
# STORM:通过检索和多视角提问合成主题大纲
| 研究预览 | STORM 论文| Co-STORM 论文 | 网站 |
**最新消息** 🔥
- [2025/01] 我们在 `knowledge-storm` v1.1.0 中添加了针对语言模型和 embedding 模型的 [litellm](https://github.com/BerriAI/litellm) 集成。
- [2024/09] Co-STORM 代码库现已发布并集成到 `knowledge-storm` Python 包 v1.0.0 中。运行 `pip install knowledge-storm --upgrade` 来体验。
- [2024/09] 我们推出了协作式 STORM (Co-STORM) 以支持人机协作的知识构建 已被 EMNLP 2024 主会议接收。
- [2024/07] 您现在可以通过 `pip install knowledge-storm` 安装我们的包了!
- [2024/07] 我们添加了 `VectorRM` 以支持基于用户提供的文档进行检索,补充了对现有搜索引擎(`YouRM`、`BingSearch`)的支持。(查看 [#58](https://github.com/stanford-oval/storm/pull/58))
- [2024/07] 我们为开发者发布了 demo light,这是一个使用 Python 中的 streamlit 框架构建的最小化用户界面,非常方便用于本地开发和演示托管(查看 [#54](https://github.com/stanford-oval/storm/pull/54))
- [2024/06] 我们将在 NAACL 2024 上展示 STORM!6 月 17 日在 Poster Session 2 找到我们,或者查看我们的[演讲材料](assets/storm_naacl2024_slides.pdf)。
- [2024/05] 我们在 [rm.py](knowledge_storm/rm.py) 中添加了 Bing 搜索支持。使用 `GPT-4o` 测试 STORM —— 我们现在在演示中使用 `GPT-4o` 模型来配置文章生成部分。
- [2024/04] 我们发布了重构后的 STORM 代码库!我们为 STORM pipeline 定义了[接口](knowledge_storm/interface.py),并重新实现了 STORM-wiki(查看 [`src/storm_wiki`](knowledge_storm/storm_wiki))以演示如何实例化该 pipeline。我们提供了 API 来支持自定义不同的语言模型以及检索/搜索集成。
[](https://github.com/psf/black)
## 概述 [(立即体验 STORM!)](https://storm.genie.stanford.edu/)

STORM is a LLM system that writes Wikipedia-like articles from scratch based on Internet search. Co-STORM further enhanced its feature by enabling human to collaborative LLM system to support more aligned and preferred information seeking and knowledge curation.
尽管该系统无法直接生成可以直接发布的文章(这通常需要进行大量的编辑),但经验丰富的 Wikipedia 编辑发现它在预写作阶段非常有帮助。
**已有超过 70,000 人体验了我们的[在线研究预览](https://storm.genie.stanford.edu/)。快来尝试一下,看看 STORM 如何助力您的知识探索之旅,并请提供反馈以帮助我们改进系统 🙏!**
## STORM 和 Co-STORM 的工作原理
### STORM
STORM 将生成带引用的长文章分解为两个步骤:
1. **预写作阶段**:系统进行基于互联网的研究以收集参考文献,并生成大纲。
2. **写作阶段**:系统使用大纲和参考文献生成带引用的完整文章。
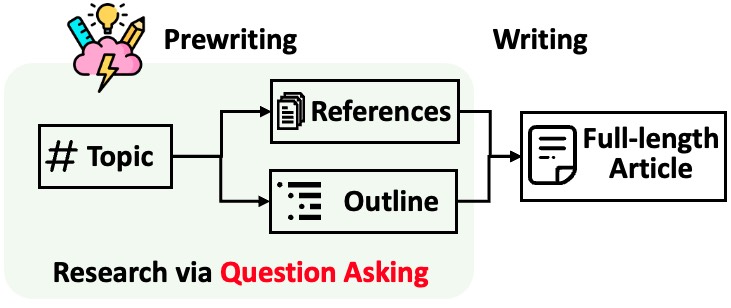
STORM 将自动化研究过程的核心确定为自动提出好的问题。直接提示语言模型提问效果并不好。为了提高问题的深度和广度,STORM 采用了两种策略:
1. **视角引导提问**:给定输入主题,STORM 通过调查类似主题的现有文章来发现不同的视角,并利用它们来控制提问过程。
2. **模拟对话**:STORM 模拟 Wikipedia 撰稿人与基于互联网资源的主题专家之间的对话,使语言模型能够更新其对主题的理解并提出后续问题。
### CO-STORM
Co-STORM 提出了 **协作对话协议**,该协议实现了一项轮次管理策略,以支持以下各方的顺畅协作:
- **Co-STORM LLM 专家**:此类 agent 基于外部知识源生成答案,和/或根据对话历史提出后续问题。
- **Moderator**:此 agent 受检索器发现的但在之前轮次中未直接使用的信息启发,生成引人深思的问题。问题生成也可以基于外部资源!
