muchdogesec/txt2stix
GitHub: muchdogesec/txt2stix
从非结构化文本中自动提取 IoC 与 TTP 并输出 STIX 2.1 Bundle。
Stars: 83 | Forks: 7
# txt2stix
[](https://codecov.io/gh/muchdogesec/txt2stix)
## 开始之前...
我们基于 txt2stix 构建了两个产品,提供更友好的用户体验:
* [Stixify: 从非结构化数据中提取机器可读的网络威胁情报](https://github.com/muchdogesec/stixify)
* [Obstracts: 将任何博客转化为结构化的威胁情报](https://github.com/muchdogesec/obstracts)
## 概述
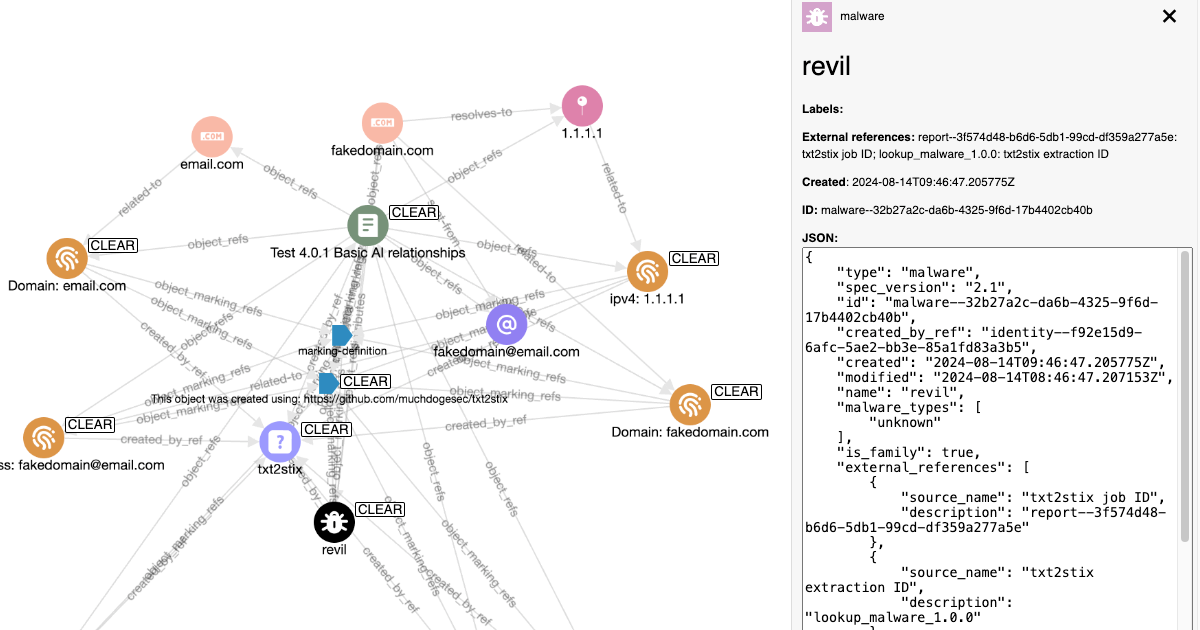
txt2stix 是一个 Python 脚本,用于识别并从文本文件中提取 IoC 和 TTP,识别它们之间的关系,将它们转换为 STIX 2.1 对象,并输出为 STIX 2.1 Bundle。
txt2stix 的总体设计目标是保持灵活但简单,以便随着时间的推移可以添加或修改新的提取内容。
简而言之,txt2stix:
1. 接受一个 txt 文件作为输入
2. 提取已启用提取类型(AI、正则表达式或查找表)的可观测对象
3. 将提取的可观测对象转换为 STIX 2.1 对象
4. 生成提取可观测对象之间的关系(AI、常规)
5. 将提取的关系转换为 STIX 2.1 SRO 对象
6. 输出一个 STIX 2.1 Bundle
## 使用方法
### 安装设置
使用以下命令安装所需依赖:
```
# 克隆最新代码
git clone https://github.com/muchdogesec/txt2stix
cd txt2stix
# 创建 venv
python3 -m venv txt2stix-venv
source txt2stix-venv/bin/activate
# 安装 requirements
pip3 install txt2stix
```
默认情况下,txt2stix 会安装 OpenAI 作为 AI 提供者。你也可以使用 Anthropic、Gemini、OpenRouter 或 Deepseek。如果计划使用这些提供者,请手动安装它们(取消注释不适用的项):
```
pip3 install txt2stix[deepseek,gemini,anthropic,openrouter]
```
### 设置变量
txt2stix 包含多个在 `.env` 文件中定义的设置。
要创建该文件的模板:
```
cp .env.example .env
```
如需了解如何设置变量及其作用,请阅读 `.env.markdown` 文件。
然后测试你的配置:
```
python3 txt2stix.py \
--check-credentials
```
它将返回一个响应以显示哪些 API 密钥可用
```
============= Service Statuses ===============
ctibutler : authorized ✔
vulmatch : authorized ✔
binlist : authorized ✔
LLMS:
openai : authorized ✔
deepseek : unsupported –
gemini : unsupported –
openrouter : unsupported –
anthropic : unsupported –
```
并非所有服务都需要配置,如果你没有使用意图,则无需设置它们。
### 使用
```
python3 txt2stix.py \
--relationship_mode MODE \
--input_file FILE.txt \
...
