiracleHH/CBA) | 基于意识的 LLM 安全认证 |  | | [MuScleLoRA](https://github.com/ZrW00/MuScleLoRA) | 用于 LLM 多场景后门微调的框架 |  | | [BadActs](https://github.com/clearloveclearlove/BadActs) | BadActs:通过激活引导对大语言模型进行后门攻击 |  | | [TrojText](https://github.com/UCF-ML-Research/TrojText) | 针对文本分类器的木马攻击 |  | | [AnyDoor](https://github.com/sail-sg/AnyDoor) | 在语言模型中创建任意后门实例 |  | | [PromptWare](https://github.com/StavC/PromptWares) | 被越狱的 GenAI 模型可能造成真正的伤害:由 GenAI 驱动的应用程序容易受到 PromptWares 的攻击 |  | | [BrokenHill](https://github.com/BishopFox/BrokenHill) | 自动化攻击工具,使用贪婪坐标梯度 (GCG) 攻击生成精心设计的提示词以绕过 LLM 中的限制 |  | | [OWASP 代理 AI](_URL_72/>) | OWASP 代理 AI (AI 代理安全) Top 10 - 预发布版本 |  |
## 学习资源 *用于学习 LLM 安全的教育平台、CTF 挑战、课程和培训资源。* | 工具 | 描述 | |------|-------------| | [Gandalf](https://gandalf.lakera.ai/) | 交互式 LLM 安全挑战游戏 | | [Prompt Airlines](https://promptairlines.com/) | 用于学习和练习提示词工程的平台 | | [PortSwigger LLM 攻击](https://portswigger.net/web-security/llm-attacks/) | 关于 WEB LLM 安全漏洞和攻击的教育资源 | | [Invariant Labs CTF 2024](https://invariantlabs.ai/play-ctf-challenge-24) | CTF。你需要黑客攻击 LLM 代理 | | [Invariant Labs CTF Summer 24](https://huggingface.co/spaces/invariantlabs/ctf-summer-24/tree/main) | 带有 CTF 挑战的 Hugging Face Space | | [Crucible](https://crucible.dreadnode.io/) | LLM 安全培训平台 | | [Poll Vault CTF](http://poll-vault.chal.hackthe.vote/) | 包含 ML/LLM 组件的 CTF 挑战 | | [MyLLMDoc](https://myllmdoc.com/) | LLM 安全培训平台 | | [AI CTF PHDFest2 2025](https://aictf.phdays.fun/) | 来自 PHDFest2 2025 的 AI CTF 竞赛 | | [安全中的 AI](https://aiinsec.ru/) | 俄罗斯 AI 安全培训平台 | | [DeepLearning.AI 红队课程](https://www.deeplearning.ai/short-courses/red-teaming-llm-applications/) | 关于 LLM 应用红队的短期课程 | | [学习提示词:攻击措施](https://learnprompting.org/docs/prompt_hacking/offensive_measures/) | 关于攻击性提示词工程技术的指南 | | [应用安全 LLM 测试](https://application.security/free/llm) | 免费的 LLM 安全测试 | | [Salt Security 博客:ChatGPT 扩展漏洞](https://salt.security/blog/security-flaws-within-chatgpt-extensions-allowed-access-to-accounts-on-third-party-websites-and-sensitive-data) | 关于 ChatGPT 浏览器扩展中安全缺陷的文章 | | [safeguarding-llms](https://github.com/sshkhr/safeguarding-llms) | TMLS 