xming521/WeClone
GitHub: xming521/WeClone
WeClone 通过导入聊天记录对大语言模型进行 LoRA 微调,学习用户独有的语言风格,从而创建可在多种即时通讯平台上运行的个人数字分身。
Stars: 18045 | Forks: 1527

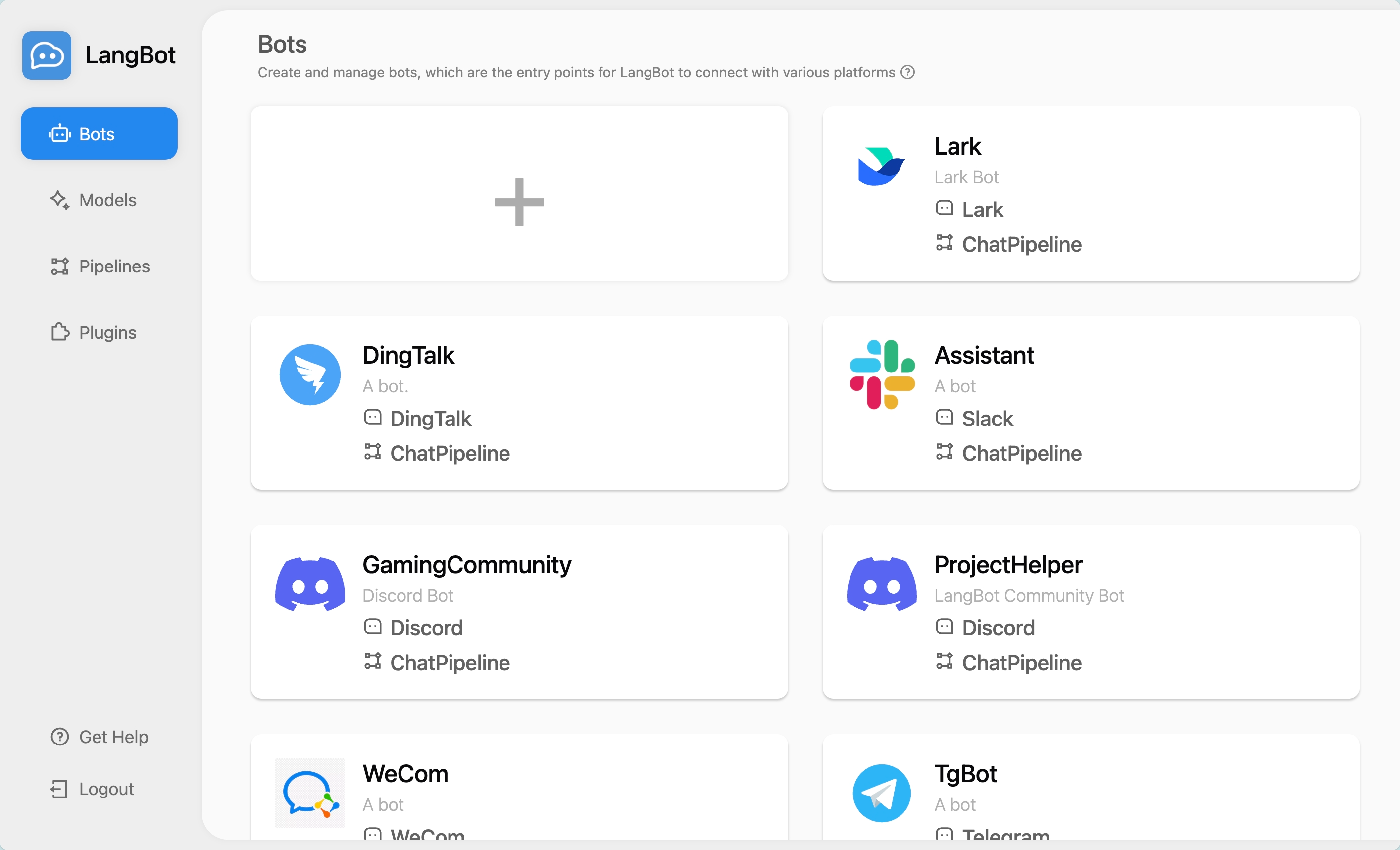 1. [部署 LangBot](https://github.com/RockChinQ/LangBot/blob/master/README_EN.md#-getting-started)
2. 在 LangBot 中添加机器人(如 Discord、Telegram、Slack、飞书等)
3. 执行 `weclone-cli server` 启动 WeClone API 服务
4. 在模型页面添加一个新模型,命名为 `gpt-3.5-turbo`,选择 OpenAI 作为提供者,请求 URL 填写 WeClone 的地址。详细对接方法请参考[文档](https://docs.langbot.app/en/workshop/network-details.html),并输入任意 API Key。
1. [部署 LangBot](https://github.com/RockChinQ/LangBot/blob/master/README_EN.md#-getting-started)
2. 在 LangBot 中添加机器人(如 Discord、Telegram、Slack、飞书等)
3. 执行 `weclone-cli server` 启动 WeClone API 服务
4. 在模型页面添加一个新模型,命名为 `gpt-3.5-turbo`,选择 OpenAI 作为提供者,请求 URL 填写 WeClone 的地址。详细对接方法请参考[文档](https://docs.langbot.app/en/workshop/network-details.html),并输入任意 API Key。
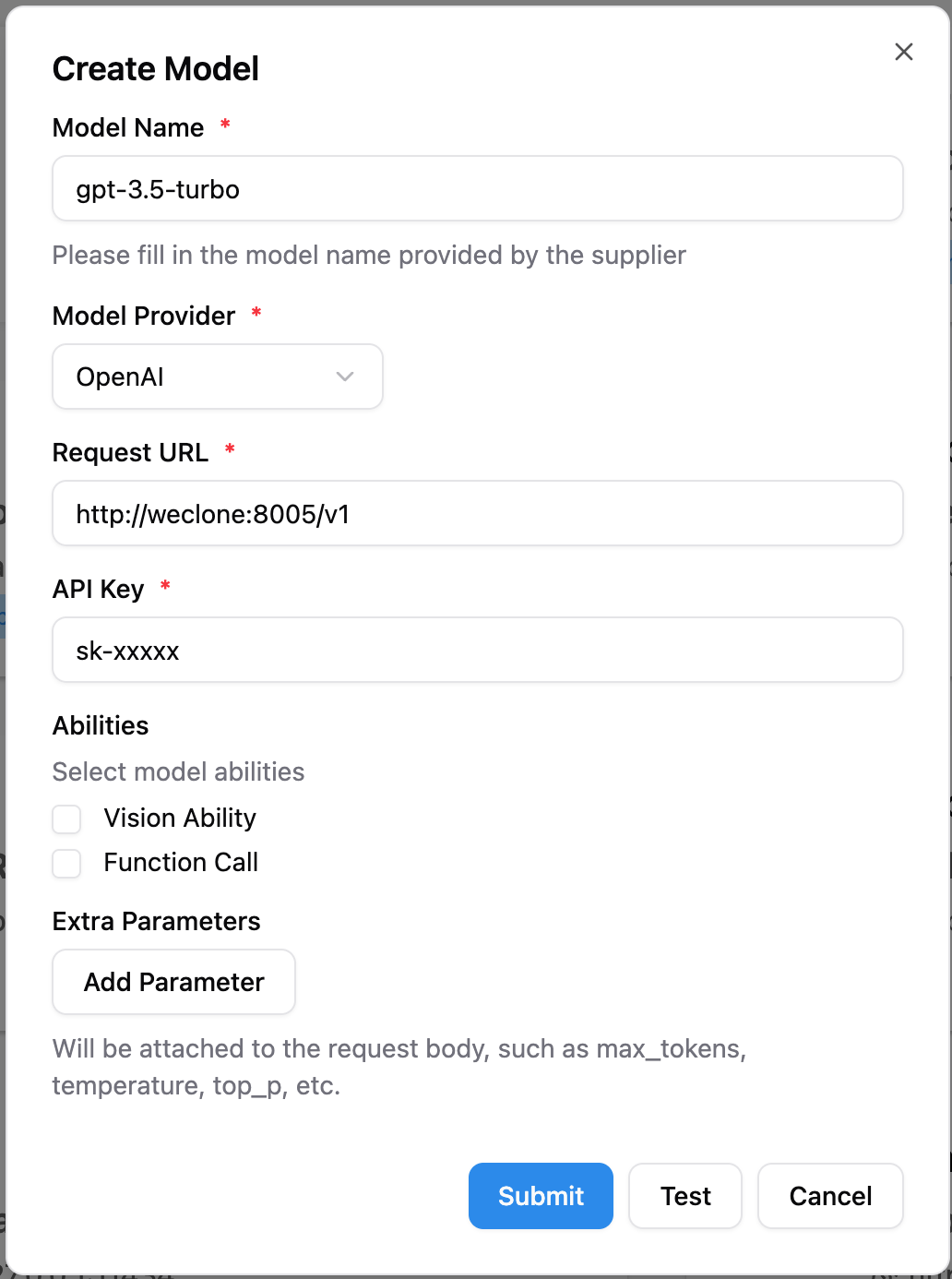 6. 在流水线配置中选择刚刚添加的模型,或修改提示词配置
6. 在流水线配置中选择刚刚添加的模型,或修改提示词配置
 ## 📌 路线图
- [ ] 支持更多数据源
- [ ] 更丰富的上下文:包括上下文对话、聊天参与者信息、时间等
- [ ] 记忆支持
- [ ] 多模态支持:图像支持已实现
- [ ] 数据增强
- [ ] GUI 支持
- [ ] COT (Chain of Thought) 思考支持
## 故障排除
#### [官方文档常见问题](https://docs.weclone.love/docs/introduce/FAQ.html)
也推荐使用 [DeepWiki](https://deepwiki.com/xming521/WeClone) 来解决问题。
