modelscope/ms-swift
GitHub: modelscope/ms-swift
ms-swift 是一个支持 600+ 大模型和 400+ 多模态模型从训练到部署的全链路框架,覆盖轻量微调、强化学习、推理加速和量化导出等核心场景。
Stars: 14558 | Forks: 1483
# SWIFT (Scalable lightWeight Infrastructure for Fine-Tuning)
## 🛠️ 安装
使用 pip 安装:
```
pip install ms-swift -U
# 使用 uv
pip install uv
uv pip install ms-swift -U --torch-backend=auto
```
从源码安装:
```
# pip install git+https://github.com/modelscope/ms-swift.git
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
# 主分支适用于 swift 4.x。要安装 swift 3.x,请运行以下命令:
# git checkout release/3.12
pip install -e .
# 使用 uv
uv pip install -e . --torch-backend=auto
```
运行环境:
| | 版本范围 | 推荐版本 | 备注 |
|--------------|--------------|---------------------|-------------------------------------------|
| python | >=3.10 | 3.12 | |
| cuda | | cuda12.8/13.0 | 如果使用 CPU、NPU、MPS 则无需安装 |
| torch | >=2.0 | 2.8.0/2.11.0 | |
| transformers | >=4.33 | 4.57.6/5.8.1 | |
| modelscope | >=1.23 | |
| datasets | >=3.0,<4.8.5 | 3.6.0/4.8.4 | |
| peft | >=0.11,<0.20 | | |
| flash_attn | | 2.8.3/4.0.0b15 | |
| trl | >=0.15,<1.0 | 0.29.1 | RLHF |
| deepspeed | >=0.14 | 0.18.9 | 训练 |
| vllm | >=0.5.1 | 0.11.0/0.21.0 | 推理/部署 |
| sglang | >=0.4.6 | | 推理/部署 |
| evalscope | >=1.0 | | 评测 |
| gradio | | 5.32.1 | Web-UI/App |
有关更多可选依赖项,您可以参考[这里](https://github.com/modelscope/ms-swift/blob/main/requirements/install_all.sh)。
## 🚀 快速开始
在单张 3090 GPU 上对 Qwen3-4B-Instruct-2507 进行 10 分钟的自我认知微调:
### 命令行界面(推荐)
```
# 13GB
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model Qwen/Qwen3-4B-Instruct-2507 \
--tuner_type lora \
--dataset 'AI-ModelScope/alpaca-gpt4-data-zh#500' \
'AI-ModelScope/alpaca-gpt4-data-en#500' \
'swift/self-cognition#500' \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 2 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--model_author swift \
--model_name swift-robot
```
小贴士:
