thinkst/zippy
GitHub: thinkst/zippy
基于压缩算法快速检测 AI 生成文本的轻量级工具,通过压缩率近似衡量文本困惑度来判断来源。
Stars: 285 | Forks: 11
# ZipPy:快速分类文本为 AI 或人类生成的方法
这是一个使用压缩技术进行快速 AI 检测的研究仓库。
尽管现有的 LLM 检测系统为数不少,但它们都使用在 LLM 或其训练数据上训练的大型模型来计算在给定前文的情况下每个单词的概率,然后计算一个分数,其中高概率的 token 越多,越可能源自 AI。本仓库中的技术和工具旨在寻找更快的近似方法,以实现可嵌入性和更高的可扩展性。
### 其他资源
以下是了解 ZipPy 的其他途径:
* [关于 ZipPy 的博客文章](https://blog.thinkst.com/2023/06/meet-zippy-a-fast-ai-llm-text-detector.html)
* [Hack.LU 演讲视频](https://www.youtube.com/watch?v=CIdVix6k5Jw)
## 基于压缩的检测器(`zippy.py` 和 `nlzmadetect`)
ZipPy 使用 LZMA、Brotli 或 zlib 的压缩率作为间接衡量文本困惑度(perplexity)的一种方式。
压缩率过去曾被用于[检测网络数据中的异常](https://ieeexplore.ieee.org/abstract/document/5199270)以进行入侵检测,因此如果困惑度大致是异常 token 的一种度量,那么就有可能使用压缩来检测低困惑度的文本。
LZMA 和 zlib 会创建一个已见 token 的字典,然后在未来的 token 处使用这些字典项代替。字典大小、token 长度等都是动态的(尽管受 0-9 的“预设”影响——其中 0 最快,但压缩效果不如 9)。基本思想是用 AI 生成的文本语料库(`ai-generated.txt`)“种子化”一个压缩流,然后测量仅包含种子数据的压缩率与追加了样本后的压缩率。在措辞、结构等方面跟随得更紧密的样本,由于字典中存在大量相似的 token,将获得更高的压缩率;而新颖的单词、结构等对于种子化的字典来说会显得异常,从而导致较差的压缩率。
### 当前评估
一些领先的 LLM 检测工具包括:
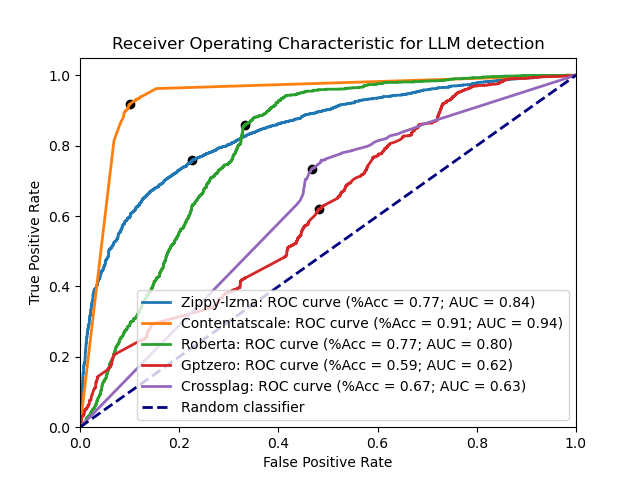
~~[OpenAI 的模型检测器 (v2)](https://openai.com/blog/new-ai-classifier-for-indicating-ai-written-text)~~,[Content at Scale](https://contentatscale.ai/ai-content-detector/),[GPTZero](https://gptzero.me/),[CrossPlag 的 AI 检测器](https://crossplag.com/ai-content-detector/),以及 [Roberta](https://huggingface.co/roberta-base-openai-detector)。
以下是它们与 LZMA 和 zlib 检测器在测试数据集上的对比:
### 安装
您可以通过以下两种方式之一安装 zippy:
#### 使用 python/pip
通过 pip:
```
pip3 install thinkst-zippy
```
或者从源码安装:
```
python3 setup.py build && python3 setup.py sdist && pip3 install dist/*.tar.gz
```
现在您可以在其他脚本中 `import zippy`。
#### 使用 pkgx
```
pkgx install zippy # or run it directly `pkgx zippy -h`
```
### 用法
ZipPy 将读取作为命令行参数传递的文件,或者从 stdin 读取以允许将文本管道传输给它。
一旦您[安装](#Installation)了 zippy,它将添加一个新脚本(`zippy`),您可以直接使用它:
```
$ zippy -h
usage: zippy [-h] [-p P] [-e {zlib,lzma,brotli,ensemble}] [-s | sample_files ...]
positional arguments:
sample_files Text file(s) containing the sample to classify
options:
-h, --help show this help message and exit
-p P Preset to use with compressor, higher values are slower but provide better compression
-e {zlib,lzma,brotli,ensemble}
Which compression engine to use: lzma, zlib, brotli, or an ensemble of all engines
-s Read from stdin until EOF is reached instead of from a file
$ zippy samples/human-generated/about_me.txt
samples/human-generated/about_me.txt
('Human', 0.06013429262166636)
```
如果您想在浏览器中使用 ZipPy 技术,请查看 [Chrome 扩展](https://chrome.google.com/webstore/detail/ai-noise-cancelling-headp/okghlbkbacncfnfcielbncabioedklcn)或 [Firefox 扩展](https://addons.mozilla.org/firefox/addon/ai-noise-cancelling-headphones/),它们在浏览器中运行 ZipPy 以标记潜在的 AI 生成内容。
### 解读结果
ZipPy 的输出本质上纯粹是 LLM 生成的语料库与提供的测试样本之间相似度的统计比较。更接近(即更多 token 与已知的 LLM 语料库匹配)的样本将以更高的置信度被评为 AI 生成;对于那些在 LLM 训练的压缩字典下压缩率较低的样本,则会被标记为人类生成。输出中有一些注意事项值得注意:
* 比较是基于文本的相似度,不同类型的样本,例如不同语言的样本,或包含许多虚构名称的样本,与英语语料库的相似度会较低。这需要一个新的 LLM 生成的语料库,或者一个能够处理多种语言类型的不同的(更大的)工具链。使用现有的 ZipPy 对非英语的人类语言样本、计算机语言样本以及非清晰散文(或诗歌)的英语样本会提供较差的响应。
* 置信度分数是前导文件(LLM 生成的语料库)的压缩率与包含样本后的压缩率之间的原始差值。较高的值表示 AI 分类输入的相似度更高,而对于那些被分类为人类的输入则表示差异更大,但这些分数不是百分比,也不是离散范围内的一个点。分数为 0 表示没有任何倾向,在[测试中](https://github.com/thinkst/zippy/blob/main/test_zippy_detect.py#L17)可以忽略“太接近”的结果,在浏览器扩展中,这些值在用于计算透明度之前会稍作调整,以倾向于不隐藏文本。
标签:AI检测, Apex, Brotli, LLM检测, LZMA, Naabu, Python, zlib, 信息鉴别, 内容安全, 内核驱动漏洞利用, 压缩算法, 困惑度, 异常检测, 数据压缩, 文本分类, 无后门, 机器学习, 深度伪造检测, 网络安全, 逆向工具, 隐私保护