Phoenix0531-sudo/BondLens
GitHub: Phoenix0531-sudo/BondLens
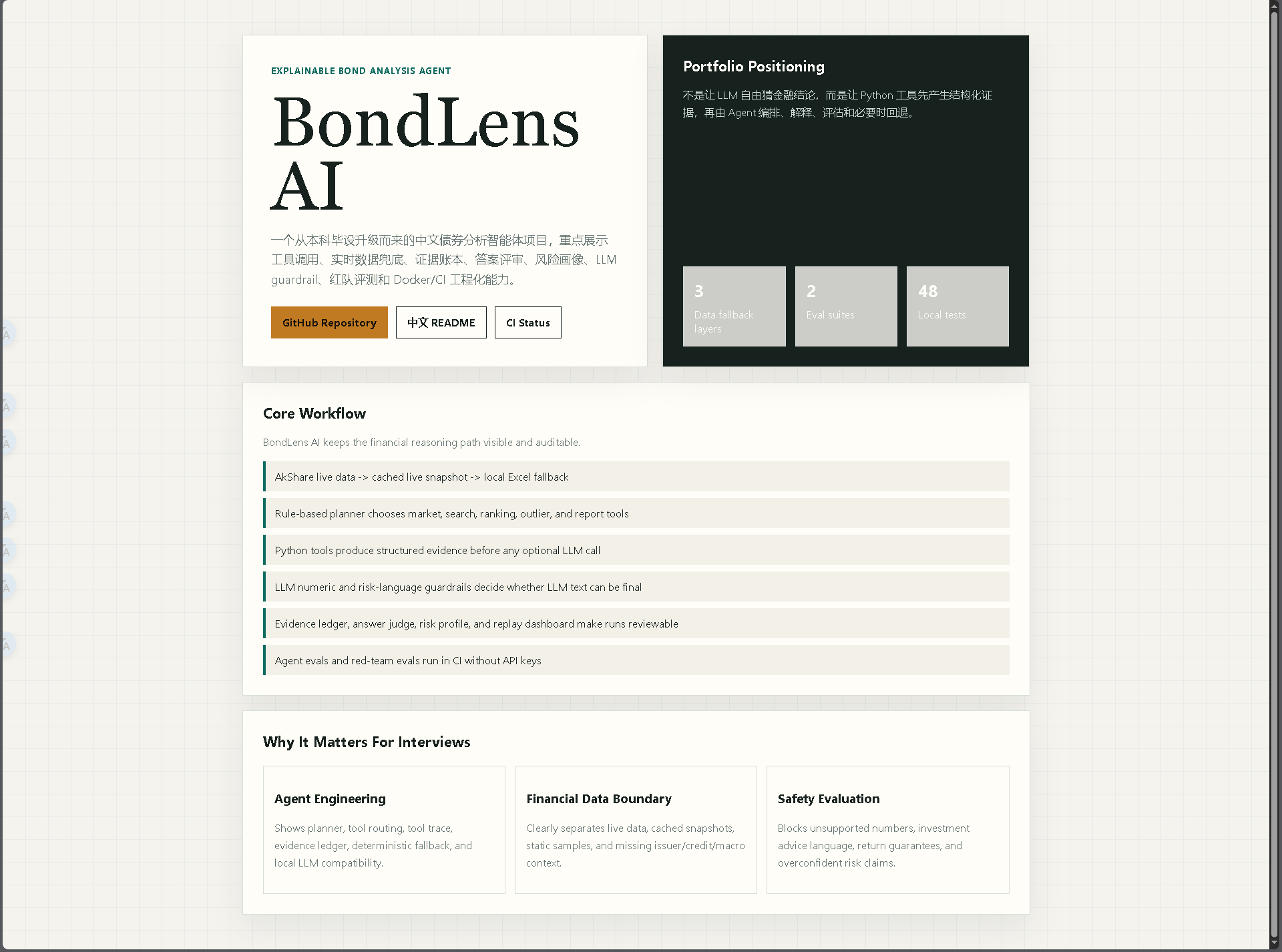
BondLens AI 是一个基于证据的中国债券市场分析智能体,通过实时数据、确定性工具链和 LLM 护栏,提供可解释、可审计的固定收益分析。
Stars: 3 | Forks: 1
# BondLens AI
**可解释债券分析 Agent**
[English](README.md) | [中文](README.zh-CN.md)

BondLens AI 是一个针对中国债券市场数据的轻量级、基于证据的分析 Agent。它默认使用 AkShare 实时债券市场数据,当无法访问实时数据时,会回退到最新缓存的实时快照;如果没有可用的快照,则回退到保留的本地 Excel 样本。每次回答都会返回一个结构化追踪记录,包含证据账本、回答评判器、风险概况、护栏状态和局限性说明。
项目主页:[https://phoenix0531-sudo.github.io/BondLens/](https://phoenix0531-sudo.github.io/BondLens/)
## 截图
## 背景
本项目最初是 2024 年的一个本科毕业设计项目:一个基于 Flask 的债券数据分析系统。原始的论文版本被保留下来,不应被重写:
- 原始论文分支:`undergraduate-thesis-2024`
- 当前分支:`main`
当前分支将毕业设计项目升级为 AI Agent / LLM 应用 / AI 工程师作品集项目,同时保留其历史渊源可见。
## 仓库结构
本仓库有意保留了两个长期分支:
- `main`:现代化的 BondLens AI 作品集项目
- `undergraduate-thesis-2024`:原始的本科毕业设计版本
没有保留发布标签,因为原始论文分支已是保留的历史版本。
## 为什么这是一个 Agent,而不是 Chatbot
BondLens AI 不会让 LLM 去猜测金融问题的答案。该 Agent 遵循一个小型的确定性循环:
1. **数据解析器** 优先加载 AkShare 实时债券数据,然后是缓存的实时快照,最后在需要时使用 `data/testdata.xlsx`。
2. **规划器** 对用户意图进行分类并选择工具。
3. **工具** 在活动数据帧上运行本地 Python 分析。
4. **证据** 作为结构化数据附加到响应中,并呈现为审查者可读的声明。
5. **报告** 基于证据生成,包含风险和局限性。
6. **可选 LLM** 只有在存在本地证据后才能润色回答。它支持 OpenAI 和兼容 OpenAI 的本地 endpoint(例如 Ollama)。
7. **LLM 护栏** 根据结构化证据检查数字声明和不安全的投资用语模式,如果 LLM 输出不安全,则回退到确定性报告。
8. **回答评判器** 记录模型输出是被接受、被护栏拒绝还是被绕过。
9. **证据账本、风险概况和重放存储** 使回答可审计,且无需在作品集 UI 中展示原始 JSON。
10. **Schema 契约** 在返回最终 API 响应之前,使用 Pydantic 对其进行验证。
如果未设置 `OPENAI_API_KEY`,项目仍可运行并使用确定性回退输出。
## 核心功能
- 意图规划:市场概览、债券搜索、排名、异常值检测、完整债券报告
- 工具追踪:每个规划器/工具步骤在 Web 页面和 API 响应中均可见
- 按名称、期限和收益率范围搜索债券
- 实时数据模式:AkShare `bond_spot_deal` 当前债券成交数据
- 证券主数据核对:由于 `bond_spot_deal` 不提供原生期限数据,匹配到的债券会从本地静态样本中进行数据丰富,并标记期限覆盖率元数据
- 缓存实时快照模式:当实时 endpoint 暂时失败时,重用最近成功的 AkShare 抓取结果
- 本地回退模式:`data/testdata.xlsx` 仍可用于离线演示和确定性测试
- 市场摘要:样本计数、收益率分布、成交量统计
- 按收益率、成交量、期限或价格排名
- 使用 z-score 进行收益率异常值检测
- 债券与市场对比:收益率百分位、成交量百分位、期限百分位、异常值状态