- 如果您想使用自定义数据集进行训练,可以参考[此指南](https://swift.readthedocs.io/en/latest/Customization/Custom-dataset.html)整理您的数据集格式,并指定 `--dataset `。
- `--model_author` 和 `--model_name` 参数仅在数据集包含 `swift/self-cognition` 时生效。
- 要使用其他模型进行训练,只需修改 `--model `。
- 默认情况下,使用 **ModelScope** 下载模型和数据集。如果您想使用 HuggingFace,只需指定 `--use_hf true`。
训练完成后,使用以下命令使用训练后的权重进行推理:
- 这里的 `--adapters` 应替换为训练期间生成的最后一个 checkpoint 文件夹。由于 adapters 文件夹中包含了训练参数文件 `args.json`,因此无需单独指定 `--model`、`--system`;Swift 会自动读取这些参数。要禁用此行为,可以设置 `--load_args false`。
```
# 使用交互式命令行进行推理。
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters output/vx-xxx/checkpoint-xxx \
--stream true \
--temperature 0 \
--max_new_tokens 2048
# merge-lora 并使用 vLLM 进行推理加速
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters output/vx-xxx/checkpoint-xxx \
--stream true \
--merge_lora true \
--infer_backend vllm \
--vllm_max_model_len 8192 \
--temperature 0 \
--max_new_tokens 2048
```
最后,使用以下命令将模型推送到 ModelScope:
```
CUDA_VISIBLE_DEVICES=0 \
swift export \
--adapters output/vx-xxx/checkpoint-xxx \
--push_to_hub true \
--hub_model_id '' \
--hub_token '' \
--use_hf false
```
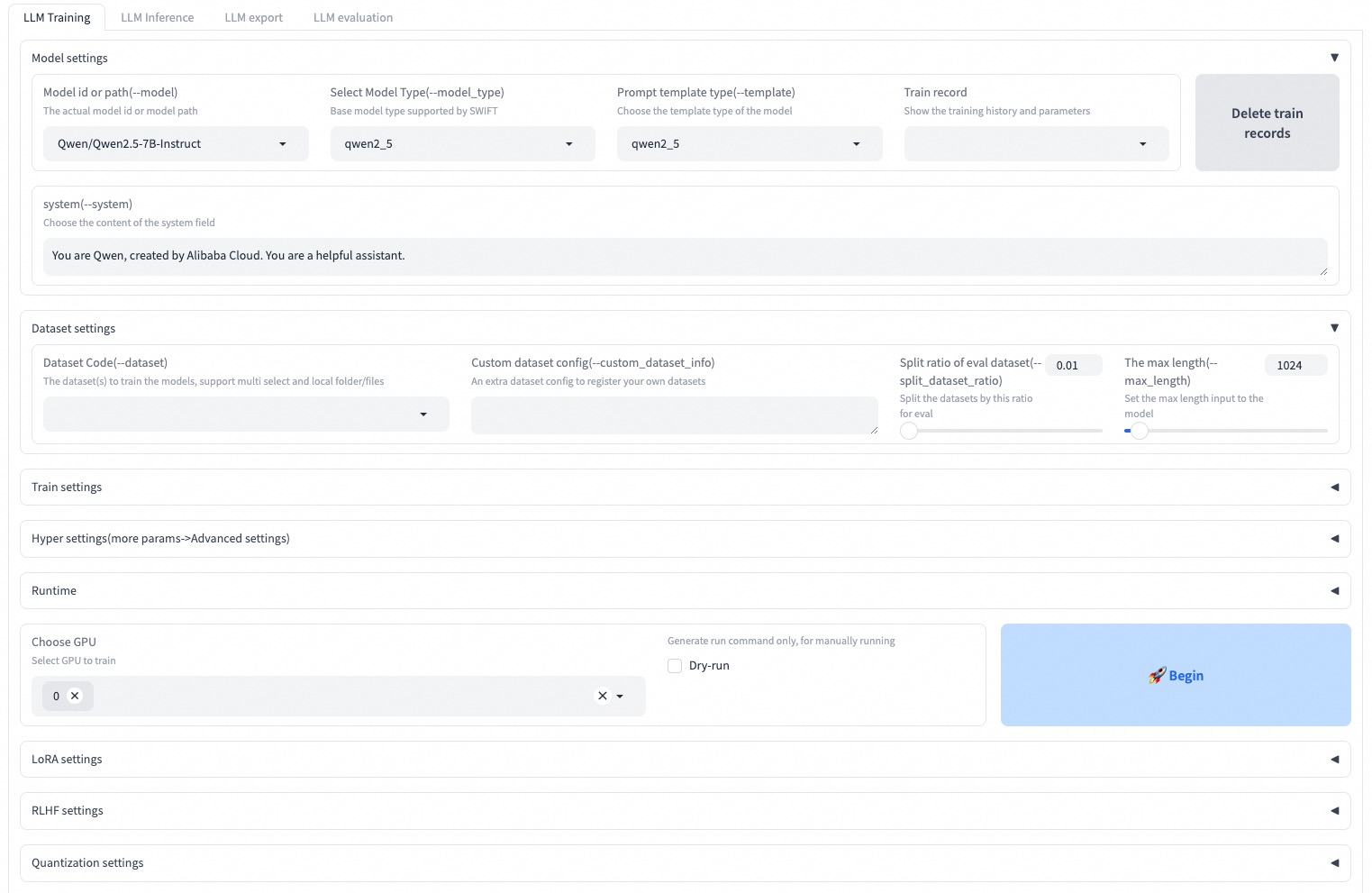
### Web-UI
Web-UI 是一个基于 Gradio 界面技术的**零门槛**训练和部署界面解决方案。有关更多详细信息,您可以查看[这里](https://swift.readthedocs.io/en/latest/GetStarted/Web-UI.html)。
```
SWIFT_UI_LANG=en swift web-ui
```
### 使用 Python
ms-swift 还支持使用 Python 进行训练和推理。以下是训练和推理的伪代码。有关更多详细信息,您可以参考[这里](https://github.com/modelscope/ms-swift/blob/main/examples/notebook/qwen2_5-self-cognition/self-cognition-sft.ipynb)。
训练:
```
from peft import LoraConfig, get_peft_model
from swift import get_model_processor, get_template, load_dataset, EncodePreprocessor
from swift.trainers import Seq2SeqTrainer, Seq2SeqTrainingArguments
# 获取模型和 template,并添加可训练的 LoRA 模块
model, tokenizer = get_model_processor(model_id_or_path, ...)
