PadishahIII/RFGuess
GitHub: PadishahIII/RFGuess
基于随机森林机器学习算法的定向社工密码字典生成工具,利用目标用户个人身份信息训练模型并生成高命中率密码猜测。
Stars: 32 | Forks: 6
RFGuess(随机森林密码猜测模型)
# 概述
本仓库包含论文《[基于随机森林的密码猜测](https://www.usenix.org/conference/usenixsecurity23/presentation/wang-ding-password-guessing)》的复现。作者提出了一系列新方法,将 PII(个人身份信息)数据转换为在经典机器学习模型中表现优异的结构。
我已经实现了论文的核心概念,并编写了一个易于使用的工具,用于训练模型、生成模式、进行猜测和评估准确率。本仓库的贡献包括:
- 一个专为基于 PII 的定向密码猜测场景设计的 GUI 程序
- 一个预训练模型
如果您想了解更多关于该项目底层逻辑和训练过程的知识,[这篇文章](https://www.wolai.com/secnote/aL4Xth452sX4XuSydnpqtj)提供了有关算法的更多细节,相应的演讲稿可以在[这里](https://www.wolai.com/secnote/row4spm7VvaYAkUmxsFQBT)找到。
有关系统设计和实现细节,请查看 [DeepWiki 链接](https://deepwiki.com/PadishahIII/RFGuess/1-overview)。
# 目录
- [概述](#overview)
- [功能](#features)
- [前置条件](#prerequisites)
- [用法](#usage)
* [主窗口](#main-window)
* [生成模式](#generate-pattern-pattern-generator-)
