EvoTestOps/LogLead
GitHub: EvoTestOps/LogLead
一个面向日志的基准测试与异常检测框架,解决日志表示与检测算法的高效集成与评估问题。
Stars: 30 | Forks: 3
# LogLead
LogLead 旨在高效地对日志异常检测算法和日志表示进行基准测试。LogLead 也被用作 [LogDelta](https://github.com/EvoTestOps/LogDelta) 和 [VisualLogAnalyzer](https://github.com/EvoTestOps/VisualLogAnalyzer) 等项目的后端,这些项目提供了更友好的日志分析和日志异常检测方法。
 目前,它包含近 1,000 种独特的异常检测组合,涵盖 8 个公共数据集、11 种日志表示(增强器)和 11 个分类器。这些资源使您能够将自身的数据、日志表示或分类器与多种场景进行基准测试。如果您认为某些内容应该被包含,请在 [问题跟踪器](https://github.com/EvoTestOps/LogLead/issues) 中提交数据集、增强器或分类器的请求。
LogLead 的一个关键优势是其自定义加载系统,能够高效地隔离来自不同系统的日志的独特方面。这种设计减少了冗余代码,因为一旦加载日志,相同的增强和异常检测代码可以普遍应用。
## 安装 LogLead
使用 `pip` 安装:
```
python -m pip install loglead
```
然后克隆项目,进入演示文件夹并运行一些演示
```
git clone https://github.com/EvoTestOps/LogLead.git
cd LogLead/demo
python HDFS_samples.py
python TB_samples.py
```
要开始使用自己的数据,最简单的方法是从 [RawLoader](https://github.com/EvoTestOps/LogLead/blob/main/loglead/loaders/raw.py) 开始。要尝试 RawLoader,请运行 [RawLoaderDemo](https://github.com/EvoTestOps/LogLead/blob/main/demo/RawLoader_NoLabels.py)。为此,您需要原始的 [BGL](https://zenodo.org/records/8196385/files/BGL.zip?download=1) 和 [HDFS](https://zenodo.org/records/8196385/files/HDFS_v1.zip?download=1) 数据集。您还需要编辑 [RawLoaderDemo 脚本](https://github.com/EvoTestOps/LogLead/blob/main/demo/RawLoader_NoLabels.py) 或在 LogLead 根目录下添加一个 ".env" 文件,以便演示知道数据在计算机上的位置。请参考 [.env.sample](https://github.com/EvoTestOps/LogLead/blob/main/.env.sample) 了解 ".env" 文件应如何设置。之后运行演示
```
python RawLoader_NoLabels.py
```
最后,您可以使用 [DownLoadData](https://github.com/EvoTestOps/LogLead/blob/main/tests/download_data.py) 下载所有数据。[配置文件](https://github.com/EvoTestOps/LogLead/blob/main/tests/datasets.yml) 控制加载哪些内容,以及在运行测试时如何使用它们。
```
cd LogLead/tests
python download_data.py
```
### 已知问题
- 如果 `scikit-learn` 的 wheel 编译失败,请检查是否安装了 `gcc` 和 `g++`。
- pip 版本没有 `BertEmbeddings` 所需的 `tensorflow` 依赖项。
请手动安装它们(最好在 conda 环境中)。
## 演示
在以下演示中,您会注意到 LogLead 设计效率的一个显著方面:代码可重用性。两个演示虽然分析不同的数据集,但共享了大量底层代码。这不仅展示了 LogLead 在处理各种日志格式方面的灵活性,还展示了其通过可重用代码组件简化分析过程的能力。
### Thunderbird 超级计算机日志演示
- **脚本**: [TB_samples.py](https://github.com/EvoTestOps/LogLead/blob/main/demo/TB_samples.py)
- **描述**: 此演示展示了一个 Thunderbird 超级计算机日志,按行(事件)级别标记。标记为“-”的第一列表示正常行为,其他标记表示异常。
- **日志快照**: 在[此处](https://github.com/logpai/loghub/blob/master/Thunderbird/Thunderbird_2k.log_structured.csv)查看日志。
- **数据集**: 演示包含一个 parquet 文件,其中包含 263,408 个日志事件的子集,其中有 21,955 个异常。
- **屏幕录制**: 如需了解演示概览,请在 YouTube 上观看我们的[5 分钟屏幕录制](https://www.youtube.com/watch?v=8stdbtTfJVo)。
### Hadoop 分布式文件系统(HDFS)日志演示
- **脚本**: [HDFS_samples.py](https://github.com/EvoTestOps/LogLead/blob/main/demo/HDFS_samples.py)
- **描述**: 此演示展示来自 Hadoop 分布式文件系统(HDFS)的日志,按序列级别标记(序列是多个日志事件的集合)。
- **日志快照**: 在[此处](https://github.com/logpai/loghub/blob/master/HDFS/HDFS_2k.log_structured.csv)查看日志。
- **异常标签**: 在单独的文件中提供。
