intentee/paddler
GitHub: intentee/paddler
Paddler 是一个用于自托管大语言模型的开源负载均衡器,简化私有化部署和扩展。
Stars: 1644 | Forks: 91
# Paddler
 数字产品及其用户需要隐私保护、可靠性、成本控制,以及摆脱闭源模型供应商依赖的选择。
Paddler 是一款开源的 LLM 负载均衡器和服务平台。它允许您在自己的基础设施上运行推理、部署和扩展 LLM,并在此过程中提供卓越的开发者体验。
## 核心特性
数字产品及其用户需要隐私保护、可靠性、成本控制,以及摆脱闭源模型供应商依赖的选择。
Paddler 是一款开源的 LLM 负载均衡器和服务平台。它允许您在自己的基础设施上运行推理、部署和扩展 LLM,并在此过程中提供卓越的开发者体验。
## 核心特性
 * 通过内置的 [llama.cpp](https://github.com/ggml-org/llama.cpp) 引擎进行推理
* 专为 LLM 设计的负载均衡
* 通过可动态添加的代理工作,支持与自动扩缩工具集成
* 请求缓冲,支持从零主机开始扩展
* 动态模型热切换
* 内置网页管理面板,用于管理、监控和测试
* 可观测性指标
## Paddler 的适用对象
* 需要在功能中集成 LLM 推理和嵌入的产品团队
* 需要大规模运行和部署 LLM 的 DevOps/LLMOps 团队
* 处理敏感数据、具有高合规性和隐私要求(如医疗、金融等)的组织
* 希望实现可预测的 LLM 成本,而非按 token 定价的组织
* 需要可靠模型性能以维持其 AI 功能一致用户体验的产品负责人
## 安装与快速开始
Paddler 以单一二进制文件的形式独立存在,因此要开始使用,您只需获取 `paddler` 二进制文件并使其在系统中可用即可。
您可以通过以下方式获取二进制文件:
* 选项 1:从我们的 [GitHub releases](https://github.com/intentee/paddler/releases) 下载最新版本
* 选项 2:或者从源代码构建 Paddler(MSRV 为 *1.88.0*)
### 使用 Paddler
一旦您使二进制文件在系统中可用,即可开始使用 Paddler。所有 Paddler 功能都可通过 `paddler` 命令访问(运行 `paddler --help` 将列出所有可用命令)。
只有两个可部署组件:`balancer`(负责分发传入请求)和 `agent`(负责通过插槽生成 token 和嵌入)。
要启动负载均衡器,请运行:
```
paddler balancer --inference-addr 127.0.0.1:8061 --management-addr 127.0.0.1:8060 --web-admin-panel-addr 127.0.0.1:8062
```
`--web-admin-panel-addr` 标志是可选的,但它允许您在网页浏览器中查看您的设置。
要启动一个具有 4 个插槽的代理,请运行:
```
paddler agent --management-addr 127.0.0.1:8060 --slots 4
