spaceandtimefdn/sxt-proof-of-sql
GitHub: spaceandtimefdn/sxt-proof-of-sql
一个高性能的零知识 SQL 证明器,通过密码学保证查询结果未被篡改,支持亚秒级生成针对百万行数据的可验证计算证明。
Stars: 5405 | Forks: 610
# SQL 证明
## 示例
Proof of SQL 附带演示其用法的示例代码。您可以在 `crates/proof-of-sql/examples` 文件夹中找到这些示例。以下是如何运行其中一些示例的说明:
### "Hello World" 示例
"Hello World" 示例演示了如何针对以下表生成并验证查询 `SELECT b FROM table WHERE a = 2` 的证明:
| a | b |
|------------|-------------|
| 1 | hi |
| 2 | hello |
| 3 | there |
| 2 | world |
#### 运行
```
cargo run --example hello_world
```
#### 输出
```
Warming up GPU... 520.959485ms
Loading data... 3.229767ms
Parsing Query... 1.870256ms
Generating Proof... 467.45371ms
Verifying Proof... 7.106864ms
Valid proof!
Query result: OwnedTable { table: {Ident { value: "b", quote_style: None }: VarChar(["hello", "world"])} }
```
有关该示例及其实现的详细说明,请参阅 [README](https://github.com/spaceandtimelabs/sxt-proof-of-sql/blob/main/crates/proof-of-sql/examples/hello_world/README.md) 和 [hello_world/main.rs](https://github.com/spaceandtimelabs/sxt-proof-of-sql/blob/main/crates/proof-of-sql/examples/hello_world/main.rs) 中的源代码。
### CSV 数据库示例
CSV 数据库示例演示了一个具有 Proof of SQL 功能的简单 CSV 后端数据库的实现。
安装示例:
```
cargo install --example posql_db --path crates/proof-of-sql #TODO: update once this is published to crates.io
```