- **数据集**: 演示包含一个 parquet 文件,其中包含 222,579 个日志事件的子集,形成 11,501 个序列,其中包含 350 个异常。
## 测试
通常,我们的测试流程包括运行以下操作。演示可以快速发现明显错误,而完整测试集需要更长的时间运行——最多 30 分钟。
基本演示
```
cd demo
python HDFS_samples.py
python TB_samples.py
```
解析器基准测试
```
cd demo/parser_benchmark
python ano_detection.py
python parsing_speed.py
```
运行完整测试
```
cd tests
python main.py
```
## 异常检测结果示例
下面您可以看到在 HDFS 数据的 0.5% 子集上训练的异常检测结果(F1-Binary)。
我们使用了 5 种不同的日志消息增强策略:[Words](https://en.wikipedia.org/wiki/Bag-of-words_model)、[Drain](https://github.com/logpai/Drain3)、[LenMa](https://github.com/keiichishima/templateminer)、[Spell](https://github.com/logpai/logparser/tree/main/logparser/Spell) 和 [BERT](https://github.com/google-research/bert)
增强策略与 5 种不同的机器学习算法进行测试:DT(决策树)、SVM(支持向量机)、LR(逻辑回归)、RF(随机森林)和 XGB(极端梯度提升)。
| | Words | Drain | Lenma | Spell | Bert | Average |
|---------|--------|--------|--------|--------|--------|---------|
| DT | 0.9719 | 0.9816 | 0.9803 | 0.9828 | 0.9301 | 0.9693 |
| SVM | 0.9568 | 0.9591 | 0.9605 | 0.9559 | 0.8569 | 0.9378 |
| LR | 0.9476 | 0.8879 | 0.8900 | 0.9233 | 0.5841 | 0.8466 |
| RF | 0.9717 | 0.9749 | 0.9668 | 0.9809 | 0.9382 | 0.9665 |
| XGB | 0.9721 | 0.9482 | 0.9492 | 0.9535 | 0.9408 | 0.9528 |
|---------|--------|--------|--------|--------|--------|---------|
| Average | 0.9640 | 0.9503 | 0.9494 | 0.9593 | 0.8500 | |
## 功能概述
LogLead 由独立的模块组成:加载器、增强器和异常检测器。我们使用 [Polars](https://www.pola.rs/) 数据帧,因为它比 Pandas 明显更快。
目前,它包含近 1,000 种独特的异常检测组合,涵盖 8 个公共数据集、11 种日志表示(增强器)和 11 个分类器。这些资源使您能够将自身的数据、日志表示或分类器与多种场景进行基准测试。如果您认为某些内容应该被包含,请在 [问题跟踪器](https://github.com/EvoTestOps/LogLead/issues) 中提交数据集、增强器或分类器的请求。
LogLead 的一个关键优势是其自定义加载系统,能够高效地隔离来自不同系统的日志的独特方面。这种设计减少了冗余代码,因为一旦加载日志,相同的增强和异常检测代码可以普遍应用。
## 安装 LogLead
使用 `pip` 安装:
```
python -m pip install loglead
```
然后克隆项目,进入演示文件夹并运行一些演示
```
git clone https://github.com/EvoTestOps/LogLead.git
cd LogLead/demo
python HDFS_samples.py
python TB_samples.py
```
要开始使用自己的数据,最简单的方法是从 [RawLoader](https://github.com/EvoTestOps/LogLead/blob/main/loglead/loaders/raw.py) 开始。要尝试 RawLoader,请运行 [RawLoaderDemo](https://github.com/EvoTestOps/LogLead/blob/main/demo/RawLoader_NoLabels.py)。为此,您需要原始的 [BGL](https://zenodo.org/records/8196385/files/BGL.zip?download=1) 和 [HDFS](https://zenodo.org/records/8196385/files/HDFS_v1.zip?download=1) 数据集。您还需要编辑 [RawLoaderDemo 脚本](https://github.com/EvoTestOps/LogLead/blob/main/demo/RawLoader_NoLabels.py) 或在 LogLead 根目录下添加一个 ".env" 文件,以便演示知道数据在计算机上的位置。请参考 [.env.sample](https://github.com/EvoTestOps/LogLead/blob/main/.env.sample) 了解 ".env" 文件应如何设置。之后运行演示
```
python RawLoader_NoLabels.py
```
最后,您可以使用 [DownLoadData](https://github.com/EvoTestOps/LogLead/blob/main/tests/download_data.py) 下载所有数据。[配置文件](https://github.com/EvoTestOps/LogLead/blob/main/tests/datasets.yml) 控制加载哪些内容,以及在运行测试时如何使用它们。
```
cd LogLead/tests
