RiccardoBiosas/awesome-MLSecOps
GitHub: RiccardoBiosas/awesome-MLSecOps
一个精心策划的 MLSecOps 资源合集,汇总了机器学习与 MLOps 安全领域的工具、文章、教程和社区资源。
Stars: 439 | Forks: 78
# 优秀的 MLSecOps 🛡️🤖
[](https://awesome.re)
[](https://github.com/RiccardoBiosas/awesome-MLSecOps/graphs/commit-activity)

[](https://twitter.com/RBiosas)
一个精心策划的 MLSecOps(机器学习安全运营)开源工具、资源和教程的精选列表。

## 目录
- [开源安全工具](#open-source-security-tools)
- [商业工具](#commercial-tools)
- [数据](#data)
- [ML 代码安全](#ml-code-security)
- [入门资源](#101-resources)
- [攻击向量](#attack-vectors)
- [博客与出版物](#blogs-and-publications)
- [MLOps 基础设施漏洞](#mlops-infrastructure-vulnerabilities)
- [社区资源](#community-resources)
- [信息图表](#infographics)
- [贡献](#contributions)
- [贡献者](#contributors-)
## 开源安全工具
#### 在本节中,你我都可以看看目前存在哪些开源解决方案和 PoC 可用于实现 ML 保护任务。当然,其中一些可能已不再维护或在运行时存在困难。然而,不提及它们是一种极大的罪过。
| 工具 | 描述 |
|------|-------------|
| [ModelScan](https://github.com/protectai/modelscan) | 防范 ML 模型序列化攻击 |
| [NB Defense](https://nbdefense.ai) | 保护 Jupyter Notebooks 安全 |
| [Garak](https://github.com/leondz/garak) | LLM 漏洞扫描器 |
| [Adversarial Robustness Toolbox](https://github.com/IBM/adversarial-robustness-toolbox) | 保护 ML 模型免受对抗性攻击的防御方法库 |
| [MLSploit](https://github.com/mlsploit/) | 用于对抗性机器学习研究交互式实验的云框架 |
| [TensorFlow Privacy](https://github.com/tensorflow/privacy) | 隐私保护机器学习算法和工具库 |
| [Foolbox](https://github.com/bethgelab/foolbox) | 用于创建和评估对抗性攻击与防御的 Python 工具箱 |
| [Advertorch](https://github.com/BorealisAI/advertorch) | 用于对抗性鲁棒性研究的 Python 工具箱 |
| [Artificial Intelligence Threat Matrix](https://collaborativeaicontrols.github.io/ATM/) | 用于识别和缓解机器学习系统威胁的框架 |
| [Adversarial ML Threat Matrix](https://github.com/mitre/advmlthreatmatrix) | AI 系统的对抗性威胁全景 |
| [CleverHans](https://github.com/cleverhans-lab/cleverhans) | 针对机器学习模型的对抗样本与防御库 |
| [AdvBox](https://github.com/advboxes/AdvBox) | Advbox 是一个用于生成对抗样本的工具箱,可欺骗 PaddlePaddle、PyTorch、Caffe2、MxNet、Keras、TensorFlow 中的神经网络 |
| [Audit AI](https://github.com/pymetrics/audit-ai) | 针对通用机器学习应用的偏见测试 |
| [Deep Pwning](https://github.com/cchio/deep-pwning) | Deep-pwning 是一个轻量级框架,用于对机器学习模型进行实验,旨在评估其在面对有动机的攻击者时的鲁棒性 |
| [Privacy Meter](https://github.com/privacytrustlab/ml_privacy_meter) | 用于审计统计和机器学习算法中数据隐私的开源库 |
| [TensorFlow Model Analysis](https://github.com/tensorflow/model-analysis) | 用于分析、验证和监控生产环境中机器学习模型的库 |
| [PromptInject](https://github.com/agencyenterprise/PromptInject) | 一个组装对抗性 prompt 的框架 |
