datalab-to/surya
GitHub: datalab-to/surya
Surya是一款多语言OCR工具,用于文档分析和安全评估。
Stars: 21146 | Forks: 1522
# Surya
Surya 是一个具有以下特性的 650M 参数 OCR 模型:
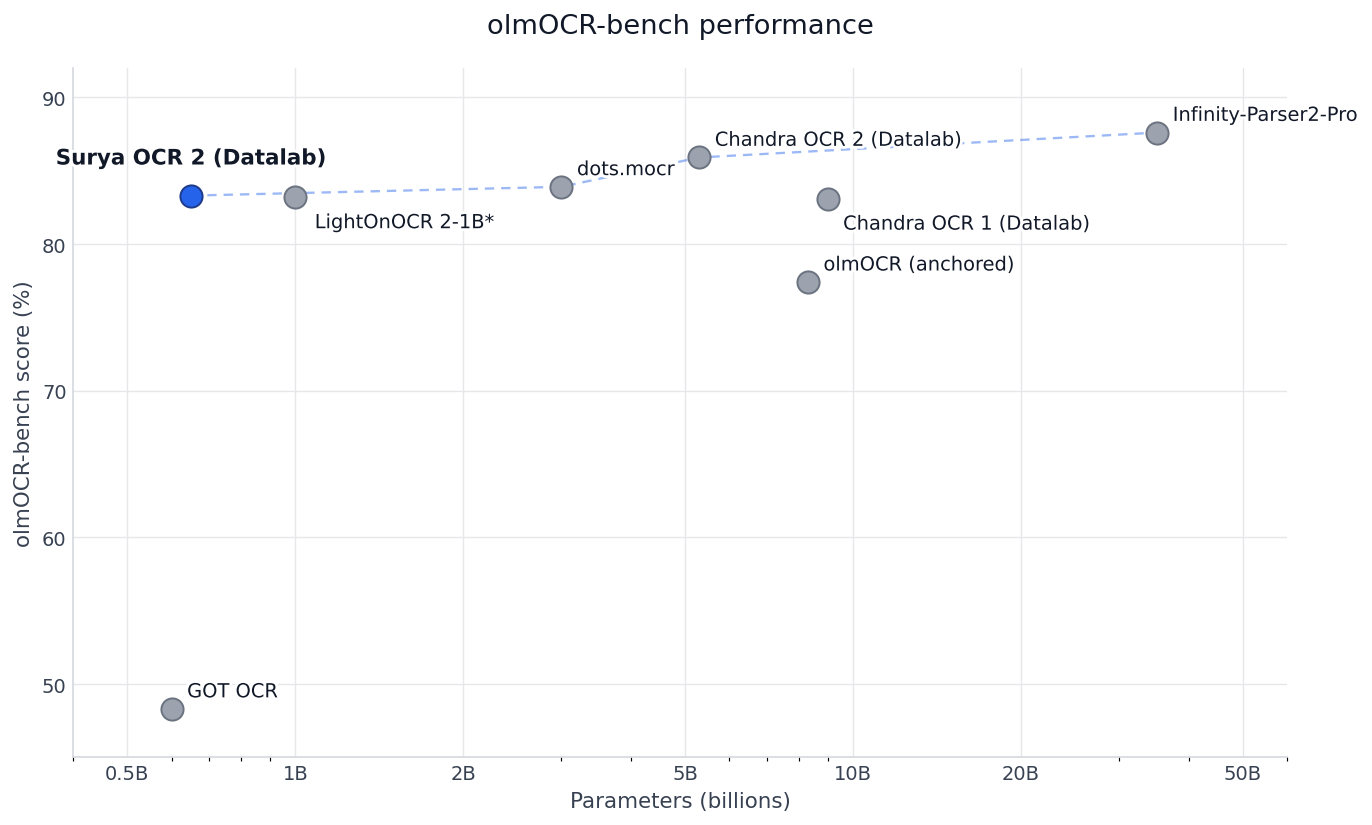
- 准确性 - 在 [olmOCR-bench](https://huggingface.co/datasets/allenai/olmOCR-bench) 上得分 83.3%(3B 参数以下最佳)
- 速度 - 在 RTX 5090 上每秒处理 5 页
- 多语言 - 在包含 91 种语言的内部基准测试中得分 87.2%(更多信息[这里](#multilingual))
- 布局分析(表格、图像、标题等)和阅读顺序
- 表格识别(行 + 列)
我们还提供更小的模型,用于行级文本检测和 OCR 错误检测。它适用于各种文档(请参阅 [用法](#usage) 和 [基准测试](#benchmarks))。
## 模型信息
 | 检测 | OCR |
|:----------------------------------------------------------------:|:-----------------------------------------------------------------------:|
|
| 检测 | OCR |
|:----------------------------------------------------------------:|:-----------------------------------------------------------------------:|
|  |
|  |
| 布局 | 表格识别 |
|:------------------------------------------------------------------:|:-------------------------------------------------------------:|
|
|
| 布局 | 表格识别 |
|:------------------------------------------------------------------:|:-------------------------------------------------------------:|
|  |
|  |
Surya 以 [印度太阳神](https://en.wikipedia.org/wiki/Surya) 命名,他拥有普世之眼。
## 示例
每一行都链接到同一页面的五个注释视图:文本行检测、OCR、布局、阅读顺序和(如有)表格识别。
| 名称 | 检测 | OCR | 布局 | 阅读顺序 | 表格识别 |
|-------------------|:-----------------------------------:|------------------------------------------:|---------------------------------------------:|------------------------------------------------:|------------------------------------------------:|
| 报纸 | [图像](static/images/newspaper.png) | [图像](static/images/newspaper_text.png) | [图像](static/images/newspaper_layout.png) | [图像](static/images/newspaper_reading.png) | |
| 教科书 | [图像](static/images/textbook.png) | [图像](static/images/textbook_text.png) | [图像](static/images/textbook_layout.png) | [图像](static/images/textbook_reading.png) | |
| 税表 | [图像](static/images/form.png) | [图像](static/images/form_text.png) | [图像](static/images/form_layout.png) | [图像](static/images/form_reading.png) | [图像](static/images/form_tablerec.png) |
| 手写笔记 | [图像](static/images/handwritten.png) | [图像](static/images/handwritten_text.png) | [图像](static/images/handwritten_layout.png) | [图像](static/images/handwritten_reading.png) | [图像](static/images/handwritten_tablerec.png) |
