lrh2000/StackRot
GitHub: lrh2000/StackRot
StackRot 是一个针对 Linux 内核 CVE-2023-3269 栈扩展漏洞的研究与利用工具,揭示了枫树结构在 RCU 回调中释放导致的 UAF 风险。
Stars: 499 | Forks: 37
# StackRot (CVE-2023-3269):Linux 内核权限提升漏洞
[][ci]
[*(GitHub-CI-verified exploit)*][ci]

在 Linux 内核 6.1 至 6.4 中发现了一个栈扩展处理缺陷,俗称“Stack Rot”。负责管理虚拟内存区域(VMA)的枫树(maple tree)结构在节点替换时未正确获取 MM 写锁,导致使用后释放(use-after-free)问题。无特权本地用户可利用此漏洞破坏内核并提升权限。
由于 StackRot 是 Linux 内核内存管理子系统中的漏洞,它几乎影响所有内核配置,且触发所需权限极低。需要注意的是,枫树节点通过 RCU 回调释放,实际内存释放会延迟到 RCU 宽限期之后。因此利用此漏洞较为困难。
据我所知,目前没有公开的针对 use-after-free-by-RCU(UAFBR)漏洞的利用程序。这标志着首次证明了 UAFBR 漏洞即使在没有 CONFIG_PREEMPT 或 CONFIG_SLAB_MERGE_DEFAULT 的情况下也可被利用。值得注意的是,该漏洞已在 [Google kCTF VRP][ctf] 提供的环境中成功验证([bzImage_upstream_6.1.25][img],[config][cfg])。
StackRot 漏洞自版本 6.1 起存在于 Linux 内核,当时 VMA 树结构从红黑树 [变更][ch] 为枫树。
## 背景
每当使用 `mmap()` 系统调用建立内存映射时,内核会创建一个名为 `vm_area_struct` 的结构,用于表示对应的虚拟内存区域(VMA)。该结构存储与映射相关的标志、属性及其他信息。
随后,当内核遇到缺页异常或其他内存相关系统调用时,需要仅基于地址快速查找 VMA。早期 VMA 使用红黑树管理,但从 Linux 内核版本 6.1 开始迁移到枫树。枫树是 RCU 安全的 B 树数据结构,适用于存储不重叠的范围,但其复杂性引入了 StackRot 漏洞。
```
struct vm_area_struct {
long unsigned int vm_start; /* 0 8 */
long unsigned int vm_end; /* 8 8 */
struct mm_struct * vm_mm; /* 16 8 */
pgprot_t vm_page_prot; /* 24 8 */
long unsigned int vm_flags; /* 32 8 */
union {
struct {
struct rb_node rb __attribute__((__aligned__(8))); /* 40 24 */
/* --- cacheline 1 boundary (64 bytes) --- */
long unsigned int rb_subtree_last; /* 64 8 */
} __attribute__((__aligned__(8))) shared __attribute__((__aligned__(8))); /* 40 32 */
struct anon_vma_name * anon_name; /* 40 8 */
} __attribute__((__aligned__(8))); /* 40 32 */
/* --- cacheline 1 boundary (64 bytes) was 8 bytes ago --- */
struct list_head anon_vma_chain; /* 72 16 */
struct anon_vma * anon_vma; /* 88 8 */
const struct vm_operations_struct * vm_ops; /* 96 8 */
long unsigned int vm_pgoff; /* 104 8 */
struct file * vm_file; /* 112 8 */
void * vm_private_data; /* 120 8 */
/* --- cacheline 2 boundary (128 bytes) --- */
atomic_long_t swap_readahead_info; /* 128 8 */
struct vm_userfaultfd_ctx vm_userfaultfd_ctx; /* 136 0 */
/* size: 136, cachelines: 3, members: 14 */
/* forced alignments: 1 */
/* last cacheline: 8 bytes */
} __attribute__((__aligned__(8)));
```
本质上,枫树由枫树节点组成。虽然树结构复杂,但 StackRot 漏洞与此无关。因此本文假设枫树仅包含一个节点,即根节点。该根节点最多可包含 16 个区间。这些区间可能表示“空洞”或指向 VMA。由于空洞也计入区间,所有区间按顺序连接,因此节点中仅需 15 个端点(也称枢轴)。注意最左和最右端点被省略,因为它们可从父节点获取。
```
struct maple_range_64 {
struct maple_pnode * parent; /* 0 8 */
long unsigned int pivot[15]; /* 8 120 */
/* --- cacheline 2 boundary (128 bytes) --- */
union {
void * slot[16]; /* 128 128 */
struct {