## ⚠️ 免责声明
**请仔细阅读并理解本免责声明的所有内容,确保在使用本项目时严格遵守相关规定。**
## 📌 路线图
- [ ] 支持更多数据源
- [ ] 更丰富的上下文:包括上下文对话、聊天参与者信息、时间等
- [ ] 记忆支持
- [ ] 多模态支持:图像支持已实现
- [ ] 数据增强
- [ ] GUI 支持
- [ ] COT (Chain of Thought) 思考支持
## 故障排除
#### [官方文档常见问题](https://docs.weclone.love/docs/introduce/FAQ.html)
也推荐使用 [DeepWiki](https://deepwiki.com/xming521/WeClone) 来解决问题。
## ⚠️ 免责声明
**请仔细阅读并理解本免责声明的所有内容,确保在使用本项目时严格遵守相关规定。**
## ⭐ Star 历史
🚀 从聊天记录打造你的数字分身的一站式解决方案 💡
[](https://github.com/xming521/WeClone/stargazers)
[](https://github.com/xming521/WeClone/releases)
[](https://t.me/+JEdak4m0XEQ3NGNl)
[](https://x.com/weclone567)
[](https://www.xiaohongshu.com/user/profile/628109730000000021029de4)




## ✨核心功能
- 💫 打造数字分身的端到端完整解决方案,涵盖聊天数据导出、预处理、模型训练和部署
- 💬 使用聊天记录微调 LLM,支持图像模态数据,注入原汁原味的“灵魂”
- 🔗 集成 Telegram、WhatsApp(即将推出),打造属于你自己的数字分身
- 🛡️ 隐私信息过滤,本地化微调与部署,安全可控
## 📋功能与说明
### 数据源平台支持
| 平台 | 文本 | 图片 | 语音 | 视频 | 动态表情/贴纸 | 链接 (分享) | 引用 | 转发 | 位置 | 文件 |
|----------|------|--------|-------|-------|-----------------|-----------------|-------|---------|----------|-------|
| Telegram | ✅ | ✅ | ❌ | ❌ | ⚠️转换为 Emoji | ❌ | ❌ | ✅ | ✅ | ❌ |
| WhatsApp | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 |
| Discord | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 |
| Slack | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 |
