LogBoost 是一款日志转换与 IP 情报丰富工具,能够将多种格式的日志统一转为 CSV 并自动补充地理位置、ASN、DNS、WhoIs、Shodan InternetDB 及威胁指标等多维度上下文信息。

LogBoost
### 这是什么?
LogBoost 是一个命令行工具,最初旨在使用免费提供的 MaxMind GeoLite2 数据库提供的 ASN、国家和城市信息,来丰富 CSV 文件中的 IP 地址。
LogBoost 可以解析并将各种结构化和半结构化日志格式转换为 CSV,同时丰富检测到的 IP 地址,支持的格式包括 JSON、IIS、W3C、ELF、CLF、CEF、KV、SYSLOG。
该工具还可以对源文件中检测到的每个 IP 地址执行反向查找,以识别当前相关的域名。如果在指定的 MaxMind 数据库目录(默认为 CWD)中检测到 'GeoLite2-Domain.mmdb',输出中也会提供丰富后的 IP 地址关联的 TLD。
除此之外,LogBoost 可以下载在 feed_config.json 中配置的基于文本的威胁情报,并将其解析到本地 SQLite 数据库中,随后利用该数据库通过指标匹配来进一步丰富检测到的 IP 地址。
此外,LogBoost 能够实时查询 IP 地址/域名的 WhoIs 服务器以及 Shodan InternetDB,从而为分析人员提供额外的丰富细节。
总而言之,LogBoost 可以将各种日志格式转换为 CSV,同时用 ASN 组织/编号、国家、城市、域名和指标匹配信息来丰富 IP 地址。
**Wiki:
**
**快速入门:
**
### 常见用例
* 丰富并合并包含数千个相似结构文件(Web 服务器日志、Cloudtrail 转储、防火墙导出等)的日志目录
* 将 JSON Lines/多行 JSON blob 转换为更易于筛选的 CSV
* 解析键值(KV)对日志,例如防火墙转储 (k1=v1,k2=v2 等)
* 将 CEF 样式的日志(来自 Syslog 或其他来源)解析为 CSV
* 通过威胁指标匹配,在任何被检查的文件中查找可疑的 IP 地址
* 丰富 IP 地址,以便在任何被检查的文件中查找关联的域名和地理位置
### 示例用法
要使用此工具,只需下载最新版本的二进制文件(如果您希望使用威胁情报增强结果,还需下载 feed_config.json)。此外,请在
注册一个免费的 MaxMind 账户,以获取免费 GeoLite2 数据库的许可证密钥。获取该密钥后,您可以将其放入环境变量 (`MM_API`) 中、放入 CWD 的文件 (`mm_api.txt`) 中,或者通过 `-api` 标志在命令行中提供。
#### 常见用法
* ```LogBoost.exe -buildti``` - 在本地构建威胁指标数据库 - 同时会更新所有已配置的订阅源。
* ```LogBoost.exe -updateti``` - 更新威胁指标数据库 - 定期运行以从配置的订阅源中提取新指标。
* ```LogBoost.exe -updateti -includedc``` - 更新威胁指标数据库,并包含数据中心 IP 地址 - 这将增加约 1.29 亿个 IP,占用约 7 GB 的磁盘空间。这通常是不必要的,因为 LogBoost 还包含一个内置的 ASN 编号列表,源自
。
* ```LogBoost.exe -logdir logs -regex -api XXX``` - 使用地理位置信息丰富包含一个或多个 CSV 文件的目录,使用正则表达式查找每行中的第一个非私有 IP 地址。