- **人类用户**:人类用户将采取主动,(1) 观察对话以深入理解主题,或 (2) 通过注入话语积极参与对话,以引导讨论焦点。
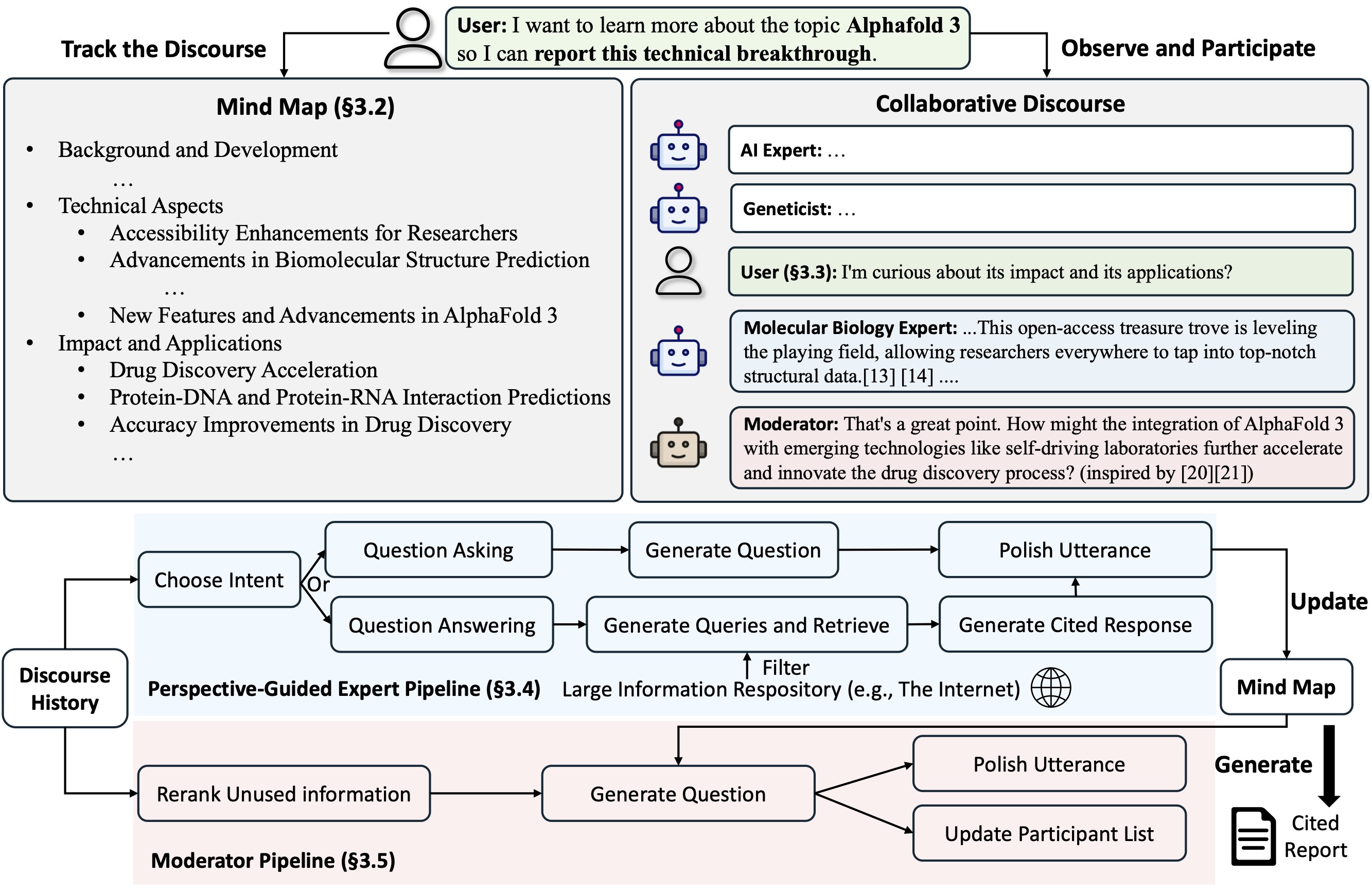
Co-STORM 还维护着一个动态更新的 **思维导图**,将收集到的信息组织成层级概念结构,旨在 **在人类用户和系统之间建立一个共享的概念空间**。事实证明,当对话变得冗长且深入时,思维导图有助于减轻大脑的负担。
STORM 和 Co-STORM 均使用 [dspy](https://github.com/stanfordnlp/dspy) 以高度模块化的方式实现。
## 安装
要安装 knowledge storm 库,请使用 `pip install knowledge-storm`。
您也可以安装源代码,这允许您直接修改 STORM 引擎的行为。
1. 克隆 git 仓库。
git clone https://github.com/stanford-oval/storm.git
cd storm
2. 安装所需的包。
conda create -n storm python=3.11
conda activate storm
pip install -r requirements.txt
## API
目前,我们的包支持:
- 语言模型组件:litellm 支持的所有语言模型,列表请见[此处](https://docs.litellm.ai/docs/providers)
- Embedding 模型组件:litellm 支持的所有 embedding 模型,列表请见[此处](https://docs.litellm.ai/docs/embedding/supported_embedding)
- 检索模块组件:`YouRM`、`BingSearch`、`VectorRM`、`SerperRM`、`BraveRM`、`SearXNG`、`DuckDuckGoSearchRM`、`TavilySearchRM`、`GoogleSearch` 和 `AzureAISearch` 作为
:star2: **非常欢迎提交 PR 以将更多搜索引擎/检索器集成到 [knowledge_storm/rm.py](knowledge_storm/rm.py) 中!**
STORM 和 Co-STORM 都在信息构建层工作,您需要设置信息检索模块和语言模型模块,以分别创建它们的 `Runner` 类。
