lance-format/lance
GitHub: lance-format/lance
面向多模态AI的现代Lakehouse数据格式,提供比Parquet快100倍的随机访问、向量搜索和数据版本控制能力。
Stars: 6654 | Forks: 713
 **面向多模态 AI 的开源 Lakehouse 格式**
**面向多模态 AI 的开源 Lakehouse 格式**
**为 Lakehouse 提供高性能向量搜索、全文搜索、随机访问和特征工程能力。**
**兼容 Pandas、DuckDB、Polars、PyArrow、Ray、Spark,更多集成正在路上。**
文档 •
社区 •
Discord
[![CI Badge]][CI]
[![Docs Badge]][Docs]
[![crates.io badge]][crates.io]
[![Python versions badge]][Python versions]
Lance 是一种面向多模态 AI 的开源 Lakehouse 格式。它包含文件格式、表格式和 Catalog 规范,允许您在对象存储之上构建完整的 Lakehouse,以驱动您的 AI 工作流。Lance 非常适合: 1. 构建具有混合搜索能力的搜索引擎和特征存储。 2. 需要高性能 IO 和随机访问的大规模 ML 训练。 3. 存储、查询和管理多模态数据,包括图像、视频、音频、文本和 Embeddings。 Lance 的核心功能包括: * **富有表现力的混合搜索:** 在同一数据集上结合向量相似性搜索、全文搜索 (BM25) 和 SQL 分析,并利用加速的二级索引。 * **闪电般的随机访问:** 随机访问速度比 Parquet 或 Iceberg 快 100 倍,且不牺牲扫描性能。 * **原生多模态数据支持:** 以统一的格式存储图像、视频、音频、文本和 Embeddings,具备高效的 Blob 编码和延迟加载能力。 * **数据演变:** 高效地添加带有回填值的列,而无需重写整个表,非常适合 ML 特征工程。 * **零拷贝版本控制:** 通过 ACID 事务、时间旅行、标签和分支进行自动版本控制——无需额外的基础设施。 * **丰富的生态系统集成:** Apache Arrow, Pandas, Polars, DuckDB, Apache Spark, Ray, Trino, Apache Flink 以及开放 Catalog (Apache Polaris, Unity Catalog, Apache Gravitino)。 有关更多详细信息,请参阅完整的 [Lance 格式规范](https://lance.org/format)。 ## 快速开始 **安装** ``` pip install pylance ``` 安装预览版: ``` pip install --pre --extra-index-url https://pypi.fury.io/lance-format/pylance ``` **转换为 Lance** ``` import lance import pandas as pd import pyarrow as pa import pyarrow.dataset df = pd.DataFrame({"a": [5], "b": [10]}) uri = "/tmp/test.parquet" tbl = pa.Table.from_pandas(df) pa.dataset.write_dataset(tbl, uri, format='parquet') parquet = pa.dataset.dataset(uri, format='parquet') lance.write_dataset(parquet, "/tmp/test.lance") ``` **读取 Lance 数据** ``` dataset = lance.dataset("/tmp/test.lance") assert isinstance(dataset, pa.dataset.Dataset) ``` **Pandas** ``` df = dataset.to_table().to_pandas() df ``` **DuckDB** ``` import duckdb # 如果发生段错误,请确保已安装 duckdb v0.7+ duckdb.query("SELECT * FROM dataset LIMIT 10").to_df() ``` **向量搜索** 下载 sift1m 子集 ``` wget ftp://ftp.irisa.fr/local/texmex/corpus/sift.tar.gz tar -xzf sift.tar.gz ``` 将其转换为 Lance ``` import lance from lance.vector import vec_to_table import numpy as np import struct nvecs = 1000000 ndims = 128 with open("sift/sift_base.fvecs", mode="rb") as fobj: buf = fobj.read() data = np.array(struct.unpack("<128000000f", buf[4 : 4 + 4 * nvecs * ndims])).reshape((nvecs, ndims)) dd = dict(zip(range(nvecs), data)) table = vec_to_table(dd) uri = "vec_data.lance" sift1m = lance.write_dataset(table, uri, max_rows_per_group=8192, max_rows_per_file=1024*1024) ``` 构建索引 ``` sift1m.create_index("vector", index_type="IVF_PQ", num_partitions=256, # IVF num_sub_vectors=16) # PQ ``` 搜索数据集 ``` # 获取前 10 个相似向量 import duckdb dataset = lance.dataset(uri) # 采样 100 个查询向量。