* ```LogBoost.exe -useti -dns -whois -idb -getall -convert -regex``` - 使用威胁情报、DNS、WhoIS、InternetDB 和 MaxMind 数据丰富 /input 中的任何文件。
* ```LogBoost.exe -logdir input -jsoncol data -ipcol client -fullparse``` - 丰富 'input' 中的任何 CSV 文件,同时展开位于名为 'data' 的列中的 JSON blob - 被丰富的 IP 地址将从名为 'client' 的列中提取。
* ```LogBoost.exe -logdir input -jsoncol data -fullparse -regex``` - 与上相同,但使用正则表达式查找第一个非私有 IP 地址。
* ```LogBoost.exe -logdir input -jsoncol data -fullparse -regex -useti``` - 与上相同,但同时使用威胁指标数据库以 IP 匹配进行丰富。
* ```LogBoost.exe -logdir input -jsoncol data -fullparse -regex -useti -dns``` - 与上相同,但对每个 IP 地址执行实时 DNS 查找以查找任何关联的域名。
* ```LogBoost.exe -logdir logs -convert -rawtxt``` - 处理 'logs' 中的所有 .csv/.log/.txt 文件 - 寻找相关的解析器,或者作为最后手段将其解析为原始文本。
* ```LogBoost.exe -logdir logs -convert -getall``` - 使用相关解析器或作为最后手段解析为原始文本,处理 'logs' 中扩展名不受限制的任何文件。
* ``` LogBoost.exe -logdir logs -maxgoperfile 40 -batchsize 100 -writebuffer 2000 -concurrentfiles 1000``` - 最多处理 1k 个并发文件,每个文件 40 个“线程”,每个线程处理 100 条记录,并且每个输出的写入器一次缓冲 2000 条记录。
* ```LogBoost.exe -logdir logs -convert -dns -useti -regex -combine ``` 查找 'logs' 中的所有 .csv/.log/.txt 文件,并使用威胁指标和 DNS 丰富通过正则提取的 IP,如果检测到该格式的解析器,则将所有输出文件合并为一个单一的 CSV。
* ```LogBoost.exe -convert -logdir iislogs -startdate 01/01/2023 -datecol date -dateformat 2006-01-02 -convert -enddate 01/04/2023``` - 解析并转换将日期存储在名为 'date' 的列/键中、且格式如指定的日志,范围包含起止日期。
### 示例输出
Enriching Azure Audit Log Export
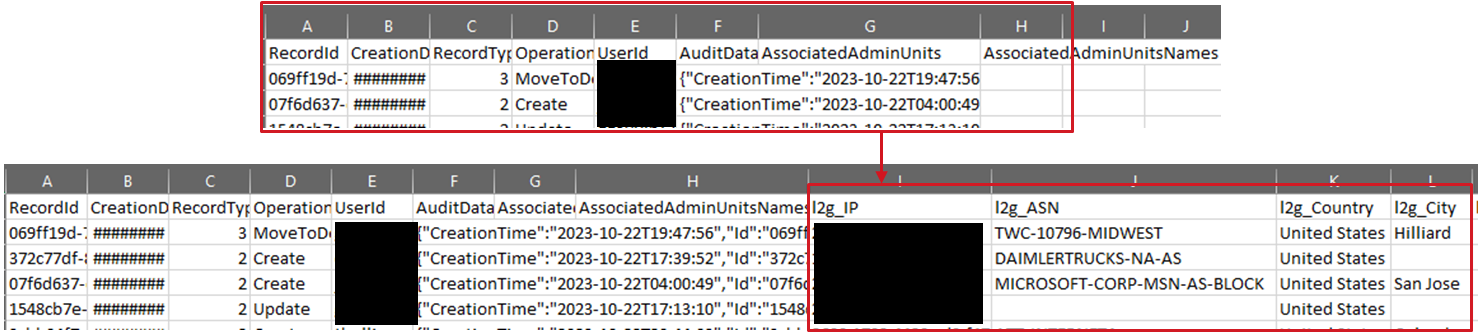
Enriching and Expanding Azure Audit Log Export