| 企业文档 | [图像](static/images/corporate.png) | [图像](static/images/corporate_text.png) | [图像](static/images/corporate_layout.png) | [图像](static/images/corporate_reading.png) | [图像](static/images/corporate_tablerec.png) |
# 商业用途
Surya 代码采用 Apache 2.0 许可。模型权重使用修改后的 AI Pubs Open Rail-M 许可(免费用于研究、个人用途和融资/收入低于 500 万美元的初创公司)。如需更广泛的模型权重商业许可,请访问我们的定价页面[这里](https://www.datalab.to/pricing?utm_source=gh-surya)。
# 安装
使用以下命令安装:
```
pip install surya-ocr
```
## 推理后端先决条件
Surya 首次使用时自动启动服务器,您需要 `vllm`(NVIDIA GPU)或 `llama.cpp`(CPU / Apple Silicon):
- **NVIDIA GPU:** [Docker](https://docs.docker.com/get-docker/) 加上 [NVIDIA 容器工具包](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html)。
- **CPU / Apple Silicon:** 从 llama.cpp 获取 `llama-server` 二进制文件:
brew install llama.cpp # macOS
# 或从 https://github.com/ggml-org/llama.cpp/releases 获取发布版本
## 从 Surya v1 升级
如果您有 v1 代码,可以迁移到以下版本:
```
# v2
from surya.inference import SuryaInferenceManager
from surya.recognition import RecognitionPredictor
manager = SuryaInferenceManager() # auto-spawns vllm or llama-server
rec = RecognitionPredictor(manager)
predictions = rec([image])
```
不同之处:
- `SuryaInferenceManager` 替换 `FoundationPredictor`。同一管理器实例在 `LayoutPredictor`、`RecognitionPredictor`、`TableRecPredictor` 之间共享。
- 输出模式已更改:请参阅以下每个部分的 JSON 表格。亮点 - `text_lines` → `blocks`(带有 `html`);布局删除 `top_k`,添加 `count`;表格识别从单元格中删除 `is_header` / `colspan` / `rowspan`。
# 使用
Surya 2 通过单个 VLM 运行布局、OCR 和表格识别。推理管理器将在首次使用时为您启动一个;您也可以通过 `SURYA_INFERENCE_URL=http://host:port/v1` 指向现有的服务器。
- 检查 `surya/settings.py` 中的设置。您可以通过环境变量覆盖任何设置(例如 `SURYA_INFERENCE_BACKEND=vllm`)。
- 文本检测和 OCR 错误是单独的模型。
### 服务器生命周期 (`--keep_server`)
默认情况下,每个命令在启动时启动 VLM 服务器并在退出时关闭它——因此连续运行多个命令每次都会支付启动(以及在 GPU 上,模型加载)成本。传递 `--keep_server` 以保持服务器运行,以便后续命令附加到它而不是重新启动:
```
surya_ocr DATA_PATH --keep_server # spawns the server and leaves it up
surya_layout DATA_PATH # attaches to the running server
surya_table DATA_PATH # ...and so on, no re-spawn
```
`--keep_server` 在每个命令上均有效。完成操作后停止服务器(使用 `docker stop` 停止 `surya-vllm-*` 容器,或终止 `llama-server` 进程),或设置 `SURYA_INFERENCE_KEEP_ALIVE=1` 以使 keep-alive 成为默认设置。
## 交互式应用程序
我包含了一个 streamlit 应用程序,允许您交互式地在图像或 PDF 文件上尝试 Surya。使用以下命令运行它:
```
pip install streamlit pdftext
surya_gui
```
## OCR(文本识别)
此命令将输出包含检测到的文本和 bboxes 的 json 文件:
```
surya_ocr DATA_PATH
```
- `DATA_PATH` 可以是图像、pdf 或图像/ pdf 文件的文件夹
- `--images` 将保存页面和检测到的块的图像(可选)