如果发生段错误,请确保已安装 duckdb v0.7+ sample = duckdb.query("SELECT vector FROM dataset USING SAMPLE 100").to_df() query_vectors = np.array([np.array(x) for x in sample.vector]) # 获取所有向量的最近邻 rs = [dataset.to_table(nearest={"column": "vector", "k": 10, "q": q}) for q in query_vectors] ``` ## 目录结构 | 目录 | 描述 | |--------------------|--------------------------| | [rust](./rust) | 核心 Rust 实现 | | [python](./python) | Python 绑定 (PyO3) | | [java](./java) | Java 绑定 (JNI) | | [docs](./docs) | 文档源码 | ## 基准测试 ### 向量搜索 我们使用 SIFT 数据集对结果进行了基准测试,包含 1M 个 128D 向量 1. 对于 100 个随机采样的查询向量,我们获得了 <1ms 的平均响应时间(在 2023 款 m2 MacBook Air 上) 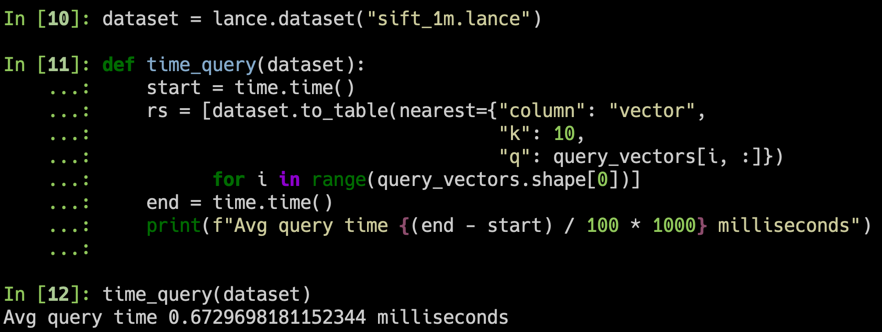 2. ANNs 总是在召回率和性能之间进行权衡 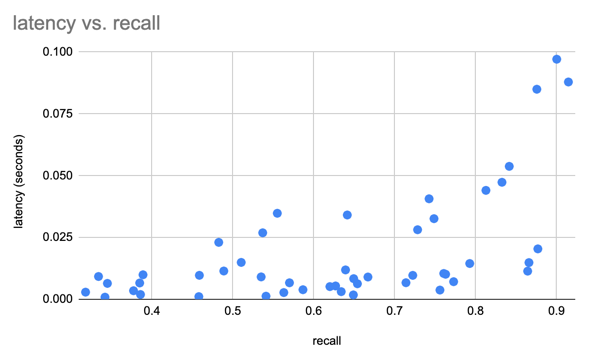 ### 对比 Parquet 我们使用 Oxford Pet 数据集创建了一个 Lance 数据集,以对 Lance 与 Parquet 以及原始图像/XML 的性能进行初步测试。对于分析查询,Lance 比读取原始元数据快 50-100 倍。对于批量随机访问,Lance 比 Parquet 和原始文件都快 100 倍。  ## 为什么选择 Lance 用于 AI/ML 工作流? 机器学习开发周期涉及多个阶段: ``` graph LR A[Collection] --> B[Exploration]; B --> C[Analytics]; C --> D[Feature Engineer]; D --> E[Training]; E --> F[Evaluation]; F --> C; E --> G[Deployment]; G --> H[Monitoring]; H --> A; ``` 传统的 Lakehouse 格式专为 SQL 分析而设计,难以处理以下 AI/ML 负载: - **向量搜索**,用于相似性和语义检索 - **快速随机访问**,用于采样和交互式探索 - **多模态数据**存储(图像、视频、音频与 Embeddings 并存) - **数据演变**,用于在不重写整个表的情况下进行特征工程 - **混合搜索**,结合向量、全文和 SQL 谓词 虽然现有格式(Parquet, Iceberg, Delta Lake)擅长 SQL 分析,但它们需要额外的专门系统来提供 AI 能力。Lance 将这些 AI 优先的功能直接引入了 Lakehouse 格式。 不同格式在 ML 开发阶段的比较: | | Lance | Parquet & ORC | JSON & XML | TFRecord | Database | Warehouse | |---------------------|-------|---------------|------------|----------|----------|-----------| | Analytics (分析) | Fast (快) | Fast (快) | Slow (慢) | Slow (慢) | Decent (尚可) | Fast (快) | | Feature Engineering (特征工程) | Fast (快) | Fast (快) | Decent (尚可) | Slow (慢) | Decent (尚可) | Good (好) | | Training (训练) | Fast (快) | Decent (尚可) | Slow (慢) | Fast (快) | N/A (不适用) | N/A (不适用) | | Exploration (探索) | Fast (快) | Slow (慢) | Fast (快) | Slow (慢) | Fast (快) | Decent (尚可) | | Infra Support (基础设施支持) | Rich (丰富) | Rich (丰富) | Decent (尚可) | Limited (有限) | Rich (丰富) | Rich (丰富) |
标签:ACID事务, Apache Arrow, Apex, DuckDB, ETL, JavaCC, JS文件枚举, Parquet, Polars, Python, PyTorch, Rust, SQL分析, 全文搜索, 凭据扫描, 可视化界面, 向量搜索, 多模态AI, 对象存储, 嵌入向量, 开源数据格式, 数据工程, 数据湖仓, 数据版本控制, 无后门, 机器学习, 深度学习, 混合检索, 特征存储, 网络流量审计, 计算机视觉, 逆向工具, 通知系统, 通知系统, 随机访问, 非结构化数据, 高性能IO