```
阅读更多关于 [安装](https://paddler.intentee.com/docs/introduction/installation/) 和 [设置基本集群](https://paddler.intentee.com/docs/starting-out/set-up-a-basic-llm-cluster/) 的信息。
## 文档与资源
- 访问我们的 [文档页面](https://paddler.intentee.com/docs/introduction/what-is-paddler/) 以安装 Paddler 并开始使用。
- [API 文档](https://paddler.intentee.com/api/introduction/using-paddler-api/) 也已可用。
- [视频概述](https://www.youtube.com/watch?v=aT6QCL8lk08)
- [FOSEDM 2026 演讲](https://fosdem.org/2026/schedule/event/PD8WGF-from_infrastructure_to_production_a_year_of_self-hosted_llms/) - 从基础设施到生产:自托管 LLM 的一年。
## 工作原理
Paddler 为轻松设置而构建。它是一个独立的二进制文件,只包含两个可部署组件:`balancer` 和 `agents`。
`balancer` 暴露以下服务:
- 推理服务(应用程序连接至此以获取 token 或嵌入)
- 管理服务,用于内部管理 Paddler 的设置
- 网页管理面板,允许您查看和测试您的 Paddler 设置
`Agents` 通常部署在单独的实例上。它们进一步将传入请求分发给 `slots`,这些插槽负责生成 token 和嵌入。
Paddler 使用内置的 llama.cpp 引擎进行推理,但实现了自己的 llama.cpp 插槽,这些插槽保持独立的上下文和 KV 缓存。
### 网页管理面板
Paddler 附带内置的网页管理面板。
您可以用它来监控您的 Paddler 集群:
* 通过内置的 [llama.cpp](https://github.com/ggml-org/llama.cpp) 引擎进行推理
* 专为 LLM 设计的负载均衡
* 通过可动态添加的代理工作,支持与自动扩缩工具集成
* 请求缓冲,支持从零主机开始扩展
* 动态模型热切换
* 内置网页管理面板,用于管理、监控和测试
* 可观测性指标
## Paddler 的适用对象
* 需要在功能中集成 LLM 推理和嵌入的产品团队
* 需要大规模运行和部署 LLM 的 DevOps/LLMOps 团队
* 处理敏感数据、具有高合规性和隐私要求(如医疗、金融等)的组织
* 希望实现可预测的 LLM 成本,而非按 token 定价的组织
* 需要可靠模型性能以维持其 AI 功能一致用户体验的产品负责人
## 安装与快速开始
Paddler 以单一二进制文件的形式独立存在,因此要开始使用,您只需获取 `paddler` 二进制文件并使其在系统中可用即可。
您可以通过以下方式获取二进制文件:
* 选项 1:从我们的 [GitHub releases](https://github.com/intentee/paddler/releases) 下载最新版本
* 选项 2:或者从源代码构建 Paddler(MSRV 为 *1.88.0*)
### 使用 Paddler
一旦您使二进制文件在系统中可用,即可开始使用 Paddler。所有 Paddler 功能都可通过 `paddler` 命令访问(运行 `paddler --help` 将列出所有可用命令)。
只有两个可部署组件:`balancer`(负责分发传入请求)和 `agent`(负责通过插槽生成 token 和嵌入)。
要启动负载均衡器,请运行:
```
paddler balancer --inference-addr 127.0.0.1:8061 --management-addr 127.0.0.1:8060 --web-admin-panel-addr 127.0.0.1:8062
```
`--web-admin-panel-addr` 标志是可选的,但它允许您在网页浏览器中查看您的设置。
要启动一个具有 4 个插槽的代理,请运行:
```
paddler agent --management-addr 127.0.0.1:8060 --slots 4
```
阅读更多关于 [安装](https://paddler.intentee.com/docs/introduction/installation/) 和 [设置基本集群](https://paddler.intentee.com/docs/starting-out/set-up-a-basic-llm-cluster/) 的信息。
## 文档与资源
- 访问我们的 [文档页面](https://paddler.intentee.com/docs/introduction/what-is-paddler/) 以安装 Paddler 并开始使用。
- [API 文档](https://paddler.intentee.com/api/introduction/using-paddler-api/) 也已可用。
- [视频概述](https://www.youtube.com/watch?v=aT6QCL8lk08)
- [FOSEDM 2026 演讲](https://fosdem.org/2026/schedule/event/PD8WGF-from_infrastructure_to_production_a_year_of_self-hosted_llms/) - 从基础设施到生产:自托管 LLM 的一年。
## 工作原理
Paddler 为轻松设置而构建。它是一个独立的二进制文件,只包含两个可部署组件:`balancer` 和 `agents`。
`balancer` 暴露以下服务:
- 推理服务(应用程序连接至此以获取 token 或嵌入)
- 管理服务,用于内部管理 Paddler 的设置
- 网页管理面板,允许您查看和测试您的 Paddler 设置
`Agents` 通常部署在单独的实例上。它们进一步将传入请求分发给 `slots`,这些插槽负责生成 token 和嵌入。
