openai/whisper
GitHub: openai/whisper
OpenAI 开源的基于大规模弱监督训练的多语种语音识别模型,支持语音转录、翻译、语种识别等多任务。
Stars: 105385 | Forks: 12803
# Whisper
[[博客]](https://openai.com/blog/whisper)
[[论文]](https://arxiv.org/abs/2212.04356)
[[模型卡片]](https://github.com/openai/whisper/blob/main/model-card.md)
[[Colab 示例]](https://colab.research.google.com/github/openai/whisper/blob/master/notebooks/LibriSpeech.ipynb)
Whisper 是一个通用的语音识别模型。它在包含多种音频的大型数据集上进行了训练,同时也是一个多任务模型,可以执行多语种语音识别、语音翻译和语种识别。
## 方法
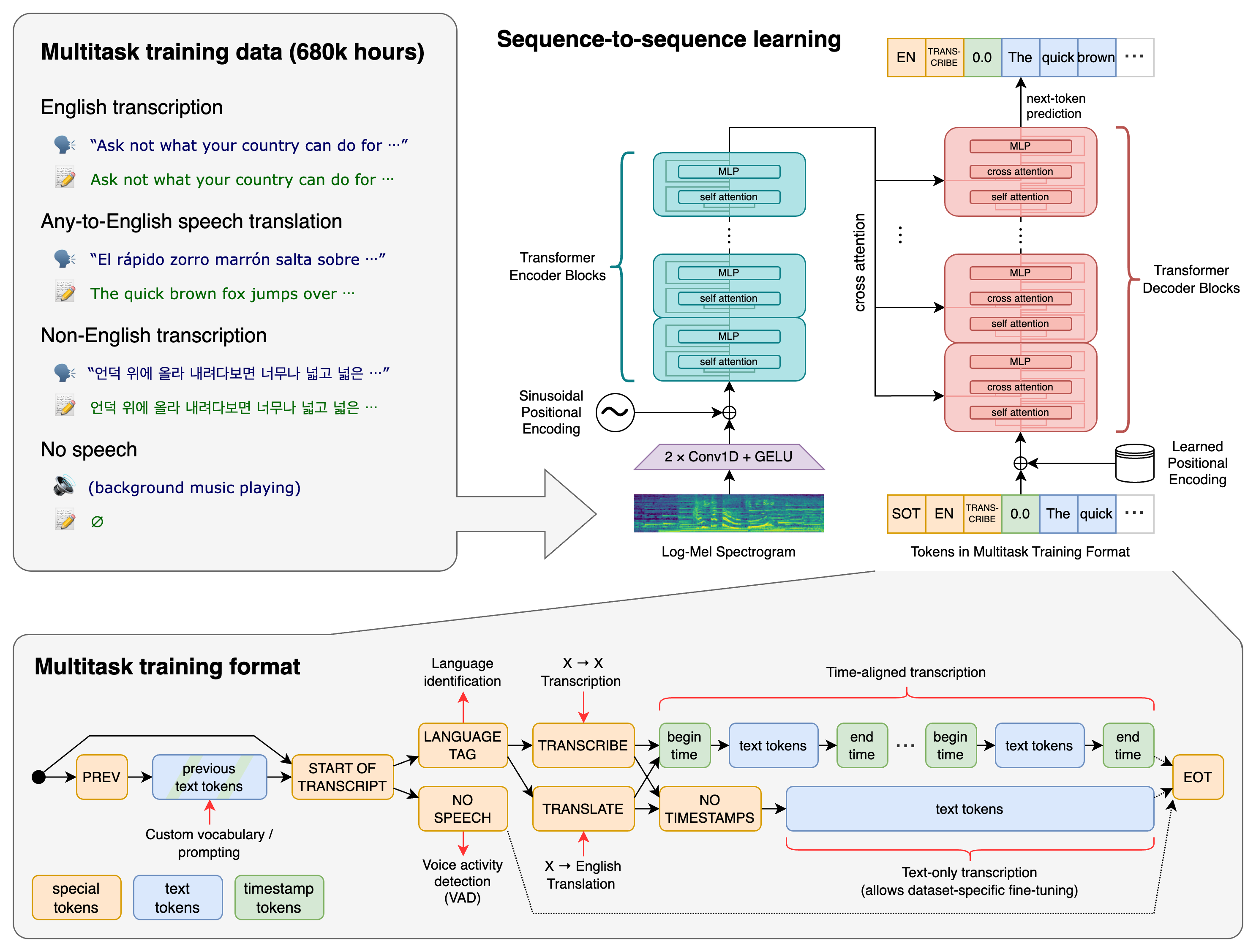
一个 Transformer 序列到序列(sequence-to-sequence)模型在各种语音处理任务上进行了训练,包括多语种语音识别、语音翻译、口语语种识别和语音活动检测。这些任务被联合表示为由解码器预测的一系列 token,从而允许单个模型取代传统语音处理 pipeline 中的许多阶段。多任务训练格式使用一组特殊 token 作为任务指定符或分类目标。
## 安装说明
我们使用 Python 3.9.9 和 [PyTorch](https://pytorch.org/) 1.10.1 来训练和测试我们的模型,但代码库预期兼容 Python 3.8-3.11 以及最新的 PyTorch 版本。该代码库还依赖于几个 Python 包,其中最著名的是 [OpenAI 的 tiktoken](https://github.com/openai/tiktoken),用于其快速的 tokenizer 实现。你可以使用以下命令下载并安装(或更新到)最新版本的 Whisper:
```
pip install -U openai-whisper
```
或者,以下命令将从该仓库拉取并安装最新的提交,及其 Python 依赖项:
```
pip install git+https://github.com/openai/whisper.git
```
要将此包更新到该仓库的最新版本,请运行:
```
pip install --upgrade --no-deps --force-reinstall git+https://github.com/openai/whisper.git
```
它还要求你的系统上安装了命令行工具 [`ffmpeg`](https://ffmpeg.org/),该工具可以从大多数包管理器中获取:
```
# 在 Ubuntu 或 Debian 上
sudo apt update && sudo apt install ffmpeg
# 在 Arch Linux 上
sudo pacman -S ffmpeg
# 在 MacOS 上使用 Homebrew (https://brew.sh/)
brew install ffmpeg
# 在 Windows 上使用 Chocolatey (https://chocolatey.org/)
choco install ffmpeg
# 在 Windows 上使用 Scoop (https://scoop.sh/)
scoop install ffmpeg
```
