**MiniCPM-V** 和 **MiniCPM-o** 是一系列专为**在设备端实现强劲性能与高效部署**而设计的多模态 LLM。MiniCPM-V 专注于跨图像、视频和文本输入的高效视觉-语言理解。MiniCPM-o 将该系列扩展至实时的端到端全模态交互,支持流式视频和音频输入,以及文本和语音输出。目前该系列最引人注目的模型包括:
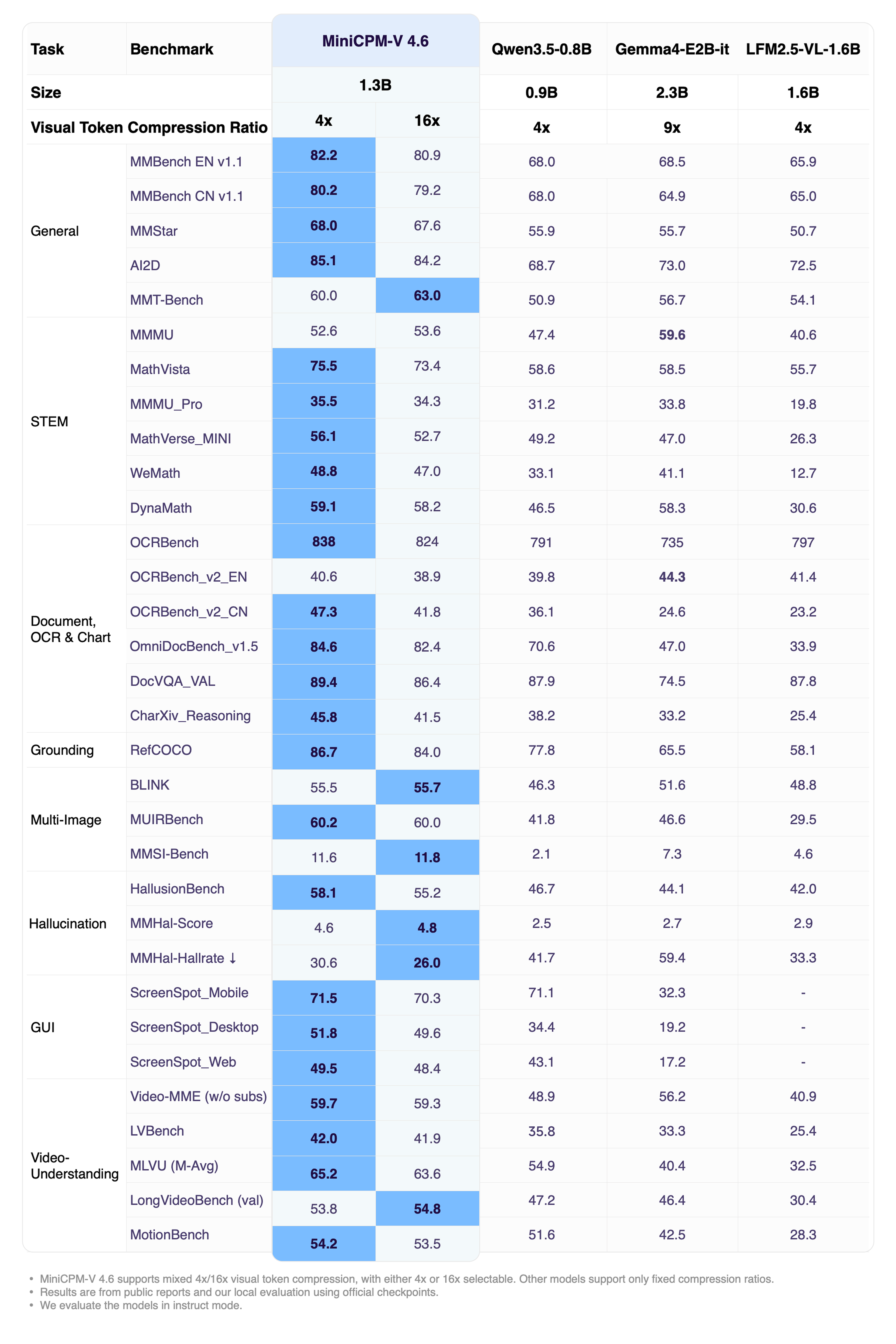
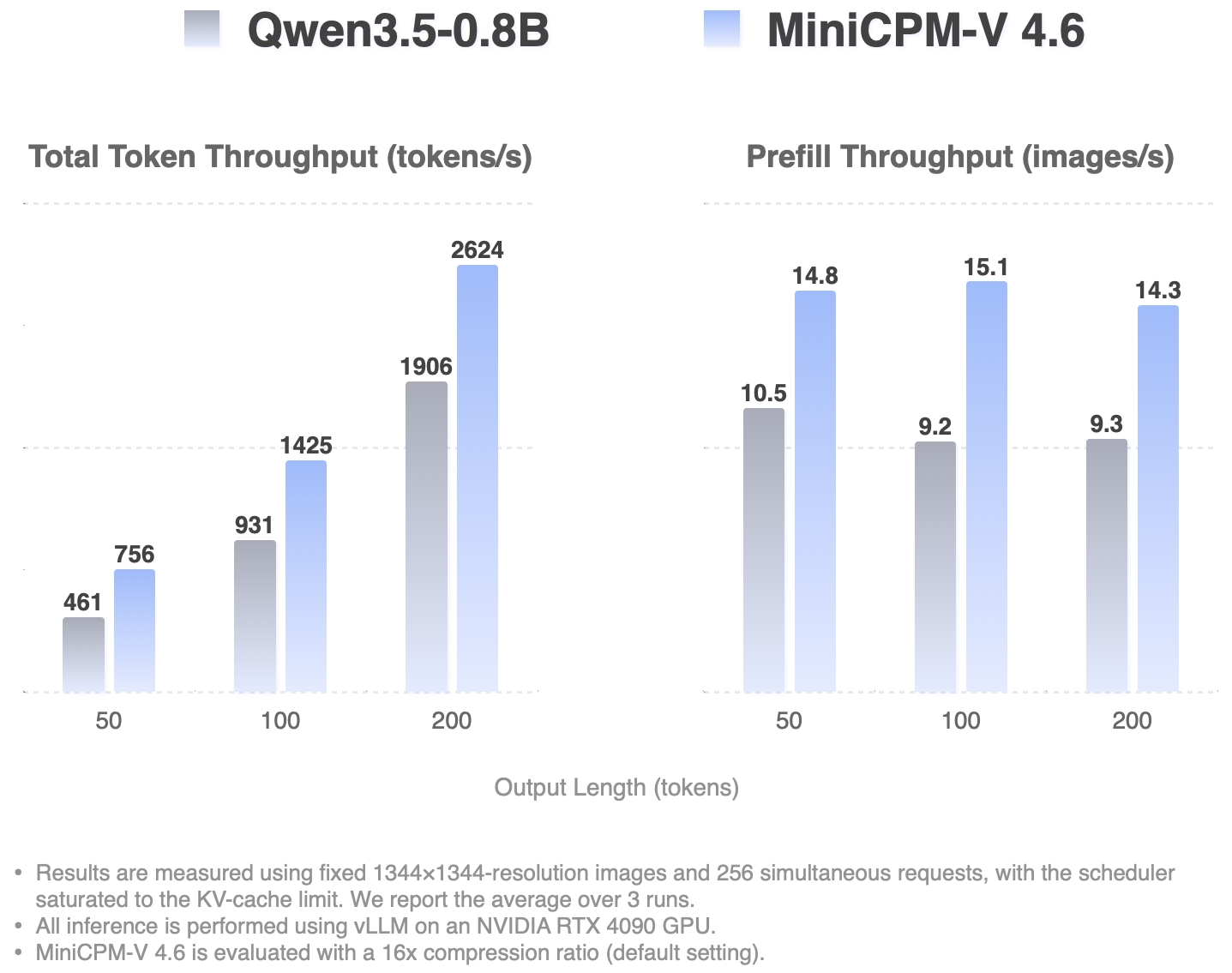
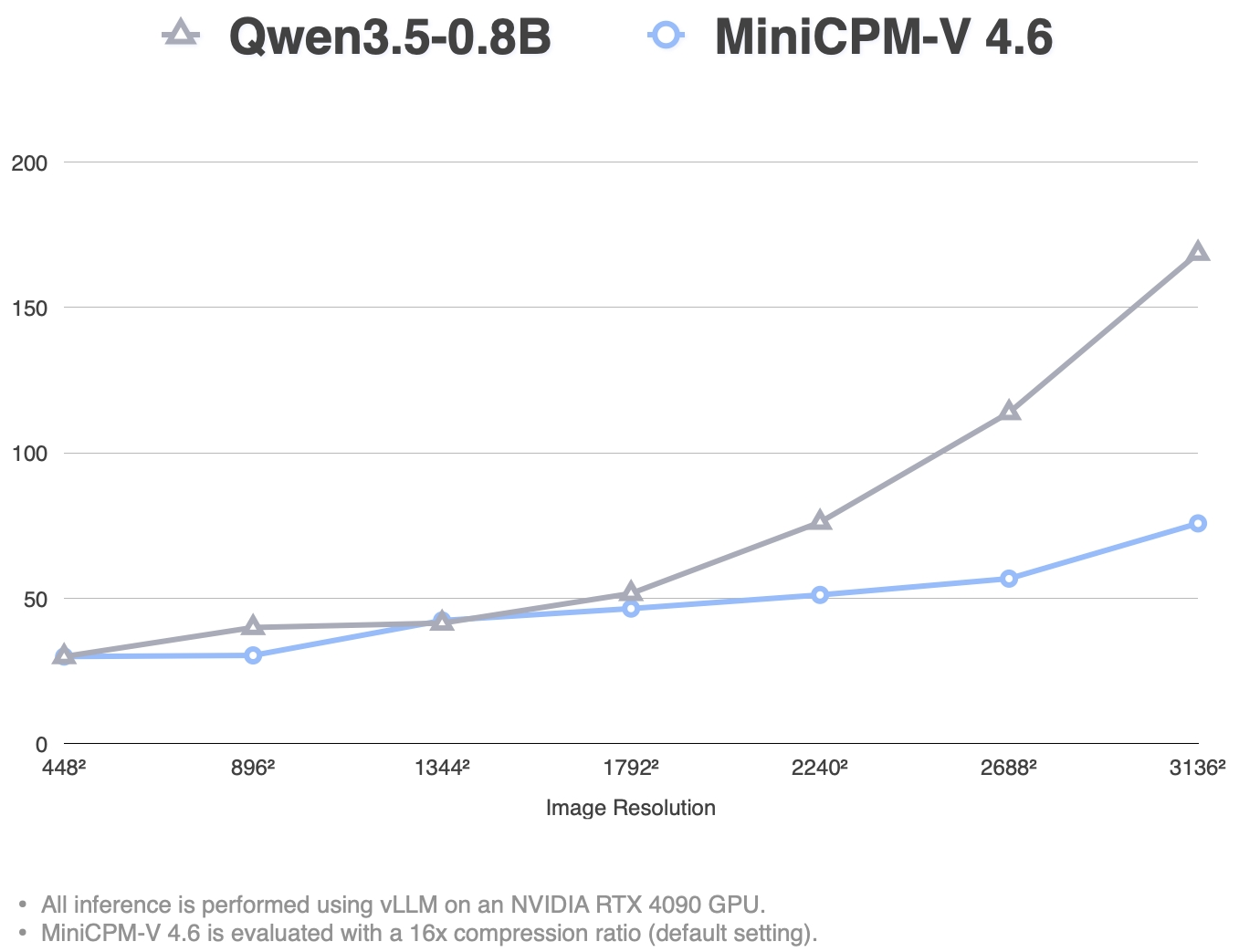
- **MiniCPM-V 4.6**:🔥🔥🔥 MiniCPM-V 系列中最新且最高效的模型。它总参数量为 1.3B,性能超越了 Gemma4-E2B-it 等更大的模型,同时比 Qwen3.5-0.8B 等更小的模型展现出更高的效率(实现约 1.5 倍的 token 吞吐量)。得益于 [LLaVA-UHD v4](https://huggingface.co/papers/2605.08985) 中最新的 **ViT 内部早期压缩技术**,MiniCPM-V 4.6 **将视觉编码计算成本降低了 50% 以上**,并支持 **混合 4x/16x 视觉 token 压缩率**,以便在不同任务中实现更灵活的性能与效率平衡。该模型可部署在 **主流移动平台上,包括 iOS、Android 和 HarmonyOS**,并开源了边缘端适配代码。
- **MiniCPM-o 4.5**:⭐️⭐️⭐️ MiniCPM-o 系列中最新且功能最强大的模型。该端到端模型总参数量为 9B,**在视觉、语音和全双工多模态实时流媒体方面接近 Gemini 2.5 Flash 的水平**,是开源社区中最通用、性能最强的模型之一。全新的全双工多模态实时流媒体能力意味着输出流(语音和文本)与实时输入流(视频和音频)互不阻塞。这使得 **MiniCPM-o 4.5 能够在实时全模态对话中同时看、听和说**,并执行**主动交互**(例如主动提醒)。
## 新闻
* [2026.05.11] 🔥🔥🔥 我们开源了 MiniCPM-V 4.6,支持混合 4x/16x 视觉 token 压缩。得益于强大的编码效率和轻量级的 1.3B 规模,它是我们迄今为止对边缘部署最友好的模型,与 Qwen3.5 0.8B 相比实现了约 1.5 倍的 token 吞吐量。立即尝试吧!
