rasbt/LLMs-from-scratch
GitHub: rasbt/LLMs-from-scratch
一本系统讲解如何用PyTorch从零构建类ChatGPT大语言模型的实战教程及配套代码仓库,覆盖数据处理、模型架构、预训练与微调全流程。
Stars: 99355 | Forks: 15249
# 构建大型语言模型(从零开始)
本仓库包含用于开发、预训练和微调类 GPT 大语言模型的代码,也是[《构建大型语言模型(从零开始)》](https://amzn.to/4fqvn0D)一书的官方代码仓库。

在[《构建大型语言模型(从零开始)》](http://mng.bz/orYv)一书中,你将通过从头开始逐步编写代码,从内到外学习并理解大语言模型(LLM)的工作原理。在本书中,我将引导你创建自己的 LLM,并通过清晰的文本、图表和示例来解释每个阶段。 本书中描述的、用于训练和开发你自己的小型但功能齐全的模型(出于教育目的)的方法,与创建大规模基础模型(如 ChatGPT 背后的模型)所使用的方法如出一辙。此外,本书还包含了加载较大预训练模型权重以进行微调的代码。 - 官方[源代码仓库](https://github.com/rasbt/LLMs-from-scratch)链接 - [Manning(出版社网站)上的图书链接](http://mng.bz/orYv) - [Amazon.com 上的图书页面链接](https://www.amazon.com/gp/product/1633437167) - ISBN 9781633437166
要下载此仓库的副本,请点击 [Download ZIP](https://github.com/rasbt/LLMs-from-scratch/archive/refs/heads/main.zip) 按钮或在你的终端中执行以下命令: ``` git clone --depth 1 https://github.com/rasbt/LLMs-from-scratch.git ```
(如果你是从 Manning 网站下载的代码包,建议访问 GitHub 上的官方代码仓库 [https://github.com/rasbt/LLMs-from-scratch](https://github.com/rasbt/LLMs-from-scratch) 以获取最新更新。)
# 目录 请注意,此 `README.md` 文件是一个 Markdown (`.md`) 文件。如果你是从 Manning 网站下载的此代码包并在本地计算机上查看,我建议使用 Markdown 编辑器或预览器以便正常浏览。如果你尚未安装 Markdown 编辑器,[Ghostwriter](https://ghostwriter.kde.org) 是一个不错的免费选项。 你也可以在浏览器中访问 GitHub 上的 [https://github.com/rasbt/LLMs-from-scratch](https://github.com/rasbt/LLMs-from-scratch) 来查看此文件及其他文件,GitHub 会自动渲染 Markdown。
[](https://github.com/rasbt/LLMs-from-scratch/actions/workflows/basic-tests-linux-uv.yml) [](https://github.com/rasbt/LLMs-from-scratch/actions/workflows/basic-tests-windows-uv-pip.yml) [](https://github.com/rasbt/LLMs-from-scratch/actions/workflows/basic-tests-macos-uv.yml) - [故障排除指南](./troubleshooting.md) | 章节标题 | 主要代码(便于快速访问) | 所有代码 + 补充材料 | |------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------|-------------------------------| | [设置建议](setup)
[如何更好地阅读本书](https://sebastianraschka.com/blog/2025/reading-books.html) | - | - | | 第 1 章:理解大型语言模型 | 无代码 | - | | 第 2 章:处理文本数据 | - [ch02.ipynb](ch02/01_main-chapter-code/ch02.ipynb)
- [dataloader.ipynb](ch02/01_main-chapter-code/dataloader.ipynb) (总结)
- [exercise-solutions.ipynb](ch02/01_main-chapter-code/exercise-solutions.ipynb) | [./ch02](./ch02) | | 第 3 章:编写注意力机制 | - [ch03.ipynb](ch03/01_main-chapter-code/ch03.ipynb)
- [multihead-attention.ipynb](ch03/01_main-chapter-code/multihead-attention.ipynb) (总结)