* [生成密码字典](#generate-password-dictionary-guess-generator-)
* [训练你的专属模型](#train-your-own-model)
- [高级配置](#advanced-configuration)
- [从源码构建](#build-from-source)
- [许可证](#license)
- [联系方式](#contact)
- [致谢](#acknowledgements)
- [附录](#appendix)
* [模式格式](#pattern-format)
# 功能
- **基于 PII 的定向密码猜测**
- 提供基于 11 万条数据训练的预训练模型(在[此处](https://github.com/PadishahIII/RFGuess/releases/download/v1.1/model.clf)获取),开箱即用
- 基于 PII 数据集生成密码模式
- 根据给定的个人信息进行密码猜测
- 支持为自定义数据集训练指定模型
- 支持评估所生成猜测的准确率
# 前置条件
- Python3
- Mysql 8.0.32
- Sklearn
点击此处
- PyQt5
点击此处
# 安装与启动
将本仓库克隆到本地。
推荐使用 `uv`:
```
uv sync
uv run python main.py
```
或者使用 `pip` 安装依赖:
```
pip install -r requirements.txt
python main.py
```
本项目使用 Mysql 存储分析数据,推荐通过 docker 启动预先配置好的数据库:
```
docker-compose up -d
```
然后连接到 `mysql://root:root@127.0.0.1:3307/rfguess`。
如果您希望使用自定义数据库,则需要手动将 `user.sql` 导入到您的数据库中,这将创建所有的数据表。