- 数据源概况:请求模式、实际 runtime 模式、提供商、抓取时间、回退原因以及遗留爬虫边界
- 针对固定收益概念的检索增强风险解释
- 带有置信度和新鲜度标签的证据质量评分
- 用于数字证据检查、不安全投资用语检查和安全回退的 LLM 忠实度护栏
- 证据账本:将工具输出转化为声明/证据/来源/置信度记录以供审查
- 回答评判器:解释 LLM 回答为何被接受、拒绝或绕过
- 结构化风险概况:数据质量、信用背景、流动性、久期、异常值和模型输出风险
- 重放仪表板:`/replay` 汇总最近的 Agent 运行情况,默认不暴露原始 JSON
- 使用 `/api/agent/schema` 的 Pydantic 响应 schema
- 用于容器和部署平台的轻量级 `/healthz` endpoint
- 用于可重复行为和安全检查的 Agent 评估和红队评估套件
- 使用 gunicorn 进行 Docker 部署
## Agent 工作流
```
flowchart TD
A[User Question] --> B[Data Source Resolver]
B --> C[Planner]
C --> D{Intent}
D -->|market_overview| E[describe_market]
D -->|bond_search| F[search_bonds]
D -->|ranking| G[rank_bonds]
D -->|outlier_detection| H[detect_yield_outliers]
D -->|bond_report| I[search_bonds + compare_bond_to_market + market/ranking/outlier tools]
E --> J[Structured Evidence]
F --> J
G --> J
H --> J
I --> J
J --> K[generate_bond_report]
K --> L[Risk explanation retrieval]
L --> M[Evidence quality assessment]
M --> N{OPENAI_API_KEY or OPENAI_BASE_URL}
N -->|missing| O[Deterministic fallback]
N -->|set| P[OpenAI or local LLM enhancement]
P --> Q[LLM numeric and language guardrail]
Q -->|passed| R[LLM final answer]
Q -->|numeric or language failure| S[Deterministic fallback answer]
R --> T[Answer Judge + Evidence Ledger + Risk Profile]
S --> T
O --> T
T --> U[Replay Dashboard]
```
## 工具追踪示例
```
User question: 搜索23附息国债26并给出收益率分析
-> data_source(mode=live, source=akshare_bond_spot_deal)
-> planner(intent=bond_report)
-> search_bonds(name=23附息国债26)
-> compare_bond_to_market()
-> describe_market()
-> rank_bonds(by=yield, top_n=5)
-> detect_yield_outliers(method=zscore, threshold=3.0)
-> generate_bond_report()
-> llm_guardrail(skipped: llm_disabled)
-> final answer
```
## 技术栈
- Python 3.11
- Flask
- AkShare
- Pandas / NumPy
- OpenPyXL
- OpenAI Python SDK(可选)
- Pytest + 本地 Agent 评估
- Docker Compose + gunicorn
- GitHub Actions CI
## 架构
```
.
