tracel-ai/burn
GitHub: tracel-ai/burn
Burn 是一个用 Rust 编写的下一代张量库和深度学习框架,在灵活性、效率和可移植性上兼顾训练与推理全流程,支持从嵌入式设备到 GPU 集群的多种后端。
Stars: 15488 | Forks: 952
 [](https://discord.gg/uPEBbYYDB6)
[](https://crates.io/crates/burn)
[](https://crates.io/crates/burn)
[](https://burn.dev/docs/burn)
[](https://github.com/tracel-ai/burn/actions/workflows/test.yml)
[](#license)
[](https://deepwiki.com/tracel-ai/burn)
[
[](https://discord.gg/uPEBbYYDB6)
[](https://crates.io/crates/burn)
[](https://crates.io/crates/burn)
[](https://burn.dev/docs/burn)
[](https://github.com/tracel-ai/burn/actions/workflows/test.yml)
[](#license)
[](https://deepwiki.com/tracel-ai/burn)
[ ](https://www.runblaze.dev)
**Burn 是下一代张量库和深度学习框架,在
](https://www.runblaze.dev)
**Burn 是下一代张量库和深度学习框架,在
灵活性、效率和可移植性上毫不妥协。**
Burn 既是一个张量库,也是一个为数值计算、模型推理和模型训练优化的深度学习框架。Burn 利用 Rust 来执行通常只有在静态图框架中才有的优化,在不影响灵活性的前提下提供极致的速度。
## 后端
 Burn 致力于在尽可能多的硬件上以尽可能快的速度运行,并提供稳健的实现。我们相信这种灵活性对于现代需求至关重要,因为您可能在云端训练模型,然后部署到因用户而异的客户硬件上。
### 支持的后端
大多数后端支持所有操作系统,因此我们在下表中没有提及它们。
**GPU 后端:**
| | CUDA | ROCm | Metal | Vulkan | WebGPU | LibTorch |
| ------- | ---- | ---- | ----- | ------ | ------ | -------- |
| Nvidia | ☑️ | - | - | ☑️ | ☑️ | ☑️ |
| AMD | - | ☑️ | - | ☑️ | ☑️ | ☑️ |
| Apple | - | - | ☑️ | - | ☑️ | ☑️ |
| Intel | - | - | - | ☑️ | ☑️ | - |
| Qualcom | - | - | - | ☑️ | ☑️ | - |
| Wasm | - | - | - | - | ☑️ | - |
**CPU 后端:**
| | Cpu (CubeCL) | Flex | LibTorch |
| ------ | ------------ | ---- | -------- |
| X86 | ☑️ | ☑️ | ☑️ |
| Arm | ☑️ | ☑️ | ☑️ |
| Wasm | - | ☑️ | - |
| no-std | - | ☑️ | - |
Burn 致力于在尽可能多的硬件上以尽可能快的速度运行,并提供稳健的实现。我们相信这种灵活性对于现代需求至关重要,因为您可能在云端训练模型,然后部署到因用户而异的客户硬件上。
### 支持的后端
大多数后端支持所有操作系统,因此我们在下表中没有提及它们。
**GPU 后端:**
| | CUDA | ROCm | Metal | Vulkan | WebGPU | LibTorch |
| ------- | ---- | ---- | ----- | ------ | ------ | -------- |
| Nvidia | ☑️ | - | - | ☑️ | ☑️ | ☑️ |
| AMD | - | ☑️ | - | ☑️ | ☑️ | ☑️ |
| Apple | - | - | ☑️ | - | ☑️ | ☑️ |
| Intel | - | - | - | ☑️ | ☑️ | - |
| Qualcom | - | - | - | ☑️ | ☑️ | - |
| Wasm | - | - | - | - | ☑️ | - |
**CPU 后端:**
| | Cpu (CubeCL) | Flex | LibTorch |
| ------ | ------------ | ---- | -------- |
| X86 | ☑️ | ☑️ | ☑️ |
| Arm | ☑️ | ☑️ | ☑️ |
| Wasm | - | ☑️ | - |