| [Agent Memory Guard](https://github.com/OWASP/www-project-agent-memory-guard) | 官方的 OWASP runtime 防御层,用于筛查 AI agent 的内存读写,阻止 prompt 注入、机密泄露和内存投毒 (ASI06) |
| [TextAttack](https://github.com/QData/TextAttack) | TextAttack 是一个用于 NLP 中的对抗性攻击、数据增强和模型训练的 Python 框架 |
| [OpenAttack](https://github.com/thunlp/OpenAttack) | 一个用于文本对抗性攻击的开源包 |
| [TextFooler](https://github.com/jind11/TextFooler) | 针对文本分类和推断的自然语言攻击模型 |
| [Flawed Machine Learning Security](https://github.com/EthicalML/fml-security) | “有缺陷的机器学习安全”的实用示例,以及涵盖从训练、打包到部署的机器学习模型生命周期端到端各个阶段的 ML 安全最佳实践 |
| [Adversarial Machine Learning CTF](https://github.com/arturmiller/adversarial_ml_ctf) | 此代码库是一个 CTF 挑战赛,展示了大多数(所有?)常见人工神经网络中的安全缺陷。它们容易受到对抗性图像的攻击 |
| [Damn Vulnerable LLM Project](https://github.com/harishsg993010/DamnVulnerableLLMProject) | 一个专为被黑客攻击而设计的大语言模型 |
| [Gandalf Lakera](https://gandalf.lakera.ai/) | Prompt 注入 CTF 演练场 |
| [Vigil](https://github.com/deadbits/vigil-llm) | LLM prompt 注入和安全扫描器 |
| [PALLMs (Payloads for Attacking Large Language Models)](https://github.com/mik0w/pallms) | 汇总在一个地方的各种用于攻击 LLM 的 payload 列表 |
| [AI-exploits](https://github.com/protectai/ai-exploits) | 针对 MLOps 系统的漏洞利用。这不仅仅是针对提供给诸如 ChatGPT 之类 LLM 的输入 |
| [Offensive ML Playbook](https://wiki.offsecml.com/Welcome+to+the+Offensive+ML+Playbook) | 攻击性 ML 手册。关于机器学习攻击和渗透测试的笔记 |
| [AnonLLM](https://github.com/fsndzomga/anonLLM) | 为大语言模型 API 匿名化个人身份信息 (PII) |
| [AI Goat](https://github.com/dhammon/ai-goat) | 存在漏洞的 LLM CTF 挑战 |
| [Pyrit](https://github.com/Azure/PyRIT) | 用于生成式 AI 的 Python 风险识别工具 |
| [Raze to the Ground: Query-Efficient Adversarial HTML Attacks on Machine-Learning Phishing Webpage Detectors](https://github.com/advmlphish/raze_to_the_ground_aisec23) | 论文《Raze to the Ground: Query-Efficient Adversarial HTML Attacks on Machine-Learning Phishing Webpage Detectors》(被 AISec '23 接收)的源代码 |
| [Giskard](https://github.com/Giskard-AI/giskard) | 用于 LLM 应用的开源测试工具 |
| [Safetensors](https://github.com/huggingface/safetensors) | 将 pickle 转换为安全的序列化选项 |
| [Citadel Lens](https://www.citadel.co.jp/en/products/lens/)| 根据行业标准对模型进行质量测试 |
| [Model-Inversion-Attack-ToolBox](https://github.com/ffhibnese/Model-Inversion-Attack-ToolBox) | 用于实施模型逆向攻击的框架 |
| [NeMo-Guardials](https://github.com/NVIDIA/NeMo-Guardrails) | NeMo Guardrails 允许构建基于 LLM 应用的开发者轻松地在应用程序代码和 LLM 之间添加可编程的护栏 |
| [AugLy](https://github.com/facebookresearch/AugLy) | 一个用于生成对抗性攻击的工具 |
