hitsz-ids/synthetic-data-generator
GitHub: hitsz-ids/synthetic-data-generator
一个专注于生成高质量结构化表格数据的框架,支持GAN、统计模型及LLM多种合成方式,兼顾隐私保护与大数据性能。
Stars: 2422 | Forks: 391
Synthetic Data Generator (SDG) 是一个专门用于生成高质量结构化表格数据的框架。
合成数据不包含任何敏感信息,但保留了原始数据的基本特征,因此不受 GDPR 和 ADPPA 等隐私法规的约束。
高质量的合成数据可以安全地应用于数据共享、模型训练与调试、系统开发与测试等各种领域。
很高兴您的到来,并期待您的贡献,请通过这份[贡献概述指南](CONTRIBUTING.md)开始参与项目!
## 💥新闻
我们目前的主要成果和时间线如下:
🔥 2024年11月21日:1) 模型集成 - 我们已将 `GaussianCopula` 模型集成到数据处理器系统中。请查看此 [PR](https://github.com/hitsz-ids/synthetic-data-generator/pull/241) 中的代码示例;2) 合成质量 - 我们实现了数据列关系的自动检测并允许指定关系,提高了合成数据的质量([代码示例](https://synthetic-data-generator.readthedocs.io/en/latest/user_guides/single_table_column_combinations.html));3) 