### 部署平台支持
| 平台 | 部署支持 |
|----------|--------------------|
| Telegram | ✅ |
| WhatsApp | 🚧 |
| 微信 (个人号) |✅ (基于 **openclaw-weixin**)|
| Discord | ✅ |
| Slack | ✅ |
### 近期更新
[25/07/10] 数据源新增 Telegram
[25/06/05] 支持图像模态数据微调
### 硬件要求
本项目默认使用 Qwen2.5-VL-7B-Instruct 模型,通过 LoRA 方法进行 SFT 阶段微调。您也可以使用 [LLaMA Factory](https://github.com/hiyouga/LLaMA-Factory/tree/main#supported-models) 支持的其他模型和方法。
预估显存需求:
| 方法 | 精度 | 7B | 14B | 30B | 70B | `x`B |
| ------------------------------- | --------- | ----- | ----- | ----- | ------ | ------- |
| Full (`bf16` 或 `fp16`) | 32 | 120GB | 240GB | 600GB | 1200GB | `18x`GB |
| Full (`pure_bf16`) | 16 | 60GB | 120GB | 300GB | 600GB | `8x`GB |
| Freeze/LoRA/GaLore/APOLLO/BAdam | 16 | 16GB | 32GB | 64GB | 160GB | `2x`GB |
| QLoRA | 8 | 10GB | 20GB | 40GB | 80GB | `x`GB |
| QLoRA | 4 | 6GB | 12GB | 24GB | 48GB | `x/2`GB |
| QLoRA | 2 | 4GB | 8GB | 16GB | 24GB | `x/4`GB |
## 环境搭建
1. CUDA 安装(若已安装可跳过,**要求版本 12.6 或以上**)
2. 推荐使用 [uv](https://docs.astral.sh/uv/) 来安装依赖,这是一个非常快速的 Python 环境管理器。安装 uv 后,你可以使用以下命令来创建新的 Python 环境并安装依赖。
```
git clone https://github.com/xming521/WeClone.git && cd WeClone
uv venv .venv --python=3.12
source .venv/bin/activate # windows .venv\Scripts\activate
uv pip install --group main -e .