| [Knockoffnets](https://github.com/tribhuvanesh/knockoffnets) | 用于实施黑盒攻击以窃取模型数据的 PoC |
| [Robust Intelligence Continous Validation](https://www.robustintelligence.com/platform/continuous-validation) | 用于持续进行模型验证以符合标准的工具 |
| [VGER](https://github.com/JosephTLucas/vger) | Jupyter 攻击框架 |
| [AIShield Watchtower](https://github.com/bosch-aisecurity-aishield/watchtower) | 来自 AIShield 的开源工具,用于研究 AI 模型并扫描漏洞 |
| [PS-fuzz](https://github.com/prompt-security/ps-fuzz) | 用于扫描 LLM 漏洞的工具 |
| [Mindgard-cli](https://github.com/Mindgard/cli/) | 通过 CLI 检查你的 AI 安全性 |
| [PurpleLLama3](https://meta-llama.github.io/PurpleLlama/)| 使用 Meta LLM Benchmark 检查 LLM 安全性 |
| [Model transparency](https://github.com/sigstore/model-transparency) | 生成模型签名 |
| [ARTkit](https://github.com/BCG-X-Official/artkit)| 针对 Gen AI 应用的基于 prompt 的自动化测试与评估|
| [LangBiTe](https://github.com/SOM-Research/LangBiTe) | 针对大语言模型的偏见测试框架 |
| [OpenDP](https://github.com/opendp/opendp)| 支持 OpenDP 项目的差分隐私算法核心库|
| [TF-encrypted](https://tf-encrypted.io/)| 用于 TensorFlow 的加密|
| [Agentic Security](https://github.com/msoedov/agentic_security)| 代理型 LLM 漏洞扫描器 / AI 红队工具包|
| [CircleGuardBench](https://github.com/whitecircle-ai/circle-guard-bench)| 一个用于评估 AI 模型保护能力的完善基准|
| [Promptfoo Scanner](https://github.com/promptfoo/promptfoo) | 一个开源的 LLM 红队工具 |
## 商业工具
| 工具 | 描述 |
|------|-------------|
| [Databricks Platform, Azure Databricks](https://azure.microsoft.com/ru-ru/products/databricks) | 数据湖数据管理和实施工具 |
| [Hidden Layer AI Detection Response](https://hiddenlayer.com/aidr/) | 用于检测和响应事件的工具 |
| [Guardian](https://protectai.com/guardian) | 在 CI/CD 中保护模型 |
| [Promptfoo](https://www.promptfoo.dev/security/) | 针对企业级 LLM 应用的持续监控、检测和修复 |
## 数据
| 工具 | 描述 |
|------|-------------|
| [ARX - Data Anonymization Tool](https://arx.deidentifier.org/) | 用于匿名化数据集的工具 |
| [Data-Veil](https://veil.ai/) | 数据脱敏和匿名化工具 |
| [Tool for IMG anonymization](https://github.com/PacktPublishing/Adversarial-AI---Attacks-Mitigations-and-Defense-Strategies/blob/main/ch10/notebooks/Image%20Anonymization.ipynb)| 图像匿名化|
| [Tool for DATA anonymization](https://github.com/PacktPublishing/Adversarial-AI---Attacks-Mitigations-and-Defense-Strategies/blob/main/ch10/notebooks/Data%20Anonymization.ipynb)| 数据匿名化|
| [BMW-Anonymization-Api](https://github.com/BMW-InnovationLab/BMW-Anonymization-API?referral=top-free-anonymization-tools-apis-and-open-source-models)| 此代码库允许你匿名化图像/视频中的敏感信息。该解决方案与我们已经发布/将要发布的用于目标检测和语义分割的基于深度学习的训练/推理解决方案完全兼容 |