void * pad[15]; /* 128 120 */
/* --- cacheline 3 boundary (192 bytes) was 56 bytes ago --- */
struct maple_metadata meta; /* 248 2 */
}; /* 128 128 */
}; /* 128 128 */
/* size: 256, cachelines: 4, members: 3 */
};
```
上述 `maple_range_64` 结构表示一个枫树节点。除端点外,槽位用于引用 VMA 结构(当节点为叶节点时)或指向其他枫树节点(当节点为内部节点时)。若某区间为空洞,对应槽位为 NULL。枢轴与槽位的排列方式如下所示:
```
Slots -> | 0 | 1 | 2 | ... | 12 | 13 | 14 | 15 |
┬ ┬ ┬ ┬ ┬ ┬ ┬ ┬ ┬
│ │ │ │ │ │ │ │ └─ Implied maximum
│ │ │ │ │ │ │ └─ Pivot 14
│ │ │ │ │ │ └─ Pivot 13
│ │ │ │ │ └─ Pivot 12
│ │ │ │ └─ Pivot 11
│ │ │ └─ Pivot 2
│ │ └─ Pivot 1
│ └─ Pivot 0
└─ Implied minimum
```
关于并发修改,枫树施加了特定限制:写入者必须持有独占锁(*规则 W*)。对于 VMA 树,该独占锁对应 MM 写锁。读者有两种选择:第一种是持有 MM 读锁(*规则 A1*),这将阻塞写入者;第二种是进入 RCU 临界区(*规则 A2*),此时写入者不会被阻塞,且读者可继续操作,因为枫树是 RCU 安全的。尽管大多数 VMA 访问采用第一种方式(规则 A1),但少数性能敏感场景(如无锁缺页)使用规则 A2。
然而还需特别注意栈扩展。栈以 MAP_GROWSDOWN 标志映射,表示访问低于区域起始地址时会自动扩展。此时对应 VMA 的起始地址及枫树中的区间会更新,且此操作未持有 MM 写锁。
```
static inline
void do_user_addr_fault(struct pt_regs *regs,
unsigned long error_code,
unsigned long address)
{
// ...
if (unlikely(!mmap_read_trylock(mm))) {
// ...
}
// ...
if (unlikely(expand_stack(vma, address))) {
// ...
}
// ...
}
```
通常栈与相邻 VMA 之间存在空洞(由栈保护页保证)。此时栈扩展仅需原子更新枫树节点中的枢轴值。但如果相邻 VMA 也设置了 MAP_GROWSDOWN 标志,则无栈保护。
```
int expand_downwards(struct vm_area_struct *vma, unsigned long address)
{
// ...
if (prev) {
if (!(prev->vm_flags & VM_GROWSDOWN) &&
vma_is_accessible(prev) &&
(address - prev->vm_end < stack_guard_gap))
return -ENOMEM;
}
// ...
}
```
结果栈扩展会消除空洞。此时需在枫树节点中移除空洞区间。由于枫树是 RCU 安全的,无法直接原地覆盖节点,而是创建新节点并替换旧节点,旧节点随后通过 RCU 回调销毁。
```
static inline void mas_wr_modify(struct ma_wr_state *wr_mas)
{
// ...
if ((wr_mas->offset_end - mas->offset <= 1) &&
mas_wr_slot_store(wr_mas)) // <-- in-place update
return;
else if (mas_wr_node_store(wr_mas)) // <-- node replacement
return;
// ...
}
```
RCU 回调仅在所有先前的 RCU 临界区结束后才会被调用。然而问题在于访问 VMA 时仅持有 MM 读锁,未进入 RCU 临界区(规则 A1)。理论上,回调可在任意时刻触发并释放旧枫树节点,但代码中可能已获取旧节点指针,进而导致使用后释放漏洞。
使用后释放(UAF)发生的调用栈如下:
```
- CPU 0 - - CPU 1 -
mm_read_lock() mm_read_lock()
expand_stack() find_vma_prev()
expand_downwards() mas_walk()
mas_store_prealloc() mas_state_walk()
mas_wr_story_entry() mas_start()
mas_wr_modify() mas_root()
mas_wr_node_store() node = rcu_dereference_check()
mas_replace() [ The node pointer is recorded ]
mas_free()
ma_free_rcu()
call_rcu(&mt_free_rcu)
[ The node is dead ]
mm_read_unlock()
[ Wait for the next RCU grace period.. ]
rcu_do_batch() mas_prev()
mt_free_rcu() mas_prev_entry()
kmem_cache_free() mas_prev_nentry()
[ The node is freed ] mas_slot()
mt_slot()
rcu_dereference_check(node->..)