python download_data.py
```
### 已知问题
- 如果 `scikit-learn` 的 wheel 编译失败,请检查是否安装了 `gcc` 和 `g++`。
- pip 版本没有 `BertEmbeddings` 所需的 `tensorflow` 依赖项。
请手动安装它们(最好在 conda 环境中)。
## 演示
在以下演示中,您会注意到 LogLead 设计效率的一个显著方面:代码可重用性。两个演示虽然分析不同的数据集,但共享了大量底层代码。这不仅展示了 LogLead 在处理各种日志格式方面的灵活性,还展示了其通过可重用代码组件简化分析过程的能力。
### Thunderbird 超级计算机日志演示
- **脚本**: [TB_samples.py](https://github.com/EvoTestOps/LogLead/blob/main/demo/TB_samples.py)
- **描述**: 此演示展示了一个 Thunderbird 超级计算机日志,按行(事件)级别标记。标记为“-”的第一列表示正常行为,其他标记表示异常。
- **日志快照**: 在[此处](https://github.com/logpai/loghub/blob/master/Thunderbird/Thunderbird_2k.log_structured.csv)查看日志。
- **数据集**: 演示包含一个 parquet 文件,其中包含 263,408 个日志事件的子集,其中有 21,955 个异常。
- **屏幕录制**: 如需了解演示概览,请在 YouTube 上观看我们的[5 分钟屏幕录制](https://www.youtube.com/watch?v=8stdbtTfJVo)。
### Hadoop 分布式文件系统(HDFS)日志演示
- **脚本**: [HDFS_samples.py](https://github.com/EvoTestOps/LogLead/blob/main/demo/HDFS_samples.py)
- **描述**: 此演示展示来自 Hadoop 分布式文件系统(HDFS)的日志,按序列级别标记(序列是多个日志事件的集合)。
- **日志快照**: 在[此处](https://github.com/logpai/loghub/blob/master/HDFS/HDFS_2k.log_structured.csv)查看日志。
- **异常标签**: 在单独的文件中提供。
- **数据集**: 演示包含一个 parquet 文件,其中包含 222,579 个日志事件的子集,形成 11,501 个序列,其中包含 350 个异常。
## 测试
通常,我们的测试流程包括运行以下操作。演示可以快速发现明显错误,而完整测试集需要更长的时间运行——最多 30 分钟。
基本演示
```
cd demo
python HDFS_samples.py
python TB_samples.py
```
解析器基准测试
```
cd demo/parser_benchmark
python ano_detection.py
python parsing_speed.py
```
运行完整测试
```
cd tests
python main.py
```
## 异常检测结果示例
下面您可以看到在 HDFS 数据的 0.5% 子集上训练的异常检测结果(F1-Binary)。
我们使用了 5 种不同的日志消息增强策略:[Words](https://en.wikipedia.org/wiki/Bag-of-words_model)、[Drain](https://github.com/logpai/Drain3)、[LenMa](https://github.com/keiichishima/templateminer)、[Spell](https://github.com/logpai/logparser/tree/main/logparser/Spell) 和 [BERT](https://github.com/google-research/bert)
增强策略与 5 种不同的机器学习算法进行测试:DT(决策树)、SVM(支持向量机)、LR(逻辑回归)、RF(随机森林)和 XGB(极端梯度提升)。
| | Words | Drain | Lenma | Spell | Bert | Average |
|---------|--------|--------|--------|--------|--------|---------|
| DT | 0.9719 | 0.9816 | 0.9803 | 0.9828 | 0.9301 | 0.9693 |
| SVM | 0.9568 | 0.9591 | 0.9605 | 0.9559 | 0.8569 | 0.9378 |
| LR | 0.9476 | 0.8879 | 0.8900 | 0.9233 | 0.5841 | 0.8466 |
| RF | 0.9717 | 0.9749 | 0.9668 | 0.9809 | 0.9382 | 0.9665 |
| XGB | 0.9721 | 0.9482 | 0.9492 | 0.9535 | 0.9408 | 0.9528 |
|---------|--------|--------|--------|--------|--------|---------|
| Average | 0.9640 | 0.9503 | 0.9494 | 0.9593 | 0.8500 | |
## 功能概述
LogLead 由独立的模块组成:加载器、增强器和异常检测器。我们使用 [Polars](https://www.pola.rs/) 数据帧,因为它比 Pandas 明显更快。
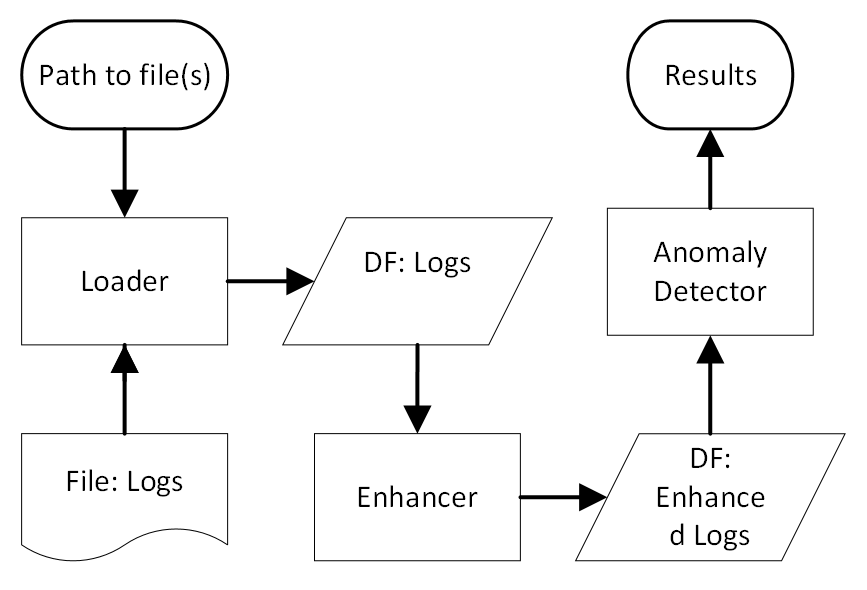 **加载器**: 此模块读取日志文件并处理每个日志文件的特定特性。它生成一个包含某些半强制字段的数据帧。这些字段使后续阶段的操作成为可能。LogLead 有一个 [RawLoader](https://github.com/EvoTestOps/LogLead/blob/main/loglead/loaders/raw.py),可以加载任何日志文件。它还具有以下公共数据集的自定义加载器,来自 10 个不同系统。定制加载器应能提高异常检测的准确性:
* 3: [HDFS_v1](https://github.com/logpai/loghub/tree/master/HDFS#hdfs_v1), [Hadoop](https://github.com/logpai/loghub/tree/master/Hadoop), [BGL](https://github.com/logpai/loghub/tree/master/BGL),感谢出色的 [LogHub 团队](https://github.com/logpai/loghub)。完整数据请参见 [Zenodo](https://zenodo.org/records/3227177)。
* 3: [Sprit](https://www.usenix.org/cfdr-data#hpc4)、[Thunderbird](https://www.usenix.org/cfdr-data#hpc4) 和 [Liberty](https://www.usenix.org/cfdr-data#hpc4) 可在 Usenix 网站上找到。
* 2: [Nezha](https://github.com/IntelligentDDS/Nezha) 包含来自两个系统的数据:[TrainTicket](https://github.com/FudanSELab/train-ticket) 和 [Google Cloud Webshop demo](https://github.com/GoogleCloudPlatform/microservices-demo)。这是第一个基于微服务系统的数据集。它除了日志数据外,还包含跟踪和指标。
* 2: [ADFA](https://github.com/verazuo/a-labelled-version-of-the-ADFA-LD-dataset) 和 [AWSCTD](https://github.com/DjPasco/AWSCTD) 是两个为入侵检测设计的数据集。
**增强器**: 此模块从日志中提取额外数据。增强过程直接在数据帧中进行,其中新增列作为增强过程的结果。例如,日志解析、创建日志消息的标记、测量日志序列长度都被视为日志增强。增强可以在事件级别进行,也可以在序列级别进行聚合。可用的增强器包括:事件长度(字符、、行)、序列长度、序列 [持续时间](https://pola-rs.github.io/polars/py-polars/html/reference/api/polars.Duration.html)、遵循“NLP”增强器:[Regex](https://crates.io/crates/regex)、[Words](https://en.wikipedia.org/wiki/Bag-of-words_model)、[Character n-grams](https://en.wikipedia.org/wiki/N-gram)。日志解析器:[Drain](https://github.com/logpai/Drain3)、[LenMa](https://github.com/keiichishima/templateminer)、[Spell](https://github.com/bave/pyspell)、[IPLoM](https://github.com/EvoTestOps/LogLead/tree/main/parsers/iplom)、[AEL](https://github.com/EvoTestOps/LogLead/tree/main/parsers/AEL)、[Brain](https://github.com/EvoTestOps/LogLead/tree/main/parsers/Brain)、[Fast-IPLoM](https://github.com/EvoTestOps/LogLead/tree/main/parsers/fast_iplom)、[Tipping](https://pypi.org/project/tipping/) 和 [BERT](https://github.com/google-research/bert)。[NextEventPrediction](https://arxiv.org/abs/2202.09214),包括其概率和困惑度。Next event prediction 可以在任何解析器输出之上计算。
**异常检测器**: 此模块使用增强后的日志数据执行异常检测。目前主要使用 SKlearn,但也包含少量客户算法。LogLead 已与以下模型集成和测试:
* 监督(5):[决策树](https://en.wikipedia.org/wiki/Decision_tree)、[支持向量机](https://en.wikipedia.org/wiki/Support_vector_machine)、[逻辑回归](https://en.wikipedia.org/wiki/Logistic_regression)、[随机森林](https://en.wikipedia.org/wiki/Random_forest)、[极端梯度提升](https://en.wikipedia.org/wiki/XGBoost)
* 无监督(4):[One-class SVM](https://en.wikipedia.org/wiki/Support_vector_machine#One-class_SVM)、[局部异常因子](https://en.wikipedia.org/wiki/Local_outlier_factor)、[孤立森林](https://en.wikipedia.org/wiki/Isolation_forest)、[K-Means](https://en.wikipedia.org/wiki/K-means_clustering)
* 自定义无监督(2):[词汇外检测器](https://github.com/EvoTestOps/LogLead/blob/main/loglead/OOV_detector.py) 统计测试集中新颖的单词或字符 n-gram 数量。[稀有性模型](https://github.com/EvoTestOps/LogLead/blob/main/loglead/RarityModel.py) 根据训练集中单词或字符 n-gram 的稀有性进行评分。请参阅我们的公开 [预印本](https://arxiv.org/abs/2312.01934) 获取更多细节。