2024 研讨会:保护 LLM 应用的实践者指南 | | [Damn Vulnerable LLM Agent](https://github.com/WithSecureLabs/damn-vulnerable-llm-agent) | 专用于安全测试和教育的故意存在漏洞的 LLM 代理 | | [GPT 代理竞技场](https://gpa.43z.one/) | 用于在各种场景中测试和评估 LLM 代理的平台 | | [AI Battle](https://play.secdim.com/game/ai-battle) | 专注于 AI 安全挑战的交互式游戏 | | [AI/LLM 漏洞利用挑战](https://academy.8ksec.io/course/ai-exploitation-challenges) | 测试你在 AI、ML 和 LLM 知识方面的挑战 | | [TryHackMe AI/ML 安全威胁](https://medium.com/genai-llm-security/tryhackme-ai-ml-security-threats-walkthrough-writeup-04abd3f717ca) | TryHackMe AI/ML 安全威胁机房的演练和题解 | 文章 | | [PromptTrace](https://prompttrace.airedlab.com) | 免费实用的 AI 安全培训平台。针对真实的 LLM 练习提示词注入、RAG 投毒和工具利用,并提供完整的提示词堆栈可见性。10 个实验 + 15 级 CTF (The Gauntlet) + 9 个与 OWASP LLM Top 10 对齐的学习模块。 |  ## 📊 社区研究文章 *来自安全社区的研究文章、安全公告和技术论文。* | 标题 | 作者 | 年份 | |-------|---------|------| | [📄 绕过 Meta 的 LLaMA 分类器:一次简单的越狱](https://www.robustintelligence.com/blog-posts/bypassing-metas-llama-classifier-a-simple-jailbreak) | Robust Intelligence | 2024 | | [📄 LangChain Gen AI 中的漏洞](https://unit42.paloaltonetworks.com/langchain-vulnerabilities/) | Unit42 | 2024 | | [📄 检测提示词注入:基于 BERT 的分类器](https://labs.withsecure.com/publications/detecting-prompt-injection-bert-based-classifier) | WithSecure Labs | 2024 | | [📄 实用的 LLM 安全:深耕一年的经验教训](http://i.blackhat.com/BH-US-24/Presentations/US24-Harang-Practical-LLM-Security-Takeaways-From-Wednesday.pdf?_gl=1*1rlcqet*_gcl_au*MjA4NjQ5NzM4LjE3MjA2MjA5MTI.*_ga*OTQ0NTQ2MTI5LjE3MjA2MjA5MTM.*_ga_K4JK67TFYV*MTcyMzQwNTIwMS44LjEuMTcyMzQwNTI2My4wLjAuMA..&_ga=2.168394339.31932933.1723405201-944546129.1720620913) | NVIDIA | 2024 | | [📄 xAI 的 Grok 中的安全 ProbLLMs](https://embracethered.com/blog/posts/2024/security-probllms-in-xai-grok/) | Embrace The Red | 2024 | | [📄 LLM 的持续预训练投毒](https://spylab.ai/blog/poisoning-pretraining/) | SpyLab AI | 2024 | | [📄 应对风险:LLM 代理中安全、隐私和伦理威胁的调查](https://arxiv.org/pdf/2411.09523) | 多位作者 | 2024 | | [📄 实用 AI 代理安全](https://ai.meta.com/blog/practical-ai-agent-security/) | Meta | 2025 | | [📄 安全公告:Anthropic 的 Slack MCP 服务器容易受到数据渗透攻击](https://embracethered.com/blog/posts/2025/security-advisory-anthropic-slack-mcp-server-data-leakage/) | Embrace The Red | 2025 | ## 🎓 教程 *用于理解和实施 LLM 安全实践的循序渐进指南和教程。