- [exercise-solutions.ipynb](ch03/01_main-chapter-code/exercise-solutions.ipynb)| [./ch03](./ch03) | | 第 4 章:从零开始实现 GPT 模型 | - [ch04.ipynb](ch04/01_main-chapter-code/ch04.ipynb)
- [gpt.py](ch04/01_main-chapter-code/gpt.py) (总结)
- [exercise-solutions.ipynb](ch04/01_main-chapter-code/exercise-solutions.ipynb) | [./ch04](./ch04) | | 第 5 章:在无标签数据上预训练 | - [ch05.ipynb](ch05/01_main-chapter-code/ch05.ipynb)
- [gpt_train.py](ch05/01_main-chapter-code/gpt_train.py) (总结)
- [gpt_generate.py](ch05/01_main-chapter-code/gpt_generate.py) (总结)
- [exercise-solutions.ipynb](ch05/01_main-chapter-code/exercise-solutions.ipynb) | [./ch05](./ch05) | | 第 6 章:微调文本分类 | - [ch06.ipynb](ch06/01_main-chapter-code/ch06.ipynb)
- [gpt_class_finetune.py](ch06/01_main-chapter-code/gpt_class_finetune.py)
- [exercise-solutions.ipynb](ch06/01_main-chapter-code/exercise-solutions.ipynb) | [./ch06](./ch06) | | 第 7 章:微调指令遵循 | - [ch07.ipynb](ch07/01_main-chapter-code/ch07.ipynb)
- [gpt_instruction_finetuning.py](ch07/01_main-chapter-code/gpt_instruction_finetuning.py) (总结)
- [ollama_evaluate.py](ch07/01_main-chapter-code/ollama_evaluate.py) (总结)
- [exercise-solutions.ipynb](ch07/01_main-chapter-code/exercise-solutions.ipynb) | [./ch07](./ch07) | | 附录 A:PyTorch 简介 | - [code-part1.ipynb](appendix-A/01_main-chapter-code/code-part1.ipynb)
- [code-part2.ipynb](appendix-A/01_main-chapter-code/code-part2.ipynb)
- [DDP-script.py](appendix-A/01_main-chapter-code/DDP-script.py)
- [exercise-solutions.ipynb](appendix-A/01_main-chapter-code/exercise-solutions.ipynb) | [./appendix-A](./appendix-A) | | 附录 B:参考文献与扩展阅读 | 无代码 | [./appendix-B](./appendix-B) | | 附录 C:练习题解答 | - [练习题解答列表](appendix-C) | [./appendix-C](./appendix-C) | | 附录 D:为训练循环添加扩展功能 | - [appendix-D.ipynb](appendix-D/01_main-chapter-code/appendix-D.ipynb) | [./appendix-D](./appendix-D) | | 附录 E:使用 LoRA 进行参数高效微调 | - [appendix-E.ipynb](appendix-E/01_main-chapter-code/appendix-E.ipynb) | [./appendix-E](./appendix-E) |
下面的思维导图总结了本书涵盖的内容。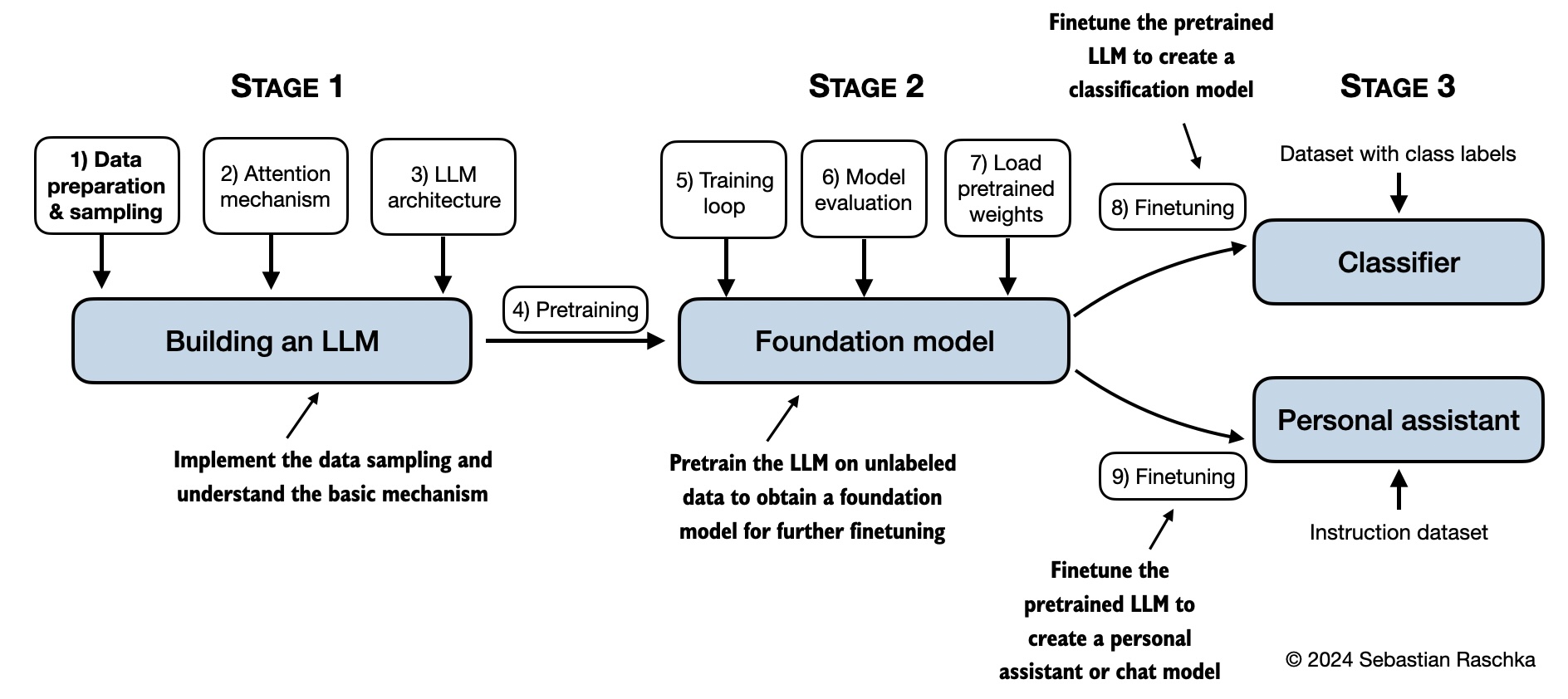