- `--output_dir` 指定要保存结果的目录,而不是默认目录
- `--page_range` 指定 PDF 中要处理的页面范围,指定为单个数字、逗号分隔的列表、范围或逗号分隔的范围 - 示例:`0,5-10,20`。
- `--keep_server` 在命令退出后保持推理服务器运行,以便后续命令重用它(请参阅 [服务器生命周期](#server-lifecycle---keep_server))。在所有命令上均可用。
`results.json` 文件包含一个以输入文件名(无扩展名)为键的字典。每个值都是一个包含页面字典的列表。每个页面字典包含:
- `blocks` - 按阅读顺序的每个块的 OCR 结果
- `label` - 规范化布局标签(例如 `Text`、`SectionHeader`、`Table`、`Equation`、`Picture`、`Form`、`PageHeader`、...)。有关完整的规范名称集,请参阅 `surya/layout/label.py:LAYOUT_PRED_RELABEL`。
- `raw_label` - 模型在规范化之前发出的原始标签
- `reading_order` - 布局输出中的 0 索引位置
- `html` - 块内容作为 HTML(数学用 `` 包装,表格用 `
|
Surya 以 [印度太阳神](https://en.wikipedia.org/wiki/Surya) 命名,他拥有普世之眼。
## 示例
每一行都链接到同一页面的五个注释视图:文本行检测、OCR、布局、阅读顺序和(如有)表格识别。
| 名称 | 检测 | OCR | 布局 | 阅读顺序 | 表格识别 |
|-------------------|:-----------------------------------:|------------------------------------------:|---------------------------------------------:|------------------------------------------------:|------------------------------------------------:|
| 报纸 | [图像](static/images/newspaper.png) | [图像](static/images/newspaper_text.png) | [图像](static/images/newspaper_layout.png) | [图像](static/images/newspaper_reading.png) | |
| 教科书 | [图像](static/images/textbook.png) | [图像](static/images/textbook_text.png) | [图像](static/images/textbook_layout.png) | [图像](static/images/textbook_reading.png) | |
| 税表 | [图像](static/images/form.png) | [图像](static/images/form_text.png) | [图像](static/images/form_layout.png) | [图像](static/images/form_reading.png) | [图像](static/images/form_tablerec.png) |
| 手写笔记 | [图像](static/images/handwritten.png) | [图像](static/images/handwritten_text.png) | [图像](static/images/handwritten_layout.png) | [图像](static/images/handwritten_reading.png) | [图像](static/images/handwritten_tablerec.png) |
| 企业文档 | [图像](static/images/corporate.png) | [图像](static/images/corporate_text.png) | [图像](static/images/corporate_layout.png) | [图像](static/images/corporate_reading.png) | [图像](static/images/corporate_tablerec.png) |
# 商业用途
Surya 代码采用 Apache 2.0 许可。模型权重使用修改后的 AI Pubs Open Rail-M 许可(免费用于研究、个人用途和融资/收入低于 500 万美元的初创公司)。如需更广泛的模型权重商业许可,请访问我们的定价页面[这里](https://www.datalab.to/pricing?utm_source=gh-surya)。
# 安装
使用以下命令安装:
```
pip install surya-ocr
```
## 推理后端先决条件
Surya 首次使用时自动启动服务器,您需要 `vllm`(NVIDIA GPU)或 `llama.cpp`(CPU / Apple Silicon):
- **NVIDIA GPU:** [Docker](https://docs.docker.com/get-docker/) 加上 [NVIDIA 容器工具包](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html)。