├── app.py # Flask app entry
├── bond_agent/
│ ├── agent.py # Agent orchestration and LLM fallback status
│ ├── planner.py # Rule-based intent planner
│ ├── data_loader.py # AkShare live loading, snapshot cache, Excel fallback
│ ├── evidence_ledger.py # Claim/evidence/source/confidence ledger
│ ├── answer_judge.py # Deterministic judge for LLM acceptance/fallback
│ ├── risk_profile.py # Structured risk profile cards
│ ├── replay_store.py # Sanitized local run replay summaries
│ ├── risk_knowledge.py # Local fixed-income risk explanation retrieval
│ ├── evidence_quality.py # Evidence scoring, freshness, and confidence labels
│ ├── llm_guardrail.py # Numeric and risk-language checks for LLM answers
│ ├── schemas.py # Pydantic API request/response contracts
│ └── tools.py # Local bond analysis tools
├── data/testdata.xlsx # Static bond sample data
├── docs/index.html # GitHub Pages project page
├── docs/deployment.md # Docker, health check, and platform deployment notes
├── evals/
│ ├── agent_eval_cases.yml # Behavior cases
│ ├── red_team_eval_cases.yml # Safety boundary cases
│ ├── run_agent_evals.py # Local eval runner
│ └── run_red_team_evals.py # Red-team eval runner
├── templates/agent.html # Agent UI
├── templates/replay.html # Recent run replay dashboard
├── tests/ # Unit and smoke tests
├── LICENSE
├── Dockerfile
└── docker-compose.yml
```
## 使用 Docker 快速开始
```
docker compose up --build
```
打开:
```
http://localhost:5000/agent
```
容器运行 gunicorn:
```
gunicorn -b 0.0.0.0:5000 app:app
```
Compose 服务命名为 `bondlens-ai`,并使用 `/healthz` 进行轻量级的平台和容器健康检查。
## 本地开发
```
python -m pip install -r requirements-dev.txt
python app.py
```
打开:
```
http://localhost:5000/agent
```
## 环境变量
```
FLASK_ENV=production
SECRET_KEY=change-me-in-production
OPENAI_API_KEY=
OPENAI_MODEL=gpt-5.4-mini
OPENAI_BASE_URL=
OPENAI_API_STYLE=auto
OPENAI_TIMEOUT_SECONDS=20
BOND_DATA_MODE=auto
BOND_LIVE_CACHE_PATH=
BOND_LIVE_CACHE_MAX_AGE_HOURS=24
BOND_REPLAY_ENABLED=true
BOND_REPLAY_DIR=
```
- `SECRET_KEY`:Flask session 密钥。
- `OPENAI_API_KEY`:可选。如果为空,则使用确定性回退。
- `OPENAI_MODEL`:用于受证据约束的回答增强的可配置模型。
- `OPENAI_BASE_URL`:可选的兼容 OpenAI 的 endpoint。对于本地 Ollama,请使用 `http://127.0.0.1:11434/v1`。
- `OPENAI_API_STYLE`:`auto`、`responses` 或 `chat`。正常使用时保持 `auto`;本地 endpoint 通常使用 chat completions。
- `OPENAI_TIMEOUT_SECONDS`:可选的 LLM 请求超时时间。默认为 `20`,以便缓慢的本地模型能够安全回退,而不是导致 Web 服务器超时。
- `BOND_DATA_MODE`:`auto`、`live` 或 `static`。`auto` 会先尝试 AkShare,然后是缓存的实时快照,最后是本地 Excel 回退。
- `BOND_LIVE_CACHE_PATH`:AkShare 快照 CSV 的可选路径。默认为 `.tmp/bond_spot_deal_snapshot.csv`。
- `BOND_LIVE_CACHE_MAX_AGE_HOURS`:在使用静态回退之前接受的最大快照时效(小时)。默认为 `24`。
- `BOND_REPLAY_ENABLED`:设置为 `false` 以禁用本地运行重放摘要。默认为 `true`。
- `BOND_REPLAY_DIR`:可选的重放目录。默认为 `.tmp/replays`,该目录会被 Git 忽略。
本地 Ollama 冒烟测试示例:
```
set OPENAI_BASE_URL=http://127.0.0.1:11434/v1
set OPENAI_MODEL=qwen2.5:1.5b
set OPENAI_API_STYLE=chat
python app.py
```
对于不需要身份验证的本地兼容 OpenAI 的 endpoint,`OPENAI_API_KEY` 可以保留为空。
小型本地模型对于验证 LLM 路径是否能够端到端运行非常有用,但确定性证据字段仍然是审查和调试的真理来源。
在 Windows 或 macOS 上使用 Docker 时,请将容器指向宿主机的 Ollama 服务:
```
set OPENAI_BASE_URL=http://host.docker.internal:11434/v1
docker compose up --build
```
API 响应会暴露安全的 LLM 状态:
```
{
"used_llm": false,
"used_llm_in_final": false,
"llm_status": "disabled",
"llm_error": null,
"llm_guardrail": {
"status": "not_run",
"numeric_status": "not_run",
"language_status": "not_run"
}
}
```
## 示例问题
```
当前样本收益率分布是什么样?