| [DeepPrivacy2](https://github.com/hukkelas/deep_privacy2)| 一个用于真实图像匿名化的工具箱 |
| [PPAP](https://github.com/tgisaturday/PPAP)| 使用对抗性保护网络进行潜在空间级别的图像匿名化|
## ML 代码安全
- [lintML](https://github.com/JosephTLucas/lintML) - 由 Nvidia 开发的针对 ML 的安全 linter
- [HiddenLayer: Model as Code](https://hiddenlayer.com/research/models-are-code/) - 关于 ML 库中一些攻击向量的研究
- [Copycat CNN](https://github.com/jeiks/Stealing_DL_Models) - 关于如何生成卷积神经网络副本的概念验证
- [differential-privacy-library](https://github.com/IBM/differential-privacy-library) - 为差分隐私和机器学习设计的库
## 入门资源
#### 你可以在这里找到一系列资源,帮助你入门 AI 安全领域。了解存在哪些攻击以及攻击者如何利用它们。
- [AI 安全 101](https://www.nightfall.ai/ai-security-101)
- [Web LLM 攻击](https://portswigger.net/web-security/llm-attacks)
- [Microsoft AI 红队](https://learn.microsoft.com/en-us/security/ai-red-team/)
- [面向 ML 工程师的 AI 风险评估](https://learn.microsoft.com/en-us/security/ai-red-team/ai-risk-assessment)
- [Microsoft - 初学者生成式 AI 安全](https://github.com/microsoft/generative-ai-for-beginners/blob/main/13-securing-ai-applications/README.md?WT.mc_id=academic-105485-koreyst)
#### AI 安全学习图谱
[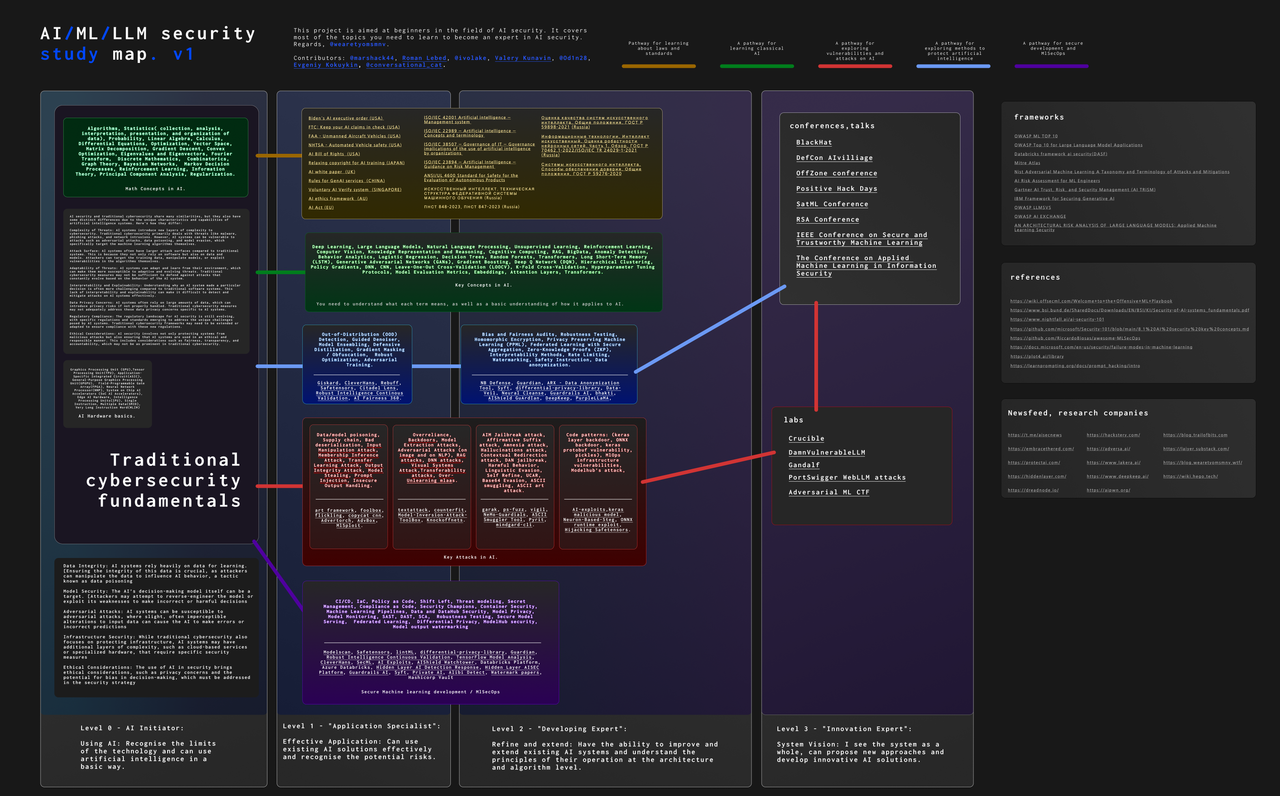](https://postimg.cc/sQvkg8tJ)
[此代码库中的完整尺寸图谱](https://github.com/wearetyomsmnv/AI-LLM-ML_security_study_map)
## 威胁建模
- [AI Villiage: LLM 威胁建模](https://aivillage.org/large%20language%20models/threat-modeling-llm/)
- [JSOTIRO/ThreatModels](https://github.com/jsotiro/ThreatModels/tree/main)
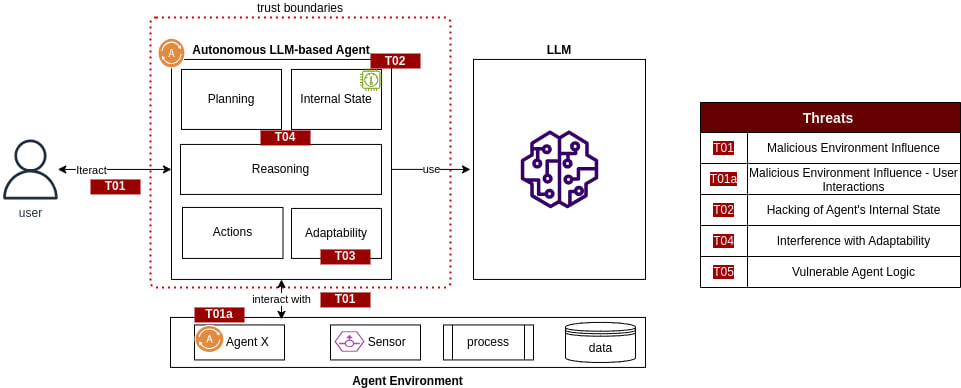
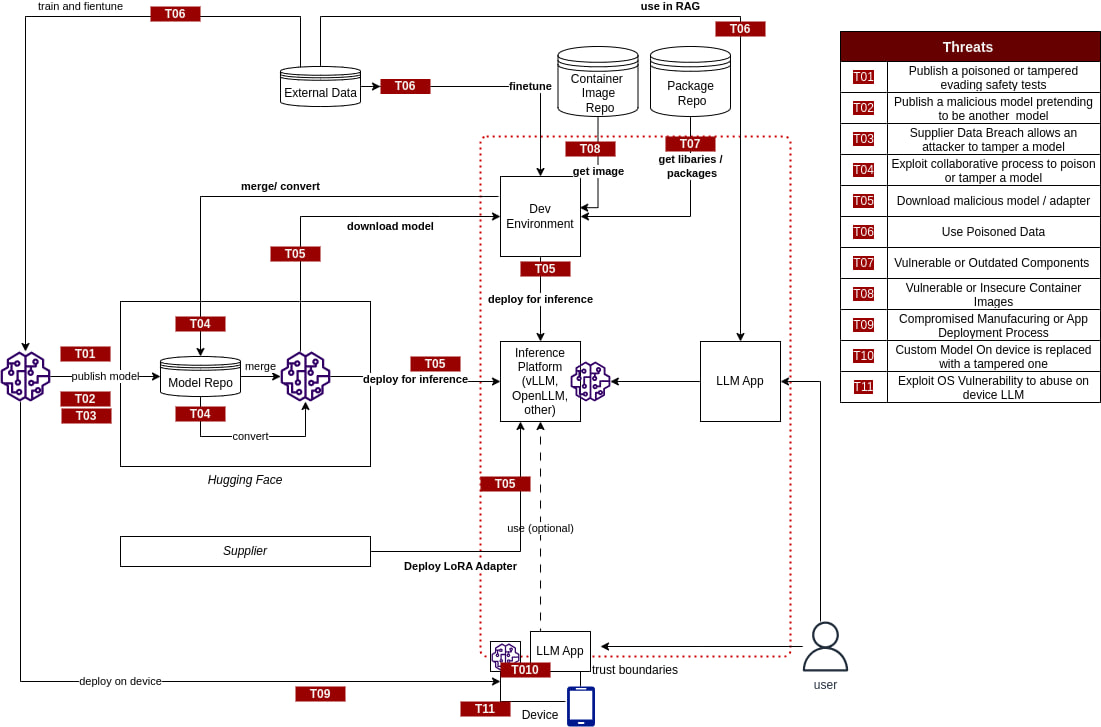
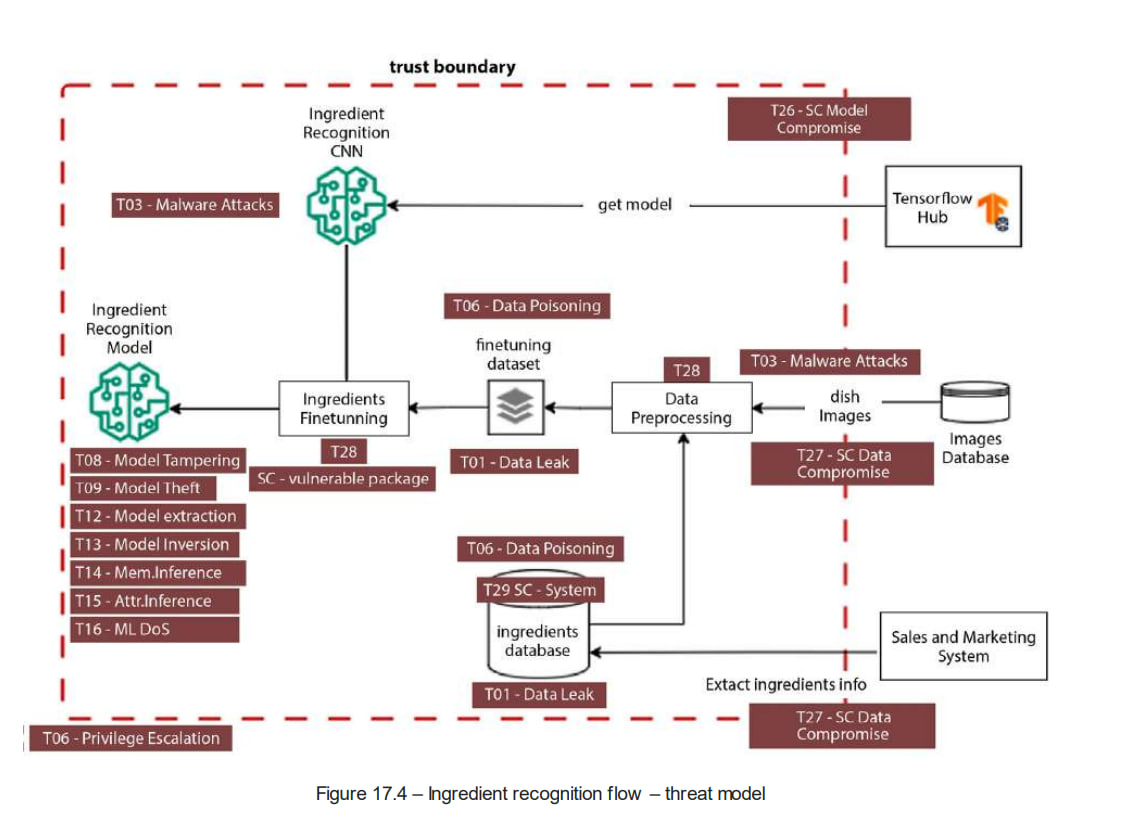
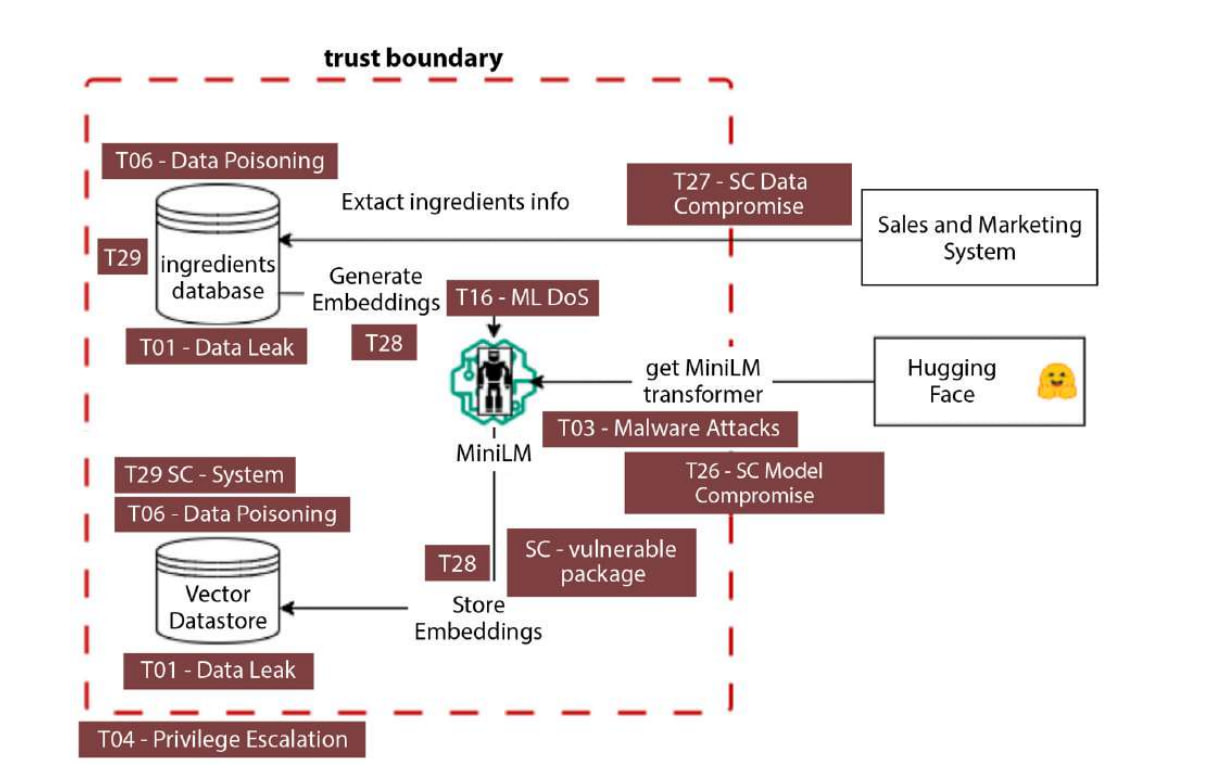
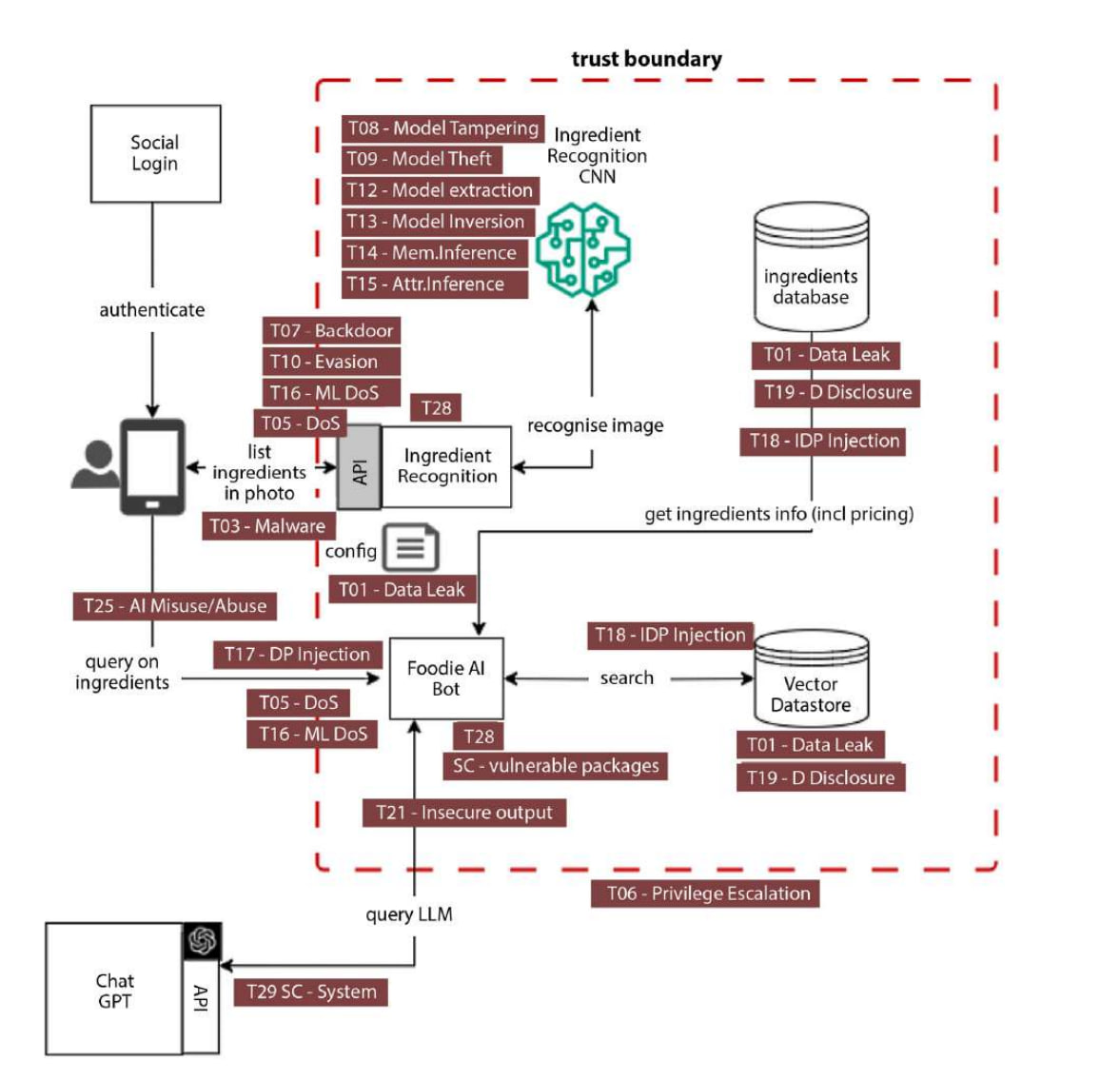
更多内容请见 **《对抗性 AI 攻击、缓解和防御策略:网络安全专业人员关于 AI 攻击、威胁建模以及使用 MLSecOps 保护 AI 的指南》**
## 攻击向量
#### 我们在此提供了一系列专注于特定攻击向量的实用资源。
- [数据投毒](https://github.com/ch-shin/awesome-data-poisoning)
- [对抗性 Prompt 利用](https://research.nccgroup.com/2022/12/05/exploring-prompt-injection-attacks)
- [模型逆向攻击](https://blogs.rstudio.com/ai/posts/2020-05-15-model-inversion-attacks/)
- [模型逃逸攻击](https://www.ibm.com/docs/en/watsonx/saas?topic=atlas-evasion-attack)
- [成员推理利用](https://arxiv.org/abs/2103.07853)
- [模型窃取攻击](https://arxiv.org/abs/2206.08451- [ML 供应链攻击](https://owasp.org/www-project-machine-learning-security-top-10/docs/ML06_2023-AI_Supply_Chain_Attacks)
- [模型拒绝服务](https://genai.owasp.org/llmrisk/llm04-model-denial-of-service/)
- [梯度泄露攻击](https://ieeexplore.ieee.org/document/10107713)