| no-std | - | ☑️ | - |
与其他框架相比,Burn 在支持多种后端方面采用了一种截然不同的方法。根据设计,大部分代码对于 Backend trait 是通用的,这使我们能够使用可互换的后端来构建 Burn。这使得组合后端成为可能,通过添加自动微分和自动内核融合等额外功能来增强它们。
与前面提到的后端相反,Autodiff 实际上是一个后端 _装饰器_。这意味着它不能单独存在;它必须封装另一个后端。 使用 Autodiff 包装基础后端的简单操作会透明地为其配备自动微分支持,从而使得在您的模型上调用 backward 成为可能。 ``` use burn::backend::{Autodiff, Wgpu}; use burn::tensor::{Distribution, Tensor}; fn main() { type Backend = Autodiff;
let device = Default::default();
let x: Tensor = Tensor::random([32, 32], Distribution::Default, &device);
let y: Tensor = Tensor::random([32, 32], Distribution::Default, &device).require_grad();
let tmp = x.clone() + y.clone();
let tmp = tmp.matmul(x);
let tmp = tmp.exp();
let grads = tmp.backward();
let y_grad = y.grad(&grads).unwrap();
println!("{y_grad}");
}
```
值得注意的是,在不支持 autodiff 的后端(用于推理)上运行的模型调用 backward 是不可能出错的,因为此方法仅由 Autodiff 后端提供。
有关更多详细信息,请参阅 [Autodiff 后端 README](./crates/burn-autodiff/README.md)。
如果内部后端支持内核融合,此装饰器将通过内核融合来增强该后端。请注意,您可以将此后端与其他后端装饰器(例如 Autodiff)组合使用。 所有第一方加速后端(如 WGPU 和 CUDA)默认使用 Fusion(`burn/fusion` feature flag),因此您通常不需要手动应用它。 ``` #[cfg(not(feature = "fusion"))] pub type Cuda = CubeBackend;
#[cfg(feature = "fusion")]
pub type Cuda = burn_fusion::Fusion>;
```
值得注意的是,我们计划基于计算密集型和内存密集型操作来实现自动梯度检查点,这将与 Fusion 后端完美配合,使您的代码在训练期间运行得更快,请参阅[此 issue](https://github.com/tracel-ai/burn/issues/936)。
有关更多详细信息,请参阅 [Fusion 后端 README](./crates/burn-fusion/README.md)。
该后端简化了硬件互操作性,例如,如果您想在 CPU 上执行某些操作而在 GPU 上执行其他操作。 ``` use burn::tensor::{Distribution, Tensor}; use burn::backend::{ Flex, Router, Wgpu, flex::FlexDevice, router::duo::MultiDevice, wgpu::WgpuDevice, }; fn main() { type Backend = Router<(Wgpu, Flex)>; let device_0 = MultiDevice::B1(WgpuDevice::DiscreteGpu(0)); let device_1 = MultiDevice::B2(FlexDevice); let tensor_gpu = Tensor::::random([3, 3], burn::tensor::Distribution::Default, &device_0);
let tensor_cpu =
Tensor::::random([3, 3], burn::tensor::Distribution::Default, &device_1);
}
```
该后端分为两部分:客户端和服务器。客户端通过网络将张量操作发送到远程计算后端。您只需一行代码即可使用任何第一方后端作为服务器: ``` fn main_server() { // Start a server on port 3000. burn::server::start::(Default::default(), 3000);
}
fn main_client() {
// Create a client that communicate with the server on port 3000.