# 用法
- [主窗口](#main-window)
- [生成模式](#generate-patternpattern-generator)
- [生成密码字典](#generate-password-dictionaryguess-generator)
- [训练你的专属模型](#train-your-own-model)
## 主窗口
运行可执行文件,您将看到如下面板:
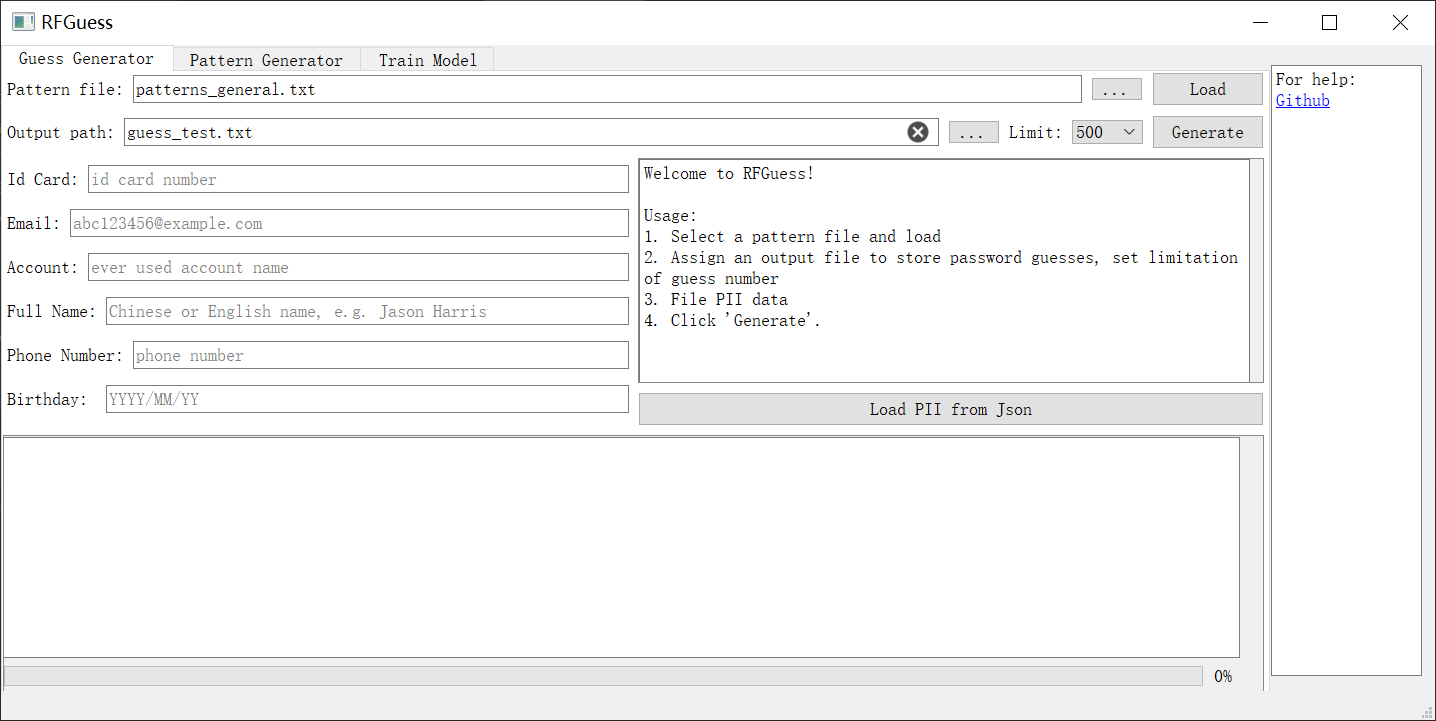
用户界面包含三个主要模块:Guess-Generator、Pattern-Generator 和 Model-Trainner。
## 生成模式(Pattern-Generator)
首先您需要获取一个训练好的模型(无论是通过 [model-trainner](#train-your-own-model) 自行训练,还是使用来自 [rfguess.clf](https://github.com/PadishahIII/RFGuess/releases/download/v1.1/model.clf) 的预训练模型)。
然后设置要生成的模式数量限制并开始生成。
1. 加载模型(.clf)
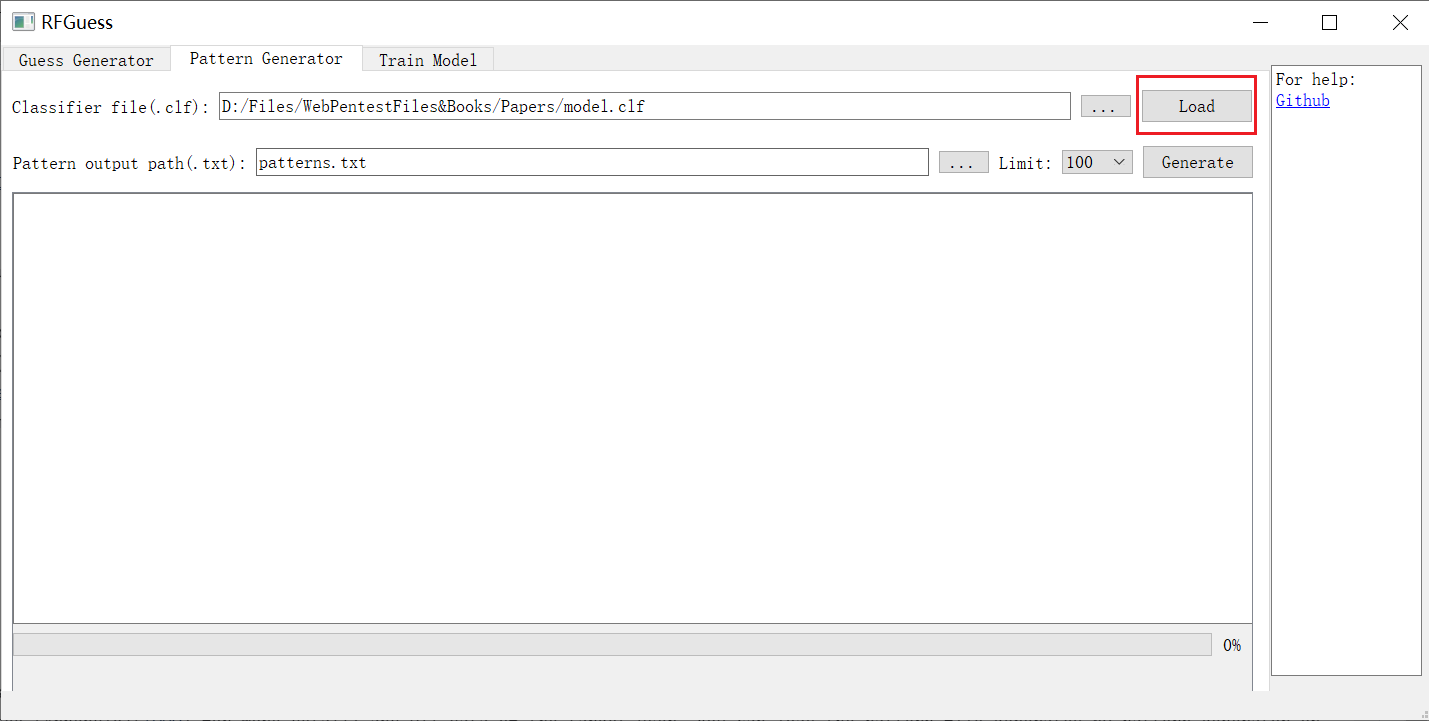
2. 指定输出路径和限制
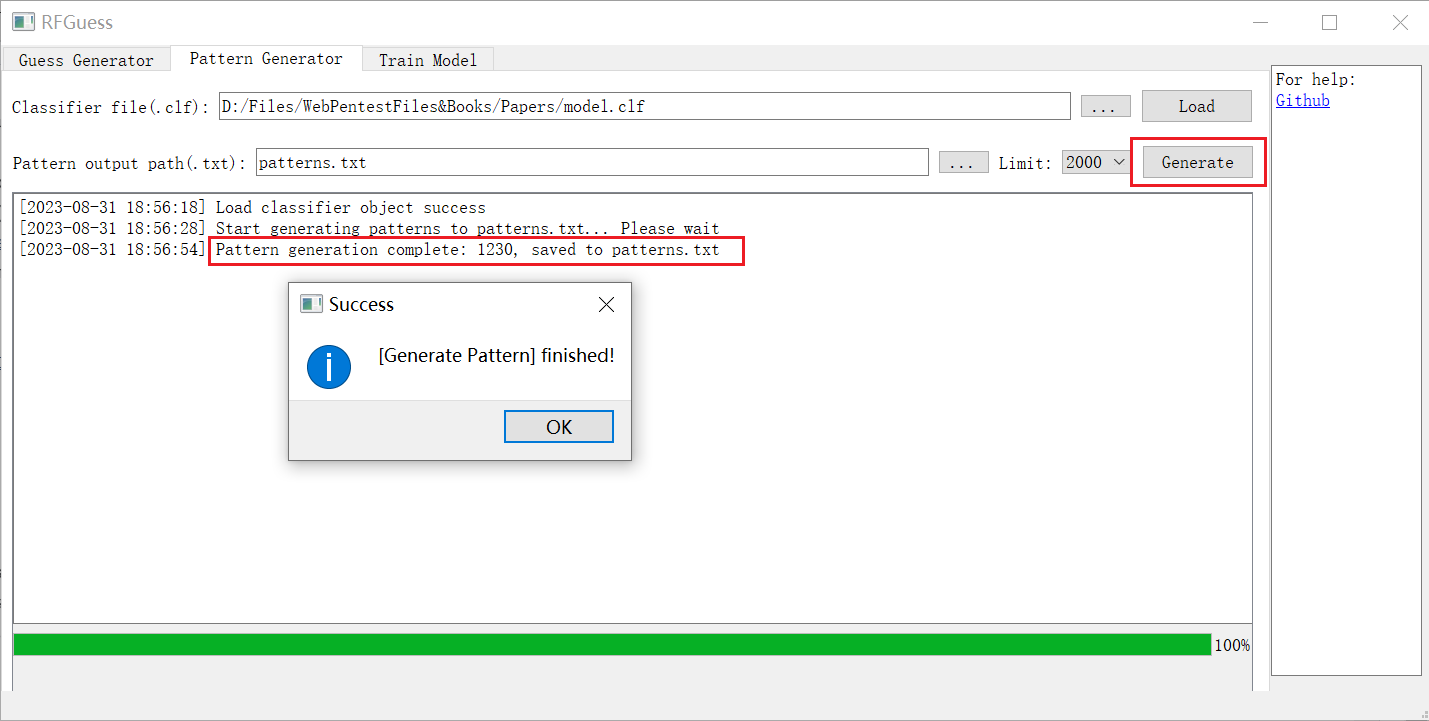
## 生成密码字典(Guess-Generator)
该模块需要一个模式文件(详见[附录](#appendix))和目标用户的 PII 数据。您可以加载由 Pattern-Generator 生成的模式文件,或使用[默认模式文件](https://github.com/PadishahIII/RFGuess/releases/download/v1.1/patterns.txt)。