* [2026.02.06] 🥳 🥳 🥳 我们开源了一个可部署在您自己设备(如 Mac 或 GPU)上的实时 Web 演示。[立即尝试](#web-demo-deployment)!
* [2026.02.03] 🔥🔥🔥 我们开源了 MiniCPM-o 4.5,它在视觉和语音方面媲美 Gemini 2.5 Flash,并支持全双工多模态实时流媒体。立即尝试吧!
* [2025.08.26] 🔥🔥🔥 我们开源了 MiniCPM-V 4.5,其性能超越了 GPT-4o-latest、Gemini-2.0 Pro 和 Qwen2.5-VL 72B。它提升了 MiniCPM-V 的热门功能,并带来了实用的新特性。立即尝试吧!
* [2025.08.01] ⭐️⭐️⭐️ 我们开源了 [MiniCPM-V & o 食谱](https://github.com/OpenSQZ/MiniCPM-V-CookBook)!它为多种用户场景提供了全面的指南,并配合我们全新的 [文档站点](https://minicpm-o.readthedocs.io/en/latest/index.html) 以便更顺畅地上手。
* [2025.03.01] 🚀🚀🚀 MiniCPM-o 的对齐技术 RLAIF-V 被 CVPR 2025 Highlights 接收、[数据集](https://huggingface.co/datasets/openbmb/RLAIF-V-Dataset)、[论文](https://arxiv.org/abs/2405.17220) 均已开源!
* [2025.01.19] ⭐️⭐️⭐️ MiniCPM-o 登顶 GitHub Trending,并在 Hugging Face Trending 上达到第二名!
* [2024.05.23] 🔥🔥🔥 MiniCPM-V 登顶 GitHub Trending 和 Hugging Face Trending!我们的演示被 Hugging Face Gradio 官方账号推荐,可在[此处](https://huggingface.co/spaces/openbmb/MiniCPM-Llama3-V-2_5)访问。快来体验吧!
点击查看更多新闻。
* [2026.05.07] 📢📢📢 我们发布了 MiniCPM-o 4.5 技术报告,介绍了其背后实现实时全双工全模态交互的关键技术。在[此处](https://huggingface.co/papers/2604.27393)阅读。
* [2026.02.05] 📢📢📢 我们注意到 Web 演示可能会因网络状况而出现延迟问题。我们正在积极努力,尽快提供用于本地部署实时交互演示的 Docker 镜像。敬请期待!
* [2025.09.18] 📢📢📢 MiniCPM-V 4.5 技术报告现已发布!请见[此处](https://arxiv.org/abs/2509.18154)。
* [2025.09.01] ⭐️⭐️⭐️ MiniCPM-V 4.5 已正式获得 [llama.cpp](https://github.com/ggml-org/llama.cpp/pull/15575)、[vLLM](https://github.com/vllm-project/vllm/pull/23586) 和 [LLaMA-Factory](https://github.com/hiyouga/LLaMA-Factory/pull/9022) 的支持。欢迎直接通过这些官方渠道使用!对 [Ollama](https://github.com/ollama/ollama/pull/12078) 和 [SGLang](https://github.com/sgl-project/sglang/pull/9610) 等其他框架的支持正在积极进行中。
* [2025.08.02] 🚀🚀🚀 我们开源了 MiniCPM-V 4.0,其在图像理解方面超越了 GPT-4.1-mini-20250414。它提升了 MiniCPM-V 2.6 的热门功能,并大幅提高了效率。我们还开源了适用于 iPhone 和 iPad 的 iOS App。立即尝试吧!
* [2025.06.20] ⭐️⭐️⭐️ 我们的官方 [Ollama 仓库](https://ollama.com/openbmb)已发布。[一键](https://ollama.com/openbmb/minicpm-o2.6)尝试我们的最新模型!
* [2025.01.24] 📢📢📢 MiniCPM-o 2.6 技术报告发布!请见[此处](https://openbmb.notion.site/MiniCPM-o-2-6-A-GPT-4o-Level-MLLM-for-Vision-Speech-and-Multimodal-Live-Streaming-on-Your-Phone-185ede1b7a558042b5d5e45e6b237da9)。
* [2025.01.23] 💡💡💡 MiniCPM-o 2.5 现已获得 [Align-Anything](https://github.com/PKU-Alignment/align-anything) 的支持,这是由 PKU-Alignment 团队开发的一个用于将任意模态大模型与人类意图对齐的框架。它支持在视觉和音频上进行 DPO 和 SFT 微调。立即尝试吧!
* [2025.01.19] 📢 **注意!** 我们目前正在努力将 MiniCPM-o 2.6 合并到 llama.cpp、Ollama 和 vllm 的官方仓库中。在合并完成之前,请使用我们的 [llama.cpp](https://github.com/OpenBMB/llama.cpp/blob/minicpm-omni/examples/llava/README-minicpmo2.6.md)、[Ollama](https://github.com/OpenBMB/ollama/blob/minicpm-v2.6/examples/minicpm-v2.6/README.md) 和 [vllm](https://github.com/OpenBMB/MiniCPM-o?tab=readme-ov-file#efficient-inference-with-llamacpp-ollama-vllm) 本地 Fork。**在合并之前使用官方仓库可能会导致意外问题**。
* [2025.01.17] 我们更新了 MiniCPM-o 2.6 int4 量化版本的使用方法,并解决了模型初始化错误。点击[此处](https://huggingface.co/openbmb/MiniCPM-o-2_6-int4)立即尝试!
* [2025.01.13] 🔥🔥🔥 我们开源了 MiniCPM-o 2.6,在视觉、语音和多模态实时流媒体方面媲美 GPT-4o-202405。它提升了 MiniCPM-V 2.6 的热门功能,并支持各种有趣的新特性。立即尝试吧!
* [2024.08.15] 我们现在还支持多图像 SFT。有关更多详细信息,请参阅[文档](https://github.com/OpenBMB/MiniCPM-V/tree/main/finetune)。
* [2024.08.14] MiniCPM-V 2.6 现在还支持使用 SWIFT 框架进行[微调](https://github.com/modelscope/ms-swift/issues/1613)!
* [2024.08.17] 🚀🚀🚀 MiniCPM-V 2.6 现已获得 [官方](https://github.com/ggerganov/llama.cpp) llama.cpp 的全面支持!各种大小的 GGUF 模型可在[此处](https://huggingface.co/openbmb/MiniCPM-V-2_6-gguf)获取。
* [2024.08.10] 🚀🚀🚀 MiniCPM-Llama3-V 2.5 现已获得 [官方](https://github.com/ggerganov/llama.cpp) llama.cpp 的全面支持!各种大小的 GGUF 模型可在[此处](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5-gguf)获取。
* [2024.08.06] 🔥🔥🔥 我们开源了 MiniCPM-V 2.6,它在单图像、多图像和视频理解方面超越了 GPT-4V。它提升了 MiniCPM-Llama3-V 2.5 的热门功能,并可在 iPad 上支持实时视频理解。立即尝试吧!
* [2024.08.03] MiniCPM-Llama3-V 2.5 技术报告发布!请见[此处](https://arxiv.org/abs/2408.01800)。
* [2024.07.19] MiniCPM-Llama3-V 2.5 现已支持 vLLM!请见[此处](#inference-with-vllm)。
* [2024.06.03] 现在,您可以通过将模型层分布到多个 GPU 上,在多个低显存 GPU(12 GB 或 16 GB)上运行 MiniCPM-Llama3-V 2.5。有关更多详细信息,请查看此[链接](https://github.com/OpenBMB/MiniCPM-V/blob/main/docs/inference_on_multiple_gpus.md)。
* [2024.05.28] 🚀🚀🚀 MiniCPM-Llama3-V 2.5 现已在 llama.cpp 和 Ollama 中全面支持其功能!请拉取**我们提供的 Fork**([llama.cpp](https://github.com/OpenBMB/llama.cpp/blob/minicpm-v2.5/examples/minicpmv/README.md)、[Ollama](https://github.com/OpenBMB/ollama/tree/minicpm-v2.5/examples/minicpm-v2.5))的最新代码。各种大小的 GGUF 模型可在[此处](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5-gguf/tree/main)获取。MiniCPM-Llama3-V 2.5 系列**尚未得到官方仓库的支持**,我们正在努力合并 PR。敬请期待!
* [2024.05.28] 💫 我们现在支持 MiniCPM-Llama3-V 2.5 的 LoRA 微调,仅需 2 块 V100 GPU!在[此处](https://github.com/OpenBMB/MiniCPM-V/tree/main/finetune#model-fine-tuning-memory-usage-statistics)查看更多统计数据。
* [2024.05.25] MiniCPM-Llama3-V 2.5 现在支持流式输出和自定义系统提示词。在[此处](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5#usage)尝试!