[ UAF occurs here ]
mm_read_unlock()
```
## 修复
我于 6 月 15 日向 Linux 内核安全团队报告了该漏洞。随后修复工作由 Linus Torvalds 主导。鉴于其复杂性,耗时近两周才形成获得共识的补丁集。
6 月 28 日,在 Linux 内核 6.5 的合并窗口期间,补丁被合并到 Linus 的代码树中。Linus 提供了 [全面的合并信息][fix],从技术角度阐述该补丁系列。
这些补丁随后被回溯到稳定内核([6.1.37][6.1]、[6.3.11][6.3] 和 [6.4.1][6.4]),于 7 月 1 日有效修复了“Stack Rot”漏洞。
## 利用
利用主要聚焦于 Google kCTF 挑战,且要求未启用 CONFIG_PREEMPT 和 CONFIG_SLAB_MERGE_DEFAULT。攻击 StackRot 的关键是定位满足以下条件的 VMA 迭代:
1. 迭代时机可控。可确保 RCU 宽限期在 VMA 迭代期间结束。
2. 迭代从 VMA 结构中检索信息并返回给用户空间。这使我们能利用枫树节点的 UAF 漏洞泄露内核地址。
3. 迭代调用 VMA 结构中的函数指针。这使我们能利用枫树节点的 UAF 漏洞控制内核模式程序计数器(PC)。
所选的 VMA 迭代负责生成 `/proc/[pid]/maps` 文件内容。以下各节将说明该迭代如何满足上述条件。
### 步骤 0:从 UAFBR 到 UAF
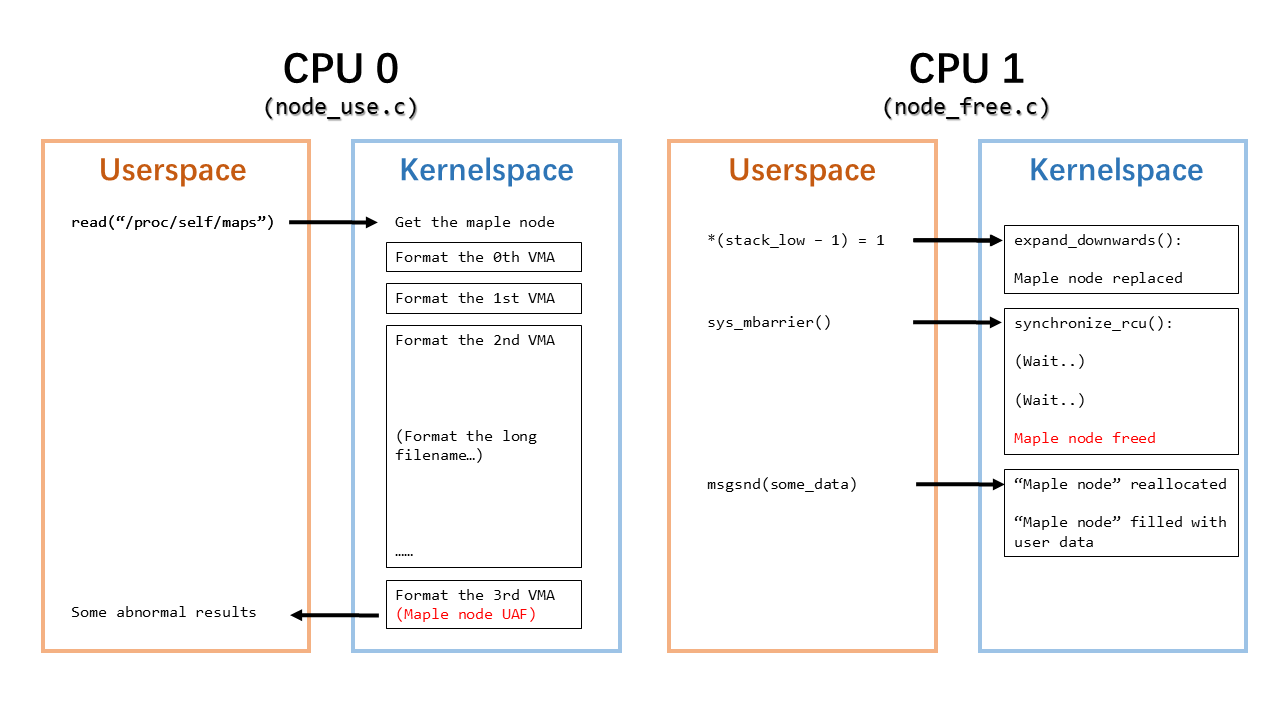
在任意 VMA 迭代中,都会获取 VMA 树根节点引用并遍历其槽位。因此,若在 VMA 迭代期间另一 CPU 触发栈扩展,节点替换会并发发生。此时访问旧节点属于使用后释放(UAFBR)状态。但只有当旧节点真正被释放时才会产生问题,而这发生在 RCU 回调中。
这带来两个挑战:(i) 确定旧节点何时被释放;(ii) 确保 VMA 迭代在旧节点释放前不会完成。
第一个问题相对简单。内核中可通过 `synchronize_rcu()` 等待 RCU 宽限期结束,使所有先前的 RCU 回调生效。在用户空间,可通过最终调用 `synchronize_rcu()` 的系统调用实现相同目的。因此,当此类系统调用返回时,可确定旧节点已被释放。值得注意的是存在一个系统调用 `membarrier(MEMBARRIER_CMD_GLOBAL, 0, -1)`,它仅调用 `synchronize_rcu()`。
```
SYSCALL_DEFINE3(membarrier, int, cmd, unsigned int, flags, int, cpu_id)
{
// ...
switch (cmd) {
// ...
case MEMBARRIER_CMD_GLOBAL:
/* MEMBARRIER_CMD_GLOBAL is not compatible with nohz_full. */
if (tick_nohz_full_enabled())
return -EINVAL;
if (num_online_cpus() > 1)
synchronize_rcu();
return 0;
// ...
}
}
```
第二个问题需要进一步考虑。可能的解决方案包括:
1. 迭代任务被抢占,RCU 宽限期结束,然后迭代恢复。但若 CONFIG_PREEMPT 未启用则无效。
2. 迭代任务进入睡眠(如等待 I/O),RCU 宽限期结束,迭代继续。目前未知是否存在满足条件且可泄露内核地址并控制程序计数器的 VMA 迭代。
3. 迭代任务被中断(如定时器中断),期间 RCU 宽限期结束。可使用 timerfd 创建多个硬件定时器,在 VMA 迭代期间超时触发长中断。但不可行,因为中断处理程序运行于禁用中断状态,若 CPU 无法处理跨处理器中断(IPI),RCU 宽限期不会结束。
4. 迭代任务被故意延长,使 RCU 宽限期过期。这是采用的方法。若当前 RCU 宽限期超过 `jiffies_till_first_fqs`(默认为数个 jiffies),则会向受害者 CPU 发送跨处理器中断(IPI)触发自愿抢占。对于 VMA 迭代,自愿抢占可使 RCU 宽限期结束,从而将 UAFBR 转换为真正的使用后释放(UAF)。
一个重要观察是:在 `/proc/[pid]/maps` 的 VMA 迭代过程中,会生成整个文件路径。对于文件映射目录名通常限制为最多 255 个字符,但目录深度无限制。因此可通过创建深度极大的文件并建立其内存映射,使访问 `/proc/[pid]/maps` 在 VMA 迭代中耗时长,从而有机会结束 RCU 宽限期并获得 UAF 原语。
```
static void
show_map_vma(struct seq_file *m, struct vm_area_struct *vma)
{
// ...
/*
* Print the dentry name for named mappings, and a
* special [heap] marker for the heap:
*/
if (file) {
seq_pad(m, ' ');
/*
* If user named this anon shared memory via
* prctl(PR_SET_VMA ..., use the provided name.
*/
if (anon_name)
seq_printf(m, "[anon_shmem:%s]", anon_name->name);
else
seq_file_path(m, file, "\n");
goto done;
}
// ...