1. 加载模式文件
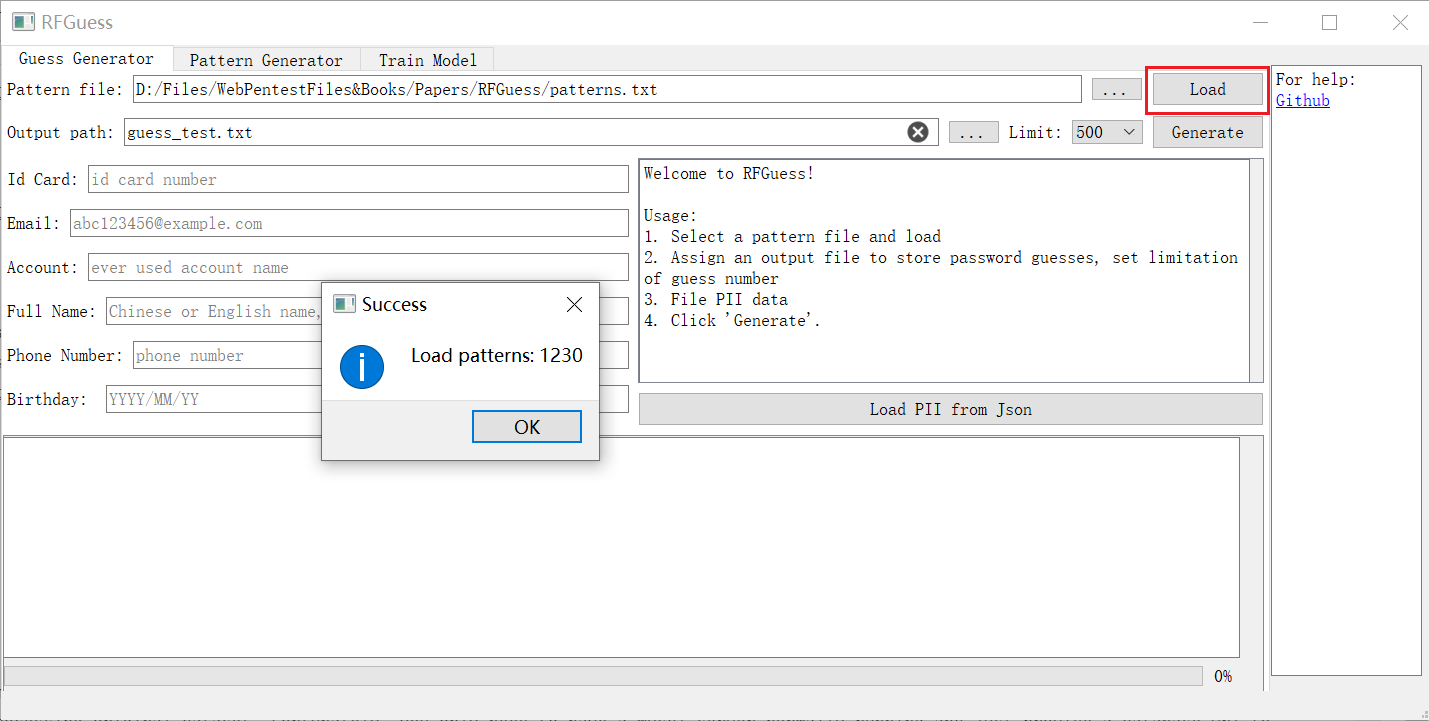
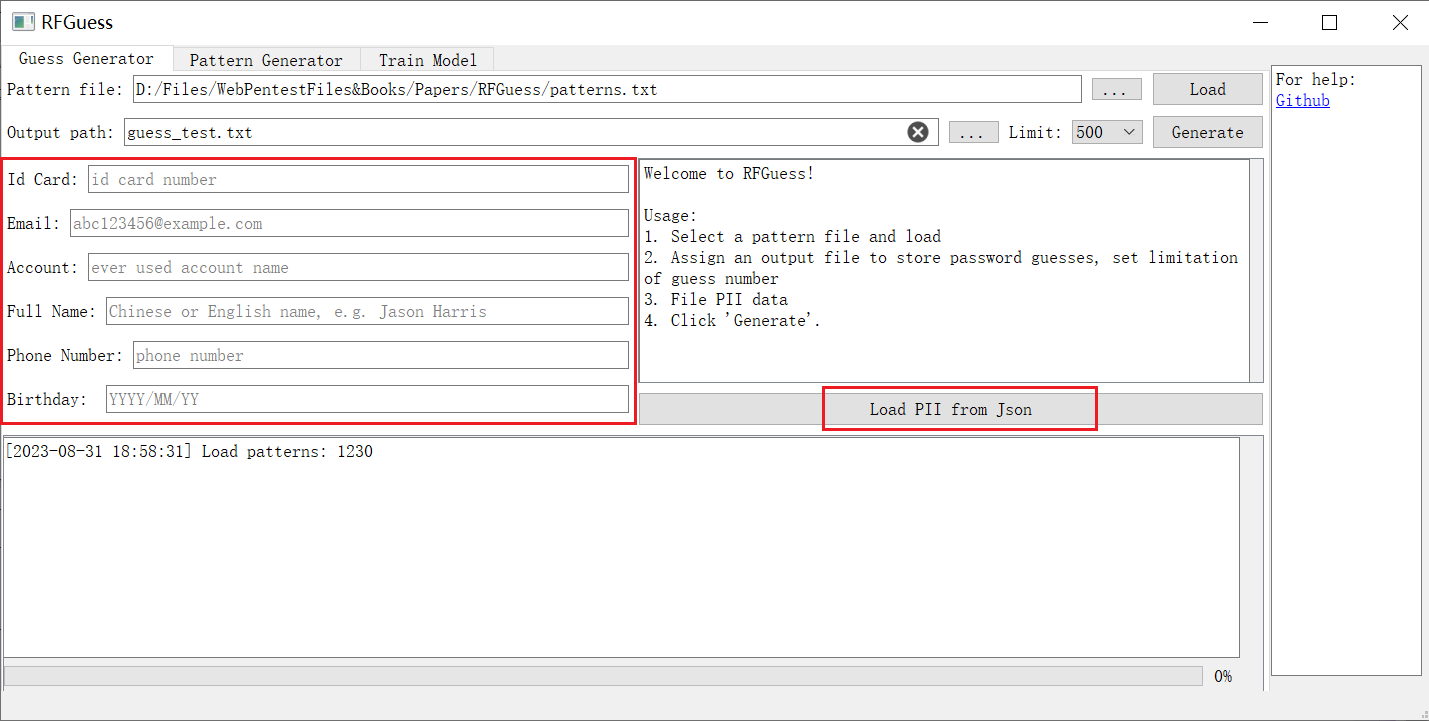
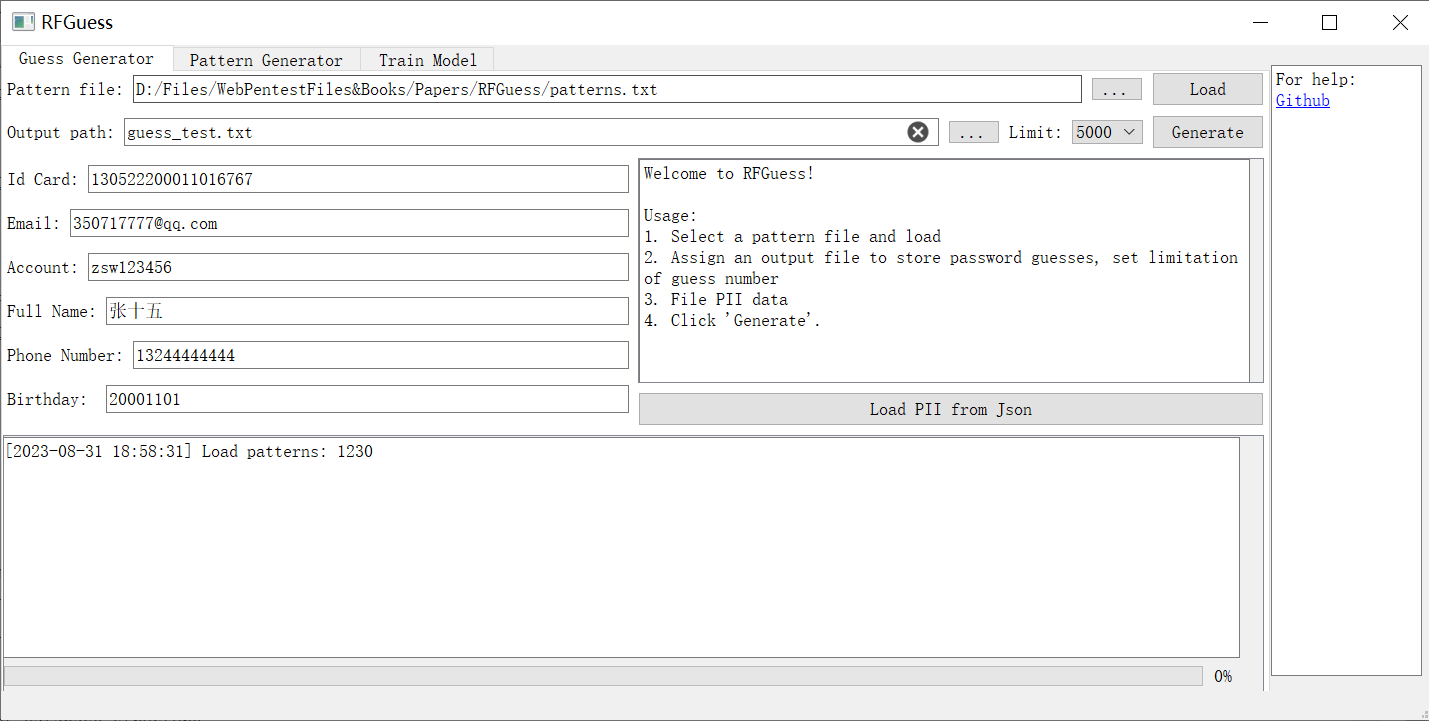
2. 填写 PII 数据
输入目标用户的个人数据或从 json 文件加载数据([格式](https://github.com/PadishahIII/RFGuess/blob/v1.1/pii.json))
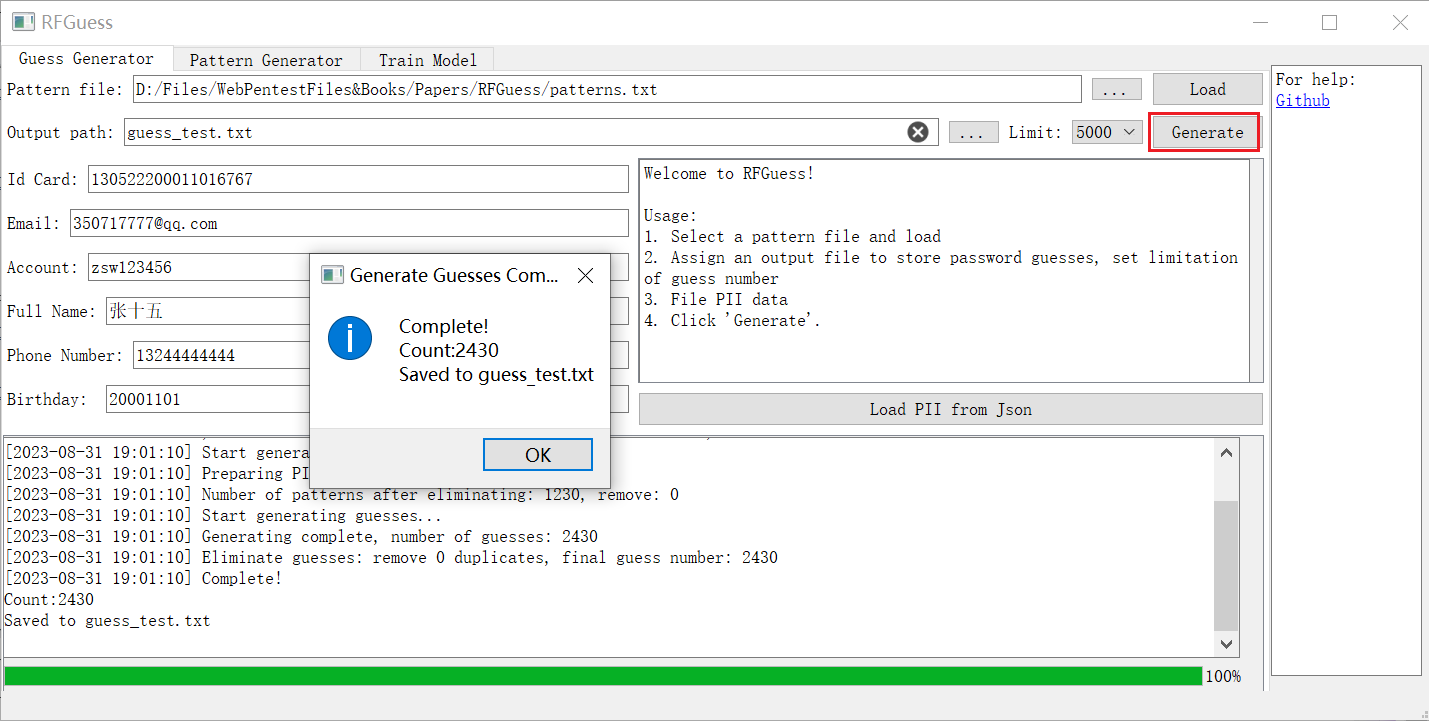
3. 生成密码字典
## 训练你的专属模型
与深度学习相比,机器学习的模型训练过程要繁琐得多。本程序中的算法需要使用 mysql 数据库来存储处理原始数据集时的中间数据结构。幸运的是,您只需要一个正常运行的 mysql 服务器并提供一个数据库连接 URL 即可。所有数据结构都会自动配置。
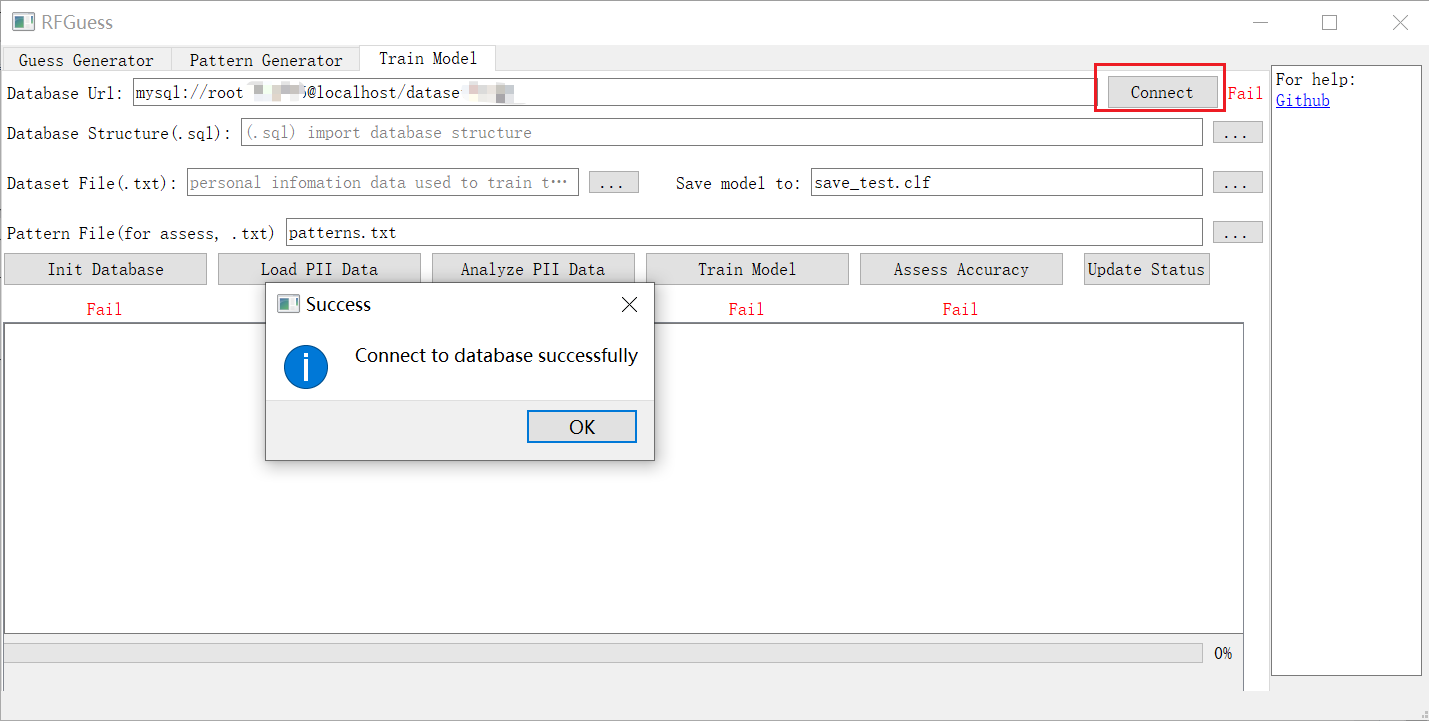
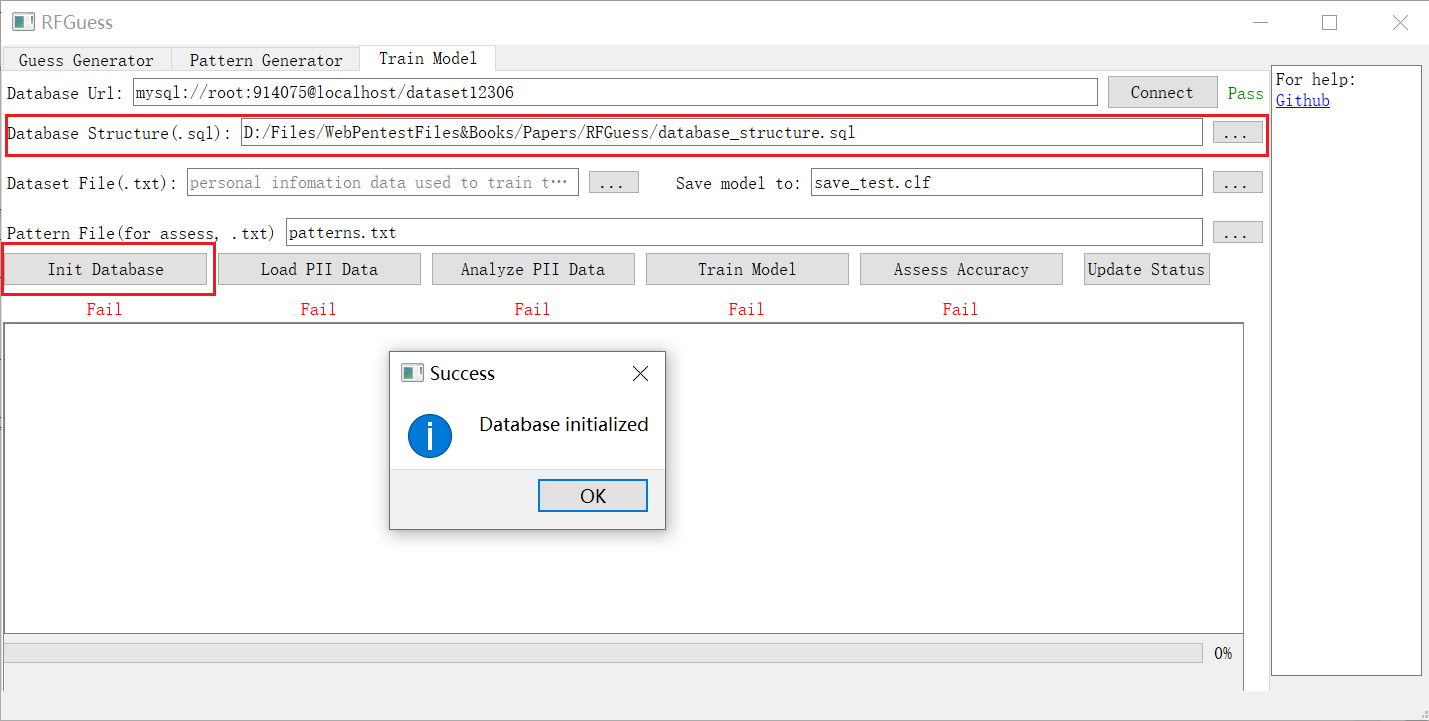
1. 连接到您的数据库并导入数据库结构
连接到数据库 URL:
导入 sql 文件(在[此处](https://github.com/PadishahIII/RFGuess/blob/v1.1/database_structure.sql)获取)。**请注意,此脚本将删除并重新创建正在使用的数据表(您可以在 `Parse/Config.py` 中查看并修改表名)。**
如果您通过 docker-compose 启动 mysql 服务器(这是推荐的方式),`user.sql` 已在启动时导入,因此您可以跳过此步骤。
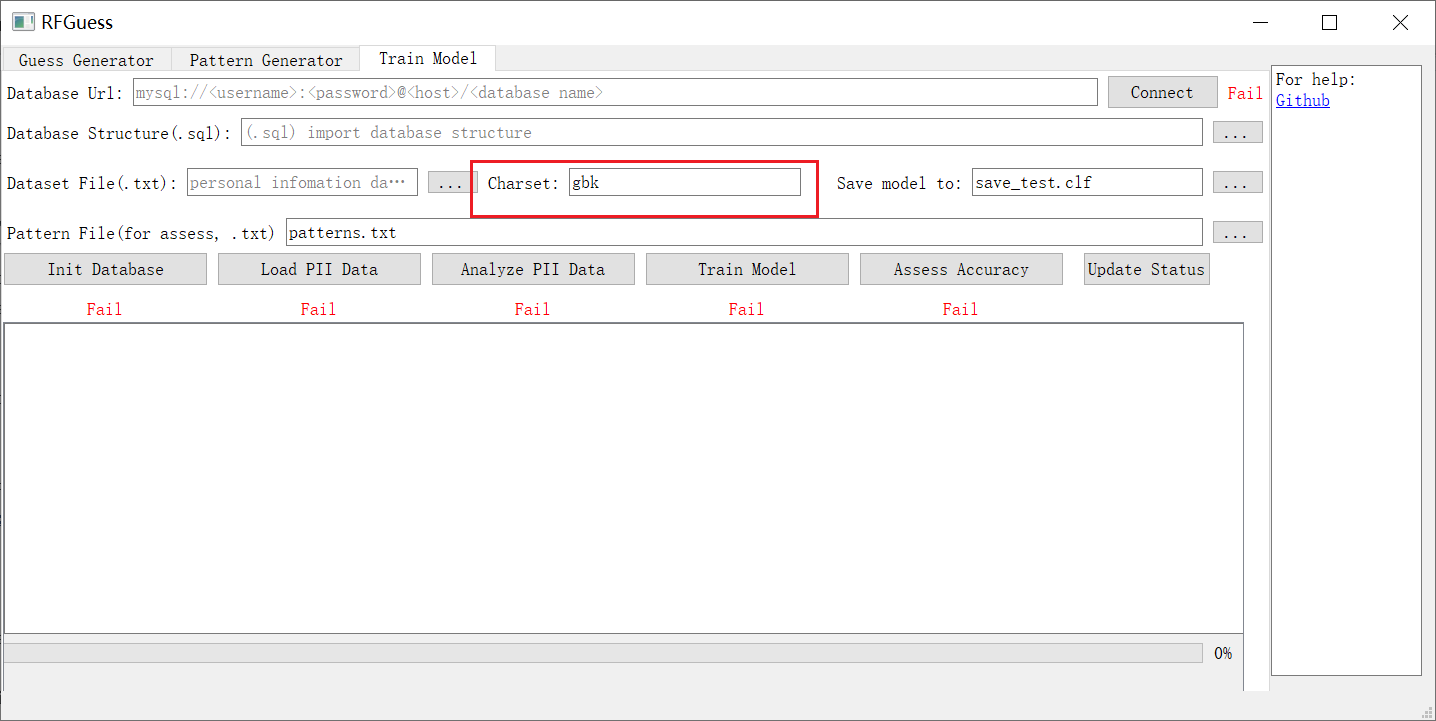
2. 加载您的 PII 数据集(.txt)