Paddler 使用内置的 llama.cpp 引擎进行推理,但实现了自己的 llama.cpp 插槽,这些插槽保持独立的上下文和 KV 缓存。
### 网页管理面板
Paddler 附带内置的网页管理面板。
您可以用它来监控您的 Paddler 集群:
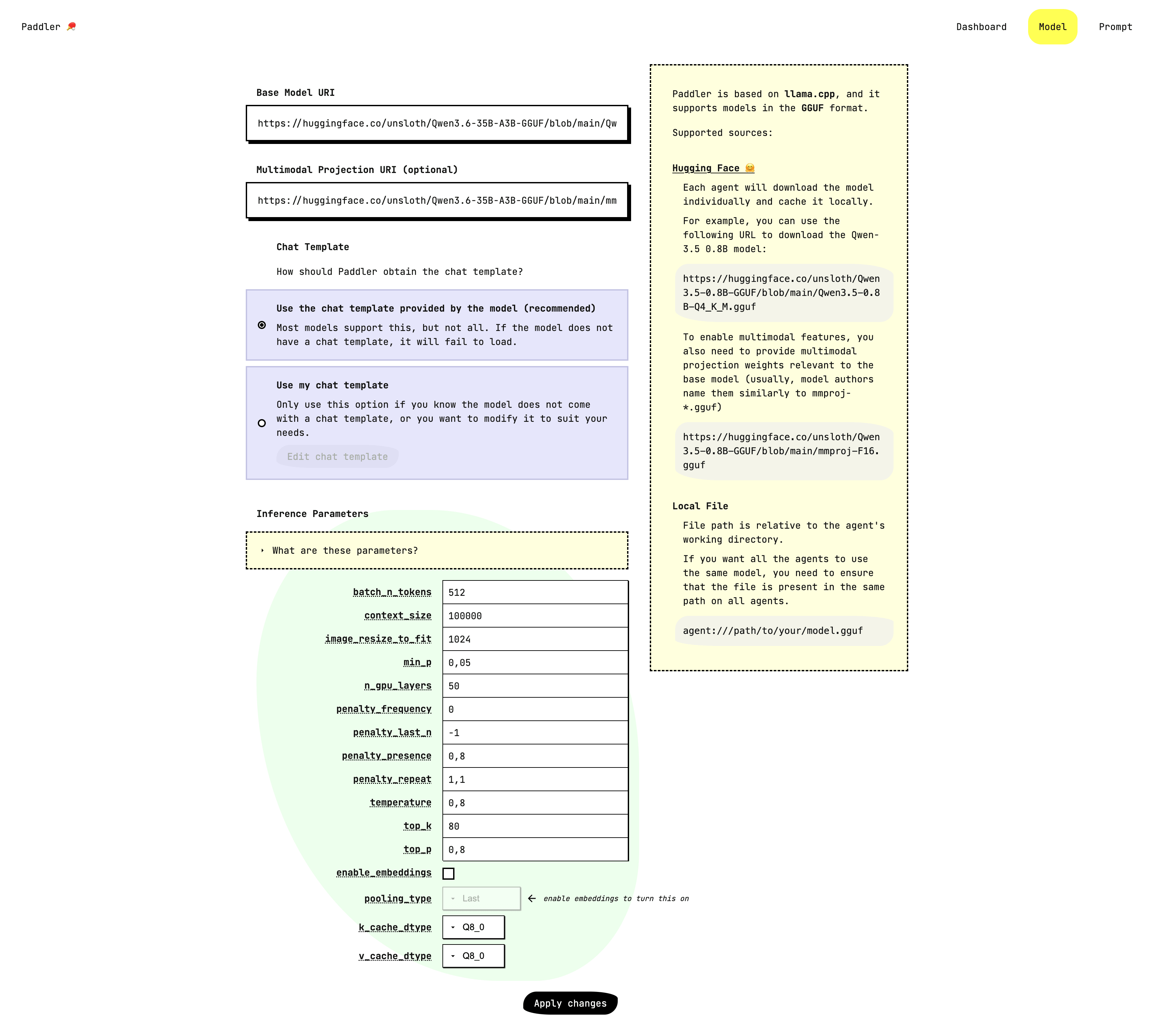
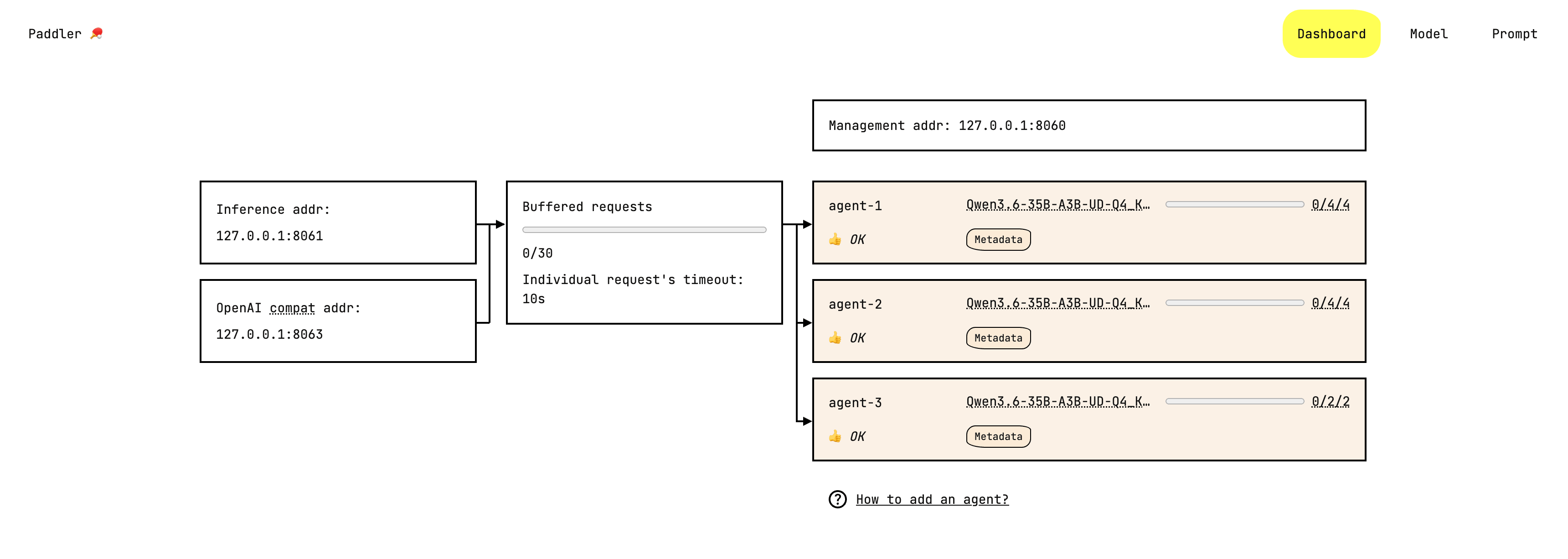 添加和更新您的模型,自定义聊天模板和推理参数:
添加和更新您的模型,自定义聊天模板和推理参数:
 并使用 GUI 测试推理:
并使用 GUI 测试推理:
 ### 桌面应用程序 (测试版)
Paddler 有两个版本:用于基础设施的命令行界面,以及用于更休闲使用场景的桌面应用程序,例如在本地 AI 集群中使用多台笔记本电脑和台式机,或设置整个办公室范围的“第二大脑”,而无需使用控制台。
您也可以混合使用两者;例如,您可以在服务器机架上设置一个 Paddler 负载均衡器,并让办公室里拥有 RTX 5090 的同事在其不需要全部算力时临时作为代理接入。
在这个版本上,您可以尽情发挥。 :)
参阅 [桌面应用程序文档](https://paddler.intentee.com/docs/desktop-app/introduction/) 开始使用。
### 桌面应用程序 (测试版)
Paddler 有两个版本:用于基础设施的命令行界面,以及用于更休闲使用场景的桌面应用程序,例如在本地 AI 集群中使用多台笔记本电脑和台式机,或设置整个办公室范围的“第二大脑”,而无需使用控制台。
您也可以混合使用两者;例如,您可以在服务器机架上设置一个 Paddler 负载均衡器,并让办公室里拥有 RTX 5090 的同事在其不需要全部算力时临时作为代理接入。
在这个版本上,您可以尽情发挥。 :)
参阅 [桌面应用程序文档](https://paddler.intentee.com/docs/desktop-app/introduction/) 开始使用。
 ## 入门指南
* [设置一个基本的 LLM 集群](https://paddler.intentee.com/docs/starting-out/set-up-a-basic-llm-cluster/)
* [使用 Paddler 的网页管理面板](https://paddler.intentee.com/docs/starting-out/using-web-admin-panel/)
* [生成 token 和嵌入](https://paddler.intentee.com/docs/starting-out/generating-tokens-and-embeddings/)
* [使用函数调用](https://paddler.intentee.com/docs/starting-out/using-function-calling/)
* [使用语法](https://paddler.intentee.com/docs/starting-out/using-grammars/)
* [使用多模态模型](https://paddler.intentee.com/docs/starting-out/using-multimodal-models/)