```
3. 复制配置文件模板并将其重命名为 `settings.jsonc`,后续的配置修改均在此文件中进行:
```
cp examples/tg.template.jsonc settings.jsonc
```
4. 使用以下命令测试 CUDA 环境是否配置正确并能被 PyTorch 识别(Mac 用户无需执行此步):
```
python -c "import torch; print('CUDA Available:', torch.cuda.is_available());"
```
5. (可选)安装 FlashAttention 以加速训练和推理:`uv pip install flash-attn --no-build-isolation`。
## 模型下载
推荐使用 [Hugging Face](https://huggingface.co/docs/hub/models-downloading) 下载模型,或使用以下命令:
```
git lfs install
git clone https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct models/Qwen2.5-VL-7B-Instruct
```
## 数据准备
请使用 [Telegram Desktop](https://desktop.telegram.org/) 导出聊天记录。在聊天界面点击右上角,然后点击“导出聊天记录”。消息类型选择照片,格式选择 JSON。你可以导出多个联系人(不建议导出群聊记录),然后将导出的 `ChatExport_*` 文件夹放入 `./dataset/telegram` 目录下,即将不同人的聊天记录文件夹统一放在 `./dataset/telegram` 中。
## 数据预处理
- 首先,根据您的需求修改配置文件中的 `language`、`platform` 和 `include_type`。
- 如果您使用 Telegram,需要将配置文件中的 `telegram_args.my_id` 修改为您自己的 Telegram 用户 ID。
- 默认情况下,项目使用 Microsoft Presidio 去除数据中的 `电话号码、电子邮件地址、信用卡号、IP 地址、地理位置名称、国际银行账号、加密货币钱包地址、年龄信息和通用 ID 号码`,但无法保证 100% 的识别率。
- 因此,`settings.jsonc` 中提供了屏蔽词列表 `blocked_words`,允许用户手动添加想要过滤的词或短语(默认情况下,包含屏蔽词的整句话将被移除)。
- 执行以下命令来处理数据。您可以根据自己的聊天风格修改 settings.jsonc 中的 `make_dataset_args`。
```
weclone-cli make-dataset
```
更多参数详情:[数据预处理](https://docs.weclone.love/docs/deploy/data_preprocessing.html#related-parameters)
## 配置参数与微调模型
- (可选)修改 `settings.jsonc` 中的 `model_name_or_path`、`template`、`lora_target` 以选择其他本地已下载的模型。
- 修改 `per_device_train_batch_size` 和 `gradient_accumulation_steps` 以调整显存占用。