```
可用参数如下:
#### 输入设置
* `--input_file` (`path/to/file.txt`,必需):待转换的文件,必须为 `.txt`
#### STIX 报告生成设置
* `--name` (文本,必需):文件名,最大 72 个字符。将在生成的 STIX Report 对象中使用。
* `--report_id` (UUIDv4,默认随机生成):有时需要控制 `report` 对象的 ID。可以传递一个有效的 UUIDv4 以指定该对象。例如传递 `2611965-930e-43db-8b95-30a1e119d7e2` 将创建 STIX 对象 ID `report--2611965-930e-43db-8b95-30a1e119d7e2`。如果不传递,将自动生成 UUID。
* `--tlp_level` (字典,默认 `clear`):可选值为 `clear`、`green`、`amber`、`amber_strict`、`red`。
* `--confidence` (0-100 之间的值):如果不传递,报告将不包含置信度评分。
* `--labels` (可选):逗号分隔的标签列表。不区分大小写(会转换为小写)。允许 `a-z`、`0-9`。例如 `label1,label2` 将创建 2 个标签。
* `--created` (日期时间,可选):默认所有对象的 `created` 时间使用脚本运行时间。如需显式设置,请使用此标志。格式为 `YYYY-MM-DDTHH:MM:SS.sssZ`,例如 `2020-01-01T00:00:00.000Z`。
* `--use_identity` (STIX 身份对象,可选,默认 txt2stix 身份):可传递完整的 STIX 2.1 身份对象(确保正确转义)。将由 STIX2 库验证。
* `--external_refs` (可选):txt2stix 会自动为生成的报告对象填充 `external_references`。可使用此参数添加额外对象。目前仅支持添加 `source_name` 和 `external_id` 值。格式为 `source_name=external_id`。例如 `--external_refs txt2stix=demo1 source=id` 将在 `external_references` 属性下创建以下对象:`{"source_name":"txt2stix","external_id":"demo1"},{"source_name":"source","external_id":"id"}`
#### 输出设置
##### 提取执行方式
* `--use_extractions` (字典,必需):如果只想使用某些提取类型,可以传递它们在 `includes/ai/config.yaml`、`includes/lookup/config.yaml` 或 `includes/pattern/config.yaml` 中的 slug。如果不传递,默认不应用任何提取。也可以传递通配符 `*`,匹配所有提取路径(例如 `'pattern_*'` 将运行所有以 `pattern_` 开头的提取——使用时请加引号)。
* 重要:如果使用任何 AI 提取 (`ai_*`),必须在 `.env` 文件中设置 AI API 密钥。
* 重要:如果使用任何 MITRE ATT&CK、CAPEC、CWE、ATLAS 或位置提取,或使用 CVE/CPE 提取,必须在 `.env` 文件中设置 `CTIBUTLER` 或 `VULMATCH` 设置。
* `--relationship_mode` (字典,必需):可选值为:
* `ai`:必须启用 AI 提供者。由用户选择的提取使用正则表达式或 AI 执行。生成由 AI 提供者创建的丰富关系。
* `standard`:由用户选择的提取使用正则表达式或 AI(必须启用 AI 提供者)。生成从提取回主报告对象的常规关系。
* `--ignore_extraction_boundary` (布尔值,默认 `false`,不兼容 AI 提取):某些情况下,同一个字符串可能根据提取设置生成多个提取。默认行为是选择最长提取并忽略其他(例如 `https://www.google.com/file.txt` 可能生成 URL、文件、域名、子域名等多个提取)。默认仅提取最长内容并忽略其余。如需提取所有内容,请设置为 `true`。
* `--ignore_image_refs` (布尔值,默认 `true`):文档中的图像引用通常不需要提取。例如 ` `,你通常不希望提取 `example.com` 和 `image.png`。因此默认忽略这些内容。请注意,只有 `img src` 被忽略,`alt` 等其他属性仍会被考虑。如需提取这些数据,请设置为 `false`。
* `--ignore_link_refs` (布尔值,默认 `true`):文档中的链接引用通常不需要提取。例如 `Bad Actor`,你通常只希望提取 `Bad Actor`。因此默认忽略链接部分。请注意,只有 `a href` 被忽略,其他属性如 `title` 仍会被考虑。如需提取链接内容,请设置为 `false`。