* [创建多代理集群](https://paddler.intentee.com/docs/starting-out/multi-agent-fleet/)
* [超越单设备限制](https://paddler.intentee.com/docs/starting-out/going-beyond-a-single-device/)
## 是否接受 AI 生成的代码?
项目中的所有代码都经过人工审核,并且大部分是手工编写的。我们一直在尝试使用 AI 生成部分代码,迄今为止,我们在以下方面取得了成功:
- 编写和维护连接到核心库的 HTTP 客户端
- [为 Paddler 创建集成测试套件,我们能够几乎自动地将所有现有测试整合到使用新的、改进后的测试套件中](https://github.com/intentee/paddler/pull/220)
如果您成功生成了某些代码,可以提交。我们仍然需要进行审核,因此请确保您明白自己在做什么。
不过,您可以尝试。:) 我们甚至添加了 [CLAUDE.md](CLAUDE.md),其中包含一些代码风格和其他基本说明。
## 名称由来
我们最初想使用 [Raft](https://raft.github.io/) 共识算法(因此叫 Paddler,因为它在 Raft 上划桨),但最终放弃了这个想法。不过,名称保留了下来。
后来,人们开始给我们发送《辛普森一家》中“那可要挨板子了”的片段,我们就欣然接受了。
## 致谢
[
## 入门指南
* [设置一个基本的 LLM 集群](https://paddler.intentee.com/docs/starting-out/set-up-a-basic-llm-cluster/)
* [使用 Paddler 的网页管理面板](https://paddler.intentee.com/docs/starting-out/using-web-admin-panel/)
* [生成 token 和嵌入](https://paddler.intentee.com/docs/starting-out/generating-tokens-and-embeddings/)
* [使用函数调用](https://paddler.intentee.com/docs/starting-out/using-function-calling/)
* [使用语法](https://paddler.intentee.com/docs/starting-out/using-grammars/)
* [使用多模态模型](https://paddler.intentee.com/docs/starting-out/using-multimodal-models/)
* [创建多代理集群](https://paddler.intentee.com/docs/starting-out/multi-agent-fleet/)
* [超越单设备限制](https://paddler.intentee.com/docs/starting-out/going-beyond-a-single-device/)