- **CPU / Apple Silicon:** 从 llama.cpp 获取 `llama-server` 二进制文件:
brew install llama.cpp # macOS
# 或从 https://github.com/ggml-org/llama.cpp/releases 获取发布版本
## 从 Surya v1 升级
如果您有 v1 代码,可以迁移到以下版本:
```
# v2
from surya.inference import SuryaInferenceManager
from surya.recognition import RecognitionPredictor
manager = SuryaInferenceManager() # auto-spawns vllm or llama-server
rec = RecognitionPredictor(manager)
predictions = rec([image])
```
不同之处:
- `SuryaInferenceManager` 替换 `FoundationPredictor`。同一管理器实例在 `LayoutPredictor`、`RecognitionPredictor`、`TableRecPredictor` 之间共享。
- 输出模式已更改:请参阅以下每个部分的 JSON 表格。亮点 - `text_lines` → `blocks`(带有 `html`);布局删除 `top_k`,添加 `count`;表格识别从单元格中删除 `is_header` / `colspan` / `rowspan`。
# 使用
Surya 2 通过单个 VLM 运行布局、OCR 和表格识别。推理管理器将在首次使用时为您启动一个;您也可以通过 `SURYA_INFERENCE_URL=http://host:port/v1` 指向现有的服务器。
- 检查 `surya/settings.py` 中的设置。您可以通过环境变量覆盖任何设置(例如 `SURYA_INFERENCE_BACKEND=vllm`)。
- 文本检测和 OCR 错误是单独的模型。
### 服务器生命周期 (`--keep_server`)
默认情况下,每个命令在启动时启动 VLM 服务器并在退出时关闭它——因此连续运行多个命令每次都会支付启动(以及在 GPU 上,模型加载)成本。传递 `--keep_server` 以保持服务器运行,以便后续命令附加到它而不是重新启动:
```
surya_ocr DATA_PATH --keep_server # spawns the server and leaves it up
surya_layout DATA_PATH # attaches to the running server
surya_table DATA_PATH # ...and so on, no re-spawn
```
`--keep_server` 在每个命令上均有效。完成操作后停止服务器(使用 `docker stop` 停止 `surya-vllm-*` 容器,或终止 `llama-server` 进程),或设置 `SURYA_INFERENCE_KEEP_ALIVE=1` 以使 keep-alive 成为默认设置。
## 交互式应用程序
我包含了一个 streamlit 应用程序,允许您交互式地在图像或 PDF 文件上尝试 Surya。使用以下命令运行它:
```
pip install streamlit pdftext
surya_gui
```
## OCR(文本识别)
此命令将输出包含检测到的文本和 bboxes 的 json 文件:
```
surya_ocr DATA_PATH
```
- `DATA_PATH` 可以是图像、pdf 或图像/ pdf 文件的文件夹
- `--images` 将保存页面和检测到的块的图像(可选)
- `--output_dir` 指定要保存结果的目录,而不是默认目录
- `--page_range` 指定 PDF 中要处理的页面范围,指定为单个数字、逗号分隔的列表、范围或逗号分隔的范围 - 示例:`0,5-10,20`。
- `--keep_server` 在命令退出后保持推理服务器运行,以便后续命令重用它(请参阅 [服务器生命周期](#server-lifecycle---keep_server))。在所有命令上均可用。
`results.json` 文件包含一个以输入文件名(无扩展名)为键的字典。每个值都是一个包含页面字典的列表。每个页面字典包含:
- `blocks` - 按阅读顺序的每个块的 OCR 结果
- `label` - 规范化布局标签(例如 `Text`、`SectionHeader`、`Table`、`Equation`、`Picture`、`Form`、`PageHeader`、...)。有关完整的规范名称集,请参阅 `surya/layout/label.py:LAYOUT_PRED_RELABEL`。
- `raw_label` - 模型在规范化之前发出的原始标签
- `reading_order` - 布局输出中的 0 索引位置
- `html` - 块内容作为 HTML(数学用 `` 包装,表格用 `...