#### AI 设置
如果使用任何 AI 提取或 AI 关系模式,必须相应设置以下内容:
* `--ai_settings_extractions` (`model:provider`,必需,如果设置了 AI 提取):
* 定义用于提取的 `提供商:模型`。可同时提供多个提供者,用空格分隔(例如 `openrouter:openai/gpt-4o openrouter:deepseek/deepseek-chat`)。如果传递多个提供者,txt2stix 将从所有模型中提取结果,去重后合并输出。当前支持:
* 提供商(需要环境变量 `OPENROUTER_API_KEY`):`openrouter:`,提供者/模型包括 `openai/gpt-4o`、`deepseek/deepseek-chat`([更多](https://openrouter.ai/models))
* 提供商(需要环境变量 `OPENAI_API_KEY`):`openai:`,模型如 `gpt-4o`、`gpt-4o-mini`、`gpt-4-turbo`、`gpt-4`([更多](https://platform.openai.com/docs/models))
* 提供商(需要环境变量 `ANTHROPIC_API_KEY`):`anthropic:`,模型如 `claude-3-5-sonnet-latest`、`claude-3-5-haiku-latest`、`claude-3-opus-latest`([更多](https://docs.anthropic.com/en/docs/about-claude/models))
* 提供商(需要环境变量GOOGLE_API_KEY`):`gemini:models/`,模型如 `gemini-1.5-pro-latest`、`gemini-1.5-flash-latest`([更多](https://ai.google.dev/gemini-api/docs/models/gemini))
* 提供商(需要环境变量 `DEEPSEEK_API_KEY`):`deepseek:`,模型 `deepseek-chat`([更多](https://api-docs.deepseek.com/quick_start/pricing))
* 参考 `tests/manual-tests/cases-ai-extraction-type.md` 获取示例
* `--ai_settings_relationships` (`model:provider`,必需,如果设置了 AI 关系模式):
* 与 `ai_settings_extractions` 类似,但定义用于生成关系的模型。仅允许一个模型。格式与 `ai_settings_extractions` 相同。
* 参考 `tests/manual-tests/cases-ai-relationships.md` 获取示例
#### 其他 AI 相关设置
* `--ai_content_check_provider` (`model:provider`,必需,如果传递):启用该标志后,AI 将尝试对输入文本进行分类:1) 判断是否为威胁情报;2) 判断威胁情报类型。用于在 Obstracts 和 Stixify 中过滤非威胁情报内容。可通过 `provider:model` 指定用于内容分类的 AI 模型。系统还会生成内容的摘要并存储为 STIX 笔记。
* `--ai_extract_if_no_incidence` (布尔值,默认 `true`,仅在设置 `ai_content_check_provider` 时有效):如果内容检查判定报告与网络安全情报无关(例如供应商营销内容),可通过此设置决定是否继续处理。设为 `false` 将停止处理。旨在以自动化方式节省 AI 代币,避免处理未知内容。
* `--ai_create_attack_flow` (布尔值):启用后,AI 模型(默认与 `--ai_settings_relationships` 相同)将为 MITRE ATT&CK 提取生成 [Attack Flow](https://center-for-threat-informed-defense.github.io/attack-flow/),以定义其逻辑顺序。需传递 `--ai_settings_relationships` 才能生效。
* `--ai_create_attack_navigator_layer` (布尔值,默认 `false`):启用后将为 MITRE ATT&CK 提取生成 [MITRE ATT&CK Navigator 层](https://mitre-attack.github.io/attack-navigator/)。对每个 ATT&CK 域(企业、ICS、移动)生成独立层。需传递 `--ai_settings_relationships`,因为 AI 负责将提取的技术关联到正确的战术。已知问题:使用 `openai:gpt-3.5` 时请避免使用该模型。