### STORM
STORM 知识构建引擎定义为一个简单的 Python `STORMWikiRunner` 类。以下是使用 You.com 搜索引擎和 OpenAI 模型的示例。
```
import os
from knowledge_storm import STORMWikiRunnerArguments, STORMWikiRunner, STORMWikiLMConfigs
from knowledge_storm.lm import LitellmModel
from knowledge_storm.rm import YouRM
lm_configs = STORMWikiLMConfigs()
openai_kwargs = {
'api_key': os.getenv("OPENAI_API_KEY"),
'temperature': 1.0,
'top_p': 0.9,
}
# STORM 是一个 LM 系统,因此不同的组件可以由不同的模型驱动,以在成本和质量之间达到良好的平衡。
# 作为最佳实践,请为 `conv_simulator_lm` 选择一个更便宜/更快的模型,该模型用于拆分查询、合成对话中的答案。
# 请为 `article_gen_lm` 选择一个更强大的模型,以生成带有引用的可验证文本。
gpt_35 = LitellmModel(model='gpt-3.5-turbo', max_tokens=500, **openai_kwargs)
gpt_4 = LitellmModel(model='gpt-4o', max_tokens=3000, **openai_kwargs)
lm_configs.set_conv_simulator_lm(gpt_35)
lm_configs.set_question_asker_lm(gpt_35)
lm_configs.set_outline_gen_lm(gpt_4)
lm_configs.set_article_gen_lm(gpt_4)
lm_configs.set_article_polish_lm(gpt_4)
# 查看 STORMWikiRunnerArguments class 以获取更多配置。
engine_args = STORMWikiRunnerArguments(...)