use burn::backend::{Autodiff, RemoteBackend};
type Backend = Autodiff;
let device = RemoteDevice::new("ws://localhost:3000");
let tensor_gpu =
Tensor::::random([3, 3], Distribution::Default, &device);
}
```
## 训练与推理
 Burn 让整个深度学习工作流程变得简单,您可以通过人性化的仪表板监控训练进度,并在从嵌入式设备到大型 GPU 集群的任何地方运行推理。
Burn 从一开始就是在考虑训练和推理的情况下构建的。同样值得注意的是,与 PyTorch 等框架相比,Burn 如何简化从训练到部署的过渡,无需修改任何代码。
Burn 让整个深度学习工作流程变得简单,您可以通过人性化的仪表板监控训练进度,并在从嵌入式设备到大型 GPU 集群的任何地方运行推理。
Burn 从一开始就是在考虑训练和推理的情况下构建的。同样值得注意的是,与 PyTorch 等框架相比,Burn 如何简化从训练到部署的过渡,无需修改任何代码。
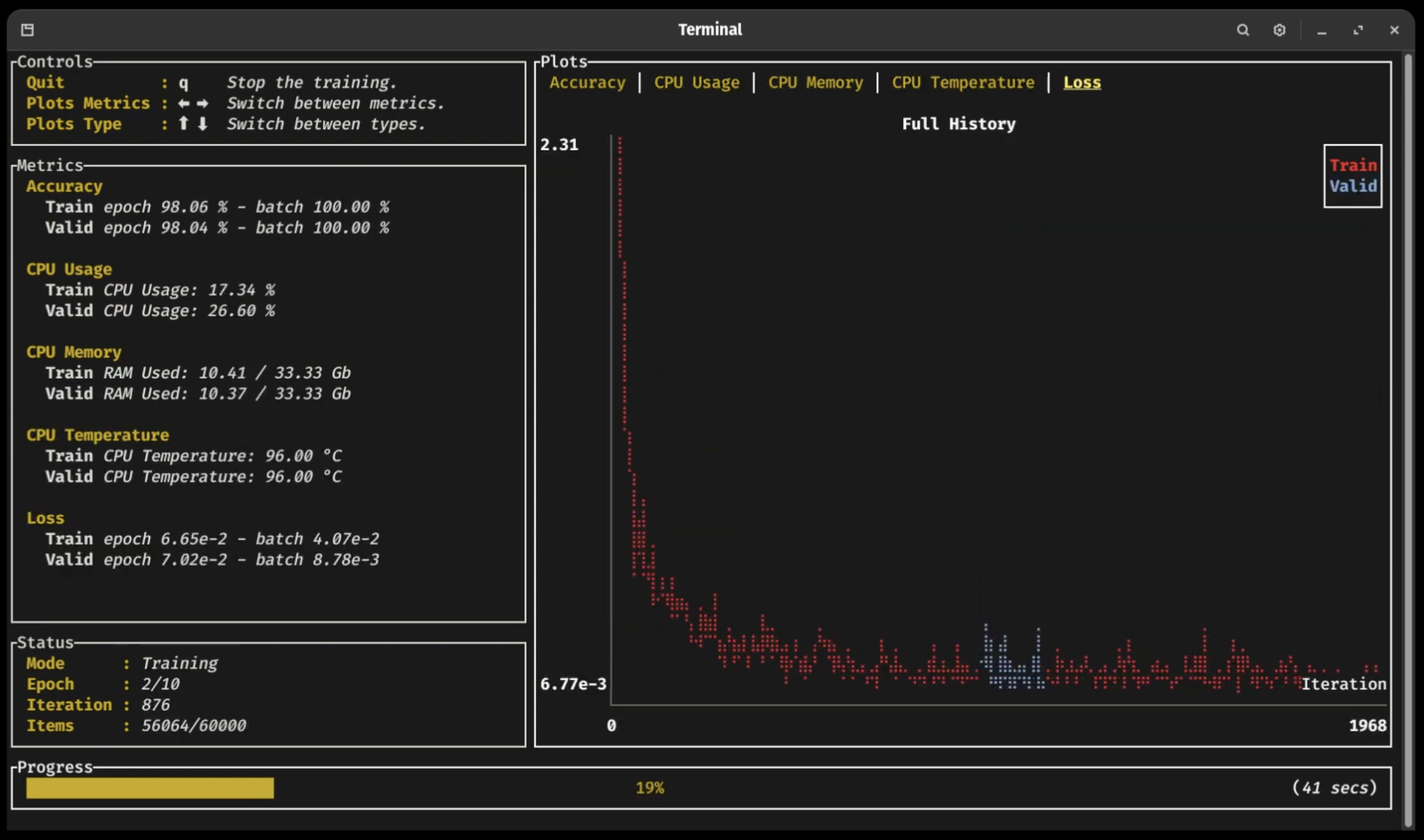
**点击以下部分展开 👇**
正如您在之前的视频中所见(点击图片!),一个基于 [Ratatui](https://github.com/ratatui-org/ratatui) crate 的全新终端 UI 仪表板允许用户轻松地跟进他们的训练过程,而无需连接任何外部应用程序。 您可以实时查看训练和验证指标的更新,并仅使用方向键分析任何已注册指标的长期进展或近期历史。可以在不崩溃的情况下中断训练循环,从而确保潜在的检查点被完全写入或重要的代码段无中断地完成 🛡
Burn 支持通过 [burn-onnx](https://github.com/tracel-ai/burn-onnx) crate 导入 ONNX(开放神经网络交换)模型,允许您轻松地将 TensorFlow 或 PyTorch 模型移植到 Burn。ONNX 模型被转换为使用 Burn 原生 API 的 Rust 代码,使导入的模型能够在任何 Burn 后端(CPU、GPU、WebAssembly)上运行,并受益于 Burn 的所有优化,例如自动内核融合。 我们的 ONNX 支持在 [Burn 书籍的此部分 🔥](https://burn.dev/books/burn/onnx-import.html) 中有进一步描述。
您可以将 PyTorch 或 Safetensors 格式的权重直接加载到您用 Burn 定义的模型中。这使得重用现有模型变得容易,同时还能享受 Burn 的性能和部署特性。 在 Burn 书籍的[保存和加载模型](https://burn.dev/books/burn/saving-and-loading.html)部分了解更多信息。
我们的几个后端可以在 WebAssembly 环境中运行:Flex 用于 CPU 执行,WGPU 用于通过 WebGPU 进行 GPU 加速。这意味着您可以直接在浏览器中运行推理。我们提供了以下示例: - [MNIST](./examples/mnist-inference-web),您可以在其中绘制数字,一个小型卷积网络会尝试找出它是哪一个! 2️⃣ 7️⃣ 😰 - [图像分类](https://github.com/tracel-ai/burn-onnx/tree/main/examples/image-classification-web) 您可以在其中上传图像并对它们进行分类! 🌄