性能增强 - 我们显著降低了 GaussianCopula 处理离散数据时的内存占用,使其能够在 `2C4G` 配置下对数千个分类数据进行训练!
🔥 2024年5月30日:Data Processor 模块正式合并。该模块将:1) 帮助 SDG 在将数据输入模型之前转换某些数据列(例如 Datetime 列)的格式(以避免被视为离散类型),并将模型生成的数据反向转换为原始格式;2) 对各种数据类型执行更定制化的预处理和后处理;3) 轻松处理原始数据中的空值等问题;4) 支持插件系统。
🔥 2024年2月20日:包含基于 LLM 的单表数据合成模型,查看 colab 示例:
LLM:数据合成 和
LLM:表外特征推断。
🔧 2024年2月7日:我们改进了 `sdgx.data_models.metadata` 以支持单表和多表的元数据信息描述,支持多种数据类型,支持自动数据类型推断。查看 colab 示例:
SDG 单表元数据。
🔶 2023年12月20日:发布 v0.1.0,包含支持亿级数据处理能力的 CTGAN 模型,查看我们与 SDV 的
基准测试对比,其中 SDG 实现了更低的内存消耗并避免了训练期间的崩溃。具体使用请查看 colab 示例:
支持亿级数据的 CTGAN。
🔆 2023年8月10日:提交了 SDG 的第一行代码。