- [云基础设施攻击](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7931962/)
- [架构与访问控制攻击](https://genai.owasp.org/llmrisk/llm08-excessive-agency/)
## 博客与出版物
#### 🌱 AI 安全社区正在不断壮大。新的博客和许多研究人员不断涌现。在这一段中,你可以看到一些博客的示例。
- 📚 [什么是 MLSecOps](https://themlsecopshacker.com/p/what-is-mlsecops)
- 🛡️ [对大语言模型的红队测试](https://huggingface.co/blog/red-teaming)
- 🔍 [Google 的 AI 红队](https://blog.google/technology/safety-security/googles-ai-red-team-the-ethical-hackers-making-ai-safer/)
- 🔒 [MLSecOps Top 10 漏洞](https://ethical.institute/security.html)
- 🏴☠️ [通过对抗性 Prompt 进行 Token 走私越狱](https://www.piratewires.com/p/gpt4-token-smuggling)
- ☣️ [数据投毒到底有多毒?针对后门和
数据投毒攻击的统一基准](https://arxiv.org/pdf/2006.12557.pdf)
- 📊 [我们需要一种衡量 AI 安全的新方法](https://blog.trailofbits.com/2023/03/14/ai-security-safety-audit-assurance-heidy-khlaaf-odd/)
- 🕵️ [PrivacyRaven:实现模型逆向攻击的概念验证](https://blog.trailofbits.com/2021/11/09/privacyraven-implementing-a-proof-of-concept-for-model-inversion/)
- 🧠 [对抗性 Prompt 工程](https://github.com/dair-ai/Prompt-Engineering-Guide/blob/main/guides/prompts-adversarial.md)
- 🔫 [TextAttack:NLP 中的对抗性攻击、数据增强和对抗性训练框架](https://arxiv.org/abs/2005.05909)
- 📋 [Trail Of Bits 对 Hugging Face 的 safetensors 库的审计](https://github.com/trailofbits/publications/blob/master/reviews/2023-03-eleutherai-huggingface-safetensors-securityreview.pdf)
- 🔝 [大语言模型应用的 OWASP Top 10](https://owasp.org/www-project-top-10-for-large-language-model-applications/descriptions/)
- 🔐 [LLM 安全](https://llmsecurity.net/)
- 🔑 [你的 MLOps 基础设施在泄露机密吗?](https://hackstery.com/2023/10/13/no-one-is-prefect-is-your-mlops-infrastructure-leaking-secrets/)
- 🚩 [Embrace The Red,展示如何攻击 LLM 的博客。](https://embracethered.com/)
- 🎙️ [音频劫持:利用生成式 AI 扭曲实时音频交易](https://securityintelligence.com/posts/using-generative-ai-distort-live-audio-transactions/)
- 🌐 [HADESS - Web LLM 攻击](https://hadess.io/web-llm-attacks/)
- 🧰 [WTF-blog - MlSecOps 框架……有哪些可用,区别是什么?](https://blog.wearetyomsmnv.wtf/articles/mlsecops-frameworks-...-which-ones-are-available-and-what-is-the-difference)
- 📚 [DreadNode 论文集](https://dreadnode.notion.site/2582fe5306274c60b85a5e37cf99da7e?v=74ab79ed1452441dab8a1fa02099fed)
- 🛡️ [CircleGuardBench:评估 AI 审核模型的新标准](https://huggingface.co/blog/whitecircle-ai/circleguardbench)
## MLOps 基础设施漏洞
#### 关于 MLOps 基础设施漏洞的非常有趣的文章。在其中一些文章中,你甚至可以找到现成的漏洞利用程序。
- [SILENT SABOTAGE](https://hiddenlayer.com/research/silent-sabotage/) - 关于将 Pickle 转换为 SafeTensors 时遭遇机器人投毒破坏的研究