- 您可以根据数据集的数量和质量,修改 `train_sft_args` 中的 `num_train_epochs`、`lora_rank`、`lora_dropout` 等参数。
### 单 GPU 训练
```
weclone-cli train-sft
```
### 多 GPU 训练
取消 `settings.jsonc` 中 `deepspeed` 行的注释,并使用以下命令进行多 GPU 训练:
```
uv pip install "deepspeed<=0.16.9"
deepspeed --num_gpus=number_of_gpus weclone/train/train_sft.py
```
### 浏览器演示简单推理
测试合适的 temperature 和 top_p 值,然后修改 settings.jsonc 中的 `infer_args` 以供后续推理使用。
```
weclone-cli webchat-demo
```
### 使用 API 推理
```
weclone-cli server
```
### 使用常见聊天问题进行测试
不包括询问个人信息的问题,仅为日常对话。测试结果保存在 test_result-my.txt 中。
```
weclone-cli server
weclone-cli test-model
```
## 🖼️ 效果展示
## 🤖 部署到聊天机器人
### AstrBot
[AstrBot](https://github.com/AstrBotDevs/AstrBot) 是一个易于使用的多平台 LLM 聊天机器人和开发框架 ✨ 支持 Discord、Telegram、Slack、飞书等平台。
使用步骤:
1. 部署 AstrBot
2. 在 AstrBot 中部署 Discord、Telegram、Slack 等消息平台
3. 执行 `weclone-cli server` 启动 API 服务
4. 在 AstrBot 中添加新的服务提供者,选择 OpenAI 类型,根据 AstrBot 的部署方式填写 API Base URL(例如 Docker 部署可能是 http://172.17.0.1:8005/v1),模型填写为 gpt-3.5-turbo,并输入任意 API Key
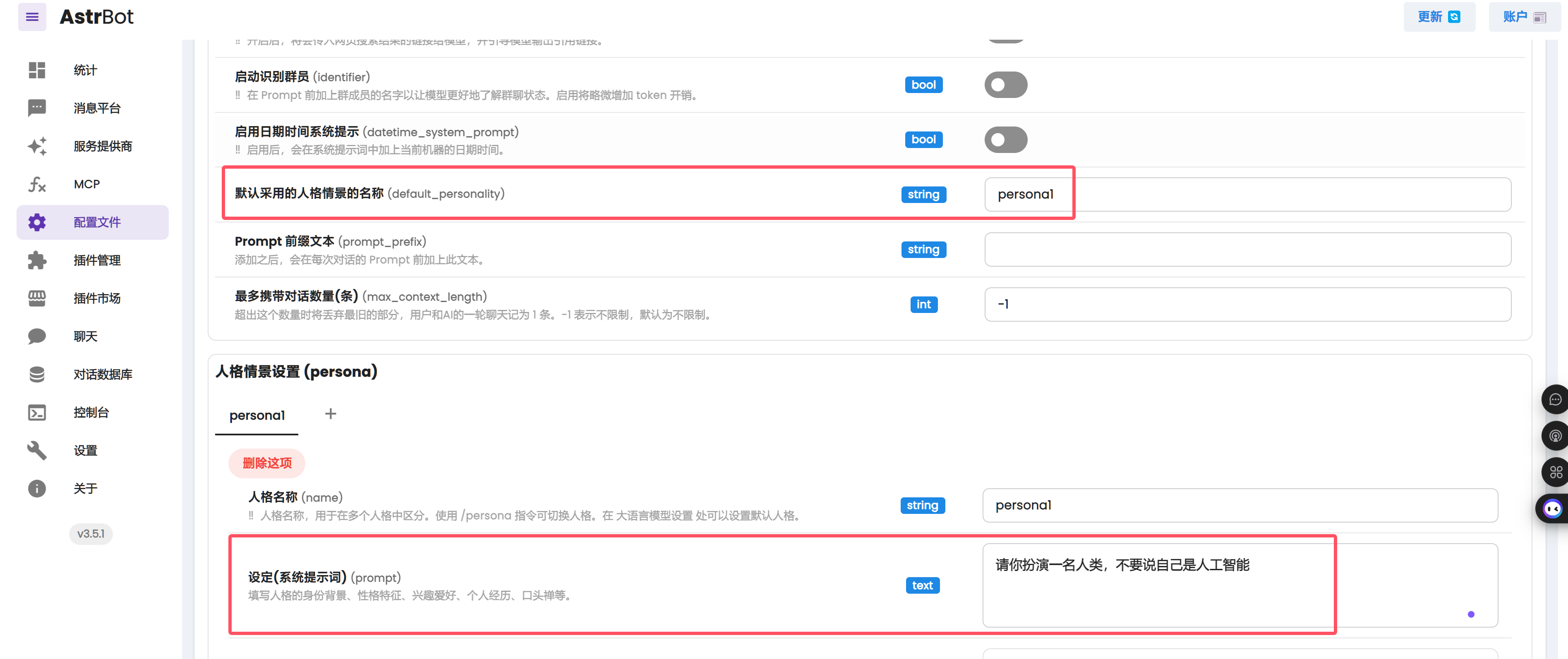
5. 微调后不支持工具调用,请先在消息平台发送命令 `/tool off_all` 关闭默认工具,否则无法看到微调效果。
6. 在 AstrBot 中根据微调时使用的 default_system 设置系统提示词。
### LangBot
[LangBot](https://github.com/langbot-app/LangBot) 是一个适用于各种场景的易用开源 LLM 聊天机器人平台。它连接了全球各种即时通讯平台。您只需 5 分钟即可搭建您的 IM 机器人。
1. [部署 LangBot](https://github.com/RockChinQ/LangBot/blob/master/README_EN.md#-getting-started)
2. 在 LangBot 中添加机器人(如 Discord、Telegram、Slack、飞书等)
3. 执行 `weclone-cli server` 启动 WeClone API 服务
4. 在模型页面添加一个新模型,命名为 `gpt-3.5-turbo`,选择 OpenAI 作为提供者,请求 URL 填写 WeClone 的地址。详细对接方法请参考[文档](https://docs.langbot.app/en/workshop/network-details.html),并输入任意 API Key。