}
```
下图展示了步骤 0:
### 步骤 1:从 slab UAF 到 page UAF
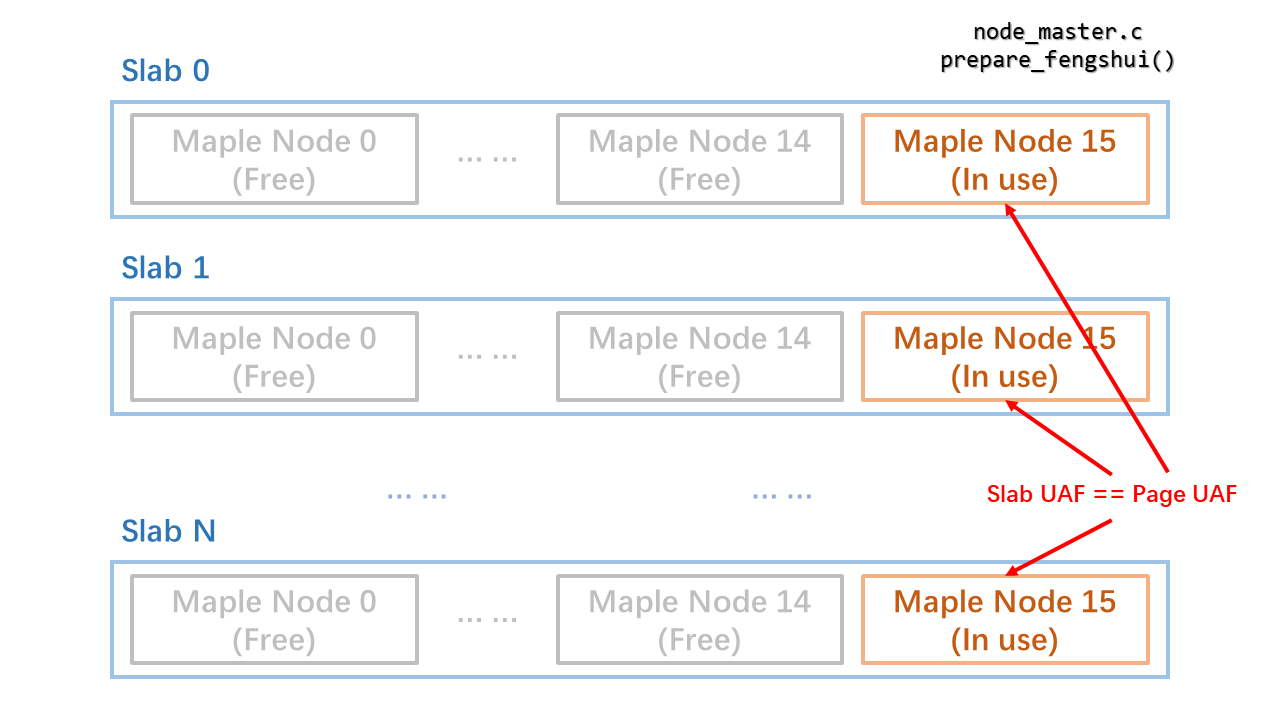
现在 UAF 在 slab 内部生效。若 CONFIG_SLAB_MERGE_DEFAULT 启用且 maple 节点 slab 与 kmalloc-256 合并,可通过从 kmalloc-256 分配新结构并填充用户数据来控制旧节点内容。但若 CONFIG_SLAB_MERGE_DEFAULT 未启用,则需要其他方法。此时需将释放节点的页返回给页分配器,从而通过分配新页并填充数据来控制旧节点。
回忆 VMA 树仅包含一个节点。因此通过 `fork()`/`clone()` 可创建多个 VMA 树及等量的枫树节点。假设一个 slab 包含 M 个枫树节点,其中 1 个节点被保留,其余节点通过 `exit()` 释放。剩余节点将成为各自 slab 中的唯一节点。最初这些 slab 位于 CPU 的 partial 列表。当 partial 列表达到上限时,slab 会回收到对应 NUMA 节点的 partial 列表。
若 slab 中最后一个枫树节点被释放,且该 slab 位于 NUMA 节点 partial 列表且已满,则页会立即返回给页分配器。此时 slab UAF 转换为 page UAF。释放页的内容可通过 `msgsnd()` 操纵,该调用分配弹性对象并直接填充用户数据。
```
static void __slab_free(struct kmem_cache *s, struct slab *slab,
void *head, void *tail, int cnt,
unsigned long addr)
{
// ...
if (unlikely(!new.inuse && n->nr_partial >= s->min_partial))
goto slab_empty;
// ...
return;
slab_empty:
// ...