- [NOT SO CLEAR: HOW MLOPS SOLUTIONS CAN MUDDY THE WATERS OF YOUR SUPPLY CHAIN](https://hiddenlayer.com/research/not-so-clear-how-mlops-solutions-can-muddy-the-waters-of-your-supply-chain/) - 关于 ClearML 平台漏洞的研究
- [Uncovering Azure's Silent Threats: A Journey into Cloud Vulnerabilities](https://www.youtube.com/watch?v=tv8tei97Sv8) - 关于 Azure MLAAS 安全问题的研究
- [The MLOps Security Landscape](https://hackstery.com/wp-content/uploads/2023/11/mlops_owasp_oslo_2023.pdf)
- [Confused Learning: Supply Chain Attacks through Machine Learning Models](https://blackhat.com/asia-24/briefings/schedule/#confused-learning-supply-chain-attacks-through-machine-learning-models-37794)
## MLSecOps pipeline
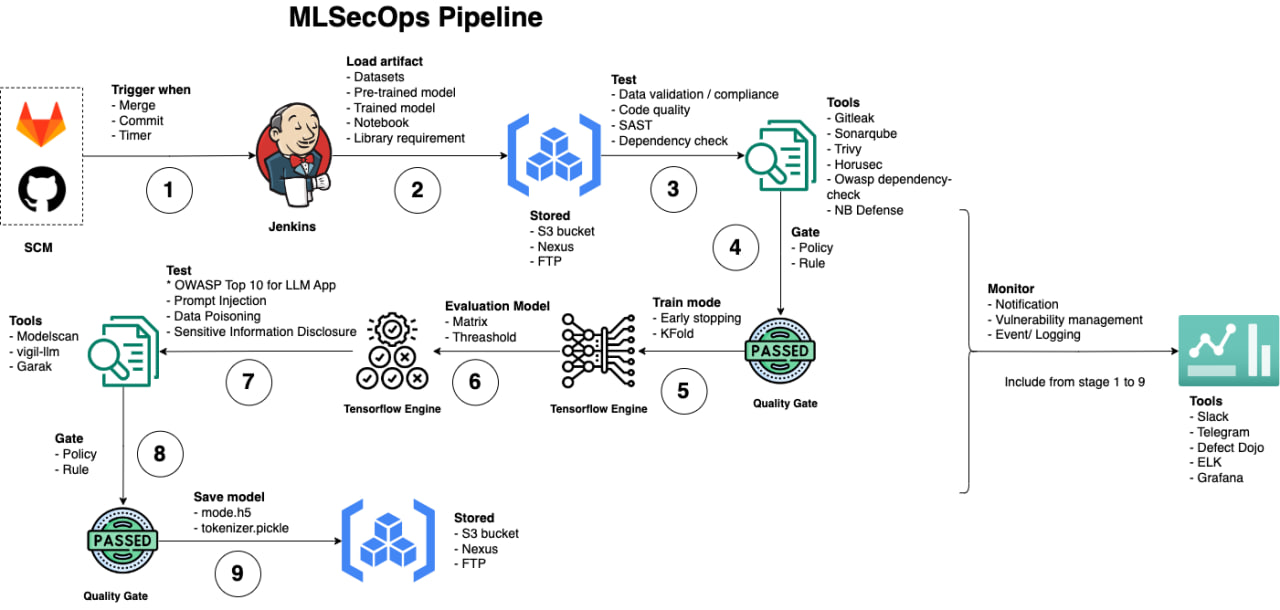
# 学术 Po(C)ker FACE
## 代码库
#### [AgentPoison](https://github.com/BillChan226/AgentPoison)
《AgentPoison: Red-teaming LLM Agents via Memory or Knowledge Base Backdoor Poisoning》的官方实现。该项目探索了在 LLM agent 中进行数据投毒和后门插入的方法,以评估其抵御此类攻击的能力。
#### [DeepPayload](https://github.com/yuanchun-li/DeepPayload)
关于将恶意 payload 嵌入深度神经网络的方法研究。
#### [backdoor](https://github.com/bolunwang/backdoor)
针对深度学习模型的后门攻击调查,重点在于在模型内部创建无法检测的漏洞。
#### [Stealing_DL_Models](https://github.com/jeiks/Stealing_DL_Models)
通过多种攻击向量窃取深度学习模型的技术,使攻击者能够复制或访问模型。
#### [datafree-model-extraction](https://github.com/cake-lab/datafree-model-extraction)
无需使用数据即可进行模型提取,允许在没有原始数据访问权限的情况下恢复模型。
#### [LLMmap](https://github.com/pasquini-dario/LLMmap)
用于映射和分析大语言模型 (LLM) 的工具,探索各种 LLM 的结构和行为。
#### [GoogleCloud-Federated-ML-Pipeline](https://github.com/raj200501/GoogleCloud-Federated-ML-Pipeline)
使用 Google Cloud 基础设施的联邦学习 pipeline,支持在分布式数据上进行模型训练。
#### [Class_Activation_Mapping_Ensemble_Attack](https://github.com/DreamyRainforest/Class_Activation_Mapping_Ensemble_Attack)
使用集成类激活图的攻击,通过操纵激活图在模型中引入错误。
#### [COLD-Attack](https://github.com/Yu-Fangxu/COLD-Attack)
在各种条件和约束下攻击深度模型的方法,侧重于创建更具弹性的攻击。
#### [pal](https://github.com/chawins/pal)
关于机器学习模型自适应攻击的研究,能够创建可适应模型防御的攻击。
#### [ZeroShotKnowledgeTransfer](https://github.com/polo5/ZeroShotKnowledgeTransfer)
Zero-shot 场景下的知识转移,探索在没有目标数据事先训练的情况下在模型之间转移知识的方法。
#### [GMI-Attack](https://github.com/AI-secure/GMI-Attack)
用于生成信息丰富标签的攻击,旨在隐蔽地从训练好的模型中提取数据。
#### [Knowledge-Enriched-DMI](https://github.com/SCccc21/Knowledge-Enriched-DMI)
利用额外的知识增强 DMI(数据挖掘与整合)方法,以提高准确性和效率。
#### [vmi](https://github.com/wangkua1/vmi)
关于可视化和解释机器学习模型方法的研究,提供对模型工作原理的洞察。
