
[](https://docs.lmcache.ai/)
[](https://pypi.org/project/lmcache/)
[](https://pypi.org/project/lmcache/)
[](https://buildkite.com/lmcache/lmcache-unittests)
[](https://github.com/LMCache/LMCache/actions/workflows/code_quality_checks.yml)
[](https://buildkite.com/lmcache/lmcache-vllm-integration-tests)
[](https://www.bestpractices.dev/projects/10841)
[](https://scorecard.dev/viewer/?uri=github.com/LMCache/LMCache)
[](https://deepwiki.com/LMCache/LMCache/)
[](https://github.com/LMCache/LMCache/graphs/commit-activity)
[](https://pypi.org/project/lmcache/)
[](https://www.youtube.com/channel/UC58zMz55n70rtf1Ak2PULJA)
| [**博客**](https://blog.lmcache.ai/)
| [**文档**](https://docs.lmcache.ai/)
| [**加入 Slack**](https://join.slack.com/t/lmcacheworkspace/shared_invite/zt-3g8e6xzz8-KzS_HI8bPERGFK5PTB~MYg)
| [**意向表**](https://forms.gle/MHwLiYDU6kcW3dLj7)
| [**路线图**](https://github.com/LMCache/LMCache/issues/1253)
## 概述
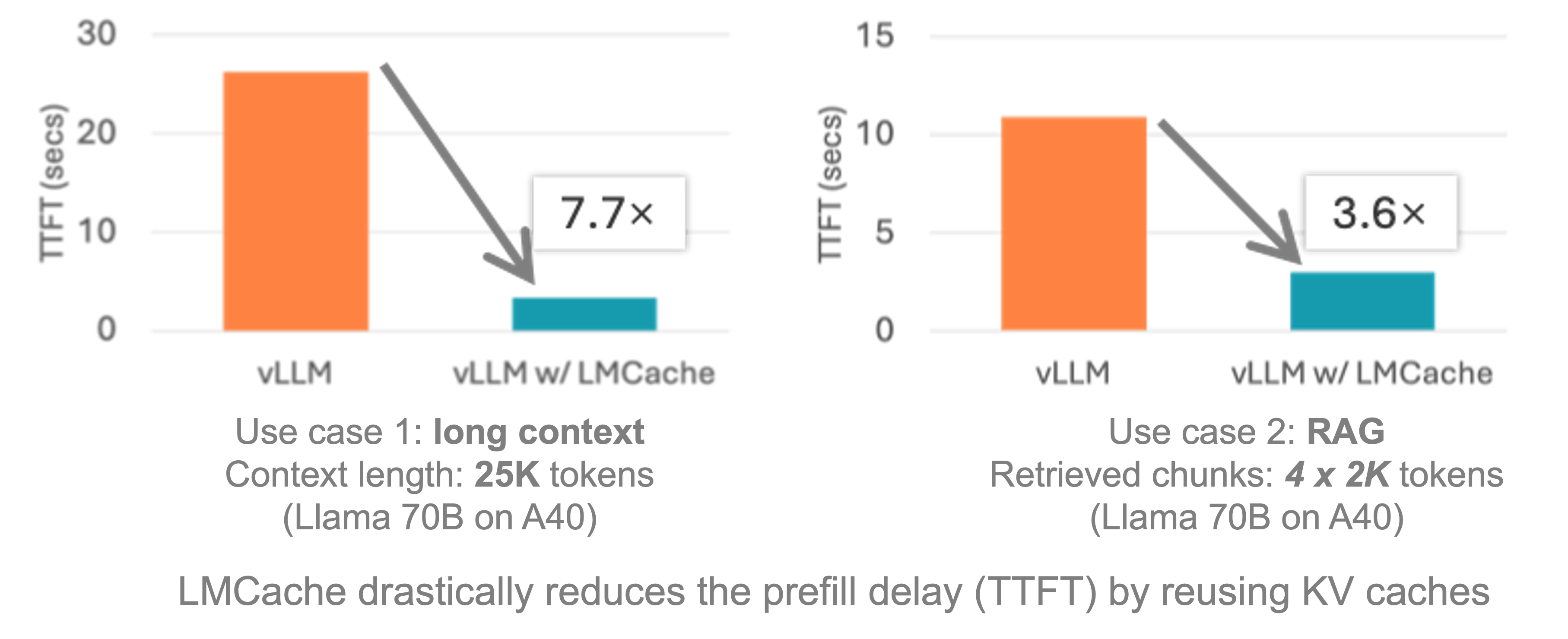
LMCache 是一个 **LLM** 服务引擎扩展,旨在 **降低 TTFT** 并 **提高吞吐量**,特别是在长上下文场景下。通过利用多种加速技术(如 zero cpu copy、NIXL、GDS 等)将可复用文本的 KV cache 存储在整个数据中心(包括 GPU、CPU、磁盘甚至 S3)中,LMCache 可以在 **_任何_** 服务引擎实例中复用 **_任何_** 可复用文本(不仅仅局限于前缀)的 KV cache。因此,LMCache 节省了宝贵的 GPU 周期并减少了用户响应延迟。
通过将 LMCache 与 vLLM 结合使用,开发人员在包括多轮 QA 和 RAG 在内的许多 LLM 用例中实现了 3-10 倍的延迟节省和 GPU 周期减少。
LMCache 在不断发展的 LLM 服务平台、基础设施提供商和开源生态系统项目中被使用、集成或引用:
- 由以下机构发起并官方支持:[Tensormesh](https://www.tensormesh.ai/)
- 被推理提供商采用:GMI cloud ([博客文章](https://www.gmicloud.ai/blog/gmi-cloud-achieves-4x-llm-performance-boost-with-tensormesh))、Google cloud ([博客文章](https://cloud.google.com/blog/topics/developers-practitioners/boosting-llm-performance-with-tiered-kv-cache-on-google-kubernetes-engine))、CoreWeave ([博客文章](https://www.coreweave.com/news/coreweave-unveils-ai-object-storage-redefining-how-ai-workloads-access-and-scale-data)) 等