## 添加新的提取
你很可能希望扩展 txt2stix 以支持新的提取功能:
* 添加新的查找表提取:将查找项添加到 `includes/lookups` 目录下的 `.txt` 文件中。查找表应为按行分隔的条目列表,用于在文档中搜索。添加后,更新 `includes/extractions/lookup/config.yaml` 中的记录以指向你的查找表。添加完成后即可在脚本运行时使用。
* 添加新的 AI 提取:编辑 `includes/extractions/ai/config.yaml` 并添加一条新记录。可在配置中定制提示词以控制 LLM 的提取行为。
目前,其他类型的提取(需修改代码逻辑)尚无法轻松添加。
## 详细文档
如需详细了解 txt2stix 的工作原理,请参考 `/docs/README.md` 中的文档。
这些文档对希望添加自定义提取的用户特别有帮助。
## 支持
[通过 dogesec 社区获取基础支持](https://community.dogesec.com/)。
## 许可证
[Apache 2.0](/LICENSE)。
`,你通常不希望提取 `example.com` 和 `image.png`。因此默认忽略这些内容。请注意,只有 `img src` 被忽略,`alt` 等其他属性仍会被考虑。如需提取这些数据,请设置为 `false`。
* `--ignore_link_refs` (布尔值,默认 `true`):文档中的链接引用通常不需要提取。例如 `Bad Actor`,你通常只希望提取 `Bad Actor`。因此默认忽略链接部分。请注意,只有 `a href` 被忽略,其他属性如 `title` 仍会被考虑。如需提取链接内容,请设置为 `false`。
#### AI 设置
如果使用任何 AI 提取或 AI 关系模式,必须相应设置以下内容:
* `--ai_settings_extractions` (`model:provider`,必需,如果设置了 AI 提取):
* 定义用于提取的 `提供商:模型`。可同时提供多个提供者,用空格分隔(例如 `openrouter:openai/gpt-4o openrouter:deepseek/deepseek-chat`)。如果传递多个提供者,txt2stix 将从所有模型中提取结果,去重后合并输出。当前支持:
* 提供商(需要环境变量 `OPENROUTER_API_KEY`):`openrouter:`,提供者/模型包括 `openai/gpt-4o`、`deepseek/deepseek-chat`([更多](https://openrouter.ai/models))
* 提供商(需要环境变量 `OPENAI_API_KEY`):`openai:`,模型如 `gpt-4o`、`gpt-4o-mini`、`gpt-4-turbo`、`gpt-4`([更多](https://platform.openai.com/docs/models))
* 提供商(需要环境变量 `ANTHROPIC_API_KEY`):`anthropic:`,模型如 `claude-3-5-sonnet-latest`、`claude-3-5-haiku-latest`、`claude-3-opus-latest`([更多](https://docs.anthropic.com/en/docs/about-claude/models))
* 提供商(需要环境变量GOOGLE_API_KEY`):`gemini:models/`,模型如 `gemini-1.5-pro-latest`、`gemini-1.5-flash-latest`([更多](https://ai.google.dev/gemini-api/docs/models/gemini))
* 提供商(需要环境变量 `DEEPSEEK_API_KEY`):`deepseek:`,模型 `deepseek-chat`([更多](https://api-docs.deepseek.com/quick_start/pricing))
* 参考 `tests/manual-tests/cases-ai-extraction-type.md` 获取示例
* `--ai_settings_relationships` (`model:provider`,必需,如果设置了 AI 关系模式):
* 与 `ai_settings_extractions` 类似,但定义用于生成关系的模型。仅允许一个模型。格式与 `ai_settings_extractions` 相同。
* 参考 `tests/manual-tests/cases-ai-relationships.md` 获取示例