PII 数据集应为 csv 格式,并符合以下原则:
- 第一行表示字段名
- 字段名应包含在 ['account', 'name', 'phone', 'idcard', 'email', 'password'] 中,**不区分大小写**
- 您可以包含允许字段的任意组合,但 ***name*** 和 ***password*** 为必填项
- 每行包含一条 PII 数据
- 每行应包含多个字段,以逗号分隔
- 空白字符将被忽略
合法的数据集示例如下:
```
name, email, password, phone
张三, 350777@aa.com , zhangsan, 111122222
John, 3333@bb.com, 3333, 44444
Jason Harris, aaaa@aa.com, 5555, 5555
```
您可以通过 *Charset* 编辑框指定目标数据集的字符集。
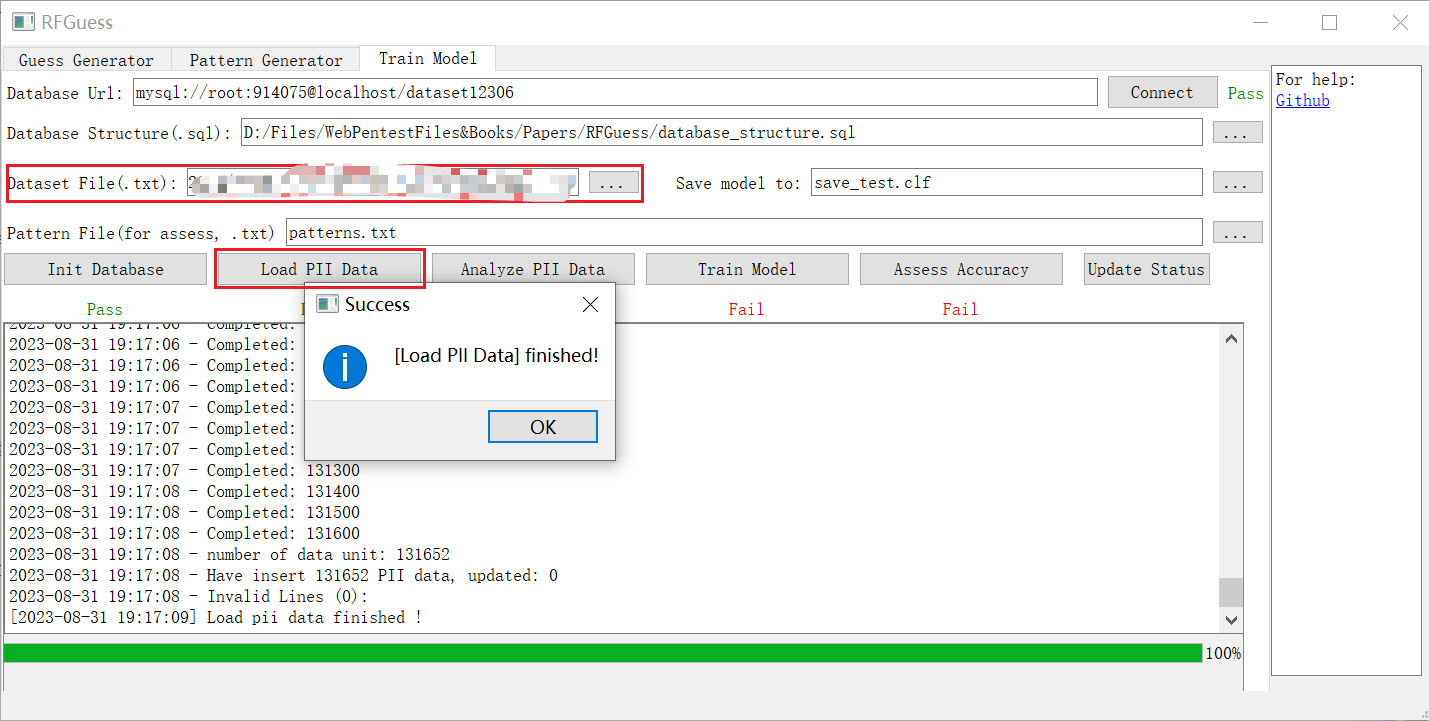
点击 *Load PII Data* 按钮并等待。您的数据集在经过一些处理后将被解析并存储在数据库中。
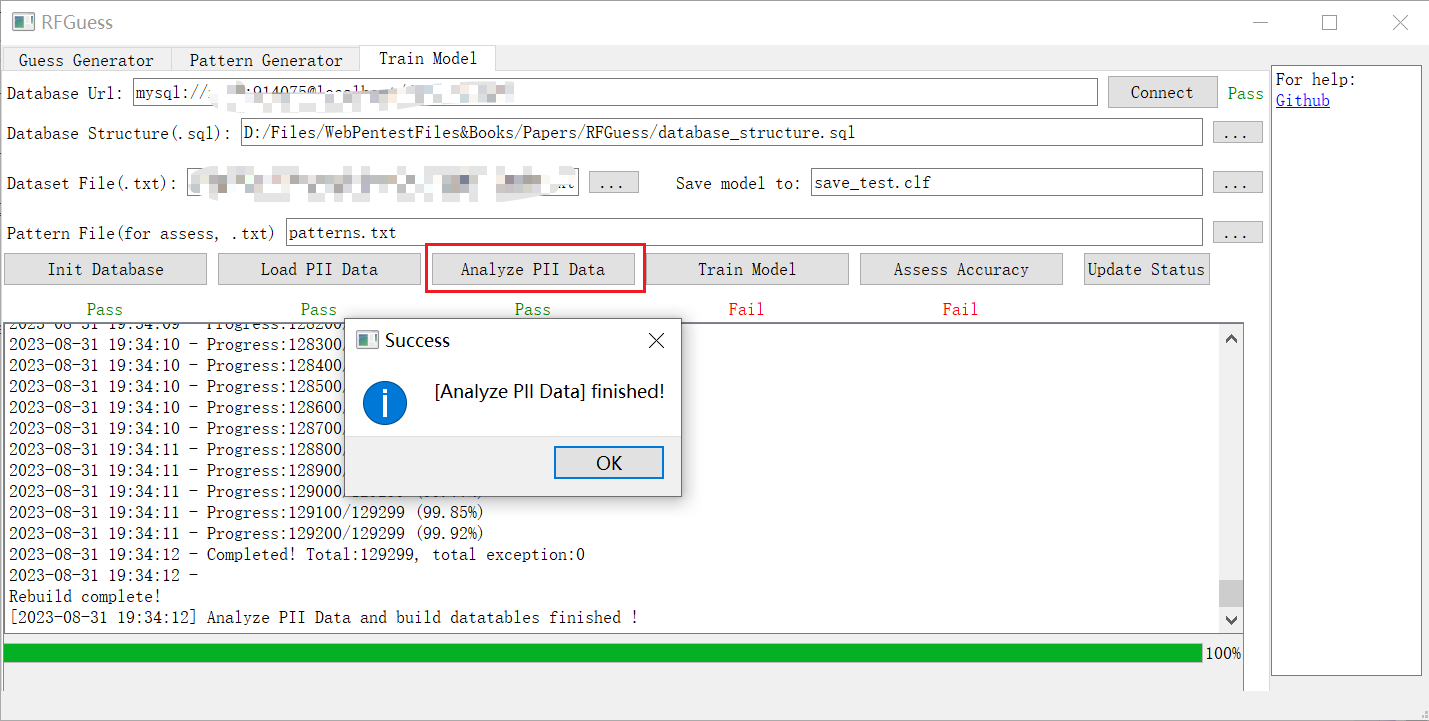
4. 分析和处理数据集
此步骤会将 PII 数据集分析为一些中间数据。
6. 训练模型
您将训练一个分类器模型并将其导出为 .clf 文件。
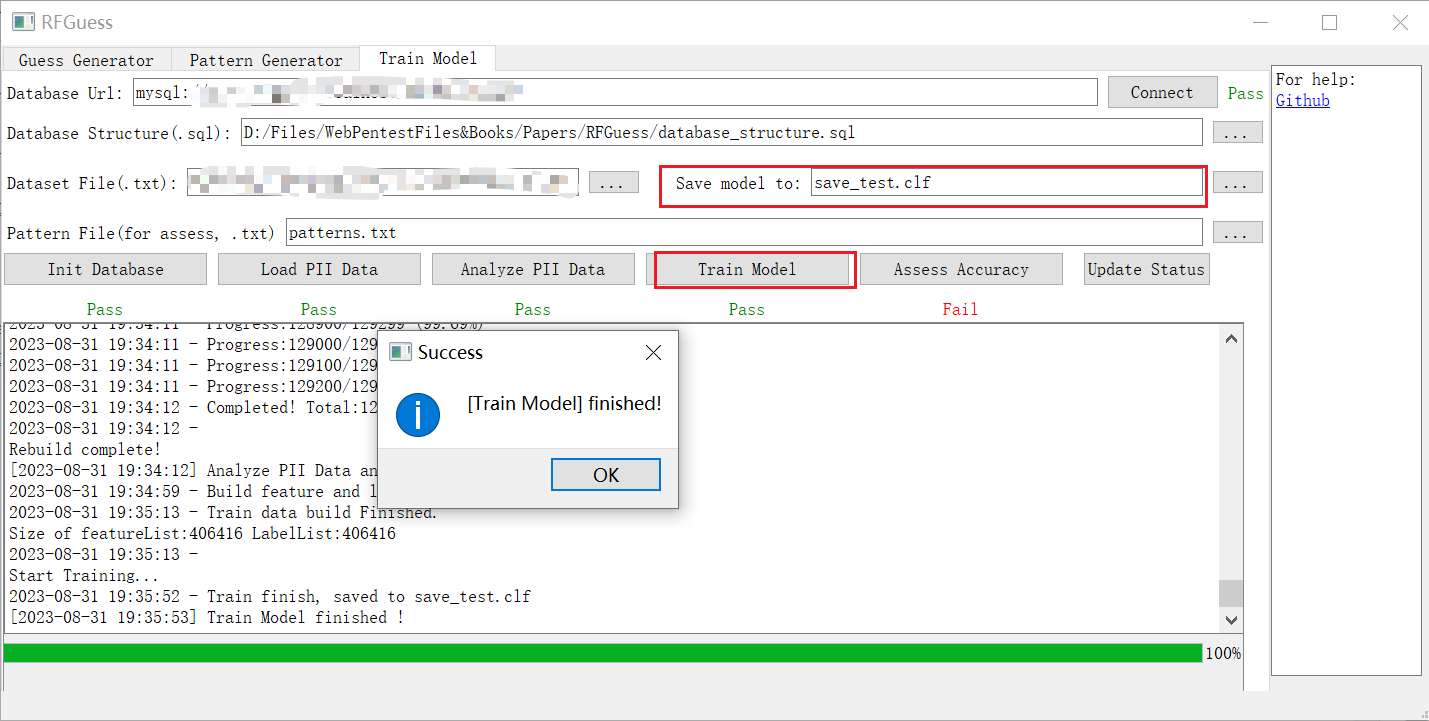
8. 评估准确率
为了评估模型的准确率,此步骤使用您数据集的 50% 作为训练集,另外 50% 作为测试集,为每条 PII 数据生成一个密码字典,并检查正确密码是否包含在该字典中。
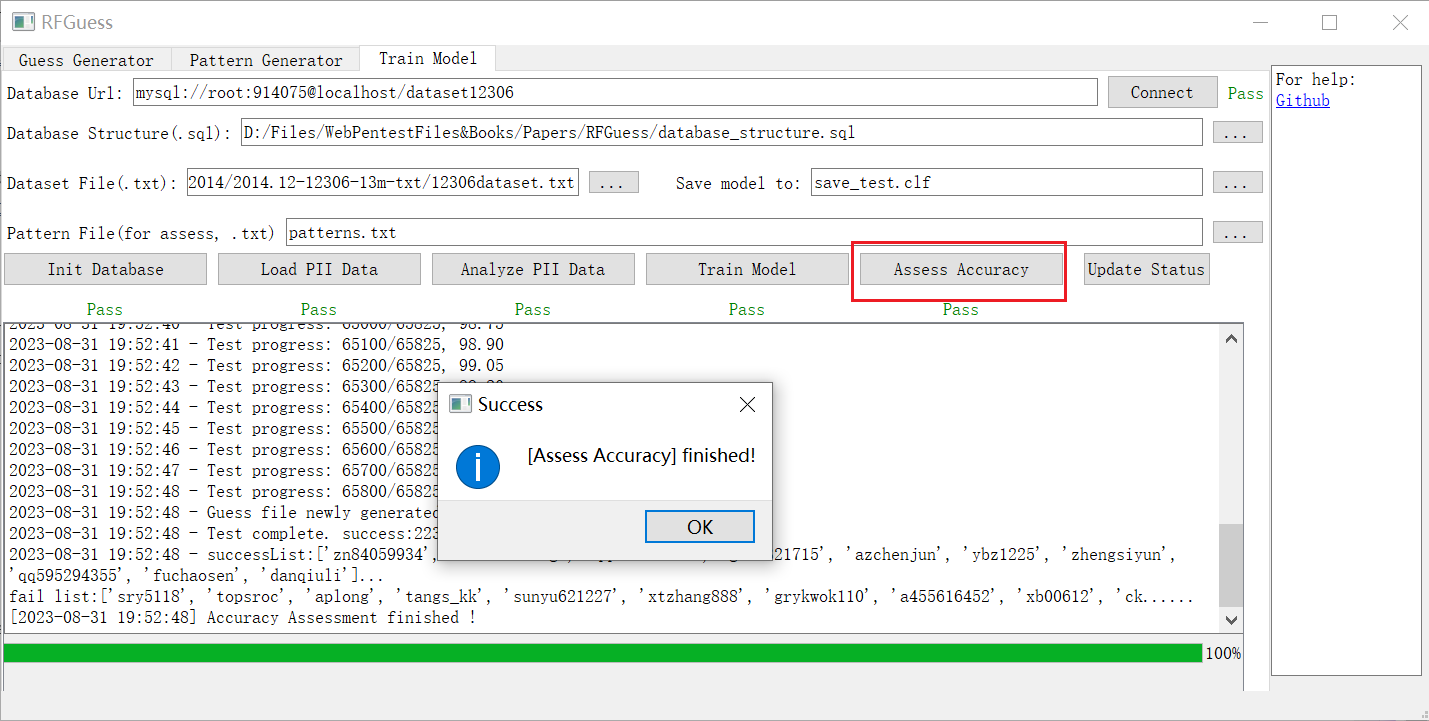
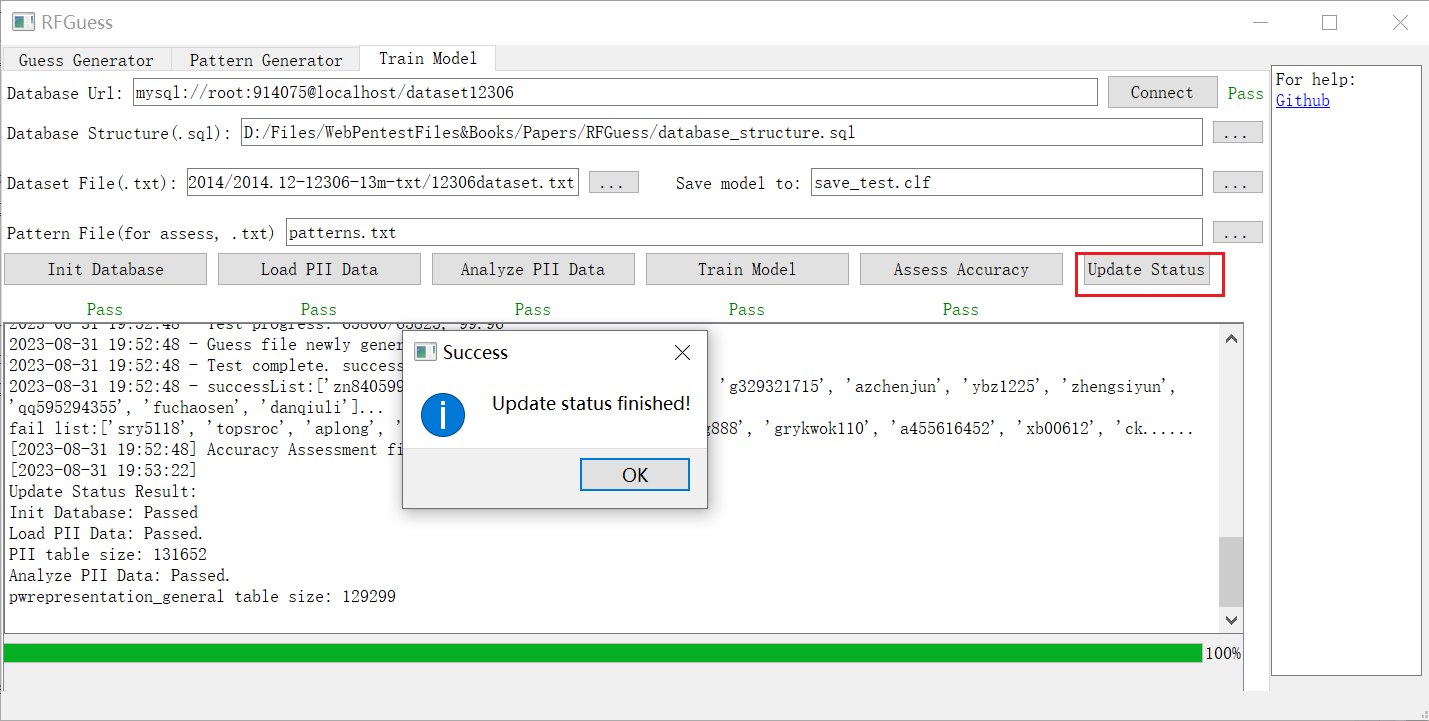