搜索23附息国债26并给出收益率分析
按收益率列出最高的前5只债券
按成交量列出最活跃的前5只债券
按期限列出最长的前5只债券
有没有收益率异常的债券?
筛选收益率大于 3 的债券
```
## API
```
POST /api/agent/query
Content-Type: application/json
{
"question": "搜索23附息国债26并给出收益率分析",
"data_mode": "auto"
}
```
关键响应字段:
- `plan`:规划器意图、选定工具、排名/搜索参数
- `tools_used`:实际用于该回答的工具
- `tool_trace`:人类可读的步骤追踪
- `data_evidence`:机器可读的市场/搜索/排名/异常值/对比证据
- `data_source`:活动数据源概况,包括请求模式、runtime 模式、提供商、抓取时间、行数和回退原因
- `risk_explanations`:检索到的固定收益风险解释
- `evidence_quality`:评分、置信度标签、覆盖率、新鲜度和惩罚项
- `evidence_ledger`:审查者可读的声明、证据、来源、工具和置信度记录
- `answer_judge`:LLM 输出的最终回答接受/拒绝状态
- `risk_profile`:结构化的数据质量、信用、流动性、久期、异常值和模型风险卡片
- `final_answer`:通过护栏的 LLM 回答,或确定性报告
- `final_answer_source`:`llm` 或 `deterministic_fallback`
- `llm_enhanced_answer`:可用时保留用于调试的原始 LLM 回答
- `llm_guardrail`:数字忠实度状态、不安全风险用语状态、评分、不支持的数字声明以及被阻止的短语
- `llm_status`:`disabled`、`success` 或 `failed`
其他操作 endpoint:
```
GET /healthz
GET /api/agent/schema
GET /replay
```
`/api/agent/schema` 返回请求、响应、健康检查和错误 payload 的 Pydantic JSON schema。
`/replay` 显示经过脱敏处理的最近运行摘要,用于面试演示和调试重放。
部署说明可在 [docs/deployment.md](docs/deployment.md) 中查看。