## 前置条件 最重要的前置条件是具备扎实的 Python 编程基础。 有了这些知识,你将为探索迷人的 LLM 世界 并理解本书中介绍的概念和代码示例做好充分准备。 如果你有深度神经网络方面的经验,你可能会觉得某些概念更熟悉,因为 LLM 正是基于这些架构构建的。 本书使用 PyTorch 从头开始实现代码,没有使用任何外部的 LLM 库。虽然精通 PyTorch 不是先决条件,但熟悉 PyTorch 的基础知识肯定会很有用。如果你刚接触 PyTorch,附录 A 提供了关于 PyTorch 的简明介绍。或者,你会发现我的另一本书[《一小时的 PyTorch:从张量到在多 GPU 上训练神经网络》](https://sebastianraschka.com/teaching/pytorch-1h/)对学习基础知识很有帮助。
## 硬件要求 本书主要章节中的代码旨在常规笔记本电脑上于合理的时间内运行,不需要专用硬件。这种方法确保了广大读者能够参与学习这些材料。此外,如果 GPU 可用,代码会自动使用它们。(请参阅[设置](https://github.com/rasbt/LLMs-from-scratch/blob/main/setup/README.md)文档以获取更多建议。) ## 视频课程 [一个长达 17 小时 15 分钟的配套视频课程](https://www.manning.com/livevideo/master-and-build-large-language-models),我在其中对本书的每一章进行了代码编写演示。该课程按照与本书结构相对应的章节和小节进行组织,既可以作为本书的独立替代品,也可以作为互补的代码跟学资源。 ## 伴读书籍 / 续作
[《构建推理模型(从零开始)》](https://mng.bz/lZ5B)虽然是一本独立的书,但也可以被视为*《构建大型语言模型(从零开始)》*的续作。
它从一个预训练模型开始,实现了包括推理时扩展、强化学习和蒸馏在内的不同推理方法,以提高模型的推理能力。
与*《构建大型语言模型(从零开始)》*类似,[《构建推理模型(从零开始)》](https://mng.bz/lZ5B)采用了一种实践的方法,从头开始实现这些方法。
## 伴读书籍 / 续作
[《构建推理模型(从零开始)》](https://mng.bz/lZ5B)虽然是一本独立的书,但也可以被视为*《构建大型语言模型(从零开始)》*的续作。
它从一个预训练模型开始,实现了包括推理时扩展、强化学习和蒸馏在内的不同推理方法,以提高模型的推理能力。
与*《构建大型语言模型(从零开始)》*类似,[《构建推理模型(从零开始)》](https://mng.bz/lZ5B)采用了一种实践的方法,从头开始实现这些方法。
 - Amazon 链接(待定)
- [Manning 链接](https://mng.bz/lZ5B)
- [GitHub 仓库](https://github.com/rasbt/reasoning-from-scratch)
- Amazon 链接(待定)
- [Manning 链接](https://mng.bz/lZ5B)
- [GitHub 仓库](https://github.com/rasbt/reasoning-from-scratch)
## 练习题 本书的每一章都包含几道练习题。解答总结在附录 C 中,相应的代码笔记本可在本仓库的主章节文件夹中找到(例如,[./ch02/01_main-chapter-code/exercise-solutions.ipynb](./ch02/01_main-chapter-code/exercise-solutions.ipynb))。 除了代码练习,你还可以从 Manning 网站下载一份 170 页的免费 PDF,标题为[《在构建大型语言模型(从零开始)上测试自己》](https://www.manning.com/books/test-yourself-on-build-a-large-language-model-from-scratch)。它每章包含大约 30 道测验题及解答,以帮助你检验自己的理解程度。 ## 附加材料
有几个文件夹包含为感兴趣读者准备的额外附加材料:
- **设置**
- [Python 设置技巧](setup/01_optional-python-setup-preferences)
- [安装本书使用的 Python 包和库](setup/02_installing-python-libraries)
- [Docker 环境设置指南](setup/03_optional-docker-environment)
- **第 2 章:处理文本数据**
- [从零开始构建字节对编码 (BPE) 分词器](ch02/05_bpe-from-scratch/bpe-from-scratch-simple.ipynb)
- [比较各种字节对编码 (BPE) 实现](ch02/02_bonus_bytepair-encoder)
- [理解嵌入层与线性层的区别](ch02/03_bonus_embedding-vs-matmul)
- [使用简单数字的数据加载器直觉](ch02/04_bonus_dataloader-intuition)
- **第 3 章:编写注意力机制**
- [比较高效的多头注意力实现](ch03/02_bonus_efficient-multihead-attention/mha-implementations.ipynb)
- [理解 PyTorch 缓冲区](ch03/03_understanding-buffers/understanding-buffers.ipynb)
- **第 4 章:从零开始实现 GPT 模型**
- [FLOPs 分析](ch04/02_performance-analysis/flops-analysis.ipynb)
- [KV 缓存](ch04/03_kv-cache)