discard_slab(s, slab);
}
```
每个 slab 中的枫树节点数量 M 取决于 CPU 数量。漏洞利用实现考虑两个 CPU 的情况,假设 M 为 16,如下图所示:
### 步骤 2:从 UAF 到地址泄露
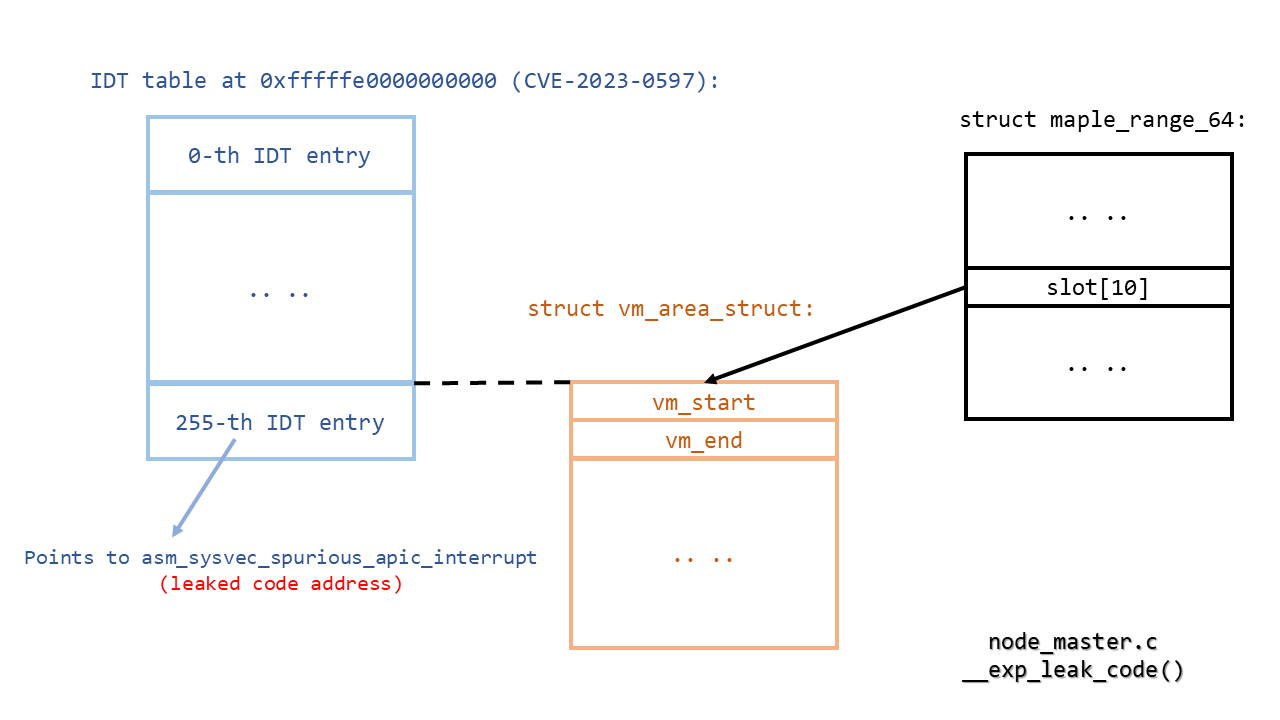
控制枫树节点后,即可操纵后续 VMA 的地址,这些 VMA 将在后续迭代中访问。由于目标迭代旨在生成 `/proc/self/maps`,因此会返回 VMA 结构中的某些信息,如起始与结束地址。
但存在挑战:枫树节点中 VMA 结构地址的设置依赖于已知地址。幸运的是,CVE-2023-0597 直接解决了此问题。根据该漏洞,`cpu_entry_area` 地址未随机化。尽管该漏洞在 Linux 6.2 中已修复且未回溯到更早稳定内核,但可通过将 VMA 结构地址覆盖为最后一个 IDT 项地址(其中包含 `asm_sysvec_spurious_apic_interrupt` 的地址)来直接泄露该入口地址,从而暴露内核代码和数据基址。
前述方法可重复使用以逐步泄露更多内核数据段地址。例如,`init_task.tasks.prev` 指针指向最新创建的 `task_struct` 结构,该结构必然位于堆上。
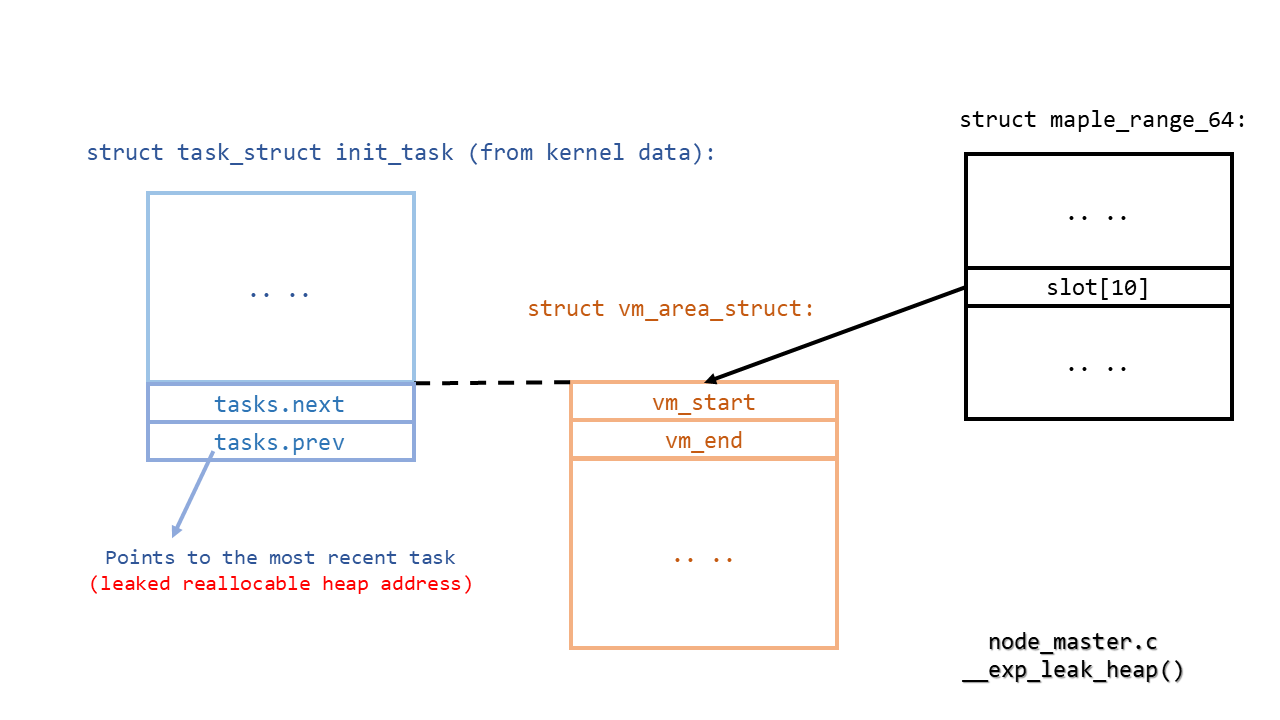
当所有新建任务终止后,其 `task_struct` 结构将被释放。若任务数量足够多,对应页将返回给页分配器。这允许重新分配这些页并填充用户数据。但需注意,释放的页通常属于每 CPU 页(PCP)列表。对于 PCP 页,只能以相同页阶重新分配。因此仅映射新页(需阶 0 页)无法达成目标。
不过,`msgsnd` 系统调用会通过 kmalloc 申请内存块并用用户数据填充。当 kmalloc 缓存耗尽时,会从页分配器申请特定阶数的页。若消息大小调整得当,可获得所需阶数。这样即可重新分配之前泄露地址的页,从而获得具有已知地址和用户可控数据的页。
### 步骤 3:从 UAF 到 root 权限
现在可以伪造目标页中的 VMA 结构,并控制 `vma->vm_ops->name` 函数指针。下一步是寻找合适的 gadget 以逃逸容器并获取 root 权限。
```
static void
show_map_vma(struct seq_file *m, struct vm_area_struct *vma)
{
// ...
if (vma->vm_ops && vma->vm_ops->name) {
name = vma->vm_ops->name(vma);
if (name)
goto done;
}
// ...