#### 其他 AI 相关设置
* `--ai_content_check_provider` (`model:provider`,必需,如果传递):启用该标志后,AI 将尝试对输入文本进行分类:1) 判断是否为威胁情报;2) 判断威胁情报类型。用于在 Obstracts 和 Stixify 中过滤非威胁情报内容。可通过 `provider:model` 指定用于内容分类的 AI 模型。系统还会生成内容的摘要并存储为 STIX 笔记。
* `--ai_extract_if_no_incidence` (布尔值,默认 `true`,仅在设置 `ai_content_check_provider` 时有效):如果内容检查判定报告与网络安全情报无关(例如供应商营销内容),可通过此设置决定是否继续处理。设为 `false` 将停止处理。旨在以自动化方式节省 AI 代币,避免处理未知内容。
* `--ai_create_attack_flow` (布尔值):启用后,AI 模型(默认与 `--ai_settings_relationships` 相同)将为 MITRE ATT&CK 提取生成 [Attack Flow](https://center-for-threat-informed-defense.github.io/attack-flow/),以定义其逻辑顺序。需传递 `--ai_settings_relationships` 才能生效。
* `--ai_create_attack_navigator_layer` (布尔值,默认 `false`):启用后将为 MITRE ATT&CK 提取生成 [MITRE ATT&CK Navigator 层](https://mitre-attack.github.io/attack-navigator/)。对每个 ATT&CK 域(企业、ICS、移动)生成独立层。需传递 `--ai_settings_relationships`,因为 AI 负责将提取的技术关联到正确的战术。已知问题:使用 `openai:gpt-3.5` 时请避免使用该模型。
## 添加新的提取
你很可能希望扩展 txt2stix 以支持新的提取功能:
* 添加新的查找表提取:将查找项添加到 `includes/lookups` 目录下的 `.txt` 文件中。查找表应为按行分隔的条目列表,用于在文档中搜索。添加后,更新 `includes/extractions/lookup/config.yaml` 中的记录以指向你的查找表。添加完成后即可在脚本运行时使用。
* 添加新的 AI 提取:编辑 `includes/extractions/ai/config.yaml` 并添加一条新记录。可在配置中定制提示词以控制 LLM 的提取行为。
目前,其他类型的提取(需修改代码逻辑)尚无法轻松添加。
## 详细文档
如需详细了解 txt2stix 的工作原理,请参考 `/docs/README.md` 中的文档。
这些文档对希望添加自定义提取的用户特别有帮助。
## 支持
[通过 dogesec 社区获取基础支持](https://community.dogesec.com/)。
## 许可证
[Apache 2.0](/LICENSE)。
`,你通常不希望提取 `example.com` 和 `image.png`。因此默认忽略这些内容。请注意,只有 `img src` 被忽略,`alt` 等其他属性仍会被考虑。如需提取这些数据,请设置为 `false`。
* `--ignore_link_refs` (布尔值,默认 `true`):文档中的链接引用通常不需要提取。例如 `Bad Actor`,你通常只希望提取 `Bad Actor`。因此默认忽略链接部分。请注意,只有 `a href` 被忽略,其他属性如 `title` 仍会被考虑。如需提取链接内容,请设置为 `false`。
#### AI 设置
如果使用任何 AI 提取或 AI 关系模式,必须相应设置以下内容:
* `--ai_settings_extractions` (`model:provider`,必需,如果设置了 AI 提取):
* 定义用于提取的 `提供商:模型`。可同时提供多个提供者,用空格分隔(例如 `openrouter:openai/gpt-4o openrouter:deepseek/deepseek-chat`)。如果传递多个提供者,txt2stix 将从所有模型中提取结果,去重后合并输出。当前支持:
* 提供商(需要环境变量 `OPENROUTER_API_KEY`):`openrouter:`,提供者/模型包括 `openai/gpt-4o`、`deepseek/deepseek-chat`([更多](https://openrouter.ai/models))
* 提供商(需要环境变量 `OPENAI_API_KEY`):`openai:`,模型如 `gpt-4o`、`gpt-4o-mini`、`gpt-4-turbo`、`gpt-4`([更多](https://platform.openai.com/docs/models))