#### [Plug-and-Play-Attacks](https://github.com/LukasStruppek/Plug-and-Play-Attacks)
无需修改模型即可“即插即用”的攻击,提供灵活且通用的攻击方法。
#### [snap-sp23](https://github.com/johnmath/snap-sp23)
用于分析和处理快照数据的工具,支持高效处理数据快照。
#### [privacy-vs-robustness](https://github.com/inspire-group/privacy-vs-robustness)
关于模型中隐私与鲁棒性之间权衡的研究,旨在平衡机器学习中的这两个方面。
#### [ML-Leaks](https://github.com/AhmedSalem2/ML-Leaks)
从训练模型中提取数据的方法,探索从机器学习模型中获取私密信息的方式。
#### [BlindMI](https://github.com/hyhmia/BlindMI)
关于盲信息提取攻击的研究,允许在无法访问模型内部结构的情况下进行数据检索。
#### [python-DP-DL](https://github.com/NNToan-apcs/python-DP-DL)
用于深度学习的差分隐私方法,确保模型训练期间的数据隐私。
#### [MMD-mixup-Defense](https://github.com/colaalex111/MMD-mixup-Defense)
使用 MMD-mixup 的防御方法,旨在提高模型抵御攻击的鲁棒性。
#### [MemGuard](https://github.com/jinyuan-jia/MemGuard)
防止内存受攻击的工具,探索防止模型内存数据泄露的方法。
#### [unsplit](https://github.com/ege-erdogan/unsplit)
用于合并和拆分数据以改善训练的方法,优化模型中异构数据的使用。
#### [face_attribute_attack](https://github.com/koushiksrivats/face_attribute_attack)
利用属性对人脸识别模型进行的攻击,探索操纵面部属性以诱发错误的方法。
#### [FVB](https://github.com/Sanjana-Sarda/FVB)
针对人脸验证模型的攻击,旨在破坏基于人脸识别的认证系统。
#### [Malware-GAN](https://github.com/yanminglai/Malware-GAN)
使用 GAN 创建恶意软件,探索使用生成式模型生成恶意代码的方法。
#### [Generative_Adversarial_Perturbations](https://github.com/OmidPoursaeed/Generative_Adversarial_Perturbations)
使用生成式模型生成对抗性扰动的方法,旨在在深度模型中引入错误。
#### [Adversarial-Attacks-with-Relativistic-AdvGAN](https://github.com/GiorgosKarantonis/Adversarial-Attacks-with-Relativistic-AdvGAN)
使用 Relativistic AdvGAN 进行对抗性攻击,探索创建更逼真和有效攻击的方法。
#### [llm-attacks](https://github.com/llm-attacks/llm-attacks)
针对大语言模型的攻击,探索 LLM 的漏洞及其保护方法。
#### [LLMs-Finetuning-Safety](https://github.com/LLM-Tuning-Safety/LLMs-Finetuning-Safety)
大语言模型的安全微调,旨在防止数据泄露并确保 LLM 调整期间的安全性。
#### [DecodingTrust](https://github.com/AI-secure/DecodingTrust)
评估模型可信度的方法,探索确定机器学习模型可靠性和安全性的方法。
#### [promptbench](https://github.com/microsoft/promptbench)
用于评估 prompt 的基准,提供测试和优化针对大语言模型查询的工具。
#### [rome](https://github.com/kmeng01/rome)
基于 ROM 代码分析和评估模型的工具,探索模型性能和弹性的各个方面。
#### [llmprivacy](https://github.com/eth-sri/llmprivacy)
关于大语言模型隐私的研究,旨在保护数据并防止 LLM 泄露。
## 社区资源
- [MLSecOps](https://mlsecops.com/)
- [MLSecOps Podcast](https://mlsecops.com/podcast)
- [MITRE ATLAS™](https://atlas.mitre.org/) 和 [SLACK 社区](https://join.slack.com/t/mitreatlas/shared_invite/zt-10i6ka9xw-~dc70mXWrlbN9dfFNKyyzQ)
- [MlSecOps 社区](https://mlsceops.com) 和 [SLACK 社区](https://mlsecops.slack.com/)