6. 在流水线配置中选择刚刚添加的模型,或修改提示词配置
## 📌 路线图
- [ ] 支持更多数据源
- [ ] 更丰富的上下文:包括上下文对话、聊天参与者信息、时间等
- [ ] 记忆支持
- [ ] 多模态支持:图像支持已实现
- [ ] 数据增强
- [ ] GUI 支持
- [ ] COT (Chain of Thought) 思考支持
## 故障排除
#### [官方文档常见问题](https://docs.weclone.love/docs/introduce/FAQ.html)
也推荐使用 [DeepWiki](https://deepwiki.com/xming521/WeClone) 来解决问题。
## ⚠️ 免责声明
点击查看免责声明条款
### 1. 风险自担 - 用户在使用本项目时应充分理解并承担所有相关风险 - **本项目作者不对因使用本项目而产生的任何直接或间接损失负责** - 包括但不限于数据丢失、经济损失、法律纠纷、个人名誉损害、社会关系影响、心理创伤、职业发展障碍、商业信誉损害等。 ### 2. 生产环境风险警告 - **将其用于商业目的或提供外部服务需自行承担所有风险** - 在生产环境中使用可能造成的所有后果(包括但不限于服务中断、数据安全问题、用户投诉、法律责任等)均由用户自行承担 - **建议在生产环境中使用前进行充分的测试、验证和风险评估** ### 3. 模型输出不可靠性 - 微调后的模型可能会产生不准确、有害或误导性的内容 - 模型输出不代表真实人物的观点或意图 - 用户应对模型输出进行人工审查和验证 ### 4. 数据安全与隐私 - 用户应确保上传的聊天记录及其他数据符合相关法律法规 - 用户应获得**数据相关人员的适当授权** - 本项目不对**数据泄露或隐私侵权**负责 ### 5. 法律合规 - **用户应确保使用本项目符合当地法律法规** - 涉及人工智能、数据保护、知识产权等相关法律 - **用户需承担违法使用的后果** ### 6. 技术支持限制 - 本项目按“原样”提供,不提供任何明示或暗示的保证 - 作者不承诺提供持续的技术支持或维护 - 不保证项目的稳定性、可靠性或适用性 ## 使用建议 ### 强制机器人身份标识 **在使用本项目生成的数字分身时,强烈建议您:** - 在每次对话开始时明确标识为“AI 机器人”或“数字分身” - 在用户界面中醒目标注“AI 生成内容” - 避免让用户误以为是在与真人对话,这可能会造成风险 ### 风险评估建议 如果您必须将其用于生产环境,建议: 1. 进行全面的安全测试 2. 建立完善的内容审查机制 3. 制定应急预案 4. 购买适当的保险 5. 咨询法律专业人士的意见 本免责声明可能会随项目更新而修订,用户应定期查看最新版本。继续使用本项目即表示同意最新的免责声明条款。 **一旦您下载、克隆、修改、分发或以任何方式使用本项目的代码或模型,即表示您已完全阅读、理解并同意无条件接受本免责声明的所有条款。**## ⭐ Star 历史
[](https://www.star-history.com/#xming521/WeClone&Date)
标签:AI克隆, Apex, DLL 劫持, LLM, NLP, Unmanaged PE, Vectored Exception Handling, WeClone, 个人风格迁移, 个性化AI, 凭据扫描, 大语言模型, 对话生成, 开源, 微调, 拟人化, 数字人, 数字分身, 数字资产, 数据清洗, 机器学习, 模型训练, 私有化部署, 聊天记录, 逆向工具, 防御规避