fishaudio/fish-speech
GitHub: fishaudio/fish-speech
开源 SOTA 级多语言文本转语音系统,支持零样本声音克隆、自然语言情感控制和多说话人生成。
Stars: 30829 | Forks: 2635
Fish Speech
**English** | [简体中文](docs/README.zh.md) | [Portuguese](docs/README.pt-BR.md) | [日本語](docs/README.ja.md) | [한국어](docs/README.ko.md) | [العربية](docs/README.ar.md)

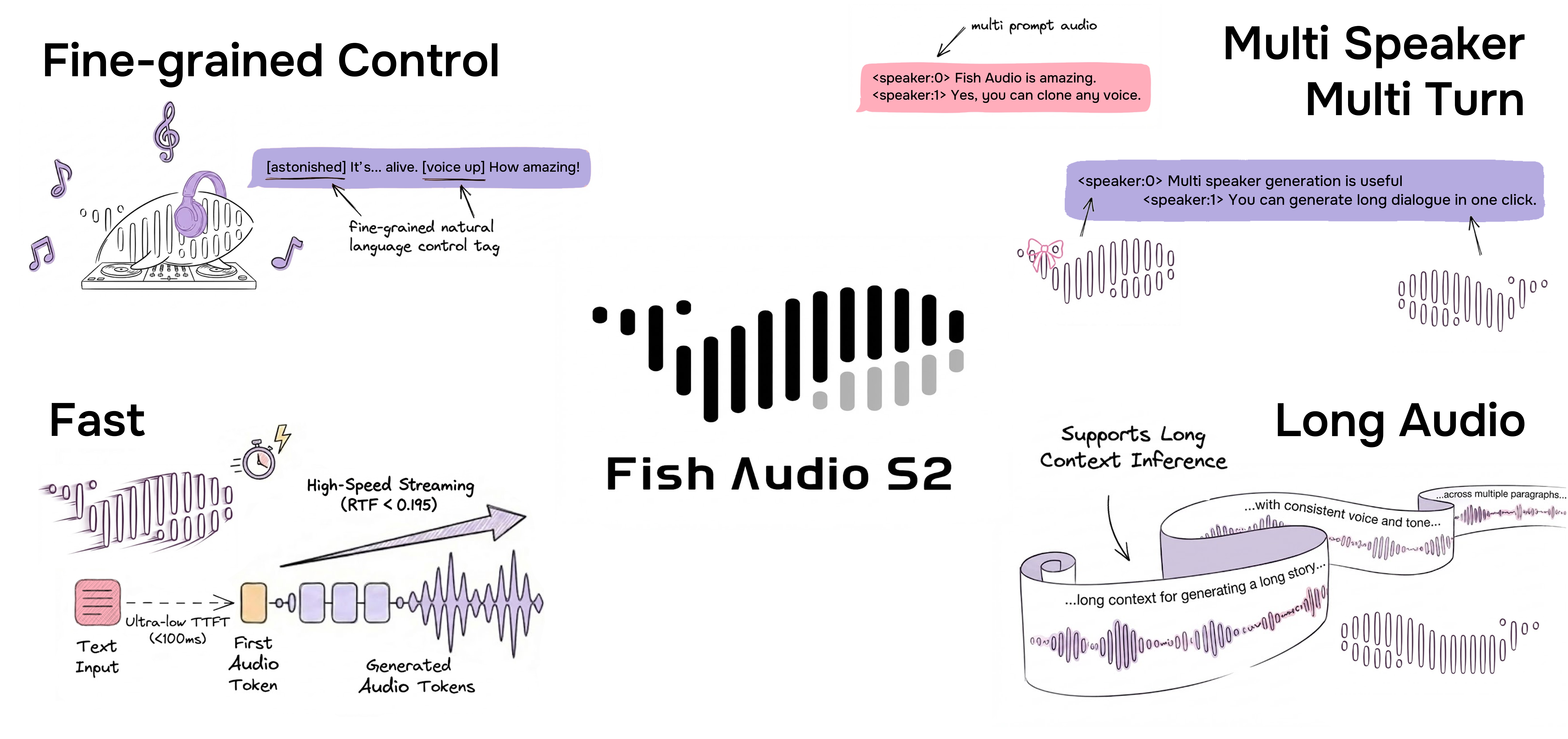 ### 通过自然语言进行细粒度内联控制
S2 允许通过在文本中的特定单词 or 短语位置直接嵌入自然语言指令,来对语音生成进行局部控制。S2 不依赖固定的预定义标签集,而是接受自由形式的文本描述 —— 例如 `[whisper in small voice]`、`[professional broadcast tone]` 或 `[pitch up]` —— 从而实现词汇级别的开放式表达控制。
### Dual-Autoregressive 架构
S2 基于 decoder-only transformer 构建,并结合了基于 RVQ 的音频编解码器(10 个 codebook,约 21 Hz 帧率)。Dual-AR 架构将生成过程分为两个阶段:
- **慢速 AR (Slow AR)** 沿时间轴运行,预测主语义 codebook。
- **快速 AR (Fast AR)** 在每个时间步生成剩余的 9 个残差 codebook,重建细粒度的声学细节。
这种非对称设计 —— 时间轴方向 4B 参数,深度轴方向 400M 参数 —— 在保持推理高效的同时保留了音频保真度。
### 强化学习对齐
S2 使用 Group Relative Policy Optimization (GRPO) 进行训练后对齐。用于过滤和标注训练数据的相同模型在 RL 期间被直接复用为奖励模型 —— 消除了预训练数据与训练后目标之间的分布不匹配。奖励信号结合了语义准确性、指令遵循度、声学偏好评分和音色相似度。
### 通过 SGLang 实现生产级流式传输
由于 Dual-AR 架构在结构上与标准自回归 LLM 同构,S2 直接继承了 SGLang 的所有 LLM 原生服务优化 —— 包括连续批处理、分页 KV 缓存、CUDA graph 重放以及基于 RadixAttention 的前缀缓存。
在单张 NVIDIA H200 GPU 上:
- **实时率 (RTF):** 0.195
- **首音频延迟:** ~100 ms
- **吞吐量:** 3,000+ 声学 tokens/s,同时保持 RTF 低于 0.5
### 多语言支持
S2 支持高质量的多语言文本转语音,无需音素或特定语言的预处理。包括:
**英语、中文、日语、韩语、阿拉伯语、德语、法语……**
**以及更多!**
支持列表正在不断扩展,请查看 [Fish Audio](https://fish.audio/) 获取最新发布信息。