` 包装等)。如果块被跳过,则为 `""`
- `polygon` - 按顺序 `[[x0,y0],[x1,y0],[x1,y1],[x0,y1]]` 的 4 个角的多边形
- `bbox` - 从多边形派生的轴对齐 `[x0, y0, x1, y1]`
- `confidence` - 块解码的每个标记的平均概率(0-1)
- `skipped` - 如果块是视觉标签(例如 Picture)且未进行 OCR,则为 true
- `error` - 如果块 OCR 调用失败,则为 true
- `image_bbox` - 页面图像的 `[0, 0, width, height]`
**性能提示**
- 吞吐量由推理后端控制。使用 `vllm` 时,请提高 `--max-num-seqs` / `--max-num-batched-tokens`(或客户端侧的 `SURYA_INFERENCE_PARALLEL`)以保持更多页面在飞行中。使用 `llama.cpp` 时,将 `SURYA_INFERENCE_PARALLEL` 设置为与 `llama-server` 上的 `--parallel` 相匹配。
- DPI 也会显着影响吞吐量 - 您可以调整 DPI 设置以在吞吐量/准确性之间进行权衡。尝试从 192 到 96 以提高吞吐量。
- MTP 也会影响延迟/吞吐量 - 您可以调整 vllm mtp 配置设置。
### 从 python
```
from PIL import Image
from surya.inference import SuryaInferenceManager
from surya.recognition import RecognitionPredictor
manager = SuryaInferenceManager()
recognition_predictor = RecognitionPredictor(manager)
# Default: full-page OCR. One VLM call per page. Returns one PageOCRResult per
# image: `.blocks` (each with label, html, polygon, bbox, confidence, ...) and
# `.image_bbox` — the same schema as block mode.
predictions = recognition_predictor([Image.open(IMAGE_PATH)])
# Block mode: pre-run layout, then per-block OCR. Same return schema as above.
# Auto-selected when `layout_results` is passed.
from surya.layout import LayoutPredictor
layout = LayoutPredictor(manager)
layouts = layout([Image.open(IMAGE_PATH)])
predictions = recognition_predictor([Image.open(IMAGE_PATH)], layouts)
```
## 文本行检测
此命令将输出包含检测到的 bboxes 的 json 文件。
```
surya_detect DATA_PATH
```
- `DATA_PATH` 可以是图像、pdf 或图像/ pdf 文件的文件夹
- `--images` 将保存页面和检测到的文本行的图像(可选)
- `--output_dir` 指定要保存结果的目录,而不是默认目录
- `--page_range` 指定 PDF 中要处理的页面范围,指定为单个数字、逗号分隔的列表、范围或逗号分隔的范围 - 示例:`0,5-10,20`。
`results.json` 文件将包含一个以输入文件名(无扩展名)为键的 JSON 字典。每个值将是一个包含字典的列表,每个字典对应于输入文档的一页。每个页面字典包含:
- `bboxes` - 文本检测到的边界框
- `bbox` - 文本行在 (x1, y1, x2, y2) 格式中的轴对齐矩形。 (x1, y1) 是左上角,(x2, y2) 是右下角。
- `polygon` - 文本行在 (x1, y1),(x2, y2),(x3, y3),(x4, y4) 格式中的多边形。点按顺时针顺序从左上角开始。
- `confidence` - 模型在检测到的文本中的置信度(0-1)
- `vertical_lines` - 在文档中检测到的垂直线
- `bbox` - 轴对齐线的坐标。
- `page` - 文件中的页码
- `image_bbox` - 图像的 bbox 在 (x1, y1, x2, y2) 格式中。 (x1, y1) 是左上角,(x2, y2) 是右下角。所有行边界框都将包含在此边界框内。
**性能提示**
检测是一个 torch 模型。`DETECTOR_BATCH_SIZE` 默认在运行时自动选择值;覆盖环境变量以控制 GPU 上的 VRAM 使用情况,并在较大卡上提高它。
### 从 python
```
from PIL import Image
from surya.detection import DetectionPredictor
det_predictor = DetectionPredictor()
predictions = det_predictor([Image.open(IMAGE_PATH)])
```
## 布局和阅读顺序
此命令将输出包含检测到的布局和阅读顺序的 json 文件。