- [注意力替代方案](ch04/#attention-alternatives)
- [分组查询注意力](ch04/04_gqa)
- [多头潜在注意力](ch04/05_mla)
- [滑动窗口注意力](ch04/06_swa)
- [门控 DeltaNet](ch04/08_deltanet)
- [混合专家模型](ch04/07_moe)
- **第 5 章:在无标签数据上预训练**
- [其他权重加载方法](ch05/02_alternative_weight_loading/)
- [在 Project Gutenberg 数据集上预训练 GPT](ch05/03_bonus_pretraining_on_gutenberg)
- [为训练循环添加扩展功能](ch05/04_learning_rate_schedulers)
- [优化预训练的超参数](ch05/05_bonus_hparam_tuning)
- [构建与预训练 LLM 交互的用户界面](ch05/06_user_interface)
- [将 GPT 转换为 Llama](ch05/07_gpt_to_llama)
- [内存高效的模型权重加载](ch05/08_memory_efficient_weight_loading/memory-efficient-state-dict.ipynb)
- [使用新 Token 扩展 Tiktoken BPE 分词器](ch05/09_extending-tokenizers/extend-tiktoken.ipynb)
- [加速 LLM 训练的 PyTorch 性能技巧](ch05/10_llm-training-speed)
- [LLM 架构](ch05/#llm-architectures-from-scratch)
- [从零开始构建 Llama 3.2](ch05/07_gpt_to_llama/standalone-llama32.ipynb)
- [从零开始构建 Qwen3 稠密模型和混合专家模型](ch05/11_qwen3/)
- [从零开始构建 Gemma 3](ch05/12_gemma3/)
- [从零开始构建 Olmo 3](
## 附加材料
有几个文件夹包含为感兴趣读者准备的额外附加材料:
- **设置**
- [Python 设置技巧](setup/01_optional-python-setup-preferences)
- [安装本书使用的 Python 包和库](setup/02_installing-python-libraries)
- [Docker 环境设置指南](setup/03_optional-docker-environment)
- **第 2 章:处理文本数据**
- [从零开始构建字节对编码 (BPE) 分词器](ch02/05_bpe-from-scratch/bpe-from-scratch-simple.ipynb)
- [比较各种字节对编码 (BPE) 实现](ch02/02_bonus_bytepair-encoder)
- [理解嵌入层与线性层的区别](ch02/03_bonus_embedding-vs-matmul)
- [使用简单数字的数据加载器直觉](ch02/04_bonus_dataloader-intuition)
- **第 3 章:编写注意力机制**
- [比较高效的多头注意力实现](ch03/02_bonus_efficient-multihead-attention/mha-implementations.ipynb)
- [理解 PyTorch 缓冲区](ch03/03_understanding-buffers/understanding-buffers.ipynb)
- **第 4 章:从零开始实现 GPT 模型**
- [FLOPs 分析](ch04/02_performance-analysis/flops-analysis.ipynb)
- [KV 缓存](ch04/03_kv-cache)
- [注意力替代方案](ch04/#attention-alternatives)
- [分组查询注意力](ch04/04_gqa)
- [多头潜在注意力](ch04/05_mla)
- [滑动窗口注意力](ch04/06_swa)
- [门控 DeltaNet](ch04/08_deltanet)
- [混合专家模型](ch04/07_moe)
- **第 5 章:在无标签数据上预训练**
- [其他权重加载方法](ch05/02_alternative_weight_loading/)
- [在 Project Gutenberg 数据集上预训练 GPT](ch05/03_bonus_pretraining_on_gutenberg)
- [为训练循环添加扩展功能](ch05/04_learning_rate_schedulers)
- [优化预训练的超参数](ch05/05_bonus_hparam_tuning)
- [构建与预训练 LLM 交互的用户界面](ch05/06_user_interface)
- [将 GPT 转换为 Llama](ch05/07_gpt_to_llama)