Burn 的核心组件支持 [no_std](https://docs.rust-embedded.org/book/intro/no-std.html)。这意味着它可以在裸机环境(例如没有操作系统的嵌入式设备)中运行。
### 基准测试 为了评估不同后端的性能并跟踪随时间的改进,我们提供了一个专门的基准测试套件。 使用 [burn-bench](https://github.com/tracel-ai/burn-bench) 运行和比较基准测试。 ## 入门指南
 刚听说 Burn?您来对地方了!继续阅读本节,希望您能很快上手。
刚听说 Burn?您来对地方了!继续阅读本节,希望您能很快上手。
为了有效地开始使用 Burn,了解其关键组件和理念至关重要。这就是为什么我们强烈建议新用户阅读 [Burn 书籍 🔥](https://burn.dev/books/burn/) 的前几部分。它提供了涵盖框架各个方面的详细示例和解释,包括诸如张量、模块和优化器等基础构建块,一直到高级用法,例如编写您自己的 GPU 内核。
让我们从一个代码片段开始,展示该框架使用起来是多么直观!在下面的代码中,我们声明了一个带有一些参数的神经网络模块及其前向传播。 ``` use burn::nn; use burn::module::Module; use burn::tensor::backend::Backend; #[derive(Module, Debug)] pub struct PositionWiseFeedForward {
linear_inner: nn::Linear,
linear_outer: nn::Linear,
dropout: nn::Dropout,
gelu: nn::Gelu,
}
impl PositionWiseFeedForward {
pub fn forward(&self, input: Tensor) -> Tensor {
let x = self.linear_inner.forward(input);
let x = self.gelu.forward(x);
let x = self.dropout.forward(x);
self.linear_outer.forward(x)
}
}
```
我们在仓库中提供了相当多的[示例](./examples),展示了如何在不同场景下使用该框架。
跟随[本书](https://burn.dev/books/burn/):
- [基本工作流](./examples/guide):创建一个自定义 CNN `Module`,在 MNIST 数据集上进行训练并用于推理。
- [自定义训练循环](./examples/custom-training-loop):实现一个基本的训练循环,而不是使用 `Learner`。
- [自定义 WGPU 内核](./examples/custom-wgpu-kernel):了解如何使用 WGPU 后端创建您的自定义操作。
其他示例:
- [自定义 CSV 数据集](./examples/custom-csv-dataset):实现一个解析 CSV 数据以进行回归任务的数据集。
- [回归](./examples/simple-regression):在 California Housing 数据集上训练一个简单的 MLP,以预测某个区域房屋的中位数价值。