### 原生多说话人生成
### 通过自然语言进行细粒度内联控制
S2 允许通过在文本中的特定单词 or 短语位置直接嵌入自然语言指令,来对语音生成进行局部控制。S2 不依赖固定的预定义标签集,而是接受自由形式的文本描述 —— 例如 `[whisper in small voice]`、`[professional broadcast tone]` 或 `[pitch up]` —— 从而实现词汇级别的开放式表达控制。
### Dual-Autoregressive 架构
S2 基于 decoder-only transformer 构建,并结合了基于 RVQ 的音频编解码器(10 个 codebook,约 21 Hz 帧率)。Dual-AR 架构将生成过程分为两个阶段:
- **慢速 AR (Slow AR)** 沿时间轴运行,预测主语义 codebook。
- **快速 AR (Fast AR)** 在每个时间步生成剩余的 9 个残差 codebook,重建细粒度的声学细节。
这种非对称设计 —— 时间轴方向 4B 参数,深度轴方向 400M 参数 —— 在保持推理高效的同时保留了音频保真度。
### 强化学习对齐
S2 使用 Group Relative Policy Optimization (GRPO) 进行训练后对齐。用于过滤和标注训练数据的相同模型在 RL 期间被直接复用为奖励模型 —— 消除了预训练数据与训练后目标之间的分布不匹配。奖励信号结合了语义准确性、指令遵循度、声学偏好评分和音色相似度。
### 通过 SGLang 实现生产级流式传输
由于 Dual-AR 架构在结构上与标准自回归 LLM 同构,S2 直接继承了 SGLang 的所有 LLM 原生服务优化 —— 包括连续批处理、分页 KV 缓存、CUDA graph 重放以及基于 RadixAttention 的前缀缓存。
在单张 NVIDIA H200 GPU 上:
- **实时率 (RTF):** 0.195
- **首音频延迟:** ~100 ms
- **吞吐量:** 3,000+ 声学 tokens/s,同时保持 RTF 低于 0.5
### 多语言支持
S2 支持高质量的多语言文本转语音,无需音素或特定语言的预处理。包括:
**英语、中文、日语、韩语、阿拉伯语、德语、法语……**
**以及更多!**
支持列表正在不断扩展,请查看 [Fish Audio](https://fish.audio/) 获取最新发布信息。
### 原生多说话人生成
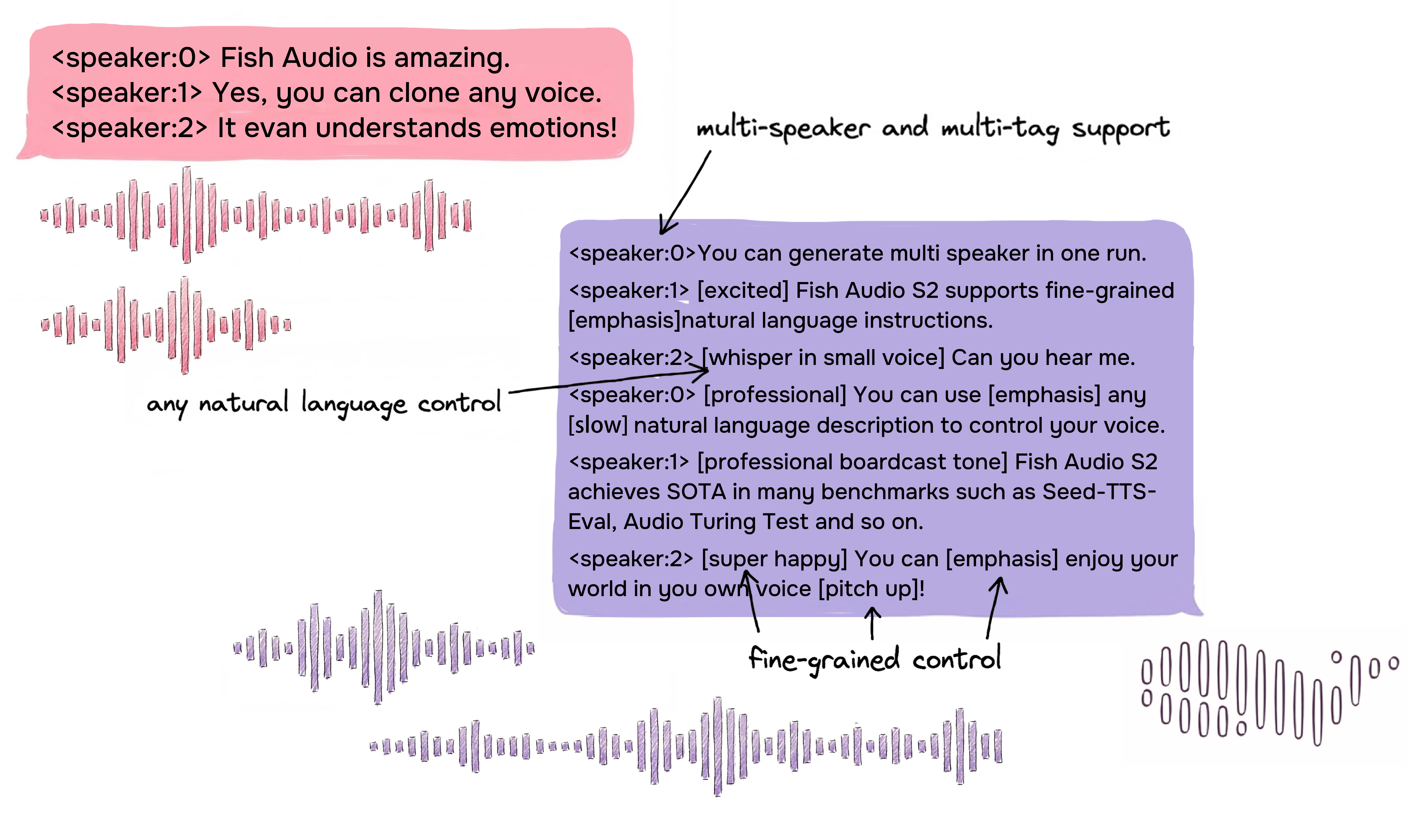 Fish Audio S2 允许用户上传包含多说话人的参考音频,模型将通过 `<|speaker:i|>` token 处理每个说话人的特征。然后你可以使用说话人 ID token 控制模型的表现,从而允许单次生成包含多个说话人。你不再需要为每个说话人单独上传参考音频。
### 多轮生成
得益于模型上下文的扩展,我们的模型现在可以利用先前的信息来提高后续生成内容的表达能力,从而增加内容的自然度。
### 快速声音克隆
Fish Audio S2 支持使用短参考样本(通常为 10-30 秒)进行精准的声音克隆。该模型能够捕捉音色、说话风格和情感倾向,生成逼真且一致的克隆声音,无需额外的微调。
请参考 [SGLang-Omni README](https://github.com/sgl-project/sglang-omni/blob/main/sglang_omni/models/fishaudio_s2_pro/README.md) 以使用 SGLang 服务器。