- [内存高效的模型权重加载](ch05/08_memory_efficient_weight_loading/memory-efficient-state-dict.ipynb)
- [使用新 Token 扩展 Tiktoken BPE 分词器](ch05/09_extending-tokenizers/extend-tiktoken.ipynb)
- [加速 LLM 训练的 PyTorch 性能技巧](ch05/10_llm-training-speed)
- [LLM 架构](ch05/#llm-architectures-from-scratch)
- [从零开始构建 Llama 3.2](ch05/07_gpt_to_llama/standalone-llama32.ipynb)
- [从零开始构建 Qwen3 稠密模型和混合专家模型](ch05/11_qwen3/)
- [从零开始构建 Gemma 3](ch05/12_gemma3/)
- [从零开始构建 Olmo 3](
## 问题、反馈与对本仓库的贡献 我欢迎各种形式的反馈,最好通过 [Manning 论坛](https://livebook.manning.com/forum?product=raschka&page=1)或 [GitHub Discussions](https://github.com/rasbt/LLMs-from-scratch/discussions) 分享。同样,如果你有任何问题或只是想与他人交流想法,请随时在论坛中发帖。 请注意,由于本仓库包含与纸质书相对应的代码,我目前无法接受扩展主章节代码内容的贡献,因为这会导致与实体书产生偏差。保持一致性有助于确保每个人都获得流畅的体验。 ## 引用 如果你发现本书或代码对你的研究有用,请考虑引用它。 芝加哥格式的引用: BibTeX 条目: ``` @book{build-llms-from-scratch-book, author = {Sebastian Raschka}, title = {Build A Large Language Model (From Scratch)}, publisher = {Manning}, year = {2024}, isbn = {978-1633437166}, url = {https://www.manning.com/books/build-a-large-language-model-from-scratch}, github = {https://github.com/rasbt/LLMs-from-scratch} } ```
在[《构建大型语言模型(从零开始)》](http://mng.bz/orYv)一书中,你将通过从头开始逐步编写代码,从内到外学习并理解大语言模型(LLM)的工作原理。在本书中,我将引导你创建自己的 LLM,并通过清晰的文本、图表和示例来解释每个阶段。 本书中描述的、用于训练和开发你自己的小型但功能齐全的模型(出于教育目的)的方法,与创建大规模基础模型(如 ChatGPT 背后的模型)所使用的方法如出一辙。此外,本书还包含了加载较大预训练模型权重以进行微调的代码。 - 官方[源代码仓库](https://github.com/rasbt/LLMs-from-scratch)链接 - [Manning(出版社网站)上的图书链接](http://mng.bz/orYv) - [Amazon.com 上的图书页面链接](https://www.amazon.com/gp/product/1633437167) - ISBN 9781633437166
要下载此仓库的副本,请点击 [Download ZIP](https://github.com/rasbt/LLMs-from-scratch/archive/refs/heads/main.zip) 按钮或在你的终端中执行以下命令: ``` git clone --depth 1 https://github.com/rasbt/LLMs-from-scratch.git ```
(如果你是从 Manning 网站下载的代码包,建议访问 GitHub 上的官方代码仓库 [https://github.com/rasbt/LLMs-from-scratch](https://github.com/rasbt/LLMs-from-scratch) 以获取最新更新。)
# 目录 请注意,此 `README.md` 文件是一个 Markdown (`.md`) 文件。如果你是从 Manning 网站下载的此代码包并在本地计算机上查看,我建议使用 Markdown 编辑器或预览器以便正常浏览。如果你尚未安装 Markdown 编辑器,[Ghostwriter](https://ghostwriter.kde.org) 是一个不错的免费选项。 你也可以在浏览器中访问 GitHub 上的 [https://github.com/rasbt/LLMs-from-scratch](https://github.com/rasbt/LLMs-from-scratch) 来查看此文件及其他文件,GitHub 会自动渲染 Markdown。