## 参考
Mäntylä MV, Wang Y, Nyyssölä J. Loglead-fast and integrated log loader, enhancer, and anomaly detector. In2024 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER) 2024 Mar 12 (pp. 395-399). IEEE. [PDF](https://ieeexplore.ieee.org/abstract/document/10589612), [preprint](https://arxiv.org/abs/2311.11809)
**加载器**: 此模块读取日志文件并处理每个日志文件的特定特性。它生成一个包含某些半强制字段的数据帧。这些字段使后续阶段的操作成为可能。LogLead 有一个 [RawLoader](https://github.com/EvoTestOps/LogLead/blob/main/loglead/loaders/raw.py),可以加载任何日志文件。它还具有以下公共数据集的自定义加载器,来自 10 个不同系统。定制加载器应能提高异常检测的准确性:
* 3: [HDFS_v1](https://github.com/logpai/loghub/tree/master/HDFS#hdfs_v1), [Hadoop](https://github.com/logpai/loghub/tree/master/Hadoop), [BGL](https://github.com/logpai/loghub/tree/master/BGL),感谢出色的 [LogHub 团队](https://github.com/logpai/loghub)。完整数据请参见 [Zenodo](https://zenodo.org/records/3227177)。
* 3: [Sprit](https://www.usenix.org/cfdr-data#hpc4)、[Thunderbird](https://www.usenix.org/cfdr-data#hpc4) 和 [Liberty](https://www.usenix.org/cfdr-data#hpc4) 可在 Usenix 网站上找到。
* 2: [Nezha](https://github.com/IntelligentDDS/Nezha) 包含来自两个系统的数据:[TrainTicket](https://github.com/FudanSELab/train-ticket) 和 [Google Cloud Webshop demo](https://github.com/GoogleCloudPlatform/microservices-demo)。这是第一个基于微服务系统的数据集。它除了日志数据外,还包含跟踪和指标。
* 2: [ADFA](https://github.com/verazuo/a-labelled-version-of-the-ADFA-LD-dataset) 和 [AWSCTD](https://github.com/DjPasco/AWSCTD) 是两个为入侵检测设计的数据集。
**增强器**: 此模块从日志中提取额外数据。增强过程直接在数据帧中进行,其中新增列作为增强过程的结果。例如,日志解析、创建日志消息的标记、测量日志序列长度都被视为日志增强。增强可以在事件级别进行,也可以在序列级别进行聚合。可用的增强器包括:事件长度(字符、、行)、序列长度、序列 [持续时间](https://pola-rs.github.io/polars/py-polars/html/reference/api/polars.Duration.html)、遵循“NLP”增强器:[Regex](https://crates.io/crates/regex)、[Words](https://en.wikipedia.org/wiki/Bag-of-words_model)、[Character n-grams](https://en.wikipedia.org/wiki/N-gram)。日志解析器:[Drain](https://github.com/logpai/Drain3)、[LenMa](https://github.com/keiichishima/templateminer)、[Spell](https://github.com/bave/pyspell)、[IPLoM](https://github.com/EvoTestOps/LogLead/tree/main/parsers/iplom)、[AEL](https://github.com/EvoTestOps/LogLead/tree/main/parsers/AEL)、[Brain](https://github.com/EvoTestOps/LogLead/tree/main/parsers/Brain)、[Fast-IPLoM](https://github.com/EvoTestOps/LogLead/tree/main/parsers/fast_iplom)、[Tipping](https://pypi.org/project/tipping/) 和 [BERT](https://github.com/google-research/bert)。[NextEventPrediction](https://arxiv.org/abs/2202.09214),包括其概率和困惑度。Next event prediction 可以在任何解析器输出之上计算。
**异常检测器**: 此模块使用增强后的日志数据执行异常检测。目前主要使用 SKlearn,但也包含少量客户算法。LogLead 已与以下模型集成和测试:
* 监督(5):[决策树](https://en.wikipedia.org/wiki/Decision_tree)、[支持向量机](https://en.wikipedia.org/wiki/Support_vector_machine)、[逻辑回归](https://en.wikipedia.org/wiki/Logistic_regression)、[随机森林](https://en.wikipedia.org/wiki/Random_forest)、[极端梯度提升](https://en.wikipedia.org/wiki/XGBoost)