}
```
下图展示了步骤 3:
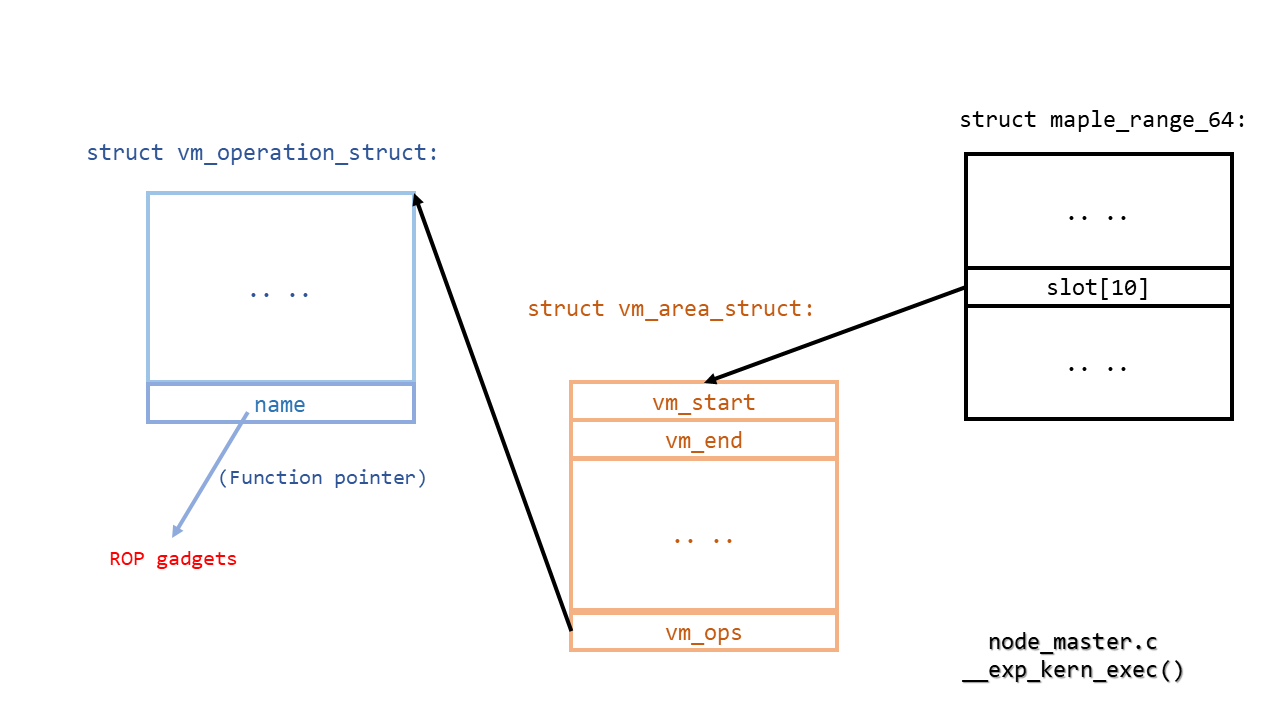
gadget 构造如下:
1. 栈 pivot:`movq %rbx, %rsi; movq %rbp, %rdi; call __x86_indirect_thunk_r13` -> `pushq %rsi; jmp 46(%rsi)` -> `popq %rsp; ret` -> `popq %rsp; ret`,其中 %rdi、%rbx 和 %r13 初始指向用户可控数据。
2. 获取 root 权限:`popq %rdi; ret` -> `prepare_kernel_cred` -> `popq %rdi; ret` -> `movq %rax, (%rdi); ret`,此时 %rdi 指向栈顶;`popq %rdi; ret` -> `commit_creds`,实际执行 `commit_creds(prepare_kernel_cred(&init_task))`。
3. 逃逸容器:`popq %rdi; ret` -> `find_task_by_vpid` -> `popq %rdi; ret` -> `movq %rax, (%rdi); ret`,此时 %rdi 指向栈顶;`popq %rdi; ret` -> `popq %rsi; ret` -> `switch_task_namespaces`,实际执行 `switch_task_namespaces(find_task_by_vpid(1), &init_nsproxy)`。
4. 解锁 mm:`popq %rax; ret` -> `movq %rbp, %rdi; call __x86_indirect_thunk_rax`,其中 %rbp 指向原始 seq_file;`popq %rax; ret` -> `m_stop`,实际执行 `m_stop(seq_file, ...)`。
5. 返回用户空间:使用 `swapgs_restore_regs_and_return_to_usermode` 并调用 `execve()` 获取 shell。
最后,使用 `nsenter --mount=/proc/1/ns/mnt` 恢复挂载命名空间,并通过 `cat /flag/flag` 获取 flag。
### 源代码
完整漏洞利用代码可在[此处](/exp)获取。更多细节请参考其 README 文件。
标签:0day挖掘, Chaos, CVE-2023-3269, exploit, Google kCTF, Linux内核漏洞, maple tree, mmap, PoC, privilege escalation, RCU延迟释放, StackRot, UAFBR, use-after-free, VMA, 内存管理, 内核安全, 内核版本6.1, 内核版本6.2, 内核版本6.3, 内核版本6.4, 内核绕过, 协议分析, 客户端加密, 暴力破解, 权限提升, 栈扩展漏洞