template = get_template(tokenizer, ...)
lora_config = LoraConfig(...)
model = get_peft_model(model, lora_config)
# 下载并加载数据集,并将文本编码为 tokens
train_dataset, val_dataset = load_dataset(dataset_id_or_path, ...)
train_dataset = EncodePreprocessor(template=template)(train_dataset, num_proc=num_proc)
val_dataset = EncodePreprocessor(template=template)(val_dataset, num_proc=num_proc)
# 训练模型
training_args = Seq2SeqTrainingArguments(...)
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
template=template,
train_dataset=train_dataset,
eval_dataset=val_dataset,
)
trainer.train()
```
推理:
```
from swift import TransformersEngine, InferRequest, RequestConfig
# 使用原生 Transformers 引擎执行推理
engine = TransformersEngine(model_id_or_path, adapters=[lora_checkpoint])
infer_request = InferRequest(messages=[{'role': 'user', 'content': 'who are you?'}])
request_config = RequestConfig(max_tokens=max_new_tokens, temperature=temperature)
resp_list = engine.infer([infer_request], request_config)
print(f'response: {resp_list[0].choices[0].message.content}')
```
## ✨ 使用
以下是使用 ms-swift 从训练到部署的最简示例。有关更多详细信息,您可以查看[示例](https://github.com/modelscope/ms-swift/tree/main/examples)。
- 如果您想使用其他模型或数据集(包括多模态模型和数据集),只需修改 `--model` 以指定相应模型的 ID 或路径,并修改 `--dataset` 以指定相应数据集的 ID 或路径。
- 默认情况下,使用 ModelScope 下载模型和数据集。如果您想使用 HuggingFace,只需指定 `--use_hf true`。
| 实用链接 |
| ------ |
| [🔥命令行参数](https://swift.readthedocs.io/en/latest/Instruction/Command-line-parameters.html) |
| [Megatron-SWIFT](https://swift.readthedocs.io/en/latest/Megatron-SWIFT/Quick-start.html) |
| [GRPO](https://swift.readthedocs.io/en/latest/Instruction/GRPO/GetStarted/GRPO.html) |
| [支持的模型和数据集](https://swift.readthedocs.io/en/latest/Instruction/Supported-models-and-datasets.html) |
| [自定义模型](https://swift.readthedocs.io/en/latest/Customization/Custom-model.html),[🔥自定义数据集](https://swift.readthedocs.io/en/latest/Customization/Custom-dataset.html) |
| [大模型教程](https://github.com/modelscope/modelscope-classroom/tree/main/LLM-tutorial) |
### 训练
支持的训练方法:
| 方法 | 全参数 | LoRA | QLoRA | Deepspeed | 多机 | 多模态 |
| ------------------------------------------------------------ | ------------------------------------------------------------ | ---- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
| [预训练](https://github.com/modelscope/ms-swift/blob/main/examples/train/pretrain) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| [监督微调](https://github.com/modelscope/ms-swift/blob/main/examples/train/lora_sft.sh) | [✅](https://github.com/modelscope/ms-swift/blob/main/examples/train/full/train.sh) | ✅ | [✅](https://github.com/modelscope/ms-swift/tree/main/examples/train/qlora) | [✅](https://github.com/modelscope/ms-swift/tree/main/examples/train/multi-gpu/deepspeed) | [✅](https://github.com/modelscope/ms-swift/tree/main/examples/train/multi-node) | [✅](https://github.com/modelscope/ms-swift/tree/main/examples/train/multimodal) |
| [GRPO](https://github.com/modelscope/ms-swift/blob/main/examples/train/grpo) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| [GKD](https://github.com/modelscope/ms-swift/blob/main/examples/train/rlhf/gkd) | ✅ | ✅ | ✅ | ✅ | ✅ | [✅](https://github.com/modelscope/ms-swift/blob/main/examples/train/multimodal/rlhf/gkd) |
| [PPO](https://github.com/modelscope/ms-swift/blob/main/examples/train/rlhf/ppo) | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