## 🎉 集成 LLM 的合成数据生成
长期以来,LLM 一直被用于理解和生成各种类型的数据。事实上,LLM 在表格数据生成方面也具备一定的能力。此外,它还具备一些传统方法(基于 GAN 或统计方法)无法实现的能力。
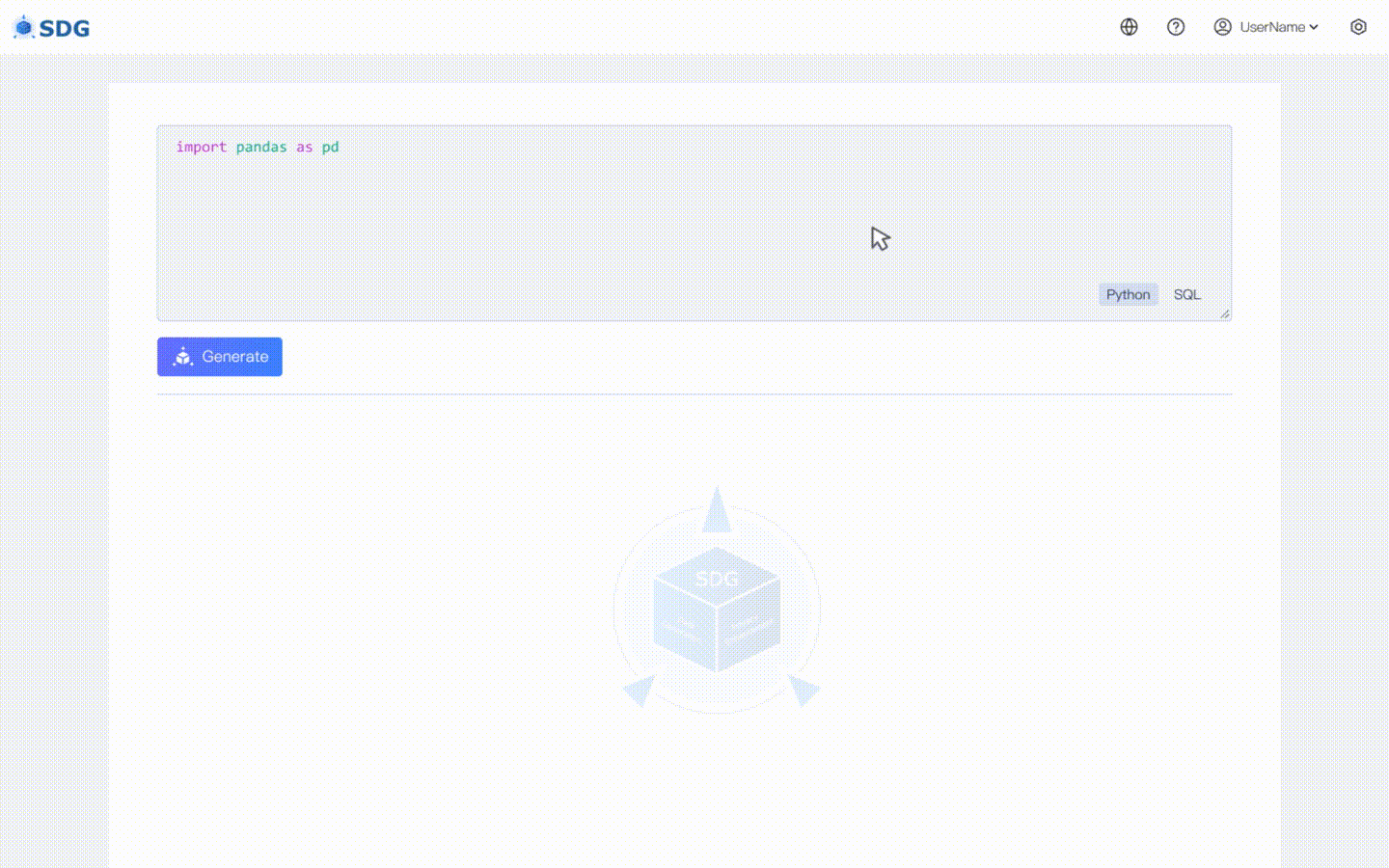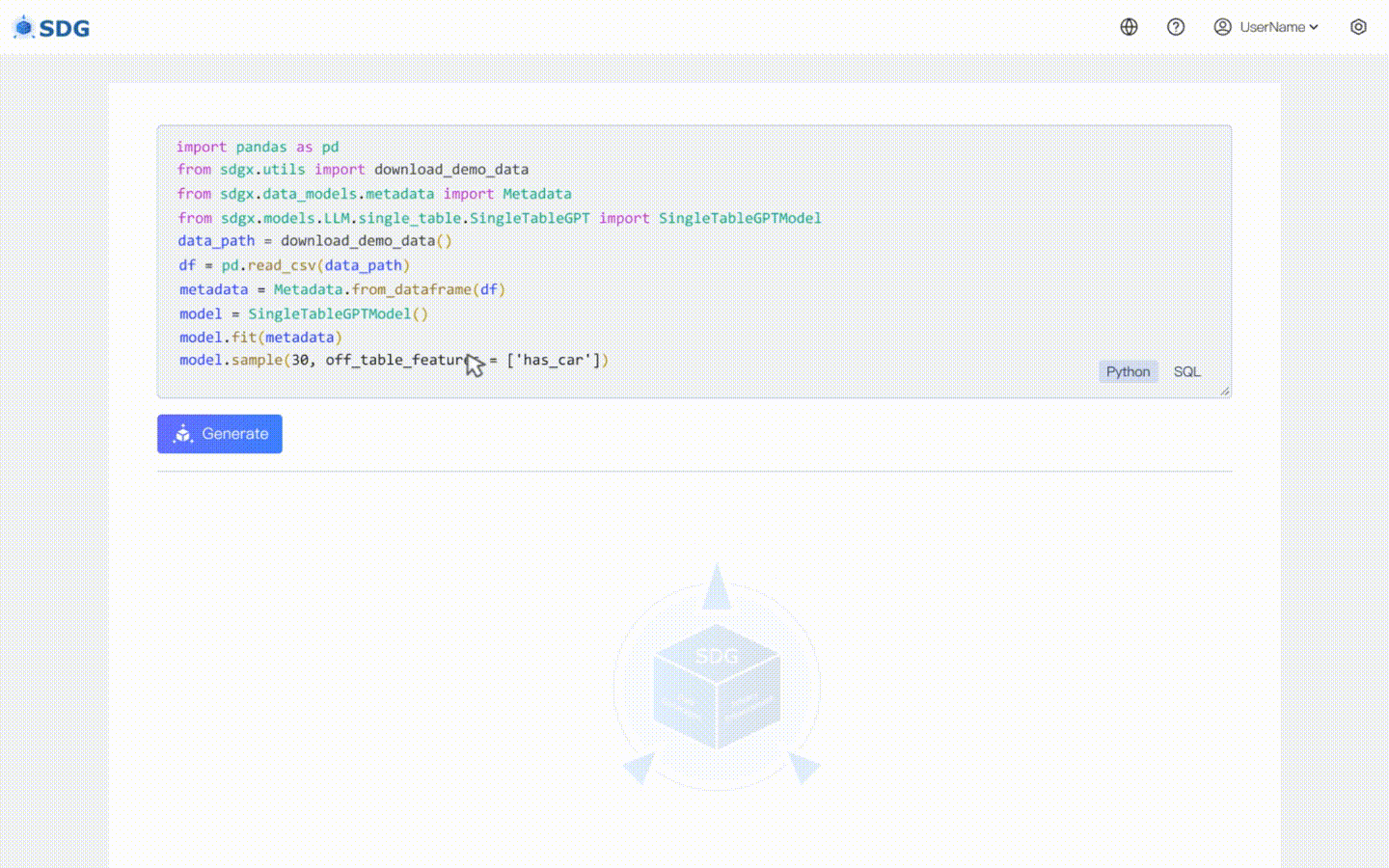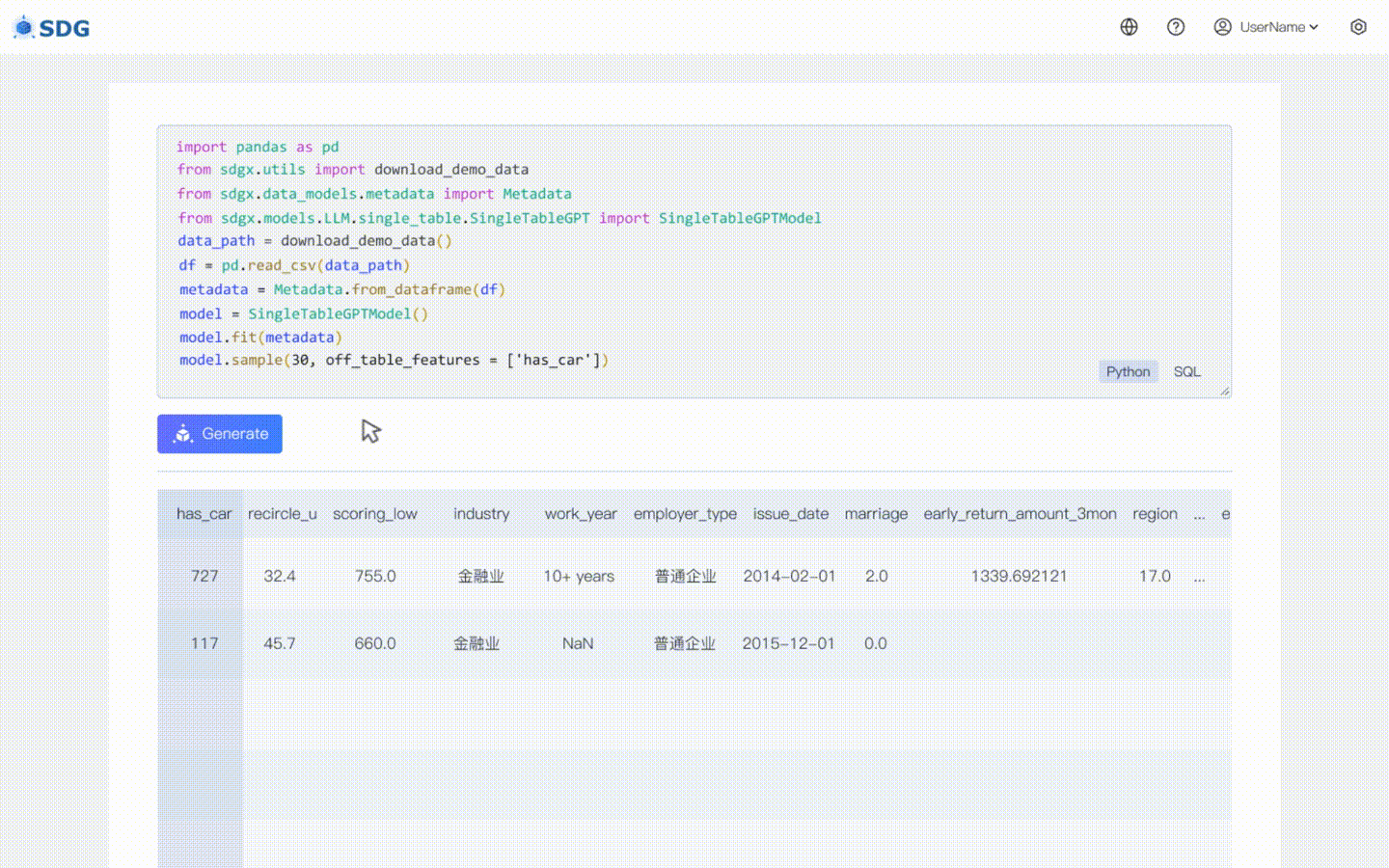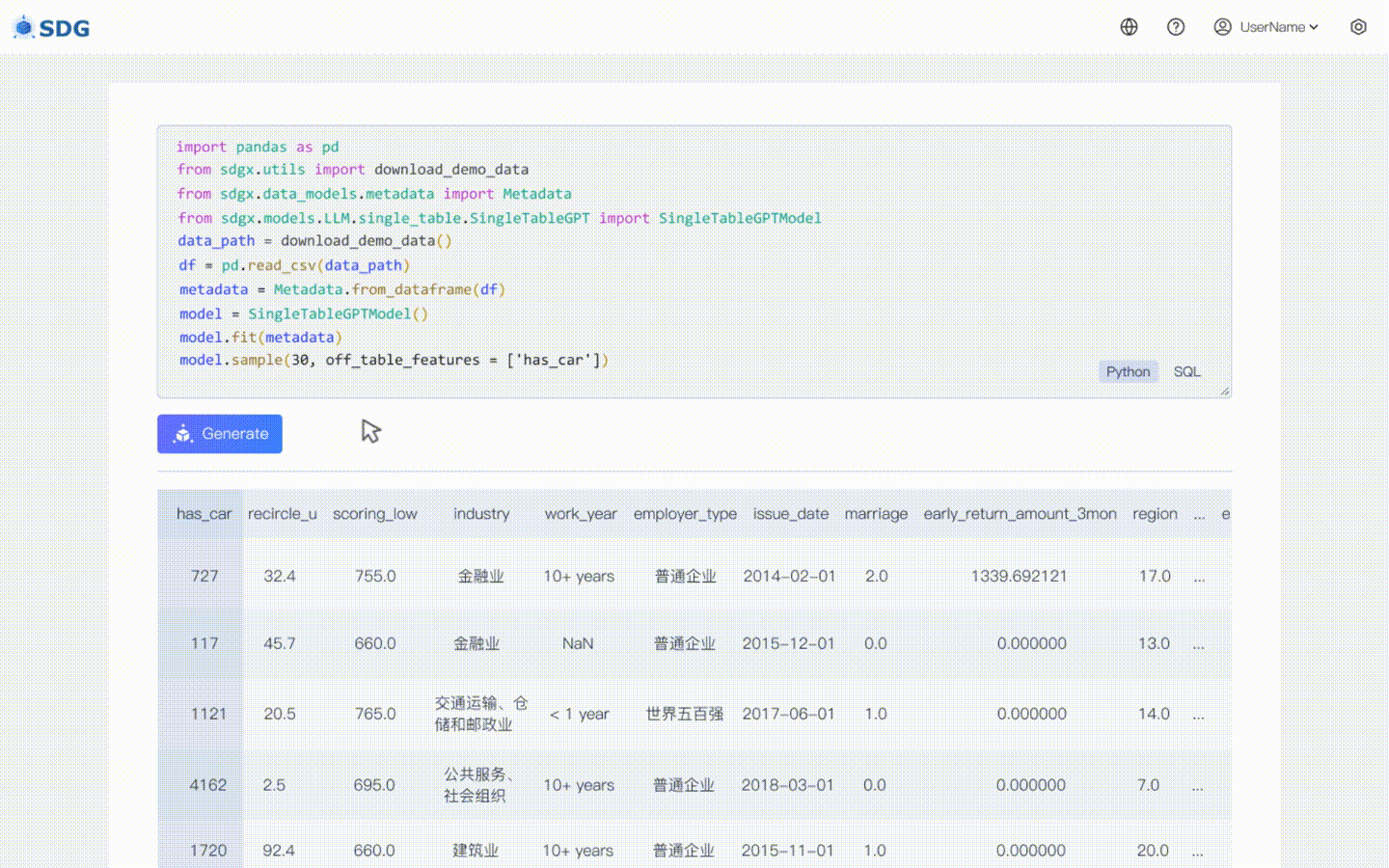
我们的 `sdgx.models.LLM.single_table.gpt.SingleTableGPTModel` 实现了两个新功能:
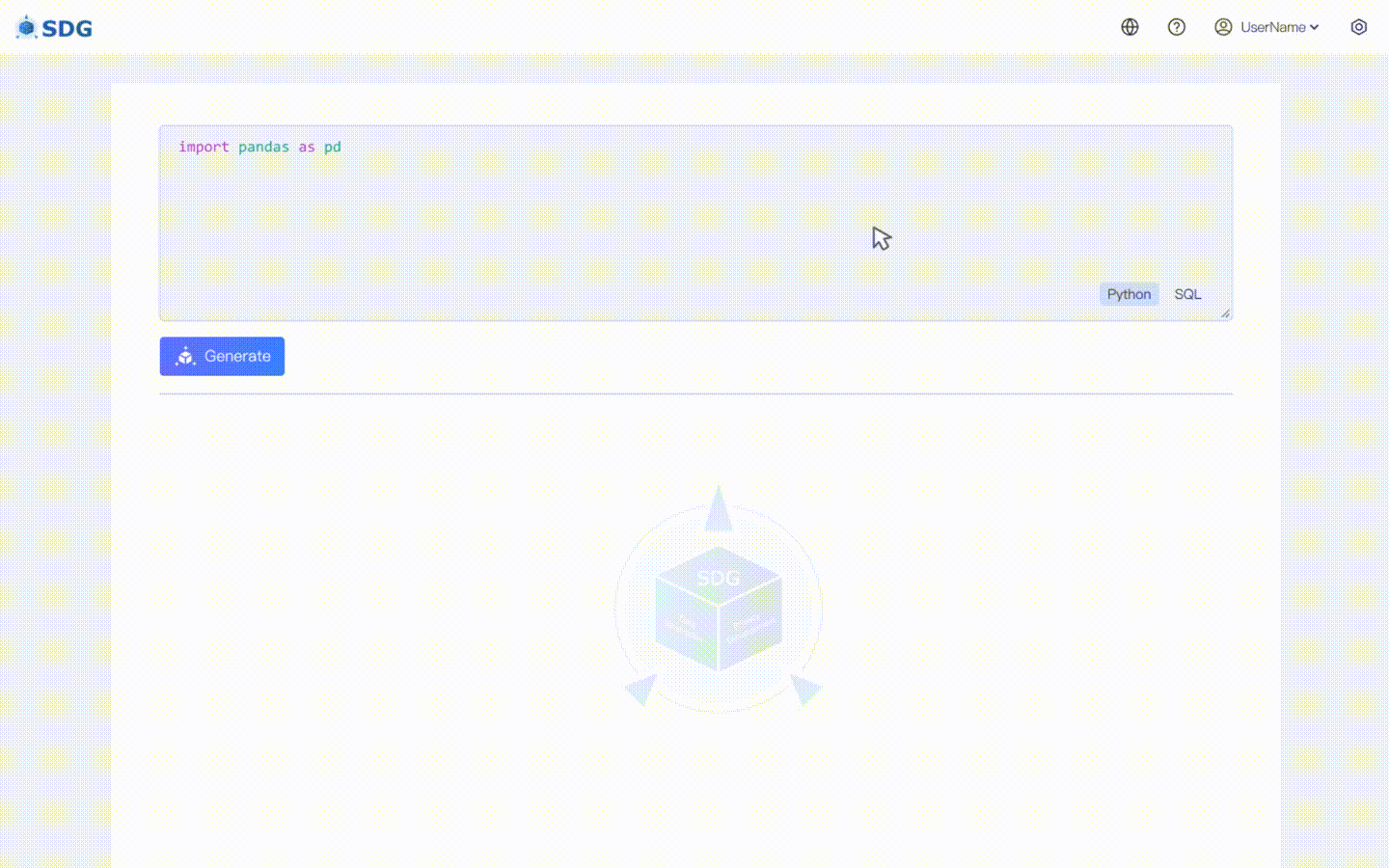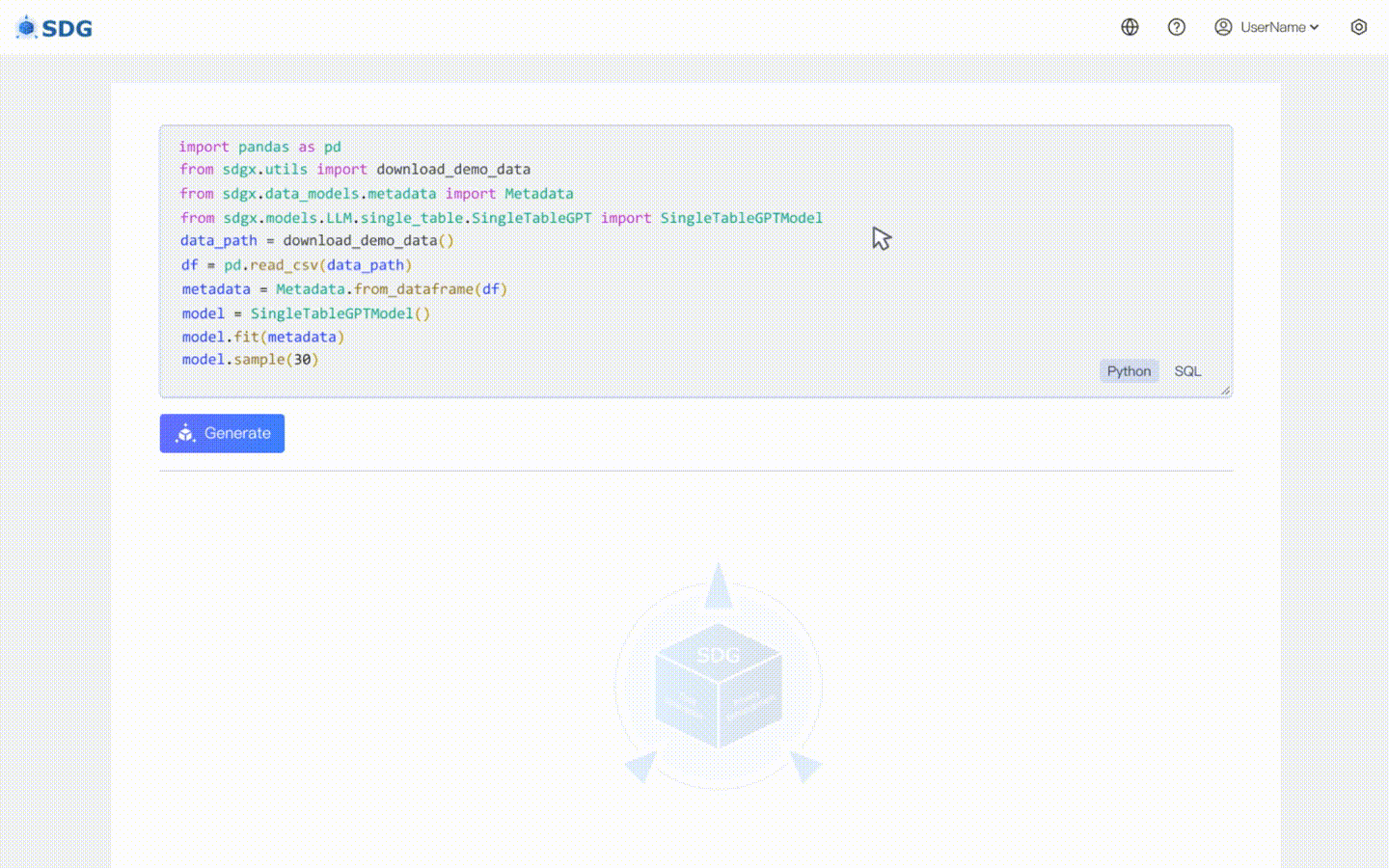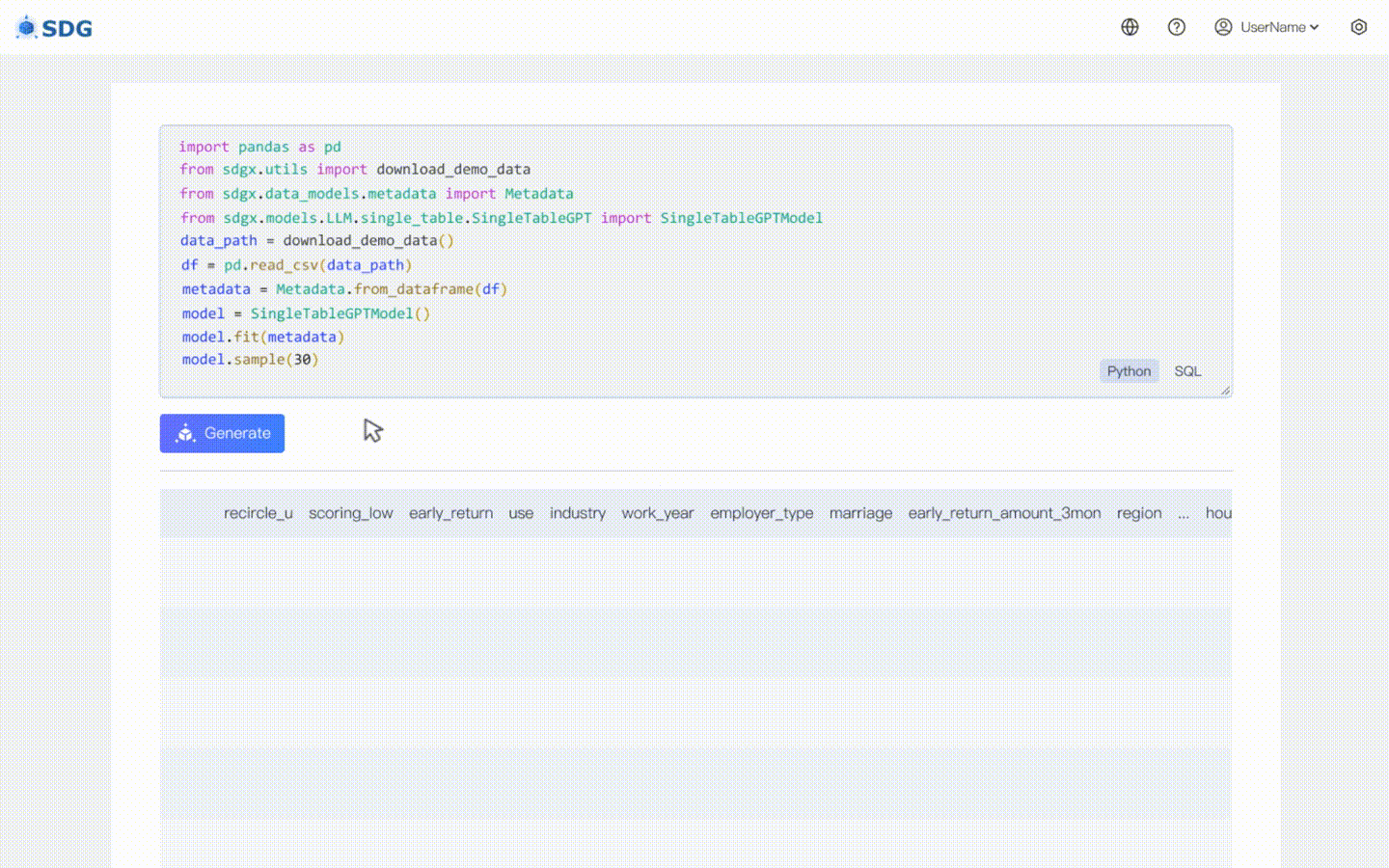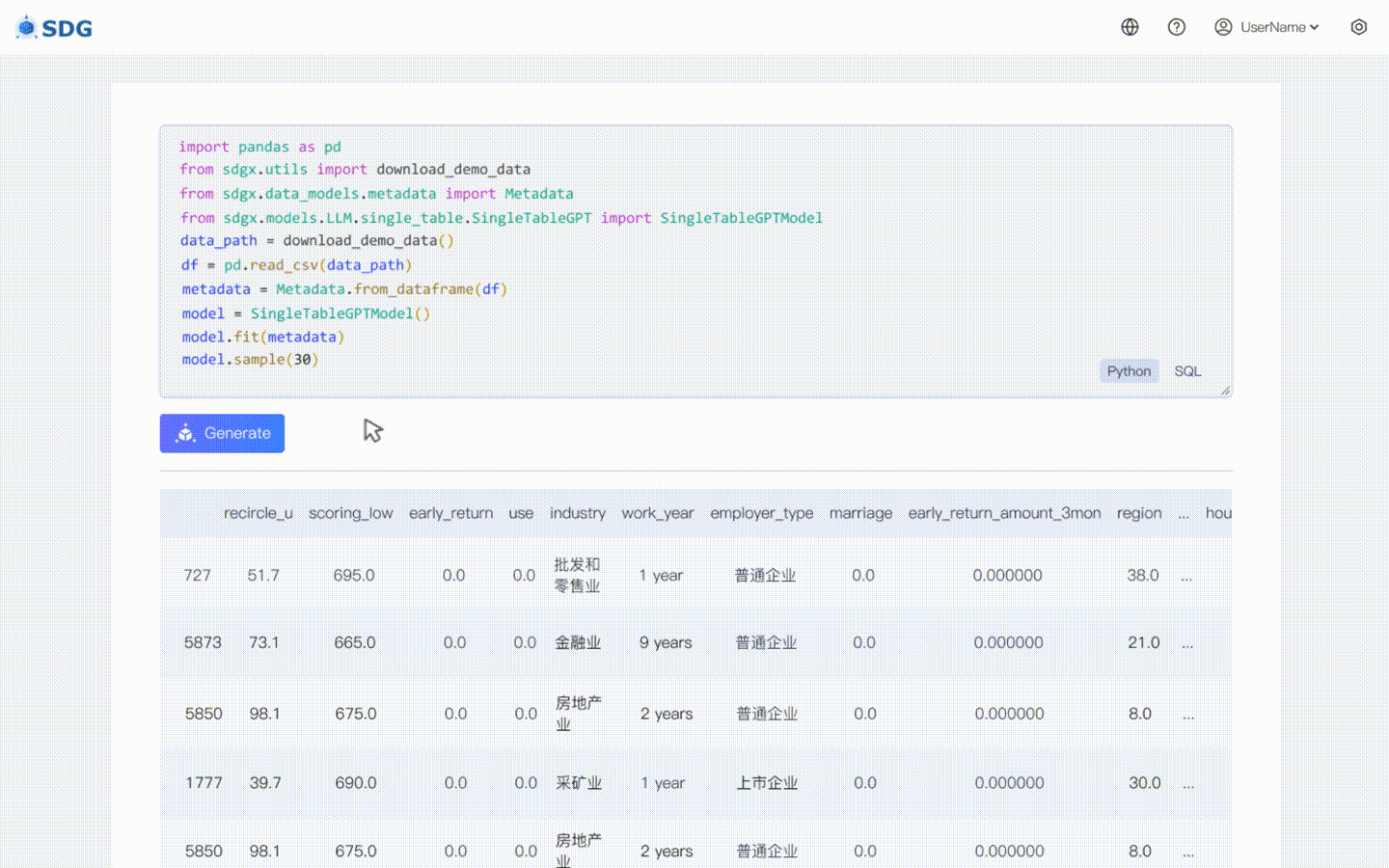
### 无数据合成数据生成
无需训练数据,可根据元数据生成合成数据,请查看我们的
colab 示例。
### 表外特征推断
根据表中的现有数据和 LLM 掌握的知识推断新的列数据,请查看我们的
colab 示例。
## 💫 为什么选择 SDG ?
- 技术进步:
- 支持广泛的统计数据合成算法,同时也集成了基于 LLM 的合成数据生成模型;
- 针对大数据进行了优化,有效降低内存消耗;
- 持续跟踪学术界和工业界的最新进展,并及时引入对优秀算法和模型的支持。
- 隐私增强:
- SDG 支持差分隐私、匿名化等方法来增强合成数据的安全性。
- 易于扩展:
- 支持以插件包的形式扩展模型、数据处理、数据连接器等。
## 🌀 快速开始
### 预构建镜像
您可以使用预构建镜像快速体验最新功能。
```
docker pull idsteam/sdgx:latest
```
### 从 PyPi 安装
```
pip install sdgx
```
### 本地安装(推荐)
通过源码安装以使用 SDG。
```
git clone git@github.com:hitsz-ids/synthetic-data-generator.git
pip install .