* [2024.05.24] 我们发布了 MiniCPM-Llama3-V 2.5 [gguf](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5-gguf),支持 [llama.cpp](#inference-with-llamacpp) 推理,并在手机上提供 6~8 token/s 的流畅解码。立即尝试吧!
* [2024.05.23] 🔍 我们发布了 Phi-3-vision-128k-instruct 和 MiniCPM-Llama3-V 2.5 之间的全面比较,包括基准评估、多语言能力和推理效率 🌟📊🌍🚀。点击[此处](./docs/compare_with_phi-3_vision.md)查看更多详情。
* [2024.05.20] 我们开源了 MiniCPM-Llama3-V 2.5,它具有更强的 OCR 能力并支持 30 多种语言,是首个达到 GPT-4V 水平性能的端侧 MLLM!我们提供了[高效推理](#deployment-on-mobile-phone)和[简单微调](./finetune/readme.md)。立即尝试吧!
* [2024.04.23] MiniM-V-2.0 现在支持 vLLM!点击[此处](#inference-with-vllm)查看更多详情。
* [2024.04.18] 我们创建了一个 HuggingFace Space 来托管 MiniCPM-V 2.0 的演示,请访问[此处](https://huggingface.co/spaces/openbmb/MiniCPM-V-2)!
* [2024.04.17] MiniCPM-V-2.0 现已支持部署 [WebUI 演示](#webui-demo)!
* [2024.04.15] MiniCPM-V-2.0 现在还支持使用 SWIFT 框架进行[微调](https://github.com/modelscope/swift/blob/main/docs/source/Multi-Modal/minicpm-v-2最佳实践.md),并启用了流式推理!
* [2024.04.12] 我们开源了 MiniCPM-V 2.0,它在理解场景文本方面实现了与 Gemini Pro 相当的性能,并在 OpenCompass (包含 11 个流行基准的综合评估)上超越了强大的 Qwen-VL-Chat 9.6B 和 Yi-VL 34B。点击 此处 查看 MiniCPM-V 2.0 技术博客。
* [2024.03.14] MiniCPM-V 现在支持使用 SWIFT 框架进行[微调](https://github.com/modelscope/swift/blob/main/docs/source/Multi-Modal/minicpm-v最佳实践.md)。感谢 [Jintao](https://github.com/Jintao-Huang) 的贡献!
* [2024.03.01] MiniCPM-V 现在可以部署在 Mac 上了!
* [2024.02.01] 我们开源了 MiniCPM-V 和 OmniLMM-12B,分别支持高效的端侧部署和强大的多模态能力。
## 目录
- [MiniCPM-V 4.6](#minicpm-v-46)
- [用法](#usages)
- [MiniCPM-o 4.5](#minicpm-o-45)
- [用法](#usages-1)
- [MiniCPM-V \& o 食谱](#minicpm-v--o-cookbook)
- [支持的推理与训练框架](#supported-inference-and-training-frameworks)
- [模型库](#model-zoo)
- [使用 MiniCPM-V \& o 的优秀作品](#awesome-work-using-minicpm-v--o)
- [技术报告与关键技术论文](#technical-reports-and-key-techniques-papers)
## MiniCPM-V 4.6
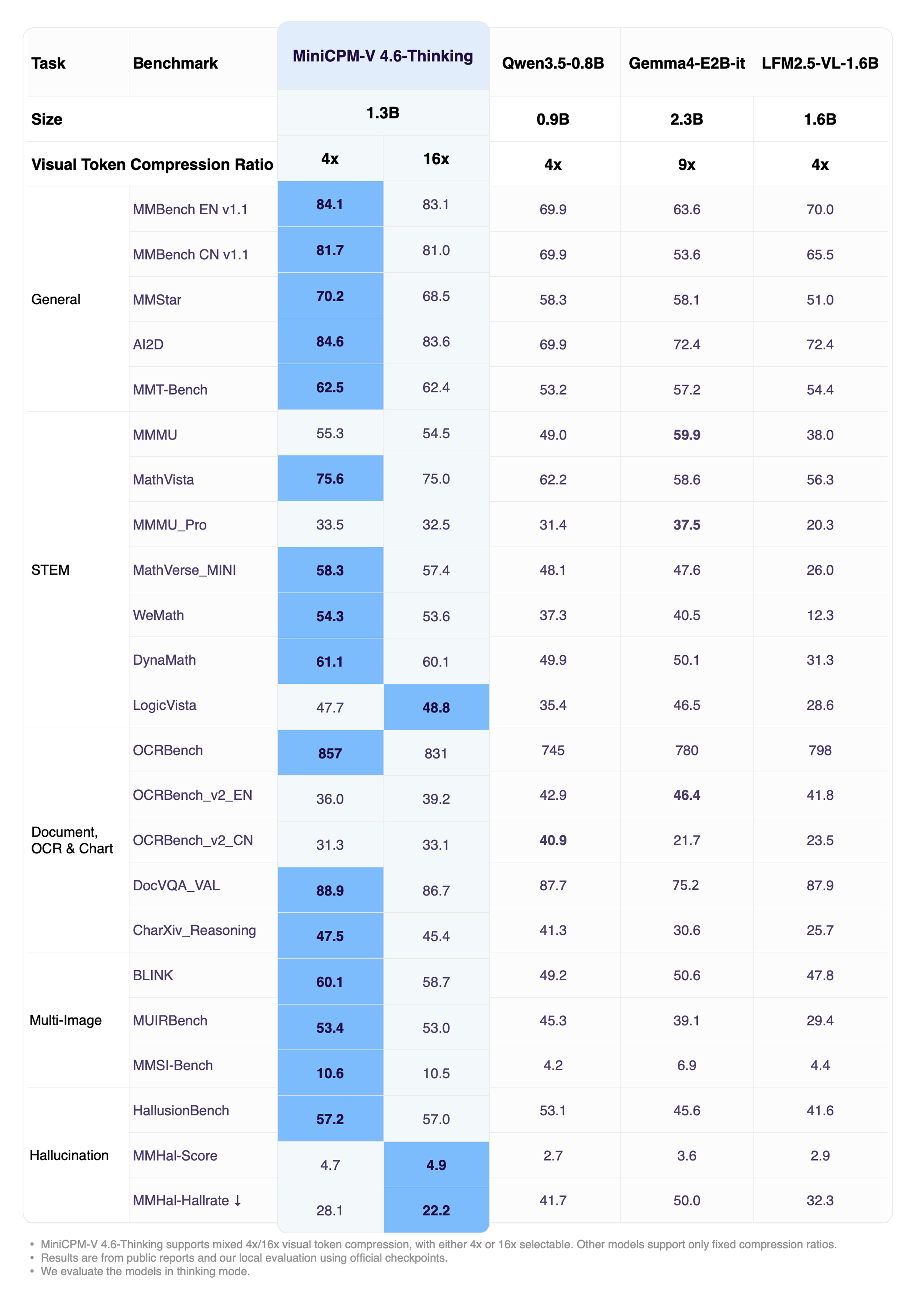
**MiniCPM-V 4.6** 是我们迄今为止对边缘部署最友好的模型。该模型基于 SigLIP2-400M 和 Qwen3.5-0.8B LLM 构建。它继承了 MiniCPM-V 家族强大的单图像、多图像和视频理解能力,同时显著提高了计算效率。它还引入了混合 4x/16x 视觉 token 压缩。MiniCPM-V 4.6 的显著特性包括:
- 🔥 **领先的基础能力。**
MiniCPM-V 4.6 在 Artificial Analysis Intelligence Index 基准测试中得分为 13,超越了得分 10 的 Qwen3.5-0.8B(token 成本降低 19 倍)和得分 11 的 Qwen3.5-0.8B-Thinking(token 成本降低 43 倍)。它还超越了更大的 Ministral 3 3B(得分 11)。
- 💪 **强大的多模态能力。**
MiniCPM-V 4.6 在大多数视觉-语言理解任务上超越了 Qwen3.5-0.8B,并在包括 OpenCompass、RefCOCO、HallusionBench、MUIRBench 和 OCRBench 在内的许多基准测试中达到了 Qwen3.5 2B 级别的能力。
- 🚀 **超高效的架构。**
基于 [LLaVA-UHD v4](https://huggingface.co/papers/2605.08985) 中的最新技术,MiniCPM-V 4.6 将视觉编码计算 FLOPs 降低了 50% 以上。它使 MiniCPM-V 4.6 能够实现比更小模型更好的效率,与 Qwen3.5-0.8B 相比实现了约 1.5 倍的 token 吞吐量。
它还支持混合 4x/16x 视觉 token 压缩率,允许在准确性和速度之间灵活切换。
- 📱 **广泛的移动平台覆盖。**
MiniCPM-V 4.6 可部署在所有三大主流移动平台——iOS、Android 和 HarmonyOS 上。随着所有边缘适配代码的开源,开发者只需[几个步骤](#deploy-minicpm-v-46-on-ios-android-and-harmonyos-platforms-)即可复现设备上的体验。
- 🛠️ **对开发者友好。**
MiniCPM-V 4.6 已适配 [推理框架](#supported-inference-and-training-frameworks)(如 SGLang、vLLM、llama.cpp、Ollama),并支持[微调生态系统](#supported-inference-and-training-frameworks)(如 SWIFT 和 LLaMA-Factory)。开发者可以在消费级 GPU 上快速为新领域和任务定制模型。我们提供了 GGUF、BNB、AWQ 和 GPTQ 格式的多种量化变体。
### 评估
**整体性能 (Instruct)**
点击查看 MiniCPM-V 4.6-Thinking 性能。
**MiniCPM-V 4.6 推理效率**
High-Concurrency Throughput Single Request TTFT (ms)
### 示例
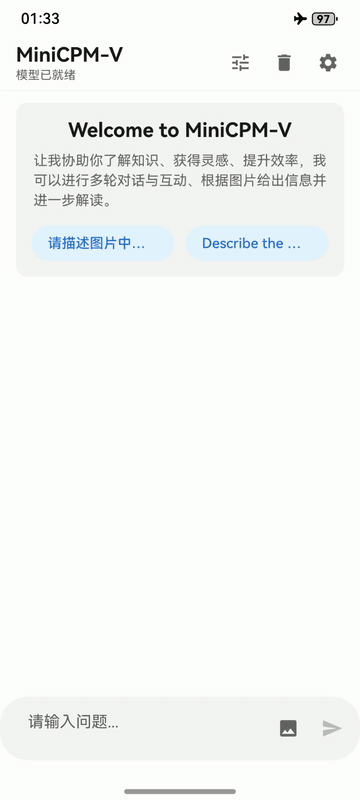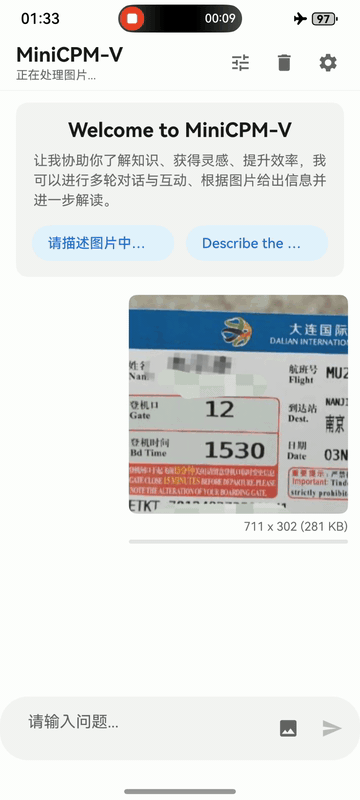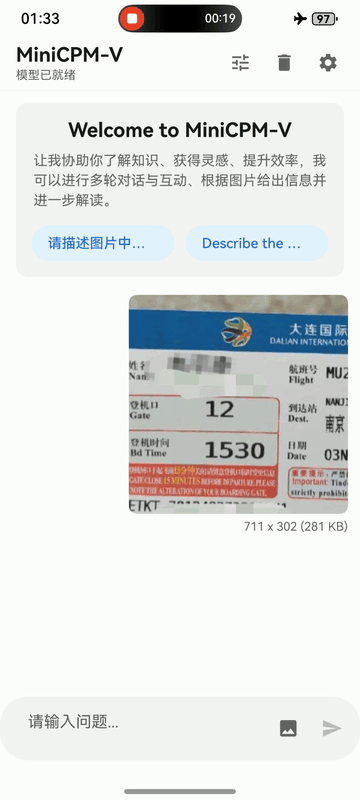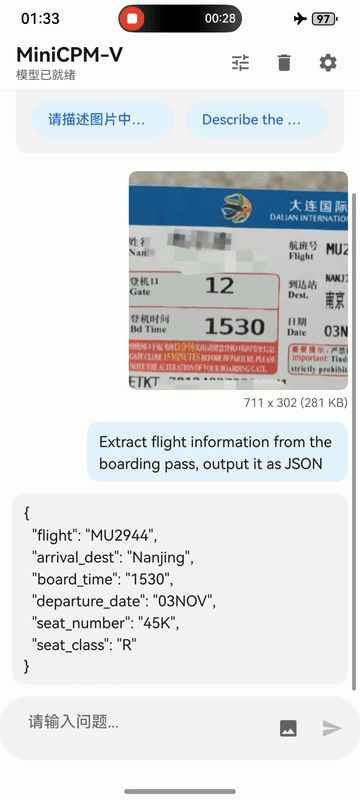