## 是否接受 AI 生成的代码?
项目中的所有代码都经过人工审核,并且大部分是手工编写的。我们一直在尝试使用 AI 生成部分代码,迄今为止,我们在以下方面取得了成功:
- 编写和维护连接到核心库的 HTTP 客户端
- [为 Paddler 创建集成测试套件,我们能够几乎自动地将所有现有测试整合到使用新的、改进后的测试套件中](https://github.com/intentee/paddler/pull/220)
如果您成功生成了某些代码,可以提交。我们仍然需要进行审核,因此请确保您明白自己在做什么。
不过,您可以尝试。:) 我们甚至添加了 [CLAUDE.md](CLAUDE.md),其中包含一些代码风格和其他基本说明。
## 名称由来
我们最初想使用 [Raft](https://raft.github.io/) 共识算法(因此叫 Paddler,因为它在 Raft 上划桨),但最终放弃了这个想法。不过,名称保留了下来。
后来,人们开始给我们发送《辛普森一家》中“那可要挨板子了”的片段,我们就欣然接受了。
## 致谢
[ ](https://github.com/ggml-org/llama.cpp)
](https://github.com/ggml-org/llama.cpp)
数字产品及其用户需要隐私保护、可靠性、成本控制,以及摆脱闭源模型供应商依赖的选择。
Paddler 是一款开源的 LLM 负载均衡器和服务平台。它允许您在自己的基础设施上运行推理、部署和扩展 LLM,并在此过程中提供卓越的开发者体验。
## 核心特性
* 通过内置的 [llama.cpp](https://github.com/ggml-org/llama.cpp) 引擎进行推理
* 专为 LLM 设计的负载均衡
* 通过可动态添加的代理工作,支持与自动扩缩工具集成
* 请求缓冲,支持从零主机开始扩展
* 动态模型热切换
* 内置网页管理面板,用于管理、监控和测试
* 可观测性指标
## Paddler 的适用对象
* 需要在功能中集成 LLM 推理和嵌入的产品团队
* 需要大规模运行和部署 LLM 的 DevOps/LLMOps 团队
* 处理敏感数据、具有高合规性和隐私要求(如医疗、金融等)的组织
* 希望实现可预测的 LLM 成本,而非按 token 定价的组织
* 需要可靠模型性能以维持其 AI 功能一致用户体验的产品负责人
## 安装与快速开始
Paddler 以单一二进制文件的形式独立存在,因此要开始使用,您只需获取 `paddler` 二进制文件并使其在系统中可用即可。
您可以通过以下方式获取二进制文件:
* 选项 1:从我们的 [GitHub releases](https://github.com/intentee/paddler/releases) 下载最新版本
* 选项 2:或者从源代码构建 Paddler(MSRV 为 *1.88.0*)
### 使用 Paddler
一旦您使二进制文件在系统中可用,即可开始使用 Paddler。所有 Paddler 功能都可通过 `paddler` 命令访问(运行 `paddler --help` 将列出所有可用命令)。
只有两个可部署组件:`balancer`(负责分发传入请求)和 `agent`(负责通过插槽生成 token 和嵌入)。
要启动负载均衡器,请运行:
```
paddler balancer --inference-addr 127.0.0.1:8061 --management-addr 127.0.0.1:8060 --web-admin-panel-addr 127.0.0.1:8062
```
`--web-admin-panel-addr` 标志是可选的,但它允许您在网页浏览器中查看您的设置。
要启动一个具有 4 个插槽的代理,请运行:
```
paddler agent --management-addr 127.0.0.1:8060 --slots 4
```
阅读更多关于 [安装](https://paddler.intentee.com/docs/introduction/installation/) 和 [设置基本集群](https://paddler.intentee.com/docs/starting-out/set-up-a-basic-llm-cluster/) 的信息。
## 文档与资源
- 访问我们的 [文档页面](https://paddler.intentee.com/docs/introduction/what-is-paddler/) 以安装 Paddler 并开始使用。
- [API 文档](https://paddler.intentee.com/api/introduction/using-paddler-api/) 也已可用。
- [视频概述](https://www.youtube.com/watch?v=aT6QCL8lk08)