```
surya_layout DATA_PATH
```
- `DATA_PATH` 可以是图像、pdf 或图像/ pdf 文件的文件夹
- `--images` 将保存页面和检测到的文本行的图像(可选)
- `--output_dir` 指定要保存结果的目录,而不是默认目录
- `--page_range` 指定 PDF 中要处理的页面范围,指定为单个数字、逗号分隔的列表、范围或逗号分隔的范围 - 示例:`0,5-10,20`。
`results.json` 文件包含一个以输入文件名(无扩展名)为键的字典。每个值是一个包含页面字典的列表。每个页面字典包含:
- `bboxes` - 按阅读顺序的布局框
- `polygon` - 4 个角的多边形 `[[x0,y0],[x1,y0],[x1,y1],[x0,y1]]`
- `bbox` - 从多边形派生的轴对齐 `[x0, y0, x1, y1]`
- `label` - 规范化标签。以下之一:`Caption`、`Footnote`、`Equation`、`ListGroup`、`PageHeader`、`PageFooter`、`Picture`、`SectionHeader`、`Table`、`Text`、`Figure`、`Code`、`Form`、`TableOfContents`、`ChemicalBlock`、`Diagram`、`Bibliography`、`BlankPage`
- `raw_label` - 模型发出的原始标签
- `position` - 0 索引的阅读顺序
- `count` - 模型对 OCR 此块进行 OCR 的令牌估计(四舍五入到 50 的倍数;用于调整每个块的解码预算)
- `confidence` - 布局解码的每个标记的平均概率(0-1)
- `image_bbox` - `[0, 0, width, height]`
- `raw` - 布局模型发出的原始 JSON,用于调试
- `error - 如果布局调用失败,则为 true
**性能提示**
布局通过共享的推理后端运行。吞吐量调整与 OCR 相同——请参阅性能提示。
### 从 python
```
from PIL import Image
from surya.inference import SuryaInferenceManager
from surya.layout import LayoutPredictor
layout_predictor = LayoutPredictor(SuryaInferenceManager())
layout_predictions = layout_predictor([Image.open(IMAGE_PATH)])
```
## 表格识别
此命令将输出包含检测到的表格单元格和行/列 ID 以及行/列边界框的 json 文件。如果您想获取单元格位置和文本以及良好的格式,请查看 [marker](https://github.com/datalab-to/marker) 仓库。您可以使用 `TableConverter` 在图像和 PDF 中检测和提取表格。它支持以 json(带有 bboxes)、markdown 和 html 格式输出。
```
surya_table DATA_PATH
```
- `DATA_PATH` 可以是图像、pdf 或图像/ pdf 文件的文件夹
- `--images` 将保存与 json 一起保存的注释行 + 列覆盖(可选)
- `--output_dir` 指定要保存结果的目录,而不是默认目录
- `--page_range` 指定 PDF 中要处理的页面范围,指定为单个数字、逗号分隔的列表、范围或逗号分隔的范围 - 示例:`0,5-10,20`。
- `--skip_table_detection` 告诉表格识别不要首先检测表格。如果您的图像已经裁剪到表格,请使用此选项。
`results.json` 文件包含一个以输入文件名(无扩展名)为键的字典。每个值是一个包含每个表格字典的列表。每个表格字典包含:
- `rows` - 按阅读顺序检测到的表格行
- `polygon` / `bbox` - 行几何形状(与其他地方相同的约定)
- `row_id` - 0 索引的行 ID
- `cols` - 检测到的表格列
- `polygon` / `bbox` - 列几何形状
- `col_id` - 0 索引的列 ID
- `cells` - 简单模式中的几何行 × 列交叉(简单模式)
- `polygon` / `bbox` - 单元格几何形状
- `row_id`、`col_id`、`cell_id`
- `html` - 完整的 `...
` HTML(仅在 `predict_full` 使用时填充;处理跨越单元格/标题行)。简单模式中为 `null`。
- `mode` - `"simple"` 或 `"full"`
- `image_bbox` - 表格裁剪的 bbox
- `error` - 如果表格识别调用失败,则为 true
- `raw` - 用于调试的原始模型输出
**性能提示**
表格识别通过共享的 VLM 路由。吞吐量调整与 OCR 相同。
### 从 python
```
from PIL import Image
from surya.inference import SuryaInferenceManager
from surya.table_rec import TableRecPredictor
table_rec_predictor = TableRecPredictor(SuryaInferenceManager())