MiniCPM-V 4.6 可部署在三大主流端侧平台——**iOS、Android 和 HarmonyOS** 上。下面的片段是手机设备上的原始录屏,未经剪辑。
iPhone iPhone 17 Pro Max Android Redmi K70 HarmonyOS HUAWEI nova 14
### 用法
#### 使用 Transformers 推理
点击展示使用 Transformers 的推理示例。
##### 安装
```
pip install "transformers[torch]>=5.7.0" torchvision torchcodec
```
##### 加载模型
```
from transformers import AutoModelForImageTextToText, AutoProcessor
model_id = "openbmb/MiniCPM-V-4.6"
processor = AutoProcessor.from_pretrained(model_id)
model = AutoModelForImageTextToText.from_pretrained(
model_id, torch_dtype="auto", device_map="auto"
)
# 为了获得更好的加速效果和节省内存,建议使用 Flash Attention 2,
# 尤其是在多图像和视频场景中。
# model = AutoModelForImageTextToText.from_pretrained(
# model_id,
# torch_dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
# device_map="auto",
# )
```
##### 图像推理
```
messages = [
{
"role": "user",
"content": [
{"type": "image", "url": "https://huggingface.co/datasets/openbmb/DemoCase/resolve/main/refract.png"},
{"type": "text", "text": "What causes this phenomenon?"},
],
}
]
downsample_mode = "16x" # Using `downsample_mode="4x"` for Finer Detail
inputs = processor.apply_chat_template(
messages, tokenize=True, add_generation_prompt=True,
return_dict=True, return_tensors="pt",
downsample_mode=downsample_mode,
max_slice_nums=36,
).to(model.device)
generated_ids = model.generate(**inputs, downsample_mode=downsample_mode, max_new_tokens=512)
generated_ids_trimmed = [
out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text[0])
```
##### 视频推理
```
messages = [
{
"role": "user",
"content": [
{"type": "video", "url": "https://huggingface.co/datasets/openbmb/DemoCase/resolve/main/football.mp4"},
{"type": "text", "text": "Describe this video in detail. Follow the timeline and focus on on-screen text, interface changes, main actions, and scene changes."},
],
}
]
downsample_mode = "16x" # Using `downsample_mode="4x"` for Finer Detail
inputs = processor.apply_chat_template(
messages, tokenize=True, add_generation_prompt=True,
return_dict=True, return_tensors="pt",
downsample_mode=downsample_mode,
max_num_frames=128,
stack_frames=1,
max_slice_nums=1,
use_image_id=False,
).to(model.device)
generated_ids = model.generate(**inputs, downsample_mode=downsample_mode, max_new_tokens=2048)
generated_ids_trimmed = [
out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text[0])
```
##### 高级参数
您可以通过向 `apply_chat_template` 传递额外的参数来自定义图像/视频处理:
| 参数 | 默认值 | 应用于 | 描述 |
|-----------|---------|------------|-------------|
| `downsample_mode` | `"16x"` | 图像和视频 | 视觉 token 下采样。`"16x"` 将 token 合并以提高效率;`"4x"` 保留多出 4 倍的 token 以获取更精细的细节。还必须传递给 `generate()`。 |
| `max_slice_nums` | `9` | 图像和视频 | 分割高分辨率图像时的最大切片数。值越高,大图像保留的细节越多。推荐:图像为 `36`,视频为 `1`。 |
| `max_num_frames` | `128` | 仅视频 | 从视频中采样的最大主帧数。 |
| `stack_frames` | `1` | 仅视频 | 每秒总采样点数。`1` = 仅主帧(无堆叠)。`N` (N>1) = 每秒 1 个主帧 + N−1 个子帧;子帧被合成网格图像并与主帧交错。推荐:`3` 或 `5`。 |
| `use_image_id` | `True` | 图像和视频 | 是否在每个图像/帧占位符之前添加 `N ` 标签。推荐:图像为 `True`,视频为 `False`。 |
##### 使用 `transformers serve` 服务
Hugging Face Transformers 包含一个轻量级的 OpenAI 兼容服务器,可用于快速测试和中等负载的部署。
```
pip install "transformers[serving]>=5.7.0"
```
启动服务器:
```
transformers serve openbmb/MiniCPM-V-4.6 --port 8000 --host 0.0.0.0 --continuous-batching
```
发送请求:
```
curl -s http://localhost:8000/v1/chat/completions \
-H 'Content-Type: application/json' \
