guidance-ai/llguidance
GitHub: guidance-ai/llguidance
llguidance 是一个高性能的 LLM 约束解码库,通过计算 token 掩码强制模型输出符合 JSON Schema、正则表达式或上下文无关文法的结构化结果。
Stars: 823 | Forks: 75
# 底层 Guidance (llguidance)
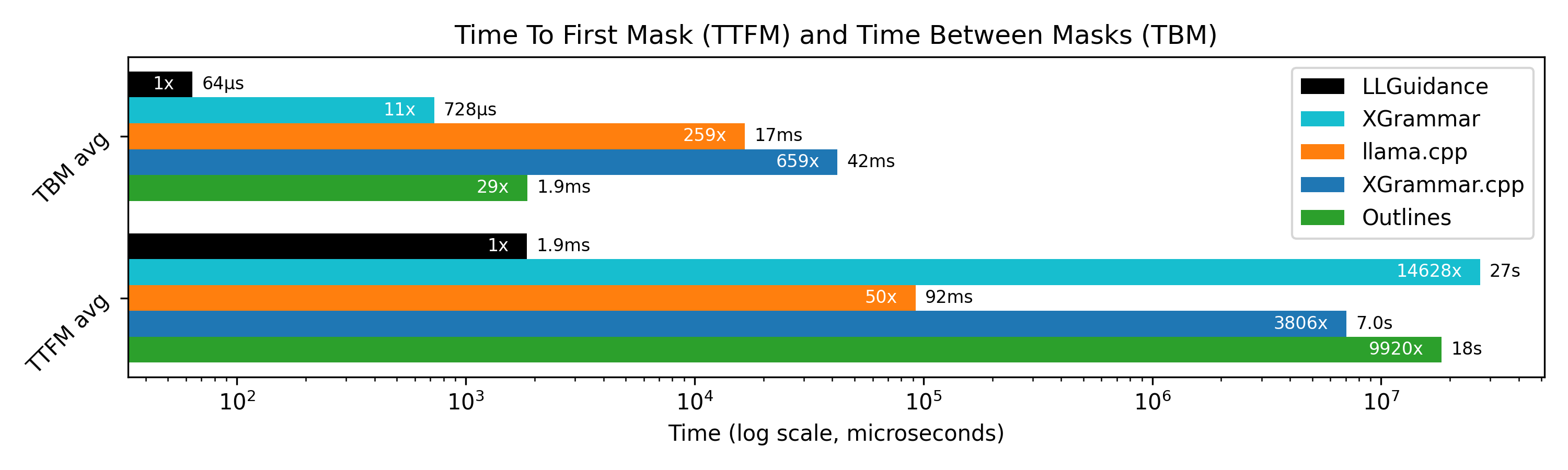
Performance results from MaskBench
* 2025-06-23 llguidance 现已发布 v1.0.0 版本
* 2025-06-11 发布了 [让结构化输出飞起来](https://guidance-ai.github.io/llguidance/llg-go-brrr) 博客文章
* 2025-05-20 LLGuidance 已 [随](https://x.com/OpenAIDevs/status/1924915341052019166) [OpenAI](https://x.com/OpenAIDevs/status/1924915343677653014) 发布,用于 JSON Schema
* 2025-04-11 集成已[合并](https://github.com/chromium/chromium/commit/07ca6337c2f714ba0477202414bd2b1692e70594)至 Chromium
* 2025-03-25 集成已[合并](https://github.com/vllm-project/vllm/pull/14779)至 vLLM (v0.8.2)
* 2025-02-26 集成已[合并](https://github.com/sgl-project/sglang/pull/3298)至 SGLang (v0.4.4)
* 2025-02-01 集成已[合并](https://github.com/ggml-org/llama.cpp/pull/10224)至 llama.cpp (b4613)
* 2025-01-21 发布 [JSONSchemaBench](https://github.com/guidance-ai/jsonschemabench),包含[论文](https://arxiv.org/abs/2501.10868)和 [MaskBench](https://github.com/guidance-ai/jsonschemabench/tree/main/maskbench)
* 2025-01-07 发布 Guidance [v0.2.0](https://github.com/guidance-ai/guidance/releases/tag/0.2.0),使用 llguidance 作为语法引擎
## 关于
该库为大语言模型 (LLM) 实现了约束解码(也称为约束采样或结构化输出)。
它可以对 LLM 的输出强制执行任意上下文无关文法,
并且速度极快——对于 128k tokenizer,每个 token 的 CPU 耗时约为 50μs,
且启动开销微乎其微。
支持以下语法格式:
- JSON schema 的[一大类子集](./docs/json_schema.md)
- 正则表达式
- [Lark 格式变体](./docs/syntax.md)的上下文无关文法;
支持内嵌 JSON schema 和正则表达式
- `llguidance` - [内部(基于 JSON 的)格式](./parser/src/api.rs);
正逐渐被废弃,转而推荐使用类 Lark 格式
内部格式最为强大(尽管类 Lark 格式正在迎头赶上,且已有计划将相关库转换为使用该格式),可由以下库生成:
- [Guidance](https://github.com/guidance-ai/guidance) (Python)
- [guidance.ts](https://github.com/mmoskal/guidance-ts) (TypeScript)
- 未来还会有更多!