有关如何在 CSV 后端数据库中创建、追加、证明和验证查询的详细使用说明和示例,请参阅 [README](https://github.com/spaceandtimelabs/sxt-proof-of-sql/blob/main/crates/proof-of-sql/examples/posql_db/README.md) 和 [posql_db/main.rs](https://github.com/spaceandtimelabs/sxt-proof-of-sql/blob/main/crates/proof-of-sql/examples/posql_db/main.rs) 中的源代码。
## 基准测试
Proof of SQL 针对速度和效率进行了优化。以下是它如此快速的原因:
1. 我们使用数据的**原生、预计算的承诺**。换句话说,当向数据库添加数据时,我们会计算数据的“摘要”,从而有效地“锁定”该数据。我们没有使用大多数区块链中使用的基于 Merkle 树的承诺,而是使用了 Proof of SQL 本身固有的承诺方案。
2. SQL 适合进行**自然的算术化**,这意味着与围绕指令/顺序计算设计的其他证明系统相比,它的开销非常小。相反,Proof of SQL 从一开始就是考虑到数据处理和并行性而设计的。
3. 我们在证明器中最昂贵的密码学计算上使用了**GPU 加速**。我们使用 [Blitzar](https://github.com/spaceandtimelabs/blitzar) 作为我们的加速框架。