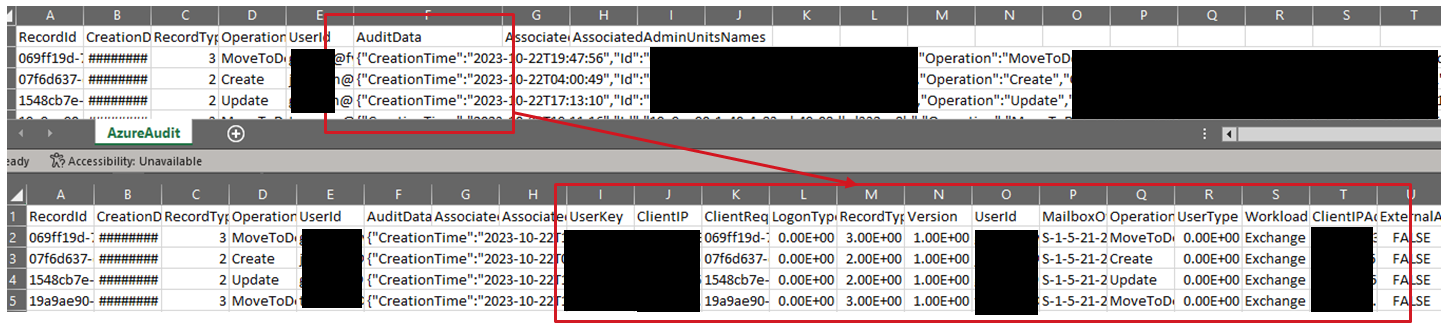
Enriching IPs with DNS (Live and MaxMind TLD if available)
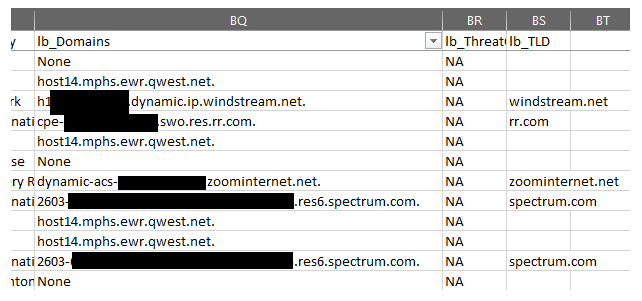
Enriching logs with built-in threat indicators
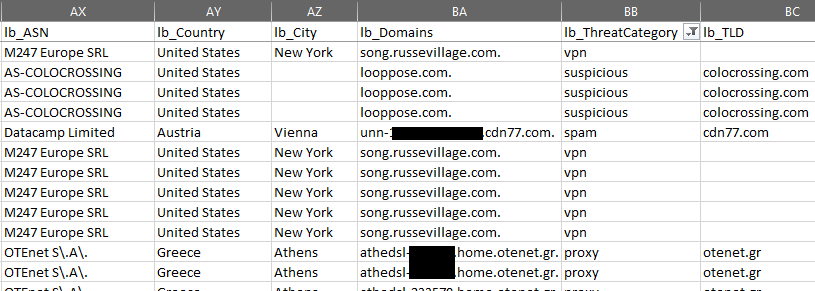
Convert Common/Combined Log Format to CSV while enriching source IP address
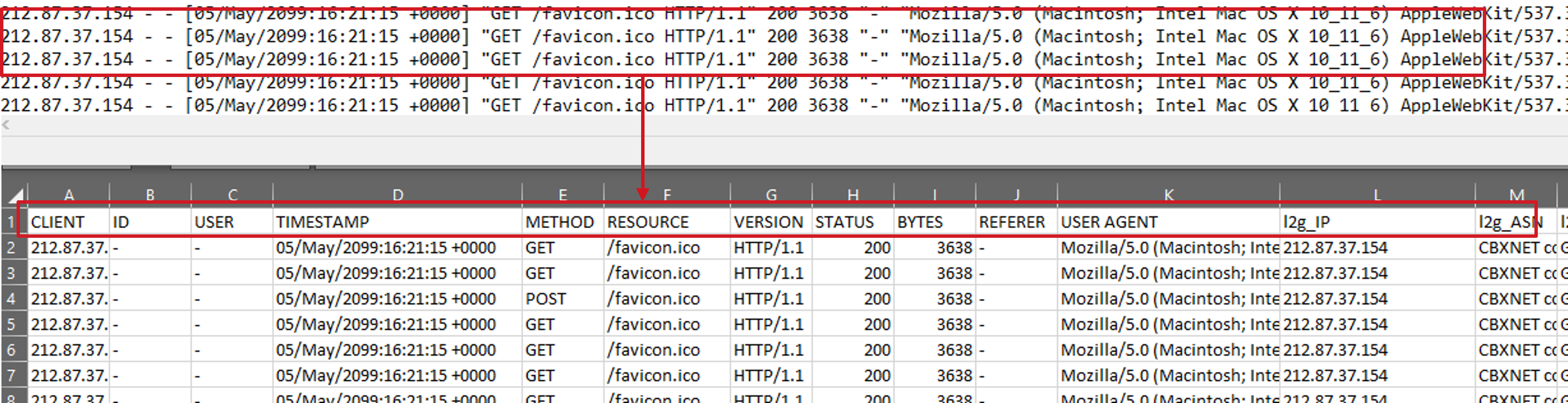
Converting JSON Lines using Shallow or Deep Key parsing
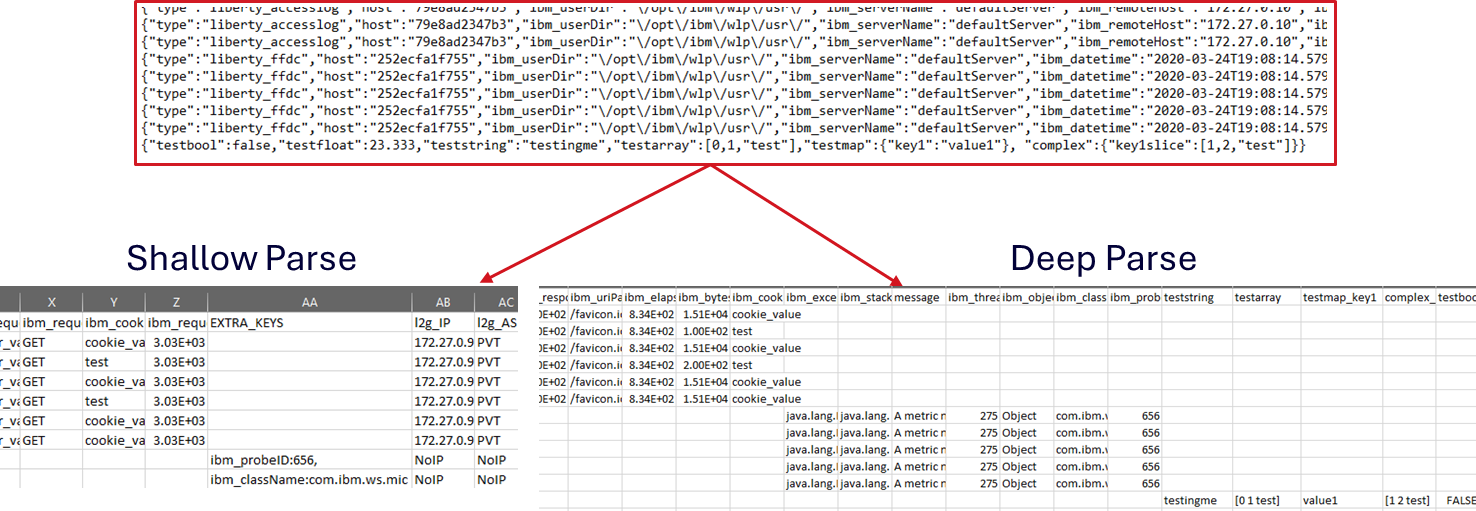
Parsing CloudTrail Multi-Line Records
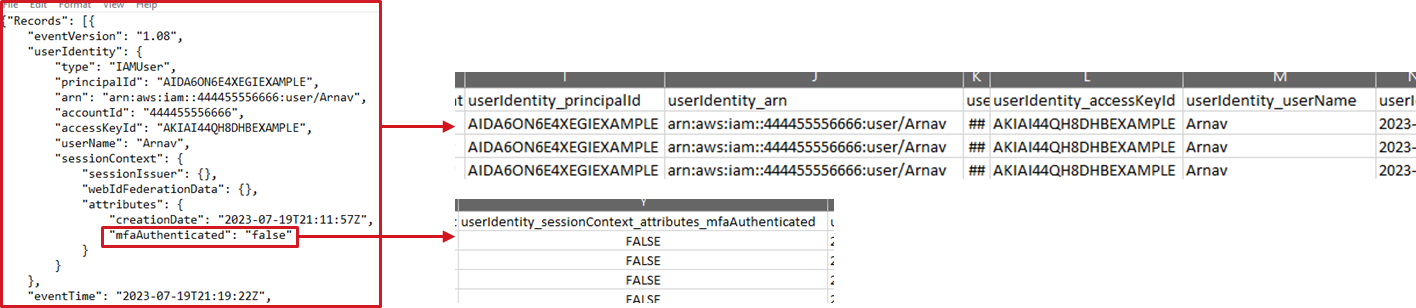
Parsing arbitrary KV-style logs using provided separators/delimiters
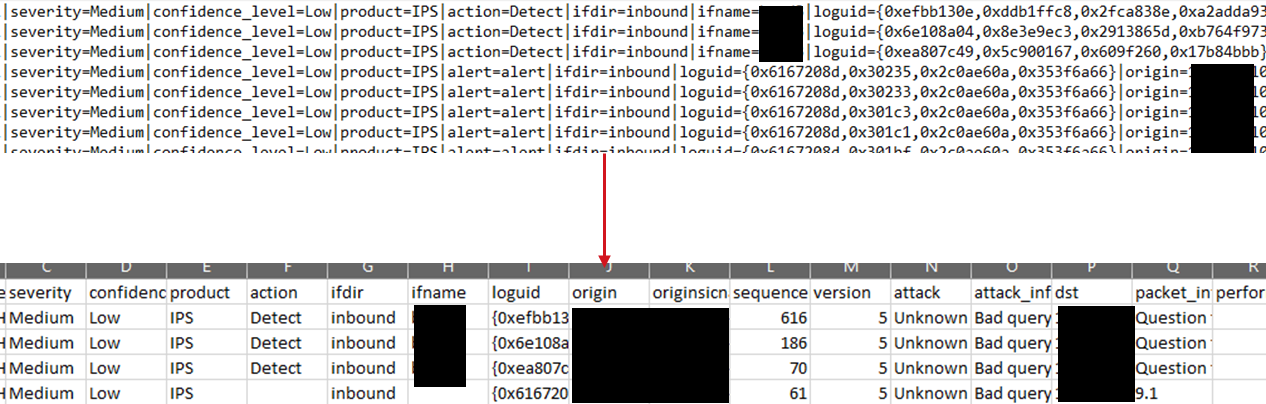
Parsing Syslog (Generic/RFC 3164/RFC 5424) to CSV
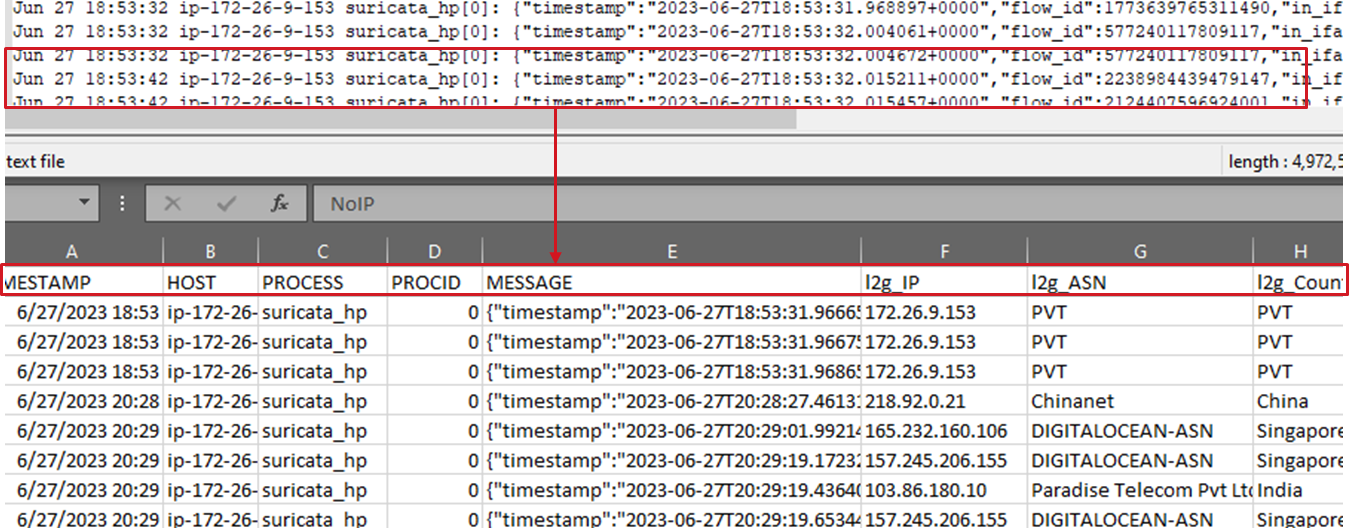
Transparently handling GZ files
### 主要功能
* 将结构化/半结构化/非结构化数据处理为丰富的 CSV
* CSV
* Internet Information Services (IIS)
* W3C Extended Format (W3C)
* Extended Log Format (ELF)
* Common Log Format / Combined Log Format (CLF)
* Common Event Format (CEF)
* 浅度或深度解析
* 每行 JSON 日志
* 浅度或深度解析
* 来自固定输入的多行 JSON Blob
* AWS CloudTrail 导出
* 通用 Syslog
* 键值 (key1=value1, key2="value 2") 样式日志
* 浅度或深度解析
* 原始文本文件
* 对所有解析器类型透明地读取纯文本文件或 GZ 归档
* “逐行”处理文件,避免将整个文件读入内存
* 将嵌入在 CSV 中的 JSON blob 展开为各个独立的列
* 在特定的日期时间范围内过滤输出
* 使用 MaxMind 地理位置信息丰富检测到的 IP / ASN 信息
* 使用 DNS 查找丰富检测到的 IP
* 使用可配置的威胁指标源丰富检测到的 IP
* 使用 WhoIs 数据丰富检测到的 IP
* 使用 Shodan InternetDB 数据丰富检测到的 IP
* 使用 WhoIs 数据丰富从 DNS 中检测到的域名
* 提取自定义指标文件
* 在每个目录的基础上合并输出
* 自定义并发设置以微调效率/吞吐量
* 默认情况下能够同时处理数千个文件
* 自动下载/更新 MaxMind 和已配置的威胁源