- [自定义图像数据集](./examples/custom-image-dataset):遵循简单的文件夹结构,在自定义图像数据集上训练一个简单的 CNN。
- [自定义渲染器](./examples/custom-renderer):实现一个自定义渲染器以显示 [`Learner`](./building-blocks/learner.md) 的进度。
- [图像分类 Web](./examples/image-classification-web):使用 Burn、WGPU 和 WebAssembly 的图像分类网络浏览器演示。
- [Web 上的 MNIST 推理](./examples/mnist-inference-web):浏览器中的交互式 MNIST 推理演示。该演示可[在线](https://burn.dev/demo/)获取。
- [MNIST 训练](./examples/mnist):演示如何使用配置了日志指标和保留训练检查点的 `Learner` 来训练自定义 `Module` (MLP)。
- [PyTorch 导入推理](./examples/import-model-weights):导入在 MNIST 上预训练的 PyTorch 模型,以使用 Burn 对样本图像执行推理。
- [文本分类](./examples/text-classification):在 AG News 或 DbPedia 数据集上训练文本分类 transformer 模型。训练后的模型随后可用于对文本样本进行分类。
- [文本生成](./examples/text-generation):在 DbPedia 数据集上训练文本生成 transformer 模型。
- [Wasserstein GAN MNIST](./examples/wgan):训练 WGAN 模型以基于 MNIST 生成新的手写数字。
为了获得更多实践见解,您可以克隆仓库并在您的计算机上直接运行它们中的任何一个!
我们维护了一份最新且精选的、使用 Burn 构建的模型和示例列表,有关更多详细信息,请参见 [tracel-ai/models 仓库](https://github.com/tracel-ai/models)。 没有看到您想要的模型?请毫不犹豫地提出 issue,我们可能会优先考虑它。使用 Burn 构建了模型并想分享它?您也可以提出 Pull Request 并将您的模型添加到社区部分!
深度学习是一种特殊形式的软件,您既需要非常高级的抽象,又需要极快的执行时间。Rust 是满足这一用例的完美候选者,因为它提供了零成本抽象来轻松创建神经网络模块,以及用于优化每个细节的细粒度内存控制。 框架在高层级上易于使用非常重要,这样其用户就可以专注于在 AI 领域进行创新。然而,由于运行模型非常依赖计算,性能是不容忽视的。 迄今为止,解决此问题的主流方案是提供 Python API,但依赖于对 C/C++ 等低级语言的绑定。这降低了可移植性,增加了复杂性,并在研究人员和工程师之间产生了摩擦。我们感觉 Rust 对待抽象的方式使其足够灵活,足以应对这种双语言二分法。 Rust 还附带了 Cargo 包管理器,这使得在任何环境中进行构建、测试和部署变得异常简单,而这 Python 中通常是一件痛苦的事。 尽管 Rust 有起初难度较高的名声,但我们坚信它能带来更可靠、无 bug 的解决方案,并且构建速度更快(经过一些练习 😅)!