### 设置
我们使用 NVIDIA A100 GPU(NC A100 v4 系列 Azure 虚拟机)运行基准测试。
为了运行这些基准测试,我们首先生成一个填充了随机数据的大型表,如下所示:



非 Linux 和/或非 GPU 机器的替代方案。
* 替代方案 #1:通过设置 `BLITZAR_BACKEND` 环境变量来启用 Blitzar 的 CPU 版本。示例: export BLITZAR_BACKEND=cpu cargo test --all-features --all-targets * 替代方案 #2:在仓库中禁用 `blitzar` 特性。示例 cargo test --no-default-features --features="arrow cpu-perf"a (BIGINT) | b (BIGINT) | c (VARCHAR) ---|---|--- 17717 | -1 | Z 11651 | -3 | W -9563 | -2 | dS -6435 | -2 | x -8338 | -1 | jI 12420 | -2 | DX 11546 | -3 | 18292 | 2 | 6500 | -1 | C 16219 | 2 | D5
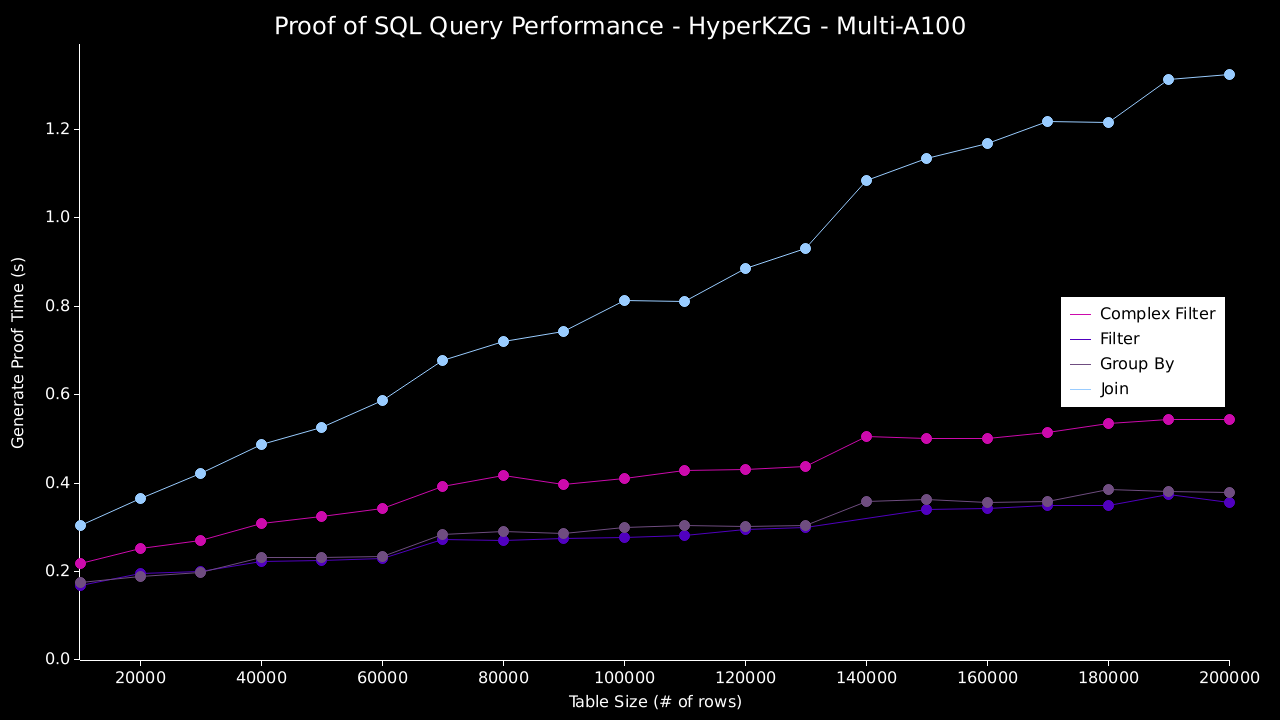
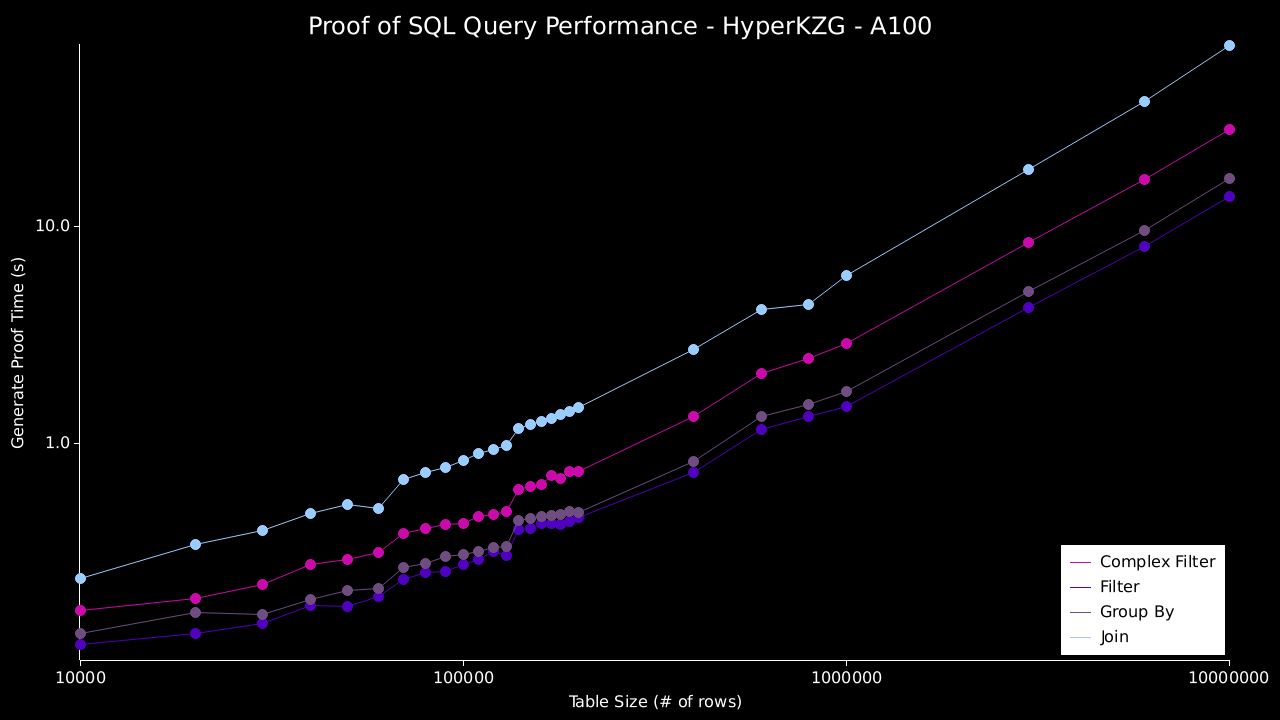