## 数据源边界
当前 Agent 路径采用实时优先的数据策略:
```
Primary: AkShare bond_spot_deal
Snapshot: .tmp/bond_spot_deal_snapshot.csv
Final fallback: data/testdata.xlsx
```
AkShare 将 `bond_spot_deal` 记录为 ChinaMoney 的当前债券成交市场接口。BondLens AI 使用的原生字段包括债券名称、净价、最新收益率、BP 变化、加权收益率和成交量。实时 endpoint 不提供期限数据,因此 BondLens AI 从本地静态样本中丰富匹配的债券名称,并在 `data_source` 中报告 `maturity_coverage`。
默认 runtime 模式是 `auto`:首先抓取实时数据,将归一化结果写入本地 CSV 快照,并在后续实时请求失败时使用该快照。如果实时抓取和快照回退均不可用或已过期,Agent 将回退到本地工作簿。`/agent` 页面和 API 还支持:
```
auto -> live first, cached snapshot second, local fallback third
live -> live source requested; fallback reason is shown if it degrades
static -> local Excel only
```
本地回退仍然是:
```
data/testdata.xlsx
```
该工作簿包含 3000 多条债券样本数据,字段包括债券名称、期限、净价、收盘收益率、加权收益率和成交量。它用于离线演示、确定性 CI 和回退行为。
实时快照默认有意存储在 `.tmp/` 下,并且不提交到 Git。这样既能保持仓库整洁,又能在公共 endpoint 暂时不可用时使本地演示具有弹性。
遗留爬虫作为毕业设计时期的历史代码保留在 `undergraduate-thesis-2024` 中。它针对旧的 CNSTOCK 新闻页面,依赖 MongoDB 和毕业设计时期的文本分析模块,不存在于当前 `main` 的 runtime 中。在 2026 年 5 月 26 日的仓库验证期间,旧的 CNSTOCK HTTP endpoint 对自动请求返回 `403 Forbidden`,因此本项目不将它们作为活跃或可靠的实时数据源呈现。