该库可通过以下语言使用:
- [Rust](./parser/README.md),[示例](./sample_parser/src/minimal.rs)
- [C 和 C++](./parser/llguidance.h),[示例](./c_sample/c_sample.cpp)
- [Python](./python/llguidance/_lib.pyi)
## 集成
该库目前已集成于:
- [Guidance](https://github.com/guidance-ai/guidance) - 用于与 LLM 交互的库
- [OpenAI 模型](https://x.com/OpenAIDevs/status/1924915343677653014) - LLGuidance 为[结构化输出](https://platform.openai.com/docs/guides/structured-outputs)提供支持(仅限 JSON Schema)
- [llama.cpp](https://github.com/ggerganov/llama.cpp/pull/10224) -
可通过 `cmake` 的 `-DLLAMA_LLGUIDANCE=ON` 选项启用;
llama.cpp 也可使用 Guidance Python 包
- **Chromium** - [已合并](https://github.com/chromium/chromium/commit/07ca6337c2f714ba0477202414bd2b1692e70594),
将用于 Chromium 内核浏览器的 `window.ai` 的 [JSON Schema 强制校验](https://github.com/webmachinelearning/prompt-api?tab=readme-ov-file#structured-output-or-json-output)
- [SGLang](https://github.com/sgl-project/sglang/pull/3298) -
使用 `--grammar-backend llguidance`;当传入 Lark 语法时,
请务必添加 `%llguidance {}` 前缀,就像在 llama.cpp 中那样
- **vLLM** - [V0 PR](https://github.com/vllm-project/vllm/pull/14589) 和 [V1 PR](https://github.com/vllm-project/vllm/pull/14779)
- [LLGTRT](https://github.com/guidance-ai/llgtrt) - 兼容 OpenAI 的 REST 服务器,使用 NVIDIA 的 [TensorRT-LLM](https://github.com/NVIDIA/TensorRT-LLM)
- [mistral.rs](https://github.com/EricLBuehler/mistral.rs/pull/899)
- [onnxruntime-genai](https://github.com/microsoft/onnxruntime-genai/pull/1381)
## 技术细节
请参阅 [让结构化输出飞起来](https://guidance-ai.github.io/llguidance/llg-go-brrr) 以获取该库的概述,
包括设计决策、性能表现以及与其他方法的比较。
给定上下文无关文法、tokenizer 和 token 前缀,llguidance 会计算出一个 token 掩码——即 tokenizer 中的一组 token——当它们被添加到当前 token 前缀时,能够生成符合该语法定义的合法字符串。对于具有 128k token 的 tokenizer,掩码计算大约需要 50μs 的单核 CPU 时间。虽然该时间取决于具体的语法,但对于从 JSON schema 派生的语法等场景依然适用。该过程没有显著的启动开销。
该库在基于[正则表达式求导](https://github.com/microsoft/derivre)的词法分析器之上,使用 Earley 算法实现了一个上下文无关文法解析器。掩码计算通过遍历所有可能 token 的[前缀树](./docs/toktrie.md)来实现,并依托于[高度优化的](./docs/optimizations.md)代码。
语法还可用于通过[快进 token](./docs/fast_forward.md)来加速解码。