* | 资源 | 描述 | |----------|-------------| | [📚 HADESS - Web LLM 攻击](https://hadess.io/web-llm-attacks/) | 了解如何利用 LLM 实施 Web 攻击 | | [📚 使用 LLM 进行红队演练](https://redteamrecipe.com/red-teaming-with-llms) | 攻击 AI 系统的实用方法 | | [📚 Lakera LLM 安全](https://www.lakera.ai/blog/llm-security) | 关于 LLM 攻击的概述 |
## 📚 书籍
*涵盖 LLM 安全、对抗性 AI 和安全 AI 开发实践的综合书籍。*
| 📖 标题 | 🖋️ 作者 | 🔍 描述 |
|----------|--------------|----------------|
| [大语言模型安全开发者手册](https://www.amazon.com/Developers-Playbook-Large-Language-Security/dp/109816220X) | Steve Wilson | 🛡️ 面向开发者的 LLM 安全综合指南 |
| [生成式 AI 安全:理论与实践 (商业与金融的未来)](https://www.amazon.com/Generative-AI-Security-Theories-Practices/dp/3031542517) | Ken Huang, Yang Wang, Ben Goertzel, Yale Li, Sean Wright, Jyoti Ponnapalli | 🔬 深入探讨生成式 AI 中的安全理论、法律、术语和实践 |
|[对抗性 AI 攻击、缓解和防御策略:网络安全专业人员关于 AI 攻击、威胁建模和使用 MLSecOps 保护 AI 的指南](https://www.packtpub.com/en-ru/product/adversarial-ai-attacks-mitigations-and-defense-strategies-9781835087985)|John Sotiropoulos| 为您的最佳 MLSecOps pipeline 提供实用的代码示例|
## 博客
*专注于 AI/LLM 安全的安全博客、Twitter 动态和 Telegram 频道。*
### 网站与 Twitter
| 资源 | 描述 |
|----------|-------------|
| [Embrace The Red](https://embracethered.com/blog/) | 关于 AI 安全、红队和 LLM 漏洞的博客 |
| [HiddenLayer](https://hiddenlayer.com/) | AI 安全公司博客 |
| [CyberArk](https://www.cyberark.com/blog) | 关于 AI 代理、身份风险和安全的博客 |
| [Straiker](https://www.straiker.ai/blog) | AI 安全研究和代理浏览器安全 |
| [Firetail](https://www.firetail.ai/blog) | LLM 安全、提示词注入和 AI 漏洞 |
| [Palo Alto Networks](https://www.paloaltonetworks.com/blog) | Unit 42 关于 AI 安全和代理 AI 攻击的研究 |
| [Trail of Bits](https://blog.trailofbits.com) | 包括 AI/ML pickle 文件安全在内的安全研究 |
| [NCSC](https://www.ncsc.gov.uk/blog) | 英国国家网络安全中心关于 AI 安全防护的博客 |
| [Knostic](https://www.knostic.ai/blog) | AI 安全态势管理 (AISPM) |
| [0din](https://0din.ai/blog) | 安全的 LLM 和 RAG 部署实践 |
| [@llm_sec](https://twitter.com/llm_sec) | 关于 LLM 安全的 Twitter 动态 |
| [@LLM_Top10](https://twitter.com/LLM_Top10) | 关于 OWASP LLM Top 10 的 Twitter 动态 |
| [@aivillage_dc](https://twitter.com/aivillage_dc) | AI Village Twitter |