[](https://github.com/rasbt/LLMs-from-scratch/actions/workflows/basic-tests-linux-uv.yml) [](https://github.com/rasbt/LLMs-from-scratch/actions/workflows/basic-tests-windows-uv-pip.yml) [](https://github.com/rasbt/LLMs-from-scratch/actions/workflows/basic-tests-macos-uv.yml) - [故障排除指南](./troubleshooting.md) | 章节标题 | 主要代码(便于快速访问) | 所有代码 + 补充材料 | |------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------|-------------------------------| | [设置建议](setup)
[如何更好地阅读本书](https://sebastianraschka.com/blog/2025/reading-books.html) | - | - | | 第 1 章:理解大型语言模型 | 无代码 | - | | 第 2 章:处理文本数据 | - [ch02.ipynb](ch02/01_main-chapter-code/ch02.ipynb)
- [dataloader.ipynb](ch02/01_main-chapter-code/dataloader.ipynb) (总结)
- [exercise-solutions.ipynb](ch02/01_main-chapter-code/exercise-solutions.ipynb) | [./ch02](./ch02) | | 第 3 章:编写注意力机制 | - [ch03.ipynb](ch03/01_main-chapter-code/ch03.ipynb)
- [multihead-attention.ipynb](ch03/01_main-chapter-code/multihead-attention.ipynb) (总结)
- [exercise-solutions.ipynb](ch03/01_main-chapter-code/exercise-solutions.ipynb)| [./ch03](./ch03) | | 第 4 章:从零开始实现 GPT 模型 | - [ch04.ipynb](ch04/01_main-chapter-code/ch04.ipynb)
- [gpt.py](ch04/01_main-chapter-code/gpt.py) (总结)
- [exercise-solutions.ipynb](ch04/01_main-chapter-code/exercise-solutions.ipynb) | [./ch04](./ch04) | | 第 5 章:在无标签数据上预训练 | - [ch05.ipynb](ch05/01_main-chapter-code/ch05.ipynb)
- [gpt_train.py](ch05/01_main-chapter-code/gpt_train.py) (总结)
- [gpt_generate.py](ch05/01_main-chapter-code/gpt_generate.py) (总结)
- [exercise-solutions.ipynb](ch05/01_main-chapter-code/exercise-solutions.ipynb) | [./ch05](./ch05) | | 第 6 章:微调文本分类 | - [ch06.ipynb](ch06/01_main-chapter-code/ch06.ipynb)
- [gpt_class_finetune.py](ch06/01_main-chapter-code/gpt_class_finetune.py)
- [exercise-solutions.ipynb](ch06/01_main-chapter-code/exercise-solutions.ipynb) | [./ch06](./ch06) | | 第 7 章:微调指令遵循 | - [ch07.ipynb](ch07/01_main-chapter-code/ch07.ipynb)
- [gpt_instruction_finetuning.py](ch07/01_main-chapter-code/gpt_instruction_finetuning.py) (总结)
- [ollama_evaluate.py](ch07/01_main-chapter-code/ollama_evaluate.py) (总结)
- [exercise-solutions.ipynb](ch07/01_main-chapter-code/exercise-solutions.ipynb) | [./ch07](./ch07) | | 附录 A:PyTorch 简介 | - [code-part1.ipynb](appendix-A/01_main-chapter-code/code-part1.ipynb)
- [code-part2.ipynb](appendix-A/01_main-chapter-code/code-part2.ipynb)
- [DDP-script.py](appendix-A/01_main-chapter-code/DDP-script.py)
