maveryn/cti-bench
GitHub: maveryn/cti-bench
首个面向网络威胁情报场景的 LLM 综合评测基准,涵盖知识问答、漏洞推理、严重性评估、技术提取与威胁归因五类任务。
Stars: 86 | Forks: 31
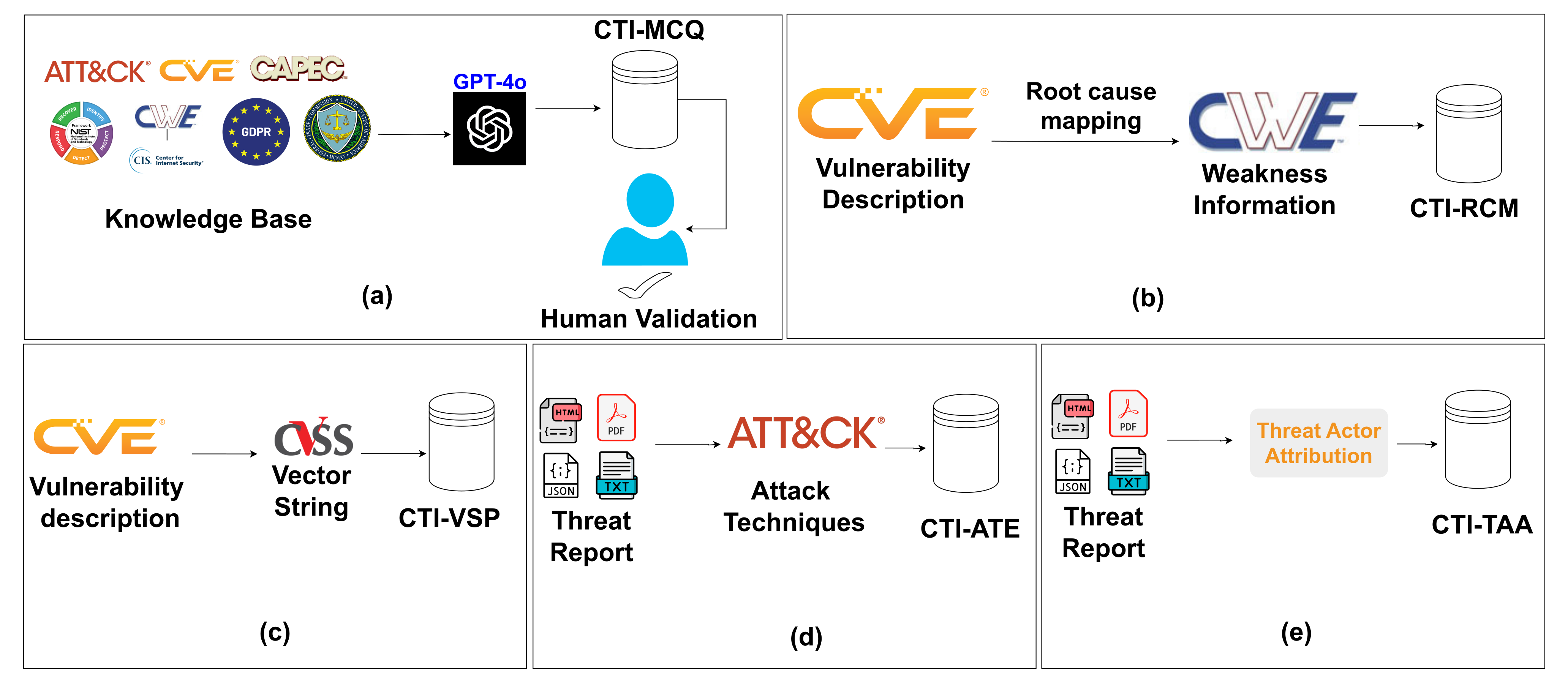
# CTIBench
CTIBench 是一个用于评估大型语言模型在实际
Cyber Threat Intelligence (CTI) 任务上表现的基准测试。它涵盖了 CTI 知识、漏洞
根因映射、漏洞严重性预测、ATT&CK 技术
提取以及威胁行为者归因。
标签:AES-256, AI4Security, AMSI绕过, Apex, CISA项目, CSV导出, CVE, CVSS, DLL 劫持, GitHub, HTTP工具, IP 地址批量处理, LLM评估, Mr. Robot, NeurIPS 2024, NoSQL, Ollama, 人工智能, 信息提取, 后渗透, 域名收集, 大语言模型, 威胁归因, 威胁检测, 安全情报, 实时处理, 密码管理, 开源软件, 插件系统, 数字签名, 数据包嗅探, 文档安全, 无线安全, 机器学习, 流量嗅探, 深度学习, 漏洞评估, 漏洞预测, 用户模式Hook绕过, 网络信息收集, 网络威胁情报, 网络安全, 网络安全审计, 网络安全评估, 逆向工具, 隐私保护