| [@elder_plinius](https://twitter.com/elder_plinius/) | 关于 AI 安全的 Twitter 动态 |
### Telegram 频道
| 频道 | 语言 | 描述 |
|---------|----------|-------------|
| [PWN AI](https://t.me/pwnai) | RU | 实用 AI 安全与 MLSecOps:LLM 安全、代理、护栏、真实威胁 |
| [Борись с ml](https://t.me/borismlsec) | RU | 机器学习 + 信息安全:ML、数据科学和网络/AI 安全 |
| [Евгений Кокуйкин — Raft](https://t.me/kokuykin) | RU | 构建 Raft AI 和基于 GPT 的应用:信任与安全、可靠性和安全性 |
| [LLM 安全](https://t.me/llmsecurity) | RU | 专注于 LLM 安全:越狱、提示词注入、对抗性攻击、基准测试 |
| [AISecHub](https://t.me/AISecHub) | EN | 全球 AI 安全枢纽:精选研究、文章、报告和工具 |
| [AI 安全实验室](https://t.me/aisecuritylab) | RU | Raft x ITMO 大学联合实验室:攻击和防御 AI 系统 |
| [ML&Sec 动态](https://t.me/mlsecfeed) | RU/EN | ML 与安全的聚合动态:新闻、工具、研究链接 |
| [AISec [x_feed]](https://t.me/aisecnews) | RU/EN | 来自 X、博客和论文的 AI 安全内容摘要 |
| [AI SecOps](https://t.me/aisecops) | RU | AI 安全运营:监控、事件响应、SIEM/SOC 集成 |
| [OK ML](https://t.me/okmlai) | RU | 专注于代码库、工具和漏洞的 ML/DS/AI 频道 |
| [AI 攻击](https://t.me/aiattacks) | EN | AI 攻击示例和威胁情报流 |
| [AGI 安全](https://t.me/agisec) | EN | 通用人工智能安全讨论 |
## 数据
*用于测试 LLM 安全、提示词注入示例和安全评估数据的测试数据集。*
| 资源 | 描述 |
|----------|-------------|
| [大语言模型的安全与隐私](https://github.com/annjawn/llm-safety-privacy) | 关于 LLM 安全和隐私的 GitHub 代码库 |
| [越狱 LLMs](https://github.com/verazuo/jailbreak_llms/tree/main/data) | 用于越狱大语言模型的数据 |
| [ChatGPT 系统提示词](https://github.com/LouisShark/chatgpt_system_prompt) | 包含 ChatGPT 系统提示词的代码库 |
| [请勿回答](https://github.com/Libr-AI/do-not-answer) | 与 LLM 响应控制相关的项目 |
| [ToxiGen](https://github.com/microsoft/ToxiGen) | Microsoft 数据集 |
| [SafetyPrompts](https://safetyprompts.com/)| LLM 安全开放数据集的活态目录 |
| [llm-security-prompt-injection](https://github.com/sinanw/llm-security-prompt-injection) | 该项目通过对一组输入提示词进行二分类来发现恶意提示词,从而调查大语言模型的安全性。分析了使用经典 ML 算法、经过训练的 LLM 模型和微调的 LLM 模型的几种方法。 |
| [提示词注入数据集](https://github.com/Dmtr-Dr/prompt-injections) | 包含用于测试和研究的提示词注入示例的数据集 |  |
## 运维安全
*运营安全注意事项:供应链风险、基础设施漏洞和生产部署安全。*
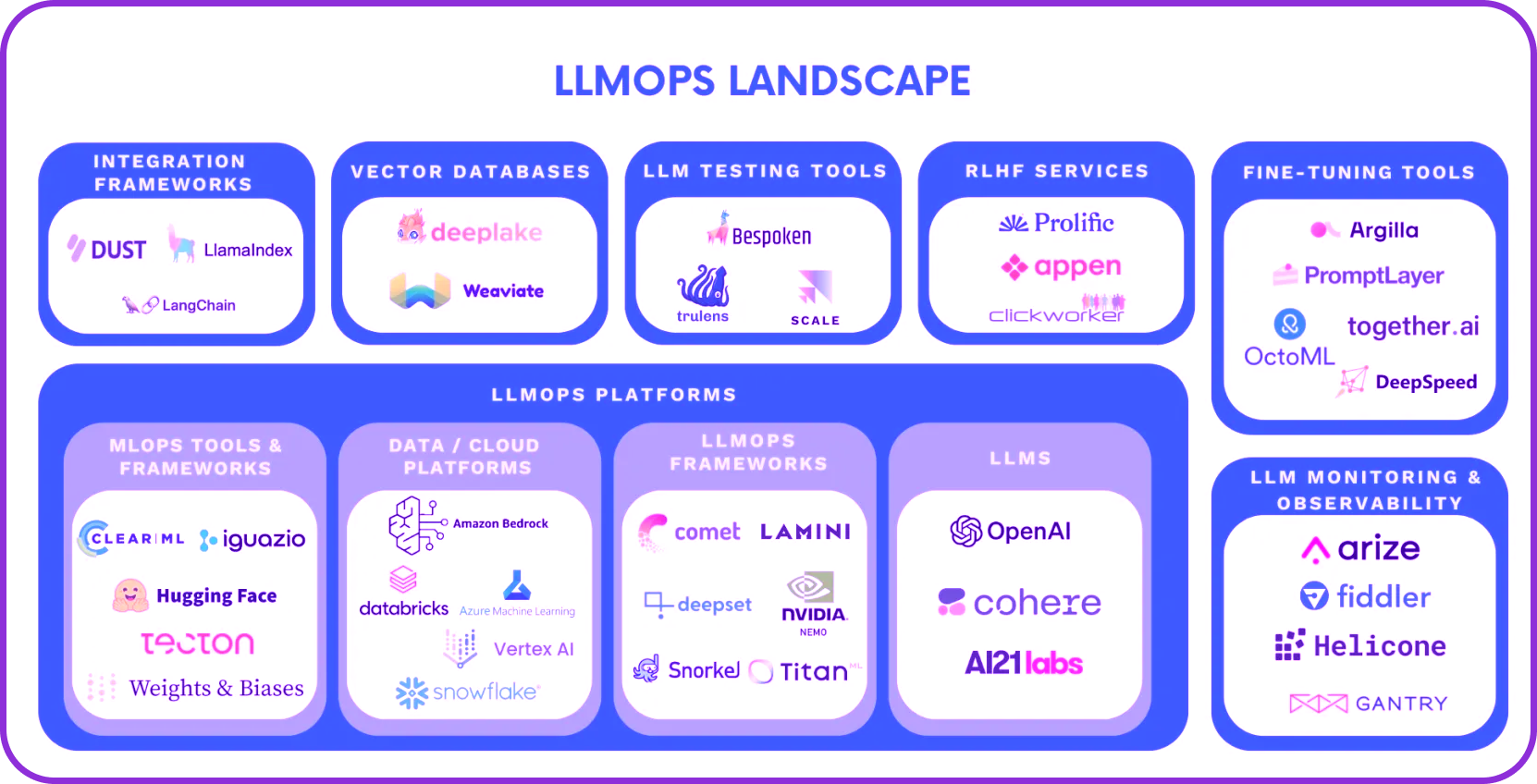
| 资源 | 描述 |
|----------|-------------|
| https://sysdig.com/blog/llmjacking-stolen-cloud-credentials-used-in-new-ai-attack/ | LLMJacking:被盗的云凭证被用于新型 AI 攻击 |