-d '{
"model": "openbmb/MiniCPM-V-4.6",
"messages": [{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": "https://huggingface.co/datasets/openbmb/DemoCase/resolve/main/refract.png"}},
{"type": "text", "text": "What causes this phenomenon?"}
]
}]
}'
```
#### 在 iOS、Android 和 HarmonyOS 平台上部署 MiniCPM-V 4.6
我们**开源了所有这些平台的边缘部署指南**,以便开发者可以在几个步骤内部署到自己的设备上。通过[下载页面](https://github.com/OpenBMB/MiniCPM-V-Apps/blob/main/DOWNLOAD.md)试用应用程序,或按照[边缘部署指南](https://github.com/OpenBMB/MiniCPM-V-Apps)获取完整源代码。
#### 在其他推理和训练框架中使用 MiniCPM-V 4.6
MiniCPM-V 4.6 支持[推理框架](#supported-inference-and-training-frameworks)(包括 SGLang、vLLM、llama.cpp、Ollama)和[训练框架](#supported-inference-and-training-frameworks)(包括 LLaMA-Factory、SWIFT)。
### 致谢
点击查看致谢。
我们要感谢以下项目:
* [Qwen3.5](https://huggingface.co/collections/Qwen/qwen35) 提供语言骨干网络
* [SigLIP2](https://github.com/google-research/big_vision/blob/main/big_vision/configs/proj/image_text/README_siglip2.md) 提供视觉理解模块
* [Transformers](https://github.com/huggingface/transformers)
## MiniCPM-o 4.5
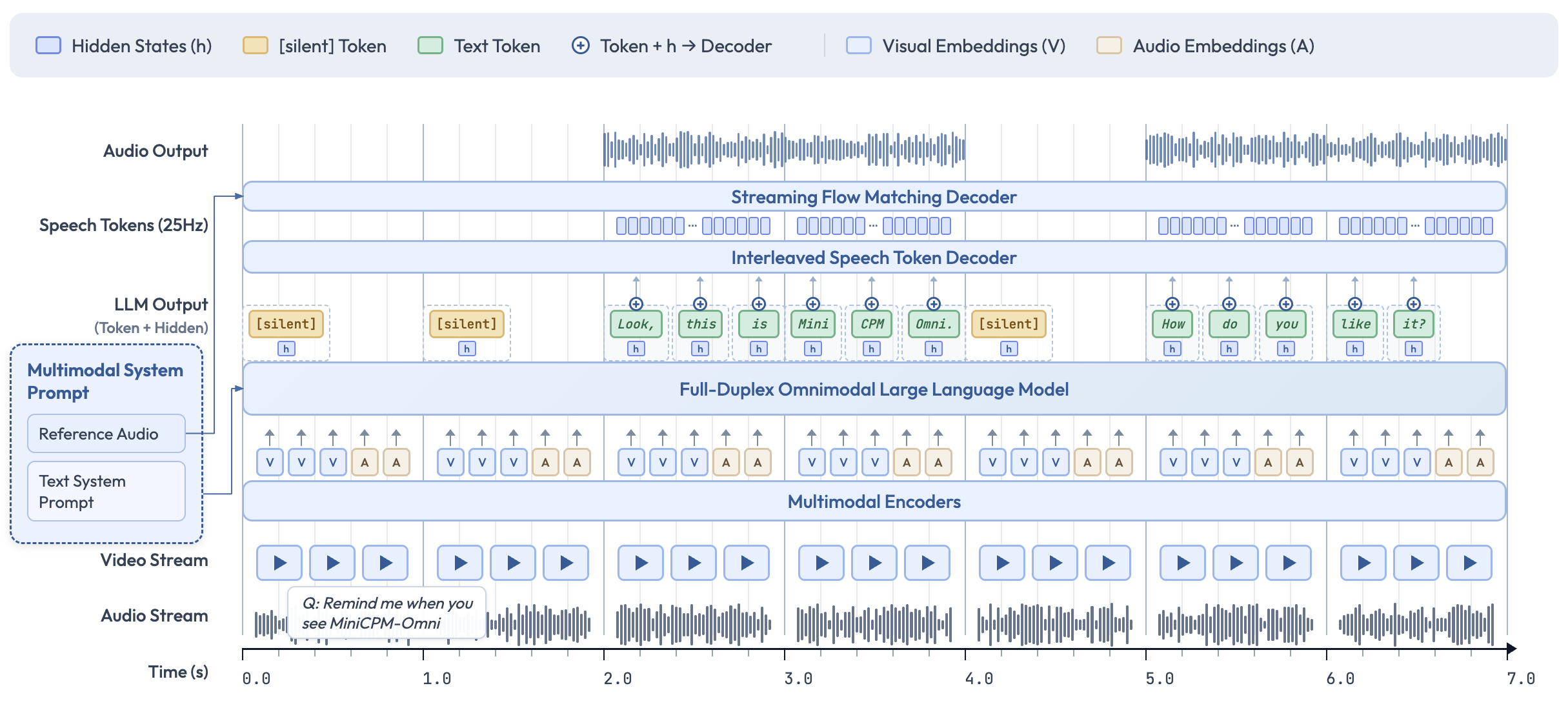
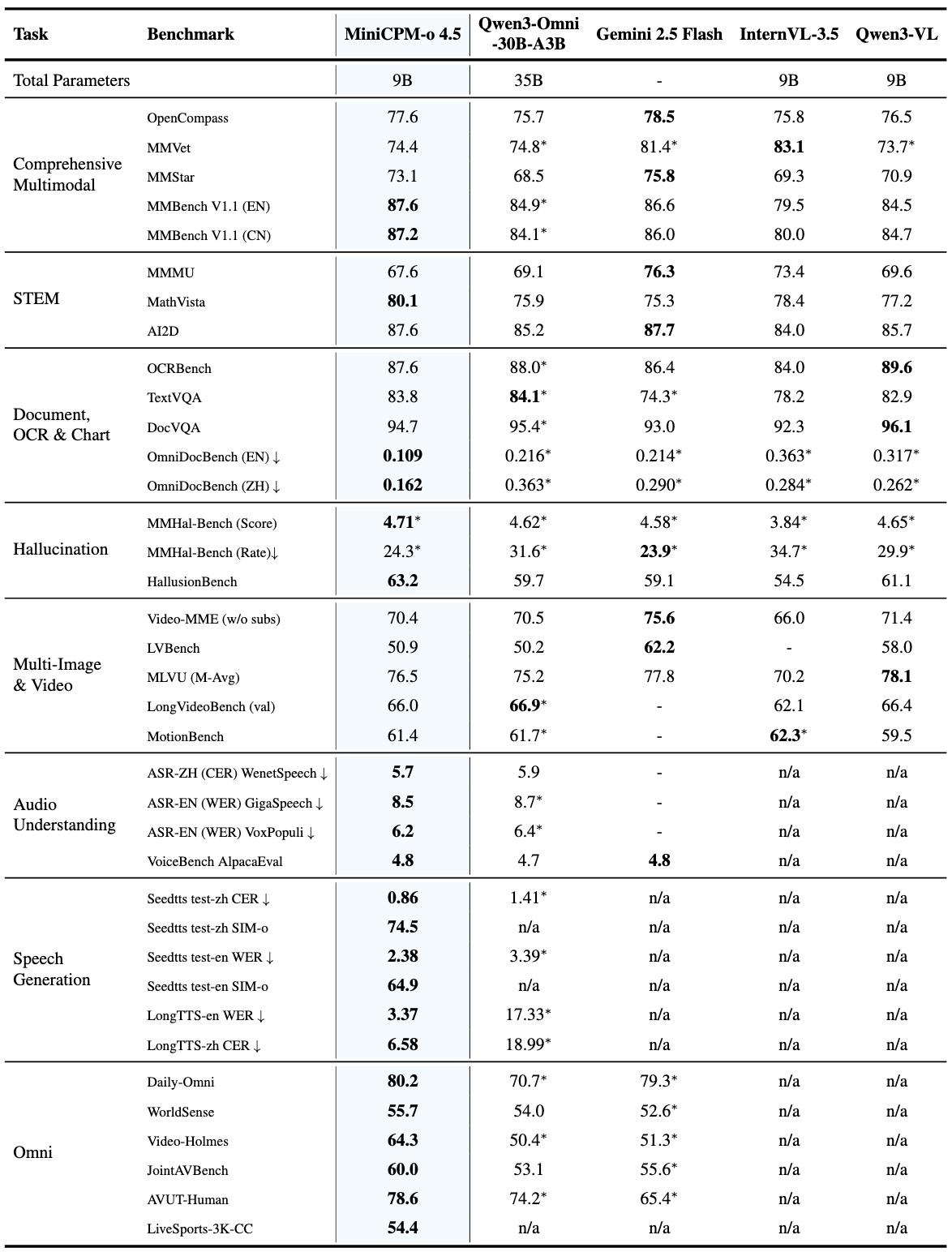
**MiniCPM-o 4.5** 是 MiniCPM-o 系列中最新且功能最强大的模型。该模型以端到端方式构建,基于 SigLip2、Whisper-medium、CosyVoice2 和 Qwen3-8B,总参数量为 9B。它展现了显著的性能提升,并引入了全双工多模态实时流媒体的新功能。MiniCPM-o 4.5 的显著特性包括:
- 🔥 **领先的视觉能力。**
MiniCPM-o 4.5 在包含 8 个流行基准测试的综合评估 OpenCompass 上取得了 77.6 的平均分。**仅有 9B 参数,它在视觉-语言能力上超越了广泛使用的专有模型(如 GPT-4o、Gemini 2.0 Pro),并接近 Gemini 2.5 Flash 的水平**。它在单个模型中支持 Instruct 和 Thinking 模式,更好地覆盖了不同用户场景下的效率和性能权衡。
- 🎙 **强大的语音能力。**
MiniCPM-o 4.5 支持**中英文双语实时语音对话,并支持可配置的声音**。它具有**更自然、富有表现力且稳定的语音对话**功能。该模型还支持有趣的功能,例如**通过简单的参考音频片段进行声音克隆和角色扮演**,其克隆性能超越了 CosyVoice2 等强大的 TTS 工具。
- 🎬 **全新的全双工和主动多模态实时流媒体能力。**
作为一项新功能,MiniCPM-o 4.5 能够以端到端的方式,在实时处理连续的视频和音频输入流的同时,生成并发的文本和语音输出流,且互不阻塞。这使得 **MiniCPM-o 4.5 能够同时看、听和说**,创造了流畅、实时的全模态对话体验。除了被动响应外,该模型还可以执行**主动交互**,例如根据对现场场景的持续理解主动发起提醒或评论。
- 💪 **强大的 OCR 能力、效率及其他。**
提升了 MiniCPM-V 系列中受欢迎的视觉能力,MiniCPM-o 4.5 能够高效处理任意宽高比的**高分辨率图像**(最高 180 万像素)和**高 FPS 视频**(最高 10fps)。它在 OmniDocBench 上实现了**端到端英文文档解析的最优性能**,超越了 Gemini-3 Flash 和 GPT-5 等专有模型,以及 DeepSeek-OCR 2 等专业工具。它还具有**可信赖的行为**,在 MMHal-Bench 上媲美 Gemini 2.5 Flash,并支持 30 多种语言的**多语言能力**。
- 💫 **易用性。**
MiniCPM-o 4.5 可以通过多种方式轻松使用:**基本用法,推荐用于 100% 精度:** 使用 Nvidia GPU 的 PyTorch 推理。**其他端侧适配**包括(1)支持 llama.cpp 和 Ollama 以在本地设备上进行高效的 CPU 推理,(2)提供 int4 和 GGUF 格式的 16 种大小的量化模型,(3)支持 vLLM 和 SGLang 进行高吞吐量和内存高效的推理,(4)支持 FlagOS 统一的多芯片后端插件。**我们还开源了 Web 演示**,能够在**本地设备(如 GPU、PC(例如 MacBook))上实现全双工多模态实时流媒体体验**。
**模型架构。**
- **端到端的全模态架构。** 模态编码器/解码器和 LLM 以端到端的方式通过隐藏状态密集连接。这实现了更好的信息流和控制,也有助于在训练期间充分利用丰富的多模态知识。
- **全双工全模态实时流媒体机制。** (1)我们将离线模态编码器/解码器转变为用于流式输入/输出的在线和全双工模式。语音 token 解码器以交错的方式对文本和语音 token 进行建模,以支持全双工语音生成(即,与新输入及时同步)。这也促进了更稳定的长语音生成(例如,> 1 分钟)。
(2)**我们以毫秒为单位同步时间线上的所有输入和输出流**,这些流通过LM 骨干网络中的时分多路复用(TDM)机制进行联合建模,用于全模态流媒体处理。它将并行的全模态流划分为小周期时间片内的顺序信息组。
- **主动交互机制。** LLM 持续监控输入的视频和音频流,并以 1Hz 的频率决定是否说话。这种高决策频率和全双工特性对于实现主动交互能力至关重要。
- **可配置的语音建模设计。** 我们继承了 MiniCPM-o 2.6 的多模态系统提示词设计,包括传统的文本系统提示词,以及用于确定助手声音的新音频系统提示词。这使得在推理时能够为语音对话克隆新声音和进行角色扮演。
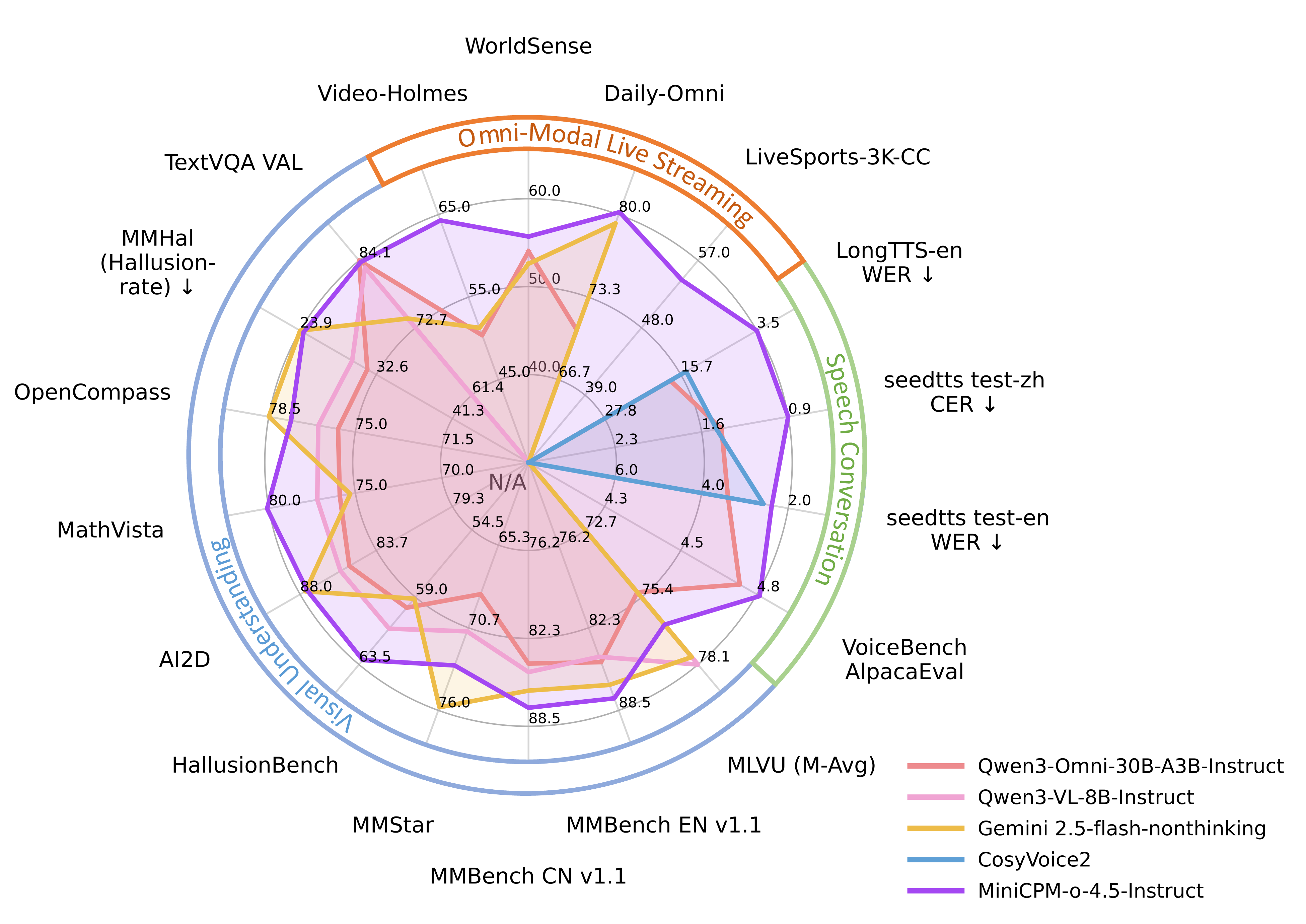
### 评估
点击查看 MiniCPM-o 4.5 的详细评估结果。
Note : Scores marked with ∗ are from our evaluation; others are cited from referenced reports. n/a indicates that the model does not support the corresponding modality. All results are reported in instruct mode/variant.