- [MITRE ATLAS™ (人工智能系统的对抗性威胁全景)](https://atlas.mitre.org/)
- [OWASP AI Exchange](https://owaspai.org)
- [OWASP 机器学习安全 Top Ten](https://owasp.org/www-project-machine-learning-security-top-10/)
- [大语言模型应用的 OWASP Top 10](https://owasp.org/www-project-top-10-for-large-language-model-applications/)
- [OWASP LLMSVS](https://owasp.org/www-project-llm-verification-standard/)
- [OWASP AI 安全元素周期表](https://owaspai.org/goto/periodictable/)
- [OWASP SLACK](https://owasp.org/slack/invite)
- [Awesome LLM Security](https://github.com/corca-ai/awesome-llm-security)
- [Hackstery](https://hackstery.com/)
- [PWNAI](https://t.me/pwnai)
- [AiSec_X_Feed](https://t.me/aisecnews)
- [HUNTR Discord 社区](https://discord.com/invite/GBmmty82CM)
- [AIRSK](https://airisk.io)
- [AI 漏洞数据库](https://avidml.org/)
- [AI 事件数据库](https://incidentdatabase.ai/)
- [Defcon AI Village CTF](https://www.kaggle.com/competitions/ai-village-ctf/overview)
- [Awesome AI Security](https://github.com/ottosulin/awesome-ai-security)
- [MLSecOps 参考代码库](https://github.com/disesdi/mlsecops_references)
- [Awesome LVLM Attack](https://github.com/liudaizong/Awesome-LVLM-Attack)
- [Awesome MLLM Safety](https://github.com/isXinLiu/Awesome-MLLM-Safety)
## 书籍
- [《对抗性 AI 攻击、缓解和防御策略:网络安全专业人员关于 AI 攻击、威胁建模以及使用 MLSecOps 保护 AI 的指南》](https://www.amazon.com/Adversarial-Attacks-Mitigations-Defense-Strategies/dp/1835087981)
- [《隐私保护机器学习》](https://www.ebooks.com/en-cg/book/211334202/privacy-preserving-machine-learning/srinivasa-rao-aravilli/)
- [《生成式 AI 安全:理论与实践(商业与金融的未来)》](https://www.amazon.com/Generative-AI-Security-Theories-Practices/dp/3031542517)
## 信息图表
### MLSecOps 生命周期
[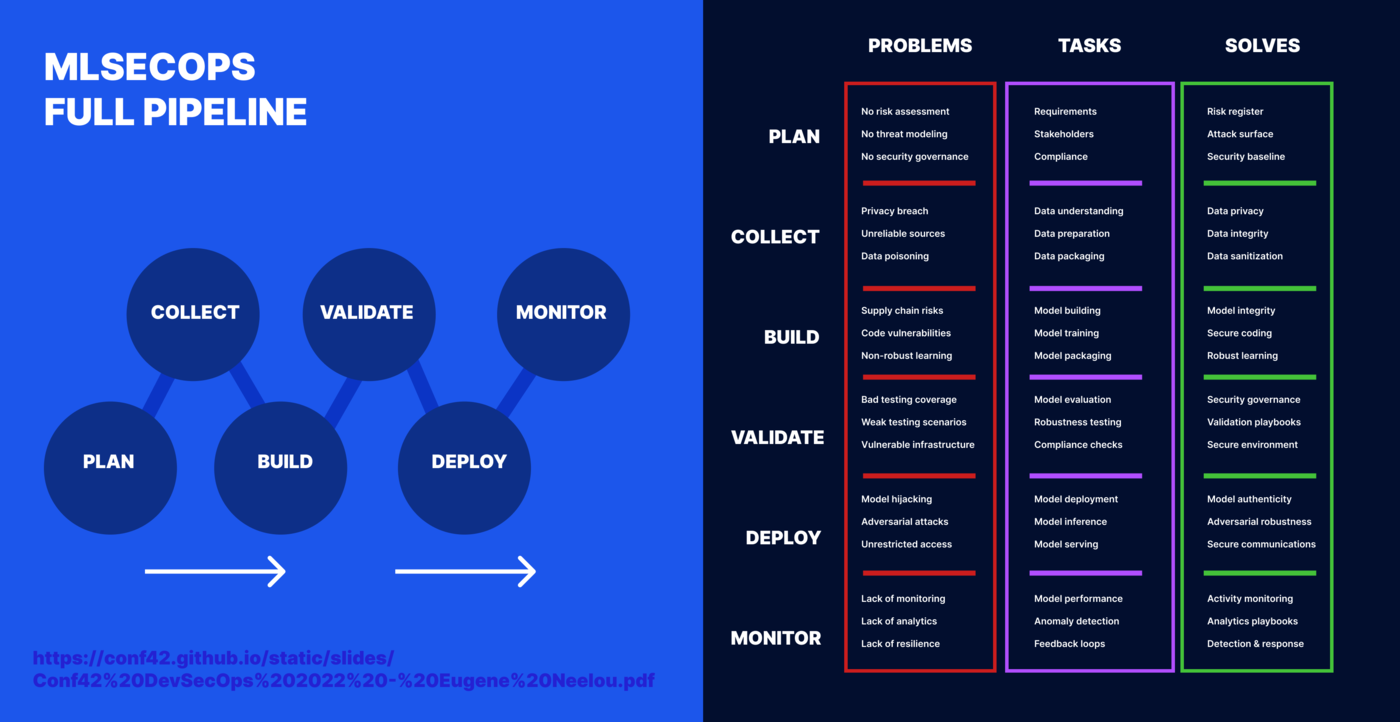](https://www.conf42.com/DevSecOps_2022_Eugene_Neelou_ai_introducing_mlsecops_for_software_20)
### AI 安全市场图谱
[](https://menlovc.com/perspective/security-for-ai-genai-risks-and-the-emerging-startup-landscape/)
## 贡献
欢迎对此列表进行任何贡献!请随时提交包含任何添加或改进的 pull request。
## 贡献者 ✨
## 仓库统计






## 活动


## 支持我们
如果你觉得这个项目有用,请考虑给它点个 Star ⭐️
[](https://github.com/sponsors/RiccardoBiosas)
## 许可证
该项目基于 MIT License 授权 - 详情请参阅 [LICENSE](LICENSE) 文件。
[](https://choosealicense.com/licenses/mit/)
 @riccardobiosas |
 @badarahmed |
 @deadbits |
 @wearetyomsmnv |
 @anmorgan24 |
 @mik0w |
 @alexcombessie |
 @Igralino |
 @typpo |
 @robvanderveer |
Made with ❤️
标签:Apex, C2, MLOps, NoSQL, 人工智能安全, 凭据扫描, 合规性, 机器学习, 逆向工具