### 要求
要使用此工具,需要来自 MaxMind 的免费 API 密钥 - 注册账户后,可以在
生成个人许可证密钥。
为了更新 MaxMind MMDB,您必须通过以下 3 种方式之一向工具提供您的账户 ID 和 API 密钥:
* 通过命令行参数 `-api`
* 通过环境变量 `MM_API`
* 通过当前工作目录中名为 `mm_api.txt` 的文件
预期格式为“$ACCOUNTID:$APIKEY” - 例如,-api "222111:6ij3x2_GRChRSGRAWeHuFbu4W136UDGdrLeV_sse"
如果在当前工作目录中未找到最新的数据库,该工具将自动下载并解压缩每个数据库的最新版本。
可以通过 `-updategeo` 标志触发本地数据库的更新。
### 输出
对一个或多个输入文件运行 LogBoost 的最终输出是一个 CSV 文件,它表示原始数据流,但将包含额外 7 列,如下所示:
* lb_IP - 表示用于丰富任务的 IP 地址。
* lb_ASN - 表示与该 IP 地址关联的 ASN 组织的名称。
* lb_ASN_Number - 表示与该 IP 地址关联的 ASN 编号
* lb_Country - 表示与该 IP 地址关联的国家名称。
* lb_City - 表示与该 IP 地址关联的城市名称。
* lb_Domains (-dns) - 表示与该 IP 地址关联的任何域名,如果有多个,则用 '|' 分隔。
* lb_TLD (-dns) - 表示与该 IP 地址关联的顶级域名 - 仅当在指定的 MaxMind 数据库目录(默认为 CWD)中找到 'GeoIP2-Domain.mmdb' 时才会填充。
* lb_ThreatCategories (-useti) - 表示与该 IP 地址关联的威胁类别 - 将是一系列诸如 'tor'、'proxy' 等以 '|' 分隔的字符串,如果未在数据库中找到,则为 'none'。
* lb_ThreatFeedCount (-useti) - 表示该 IP 地址出现过的唯一威胁源的数量。
* lb_ThreatFeeds (-useti) - 表示该 IP 地址出现过的实际威胁源 - 以 '|' 分隔。
* lb_Domains - (-dns) - 表示该 IP 解析到的域名。
* lb_TLD - (-dns) - 表示该 IP 解析到的主机名/TLD(例如:aws.com)
* lb_DomainWhois_CreatedDate (-whois & -dns) - 表示 Whois 报告的域名创建日期
* lb_DomainWhois_UpdatedDate (-whois & -dns) - 表示 Whois 报告的域名更新日期
* lb_DomainWhois_Country (-whois & -dns) - 表示 Whois 报告的域名注册国家
* lb_DomainWhois_Organization (-whois & -dns) - 表示 Whois 报告的域名注册组织
* lb_IPWhois_CIDR (-whois) - 表示该 IP 地址所属的 CIDR 网络
* lb_IPWhois_NetName (-whois) - 表示该 IP 地址所属的网络名称
* lb_IPWhois_NetType (-whois) - 表示该 IP 地址所属的网络类型(如重新分配等)
* lb_IPWhois_Organization (-whois) - 表示该 IP 地址所属的组织名称