点击查看视觉理解结果。
**图像理解**
模型 OpenCompass MMBench EN v1.1 MMBench CN v1.1 MathVista MMVet MMMU MMStar HallusionBench AI2D OCRBench TextVQA_VAL DocVQA_VAL MMT-Bench_VAL MM-IFEval Mantis-Eval MuirBench MMSI-Bench MMHal-Score MMHal-Hallrate↓
Gemini2.5-Flash-Nonthinking
78.5 86.6 86.0 75.3
81.4 * 76.3 75.8 59.1
87.7 864
74.3*
93.0
70.0 * 75.8* 72.8*
74.5* 12.1*
4.6 * 23.9*
Gemini2.0-Pro
73.3
83.0
83.0
71.3
70.4
72.6
68.5
49.8
84.8
863
-
-
-
-
-
-
-
-
-
GPT-4o
75.4
86.0
86.0 71.6
76.9
72.9
70.2
57.0
86.3
822
77.4
93.0
66.7*
64.6
70.1*
70.5*
8.1*
4.2*
25.0*
InternVL-3.5-8B
75.8
79.5
80.0*
78.4 83.1 73.4 69.3
54.5
84.0
840
78.2
92.3
66.7
56.3*
70.5
55.8
-
3.8*
34.7*
Qwen3-VL-8B-Instruct
76.5
84.5
84.7
77.2
73.7*
69.6
70.9
61.1 85.7
896 82.9*
96.1 60.9*
59.4*
74.2*
64.4
11.3*
4.7* 29.9*
Qwen3-Omni-30B-A3B-Instruct
75.7
84.9*
84.1*
75.9
74.8*
69.1
68.5
59.7
85.2
880 * 84.1* 95.4 * 70.4* 65.7*
78.3 * 61.9*
14.2 * 4.6 * 31.6*
MiniCPM-o 4.5-Instruct
77.6 87.6 87.2 80.1 74.4
67.6
73.1 63.2 87.6 876
83.8 94.7
69.7
66.3 79.7 72.0 16.6 4.7 24.3
**图像理解**
模型 OpenCompass MMBench EN v1.1 MMBench CN v1.1 MathVista MMVet MMMU MMStar HallusionBench AI2D OCRBench TextQA_VAL DocVQA_VAL MMT-Bench_VAL MM-IFEval
Gemini2.5-Flash-Thinking
79.9 87.1
87.3
79.4
81.2* 77.7 76.5 63.5
88.7 853
73.8*
92.8
70.7*
75.7 *
GPT-5
79.7 85.5*
85.6*
81.9 77.6 81.8 75.7 65.2 89.5 807
77.8*
91.3*
72.7* 83.1*
Qwen3-VL-8B-Thinking
77.3
85.3
85.5
81.4 69.8*
74.1
75.3
65.4 84.9
819
77.8*
95.3 68.1*
73.5*
Qwen3-Omni-30B-A3B-Thinking
78.5
88.2 * 87.7* 80.0
74.8*
75.6
74.9
62.8
86.1
859 * 80.8* 94.2 * 70.9 * 69.9*
MiniCPM-o 4.5-Thinking
78.2
89.0 87.6 81.0
73.6
70.2
73.6
62.6
88.5
879 79.8 92.3
69.7
68.2
**视频理解**
模型 Video-MME LVBench MLVU LongVideoBench MotionBench
Gemini2.5-Flash-Nonthinking
75.6 62.2 77.8 -
-
InternVL-3.5-8B
66.0
-
70.2
62.1
62.3*
Qwen3-Omni-30B-A3B-Instruct
70.5 50.2
75.2
66.9* 61.7 *
MiniCPM-o 4.5-Instruct
70.4
50.9 76.5 66.0 61.4
点击查看文档解析结果。
**OmniDocBench**
方法类型 方法 OverallEdit↓ TextEdit↓ FormulaEdit↓ TableTEDS↑ TableEdit↓ Read OrderEdit↓
EN ZH EN ZH EN ZH EN ZH EN ZH EN ZH
Pipeline
MinerU 2.5
0.117*
0.172*
0.051*
0.08*
0.256 * 0.455*
85.9*
89.4*
0.115*
0.081*
0.047*
0.072*
PaddleOCR-VL
0.105 0.126 0.041 0.062 0.241 0.316 88
92.1 0.093 0.062 0.045
0.063
End-to-end Model
Qwen2.5-VL-72B
0.214
0.261
0.092
0.18
0.315
0.434
82.9
83.9
0.341
0.262
0.106
0.168
GPT 5
0.218*
0.33*
0.139*
0.344*
0.396*
0.555*
77.55*
73.09*
0.188*
0.196*
0.151*
0.227*
Gemini2.5-Flash-Nonthinking
0.214*
0.29*
0.159*
0.273*
0.368*
0.524*
80.9*
85.5*
0.197*
0.167*
0.132*
0.195*
Gemini-2.5-Pro-Nonthinking
0.148*
0.212*
0.055*
0.168*
0.356*
0.439*
85.8*
86.4*
0.13*
0.119*
0.049*
0.121*
Gemini-3 Flash-Nonthinking
0.155*
0.201*
0.138*
0.255*
0.297*
0.351*
86.4*
89.8*
0.116*
0.1*
0.072*
0.099*
doubao-1-5-thinking-vision-pro-250428
0.14
0.162
0.043
0.085
0.295
0.384
83.3
89.3
0.165
0.085
0.058
0.094
dots.ocr
0.125
0.16
0.032 0.066 0.329
0.416
88.6 89
0.099
0.092
0.04 0.067
HunyuanOCR
0.12*
0.125* 0.046*
0.071*
0.288*
0.33 * 89.6* 94.4* 0.089* 0.045* 0.055*
0.056*
DeepSeek-OCR 2
0.119*
0.146*
0.041 * 0.08*
0.256 * 0.345*
82.6*
89.9*
0.123*
0.078*
0.055*
0.081*
Qwen3-Omni-30B-A3B-Instruct
0.216*
0.363*
0.128*
0.337*
0.402*
0.529*
77.3*
71.8*
0.181*
0.255*
0.152*
0.332*
MiniCPM-o 4.5-Instruct
0.109 0.162
0.046
0.078
0.257
0.41
86.8
88.9
0.097
0.084
0.037 0.074
点击查看文本能力结果。
**文本能力**
模型 IFEval-PLS BBH CMMLU MMLU HumanEval MBPP Math500 GSM8K 平均分
Qwen3-8B-Instruct
83.0*
69.4*
78.7*
81.7* 86.6* 75.9*
84.0* 93.4*
81.6
MiniCPM-o 4.5-Instruct
84.7 81.1 79.5 77.0
86.6 76.7 77.0
94.5 82.1
点击查看全模态半双工结果。
**全模态半双工**
模型 Daily-Omni WorldSense Video-Holmes JointAVBench AVUT-Human
FutureOmni Video-MME-Short 平均分
Gemini2.5-Flash-Nonthinking
79.3 * 52.6*
51.3 * 55.6 * 65.4*
55.6*
85.5* 63.6
Qwen3-Omni-30B-A3B-Instruct
70.7*
54.0 50.4*
53.1
74.2 * 62.1 81.3*
63.7
MiniCPM-o 4.5-Instruct
80.2 55.7 64.3 60.0 78.6 56.1 84.7 68.5
点击查看视觉双工结果。
**视觉双工**
模型 LiveSports-3K-CC
LiveCC-7B-Instruct
41.5
StreamingVLM
45.6
MiniCPM-o 4.5-Instruct
54.4
点击查看音频理解结果。
**音频理解**
模型 ASR-ZH ASR-EN AST MultiTask SpeechQA
AISHELL-1 AISHELL-2 WenetSpeech test-net WenetSpeech test-meeting LibriSpeech test-clean LibriSpeech GigaSpeech test VoxPopuli-V1-En CoVoST 2 en2zh
作为一项实验性尝试,我们发现 MiniCPM-o 4.5 存在一些值得进一步研究和改进的显著局限性。
- **基础能力。** 全双工全能态直播流能力的基础性能仍有待提升。
- **全能模式下的语音输出不稳定。** 在全双工全能态直播流模式下,语音合成可能会出现字符发音错误。
- **语言混杂。** 在语音和全能模式下,模型有时会出现中英文混杂响应的情况。
- **Web 演示高延迟。** 用户在访问托管于海外服务器的 Web 演示时,可能会遇到异常的高延迟,甚至丢失部分模型输出片段。我们建议在网络条件良好的情况下进行本地部署。
### 致谢
点击查看致谢。
我们要感谢以下项目:
* [Qwen3](https://huggingface.co/Qwen/Qwen3-8B) 提供语言骨干网络
* [SigLIP2](https://github.com/google-research/big_vision/blob/main/big_vision/configs/proj/image_text/README_siglip2.md) 提供视觉理解模块
* [Whisper](https://github.com/openai/whisper) 提供音频和语音理解模块
* [CosyVoice2](https://github.com/FunAudioLLM/CosyVoice) 和 [Step-Audio2](https://github.com/stepfun-ai/Step-Audio2) 提供语音分词器及高效的 Token2Wav 模块。
* [Transformers](https://github.com/huggingface/transformers)
## MiniCPM-V & o 实践指南
[MiniCPM-V & o 实践指南](https://github.com/OpenSQZ/MiniCPM-V-CookBook) 提供了基于场景的方案,涵盖使用 MiniCPM-V 和 MiniCPM-o 进行部署、微调、量化和构建演示的步骤。[文档网站](https://minicpm-o.readthedocs.io/en/latest/index.html) 以结构化的方式呈现这些方案,方便快速查阅。
该指南面向:
* **个人用户**:本地推理、量化部署和端侧设备演示。
* **企业用户**:可扩展服务、高吞吐量推理和生产级部署。
* **研究人员**:微调、模型适配和实验性工作流。
有关特定框架的部署和训练指南,请参见[支持的推理与训练框架](#supported-inference-and-training-frameworks)。
## 支持的推理与训练框架
### 推理:vLLM, SGLang, llama.cpp, Ollama, FlagOS
我们支持使用 vLLM、SGLang、llama.cpp 和 Ollama 进行推理。请参阅下方各模型的部署指南,或访问我们的[实践指南](https://github.com/OpenSQZ/MiniCPM-V-CookBook)获取更多详情。
| 框架 | MiniCPM-V 4.6 | MiniCPM-o 4.5 | MiniCPM-V 4.5 | MiniCPM-V 4.0 | 先前 MiniCPM-V/o 模型 |
|:---|:---:|:---:|:---:|:---:|:---:|
| vLLM | [指南](https://github.com/OpenSQZ/MiniCPM-V-CookBook/blob/main/deployment/vllm/minicpm-v4_6_vllm.md) | [指南](https://github.com/OpenSQZ/MiniCPM-V-CookBook/blob/main/deployment/vllm/minicpm-o4_5_vllm.md) | [指南](https://github.com/OpenSQZ/MiniCPM-V-CookBook/blob/main/deployment/vllm/minicpm-v4_5_vllm.md) | [指南](https://github.com/OpenSQZ/MiniCPM-V-CookBook/blob/main/deployment/vllm/minicpm-v4_vllm.md) | [指南](https://github.com/OpenSQZ/MiniCPM-V-CookBook/blob/main/deployment/vllm/README.md) |