* 无监督(4):[One-class SVM](https://en.wikipedia.org/wiki/Support_vector_machine#One-class_SVM)、[局部异常因子](https://en.wikipedia.org/wiki/Local_outlier_factor)、[孤立森林](https://en.wikipedia.org/wiki/Isolation_forest)、[K-Means](https://en.wikipedia.org/wiki/K-means_clustering)
* 自定义无监督(2):[词汇外检测器](https://github.com/EvoTestOps/LogLead/blob/main/loglead/OOV_detector.py) 统计测试集中新颖的单词或字符 n-gram 数量。[稀有性模型](https://github.com/EvoTestOps/LogLead/blob/main/loglead/RarityModel.py) 根据训练集中单词或字符 n-gram 的稀有性进行评分。请参阅我们的公开 [预印本](https://arxiv.org/abs/2312.01934) 获取更多细节。
## 参考
Mäntylä MV, Wang Y, Nyyssölä J. Loglead-fast and integrated log loader, enhancer, and anomaly detector. In2024 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER) 2024 Mar 12 (pp. 395-399). IEEE. [PDF](https://ieeexplore.ieee.org/abstract/document/10589612), [preprint](https://arxiv.org/abs/2311.11809)
目前,它包含近 1,000 种独特的异常检测组合,涵盖 8 个公共数据集、11 种日志表示(增强器)和 11 个分类器。这些资源使您能够将自身的数据、日志表示或分类器与多种场景进行基准测试。如果您认为某些内容应该被包含,请在 [问题跟踪器](https://github.com/EvoTestOps/LogLead/issues) 中提交数据集、增强器或分类器的请求。
LogLead 的一个关键优势是其自定义加载系统,能够高效地隔离来自不同系统的日志的独特方面。这种设计减少了冗余代码,因为一旦加载日志,相同的增强和异常检测代码可以普遍应用。
## 安装 LogLead
使用 `pip` 安装:
```
python -m pip install loglead
```
然后克隆项目,进入演示文件夹并运行一些演示
```
git clone https://github.com/EvoTestOps/LogLead.git
cd LogLead/demo
python HDFS_samples.py
python TB_samples.py
```
要开始使用自己的数据,最简单的方法是从 [RawLoader](https://github.com/EvoTestOps/LogLead/blob/main/loglead/loaders/raw.py) 开始。要尝试 RawLoader,请运行 [RawLoaderDemo](https://github.com/EvoTestOps/LogLead/blob/main/demo/RawLoader_NoLabels.py)。为此,您需要原始的 [BGL](https://zenodo.org/records/8196385/files/BGL.zip?download=1) 和 [HDFS](https://zenodo.org/records/8196385/files/HDFS_v1.zip?download=1) 数据集。您还需要编辑 [RawLoaderDemo 脚本](https://github.com/EvoTestOps/LogLead/blob/main/demo/RawLoader_NoLabels.py) 或在 LogLead 根目录下添加一个 ".env" 文件,以便演示知道数据在计算机上的位置。请参考 [.env.sample](https://github.com/EvoTestOps/LogLead/blob/main/.env.sample) 了解 ".env" 文件应如何设置。之后运行演示
```
python RawLoader_NoLabels.py
```
最后,您可以使用 [DownLoadData](https://github.com/EvoTestOps/LogLead/blob/main/tests/download_data.py) 下载所有数据。[配置文件](https://github.com/EvoTestOps/LogLead/blob/main/tests/datasets.yml) 控制加载哪些内容,以及在运行测试时如何使用它们。
```
cd LogLead/tests
python download_data.py
```
### 已知问题
- 如果 `scikit-learn` 的 wheel 编译失败,请检查是否安装了 `gcc` 和 `g++`。
- pip 版本没有 `BertEmbeddings` 所需的 `tensorflow` 依赖项。
请手动安装它们(最好在 conda 环境中)。
## 演示
在以下演示中,您会注意到 LogLead 设计效率的一个显著方面:代码可重用性。两个演示虽然分析不同的数据集,但共享了大量底层代码。这不仅展示了 LogLead 在处理各种日志格式方面的灵活性,还展示了其通过可重用代码组件简化分析过程的能力。
### Thunderbird 超级计算机日志演示
- **脚本**: [TB_samples.py](https://github.com/EvoTestOps/LogLead/blob/main/demo/TB_samples.py)
- **描述**: 此演示展示了一个 Thunderbird 超级计算机日志,按行(事件)级别标记。标记为“-”的第一列表示正常行为,其他标记表示异常。