- [exercise-solutions.ipynb](appendix-A/01_main-chapter-code/exercise-solutions.ipynb) | [./appendix-A](./appendix-A) | | 附录 B:参考文献与扩展阅读 | 无代码 | [./appendix-B](./appendix-B) | | 附录 C:练习题解答 | - [练习题解答列表](appendix-C) | [./appendix-C](./appendix-C) | | 附录 D:为训练循环添加扩展功能 | - [appendix-D.ipynb](appendix-D/01_main-chapter-code/appendix-D.ipynb) | [./appendix-D](./appendix-D) | | 附录 E:使用 LoRA 进行参数高效微调 | - [appendix-E.ipynb](appendix-E/01_main-chapter-code/appendix-E.ipynb) | [./appendix-E](./appendix-E) |
下面的思维导图总结了本书涵盖的内容。
## 前置条件 最重要的前置条件是具备扎实的 Python 编程基础。 有了这些知识,你将为探索迷人的 LLM 世界 并理解本书中介绍的概念和代码示例做好充分准备。 如果你有深度神经网络方面的经验,你可能会觉得某些概念更熟悉,因为 LLM 正是基于这些架构构建的。 本书使用 PyTorch 从头开始实现代码,没有使用任何外部的 LLM 库。虽然精通 PyTorch 不是先决条件,但熟悉 PyTorch 的基础知识肯定会很有用。如果你刚接触 PyTorch,附录 A 提供了关于 PyTorch 的简明介绍。或者,你会发现我的另一本书[《一小时的 PyTorch:从张量到在多 GPU 上训练神经网络》](https://sebastianraschka.com/teaching/pytorch-1h/)对学习基础知识很有帮助。
## 硬件要求 本书主要章节中的代码旨在常规笔记本电脑上于合理的时间内运行,不需要专用硬件。这种方法确保了广大读者能够参与学习这些材料。此外,如果 GPU 可用,代码会自动使用它们。(请参阅[设置](https://github.com/rasbt/LLMs-from-scratch/blob/main/setup/README.md)文档以获取更多建议。) ## 视频课程 [一个长达 17 小时 15 分钟的配套视频课程](https://www.manning.com/livevideo/master-and-build-large-language-models),我在其中对本书的每一章进行了代码编写演示。该课程按照与本书结构相对应的章节和小节进行组织,既可以作为本书的独立替代品,也可以作为互补的代码跟学资源。
## 伴读书籍 / 续作
[《构建推理模型(从零开始)》](https://mng.bz/lZ5B)虽然是一本独立的书,但也可以被视为*《构建大型语言模型(从零开始)》*的续作。
它从一个预训练模型开始,实现了包括推理时扩展、强化学习和蒸馏在内的不同推理方法,以提高模型的推理能力。
与*《构建大型语言模型(从零开始)》*类似,[《构建推理模型(从零开始)》](https://mng.bz/lZ5B)采用了一种实践的方法,从头开始实现这些方法。
- Amazon 链接(待定)
- [Manning 链接](https://mng.bz/lZ5B)
- [GitHub 仓库](https://github.com/rasbt/reasoning-from-scratch)
## 练习题 本书的每一章都包含几道练习题。解答总结在附录 C 中,相应的代码笔记本可在本仓库的主章节文件夹中找到(例如,[./ch02/01_main-chapter-code/exercise-solutions.ipynb](./ch02/01_main-chapter-code/exercise-solutions.ipynb))。 除了代码练习,你还可以从 Manning 网站下载一份 170 页的免费 PDF,标题为[《在构建大型语言模型(从零开始)上测试自己》](https://www.manning.com/books/test-yourself-on-build-a-large-language-model-from-scratch)。它每章包含大约 30 道测验题及解答,以帮助你检验自己的理解程度。
## 附加材料
有几个文件夹包含为感兴趣读者准备的额外附加材料:
- **设置**
- [Python 设置技巧](setup/01_optional-python-setup-preferences)
- [安装本书使用的 Python 包和库](setup/02_installing-python-libraries)
- [Docker 环境设置指南](setup/03_optional-docker-environment)
- **第 2 章:处理文本数据**
- [从零开始构建字节对编码 (BPE) 分词器](ch02/05_bpe-from-scratch/bpe-from-scratch-simple.ipynb)