如果 [tiktoken](https://github.com/openai/tiktoken) 没有为你的平台提供预编译的 wheel,你可能还需要安装 [`rust`](http://rust-lang.org)。如果你在上面的 `pip install` 命令中看到安装错误,请按照[入门页面](https://www.rust-lang.org/learn/get-started)安装 Rust 开发环境。此外,你可能需要配置 `PATH` 环境变量,例如 `export PATH="$HOME/.cargo/bin:$PATH"`。如果安装失败并提示 `No module named 'setuptools_rust'`,你需要安装 `setuptools_rust`,例如通过运行以下命令:
```
pip install setuptools-rust
```
## 可用的模型和语言
共有六种模型大小,其中四种提供仅限英文的版本,以供在速度和准确性之间进行权衡。
以下是可用模型的名称、它们的大致内存需求,以及相对于 large 模型的推理速度。
下方的相对速度是通过在 A100 上转录英文语音来测量的,实际速度可能会因语言、语速和可用硬件等多种因素而有很大差异。
| 大小 | 参数量 | 仅英文模型 | 多语种模型 | 所需显存 | 相对速度 |
|:------:|:----------:|:------------------:|:------------------:|:-------------:|:--------------:|
| tiny | 39 M | `tiny.en` | `tiny` | ~1 GB | ~10x |
| base | 74 M | `base.en` | `base` | ~1 GB | ~7x |
| small | 244 M | `small.en` | `small` | ~2 GB | ~4x |
| medium | 769 M | `medium.en` | `medium` | ~5 GB | ~2x |
| large | 1550 M | N/A | `large` | ~10 GB | 1x |
| turbo | 809 M | N/A | `turbo` | ~6 GB | ~8x |
对于仅限英文的应用场景,`.en` 模型往往表现更好,特别是 `tiny.en` 和 `base.en` 模型。我们观察到,对于 `small.en` 和 `medium.en` 模型,这种差异变得不那么明显。
此外,`turbo` 模型是 `large-v3` 的优化版本,它提供了更快的转录速度,同时准确性仅有极小下降。
Whisper 的性能在很大程度上取决于语言。下图展示了 `large-v3` 和 `large-v2` 模型按语言划分的性能细分,使用在 Common Voice 15 和 Fleurs 数据集上评估的 WER(词错率)或 CER(字符错率,以*斜体*显示)。与其它模型和数据集对应的 WER/CER 指标可以在[论文](https://arxiv.org/abs/2212.04356)的附录 D.1、D.2 和 D.4 中找到,以及附录 D.3 中用于翻译的 BLEU(Bilingual Evaluation Understudy)分数。

## 命令行用法
以下命令将使用 `turbo` 模型转录音频文件中的语音:
```
whisper audio.flac audio.mp3 audio.wav --model turbo
```
默认设置(选择 `turbo` 模型)非常适合转录英文。但是,**`turbo` 模型并未针对翻译任务进行训练**。如果你需要**将非英文语音翻译成英文**,请使用**多语种模型**(`tiny`、`base`、`small`、`medium`、`large`)之一,而不是 `turbo`。