Burn 致力于在尽可能多的硬件上以尽可能快的速度运行,并提供稳健的实现。我们相信这种灵活性对于现代需求至关重要,因为您可能在云端训练模型,然后部署到因用户而异的客户硬件上。
与其他框架相比,Burn 在支持多种后端方面采用了一种截然不同的方法。根据设计,大部分代码对于 Backend trait 是通用的,这使我们能够使用可互换的后端来构建 Burn。这使得组合后端成为可能,通过添加自动微分和自动内核融合等额外功能来增强它们。
Autodiff:为任何后端带来反向传播的后端装饰器 🔄
与前面提到的后端相反,Autodiff 实际上是一个后端 _装饰器_。这意味着它不能单独存在;它必须封装另一个后端。 使用 Autodiff 包装基础后端的简单操作会透明地为其配备自动微分支持,从而使得在您的模型上调用 backward 成为可能。 ``` use burn::backend::{Autodiff, Wgpu}; use burn::tensor::{Distribution, Tensor}; fn main() { type Backend = Autodiff
Fusion:为所有第一方后端带来内核融合的后端装饰器
如果内部后端支持内核融合,此装饰器将通过内核融合来增强该后端。请注意,您可以将此后端与其他后端装饰器(例如 Autodiff)组合使用。 所有第一方加速后端(如 WGPU 和 CUDA)默认使用 Fusion(`burn/fusion` feature flag),因此您通常不需要手动应用它。 ``` #[cfg(not(feature = "fusion"))] pub type Cuda
Router (Beta):将多个后端组合成一个的后端装饰器
该后端简化了硬件互操作性,例如,如果您想在 CPU 上执行某些操作而在 GPU 上执行其他操作。 ``` use burn::tensor::{Distribution, Tensor}; use burn::backend::{ Flex, Router, Wgpu, flex::FlexDevice, router::duo::MultiDevice, wgpu::WgpuDevice, }; fn main() { type Backend = Router<(Wgpu, Flex)>; let device_0 = MultiDevice::B1(WgpuDevice::DiscreteGpu(0)); let device_1 = MultiDevice::B2(FlexDevice); let tensor_gpu = Tensor::
Remote (Beta):用于远程后端执行的后端装饰器,适用于分布式计算
该后端分为两部分:客户端和服务器。客户端通过网络将张量操作发送到远程计算后端。您只需一行代码即可使用任何第一方后端作为服务器: ``` fn main_server() { // Start a server on port 3000. burn::server::start::
## 训练与推理
Burn 让整个深度学习工作流程变得简单,您可以通过人性化的仪表板监控训练进度,并在从嵌入式设备到大型 GPU 集群的任何地方运行推理。
Burn 从一开始就是在考虑训练和推理的情况下构建的。同样值得注意的是,与 PyTorch 等框架相比,Burn 如何简化从训练到部署的过渡,无需修改任何代码。
**点击以下部分展开 👇**
训练仪表板 📈
正如您在之前的视频中所见(点击图片!),一个基于 [Ratatui](https://github.com/ratatui-org/ratatui) crate 的全新终端 UI 仪表板允许用户轻松地跟进他们的训练过程,而无需连接任何外部应用程序。 您可以实时查看训练和验证指标的更新,并仅使用方向键分析任何已注册指标的长期进展或近期历史。可以在不崩溃的情况下中断训练循环,从而确保潜在的检查点被完全写入或重要的代码段无中断地完成 🛡
ONNX 支持 🐫
Burn 支持通过 [burn-onnx](https://github.com/tracel-ai/burn-onnx) crate 导入 ONNX(开放神经网络交换)模型,允许您轻松地将 TensorFlow 或 PyTorch 模型移植到 Burn。ONNX 模型被转换为使用 Burn 原生 API 的 Rust 代码,使导入的模型能够在任何 Burn 后端(CPU、GPU、WebAssembly)上运行,并受益于 Burn 的所有优化,例如自动内核融合。 我们的 ONNX 支持在 [Burn 书籍的此部分 🔥](https://burn.dev/books/burn/onnx-import.html) 中有进一步描述。