## 鸣谢
- [VITS2 (daniilrobnikov)](https://github.com/daniilrobnikov/vits2)
- [Bert-VITS2](https://github.com/fishaudio/Bert-VITS2)
- [GPT VITS](https://github.com/innnky/gpt-vits)
- [MQTTS](https://github.com/b04901014/MQTTS)
- [GPT Fast](https://github.com/pytorch-labs/gpt-fast)
- [GPT-SoVITS](https://github.com/RVC-Boss/GPT-SoVITS)
- [Qwen3](https://github.com/QwenLM/Qwen3)
## 技术报告
```
@misc{fish-speech-v1.4,
title={Fish-Speech: Leveraging Large Language Models for Advanced Multilingual Text-to-Speech Synthesis},
author={Shijia Liao and Yuxuan Wang and Tianyu Li and Yifan Cheng and Ruoyi Zhang and Rongzhi Zhou and Yijin Xing},
year={2024},
eprint={2411.01156},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2411.01156},
}
@misc{liao2026fishaudios2technical,
title={Fish Audio S2 Technical Report},
author={Shijia Liao and Yuxuan Wang and Songting Liu and Yifan Cheng and Ruoyi Zhang and Tianyu Li and Shidong Li and Yisheng Zheng and Xingwei Liu and Qingzheng Wang and Zhizhuo Zhou and Jiahua Liu and Xin Chen and Dawei Han},
year={2026},
eprint={2603.08823},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2603.08823},
}
```
Fish Audio S2 允许用户上传包含多说话人的参考音频,模型将通过 `<|speaker:i|>` token 处理每个说话人的特征。然后你可以使用说话人 ID token 控制模型的表现,从而允许单次生成包含多个说话人。你不再需要为每个说话人单独上传参考音频。
### 多轮生成
得益于模型上下文的扩展,我们的模型现在可以利用先前的信息来提高后续生成内容的表达能力,从而增加内容的自然度。
### 快速声音克隆
Fish Audio S2 支持使用短参考样本(通常为 10-30 秒)进行精准的声音克隆。该模型能够捕捉音色、说话风格和情感倾向,生成逼真且一致的克隆声音,无需额外的微调。
