GamehunterKaan/CompanyEnum
GitHub: GamehunterKaan/CompanyEnum
这是一个基于 Flask 的 OSINT 自动化仪表盘,能够针对公司名称执行并行爬取,整合商业概况、财务、技术架构及人员评价等多维度情报。
Stars: 0 | Forks: 0
# CompanyEnum
一个 Flask Web 应用,针对公司名称执行一次性 OSINT 扫描,并在实时仪表板中展示结果。您输入一家公司,即可实时观察每个爬虫的进度,并获得一份包含公司概况、财务状况、人员信息、Web 技术态势以及客户/员工评价的分栏报告。

## 收集内容
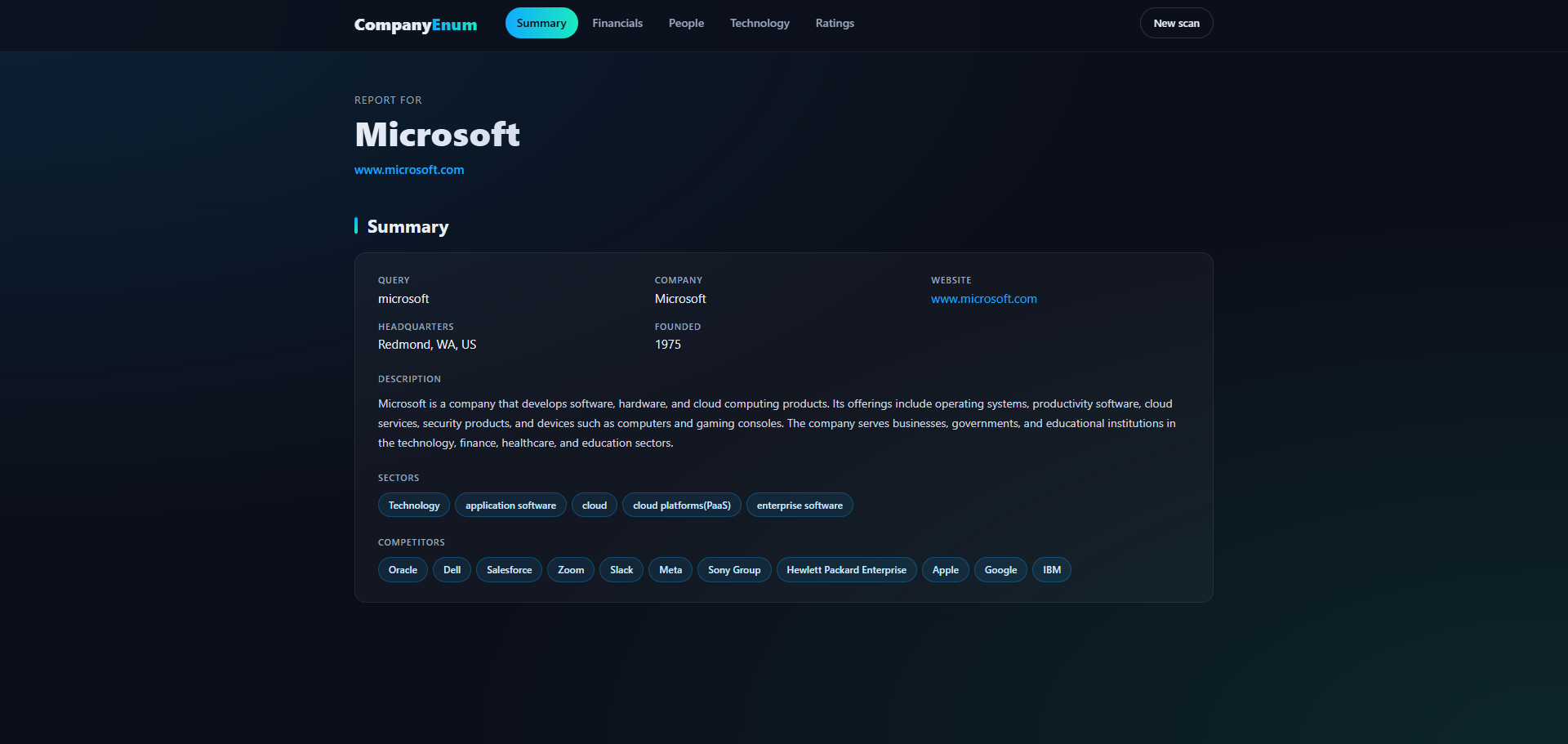
| 标签页 | 来源 | 数据 |
| ------------ | --------------------------------------------------- | ------------------------------------------------------------------------------------------------- |
| Summary | Craft.co, Google(网站回退) | 公司名称、网站、总部、成立日期、描述、行业领域、竞争对手 |
| Financials | Craft.co | 股价、市值、收入 |
| People | Craft.co | 职位与高管 |
| Technology | securityheaders.com, SSL Shopper, Sucuri SiteCheck, whois.com | HTTP 安全头评分、原始头信息、TLS 证书及 SAN、Sucuri 评级与建议、WHOIS 记录 |
| Ratings | Trustpilot, CareerBliss | 综合评分以及带星级组件的最新评价 |
## 工作原理
提交后会启动一个后台线程,依次运行每个爬虫,并将各步骤状态写入内存中的作业存储。浏览器被重定向到一个加载页面,该页面每 500 ms 轮询一次 `/status/`,并将每个步骤渲染为 pending(待定)→ running(运行中)→ done(完成)/ skipped(跳过)/ error(错误)。当作业完成时,页面会自动导航到 `/result/`。
[submodules/](submodules/) 中的爬虫根据目标对机器人检测的严格程度,混合采用以下三种策略:
- **requests / BeautifulSoup**:用于不进行拦截的网站(whois.com, SSL Shopper, Sucuri API)。
- **cloudscraper**:用于仍可接受良好浏览器指纹的 Cloudflare 防护网站(Craft.co, securityheaders.com)。
- **Playwright + playwright-stealth**(无头 Chromium):用于没有真实浏览器就无法绕过反机器人措施的网站(Trustpilot, CareerBliss)。
## 项目布局
```
main.py Flask app, routes, background job runner
requirements.txt Python dependencies