| SGLang | [指南](https://github.com/OpenSQZ/MiniCPM-V-CookBook/blob/main/deployment/sglang/minicpm-v4_6_sglang.md) | [指南](https://github.com/OpenSQZ/MiniCPM-V-CookBook/blob/main/deployment/sglang/MiniCPM-o4_5_sglang.md) | [指南](https://github.com/OpenSQZ/MiniCPM-V-CookBook/blob/main/deployment/sglang/minicpm-v4_5_sglang.md) | [指南](https://github.com/OpenSQZ/MiniCPM-V-CookBook/blob/main/deployment/sglang/MiniCPM-v4_sglang.md) | [指南](https://github.com/OpenSQZ/MiniCPM-V-CookBook/blob/main/deployment/sglang/README.md) |
| llama.cpp | [指南](https://github.com/OpenSQZ/MiniCPM-V-CookBook/blob/main/deployment/llama.cpp/minicpm-v4_6_llamacpp.md) | [指南](https://github.com/OpenSQZ/MiniCPM-V-CookBook/blob/main/deployment/llama.cpp/minicpm-o4_5_llamacpp.md) | [指南](https://github.com/OpenSQZ/MiniCPM-V-CookBook/blob/main/deployment/llama.cpp/minicpm-v4_5_llamacpp.md) | [指南](https://github.com/OpenSQZ/MiniCPM-V-CookBook/blob/main/deployment/llama.cpp/minicpm-v4_llamacpp.md) | [指南](https://github.com/OpenSQZ/MiniCPM-V-CookBook/blob/main/deployment/llama.cpp/README.md) |
| Ollama | [指南](https://github.com/OpenSQZ/MiniCPM-V-CookBook/blob/main/deployment/ollama/minicpm-v4_6_ollama.md) | [指南](https://github.com/OpenSQZ/MiniCPM-V-CookBook/blob/main/deployment/ollama/minicpm-o4_5_ollama.md) | [指南](https://github.com/OpenSQZ/MiniCPM-V-CookBook/blob/main/deployment/ollama/minicpm-v4_5_ollama.md) | [指南](https://github.com/OpenSQZ/MiniCPM-V-CookBook/blob/main/deployment/ollama/minicpm-v4_ollama.md) | [指南](https://github.com/OpenSQZ/MiniCPM-V-CookBook/blob/main/deployment/ollama/README.md) |
#### FlagOS
FlagOS 支持在包括 Nvidia GPU 在内的六大家族 AI 芯片上对 MiniCPM-o 4.5 进行推理。
点击显示 FlagOS 支持详情。
为了实现跨不同 AI 芯片的大规模部署,北京智源研究院联合国内外众多研究机构、芯片厂商、系统厂商以及算法与软件组织,共同发起并建立了 FlagOS 开源社区。
FlagOS 社区致力于为各种 AI 芯片构建统一的开源系统软件栈,涵盖大规模算子库、统一 AI 编译器、并行训练与推理框架以及统一通信库等核心开源项目。旨在打造连接“模型-系统-芯片”层的开放技术生态。通过实现“一次开发,跨芯片部署”,FlagOS 释放了硬件的计算潜力,打破了不同芯片软件栈之间的生态孤岛,有效降低了开发者的迁移成本。FlagOS 社区孕育了软硬件 AI 生态,克服了单一厂商闭源垄断的问题,促进了 AI 硬件技术的广泛部署,并致力于扎根中国,拥抱全球合作。
官方网站:https://flagos.io。
##### FlagOS:支持多种 AI 芯片
得益于 FlagOS 统一的多芯片 AI 系统软件栈,MiniCPM-o 4.5 在极短的时间内适配了 6 款不同的 AI 芯片。目前,MiniCPM-o 4.5 的多芯片版本已在 FlagRelease(FlagOS 的跨多架构 AI 芯片大模型自动迁移、适配和部署平台)上发布。详情如下:
| 厂商 | ModelScope | Huggingface |
|:----------------|:------------:|:------------:|
| Nvidia | [MiniCPM-o-4.5-nvidia-FlagOS](https://modelscope.cn/models/FlagRelease/MiniCPM-o-4.5-nvidia-FlagOS) | [MiniCPM-o-4.5-nvidia-FlagOS](https://huggingface.co/FlagRelease/MiniCPM-o-4.5-nvidia-FlagOS) |
| Hygon-BW1000 | [MiniCPM-o-4.5-hygon-FlagOS](https://modelscope.cn/models/FlagRelease/MiniCPM-o-4.5-hygon-FlagOS) | [MiniCPM-o-4.5-hygon-FlagOS](https://huggingface.co/FlagRelease/MiniCPM-o-4.5-hygon-FlagOS) |
| Metax-C550 | [MiniCPM-o-4.5-metax-FlagOS](https://modelscope.cn/models/FlagRelease/MiniCPM-o-4.5-metax-FlagOS) | [MiniCPM-o-4.5-metax-FlagOS](https://huggingface.co/FlagRelease/MiniCPM-o-4.5-metax-FlagOS) |
| Iluvatar-BIV150 | [MiniCPM-o-4.5-iluvatar-FlagOS](https://modelscope.cn/models/FlagRelease/MiniCPM-o-4.5-iluvatar-FlagOS) | [MiniCPM-o-4.5-iluvatar-FlagOS](https://huggingface.co/FlagRelease/MiniCPM-o-4.5-iluvatar-FlagOS) |
| Ascend-A3 | [MiniCPM-o-4.5-ascend-FlagOS](https://modelscope.cn/models/FlagRelease/MiniCPM-o-4.5-ascend-FlagOS) | [MiniCPM-o-4.5-ascend-FlagOS](https://huggingface.co/FlagRelease/MiniCPM-o-4.5-ascend-FlagOS) |
| Zhenwu-810E | [MiniCPM-o-4.5-zhenwu-FlagOS](https://modelscope.cn/models/FlagRelease/MiniCPM-o-4.5-zhenwu-FlagOS) | [MiniCPM-o-4.5-zhenwu-FlagOS](https://huggingface.co/FlagRelease/MiniCPM-o-4.5-zhenwu-FlagOS) |
###### 全面评估
**Transformers-FlagOS 版本**
在多后端上使用 `USE_FLAGOS=1` 与在 Nvidia-CUDA 上使用 `USE_FLAGOS=0` 的精度差异
| 指标 | FlagOS 后端 | 与 Nvidia-CUDA 的差异 |
|:-------------------------|:---------------:|:---------------------------:|
| Video-MME 0-shot avg@1 ↑ | Nvidia | 0.33% |
| Video-MME 0-shot avg@1 ↑ | Hygon-BW1000 | 0.17% |
| Video-MME 0-shot avg@1 ↑ | Ascend-A3 | 0.50% |
| Video-MME 0-shot avg@1 ↑ | Iluvatar-BIV150 | 1.83% |
| Video-MME 0-shot avg@1 ↑ | Metax-C550 | 0.75% |
**VLLM-FlagOS 版本**
在 Nvidia 上使用 `USE_FLAGGEMS=1 FLAGCX_PATH=/workspace/FlagCX` 或在 ZHENW 810E 上使用 `USE_FLAGGEMS=1`,与直接在 Nvidia 上启动 vllm 服务器的精度差异
| 指标 (avg@1) | Nvidia-FlagOS 与 Nvidia-CUDA 的差异 | Zhenwu-FlagOS 与 Nvidia-CUDA 的差异 |
|:--------------------|:------------------------------------------------:|:------------------------------------------------:|
| CMMMU ↑ | 0.72% | 3.5% |
| MMMU ↑ | 1.44% | 1.18% |
| MMMU_Pro_standard ↑ | 0.83% | 0.22% |
| MM-Vet v2 ↑ | 0.46% | 1.33% |
| OCRBench ↑ | 0.10% | 1% |
| CII-Bench ↑ | 0.40% | 0.13% |
| Blink ↑ | 1.90% | 2.19% |
##### FlagOS 使用说明
###### FlagOS 在 Nvidia 上的性能加速
在 Transformers 版本中,在 CUDA 和 FlagOS 生态系统精度对齐的前提下,FlagOS 在总任务执行时间上比 CUDA 实现了 6% 的性能提升。
**从 FlagRelease 获取【推荐】**
FlagRelease 是由 FlagOS 团队开发的跨多架构 AI 芯片大模型自动迁移、适配和部署平台。MiniCPM-o 4.5 的多芯片版本已在 FlagRelease 上发布。平台上预装了所有必需的软件包,用户无需进行安装。
- FlagRelease 镜像核心版本
| 组件 | 版本 |
|:------------------------|:------------------------------------|
| 加速卡驱动 | 570.158.01 |
| CUDA SDK Build | cuda_13.0.r13.0/compiler.36424714_0 |
| FlagTree | 0.4.0+3.5 |
| FlagGems | 4.2.1rc0 |
| vllm & vllm-plugin-fl | 0.13.0 + vllm_fl 0.0.0 |
| FlagCX | 0.1.0 |
- FlagRelease 快速入门
| 厂商 | ModelScope | Huggingface |
|:-----------|:------------:|:------------:|
| Nvidia | [MiniCPM-o-4.5-nvidia-FlagOS](https://modelscope.cn/models/FlagRelease/MiniCPM-o-4.5-nvidia-FlagOS) | [MiniCPM-o-4.5-nvidia-FlagOS](https://huggingface.co/FlagRelease/MiniCPM-o-4.5-nvidia-FlagOS) |
| Hygon-BW1000 | [MiniCPM-o-4.5-hygon-FlagOS](https://modelscope.cn/models/FlagRelease/MiniCPM-o-4.5-hygon-FlagOS) | [MiniCPM-o-4.5-hygon-FlagOS](https://huggingface.co/FlagRelease/MiniCPM-o-4.5-hygon-FlagOS) |
| Metax-C550 | [MiniCPM-o-4.5-metax-FlagOS](https://modelscope.cn/models/FlagRelease/MiniCPM-o-4.5-metax-FlagOS) | [MiniCPM-o-4.5-metax-FlagOS](https://huggingface.co/FlagRelease/MiniCPM-o-4.5-metax-FlagOS) |
| Iluvatar-BIV150 | [MiniCPM-o-4.5-iluvatar-FlagOS](https://modelscope.cn/models/FlagRelease/MiniCPM-o-4.5-iluvatar-FlagOS) | [MiniCPM-o-4.5-iluvatar-FlagOS](https://huggingface.co/FlagRelease/MiniCPM-o-4.5-iluvatar-FlagOS) |
| Ascend-A3 | [MiniCPM-o-4.5-ascend-FlagOS](https://modelscope.cn/models/FlagRelease/MiniCPM-o-4.5-ascend-FlagOS) | [MiniCPM-o-4.5-ascend-FlagOS](https://huggingface.co/FlagRelease/MiniCPM-o-4.5-ascend-FlagOS) |