请参考 [SGLang-Omni README](https://github.com/sgl-project/sglang-omni/blob/main/sglang_omni/models/fishaudio_s2_pro/README.md) 以使用 SGLang 服务器。
## 鸣谢
- [VITS2 (daniilrobnikov)](https://github.com/daniilrobnikov/vits2)
- [Bert-VITS2](https://github.com/fishaudio/Bert-VITS2)
- [GPT VITS](https://github.com/innnky/gpt-vits)
- [MQTTS](https://github.com/b04901014/MQTTS)
- [GPT Fast](https://github.com/pytorch-labs/gpt-fast)
- [GPT-SoVITS](https://github.com/RVC-Boss/GPT-SoVITS)
- [Qwen3](https://github.com/QwenLM/Qwen3)
## 技术报告
```
@misc{fish-speech-v1.4,
title={Fish-Speech: Leveraging Large Language Models for Advanced Multilingual Text-to-Speech Synthesis},
author={Shijia Liao and Yuxuan Wang and Tianyu Li and Yifan Cheng and Ruoyi Zhang and Rongzhi Zhou and Yijin Xing},
year={2024},
eprint={2411.01156},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2411.01156},
}
@misc{liao2026fishaudios2technical,
title={Fish Audio S2 Technical Report},
author={Shijia Liao and Yuxuan Wang and Songting Liu and Yifan Cheng and Ruoyi Zhang and Tianyu Li and Shidong Li and Yisheng Zheng and Xingwei Liu and Qingzheng Wang and Zhizhuo Zhou and Jiahua Liu and Xin Chen and Dawei Han},
year={2026},
eprint={2603.08823},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2603.08823},
}
```
标签:AIGC, DLL 劫持, Docker, Fish Audio, Fish Speech, Hugging Face, SOTA, Transformer, TTS, Vectored Exception Handling, 人工智能, 人机交互, 凭据扫描, 声码器, 声音克隆, 多语言支持, 大语言模型, 安全测试框架, 安全防御评估, 开源模型, 数字人, 文本转语音, 深度学习, 用户模式Hook绕过, 神经网路, 自动语音识别, 语音合成, 语音技术, 语音生成, 请求拦截, 逆向工具