* 提供商(需要环境变量 `ANTHROPIC_API_KEY`):`anthropic:`,模型如 `claude-3-5-sonnet-latest`、`claude-3-5-haiku-latest`、`claude-3-opus-latest`([更多](https://docs.anthropic.com/en/docs/about-claude/models))
* 提供商(需要环境变量GOOGLE_API_KEY`):`gemini:models/`,模型如 `gemini-1.5-pro-latest`、`gemini-1.5-flash-latest`([更多](https://ai.google.dev/gemini-api/docs/models/gemini))
* 提供商(需要环境变量 `DEEPSEEK_API_KEY`):`deepseek:`,模型 `deepseek-chat`([更多](https://api-docs.deepseek.com/quick_start/pricing))
* 参考 `tests/manual-tests/cases-ai-extraction-type.md` 获取示例
* `--ai_settings_relationships` (`model:provider`,必需,如果设置了 AI 关系模式):
* 与 `ai_settings_extractions` 类似,但定义用于生成关系的模型。仅允许一个模型。格式与 `ai_settings_extractions` 相同。
* 参考 `tests/manual-tests/cases-ai-relationships.md` 获取示例
#### 其他 AI 相关设置
* `--ai_content_check_provider` (`model:provider`,必需,如果传递):启用该标志后,AI 将尝试对输入文本进行分类:1) 判断是否为威胁情报;2) 判断威胁情报类型。用于在 Obstracts 和 Stixify 中过滤非威胁情报内容。可通过 `provider:model` 指定用于内容分类的 AI 模型。系统还会生成内容的摘要并存储为 STIX 笔记。
* `--ai_extract_if_no_incidence` (布尔值,默认 `true`,仅在设置 `ai_content_check_provider` 时有效):如果内容检查判定报告与网络安全情报无关(例如供应商营销内容),可通过此设置决定是否继续处理。设为 `false` 将停止处理。旨在以自动化方式节省 AI 代币,避免处理未知内容。
* `--ai_create_attack_flow` (布尔值):启用后,AI 模型(默认与 `--ai_settings_relationships` 相同)将为 MITRE ATT&CK 提取生成 [Attack Flow](https://center-for-threat-informed-defense.github.io/attack-flow/),以定义其逻辑顺序。需传递 `--ai_settings_relationships` 才能生效。
* `--ai_create_attack_navigator_layer` (布尔值,默认 `false`):启用后将为 MITRE ATT&CK 提取生成 [MITRE ATT&CK Navigator 层](https://mitre-attack.github.io/attack-navigator/)。对每个 ATT&CK 域(企业、ICS、移动)生成独立层。需传递 `--ai_settings_relationships`,因为 AI 负责将提取的技术关联到正确的战术。已知问题:使用 `openai:gpt-3.5` 时请避免使用该模型。
## 添加新的提取
你很可能希望扩展 txt2stix 以支持新的提取功能:
* 添加新的查找表提取:将查找项添加到 `includes/lookups` 目录下的 `.txt` 文件中。查找表应为按行分隔的条目列表,用于在文档中搜索。添加后,更新 `includes/extractions/lookup/config.yaml` 中的记录以指向你的查找表。添加完成后即可在脚本运行时使用。
* 添加新的 AI 提取:编辑 `includes/extractions/ai/config.yaml` 并添加一条新记录。可在配置中定制提示词以控制 LLM 的提取行为。
目前,其他类型的提取(需修改代码逻辑)尚无法轻松添加。
## 详细文档
如需详细了解 txt2stix 的工作原理,请参考 `/docs/README.md` 中的文档。
这些文档对希望添加自定义提取的用户特别有帮助。
## 支持
[通过 dogesec 社区获取基础支持](https://community.dogesec.com/)。
## 许可证
[Apache 2.0](/LICENSE)。标签:AI提取, DAST, IoC提取, STIX 2.1, TTP提取, 企业安全, 关系图谱, 基线检查, 威胁建模, 威胁情报, 开发者工具, 恶意软件分析, 情报共享, 情报可视化, 情报转换, 数据转换, 文本分析, 机器学习辅助, 网络安全, 网络资产管理, 逆向工具, 隐私保护