9. 恢复上次运行的状态
10.
使用 "Update Status" 按钮加载上次运行的进度,并检查各个阶段的状态。
# 高级配置
在 [Config.py](https://github.com/PadishahIII/RFGuess/blob/master/Parser/Config.py) 中查看更多详细配置。
**算法配置**
主算法中使用了 *Markov n-gram* 模型,您可以通过 *pii_order* 参数设置 *n*:
```
pii_order = 6
```
您可以通过以下两个阈值来控制猜测的数量限制,这些阈值是根据生长模式的可能性计算的。
只有当一种模式的可能性大于阈值时,才会被采用。因此,阈值越大,猜测数量越少,反之亦然。值得注意的是,您不应将阈值设置得过小(小于 *1e-11*),以避免被无用的模式淹没。
```
general_generator_threshold = 1.2e-8
```
**数据库配置**
您可以根据需要配置数据库的表名:
```
class TableNames:
PII = "PII"
pwrepresentation = "pwrepresentation"
representation_frequency = "representation_frequency"
pwrepresentation_frequency = "pwrepresentation_frequency"
pwrepresentation_unique = "pwrepresentation_unique"
pwrepresentation_general = f"{pwrepresentation}_general"
representation_frequency_base_general = f"representation_frequency_base_general"
representation_frequency_general = f"{representation_frequency}_general"
pwrepresentation_frequency_general = f"{pwrepresentation_frequency}_general"
pwrepresentation_unique_general = f"{pwrepresentation_unique}_general"
```
**分类器配置**
通过以下配置调整随机森林的参数:
```
class RFParams:
n_estimators = 30
criterion = 'gini'
min_samples_leaf = 10
max_features = 0.8
```
# 从源码构建
本项目使用 **Python3.11** 编写。推荐的设置使用 `uv`:
```
uv sync
uv run python main.py
```
如果您倾向于使用 `pip`,仍然可以通过以下命令安装依赖:
```
pip install -r requirements.txt
```
然后运行以下命令启动主窗口:
```
python main.py
```
# 许可证
此代码在 [MIT 许可证](https://github.com/PadishahIII/RFGuess/blob/master/LICENSE)下发布。您可以在此条款下自由使用、修改、分发或出售。
# 联系方式
- straystrayer@gmail.com
项目链接:[https://github.com/PadishahIII/RFGuess](https://github.com/PadishahIII/RFGuess)