## 风险解释层
BondLens AI 包含一个针对固定收益风险概念的本地检索增强解释层。在 Python 工具生成证据后,Agent 会从精选的本地知识库中检索相关片段,涵盖:
- 收益率解释
- 流动性风险
- 期限和久期敏感性
- 收益率异常值审查
- 信用背景局限性
- 实时/静态数据边界
这使得解释有理有据且可重复,无需外部向量数据库或实时 LLM 调用。
## 证据质量
每次 Agent 回答都包含一个 `evidence_quality` 对象,具有:
- `score`:当前回答的 0-100 证据质量评分
- `level`:当前活动证据集的低、中或高置信度
- `analysis_confidence`:对描述性分析的置信度
- `decision_confidence`:故意设为低,因为未附加发行人评级、信用事件、宏观曲线和完整的证券主数据
- `data_freshness`:`live_fetch`、`cached_live_snapshot` 或 `static_snapshot`
- `coverage`:哪些证据块可用
- `penalties`:限制结论的缺失上下文
## 证据账本、回答评判器和重放
默认 Web UI 避免使用原始 JSON/类似代码的诊断面板。相反,它呈现:
- **证据账本**:从活动工具输出派生的声明/证据/来源/置信度记录。
- **回答评判器**:一个确定性接受层,显示 LLM 文本是被接受、被护栏拒绝还是被绕过。
- **概况**:用于数据质量、信用背景、流动性、久期、收益率异常值和模型输出风险的结构化卡片。
- **重放仪表板**:`/replay` 默认将脱敏后的运行摘要存储在 `.tmp/replays` 下。
原始的机器可读契约仍可通过 `/api/agent/query` 和 `/api/agent/schema` 获取。
## Agent 评估
运行确定性行为检查:
```
python evals/run_agent_evals.py
```
运行红队安全检查:
```
python evals/run_red_team_evals.py
```
评估套件检查:
- 预期的规划器意图
- 预期的工具
- 必需的回答关键词
- 可选的禁止回答关键词
- 投资建议和保证收益边界案例
它不会调用 OpenAI。
## 测试
```
python -m pytest -q
```
覆盖范围包括:
- 规划器意图分类
- 感知意图的工具路由
- 数据源元数据