* lb_IPWhois_Created (-whois) - 表示根据 Whois 该 IP 的创建日期
* lb_IPWhois_Updated (-whois) - 表示根据 Whois 该 IP 的最新更新日期
* lb_IPWhois_Country (-whois) - 表示根据 Whois 该 IP 的注册国家
* lb_IPWhois_Parent (-whois) - 表示根据 Whois 该 IP 的父网络
* lb_IDB_cpes (-idb) - 表示该 IP 地址的任何已知 CPE
* lb_IDB_hostnames (-idb) - 表示该 IP 地址的任何已知主机名
* lb_IDB_ports (-idb) - 表示任何已知的开放端口
* lb_IDB_tags (-idb) - 表示任何额外的标签详细信息
* lb_IDB_vulns (-idb) - 表示任何已扫描/已知的漏洞
### 命令行参数
```
-dbdir [string] (default="") - Specify the directory containing MaxMind DBs at the dir or one level below - if they don't exist, will attempt to download.
-updategeo [bool] (default=false) - Update local MaxMind DBs (if they already exist)
-api [string] (default="") - Specify a MaxMind API accountid/ke in format "$ID:$KEY" - if not provided will subsequently check for ENVVAR 'MM_API' then mm_api.txt in CWD.
-logdir [string] (default="input") - specify the directory containing one or more files to process
-outputdir [string] (default="output") - specify the directory to store enriched logs - defaults to $CWD\output
-ipcol [string] (default="IP address") - specify the name of a column in the CSV files that stores IP addresses - defaults to 'IP address' to find Azure Signin Data column
-jsoncol [string] (default="AuditData") - specify the name of a column in the CSV files storing Azure Audit JSON blobs - defaults to 'AuditData'
-regex [bool] (default=false) - Scan each line for first IP address matche via regex rather than specifying a specific column name.