| https://huggingface.co/docs/hub/security | Hugging Face Hub 安全文档 |
| https://github.com/ShenaoW/awesome-llm-supply-chain-security | LLM 供应链安全资源|
| https://developer.nvidia.com/blog/secure-llm-tokenizers-to-maintain-application-integrity/ | 保护 LLM 分词器以维护应用完整性 |
| https://sightline.protectai.com/ | Sightline by ProtectAI (ProtectAI 现已成为 Palo Alto Networks 的一部分)
检查以下工具的漏洞:
• Nemo by Nvidia
• Deep Lake
• Fine-Tuner AI
• Snorkel AI
• Zen ML
• Lamini AI
• Comet
• Titan ML
• Deepset AI
• Valohai
**用于查找 LLMops 工具漏洞** | | https://wearetyomsmnv.github.io/ml_supply_chain_map/ | 我的供应链地图| | [ShadowMQ:代码复用如何在 AI 生态系统中传播严重漏洞](
检查以下工具的漏洞:
• Nemo by Nvidia
• Deep Lake
• Fine-Tuner AI
• Snorkel AI
• Zen ML
• Lamini AI
• Comet
• Titan ML
• Deepset AI
• Valohai
**用于查找 LLMops 工具漏洞** | | https://wearetyomsmnv.github.io/ml_supply_chain_map/ | 我的供应链地图| | [ShadowMQ:代码复用如何在 AI 生态系统中传播严重漏洞](
## 🏗 框架
*用于 LLM 和 AI 安全的综合安全框架、标准和治理模型。*
**LLMSECOPS,由 OWASP 提出**

### 附加安全框架
| 框架 | 组织 | 描述 |
|-----------|--------------|-------------|
| [MCP 安全治理](https://github.com/CloudSecurityAlliance/mcp-security-governance) | Cloud Security Alliance | 模型上下文协议生态系统的治理框架。为安全的 MCP 服务器部署制定策略、标准和评估工具。 |
| [Databricks AI 安全框架 (DASF) 2.0](https://www.databricks.com/resources/whitepaper/databricks-ai-security-framework-dasf) | Databricks | 用于管理 AI 安全的实用框架。包含跨三个阶段的 62 项安全风险和适用于任何数据及 AI 平台的 64 项控制措施。 |
| [Google 安全 AI 框架 (SAIF) 2.0](https://saif.google/) | Google | 专注于代理的安全 AI 框架。面向实践者的框架,用于构建用户可以信任的强大代理。 |
| [Snowflake AI 安全框架](https://www.snowflake.com/en/resources/white-paper/snowflake-ai-security-framework/) | Snowflake | 用于保护 Snowflake 平台上 AI 部署的综合框架。 |
## AI 安全解决方案雷达
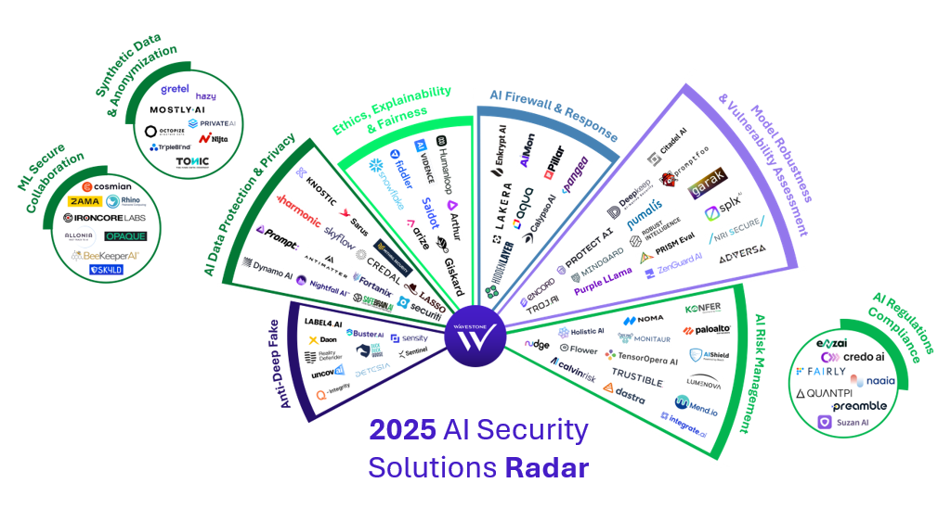
OWASP Top 10 for LLM Applications 2025 (v2.0) Updated list including System Prompt Leakage, Vector and Embedding Weaknesses |
OWASP Top 10 for Agentic Applications (2026 Edition) First industry standard for autonomous AI agent risks (released Dec 2025) |
OWASP AI Testing Guide v1 Open standard for testing AI system trustworthiness (Nov 2025) |