- 风险解释检索
- 证据质量评估
- 市场统计
- 排名工具
- 收益率异常值检测
- 债券与市场对比
- 具体债券报告行为
- 带有 mock 的 LLM 禁用/成功/失败状态
- LLM 数字和不安全风险用语护栏
- 证据账本、回答评判器、风险概况和重放存储
- Pydantic Agent 响应 schema
- 健康检查和 schema endpoint
- 实时快照缓存回退
- Flask 页面/API 冒烟测试
- 评估案例加载
## 仓库策略
公共仓库有意保持紧凑:源代码、测试、评估、Docker、文档、截图、CI 和许可证。通用的社区模板已被移除,因为这是一个个人作品集项目,而不是开源协作中心。
推荐的分支策略是保护 `main`,并要求在合并之前通过 CI 工作流。原始论文分支仍作为历史参考,不应接收现代功能开发。
## 数据边界
所有金融结论均根据每个响应中显示的活动数据源计算得出:
```
AkShare bond_spot_deal, the cached AkShare snapshot, or data/testdata.xlsx when static/fallback mode is active
```
Agent 不会捏造发行人评级、信用事件、宏观观点或投资建议。遗留爬虫代码仅保留在论文分支中;当前 `main` 分支使用 AkShare 实时数据加上本地 Excel 回退。
## 现代项目清理
`main` 分支移除了遗留的登录/数据库代码、过时的爬虫代码、旧的论文 UI 页面、IDE 元数据和未引用的静态数据转储。这是安全的,因为:
- `undergraduate-thesis-2024` 保留了原始仓库状态。
- 当前 Flask 路由仅服务于 BondLens AI 及其 API。
- 核心债券样本数据、Agent 代码、测试、Docker 和 README 文档均予保留。
## 面试讨论点
- **工具调用设计**:确定性规划器将用户意图映射到本地 Python 工具。
- **实时优先源设计**:AkShare 实时数据为默认设置,具有缓存的实时快照和静态回退层以保障可靠性。
- **证据约束**:最终回答基于 `data_evidence` 生成,而非自由形式的金融猜测。
- **证据账本**:UI 将数据证据转化为可审计的声明,而不是倾倒原始 JSON。
- **本地 LLM 兼容性**:兼容 OpenAI 的 endpoint 无需付费 API 密钥即可执行 LLM 路径。