| [DPO](https://github.com/modelscope/ms-swift/blob/main/examples/train/rlhf/dpo) | ✅ | ✅ | ✅ | ✅ | ✅ | [✅](https://github.com/modelscope/ms-swift/blob/main/examples/train/multimodal/rlhf/dpo) |
| [KTO](https://github.com/modelscope/ms-swift/blob/main/examples/train/rlhf/kto.sh) | ✅ | ✅ | ✅ | ✅ | ✅ | [✅](https://github.com/modelscope/ms-swift/blob/main/examples/train/multimodal/rlhf/kto.sh) |
| [奖励模型](https://github.com/modelscope/ms-swift/blob/main/examples/train/rlhf/rm.sh) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| [CPO](https://github.com/modelscope/ms-swift/blob/main/examples/train/rlhf/cpo.sh) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| [SimPO](https://github.com/modelscope/ms-swift/blob/main/examples/train/rlhf/simpo.sh) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| [ORPO](https://github.com/modelscope/ms-swift/blob/main/examples/train/rlhf/orpo.sh) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| [Embedding](https://github.com/modelscope/ms-swift/blob/main/examples/train/embedding) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| [Reranker](https://github.com/modelscope/ms-swift/tree/main/examples/train/reranker) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| [序列分类](https://github.com/modelscope/ms-swift/blob/main/examples/train/seq_cls) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
预训练:
```
# 8*A100
NPROC_PER_NODE=8 \
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \
swift pt \
--model Qwen/Qwen3-4B-Base \
--dataset swift/chinese-c4 \
--streaming true \
--tuner_type full \
--deepspeed zero2 \
--output_dir output \
--max_steps 10000 \
...
```
微调:
```
CUDA_VISIBLE_DEVICES=0 swift sft \
--model Qwen/Qwen3-4B-Instruct-2507 \
--dataset AI-ModelScope/alpaca-gpt4-data-en \
--tuner_type lora \
--output_dir output \
...
```
RLHF:
```
CUDA_VISIBLE_DEVICES=0 swift rlhf \
--rlhf_type dpo \
--model Qwen/Qwen3-4B-Instruct-2507 \
--dataset hjh0119/shareAI-Llama3-DPO-zh-en-emoji \
--tuner_type lora \
--output_dir output \
...
```
### Megatron-SWIFT
ms-swift 支持使用 Megatron 并行技术加速训练,包括大规模集群训练和 MoE 模型训练。支持以下训练方法:
| 方法 | 全参数 | LoRA | MoE | 多模态 | FP8 |
| ---------------------- | -------------- | ---- | ---- | ---------- | ---- |
| 预训练 | ✅ | ✅ | ✅ | ✅ | ✅ |
| [监督微调](https://github.com/modelscope/ms-swift/tree/main/examples/megatron) | ✅ | ✅ | ✅ | ✅ | ✅ |
| [GRPO](https://github.com/modelscope/ms-swift/tree/main/examples/megatron/grpo) | ✅ | ✅ | ✅ | ✅ | ✅ |
| [GKD](https://github.com/modelscope/ms-swift/tree/main/examples/megatron/rlhf/gkd) | ✅ | ✅ | ✅ | ✅ | ✅ |
| [DPO](https://github.com/modelscope/ms-swift/tree/main/examples/megatron/rlhf/dpo) | ✅ | ✅ | ✅ | ✅ | ✅ |
| [KTO](https://github.com/modelscope/ms-swift/tree/main/examples/megatron/rlhf/kto) | ✅ | ✅ | ✅ | ✅ | ✅ |
| [RM](https://github.com/modelscope/ms-swift/tree/main/examples/megatron/rlhf/rm) | ✅ | ✅ | ✅ | ✅ | ✅ |
| [Embedding](https://github.com/modelscope/ms-swift/tree/main/examples/megatron/embedding) | ✅ | ✅| ✅ | ✅ | ✅ |
| [Reranker](https://github.com/modelscope/ms-swift/tree/main/examples/megatron/reranker) | ✅ | ✅| ✅ | ✅ | ✅ |
| [序列分类](https://github.com/modelscope/ms-swift/tree/main/examples/megatron/seq_cls) | ✅ | ✅ | ✅ | ✅ | ✅ |
```
NPROC_PER_NODE=2 CUDA_VISIBLE_DEVICES=0,1 megatron sft \
--model Qwen/Qwen3-4B-Instruct-2507 \
--save_safetensors true \
--dataset AI-ModelScope/alpaca-gpt4-data-zh \
--tuner_type lora \
--output_dir output \
...