- **日志快照**: 在[此处](https://github.com/logpai/loghub/blob/master/Thunderbird/Thunderbird_2k.log_structured.csv)查看日志。
- **数据集**: 演示包含一个 parquet 文件,其中包含 263,408 个日志事件的子集,其中有 21,955 个异常。
- **屏幕录制**: 如需了解演示概览,请在 YouTube 上观看我们的[5 分钟屏幕录制](https://www.youtube.com/watch?v=8stdbtTfJVo)。
### Hadoop 分布式文件系统(HDFS)日志演示
- **脚本**: [HDFS_samples.py](https://github.com/EvoTestOps/LogLead/blob/main/demo/HDFS_samples.py)
- **描述**: 此演示展示来自 Hadoop 分布式文件系统(HDFS)的日志,按序列级别标记(序列是多个日志事件的集合)。
- **日志快照**: 在[此处](https://github.com/logpai/loghub/blob/master/HDFS/HDFS_2k.log_structured.csv)查看日志。
- **异常标签**: 在单独的文件中提供。
- **数据集**: 演示包含一个 parquet 文件,其中包含 222,579 个日志事件的子集,形成 11,501 个序列,其中包含 350 个异常。
## 测试
通常,我们的测试流程包括运行以下操作。演示可以快速发现明显错误,而完整测试集需要更长的时间运行——最多 30 分钟。
基本演示
```
cd demo
python HDFS_samples.py
python TB_samples.py
```
解析器基准测试
```
cd demo/parser_benchmark
python ano_detection.py
python parsing_speed.py
```
运行完整测试
```
cd tests
python main.py
```
## 异常检测结果示例
下面您可以看到在 HDFS 数据的 0.5% 子集上训练的异常检测结果(F1-Binary)。
我们使用了 5 种不同的日志消息增强策略:[Words](https://en.wikipedia.org/wiki/Bag-of-words_model)、[Drain](https://github.com/logpai/Drain3)、[LenMa](https://github.com/keiichishima/templateminer)、[Spell](https://github.com/logpai/logparser/tree/main/logparser/Spell) 和 [BERT](https://github.com/google-research/bert)
增强策略与 5 种不同的机器学习算法进行测试:DT(决策树)、SVM(支持向量机)、LR(逻辑回归)、RF(随机森林)和 XGB(极端梯度提升)。
| | Words | Drain | Lenma | Spell | Bert | Average |
|---------|--------|--------|--------|--------|--------|---------|
| DT | 0.9719 | 0.9816 | 0.9803 | 0.9828 | 0.9301 | 0.9693 |
| SVM | 0.9568 | 0.9591 | 0.9605 | 0.9559 | 0.8569 | 0.9378 |
| LR | 0.9476 | 0.8879 | 0.8900 | 0.9233 | 0.5841 | 0.8466 |
| RF | 0.9717 | 0.9749 | 0.9668 | 0.9809 | 0.9382 | 0.9665 |
| XGB | 0.9721 | 0.9482 | 0.9492 | 0.9535 | 0.9408 | 0.9528 |
|---------|--------|--------|--------|--------|--------|---------|
| Average | 0.9640 | 0.9503 | 0.9494 | 0.9593 | 0.8500 | |
## 功能概述
LogLead 由独立的模块组成:加载器、增强器和异常检测器。我们使用 [Polars](https://www.pola.rs/) 数据帧,因为它比 Pandas 明显更快。
**加载器**: 此模块读取日志文件并处理每个日志文件的特定特性。它生成一个包含某些半强制字段的数据帧。这些字段使后续阶段的操作成为可能。LogLead 有一个 [RawLoader](https://github.com/EvoTestOps/LogLead/blob/main/loglead/loaders/raw.py),可以加载任何日志文件。它还具有以下公共数据集的自定义加载器,来自 10 个不同系统。定制加载器应能提高异常检测的准确性:
* 3: [HDFS_v1](https://github.com/logpai/loghub/tree/master/HDFS#hdfs_v1), [Hadoop](https://github.com/logpai/loghub/tree/master/Hadoop), [BGL](https://github.com/logpai/loghub/tree/master/BGL),感谢出色的 [LogHub 团队](https://github.com/logpai/loghub)。完整数据请参见 [Zenodo](https://zenodo.org/records/3227177)。
* 3: [Sprit](https://www.usenix.org/cfdr-data#hpc4)、[Thunderbird](https://www.usenix.org/cfdr-data#hpc4) 和 [Liberty](https://www.usenix.org/cfdr-data#hpc4) 可在 Usenix 网站上找到。