# 致谢
- [基于随机森林的密码猜测](https://www.usenix.org/conference/usenixsecurity23/presentation/wang-ding-password-guessing)
# 附录
## 模式格式
| 标签 | 描述 |
|-----|--------------------------------------------------|
| N1 | 全名 |
| N2 | 姓名缩写 |
| N3 | 姓氏 |
| N4 | 名字 |
| N5 | 名字首字符加姓氏 |
| N6 | 姓氏首字符加名字 |
| N7 | 姓氏大写 |
| N8 | 姓氏首字符 |
| N9 | 名字缩写 |
| B1 | 生日 (YYYYMMDD 格式) |
| B2 | MMDDYYYY 格式 |
| B3 | DDMMYYYY 格式 |
| B4 | MMDD 格式 |
| B5 | YYYY 格式 |
| B6 | YYYYMM 格式 |
| B7 | MMYYYY 格式 |
| B8 | YYMMDD 格式 |
| B9 | MMDDYY 格式 |
| B10 | DDMMYY 格式 |
| A1 | 账户 |
| A2 | 账户的字母部分 |
| A3 | 账户的数字部分 |
| E1 | 邮箱前缀 |
| E2 | 邮箱的字母部分 |
| E3 | 邮箱的数字部分 |
| E4 | 邮箱站点,如 qq, 163 |
| P1 | 电话号码 |
| P2 | 电话号码前三位 |
| P3 | 电话号码后四位 |
| I1 | 身份证号 |
| I2 | 身份证号前三位 |
| I3 | 身份证号前六位 |
标签:Apex, BSD, DOS头擦除, PII, Python, VEH, 个人身份信息, 后端开发, 图形界面, 字典攻击, 密码安全, 密码猜测, 密码破解, 数据挖掘, 无后门, 机器学习, 社工字典, 网络安全, 请求拦截, 逆向工具, 随机森林, 随机森林模型, 隐私保护