```
### 强化学习
ms-swift 支持丰富的 GRPO 算法族:
| 方法 | 全参数 | LoRA | 多模态 | 多机 |
| ------------------------------------------------------------ | -------------- | ---- | ---------- | ------------- |
| [GRPO](https://swift.readthedocs.io/en/latest/Instruction/GRPO/GetStarted/GRPO.html) | ✅ | ✅ | ✅ | ✅ |
| [DAPO](https://swift.readthedocs.io/en/latest/Instruction/GRPO/AdvancedResearch/DAPO.html) | ✅ | ✅ | ✅ | ✅ |
| [GSPO](https://swift.readthedocs.io/en/latest/Instruction/GRPO/AdvancedResearch/GSPO.html) | ✅ | ✅ | ✅ | ✅ |
| [SAPO](https://swift.readthedocs.io/en/latest/Instruction/GRPO/AdvancedResearch/SAPO.html) | ✅ | ✅ | ✅ | ✅ |
| [CISPO](https://swift.readthedocs.io/en/latest/Instruction/GRPO/AdvancedResearch/CISPO.html) | ✅ | ✅ | ✅ | ✅ |
| [CHORD](https://swift.readthedocs.io/en/latest/Instruction/GRPO/AdvancedResearch/CHORD.html) | ✅ | ✅ | ✅ | ✅ |
| [RLOO](https://swift.readthedocs.io/en/latest/Instruction/GRPO/AdvancedResearch/RLOO.html) | ✅ | ✅ | ✅ | ✅ |
| [Reinforce++](https://swift.readthedocs.io/en/latest/Instruction/GRPO/AdvancedResearch/REINFORCEPP.html) | ✅ | ✅ | ✅ | ✅ |
```
CUDA_VISIBLE_DEVICES=0,1,2,3 NPROC_PER_NODE=4 \
swift rlhf \
--rlhf_type grpo \
--model Qwen/Qwen3-4B-Instruct-2507 \
--tuner_type lora \
--use_vllm true \
--vllm_mode colocate \
--dataset AI-MO/NuminaMath-TIR#10000 \
--output_dir output \
...
```
### 推理
```
CUDA_VISIBLE_DEVICES=0 swift infer \
--model Qwen/Qwen3-4B-Instruct-2507 \
--stream true \
--infer_backend transformers \
--max_new_tokens 2048
```
### 接口推理
```
CUDA_VISIBLE_DEVICES=0 swift app \
--model Qwen/Qwen3-4B-Instruct-2507 \
--stream true \
--infer_backend transformers \
--max_new_tokens 2048
```
### 部署
```
CUDA_VISIBLE_DEVICES=0 swift deploy \
--model Qwen/Qwen3-4B-Instruct-2507 \
--infer_backend vllm
```
### 采样
```
CUDA_VISIBLE_DEVICES=0 swift sample \
--model Qwen/Qwen3-4B-Instruct-2507 \
--sampler_engine transformers \
--num_return_sequences 5 \
--dataset AI-ModelScope/alpaca-gpt4-data-zh#5
```
### 评测
```
CUDA_VISIBLE_DEVICES=0 swift eval \
--model Qwen/Qwen3-4B-Instruct-2507 \
--infer_backend sglang \
--eval_backend OpenCompass \
--eval_dataset ARC_c
```
### 量化
```
CUDA_VISIBLE_DEVICES=0 swift export \
--model Qwen/Qwen3-4B-Instruct-2507 \
--quant_method fp8 \
--dataset AI-ModelScope/alpaca-gpt4-data-zh \
--output_dir Qwen3-4B-Instruct-2507-FP8
```
### 推送模型
```
swift export \
--model \
--push_to_hub true \
--hub_model_id '' \
--hub_token ''
```
## 🏛 许可证
本框架采用 [Apache License (Version 2.0)](https://github.com/modelscope/ms-swift/blob/master/LICENSE) 授权。对于模型和数据集,请参考原始资源页面并遵循相应的 License。
## 📎 引用
```
@misc{zhao2024swiftascalablelightweightinfrastructure,
title={SWIFT:A Scalable lightWeight Infrastructure for Fine-Tuning},