submodules/
craftco.py Craft.co profile + executives scraper
trustpilot.py Trustpilot reviews (Playwright)
careerbliss.py CareerBliss reviews (Playwright)
findwebsite.py Website resolver (Craft.co field + Google fallback)
securityheaders.py securityheaders.com scanner
sslhopper.py SSL Shopper cert checker
sucuri.py Sucuri SiteCheck API client
whoisquery.py whois.com scraper
compiledata.py HTML rendering for each output tab
static/
style.css Input page (waves, gradient, search bar)
loading.css Loading page (progress bar + step list)
output-style.css Report page (cards, tags, stars, grade badge)
script.js Output page tab switching + scroll progress
templates/
input.html Search form with example chips
loading.html Live progress UI
output.html Tabbed report
```
## 安装说明
需要 Python 3.9 或更高版本。
```
pip install -r requirements.txt
playwright install chromium
```
第二条命令会下载 Playwright 用于 Trustpilot 和 CareerBliss 所需的无头 Chromium 二进制文件。
## 运行
```
python main.py
```
然后打开 `http://127.0.0.1:5000/` 并输入公司名称。使用输入页面上的示例标签进行快速测试。
## 注意事项
- 内存中的作业存储上限为 32 条,按最旧优先原则驱逐。
- 单次扫描大约需要 20-40 秒,具体取决于网络状况以及哪些爬虫发生延迟。
- 如果 Craft.co 找不到该公司,网站解析器会回退到 Google 搜索;如果 Google 弹出 CAPTCHA,此回退可能会静默失败。在这种情况下,Technology 标签页将填充“Company website not found”占位符,其他功能仍然正常工作。
- 爬虫针对的是真实的 HTML 和 API 结构,这些结构可能会在毫无预警的情况下发生变化。当源网站重构页面时,偶尔可能会出现失效。
标签:BeautifulSoup, ESC4, Flask, GitHub, OSINT, Splunk, SSL证书, Web Scraping, Whois, 仪表板, 企业侦察, 员工评价, 安全头, 实时处理, 密码管理, 技术栈识别, 特征检测, 竞争对手分析, 被动信息收集, 财务数据, 逆向工具