例如,要转录包含非英文语音的音频文件,你可以指定语言:
```
whisper japanese.wav --language Japanese
```
要将语音**翻译**为英文,请使用:
```
whisper japanese.wav --model medium --language Japanese --task translate
```
运行以下命令查看所有可用选项:
```
whisper --help
```
有关所有可用语言的列表,请参见 [tokenizer.py](https://github.com/openai/whisper/blob/main/whisper/tokenizer.py)。
## Python 用法
转录也可以在 Python 中执行:
```
import whisper
model = whisper.load_model("turbo")
result = model.transcribe("audio.mp3")
print(result["text"])
```
在内部,`transcribe()` 方法会读取整个文件,并使用滑动的 30 秒窗口处理音频,在每个窗口上执行自回归的序列到序列预测。
以下是 `whisper.detect_language()` 和 `whisper.decode()` 的使用示例,它们提供了对模型的更低层级访问。
```
import whisper
model = whisper.load_model("turbo")
# 加载音频并进行填充/裁剪以适应 30 秒
audio = whisper.load_audio("audio.mp3")
audio = whisper.pad_or_trim(audio)
# 生成 log-Mel spectrogram 并移动到与模型相同的设备
mel = whisper.log_mel_spectrogram(audio, n_mels=model.dims.n_mels).to(model.device)
# 检测 spoken language
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")
# 解码音频
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)
# 打印识别出的文本
print(result.text)
```
## 更多示例
请在 Discussions 的 [🙌 展示与分享](https://github.com/openai/whisper/discussions/categories/show-and-tell)类别中分享更多关于 Whisper 的示例用法以及第三方扩展,例如 Web 演示、与其他工具的集成、针对不同平台的移植等。
## 许可证
Whisper 的代码和模型权重在 MIT 许可证下发布。有关更多详细信息,请参见 [LICENSE](https://github.com/openai/whisper/blob/main/LICENSE)。
标签:AI大模型, Apex, ASR, NLP, OpenAI, Python, PyTorch, Transformer, VAD, Whisper, 人工智能, 内存规避, 凭据扫描, 可视化界面, 声学模型, 多任务学习, 多语言识别, 大模型, 序列到序列模型, 开源模型, 弱监督学习, 文本转写, 无后门, 机器学习, 深度学习, 深度神经网络, 用户模式Hook绕过, 自动语音识别, 语言检测, 语音技术, 语音翻译, 语音识别, 语音转文本, 跨语言处理, 逆向工具, 音频处理