- **LLM 护栏**:在 LLM 回答成为最终回答之前,会检查数字声明和不安全的投资用语。
- **回答评判器和重放**:被接受/拒绝的模型输出可见,并且可以审查最近的运行。
- **回退设计**:无需 API 密钥;OpenAI/本地 LLM 路径是可选且可观察的。
- **风险边界**:输出始终包含局限性和非投资建议语言。
- **评估方法**:本地行为评估和红队评估测试意图、工具选择、回答约束和安全边界。
- **Docker 化**:gunicorn runtime、健康检查和可重现的依赖安装。
- **遗留迁移**:保留原始论文版本,清理现代分支以供作品集使用。
## 路线图
- 在实时市场 Feed 周围添加发行人评级、债券主数据和收益率曲线背景
- 将 RAG 从本地片段扩展到文档支持的检索
- 添加 PDF/Markdown 报告导出
- 在实时快照和静态回退之间添加更丰富的证据一致性评估
- 添加久期、凸性、信用利差和流动性分桶
- 在有稳定的债券详细信息数据源时,添加后台证券主数据刷新任务
## 许可证
MIT。在使用本项目进行学习、作品集审查或面试讨论时,请保持论文来源和作者背景可见。
## 免责声明
BondLens AI 不提供投资建议、交易建议、评级意见或收益保证。输出仅供学习、研究和工程演示使用。
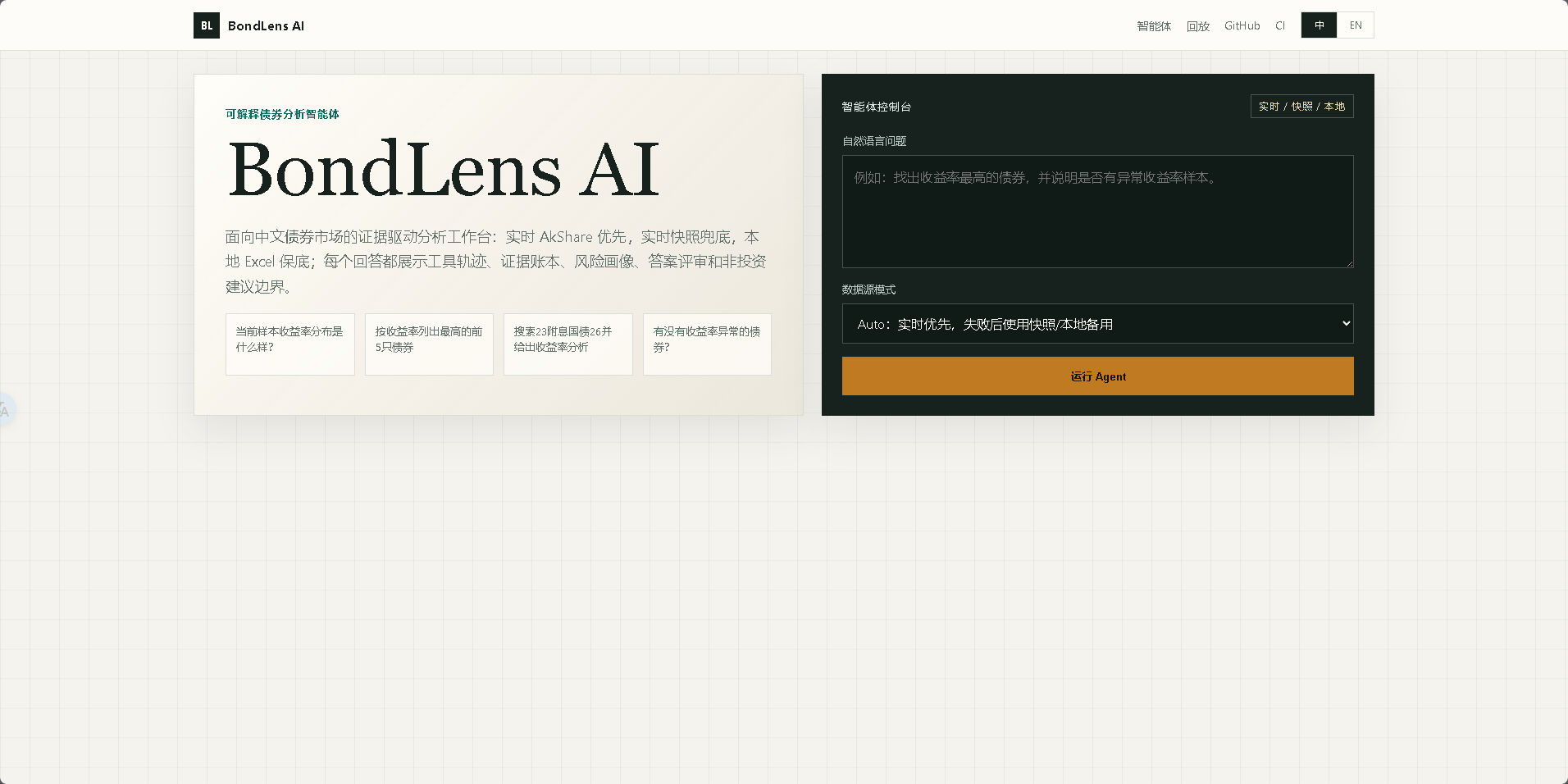
Agent Workbench |
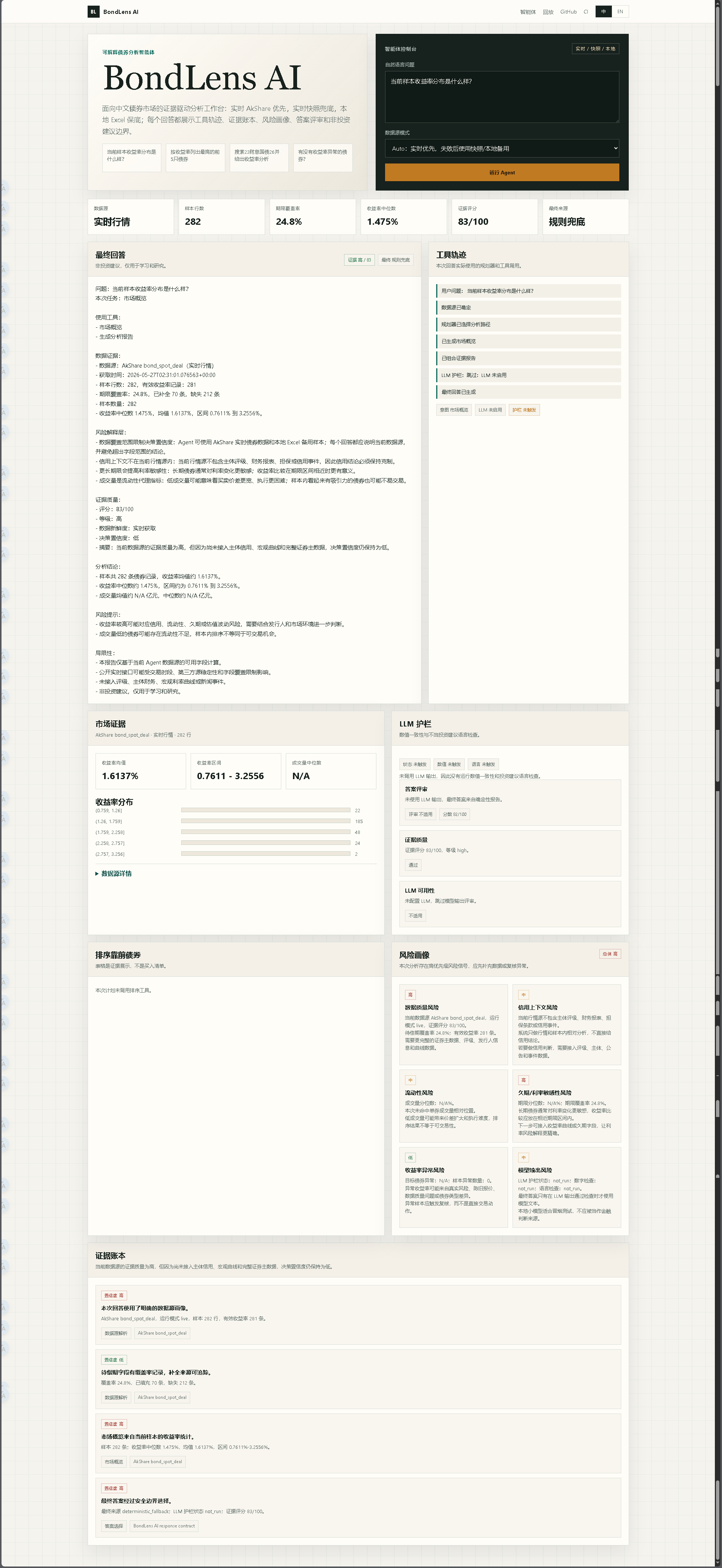
Answer, Tool Trace, and Evidence |
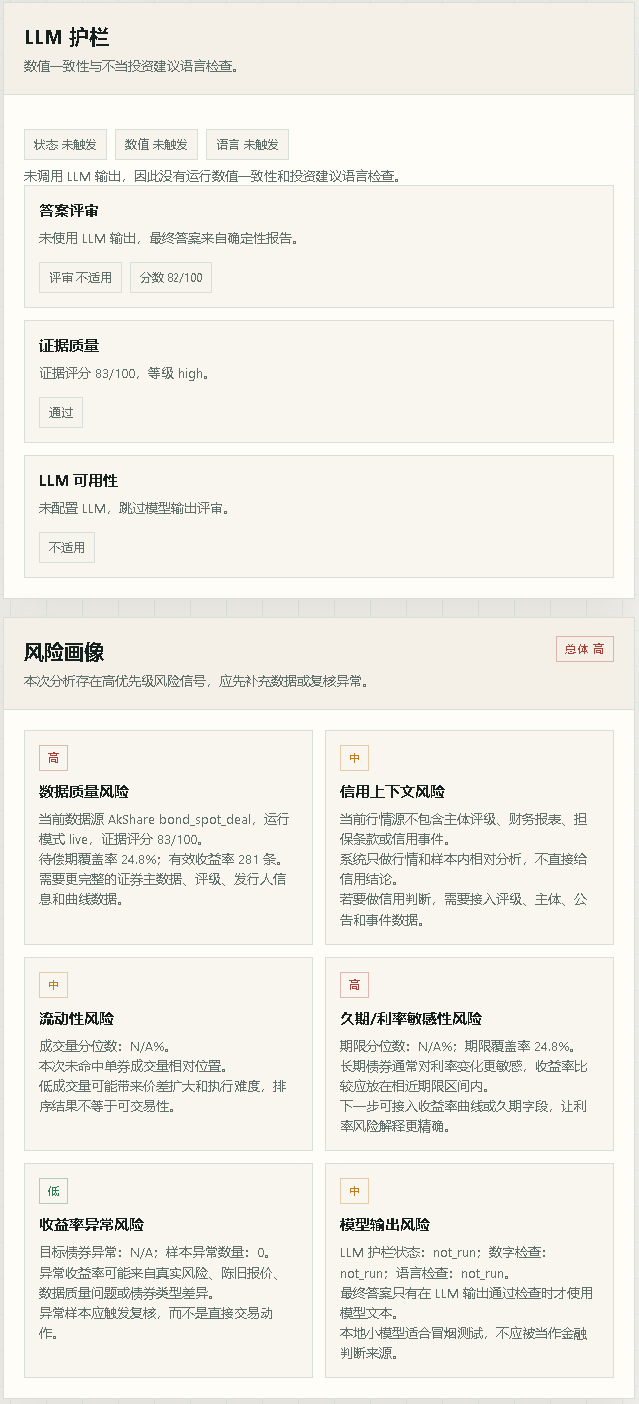
Risk Profile and Answer Judge |
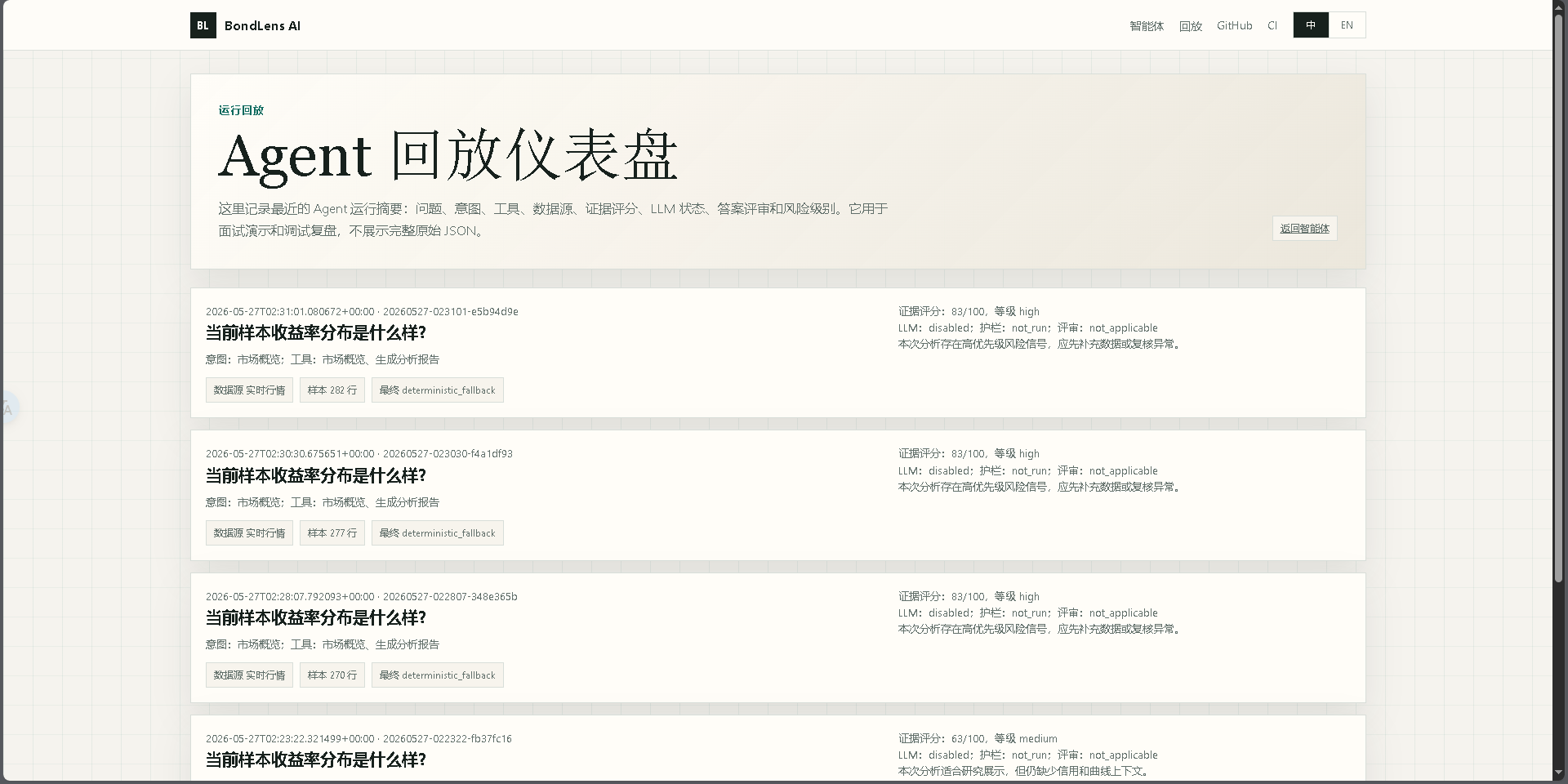
Replay Dashboard |
GitHub Pages Project Page |
Live-first data, deterministic tools, optional LLM enhancement, guardrails, replay, Docker, and CI in one portfolio-ready project. |
标签:AI智能体, DLL 劫持, Flask, 债券分析, 大语言模型, 版权保护, 请求拦截, 逆向工具, 金融科技