- 与数据和存储基础设施提供商集成:Redis ([博客文章](https://redis.io/blog/get-faster-llm-inference-and-cheaper-responses-with-lmcache-and-redis/))、Weka ([博客文章](https://www.weka.io/blog/ai-ml/open-sourcing-gds-integration-from-augmented-memory-grid-see-results-for-yourself/))、PliOps ([博客文章](https://www.manilatimes.net/2025/03/12/tmt-newswire/globenewswire/pliops-announces-collaboration-with-vllm-production-stack-to-enhance-llm-inference-performance/2072000)) 等
- 被开源项目和平台使用:[vLLM](https://github.com/vllm-project/vllm) [](https://github.com/vllm-project/vllm), [SGLang](https://github.com/sgl-project/sglang) [](https://github.com/sgl-project/sglang), [vLLM Production Stack](https://github.com/vllm-project/production-stack) [](https://github.com/vllm-project/production-stack), [llm-d](https://github.com/llm-d/llm-d/) [](https://github.com/llm-d/llm-d), [NVIDIA dynamo](https://github.com/ai-dynamo/dynamo) [](https://github.com/ai-dynamo/dynamo), [KServe](https://github.com/kserve/kserve) [](https://github.com/kserve/kserve) 等。
欲了解更多详情,请查看我们的 [Ray Summit 演讲](https://www.youtube.com/watch?v=TwLd15HE6AM) 和 [技术报告](https://lmcache.ai/tech_report.pdf)。
## 功能特性
- [x] 🔥 与 vLLM v1 集成,包含以下功能:
* 高性能 CPU KVCache 卸载 (offloading)
* 分离式预填充 (Disaggregated prefill)
* P2P KVCache 共享
- [x] 与 SGLang 集成以进行 KV cache 卸载
- [x] 存储支持如下:
* CPU
* 磁盘
* [NIXL](https://github.com/ai-dynamo/nixl)
- [x] 通过 pip 和最新版 vLLM 提供安装支持
## 安装说明
要使用 LMCache,只需通过您的包管理器(例如 pip)安装 `lmcache`:
```
pip install lmcache
```
适用于 Linux NVIDIA GPU 平台。
文档中提供了更详细的[安装说明](https://docs.lmcache.ai/getting_started/installation),特别是当您未使用最新稳定版本的 vllm,或使用具有不同依赖项的其他服务引擎时。文档中可以解决任何“未定义符号 (undefined symbol)”或 torch 版本不匹配的问题。