GenAI Security Solutions Reference Guide Vendor-neutral guide for GenAI security architecture (Q2-Q3 2025) |
LLM AI Cybersecurity & Governance Checklist Security and governance checklist |
LLMSecOps Cybersecurity Solution Landscape Solution landscape overview |
## 🌐 社区 *面向 LLM 安全从业者的社区资源、平台和协作空间。*
| 平台 | 详情 |
|:--------:|---------|
| [OWASP SLACK](https://owasp.org/slack/invite) | **频道:**
• #project-top10-for-llm
• #ml-risk-top5
• #project-ai-community
• #project-mlsec-top10
• #team-llm_ai-secgov
• #team-llm-redteam
• #team-llm-v2-brainstorm | | [Awesome LLM 安全](https://github.com/corca-ai/awesome-llm-security) | GitHub 代码库 | | [Awesome AI 安全 Telegram](https://github.com/ivolake/awesome-ai-security-tg) | 关于 AI 安全、AI/MLSecOps、LLM 安全的 Telegram 频道和聊天精选列表 |  | | [LVE_Project](https://lve-project.org/) | 官方网站 | | [Lakera AI 安全资源中心](https://docs.google.com/spreadsheets/d/1tv3d2M4-RO8xJYiXp5uVvrvGWffM-40La18G_uFZlRM/edit?gid=639798153#gid=639798153) | Google Sheets 文档 | | [llm-testing-findings](https://github.com/BishopFox/llm-testing-findings/)| 带有建议、CWE 及其他内容的模板 | | [Arcanum 提示词注入分类法](https://github.com/Arcanum-Sec/arc_pi_taxonomy/tree/main) | 对提示词注入攻击进行分类(包括攻击意图、技术和规避方法)的结构化分类法。面向安全研究人员、AI 开发人员和红队的资源。 |  |
## 基准测试
*用于评估 LLM 安全能力的安全基准、评估框架和标准化测试。*
| 资源 | 描述 | 星标数 |
|----------|-------------|-------|
| [骨干破壁基准](https://www.lakera.ai/blog/the-backbone-breaker-benchmark) | 用于测试 AI 代理安全的人类依据基准。由 Lakera 与英国 AI 安全研究所利用来自 Gandalf: Agent Breaker 的 194,000 多次人类攻击尝试构建。跨 10 个威胁快照测试骨干 LLM 的恢复能力。 | 文章 |
| [骨干破壁基准论文](https://arxiv.org/html/2508.18106v3) | 关于骨干破壁基准方法论和发现的研究论文 | 文章 |
| [CyberSoCEval](https://ai.meta.com/research/publications/cybersoceval-benchmarking-llms-capabilities-for-malware-analysis-and-threat-intelligence-reasoning/) | Meta 的基准,用于评估 LLM 在恶意软件分析和威胁情报推理中的能力 | Meta Research |
| [代理安全基准 (ASB)](https://github.com/agiresearch/ASB) | 代理安全基准 |  |
| [AI 安全基准](https://sproutnan.github.io/AI-Safety_Benchmark/) | 全面的 AI 安全评估基准 | N/A |
| [AI 安全基准论文](https://arxiv.org/abs/2506.14697) | 关于 AI 安全基准方法论的研究论文 | 文章 |
| [评估提示词注入数据集](https://hiddenlayer.com/innovation-hub/evaluating-prompt-injection-datasets/) | 对提示词注入数据集的分析和评估框架 | HiddenLayer |