导入 PyTorch 或 Safetensors 模型 🚚
您可以将 PyTorch 或 Safetensors 格式的权重直接加载到您用 Burn 定义的模型中。这使得重用现有模型变得容易,同时还能享受 Burn 的性能和部署特性。 在 Burn 书籍的[保存和加载模型](https://burn.dev/books/burn/saving-and-loading.html)部分了解更多信息。
在浏览器中推理 🌐
我们的几个后端可以在 WebAssembly 环境中运行:Flex 用于 CPU 执行,WGPU 用于通过 WebGPU 进行 GPU 加速。这意味着您可以直接在浏览器中运行推理。我们提供了以下示例: - [MNIST](./examples/mnist-inference-web),您可以在其中绘制数字,一个小型卷积网络会尝试找出它是哪一个! 2️⃣ 7️⃣ 😰 - [图像分类](https://github.com/tracel-ai/burn-onnx/tree/main/examples/image-classification-web) 您可以在其中上传图像并对它们进行分类! 🌄
嵌入式:no_std 支持 ⚙️
Burn 的核心组件支持 [no_std](https://docs.rust-embedded.org/book/intro/no-std.html)。这意味着它可以在裸机环境(例如没有操作系统的嵌入式设备)中运行。
### 基准测试 为了评估不同后端的性能并跟踪随时间的改进,我们提供了一个专门的基准测试套件。 使用 [burn-bench](https://github.com/tracel-ai/burn-bench) 运行和比较基准测试。 ## 入门指南
刚听说 Burn?您来对地方了!继续阅读本节,希望您能很快上手。
Burn 书籍 🔥
为了有效地开始使用 Burn,了解其关键组件和理念至关重要。这就是为什么我们强烈建议新用户阅读 [Burn 书籍 🔥](https://burn.dev/books/burn/) 的前几部分。它提供了涵盖框架各个方面的详细示例和解释,包括诸如张量、模块和优化器等基础构建块,一直到高级用法,例如编写您自己的 GPU 内核。
示例 🙏
让我们从一个代码片段开始,展示该框架使用起来是多么直观!在下面的代码中,我们声明了一个带有一些参数的神经网络模块及其前向传播。 ``` use burn::nn; use burn::module::Module; use burn::tensor::backend::Backend; #[derive(Module, Debug)] pub struct PositionWiseFeedForward
预训练模型 🤖
我们维护了一份最新且精选的、使用 Burn 构建的模型和示例列表,有关更多详细信息,请参见 [tracel-ai/models 仓库](https://github.com/tracel-ai/models)。 没有看到您想要的模型?请毫不犹豫地提出 issue,我们可能会优先考虑它。使用 Burn 构建了模型并想分享它?您也可以提出 Pull Request 并将您的模型添加到社区部分!
为什么使用 Rust 进行深度学习? 🦀
深度学习是一种特殊形式的软件,您既需要非常高级的抽象,又需要极快的执行时间。Rust 是满足这一用例的完美候选者,因为它提供了零成本抽象来轻松创建神经网络模块,以及用于优化每个细节的细粒度内存控制。 框架在高层级上易于使用非常重要,这样其用户就可以专注于在 AI 领域进行创新。然而,由于运行模型非常依赖计算,性能是不容忽视的。 迄今为止,解决此问题的主流方案是提供 Python API,但依赖于对 C/C++ 等低级语言的绑定。这降低了可移植性,增加了复杂性,并在研究人员和工程师之间产生了摩擦。我们感觉 Rust 对待抽象的方式使其足够灵活,足以应对这种双语言二分法。 Rust 还附带了 Cargo 包管理器,这使得在任何环境中进行构建、测试和部署变得异常简单,而这 Python 中通常是一件痛苦的事。 尽管 Rust 有起初难度较高的名声,但我们坚信它能带来更可靠、无 bug 的解决方案,并且构建速度更快(经过一些练习 😅)!