# Default: rows + columns only, cells derived from intersections.
table_predictions = table_rec_predictor([Image.open(IMAGE_PATH)])
# Or full HTML output (better for spanning cells / headers):
# table_predictions = table_rec_predictor.predict_full([image])
```
## 数学/方程式
Surya 2 将数学作为全页 OCR 的一部分处理——识别到的方程式以与周围散文相同的 HTML 输出返回,在 KaTeX 兼容的 LaTeX 中,无需单独的 LaTeX OCR 过程。
# 推理后端
布局、OCR 和表格识别都共享一个 VLM,由 `vllm`(GPU)或 `llama.cpp`(CPU / Apple Silicon)提供。`SuryaInferenceManager` 将自动启动一个;您也可以指向一个正在运行的预启动服务器:
```
# Attach to an existing vllm
export SURYA_INFERENCE_BACKEND=vllm
export SURYA_INFERENCE_URL=http://localhost:8000/v1
```
| 设置 | 默认 | 备注 |
|-----------------------------------|-----------------------------------|--------------------------------------------------------|
| `SURYA_INFERENCE_BACKEND` | auto (NVIDIA 有 vllm,否则 llamacpp) | `vllm` \| `llamacpp` \| unset (auto) |
| `SURYA_INFERENCE_URL` | (自动启动) | 连接到正在运行的 OpenAI 兼容服务器 |
| `SURYA_INFERENCE_PARALLEL` | 8 | 后端客户端并发 |
| `SURYA_INFERENCE_KEEP_ALIVE` | false | 退出后保持启动的服务器运行(请参阅 `--keep_server`) |
| `SURYA_GUIDED_LAYOUT` | true | JSON-schema 限制的布局解码 |
# 局限性
- 这专门用于文档 OCR。在照片或自然场景上的性能不是目标。
- 布局、OCR 和表格识别都需要一个正在运行的推理后端(vllm 或 llama.cpp)。检测完全在 torch 上运行,无需它。
## 故障排除
如果 OCR 未能正常工作:
- 尝试提高图像的分辨率,以便文本更大。如果分辨率已经非常高,请尝试将其降低到不超过 `2048px` 宽度。
- 对图像进行预处理(二值化、倾斜校正等)可以帮助非常旧的/模糊的图像。
- 如果您
| 检测 | OCR |
|:----------------------------------------------------------------:|:-----------------------------------------------------------------------:|
| | |
| 布局 | 表格识别 |
|:------------------------------------------------------------------:|:-------------------------------------------------------------:|
| | |
Surya 以 [印度太阳神](https://en.wikipedia.org/wiki/Surya) 命名,他拥有普世之眼。
## 示例
每一行都链接到同一页面的五个注释视图:文本行检测、OCR、布局、阅读顺序和(如有)表格识别。
| 名称 | 检测 | OCR | 布局 | 阅读顺序 | 表格识别 |
|-------------------|:-----------------------------------:|------------------------------------------:|---------------------------------------------:|------------------------------------------------:|------------------------------------------------:|
| 报纸 | [图像](static/images/newspaper.png) | [图像](static/images/newspaper_text.png) | [图像](static/images/newspaper_layout.png) | [图像](static/images/newspaper_reading.png) | |
| 教科书 | [图像](static/images/textbook.png) | [图像](static/images/textbook_text.png) | [图像](static/images/textbook_layout.png) | [图像](static/images/textbook_reading.png) | |
| 税表 | [图像](static/images/form.png) | [图像](static/images/form_text.png) | [图像](static/images/form_layout.png) | [图像](static/images/form_reading.png) | [图像](static/images/form_tablerec.png) |
| 手写笔记 | [图像](static/images/handwritten.png) | [图像](static/images/handwritten_text.png) | [图像](static/images/handwritten_layout.png) | [图像](static/images/handwritten_reading.png) | [图像](static/images/handwritten_tablerec.png) |
| 企业文档 | [图像](static/images/corporate.png) | [图像](static/images/corporate_text.png) | [图像](static/images/corporate_layout.png) | [图像](static/images/corporate_reading.png) | [图像](static/images/corporate_tablerec.png) |