rm = YouRM(ydc_api_key=os.getenv('YDC_API_KEY'), k=engine_args.search_top_k)
runner = STORMWikiRunner(engine_args, lm_configs, rm)
```
可以通过简单的 `run` 方法来启动 `STORMWikiRunner` 实例:
```
topic = input('Topic: ')
runner.run(
topic=topic,
do_research=True,
do_generate_outline=True,
do_generate_article=True,
do_polish_article=True,
)
runner.post_run()
runner.summary()
```
- `do_research`:如果为 True,模拟不同视角的对话以收集有关该主题的信息;否则,加载结果。
- `do_generate_outline`:如果为 True,为该主题生成大纲;否则,加载结果。
- `do_generate_article`:如果为 True,根据大纲和收集到的信息为该主题生成文章;否则,加载结果。
- `do_polish_article`:如果为 True,通过添加总结部分并(可选地)删除重复内容来润色文章;否则,加载结果。
### Co-STORM
Co-STORM 知识构建引擎定义为一个简单的 Python `CoStormRunner` 类。以下是使用 Bing 搜索引擎和 OpenAI 模型的示例。
```
from knowledge_storm.collaborative_storm.engine import CollaborativeStormLMConfigs, RunnerArgument, CoStormRunner
from knowledge_storm.lm import LitellmModel
from knowledge_storm.logging_wrapper import LoggingWrapper
from knowledge_storm.rm import BingSearch
# Co-STORM 采用了与 STORM 相同的多 LM 系统范式
lm_config: CollaborativeStormLMConfigs = CollaborativeStormLMConfigs()
openai_kwargs = {
"api_key": os.getenv("OPENAI_API_KEY"),
"api_provider": "openai",
"temperature": 1.0,
"top_p": 0.9,
"api_base": None,
}
question_answering_lm = LitellmModel(model=gpt_4o_model_name, max_tokens=1000, **openai_kwargs)
discourse_manage_lm = LitellmModel(model=gpt_4o_model_name, max_tokens=500, **openai_kwargs)
utterance_polishing_lm = LitellmModel(model=gpt_4o_model_name, max_tokens=2000, **openai_kwargs)
warmstart_outline_gen_lm = LitellmModel(model=gpt_4o_model_name, max_tokens=500, **openai_kwargs)
question_asking_lm = LitellmModel(model=gpt_4o_model_name, max_tokens=300, **openai_kwargs)
knowledge_base_lm = LitellmModel(model=gpt_4o_model_name, max_tokens=1000, **openai_kwargs)
lm_config.set_question_answering_lm(question_answering_lm)
lm_config.set_discourse_manage_lm(discourse_manage_lm)
lm_config.set_utterance_polishing_lm(utterance_polishing_lm)
lm_config.set_warmstart_outline_gen_lm(warmstart_outline_gen_lm)
lm_config.set_question_asking_lm(question_asking_lm)
lm_config.set_knowledge_base_lm(knowledge_base_lm)
# 查看 Co-STORM 的 RunnerArguments class 以获取更多配置。
topic = input('Topic: ')
runner_argument = RunnerArgument(topic=topic, ...)