-convert [bool] (default=false) - Tells LogBoost to look for .log/.txt files in the specified log directory in addition to CSV then attempts to read them in one of a few ways
-rawtxt [bool] - Handle any identified .txt/.log file as raw text if parser is not identified - should be used with -convert.
-fullparse [bool] - Specify to perform 'deep' key detection on file formats with variable columns such as CSVs with JSON Blobs, CEF, JSON, etc - will increase processing time since we have to read the whole file twice basically.
-getall [bool] - Look for any file in input directory and process as raw text if a parser is not identified - similar to '-rawtxt -convert' but also gets files without extensions or files that do not have .txt/.log extension.
-separator [string] (default="=") - Used when -convert is specified to try and parse kv style logging. Example - if log is in format k1=v1,k2=v2 then the separator would be '='
-delimiter [string] (default=",") - Used when -convert is specified to try and parse kv style logging. Example - if log is in format k1=v1,k2=v2 then the delimiter would be ','
-passthrough [bool] (default=false) - If specified, will skip any enrichment tasks and just convert input to CSV.
-dns [bool] (default=false) - Tell LogBoost to perform reverse-lookups on detected IP addresses to find currently associated domains.
-maxgoperfile [int] (default=20) - Limit number of goroutines spawned per file for concurrent chunk processing
-batchsize [int] (default=500) - Limit how many lines per-file are sent to each spawned goroutine
-writebuffer [int] (default=2000) - How many lines to buffer in memory before writing to CSV
-concurrentfiles [int] (default=100) - Limit how many files are processed concurrently.
-whois [bool] (default=false) - Enrich IP address (and domain if using -dns) with live WhoIs lookups
-idb [bool] (default=false) - Enrich IP address with live Shodan InternetDB data
-combine [bool] (default=false) - Combine all files in each output directory into a single CSV per-directory - this will not work if the files do not share the same header sequence/number of columns.
-buildti [bool] (default=false) - Build the threat intelligence database based on feed_config.json
-updateti [bool] (default=false) - Update (and build if it doesn't exist) the threat intelligence database based on feed_config.json
-includedc [bool] (default=false) - When using -updateti, if this is also specified LogBoost will download and expand a lsit of known DataCenter IP addresses for use in enrichment.
-useti [bool] (default=false) - Use the threat intelligence database if it exists
-intelfile [string] - Specify the path to an intelligence file to ingest into the threat DB (must use with -inteltype and -intelname)
-inteltype [string] - Specify the type to appear when there is a match on custom-ingested ingelligence (must use with -intelfile and -intelname)
-intelname [string] - Specify the name to appear when there is a match on custom-ingested ingelligence (must use with -intelfile and -inteltype)
-summarizeti [bool] - Summarize the existing threat database
-startdate [string] - Start date of data to parse - defaults to year 1800. Can be used with or without enddate.
-enddate [string] - End date of data to parse - defaults to year 2300. Can be used with or without startdate.