# 商业用途
Surya 代码采用 Apache 2.0 许可。模型权重使用修改后的 AI Pubs Open Rail-M 许可(免费用于研究、个人用途和融资/收入低于 500 万美元的初创公司)。如需更广泛的模型权重商业许可,请访问我们的定价页面[这里](https://www.datalab.to/pricing?utm_source=gh-surya)。
# 安装
使用以下命令安装:
```
pip install surya-ocr
```
## 推理后端先决条件
Surya 首次使用时自动启动服务器,您需要 `vllm`(NVIDIA GPU)或 `llama.cpp`(CPU / Apple Silicon):
- **NVIDIA GPU:** [Docker](https://docs.docker.com/get-docker/) 加上 [NVIDIA 容器工具包](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html)。
- **CPU / Apple Silicon:** 从 llama.cpp 获取 `llama-server` 二进制文件:
brew install llama.cpp # macOS
# 或从 https://github.com/ggml-org/llama.cpp/releases 获取发布版本
## 从 Surya v1 升级
如果您有 v1 代码,可以迁移到以下版本:
```
# v2
from surya.inference import SuryaInferenceManager
from surya.recognition import RecognitionPredictor
manager = SuryaInferenceManager() # auto-spawns vllm or llama-server
rec = RecognitionPredictor(manager)
predictions = rec([image])
```
不同之处:
- `SuryaInferenceManager` 替换 `FoundationPredictor`。同一管理器实例在 `LayoutPredictor`、`RecognitionPredictor`、`TableRecPredictor` 之间共享。
- 输出模式已更改:请参阅以下每个部分的 JSON 表格。亮点 - `text_lines` → `blocks`(带有 `html`);布局删除 `top_k`,添加 `count`;表格识别从单元格中删除 `is_header` / `colspan` / `rowspan`。
# 使用
Surya 2 通过单个 VLM 运行布局、OCR 和表格识别。推理管理器将在首次使用时为您启动一个;您也可以通过 `SURYA_INFERENCE_URL=http://host:port/v1` 指向现有的服务器。
- 检查 `surya/settings.py` 中的设置。您可以通过环境变量覆盖任何设置(例如 `SURYA_INFERENCE_BACKEND=vllm`)。
- 文本检测和 OCR 错误是单独的模型。
### 服务器生命周期 (`--keep_server`)
默认情况下,每个命令在启动时启动 VLM 服务器并在退出时关闭它——因此连续运行多个命令每次都会支付启动(以及在 GPU 上,模型加载)成本。传递 `--keep_server` 以保持服务器运行,以便后续命令附加到它而不是重新启动:
```
surya_ocr DATA_PATH --keep_server # spawns the server and leaves it up
surya_layout DATA_PATH # attaches to the running server
surya_table DATA_PATH # ...and so on, no re-spawn
```
`--keep_server` 在每个命令上均有效。完成操作后停止服务器(使用 `docker stop` 停止 `surya-vllm-*` 容器,或终止 `llama-server` 进程),或设置 `SURYA_INFERENCE_KEEP_ALIVE=1` 以使 keep-alive 成为默认设置。
## 交互式应用程序
我包含了一个 streamlit 应用程序,允许您交互式地在图像或 PDF 文件上尝试 Surya。使用以下命令运行它:
```
pip install streamlit pdftext
surya_gui
```
## OCR(文本识别)
此命令将输出包含检测到的文本和 bboxes 的 json 文件:
```
surya_ocr DATA_PATH
```
- `DATA_PATH` 可以是图像、pdf 或图像/ pdf 文件的文件夹
- `--images` 将保存页面和检测到的块的图像(可选)
- `--output_dir` 指定要保存结果的目录,而不是默认目录
- `--page_range` 指定 PDF 中要处理的页面范围,指定为单个数字、逗号分隔的列表、范围或逗号分隔的范围 - 示例:`0,5-10,20`。
- `--keep_server` 在命令退出后保持推理服务器运行,以便后续命令重用它(请参阅 [服务器生命周期](#server-lifecycle---keep_server))。在所有命令上均可用。
`results.json` 文件包含一个以输入文件名(无扩展名)为键的字典。每个值都是一个包含页面字典的列表。每个页面字典包含:
- `blocks` - 按阅读顺序的每个块的 OCR 结果
- `label` - 规范化布局标签(例如 `Text`、`SectionHeader`、`Table`、`Equation`、`Picture`、`Form`、`PageHeader`、...)。有关完整的规范名称集,请参阅 `surya/layout/label.py:LAYOUT_PRED_RELABEL`。
- `raw_label` - 模型在规范化之前发出的原始标签
- `reading_order` - 布局输出中的 0 索引位置
- `html` - 块内容作为 HTML(数学用 `` 包装,表格用 `标签:OCR 模型, 光学字符识别, 图像识别, 多语言支持, 安全测试框架, 布局分析, 技术基准, 文本检测, 文本识别, 文档处理, 机器学习模型, 模型优化, 模型创新, 模型参数, 模型命名, 模型大小, 模型应用, 模型性能, 模型扩展, 模型效率, 模型比较, 模型精度, 模型评估, 模型速度, 模型部署, 深度学习, 表格识别, 逆向工具, 阅读顺序