* 2: [Nezha](https://github.com/IntelligentDDS/Nezha) 包含来自两个系统的数据:[TrainTicket](https://github.com/FudanSELab/train-ticket) 和 [Google Cloud Webshop demo](https://github.com/GoogleCloudPlatform/microservices-demo)。这是第一个基于微服务系统的数据集。它除了日志数据外,还包含跟踪和指标。
* 2: [ADFA](https://github.com/verazuo/a-labelled-version-of-the-ADFA-LD-dataset) 和 [AWSCTD](https://github.com/DjPasco/AWSCTD) 是两个为入侵检测设计的数据集。
**增强器**: 此模块从日志中提取额外数据。增强过程直接在数据帧中进行,其中新增列作为增强过程的结果。例如,日志解析、创建日志消息的标记、测量日志序列长度都被视为日志增强。增强可以在事件级别进行,也可以在序列级别进行聚合。可用的增强器包括:事件长度(字符、、行)、序列长度、序列 [持续时间](https://pola-rs.github.io/polars/py-polars/html/reference/api/polars.Duration.html)、遵循“NLP”增强器:[Regex](https://crates.io/crates/regex)、[Words](https://en.wikipedia.org/wiki/Bag-of-words_model)、[Character n-grams](https://en.wikipedia.org/wiki/N-gram)。日志解析器:[Drain](https://github.com/logpai/Drain3)、[LenMa](https://github.com/keiichishima/templateminer)、[Spell](https://github.com/bave/pyspell)、[IPLoM](https://github.com/EvoTestOps/LogLead/tree/main/parsers/iplom)、[AEL](https://github.com/EvoTestOps/LogLead/tree/main/parsers/AEL)、[Brain](https://github.com/EvoTestOps/LogLead/tree/main/parsers/Brain)、[Fast-IPLoM](https://github.com/EvoTestOps/LogLead/tree/main/parsers/fast_iplom)、[Tipping](https://pypi.org/project/tipping/) 和 [BERT](https://github.com/google-research/bert)。[NextEventPrediction](https://arxiv.org/abs/2202.09214),包括其概率和困惑度。Next event prediction 可以在任何解析器输出之上计算。
**异常检测器**: 此模块使用增强后的日志数据执行异常检测。目前主要使用 SKlearn,但也包含少量客户算法。LogLead 已与以下模型集成和测试:
* 监督(5):[决策树](https://en.wikipedia.org/wiki/Decision_tree)、[支持向量机](https://en.wikipedia.org/wiki/Support_vector_machine)、[逻辑回归](https://en.wikipedia.org/wiki/Logistic_regression)、[随机森林](https://en.wikipedia.org/wiki/Random_forest)、[极端梯度提升](https://en.wikipedia.org/wiki/XGBoost)
* 无监督(4):[One-class SVM](https://en.wikipedia.org/wiki/Support_vector_machine#One-class_SVM)、[局部异常因子](https://en.wikipedia.org/wiki/Local_outlier_factor)、[孤立森林](https://en.wikipedia.org/wiki/Isolation_forest)、[K-Means](https://en.wikipedia.org/wiki/K-means_clustering)
* 自定义无监督(2):[词汇外检测器](https://github.com/EvoTestOps/LogLead/blob/main/loglead/OOV_detector.py) 统计测试集中新颖的单词或字符 n-gram 数量。[稀有性模型](https://github.com/EvoTestOps/LogLead/blob/main/loglead/RarityModel.py) 根据训练集中单词或字符 n-gram 的稀有性进行评分。请参阅我们的公开 [预印本](https://arxiv.org/abs/2312.01934) 获取更多细节。
## 参考
Mäntylä MV, Wang Y, Nyyssölä J. Loglead-fast and integrated log loader, enhancer, and anomaly detector. In2024 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER) 2024 Mar 12 (pp. 395-399). IEEE. [PDF](https://ieeexplore.ieee.org/abstract/document/10589612), [preprint](https://arxiv.org/abs/2311.11809)标签:BGL, HDFS, LogDelta, LogLead, pip安装, Python日志, VisualLogAnalyzer, 分类器组合, 可扩展加载器, 异常检测, 日志分割, 日志加载, 日志加载器, 日志可视化, 日志基准, 日志增强, 日志处理, 日志平台, 日志异常检测算法, 日志挖掘, 日志数据, 日志标注, 日志模式识别, 日志演示, 日志特征工程, 日志系统, 日志聚类, 日志表征学习, 日志表示, 机器学习分类器, 特征工程, 逆向工具