logging_wrapper = LoggingWrapper(lm_config)
bing_rm = BingSearch(bing_search_api_key=os.environ.get("BING_SEARCH_API_KEY"),
k=runner_argument.retrieve_top_k)
costorm_runner = CoStormRunner(lm_config=lm_config,
runner_argument=runner_argument,
logging_wrapper=logging_wrapper,
rm=bing_rm)
```
可以通过 `warmstart()` 和 `step(...)` 方法来启动 `CoStormRunner` 实例。
```
# 热启动系统以在 Co-STORM 和用户之间建立共享的概念空间
costorm_runner.warm_start()
# 逐步进行协作对话
# 按任意顺序运行以下任意代码片段,次数不限
# 要查看对话:
conv_turn = costorm_runner.step()
# 注入你的话语以主动引导对话:
costorm_runner.step(user_utterance="YOUR UTTERANCE HERE")
# 基于协作对话生成报告
costorm_runner.knowledge_base.reorganize()
article = costorm_runner.generate_report()
print(article)
```
## 使用示例脚本快速开始
我们在 [examples 文件夹](examples) 中提供了脚本,作为在不同配置下运行 STORM 和 Co-STORM 的快速入门。
我们建议使用 `secrets.toml` 来设置 API 密钥。在根目录下创建一个 `secrets.toml` 文件并添加以下内容:
```
# ============ language model configurations ============
# 设置 OpenAI API key。
OPENAI_API_KEY="your_openai_api_key"
# 如果你正在使用 OpenAI 提供的 API 服务,请包含以下行:
OPENAI_API_TYPE="openai"
# 如果你正在使用 Microsoft Azure 提供的 API 服务,请包含以下行:
OPENAI_API_TYPE="azure"
AZURE_API_BASE="your_azure_api_base_url"
AZURE_API_VERSION="your_azure_api_version"
# ============ retriever configurations ============
BING_SEARCH_API_KEY="your_bing_search_api_key" # if using bing search
# ============ encoder configurations ============
ENCODER_API_TYPE="openai" # if using openai encoder
```
### STORM 示例
**要使用默认配置运行带有 `gpt` 系列模型的 STORM:**
运行以下命令。
```
python examples/storm_examples/run_storm_wiki_gpt.py \
--output-dir $OUTPUT_DIR \
--retriever bing \
--do-research \
--do-generate-outline \
--do-generate-article \
--do-polish-article
```
**要使用您最喜欢的语言模型或基于您自己的语料库运行 STORM:** 请查看 [examples/storm_examples/README.md](examples/storm_examples/README.md)。
### Co-STORM 示例
要使用默认配置运行带有 `gpt` 系列模型的 Co-STORM,
1. 将 `BING_SEARCH_API_KEY="xxx"` 和 `ENCODER_API_TYPE="xxx"` 添加到 `secrets.toml` 中
2. 运行以下命令
```
python examples/costorm_examples/run_costorm_gpt.py \
--output-dir $OUTPUT_DIR \
--retriever bing
```
## 自定义 Pipeline
### STORM
如果您已经安装了源代码,则可以根据自己的用例自定义 STORM。STORM 引擎由 4 个模块组成:
1. 知识构建模块:收集有关给定主题的广泛信息。
2. 大纲生成模块:通过为构建的知识生成层级大纲来组织收集到的信息。
3. 文章生成模块:使用收集到的信息填充生成的大纲。
4. 文章润色模块:完善并增强所写文章,以获得更好的呈现效果。
每个模块的接口在 `knowledge_storm/interface.py` 中定义,而它们的实现则在 `knowledge_storm/storm_wiki/modules/*` 中实例化。这些模块可以根据您的具体要求进行自定义(例如,以项目符号格式而不是完整段落生成部分)。
### Co-STORM
如果您已经安装了源代码,则可以根据自己的用例自定义 Co-STORM
1. Co-STORM 引入了多种 LLM agent 类型(即 Co-STORM 专家和 Moderator)。LLM agent 接口在 `knowledge_storm/interface.py` 中定义,而其实现则在 `knowledge_storm/collaborative_storm/modules/co_storm_agents.py` 中实例化。可以自定义不同的 LLM agent 策略。