author={Yuze Zhao and Jintao Huang and Jinghan Hu and Xingjun Wang and Yunlin Mao and Daoze Zhang and Zeyinzi Jiang and Zhikai Wu and Baole Ai and Ang Wang and Wenmeng Zhou and Yingda Chen},
year={2024},
eprint={2408.05517},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2408.05517},
}
```
## Star History
[](https://star-history.com/#modelscope/ms-swift&Date)

ModelScope Community Website
中文 | English
![]()
![]()
![]()
![]()

![]()
更多
- 🎁 2025.06.11: 支持使用 Megatron 并行技术进行 RLHF 训练。训练脚本可以在[这里](https://github.com/modelscope/ms-swift/tree/main/examples/megatron/rlhf)找到。 - 🎁 2025.05.29: 在 pretrain、sft、dpo 和 grpo 中支持序列并行,查看脚本在[这里](https://github.com/modelscope/ms-swift/tree/main/examples/train/sequence_parallel)。 - 🎁 2025.05.11: GRPO 现已支持为奖励模型自定义处理逻辑。请查看[这里](./docs/source_en/Instruction/GRPO/DeveloperGuide/reward_model.md)的 GenRM 示例。 - 🎁 2025.04.15: ms-swift 论文已被 AAAI 2025 接收。您可以在[此链接](https://ojs.aaai.org/index.php/AAAI/article/view/35383)找到该论文。 - 🎁 2025.03.23: 现已支持多轮 GRPO,用于训练多轮对话场景(例如 Agent 工具调用)。请参阅[文档](./docs/source_en/Instruction/GRPO/DeveloperGuide/multi_turn.md)。 - 🎁 2025.03.16: 现已支持 Megatron 的并行训练技术。请查看[Megatron-SWIFT 训练文档](https://swift.readthedocs.io/en/latest/Megatron-SWIFT/Quick-start.html)。 - 🎁 2025.03.15: 支持纯文本和多模态模型的 embedding 模型微调。请查看[训练脚本](examples/train/embedding)。 - 🎁 2025.03.05: 支持 GRPO 的混合模式,在[这里](examples/train/grpo/internal/vllm_72b_4gpu.sh)提供了在 4 张 GPU(4*80G)上训练 72B 模型的脚本。同时支持使用 vllm 进行 tensor parallelism,训练脚本可在[这里](examples/train/grpo/internal)获取。 - 🎁 2025.02.21: GRPO 算法现已支持 LMDeploy,训练脚本可在[这里](examples/train/grpo/internal/full_lmdeploy.sh)获取。此外,我们对 GRPO 算法的性能进行了测试,使用各种技巧实现了高达 300% 的训练速度提升。请在此处查看 WanDB 表格[这里](https://wandb.ai/tastelikefeet/grpo_perf_test?nw=nwuseryuzezyz)。 - 🎁 2025.02.21: 现已支持 `swift sample` 命令。强化微调脚本可在[这里](docs/source_en/Instruction/Reinforced-Fine-tuning.md)找到,大模型 API 蒸馏采样脚本可在[这里](examples/sampler/distill/distill.sh)获取。 - 🔥 2025.02.12: 新增对 GRPO(Group Relative Policy Optimization)训练算法的支持。文档可在[这里](docs/source_en/Instruction/GRPO/GetStarted/GRPO.md)获取。 - 🎁 2024.12.04: **ms-swift 3.0** 重大更新。请参考[发布说明与变更](docs/source_en/Instruction/ReleaseNote3.0.md)。 - 🎉 2024.08.12: ms-swift 论文已在 arXiv 上发表,可在[此处](https://arxiv.org/abs/2408.05517)阅读。 - 🔥 2024.08.05: 支持使用 [evalscope](https://github.com/modelscope/evalscope/) 作为大模型和多模态模型的评测后端。 - 🔥 2024.07.29: 支持使用 [vllm](https://github.com/vllm-project/vllm) 和 [lmdeploy](https://github.com/InternLM/lmdeploy) 加速大模型和多模态模型的推理。在进行 infer/deploy/eval 时,可以指定 `--infer_backend vllm/lmdeploy`。 - 🔥 2024.07.24: 支持多模态大模型的人类偏好对齐训练,包括 DPO/ORPO/SimPO/CPO/KTO/RM/PPO。 - 🔥 2024.02.01: 支持 Agent 训练!训练算法源自[这篇论文](https://arxiv.org/pdf/2309.00986.pdf)。标签:DLL 劫持, ModelScope, PyTorch, 人工智能, 凭据扫描, 多模态模型, 大语言模型, 微调框架, 用户模式Hook绕过, 逆向工具