-datecol [string] - Name of the column/header that contains the date to parse. Must be provided with startdate/enddate. Will check for either full equality or if the scanned column name contains the provided string - so be specific.
-dateformat [string] - Provide the format of the datecol data in golang style ("2006-01-02T15:04:05Z") - rearrange as appropriate (see example). Must be provided with startdate/enddate.
```
### 威胁情报说明
LogBoost 能够将可配置的基于文本的威胁指标源下载并归一化到单个 SQLite 数据库中,并根据其摄取的情报“类型”,在处理期间使用此数据库来丰富记录。
默认包含超过 90 个开源情报源 - 当使用 'buildti' 标志时,将首次初始化数据库 - 这仅需执行一次。随后,可以使用 'updateti' 标志下载最新的情报副本并将其提取到现有数据库中。这并非旨在成为一个 TIP,而是用于在日志中追踪可疑活动的快速参考。
使用 '-updateti' 时,如果同时使用了 '-includedc',则会将额外的数据中心 IP 地址列表添加到数据库中 - 这将消耗大约 7 GB 的磁盘空间并增加约 1.29 亿个 IP 地址。这通常是不必要的,因为 LogBoost 还包含了源自
的、对应于数据中心的 ASN 编号列表,用于确定任何特定 IP 地址是否属于数据中心。
在丰富过程中实际使用数据库时,请加入 'useti' 标志 - 这会有轻微的效率损耗,但通常可以忽略不计 - 如果只需要地理位置信息,则无需使用此功能。
使用 `-intelfile` 和 `-inteltype` 标志可以将自定义的基于文本的文件添加到底层数据库中。
**包含的指标源:**
### 功能待办 (TODO)
* 添加在同时处理各种日志类型时指定多个 IP 地址列名的功能。
* 通过重命名确保嵌入的 JSON 键与现有列名之间不会发生冲突。
* 可能会做:直接内联导出为 par 或其他数据结构而不是 CSV。
### 性能考量
LogBoost 能够处理大量数据,因为所有文件处理都在单独的 goroutine 中进行 - 这意味着如果将其指向包含 10,000 个文件的源目录,根据 `-concurrentfiles` 设置,可能会产生 10,000 个独立的 goroutine。此外,`maxgoperfile` 参数控制为每个单独文件处理批次而派生的子例程数量 - 因此,如果将其设置为 1,则在任何时候都会生成 1 万个 goroutine - 如果使用默认值 20,假设所有文件处理同时发生,将会产生多达 200,000 个 goroutine。
实际上,这在大多数现代机器上不应造成任何问题 - 一台具有 4 GB RAM 的机器能够轻松处理约 1,000,000 个 goroutine - 但现在我们必须考虑正在处理的文件 - 这正是 `batchsize` 变得重要的地方。我们必须选择一个既适合我们正在处理的数据,又适合我们正在运行的机器的 `batchsize` - 默认值通常是确保工作高效处理的良好起点,但如果性能不佳,应进行调整。
此外,`-concurrentfiles` 标志可用于限制同时处理的文件数量 - 默认为 100 - 连同 `-batchsize` 和 `-maxgoperfile`,用户可以微调与文件处理相关的各种并发设置,以确保性能和内存使用量适合当前的任务和系统。
除此之外 - 当行被发送到每个输出文件的主写入器时,它们会在写入文件之前被缓冲到一个切片中,以帮助提高吞吐量 - 每个输出文件一次缓冲的行数可以通过 `-writebuffer` 参数进行控制 - 默认为 1000。
### DNS 注意事项
LogBoost 能够根据输入数据生成大量的 DNS 查询 - 当开始执行时,会建立一个内存缓存来保存每个检测到的 IP 地址的 DNS 记录响应 - 这有助于减少对同一 IP 地址的冗余 DNS 请求,从而提高整体吞吐量。
尽管如此,请注意,在处理大量 IP 地址时,`-dns` 可能会对整体执行时间产生很大影响 - 减少整体 batch size 并增加 `maxgoperfile` 以将 DNS 请求分配到更多的 goroutine 中可能是有意义的。
此外 - DNS 请求可能会被上游服务器(例如 Google DNS)限流 - 在处理大量数据时,这可能是一个问题。
为了缓解此问题,DNS 结果会被缓存以供重用 - 执行完成后,缓存将保存到 `dns.cache` 目录中 - 在同一工作目录中进行任何后续执行时,将重用此缓存 - 这意味着如果缓存中存在某个 IP 地址,我们将不会再对其进行新的查询。如果您想执行“全新”查询,只需删除缓存目录,它将自动重建。
### 处理不同的日志类型
#### CSV
处理 CSV 输入非常简单:
1. 通过 `-logdir` 将 LogBoost 指向日志
2. 使用 `-ipcol` 告诉 LogBoost 哪一列包含 IP 地址,或者使用 `-regex` 让它扫描每行以查找第一个非私有 IP 地址
3. 就这些 - 如果需要,您可以使用诸如 `-dns`、`-useti` 或日期过滤标志等附加设置,但这对于标准 CSV 的基本处理已经足够了。
```
LogBoost.exe -logdir C:\csvfiles
```
如果我们正在处理包含时间分隔文件的目录,包含 `-combine` 以将相似的文件推送到每个输出目录中可能会很有用。
```
LogBoost.exe -logdir C:\csvfiles -combine
```
要展开内嵌的 JSON blob,请使用 `-jsoncol` 并提供列名 - 默认情况下,使用 'AuditData' 来帮助处理 Azure 审计导出。还要使用 `fullparse` 来启用此功能。
```
LogBoost.exe -logdir C:\csvwithjson -jsoncol "jsondata" -fullparse
```
#### IIS/W3C/ELF/CLF(Web 服务器样式日志)
1. 通过 `-logdir` 告诉 LogBoost 在哪里可以找到日志
2. 包含 `-convert` 标志以便我们查找 .csv 以外的文件
3. 核心来说 - 这就是所需的全部 - 如果您正在处理包含相似文件的目录,包含 `-combine` 来合并输出可能也会很有用。
4. 如果需要,也可以使用可选标志,如 -dns、-useti 和日期过滤。
```
LogBoost.exe -logdir C:\inetpub\logs -convert -combine
```
#### 通用事件格式 (CEF)
处理方式与上面类似 - 由于这些通常不是 CSV 文件,我们需要使用 `-convert` 标志来查找/解析它们。
LogBoost 目前能够检测/解析 4 种类型的 CEF 输入,下面提供了行示例:
* 带有 syslog RFC 3164 标头的 CEF
* <6>Sep 14 14:12:51 10.1.1.143 CEF:0|.....
* 带有 syslog RFC 5424 标头的 CEF
* <34>1 2003-10-11T22:14:15.003Z mymachine.example.com CEF:0|.....
* 带有通用 syslog 标头的 CEF
* Jun 27 18:19:37 ip-172-31-82-74 systemd[1]: CEF:0|.....
* 不带任何前缀/标头的 CEF
* CEF:0|.....