## 快速入门
入门的最佳方式是查阅文档中的[快速入门示例](https://docs.lmcache.ai/getting_started/quickstart/)。
## 文档
请查阅在线提供的 LMCache [文档](https://docs.lmcache.ai/)。
我们也定期在 [LMCache 博客](https://blog.lmcache.ai/) 中发布文章。
## 示例
请亲自动手尝试我们的[示例](https://github.com/LMCache/LMCache/tree/dev/examples),
演示如何利用 LMCache 解决不同的使用案例。
## 有兴趣连接?
填写[意向表](https://forms.gle/mQfQDUXbKfp2St1z7)、[订阅我们的新闻简报](https://mailchi.mp/tensormesh/lmcache-sign-up-newsletter)、[加入 LMCache slack](https://join.slack.com/t/lmcacheworkspace/shared_invite/zt-3g8e6xzz8-KzS_HI8bPERGFK5PTB~MYg) 或[发送邮件](mailto:contact@lmcache.ai),我们的团队将与您联系!
## 社区会议
LMCache 的社区会议 [Zoom 链接]( https://uchicago.zoom.us/j/6603596916?pwd=Z1E5MDRWUSt2am5XbEt4dTFkNGx6QT09) 每两周举行一次。欢迎所有人加入!
会议每两周举行一次,时间为:周二上午 9:00 (PT) – [添加到 Google 日历](https://calendar.google.com/calendar/u/0/r?cid=Y19mNGY2ZmMwZjUxMWYyYTZmZmE1ZTVlMGI2Yzk2NmFmZjNhM2Y4ODZiZmU5OTU5MDJlMmE3ZmUyOGZmZThlOWY5QGdyb3VwLmNhbGVuZGFyLmdvb2dsZS5jb20)
我们将每次会议的记录保存在此[文档](https://docs.google.com/document/d/1_Fl3vLtERFa3vTH00cezri78NihNBtSClK-_1tSrcow)中,包含站会摘要、讨论和行动项。
会议录像可在 [YouTube LMCache 频道](https://www.youtube.com/channel/UC58zMz55n70rtf1Ak2PULJA) 上观看。
## 贡献指南
我们欢迎并重视所有贡献与合作。请查阅[贡献指南](CONTRIBUTING.md)以了解如何做出贡献。
我们会持续更新 [[Onboarding] Welcoming contributors with good first issues!](https://github.com/LMCache/LMCache/issues/627)
## 引用
如果您在研究中使用 LMCache,请引用我们的论文:
```
@inproceedings{liu2024cachegen,
title={Cachegen: Kv cache compression and streaming for fast large language model serving},
author={Liu, Yuhan and Li, Hanchen and Cheng, Yihua and Ray, Siddhant and Huang, Yuyang and Zhang, Qizheng and Du, Kuntai and Yao, Jiayi and Lu, Shan and Ananthanarayanan, Ganesh and others},
booktitle={Proceedings of the ACM SIGCOMM 2024 Conference},
pages={38--56},
year={2024}
}
@article{cheng2024large,
title={Do Large Language Models Need a Content Delivery Network?},
author={Cheng, Yihua and Du, Kuntai and Yao, Jiayi and Jiang, Junchen},
journal={arXiv preprint arXiv:2409.13761},
year={2024}
}
@inproceedings{10.1145/3689031.3696098,
author = {Yao, Jiayi and Li, Hanchen and Liu, Yuhan and Ray, Siddhant and Cheng, Yihua and Zhang, Qizheng and Du, Kuntai and Lu, Shan and Jiang, Junchen},
title = {CacheBlend: Fast Large Language Model Serving for RAG with Cached Knowledge Fusion},
year = {2025},
url = {https://doi.org/10.1145/3689031.3696098},
doi = {10.1145/3689031.3696098},
booktitle = {Proceedings of the Twentieth European Conference on Computer Systems},
pages = {94–109},
}
@article{cheng2025lmcache,
title={LMCache: An Efficient KV Cache Layer for Enterprise-Scale LLM Inference},
author={Cheng, Yihua and Liu, Yuhan and Yao, Jiayi and An, Yuwei and Chen, Xiaokun and Feng, Shaoting and Huang, Yuyang and Shen, Samuel and Du, Kuntai and Jiang, Junchen},
journal={arXiv preprint arXiv:2510.09665},
year={2025}
}
```
## 社交媒体
[Linkedin](https://www.linkedin.com/company/lmcache-lab/?viewAsMember=true) | [Twitter](https://x.com/lmcache) | [Youtube](https://www.youtube.com/@LMCacheTeam)
## 许可证
LMCache 代码库根据 Apache License 2.0 授权。详情请参阅 [LICENSE](LICENSE) 文件。