### 比较与性能
请参阅 [JSON Schema Bench](https://github.com/guidance-ai/jsonschemabench) 中的
[MaskBench](https://github.com/guidance-ai/jsonschemabench/tree/main/maskbench) 以获取详细的性能比较。
[LM-format-enforcer](https://github.com/noamgat/lm-format-enforcer) 和 [llama.cpp grammars](https://github.com/ggerganov/llama.cpp/blob/master/grammars/README.md) 与 llguidance 类似,它们都在解码过程的每一步动态构建 token 掩码。不过这两者的速度都要慢得多——前者是因为采用了易于阅读的 Python 代码,后者则是因为缺乏词法分析器且使用了回溯解析器,这种方式虽然优雅,但效率低下。
[Outlines](https://github.com/dottxt-ai/outlines) 根据约束条件构建自动机,然后为所有自动机状态预计算 token 掩码,这可能使采样变得很快,但本质上限制了约束的复杂性,并引入了显著的启动开销和内存占用。Llguidance 则是即时计算 token 掩码,基本没有启动成本。llguidance 中的词法分析器自动机是延迟构建的,且通常要小得多,因为上下文无关文法已经规定了顶层的结构。
[XGrammar](https://github.com/mlc-ai/xgrammar) 采用的方法与 llama.cpp 类似(显式的、基于栈的字符级解析器),同时结合了对特定 token 掩码的预计算,这点类似于 Outlines。其预计算过程通常耗时数秒,有时甚至长达数分钟。如果预计算在给定输入下运行良好,掩码的计算速度会非常快(在我们测试的半数掩码中耗时不到 8μs),但如果与特定输入不匹配,
掩码计算时间可能会长达数十甚至数百毫秒。
在 llguidance 中,针对典型的 JSON schema 进行完整掩码计算大约需要 1.5ms(对于 128k tokenizer)。
然而,[“切片器”优化](./docs/optimizations.md#slicer-optimization)往往可以生效,
因此在 [JSON Schema Bench](https://github.com/guidance-ai/jsonschemabench) 中
(250万个 token,1万个 schema)的平均掩码计算耗时不到 50μs,
其中耗时超过 1ms 的掩码不到 1%,
耗时超过 10ms 的仅占 0.001%(但仍短于 30ms)。
该优化不涉及任何繁重的预计算。
因此,在 16 核环境下,假设前向传递耗时 10ms,llguidance 可以处理高达 3200 的 batch size,而不会拖慢模型速度。(请注意,对于较小的 batch size,10ms 的前向传递耗时通常在 batch size 达到 100-200 时会增加至 20ms 以上。)
## 构建
- [安装 rust](https://www.rust-lang.org/tools/install);需 1.87 或更高版本
如果您只需要 C 或 Rust 库 (`llguidance`),
请查看 [parser](./parser/README.md) 目录。
对于 Python 绑定:
- 安装 python 3.10 或更高版本;您很可能需要使用虚拟环境/conda
- 运行 `./scripts/install-deps.sh`
- 进行构建以及在任何更改之后,运行 `./scripts/test-guidance.sh`
这将构建该库的 Python 绑定并运行测试
(大部分测试位于 Guidance 代码库中 - 脚本会自动克隆它)。
## 商标
本项目可能包含项目、产品或服务的商标或徽标。Microsoft 商标或徽标的授权使用受
[Microsoft 商标与品牌指南](https://www.microsoft.com/en-us/legal/intellectualproperty/trademarks/usage/general) 的约束并必须遵循该指南。
在修改后的项目中使用 Microsoft 商标或徽标时,不得引起混淆或暗示 Microsoft 的赞助。
任何第三方商标或徽标的使用均受相关第三方政策的约束。
标签:DLL 劫持, JSON Schema, Rust, 人工智能, 可视化界面, 大语言模型, 推理引擎, 用户模式Hook绕过, 结构化输出, 网络流量审计, 逆向工具, 通知系统