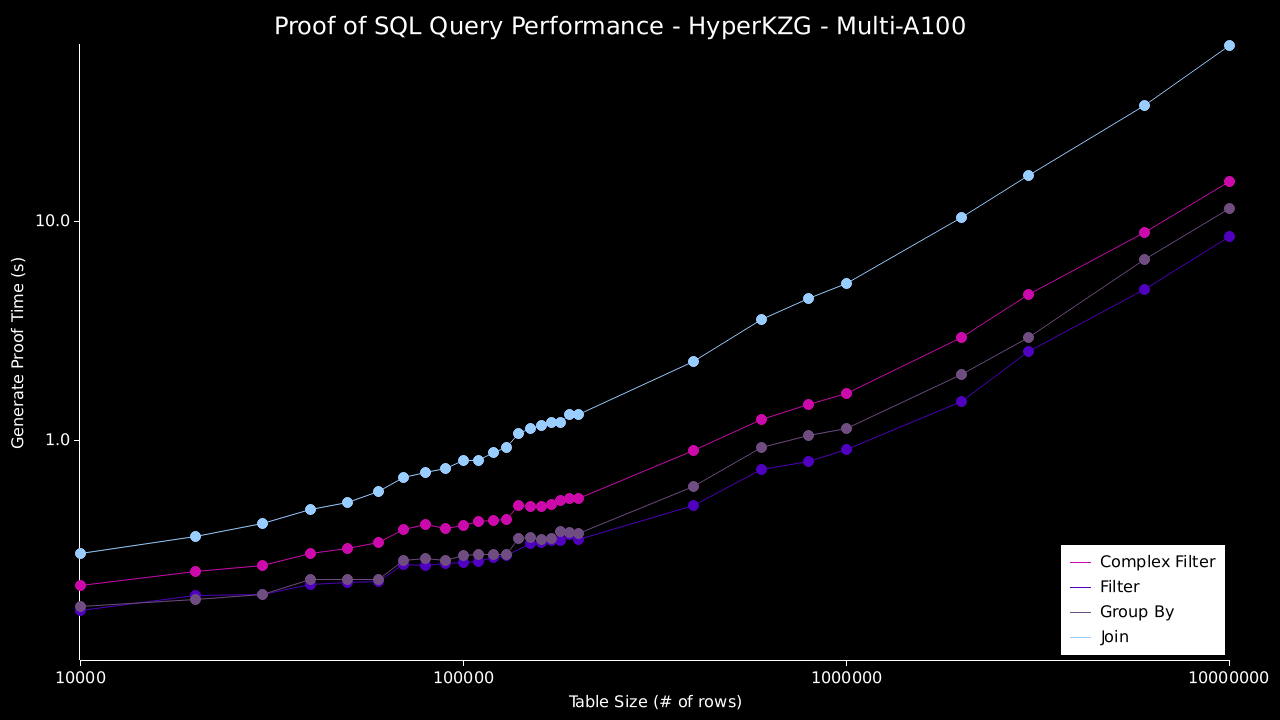
然后,我们针对这些数据运行以下 4 个查询,并证明和验证结果: * 过滤 - `SELECT b FROM bench_table WHERE a = 0` * 复杂过滤 - `SELECT * FROM bench_table WHERE (((a = 0) AND (b = 1)) OR ((c = 'a') AND (d = 'b')))` * 分组 - `SELECT SUM(a), COUNT(*) FROM bench_table WHERE a = 0 GROUP BY b` * 连接 - `SELECT table_a.column, table_b.column FROM table_a JOIN table_b on table_a.column=table_b.column` ### 结果 下图展示了在单台和多台 A100 机器上使用 `HyperKZG` 承诺方案的结果。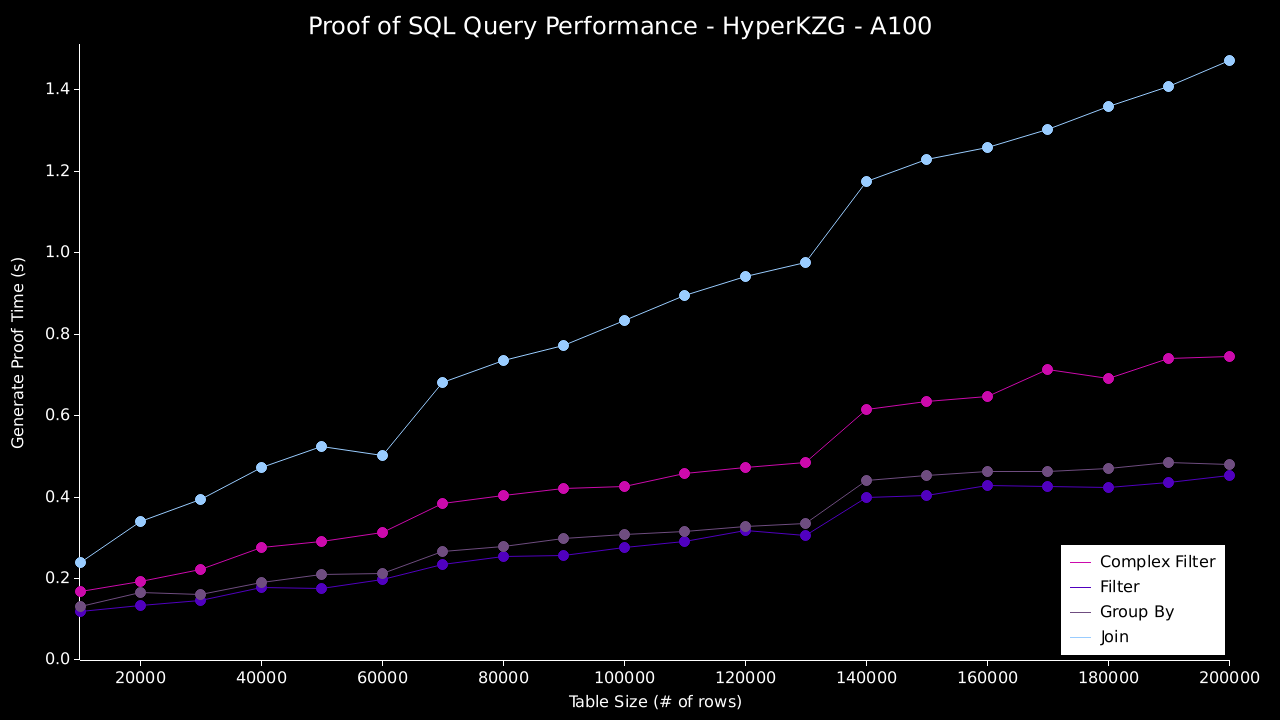
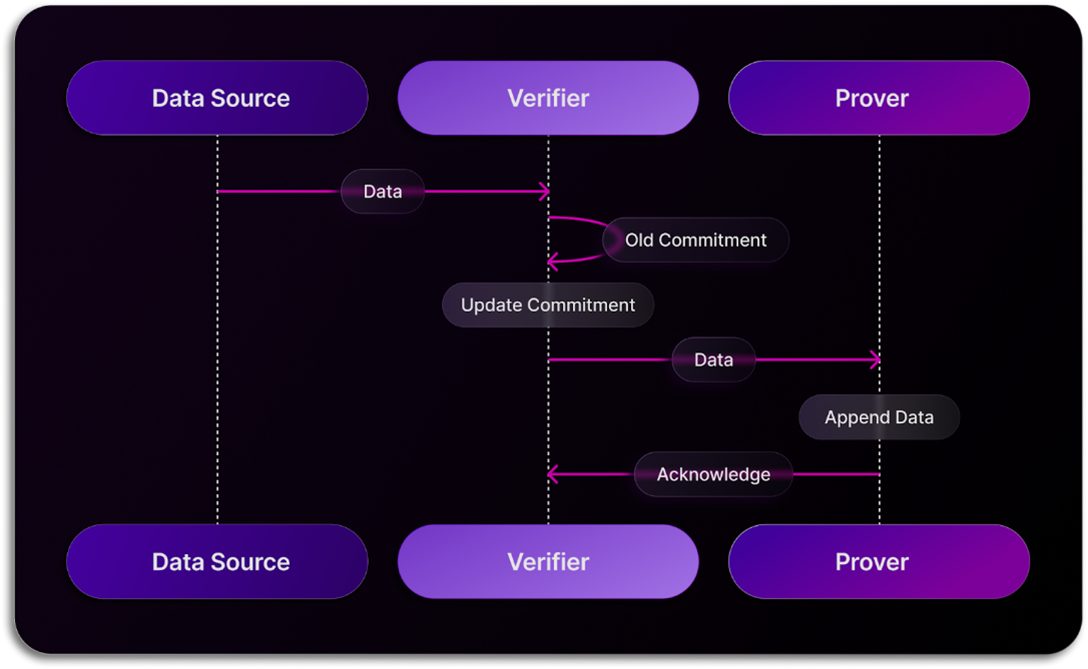
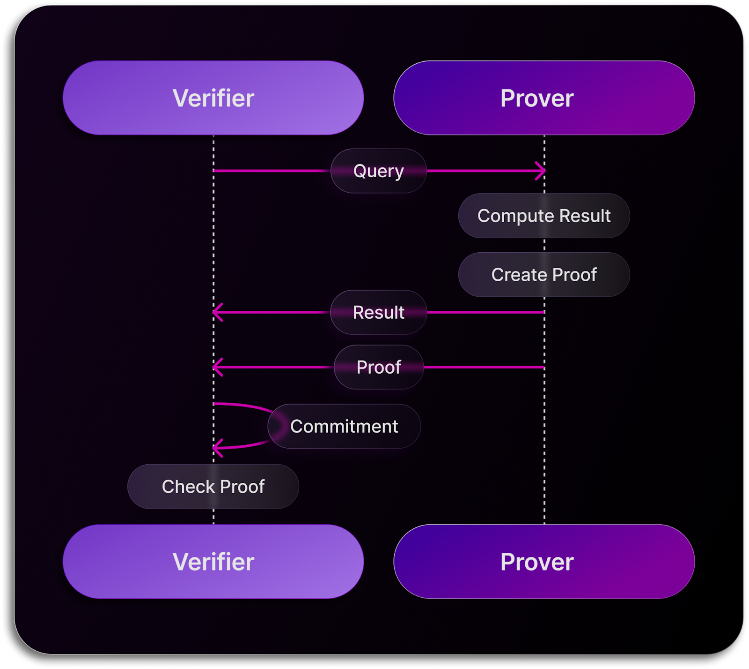
标签:SQL数据库, Web3, 区块链, 可视化界面, 多线程, 密码学, 手动系统调用, 数据验证, 智能合约, 通知系统, 零知识证明