此外,LogBoost 能够解析给定文件中所有可能的 K=V 扩展,并将其用作列标题,实际上是将 CEF 扩展“展平”以便于筛选。这可以通过 `-fullparse` 标志来启用 - 这会增加处理时间,因为我们需要读取文件两次 - 一次用于收集所有可能的标题,另一次用于实际解析它。
#### JSON
LogBoost 能够对如下所示的每行 JSON 消息日志执行浅度或深度解析:
```
{"type":"liberty_accesslog","host":"79e8ad2347b3","ibm_userDir":"\/opt\/ibm\/wlp\/usr\/","ibm_serverName":"defaultServer","ibm_remoteHost":"172.27.0.10","ibm_requestProtocol":"HTTP\/1.1","ibm_userAgent":"Apache-CXF/3.3.3-SNAPSHOT","ibm_requestHeader_headername":"header_value","ibm_requestMethod":"GET","ibm_responseHeader_connection":"Close","ibm_requestPort":"9080","ibm_requestFirstLine":"GET \/favicon.ico HTTP\/1.1","ibm_responseCode":200,"ibm_requestStartTime":"2020-07-14T13:28:19.887-0400","ibm_remoteUserID":"user","ibm_uriPath":"\/favicon.ico","ibm_elapsedTime":834,"ibm_accessLogDatetime":"2020-07-14T13:28:19.887-0400","ibm_remoteIP":"172.27.0.9","ibm_requestHost":"172.27.0.9","ibm_bytesSent":15086,"ibm_bytesReceived":15086,"ibm_cookie_cookiename":"cookie_value","ibm_requestElapsedTime":3034,"ibm_datetime":"2020-07-14T13:28:19.887-0400","ibm_sequence":"1594747699884_0000000000001"}
{"type":"liberty_accesslog","host":"79e8ad2347b3","ibm_userDir":"\/opt\/ibm\/wlp\/usr\/","ibm_serverName":"defaultServer","ibm_remoteHost":"172.27.0.10","ibm_requestProtocol":"HTTP\/1.1","ibm_userAgent":"Apache-CXF/3.3.3-SNAPSHOT","ibm_requestHeader_headername":"header_value","ibm_requestMethod":"GET","ibm_responseHeader_connection":"Close","ibm_requestPort":"9080","ibm_requestFirstLine":"GET \/favicon.ico HTTP\/1.1","ibm_responseCode":200,"ibm_requestStartTime":"2020-07-14T13:28:19.887-0400","ibm_remoteUserID":"user","ibm_uriPath":"\/favicon.ico","ibm_elapsedTime":834,"ibm_accessLogDatetime":"2020-07-14T13:28:19.887-0400","ibm_remoteIP":"172.27.0.9","ibm_requestHost":"172.27.0.9","ibm_bytesSent":15086,"ibm_bytesReceived":15086,"ibm_cookie_cookiename":"cookie_value","ibm_requestElapsedTime":3034,"ibm_datetime":"2020-07-14T13:28:19.887-0400","ibm_sequence":"1594747699884_0000000000001"}
```
“浅度”解析是指从文件中读取一行,并仅使用该行中存在的键作为列 - 在解析时,任何额外的键将作为原始字符串存储在名为 'EXTRA_KEYS' 的列中。
```
LogBoost.exe -logdir C:\jsonlogs -convert
```
“深度”解析文件意味着先读取整个文件以收集所有可能的键,然后再次读取以根据检测到的键实际解析并赋值。要启用此功能,请添加 -fullparse,如下所示:
```
LogBoost.exe -logdir C:\jsonlogs -convert -fullparse
```
#### KV 消息
LogBoost(在大多数情况下)能够处理标准的 KV 样式日志格式 - 默认分隔符是 '=',默认的 kv 分隔符是 ',' - 例如,要解析包含以下行的文件:
```
timestamp="Jun 12 2023 00:00:00.000", source=host1, message="test message", ip=1.1.1.1
timestamp="Jun 12 2023 00:00:00.000", source=host1, message="test message", ip=1.1.1.1
```
只需使用以下命令行:
```
LogBoost.exe -logdir C:\kvlogs -convert
```
由于此文件使用标准的分隔符,因此不需要任何特殊操作。如果文件看起来像这样:
```
timestamp:"Jun 12 2023 00:00:00.000"| source:host1| message:"test message"| ip:1.1.1.1
timestamp:"Jun 12 2023 00:00:00.000"| source:host1| message:"test message"| ip:1.1.1.1
```
然后按如下所示更改您的命令:
```
LogBoost.exe -logdir C:\kvlogs -convert -separator "|" -delimiter ":"
```
#### 通用 Syslog
这里不需要任何特殊操作 - 与 IIS/CEF 等类似,只需指定您的日志目录并使用 `-convert` - 但由于 syslog 等类似文件通常没有扩展名,请确保同时使用 `-getall` - 此标志使 LogBoost 尝试处理日志目录中的任何类型的文件,而不仅仅是 .csv、.txt 或 .log。
默认情况下,LogBoost 可以解析通用 syslog、RFC5424 和 RFC3164,下面提供了每种格式的示例。
* 通用
* Jun 27 18:19:37 ip-172-31-82-74 systemd[1]: MESSAGE
* Jun 27 18:17:39 ip-172-31-82-74 sudo: MESSAGE
* RFC 5424
* <34>1 2003-10-11T22:14:15.003Z mymachine.example.com MESSAGE
* RFC 3164
* <6>Sep 14 14:12:51 10.1.1.143 MESSAGE
#### 任何其他基于文本的文件
虽然 LogBoost 可能没有针对每种类型的日志或文件类型的解析器 - 但它仍然可以通过使用正则表达式在文件每一行中查找第一个非私有 IP 地址并进行适当的丰富,从而帮助分析人员快速丰富任何文件类型。
```
LogBoost.exe -logdir C:\somelogs -convert -rawtxt
```
输入文件的每一行都将全部包含在生成的 CSV 的第一列中,并添加额外的列用于 LogBoost 的信息丰富。
要分析目录中所有扩展名不受限制的文件,请使用 `-getall` - 如果没有此参数,`-convert` 默认只会处理 .txt/.log 文件。
#### 参考资料
本节列出了在构建此实用工具时依赖或发现有用的任何页面、文章、包或其他内容。
*
*
*
*
*
*