2. Co-STORM 引入了协作对话协议,其核心功能围绕着轮次策略管理。我们通过 `knowledge_storm/collaborative_storm/engine.py` 中的 `DiscourseManager` 提供了轮次策略管理的示例实现。它可以进行自定义和进一步改进。
## 数据集
为了促进对自动知识构建和复杂信息检索的研究,我们的项目发布了以下数据集:
### FreshWiki
FreshWiki 数据集是 100 篇高质量 Wikipedia 文章的集合,重点关注 2022 年 2 月至 2023 年 9 月期间编辑次数最多的页面。有关更多详细信息,请参阅 [STORM 论文](https://arxiv.org/abs/2402.14207) 中的第 2.1 节。
您可以直接从 [huggingface](https://huggingface.co/datasets/EchoShao8899/FreshWiki) 下载数据集。为了缓解数据污染问题,我们归档了数据构建 pipeline 的[源代码](https://github.com/stanford-oval/storm/tree/NAACL-2024-code-backup/FreshWiki),以便在未来日期可以重复使用。
### WildSeek
为了研究用户在实际复杂信息检索任务中的兴趣,我们利用从网络研究预览中收集的数据创建了 WildSeek 数据集。我们对数据进行了下采样,以确保主题的多样性和数据的质量。每个数据点都是由一个主题和用户对该主题进行深度搜索的目标组成的一对数据。有关更多详细信息,请参阅 [Co-STORM 论文](https://www.arxiv.org/abs/2408.15232) 的第 2.2 节和附录 A。
WildSeek 数据集可在[此处](https://huggingface.co/datasets/YuchengJiang/WildSeek)获取。
## 复现 STORM 和 Co-STORM 论文结果
有关 STORM 论文的实验,请在[此处](https://github.com/stanford-oval/storm/tree/NAACL-2024-code-backup)切换到 `NAACL-2024-code-backup` 分支。
有关 Co-STORM 论文的实验,请切换到 `EMNLP-2024-code-backup` 分支(目前为占位符,将很快更新)。
## 路线图与贡献
我们的团队正在积极致力于:
1. Human-in-the-Loop 功能:支持用户参与知识构建过程。
2. 信息抽象:为构建的信息开发抽象,以支持超越 Wikipedia 风格报告的呈现格式。
联系人:[Yijia Shao](mailto:shaoyj@stanford.edu) 和 [Yucheng Jiang](mailto:yuchengj@stanford.edu)
## 致谢
我们要感谢 Wikipedia 提供其出色的开源内容。FreshWiki 数据集来源于 Wikipedia,采用知识共享署名-相同方式共享 (CC BY-SA) 许可。
我们非常感谢 [Michelle Lam](https://michelle123lam.github.io/) 为本项目设计徽标,以及 [Dekun Ma](https://dekun.me) 领导 UI 开发。
感谢 Vercel 对[开源软件](https://storm.genie.stanford.edu)的支持
## 引用
如果您在您的作品中使用了此代码或其部分内容,请引用我们的论文:
```
@inproceedings{jiang-etal-2024-unknown,
title = "Into the Unknown Unknowns: Engaged Human Learning through Participation in Language Model Agent Conversations",
author = "Jiang, Yucheng and
Shao, Yijia and
Ma, Dekun and
Semnani, Sina and
Lam, Monica",
editor = "Al-Onaizan, Yaser and
Bansal, Mohit and
Chen, Yun-Nung",
booktitle = "Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2024",
address = "Miami, Florida, USA",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.emnlp-main.554/",
doi = "10.18653/v1/2024.emnlp-main.554",
pages = "9917--9955",
}
@inproceedings{shao-etal-2024-assisting,
title = "Assisting in Writing {W}ikipedia-like Articles From Scratch with Large Language Models",
author = "Shao, Yijia and
Jiang, Yucheng and
Kanell, Theodore and
Xu, Peter and
Khattab, Omar and
Lam, Monica",
editor = "Duh, Kevin and
Gomez, Helena and
Bethard, Steven",
booktitle = "Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)",
month = jun,
year = "2024",
address = "Mexico City, Mexico",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.naacl-long.347/",
doi = "10.18653/v1/2024.naacl-long.347",
pages = "6252--6278",
}
```