- [比较各种字节对编码 (BPE) 实现](ch02/02_bonus_bytepair-encoder)
- [理解嵌入层与线性层的区别](ch02/03_bonus_embedding-vs-matmul)
- [使用简单数字的数据加载器直觉](ch02/04_bonus_dataloader-intuition)
- **第 3 章:编写注意力机制**
- [比较高效的多头注意力实现](ch03/02_bonus_efficient-multihead-attention/mha-implementations.ipynb)
- [理解 PyTorch 缓冲区](ch03/03_understanding-buffers/understanding-buffers.ipynb)
- **第 4 章:从零开始实现 GPT 模型**
- [FLOPs 分析](ch04/02_performance-analysis/flops-analysis.ipynb)
- [KV 缓存](ch04/03_kv-cache)
- [注意力替代方案](ch04/#attention-alternatives)
- [分组查询注意力](ch04/04_gqa)
- [多头潜在注意力](ch04/05_mla)
- [滑动窗口注意力](ch04/06_swa)
- [门控 DeltaNet](ch04/08_deltanet)
- [混合专家模型](ch04/07_moe)
- **第 5 章:在无标签数据上预训练**
- [其他权重加载方法](ch05/02_alternative_weight_loading/)
- [在 Project Gutenberg 数据集上预训练 GPT](ch05/03_bonus_pretraining_on_gutenberg)
- [为训练循环添加扩展功能](ch05/04_learning_rate_schedulers)
- [优化预训练的超参数](ch05/05_bonus_hparam_tuning)
- [构建与预训练 LLM 交互的用户界面](ch05/06_user_interface)
- [将 GPT 转换为 Llama](ch05/07_gpt_to_llama)
- [内存高效的模型权重加载](ch05/08_memory_efficient_weight_loading/memory-efficient-state-dict.ipynb)
- [使用新 Token 扩展 Tiktoken BPE 分词器](ch05/09_extending-tokenizers/extend-tiktoken.ipynb)
- [加速 LLM 训练的 PyTorch 性能技巧](ch05/10_llm-training-speed)
- [LLM 架构](ch05/#llm-architectures-from-scratch)
- [从零开始构建 Llama 3.2](ch05/07_gpt_to_llama/standalone-llama32.ipynb)
- [从零开始构建 Qwen3 稠密模型和混合专家模型](ch05/11_qwen3/)
- [从零开始构建 Gemma 3](ch05/12_gemma3/)
- [从零开始构建 Olmo 3](## 问题、反馈与对本仓库的贡献 我欢迎各种形式的反馈,最好通过 [Manning 论坛](https://livebook.manning.com/forum?product=raschka&page=1)或 [GitHub Discussions](https://github.com/rasbt/LLMs-from-scratch/discussions) 分享。同样,如果你有任何问题或只是想与他人交流想法,请随时在论坛中发帖。 请注意,由于本仓库包含与纸质书相对应的代码,我目前无法接受扩展主章节代码内容的贡献,因为这会导致与实体书产生偏差。保持一致性有助于确保每个人都获得流畅的体验。 ## 引用 如果你发现本书或代码对你的研究有用,请考虑引用它。 芝加哥格式的引用: BibTeX 条目: ``` @book{build-llms-from-scratch-book, author = {Sebastian Raschka}, title = {Build A Large Language Model (From Scratch)}, publisher = {Manning}, year = {2024}, isbn = {978-1633437166}, url = {https://www.manning.com/books/build-a-large-language-model-from-scratch}, github = {https://github.com/rasbt/LLMs-from-scratch} } ```
标签:Apex, ChatGPT, DLL 劫持, Finetuning, GPT, LLM, NLP, Promptflow, PyTorch, Transformer, Unmanaged PE, 人工智能, 从零开始构建, 代码教程, 凭据扫描, 大语言模型, 开源书籍, 微调, 教育学习, 机器学习, 深度学习, 漏洞管理, 用户模式Hook绕过, 算法实现, 逆向工具, 预训练