- [FOSEDM 2026 演讲](https://fosdem.org/2026/schedule/event/PD8WGF-from_infrastructure_to_production_a_year_of_self-hosted_llms/) - 从基础设施到生产:自托管 LLM 的一年。
## 工作原理
Paddler 为轻松设置而构建。它是一个独立的二进制文件,只包含两个可部署组件:`balancer` 和 `agents`。
`balancer` 暴露以下服务:
- 推理服务(应用程序连接至此以获取 token 或嵌入)
- 管理服务,用于内部管理 Paddler 的设置
- 网页管理面板,允许您查看和测试您的 Paddler 设置
`Agents` 通常部署在单独的实例上。它们进一步将传入请求分发给 `slots`,这些插槽负责生成 token 和嵌入。
Paddler 使用内置的 llama.cpp 引擎进行推理,但实现了自己的 llama.cpp 插槽,这些插槽保持独立的上下文和 KV 缓存。
### 网页管理面板
Paddler 附带内置的网页管理面板。
您可以用它来监控您的 Paddler 集群:
添加和更新您的模型,自定义聊天模板和推理参数:
并使用 GUI 测试推理:
### 桌面应用程序 (测试版)
Paddler 有两个版本:用于基础设施的命令行界面,以及用于更休闲使用场景的桌面应用程序,例如在本地 AI 集群中使用多台笔记本电脑和台式机,或设置整个办公室范围的“第二大脑”,而无需使用控制台。
您也可以混合使用两者;例如,您可以在服务器机架上设置一个 Paddler 负载均衡器,并让办公室里拥有 RTX 5090 的同事在其不需要全部算力时临时作为代理接入。
在这个版本上,您可以尽情发挥。 :)
参阅 [桌面应用程序文档](https://paddler.intentee.com/docs/desktop-app/introduction/) 开始使用。
## 入门指南
* [设置一个基本的 LLM 集群](https://paddler.intentee.com/docs/starting-out/set-up-a-basic-llm-cluster/)
* [使用 Paddler 的网页管理面板](https://paddler.intentee.com/docs/starting-out/using-web-admin-panel/)
* [生成 token 和嵌入](https://paddler.intentee.com/docs/starting-out/generating-tokens-and-embeddings/)
* [使用函数调用](https://paddler.intentee.com/docs/starting-out/using-function-calling/)
* [使用语法](https://paddler.intentee.com/docs/starting-out/using-grammars/)
* [使用多模态模型](https://paddler.intentee.com/docs/starting-out/using-multimodal-models/)
* [创建多代理集群](https://paddler.intentee.com/docs/starting-out/multi-agent-fleet/)
* [超越单设备限制](https://paddler.intentee.com/docs/starting-out/going-beyond-a-single-device/)
## 是否接受 AI 生成的代码?
项目中的所有代码都经过人工审核,并且大部分是手工编写的。我们一直在尝试使用 AI 生成部分代码,迄今为止,我们在以下方面取得了成功:
- 编写和维护连接到核心库的 HTTP 客户端
- [为 Paddler 创建集成测试套件,我们能够几乎自动地将所有现有测试整合到使用新的、改进后的测试套件中](https://github.com/intentee/paddler/pull/220)
如果您成功生成了某些代码,可以提交。我们仍然需要进行审核,因此请确保您明白自己在做什么。
不过,您可以尝试。:) 我们甚至添加了 [CLAUDE.md](CLAUDE.md),其中包含一些代码风格和其他基本说明。
## 名称由来
我们最初想使用 [Raft](https://raft.github.io/) 共识算法(因此叫 Paddler,因为它在 Raft 上划桨),但最终放弃了这个想法。不过,名称保留了下来。
后来,人们开始给我们发送《辛普森一家》中“那可要挨板子了”的片段,我们就欣然接受了。
## 致谢
[](https://github.com/ggml-org/llama.cpp)标签:AI平台, API集成, CPU推理, DLL 劫持, ggml框架, GPU推理, llama.cpp, MLOps, Rust语言, 动态扩展, 可观测性, 可视化界面, 基础设施, 多模态模型, 大语言模型, 成本控制, 服务部署, 模型交换, 模型推理, 监控, 管理面板, 网络安全, 自动缩放, 自托管平台, 请求缓冲, 负载均衡, 通知系统, 隐私保护