| Zhenwu-810E | [MiniCPM-o-4.5-zhenwu-FlagOS](https://modelscope.cn/models/FlagRelease/MiniCPM-o-4.5-zhenwu-FlagOS) | [MiniCPM-o-4.5-zhenwu-FlagOS](https://huggingface.co/FlagRelease/MiniCPM-o-4.5-zhenwu-FlagOS) |
###### 从零开始构建
- 依赖项:Python 3.12, GLIBC 2.39, GLIBCXX 3.4.33, CXXABI 1.3.15
**Transformers**
- 安装 FlagOS 算子库
官方仓库:https://github.com/flagos-ai/FlagGems
pip install flag-gems==4.2.1rc0
- 安装 FlagOS 编译器
官方仓库:https://github.com/flagos-ai/flagtree
核心依赖版本快速参考:https://github.com/flagos-ai/FlagTree/blob/main/documents/build.md#tips-for-building
pip uninstall triton
python3 -m pip install flagtree==0.4.0+3.5 --index-url=https://resource.flagos.net/repository/flagos-pypi-hosted/simple --trusted-host=https://resource.flagos.net
- 启用加速
在您要运行的任务命令前添加 `USE_FLAGOS=1`。例如,当您运行:
python3 generate_speech_from_video.py
若要使用 MiniCPM-o-4.5 模型从视频内容生成语音响应,您可以:
USE_FLAGOS=1 python3 generate_speech_from_video.py
以此通过 FlagOS 加速此过程。
**Vllm 版本**
- 安装 FlagOS 算子库
官方:https://github.com/flagos-ai/FlagGems
pip install flag-gems==4.2.1rc0
pip install triton==3.5.1
- 启用加速
在您要运行的任务命令前添加 `USE_FLAGOS=1`。例如,当您运行:
vllm serve ${model_path} --dtype auto --gpu_memory_utilization 0.9 --trust-remote-code --max-num-batched-tokens 2048 --served-model-name cpmo --port ${Port}
要启动 MiniCPM-o-4.5 服务器,您可以:
USE_FLAGOS=1 vllm serve ${model_path} --dtype auto --gpu_memory_utilization 0.9 --trust-remote-code --max-num-batched-tokens 2048 --served-model-name cpmo --port ${Port}
以此通过 FlagOS 加速此过程。
##### 使用 FlagOS 统一多芯片后端插件
[vllm-plugin-FL](https://github.com/flagos-ai/vllm-plugin-FL) 是为 vLLM 推理/服务框架构建的插件。它基于 FlagOS 统一的多芯片后端开发,旨在扩展 vLLM 在各种硬件环境中的能力和性能。
###### 使用 vllm-plugin-FL
| 厂商 | 从零开始构建 | 从 FlagRelease 获取 |
|:-------|:-------------|:----------------|
| Nvidia | [vllm-plugin-FL/MiniCPM-o-4.5](https://github.com/flagos-ai/vllm-plugin-FL/blob/main/examples/minicpm/README.md) | [MiniCPM-o-4.5-ModelScope](https://modelscope.cn/models/FlagRelease/MiniCPM-o-4.5-nvidia-FlagOS), [MiniCPM-o-4.5-HuggingFace](https://huggingface.co/FlagRelease/MiniCPM-o-4.5-nvidia-FlagOS) |
### 训练:LLaMA-Factory, SWIFT
我们支持使用 LLaMA-Factory 和 SWIFT 进行微调。详情请参考我们的[实践指南](https://github.com/OpenSQZ/MiniCPM-V-Cookbook)。
| 框架 | MiniCPM-V 4.6 | 先前 MiniCPM-V/o 模型 |
|:---|:---:|:---:|
| LLaMA-Factory | [指南](https://github.com/OpenSQZ/MiniCPM-V-CookBook/blob/main/finetune/llamafactory_minicpmv46.md) | [指南](https://github.com/OpenSQZ/MiniCPM-V-CookBook/blob/main/finetune/llama-factory/finetune_llamafactory.md) |
| SWIFT | [指南](https://github.com/OpenSQZ/MiniCPM-V-CookBook/blob/main/finetune/swift_minicpmv46.md) | [指南](https://github.com/OpenSQZ/MiniCPM-V-CookBook/blob/main/finetune/swift.md) |
## 模型库
| 模型 | 设备 | 内存 | 描述 | 下载 |
|:-----------|:--:|:-----------:|:-------------------|:---------------:|
| MiniCPM-V 4.6 | GPU | 4 GB | 迄今为止最小的 MiniCPM-V 模型,在单图、多图和视频理解任务中具有强大的编码和解码效率。 | [🤗](https://huggingface.co/openbmb/MiniCPM-V-4.6) [
## 技术报告与核心技术研究论文
👏 欢迎探索 MiniCPM-o/V 的核心技术与研究:
**技术报告:** [MiniCPM-o 4.5](https://huggingface.co/papers/2604.27393) | [MiniCPM-V 4.5](https://arxiv.org/abs/2509.18154) | [MiniCPM-o 2.6](https://openbmb.notion.site/MiniCPM-o-2-6-A-GPT-4o-Level-MLLM-for-Vision-Speech-and-Multimodal-Live-Streaming-on-Your-Phone-185ede1b7a558042b5d5e45e6b237da9) | [MiniCPM-Llama3-V 2.5](https://arxiv.org/abs/2408.01800) | [MiniCPM-V 2.0](https://openbmb.vercel.app/minicpm-v-2)
**研究:** [LLaVA-UHD](https://github.com/thunlp/LLaVA-UHD) | [VisCPM](https://github.com/OpenBMB/VisCPM/tree/main) | [RLPR](https://github.com/OpenBMB/RLPR) | [RLHF-V](https://github.com/RLHF-V/RLHF-V) | [RLAIF-V](https://github.com/RLHF-V/RLAIF-V) | [LLaVA-UHD-v4](https://arxiv.org/abs/2605.08985)
## 引用
如果您觉得我们的模型/代码/论文对您有帮助,请考虑引用我们的论文 📝 并给我们点个 Star ⭐️!
```
@misc{cui2026minicpmo45realtimefullduplex,
title={MiniCPM-o 4.5: Towards Real-Time Full-Duplex Omni-Modal Interaction},
author={Junbo Cui and Bokai Xu and Chongyi Wang and Tianyu Yu and Weiyue Sun and Yingjing Xu and Tianran Wang and Zhihui He and Wenshuo Ma and Tianchi Cai and others},
year={2026},
url={https://arxiv.org/abs/2604.27393},
}
@proceedings{yu2025minicpmv45cookingefficient,
title={MiniCPM-V 4.5: Cooking Efficient MLLMs via Architecture, Data, and Training Recipe},
author={Tianyu Yu and Zefan Wang and Chongyi Wang and Fuwei Huang and Wenshuo Ma and Zhihui He and Tianchi Cai and Weize Chen and Yuxiang Huang and Yuanqian Zhao and others},
year={2025},
url={https://arxiv.org/abs/2509.18154},
}
@article{yao2024minicpm,
title={MiniCPM-V: A GPT-4V Level MLLM on Your Phone},
author={Yao, Yuan and Yu, Tianyu and Zhang, Ao and Wang, Chongyi and Cui, Junbo and Zhu, Hongji and Cai, Tianchi and Li, Haoyu and Zhao, Weilin and He, Zhihui and others},
journal={arXiv preprint arXiv:2408.01800},
year={2024}
}
```
标签: AI风险缓解, MiniCPM-o, MiniCPM-V, MLLM, OpenBMB, Transformer, 人工智能, 凭据扫描, 图像理解, 多模态大语言模型, 大模型, 实时交互, 微型模型, 手机AI, 模型压缩, 流媒体处理, 深度学习, 用户模式Hook绕过, 端侧AI, 端侧部署, 系统调用监控, 视觉语言模型, 视频理解, 计算机视觉, 语音交互, 语音合成, 轻量级模型, 边缘计算, 高效推理
 MiniCPM-V 4.6 可部署在三大主流端侧平台——**iOS、Android 和 HarmonyOS** 上。下面的片段是手机设备上的原始录屏,未经剪辑。
MiniCPM-V 4.6 可部署在三大主流端侧平台——**iOS、Android 和 HarmonyOS** 上。下面的片段是手机设备上的原始录屏,未经剪辑。
 ### 评估
### 评估
 Note: Scores marked with ∗ are from our evaluation; others are cited from referenced reports. n/a indicates that the model does not support the corresponding modality. All results are reported in instruct mode/variant.
Note: Scores marked with ∗ are from our evaluation; others are cited from referenced reports. n/a indicates that the model does not support the corresponding modality. All results are reported in instruct mode/variant.
 **专为手机打造的袖珍级 MLLM,实现超高效的图像与视频理解**
[中文](./README_zh.md) |
English
**专为手机打造的袖珍级 MLLM,实现超高效的图像与视频理解**
[中文](./README_zh.md) |
English

 ](https://modelscope.cn/models/OpenBMB/MiniCPM-V-4.6) |
| MiniCPM-V 4.6 gguf | CPU | 2 GB | gguf 版本,内存占用更低,推理速度更快。 | [🤗](https://huggingface.co/openbmb/MiniCPM-V-4.6-gguf) [
](https://modelscope.cn/models/OpenBMB/MiniCPM-V-4.6) |
| MiniCPM-V 4.6 gguf | CPU | 2 GB | gguf 版本,内存占用更低,推理速度更快。 | [🤗](https://huggingface.co/openbmb/MiniCPM-V-4.6-gguf) [ [THUNLP](https://nlp.csai.tsinghua.edu.cn/)
-
[THUNLP](https://nlp.csai.tsinghua.edu.cn/)
-  [ModelBest](https://modelbest.cn/)
## 🌟 Star 历史
[ModelBest](https://modelbest.cn/)
## 🌟 Star 历史