| [LLM 安全指导基准](https://github.com/davisconsultingservices/llm_security_guidance_benchmarks) | 使用 SECURE 数据集对轻量级开源 LLM 进行安全指导有效性的基准测试 |  |
| [SECURE](https://github.com/aiforsec/SECURE) | 用于在网络安全场景中评估 LLM 的基准,重点关注工业控制系统 |  |
| [NIST AI TEVV](https://www.nist.gov/ai-test-evaluation-validation-and-verification-tevv) | 由 NIST 提出的 AI 测试、评估、验证和确认框架 | N/A |
| [驯服野兽:深入 Llama 3 红队演练过程](https://media.defcon.org/DEF%20CON%2032/DEF%20CON%2032%20presentations/DEF%20CON%2032%20-%20Aaron%20Grattafiori%20Ivan%20Evtimov%20Joanna%20Bitton%20Maya%20Pavlova%20-%20Taming%20the%20Beast%20-%20Inside%20the%20Llama%203%20Red%20Team%20Process.pdf) | 关于 Llama 3 红队演练的 DEF CON 32 演讲 | 2024 |
| [SecLens](https://github.com/mattersec-labs/seclens) | 用于使用涵盖 10 种语言的 406 个已确认 CVE 评估 LLM 在真实世界漏洞检测中表现的基准。通过 5 个利益相关者视角和与 OWASP 类别对齐的 35 个维度,对 12 个前沿模型进行评分。[论文](https://arxiv.org/abs/2604.01637) |  |
- [OpenClaw Monitor](https://github.com/flik2002/openclaw-monitor-frontend) - 用于 AI 代理和 LLM 的 AI 监控仪表板。[演示](https://flik2002.github.io/openclaw-monitor-frontend)• #project-top10-for-llm
• #ml-risk-top5
• #project-ai-community
• #project-mlsec-top10
• #team-llm_ai-secgov
• #team-llm-redteam
• #team-llm-v2-brainstorm | | [Awesome LLM 安全](https://github.com/corca-ai/awesome-llm-security) | GitHub 代码库 | | [Awesome AI 安全 Telegram](https://github.com/ivolake/awesome-ai-security-tg) | 关于 AI 安全、AI/MLSecOps、LLM 安全的 Telegram 频道和聊天精选列表 |  | | [LVE_Project](https://lve-project.org/) | 官方网站 | | [Lakera AI 安全资源中心](https://docs.google.com/spreadsheets/d/1tv3d2M4-RO8xJYiXp5uVvrvGWffM-40La18G_uFZlRM/edit?gid=639798153#gid=639798153) | Google Sheets 文档 | | [llm-testing-findings](https://github.com/BishopFox/llm-testing-findings/)| 带有建议、CWE 及其他内容的模板 | | [Arcanum 提示词注入分类法](https://github.com/Arcanum-Sec/arc_pi_taxonomy/tree/main) | 对提示词注入攻击进行分类(包括攻击意图、技术和规避方法)的结构化分类法。面向安全研究人员、AI 开发人员和红队的资源。 |  |
标签:AI安全, C2, Chat Copilot, CISA项目, DLL 劫持, LangChain, LlamaIndex, LLMSecOps, RAG安全, Red Canary, 后端开发, 大语言模型, 威胁建模, 学习资源, 安全运营, 扫描框架, 数据污染, 最佳实践, 架构风险, 概念验证, 漏洞分析, 网络安全, 请求拦截, 路径探测, 轻量级, 逆向工具, 隐私保护