# 或从 git 安装
pip install git+https://github.com/hitsz-ids/synthetic-data-generator.git
```
### 单表数据生成与评估快速演示
#### 演示代码
```
from sdgx.data_connectors.csv_connector import CsvConnector
from sdgx.models.ml.single_table.ctgan import CTGANSynthesizerModel
from sdgx.synthesizer import Synthesizer
from sdgx.utils import download_demo_data
# 这将下载演示数据到 ./dataset
dataset_csv = download_demo_data()
# 为 csv 文件创建 data connector
data_connector = CsvConnector(path=dataset_csv)
# 初始化 synthesizer,使用 CTGAN 模型
synthesizer = Synthesizer(
model=CTGANSynthesizerModel(epochs=1), # For quick demo
data_connector=data_connector,
)
# 拟合模型
synthesizer.fit()
# 采样
sampled_data = synthesizer.sample(1000)
print(sampled_data)
```
#### 对比
真实数据如下:
```
>>> data_connector.read()
age workclass fnlwgt education ... capitalloss hoursperweek native-country class
0 2 State-gov 77516 Bachelors ... 0 2 United-States <=50K
1 3 Self-emp-not-inc 83311 Bachelors ... 0 0 United-States <=50K
2 2 Private 215646 HS-grad ... 0 2 United-States <=50K
3 3 Private 234721 11th ... 0 2 United-States <=50K
4 1 Private 338409 Bachelors ... 0 2 Cuba <=50K
... ... ... ... ... ... ... ... ... ...
48837 2 Private 215419 Bachelors ... 0 2 United-States <=50K
48838 4 NaN 321403 HS-grad ... 0 2 United-States <=50K
48839 2 Private 374983 Bachelors ... 0 3 United-States <=50K
48840 2 Private 83891 Bachelors ... 0 2 United-States <=50K
48841 1 Self-emp-inc 182148 Bachelors ... 0 3 United-States >50K
[48842 rows x 15 columns]
```
合成数据如下:
```
>>> sampled_data
age workclass fnlwgt education ... capitalloss hoursperweek native-country class
0 1 NaN 28219 Some-college ... 0 2 Puerto-Rico <=50K
1 2 Private 250166 HS-grad ... 0 2 United-States >50K
2 2 Private 50304 HS-grad ... 0 2 United-States <=50K
3 4 Private 89318 Bachelors ... 0 2 Puerto-Rico >50K
4 1 Private 172149 Bachelors ... 0 3 United-States <=50K
.. ... ... ... ... ... ... ... ... ...
995 2 NaN 208938 Bachelors ... 0 1 United-States <=50K
996 2 Private 166416 Bachelors ... 2 2 United-States <=50K
997 2 NaN 336022 HS-grad ... 0 1 United-States <=50K
998 3 Private 198051 Masters ... 0 2 United-States >50K
999 1 NaN 41973 HS-grad ... 0 2 United-States <=50K
[1000 rows x 15 columns]
```
## 👩🎓 相关工作
- CTGAN:[Modeling Tabular Data using Conditional GAN](https://proceedings.neurips.cc/paper/2019/hash/254ed7d2de3b23ab10936522dd547b78-Abstract.html)
- C3-TGAN: [C3-TGAN- Controllable Tabular Data Synthesis with Explicit Correlations and Property Constraints](https://www.researchgate.net/publication/374652636_C3-TGAN-_Controllable_Tabular_Data_Synthesis_with_Explicit_Correlations_and_Property_Constraints)
- TVAE:[Modeling Tabular Data using Conditional GAN](https://proceedings.neurips.cc/paper/2019/hash/254ed7d2de3b23ab10936522dd547b78-Abstract.html)
- table-GAN:[Data Synthesis based on Generative Adversarial Networks](https://arxiv.org/pdf/1806.03384.pdf)
- CTAB-GAN:[CTAB-GAN: Effective Table Data Synthesizing](https://proceedings.mlr.press/v157/zhao21a/zhao21a.pdf)
- OCT-GAN: [OCT-GAN: Neural ODE-based Conditional Tabular GANs](https://arxiv.org/pdf/2105.14969.pdf)
## 🤝 加入社区
SDG 项目由**哈尔滨工业大学数据安全研究所**发起。如果您对我们的项目感兴趣,欢迎加入我们的社区。我们欢迎致力于通过开源实现数据保护和安全的组织、团队和个人:
- 在起草 pull request 之前,请阅读 [CONTRIBUTING](./CONTRIBUTING.md)。
- 通过查看 [查看 Good First Issue](https://github.com/hitsz-ids/synthetic-data-generator/labels/good%20first%20issue) 提交 issue 或提交 Pull Request。
- 通过二维码加入我们的微信群。

## 📄 许可证
SDG 开源项目使用 Apache-2.0 许可证,请参考 [LICENSE](https://github.com/hitsz-ids/synthetic-data-generator/blob/main/LICENSE)。
标签:Apex, C2, Python, SDG, 人工智能, 凭据扫描, 合成数据生成, 大数据, 开源框架, 持续集成, 数据增强, 数据科学, 数据脱敏, 数据集构建, 无后门, 机器学习, 深度学习, 生成模型, 用户模式Hook绕过, 目录扫描, 结构化数据, 网络安全, 表格数据, 请求拦截, 调试插件, 资源验证, 逆向工具, 隐私保护, 隐私计算







