citusdata/citus
GitHub: citusdata/citus
Citus 是一个 PostgreSQL 扩展,通过分布式分片与并行查询引擎将单机 Postgres 转变为可横向扩展的分布式数据库。
Stars: 12570 | Forks: 780
| **
Citus 数据库是 100% 开源的。
![]()
了解 [Citus 13.0 发布博客](https://www.citusdata.com/blog/2025/02/06/distribute-postgresql-17-with-citus-13/) 和 [Citus 更新页面](https://www.citusdata.com/updates/) 中的新功能。
**| |---|
 [](https://docs.citusdata.com/) [](https://stackoverflow.com/questions/tagged/citus) [](https://slack.citusdata.com/) [](https://app.codecov.io/gh/citusdata/citus) [](https://twitter.com/intent/follow?screen_name=citusdata) ## 什么是 Citus? Citus 是一个 [PostgreSQL 扩展](https://www.citusdata.com/blog/2017/10/25/what-it-means-to-be-a-postgresql-extension/),它将 Postgres 转变为分布式数据库——让您在任何规模下都能实现高性能。 通过 Citus,您可以为 PostgreSQL 数据库扩展新的超能力: - **分布式表** 在 PostgreSQL 节点集群中进行分片,以整合它们的 CPU、内存、存储和 I/O 容量。 - **引用表** 被复制到所有节点,用于来自分布式表的连接和外键,并最大化读取性能。 - **分布式查询引擎** 在整个集群中路由并并行化分布式表上的 SELECT、DML 和其他操作。 - **列式存储** 压缩数据,加快扫描速度,并支持快速投影,适用于常规表和分布式表。 - **从任意节点查询** 使您能够将集群的全部容量用于分布式查询。 您可以使用 Citus 的这些超能力,使您的 Postgres 数据库在单个 Citus 节点上即可具备向外扩展的能力。或者,您也可以构建一个能够处理**高事务吞吐量**(尤其是在**多租户应用**中)、运行**快速分析查询**,并处理大量**时间序列**或 **IoT 数据**以进行**实时分析**的大型集群。当您的数据大小和容量增长时,您可以轻松地向集群添加更多 worker 节点并重新平衡分片。 我们的 [SIGMOD '21](https://2021.sigmod.org/) 论文 [Citus:用于数据密集型应用的分布式 PostgreSQL](https://doi.org/10.1145/3448016.3457551) 更详细地介绍了 Citus 是什么、它是如何工作的,以及它为什么以这种方式工作。  由于 Citus 是 Postgres 的扩展,因此您可以在最新的 Postgres 版本中使用 Citus。而且 Citus 能与您已经熟悉的 PostgreSQL 工具和扩展无缝协作。 - [为什么选择 Citus?](#why-citus) - [入门指南](#getting-started) - [使用 Citus](#using-citus) - [基于 schema 的分片](#schema-based-sharding) - [设置高可用性](#setting-up-with-high-availability) - [文档](#documentation) - [架构](#architecture) - [何时使用 Citus](#when-to-use-citus) - [需要帮助?](#need-help) - [贡献](#contributing) - [保持联系](#stay-connected) ## 为什么选择 Citus? 开发者选择 Citus 有两个原因: 1. 您的应用程序正在超出单个 PostgreSQL 节点的承受能力 如果您的数据大小和数量随着时间的推移而增加,您可能会开始在单个 PostgreSQL 节点上遇到各种性能和可扩展性问题。例如:高 CPU 利用率和 I/O 等待时间减慢了您的查询速度,SQL 查询返回内存不足错误,autovacuum 无法跟上导致表膨胀等。 使用 Citus,您可以分布并有选择地压缩表,以始终保持足够的内存、CPU 和 I/O 容量,从而在大规模下实现高性能。分布式查询引擎可以在整个集群中高效地路由事务,同时在所有核心上并行化分析查询和批处理操作。此外,您仍然可以使用您所熟知和喜爱的 PostgreSQL 功能和工具。 2. PostgreSQL 能做其他系统做不到的事情 有许多为向外扩展而构建的数据处理系统,但很少有系统能拥有像 PostgreSQL 那样强大的功能,包括:高级连接和子查询、用户定义的函数、update/delete/upsert、约束和外键、强大的扩展(例如 PostGIS、HyperLogLog)、多种类型的索引、时间分区以及复杂的 JSON 支持。 Citus 使 PostgreSQL 最强大的功能能够在任何规模下发挥作用,允许您在单个数据库系统上处理复杂的数据密集型工作负载。 ## 入门指南 开始使用 Citus 最快的方法是使用云中的 [Azure Cosmos DB for PostgreSQL](https://learn.microsoft.com/azure/cosmos-db/postgresql/quickstart-create-portal) 托管服务——或者[在本地设置 Citus](https://docs.citusdata.com/en/stable/installation/single_node.html)。 ### Azure 上的 Citus 托管服务 您可以在几分钟内通过 [Azure Cosmos DB for PostgreSQL 门户](https://azure.microsoft.com/products/cosmos-db/)获得一个完全托管的 Citus 集群。Azure 将为您所有的服务器管理备份、通过自动故障转移实现的高可用性、软件更新、监控等。要开始在 Azure 上使用 Citus,请使用 [Azure Cosmos DB for PostgreSQL 快速入门](https://learn.microsoft.com/azure/cosmos-db/postgresql/quickstart-create-portal)。 ### 使用 Docker 运行 Citus 最小可能的 Citus 集群是带有 Citus 扩展的单个 PostgreSQL 节点,这意味着您可以通过运行单个 Docker 容器来试用 Citus。 ``` # 在端口 5500 上运行带有 Citus 的 PostgreSQL docker run -d --name citus -p 5500:5432 -e POSTGRES_PASSWORD=mypassword citusdata/citus # 在 Docker 容器内使用 psql 连接 docker exec -it citus psql -U postgres # 或者,使用本地 psql 连接 psql -U postgres -d postgres -h localhost -p 5500 ``` ### 在本地安装 Citus 如果您已经在本地安装了 PostgreSQL,安装 Citus 最简单的方法是使用我们的打包仓库 在 Ubuntu / Debian 上安装包: 在 Red Hat 上安装包: 要将 Citus 添加到您的本地 PostgreSQL 数据库中,请将以下内容添加到 `postgresql.conf`: ``` shared_preload_libraries = 'citus' ``` 重启 PostgreSQL 后,使用 `psql` 连接并运行: ``` CREATE EXTENSION citus; ``` 您现在已准备好开始在单节点上使用 Citus 表。 ### 在多节点上安装 Citus 如果您想设置多节点集群,您也可以设置额外的带有 Citus 扩展的 PostgreSQL 节点,并将它们添加进来组成一个 Citus 集群: ``` -- before adding the first worker node, tell future worker nodes how to reach the coordinator SELECT citus_set_coordinator_host('10.0.0.1', 5432); -- add worker nodes SELECT citus_add_node('10.0.0.2', 5432); SELECT citus_add_node('10.0.0.3', 5432); -- rebalance the shards over the new worker nodes SELECT rebalance_table_shards(); ``` 有关更多详细信息,请参阅我们关于在各种操作系统上[如何设置多节点 Citus 集群的文档](https://docs.citusdata.com/en/stable/installation/multi_node.html)。 ## 使用 Citus 拥有 Citus 集群后,您就可以开始创建分布式表、引用表并使用列式存储了。 ### 创建分布式表 `create_distributed_table` UDF 将在本地或 worker 节点上透明地对您的表进行分片: ``` CREATE TABLE events ( device_id bigint, event_id bigserial, event_time timestamptz default now(), data jsonb not null, PRIMARY KEY (device_id, event_id) ); -- distribute the events table across shards placed locally or on the worker nodes SELECT create_distributed_table('events', 'device_id'); ``` 在此操作之后,针对特定设备 ID 的查询将被高效地路由到单个 worker 节点,而跨设备 ID 的查询将在整个集群中并行化。 ``` -- insert some events INSERT INTO events (device_id, data) SELECT s % 100, ('{"measurement":'||random()||'}')::jsonb FROM generate_series(1,1000000) s; -- get the last 3 events for device 1, routed to a single node SELECT * FROM events WHERE device_id = 1 ORDER BY event_time DESC, event_id DESC LIMIT 3; ┌───────────┬──────────┬───────────────────────────────┬───────────────────────────────────────┐ │ device_id │ event_id │ event_time │ data │ ├───────────┼──────────┼───────────────────────────────┼───────────────────────────────────────┤ │ 1 │ 1999901 │ 2021-03-04 16:00:31.189963+00 │ {"measurement": 0.88722643925054} │ │ 1 │ 1999801 │ 2021-03-04 16:00:31.189963+00 │ {"measurement": 0.6512231304621992} │ │ 1 │ 1999701 │ 2021-03-04 16:00:31.189963+00 │ {"measurement": 0.019368766051897524} │ └───────────┴──────────┴───────────────────────────────┴───────────────────────────────────────┘ (3 rows) Time: 4.588 ms -- explain plan for a query that is parallelized across shards, which shows the plan for -- a query one of the shards and how the aggregation across shards is done EXPLAIN (VERBOSE ON) SELECT count(*) FROM events; ┌────────────────────────────────────────────────────────────────────────────────────┐ │ QUERY PLAN │ ├────────────────────────────────────────────────────────────────────────────────────┤ │ Aggregate │ │ Output: COALESCE((pg_catalog.sum(remote_scan.count))::bigint, '0'::bigint) │ │ -> Custom Scan (Citus Adaptive) │ │ ... │ │ -> Task │ │ Query: SELECT count(*) AS count FROM events_102008 events WHERE true │ │ Node: host=localhost port=5432 dbname=postgres │ │ -> Aggregate │ │ -> Seq Scan on public.events_102008 events │ └────────────────────────────────────────────────────────────────────────────────────┘ ``` ### 创建具有协同定位的分布式表 具有相同分布列的分布式表可以进行协同定位,以在分布式表之间实现高性能的分布式连接和外键。 默认情况下,分布式表将根据分布列的类型进行协同定位,但您可以使用 `create_distributed_table` 中的 `colocate_with` 参数显式定义协同定位。 ``` CREATE TABLE devices ( device_id bigint primary key, device_name text, device_type_id int ); CREATE INDEX ON devices (device_type_id); -- co-locate the devices table with the events table SELECT create_distributed_table('devices', 'device_id', colocate_with := 'events'); -- insert device metadata INSERT INTO devices (device_id, device_name, device_type_id) SELECT s, 'device-'||s, 55 FROM generate_series(0, 99) s; -- optionally: make sure the application can only insert events for a known device ALTER TABLE events ADD CONSTRAINT device_id_fk FOREIGN KEY (device_id) REFERENCES devices (device_id); -- get the average measurement across all devices of type 55, parallelized across shards SELECT avg((data->>'measurement')::double precision) FROM events JOIN devices USING (device_id) WHERE device_type_id = 55; ┌────────────────────┐ │ avg │ ├────────────────────┤ │ 0.5000191877513974 │ └────────────────────┘ (1 row) Time: 209.961 ms ``` 协同定位还可以帮助您扩展 [INSERT..SELECT](https://docs.citusdata.com/en/stable/articles/aggregation.html)、[存储过程](https://www.citusdata.com/blog/2020/11/21/making-postgres-stored-procedures-9x-faster-in-citus/)和[分布式事务](https://www.citusdata.com/blog/2017/06/02/scaling-complex-sql-transactions/)。 ###在不中断应用程序的情况下分布表 ``` CREATE TABLE device_logs ( device_id bigint primary key, log text ); -- insert device logs INSERT INTO device_logs (device_id, log) SELECT s, 'device log:'||s FROM generate_series(0, 99) s; -- convert device_logs into a distributed table without interrupting the application SELECT create_distributed_table_concurrently('device_logs', 'device_id', colocate_with := 'devices'); -- get the count of the logs, parallelized across shards SELECT count(*) FROM device_logs; ┌───────┐ │ count │ ├───────┤ │ 100 │ └───────┘ (1 row) Time: 48.734 ms ``` ### 创建引用表 当您需要不包含分布列的快速连接或外键时,您可以使用 `create_reference_table` 将表复制到集群中的所有节点。 ``` CREATE TABLE device_types ( device_type_id int primary key, device_type_name text not null unique ); -- replicate the table across all nodes to enable foreign keys and joins on any column SELECT create_reference_table('device_types'); -- insert a device type INSERT INTO device_types (device_type_id, device_type_name) VALUES (55, 'laptop'); -- optionally: make sure the application can only insert devices with known types ALTER TABLE devices ADD CONSTRAINT device_type_fk FOREIGN KEY (device_type_id) REFERENCES device_types (device_type_id); -- get the last 3 events for devices whose type name starts with laptop, parallelized across shards SELECT device_id, event_time, data->>'measurement' AS value, device_name, device_type_name FROM events JOIN devices USING (device_id) JOIN device_types USING (device_type_id) WHERE device_type_name LIKE 'laptop%' ORDER BY event_time DESC LIMIT 3; ┌───────────┬───────────────────────────────┬─────────────────────┬─────────────┬──────────────────┐ │ device_id │ event_time │ value │ device_name │ device_type_name │ ├───────────┼───────────────────────────────┼─────────────────────┼─────────────┼──────────────────┤ │ 60 │ 2021-03-04 16:00:31.189963+00 │ 0.28902084163415864 │ device-60 │ laptop │ │ 8 │ 2021-03-04 16:00:31.189963+00 │ 0.8723803076285073 │ device-8 │ laptop │ │ 20 │ 2021-03-04 16:00:31.189963+00 │ 0.8177634801548557 │ device-20 │ laptop │ └───────────┴───────────────────────────────┴─────────────────────┴─────────────┴──────────────────┘ (3 rows) Time: 146.063 ms ``` 引用表使您能够向外扩展复杂的数据模型,并充分利用关系数据库的功能。 ### 创建具有列式存储的表 要在您的 PostgreSQL 数据库中使用列式存储,您只需在 `CREATE TABLE` 语句中添加 `USING columnar`,您的数据将使用列式访问方法自动压缩。 ``` CREATE TABLE events_columnar ( device_id bigint, event_id bigserial, event_time timestamptz default now(), data jsonb not null ) USING columnar; -- insert some data INSERT INTO events_columnar (device_id, data) SELECT d, '{"hello":"columnar"}' FROM generate_series(1,10000000) d; -- create a row-based table to compare CREATE TABLE events_row AS SELECT * FROM events_columnar; -- see the huge size difference! \d+ List of relations ┌────────┬──────────────────────────────┬──────────┬───────┬─────────────┬────────────┬─────────────┐ │ Schema │ Name │ Type │ Owner │ Persistence │ Size │ Description │ ├────────┼──────────────────────────────┼──────────┼───────┼─────────────┼────────────┼─────────────┤ │ public │ events_columnar │ table │ marco │ permanent │ 25 MB │ │ │ public │ events_row │ table │ marco │ permanent │ 651 MB │ │ └────────┴──────────────────────────────┴──────────┴───────┴─────────────┴────────────┴─────────────┘ (2 rows) ``` 您可以单独使用列式存储,也可以在分布式表中使用它,以结合压缩和分布式查询引擎的优势。 使用列式存储时,您应该只使用 `COPY` 或 `INSERT..SELECT` 批量加载数据,以实现良好的压缩。列式表目前不支持 update、delete 和外键。但是,您可以使用分区表,其中较新的分区使用基于行的存储,而较旧的分区使用列式存储进行压缩。 要了解有关列式存储的更多信息,请查看[列式存储 README](https://github.com/citusdata/citus/blob/master/src/backend/columnar/README.md)。 ## 基于 schema 的分片 从 Citus 12.0 开始可用,[基于 schema 的分片](https://docs.citusdata.com/en/stable/get_started/concepts.html#schema-based-sharding)是共享数据库、独立 schema 的模型,schema 成为数据库中的逻辑分片。多租户应用可以为每个租户使用一个 schema,从而轻松地沿租户维度进行分片。不需要修改查询,并且应用程序通常只需要进行微小的修改,以便在切换租户时设置正确的 search_path。基于 schema 的分片是微服务的理想解决方案,也适用于部署无法进行基于行的分片所需更改的应用程序的 ISV。 ### 创建分布式 schema 您可以通过调用 `citus_schema_distribute` 将现有 schema 转换为分布式 schema: ``` SELECT citus_schema_distribute('user_service'); ``` 或者,您可以设置 `citus.enable_schema_based_sharding`,使所有新创建的 schema 自动转换为分布式 schema: ``` SET citus.enable_schema_based_sharding TO ON; CREATE SCHEMA AUTHORIZATION user_service; CREATE SCHEMA AUTHORIZATION time_service; CREATE SCHEMA AUTHORIZATION ping_service; ``` ### 运行查询 查询将基于 `search_path` 或通过在查询中显式使用 schema 名称被正确路由到相应的 schema。 对于[微服务](https://docs.citusdata.com/en/stable/get_started/tutorial_microservices.html),您将为每个与 schema 名称匹配的服务创建一个 USER,因此默认的 `search_path` 将包含该 schema 名称。连接后,用户查询将自动路由,无需对微服务进行任何更改。 ``` CREATE USER user_service; CREATE SCHEMA AUTHORIZATION user_service; ``` 对于典型的多租户应用程序,您将在应用程序中将搜索路径设置为租户的 schema 名称: ``` SET search_path = tenant_name, public; ``` ## 设置高可用性 Citus 集群的 patronictl list 输出示例: ``` postgres@coord1:~$ patronictl list demo ``` ``` + Citus cluster: demo ----------+--------------+---------+----+-----------+ | Group | Member | Host | Role | State | TL | Lag in MB | +-------+---------+-------------+--------------+---------+----+-----------+ | 0 | coord1 | 172.27.0.10 | Replica | running | 1 | 0 | | 0 | coord2 | 172.27.0.6 | Sync Standby | running | 1 | 0 | | 0 | coord3 | 172.27.0.4 | Leader | running | 1 | | | 1 | work1-1 | 172.27.0.8 | Sync Standby | running | 1 | 0 | | 1 | work1-2 | 172.27.0.2 | Leader | running | 1 | | | 2 | work2-1 | 172.27.0.5 | Sync Standby | running | 1 | 0 | | 2 | work2-2 | 172.27.0.7 | Leader | running | 1 | | +-------+---------+-------------+--------------+---------+----+-----------+ ``` ## 文档 如果您准备好开始使用 Citus 或想了解更多信息,我们建议您阅读 [Citus 开源文档](https://docs.citusdata.com/en/stable/)。或者,如果您正在 Azure 上使用 Citus,那么可以从 [Azure Cosmos DB for PostgreSQL](https://learn.microsoft.com/azure/cosmos-db/postgresql/introduction) 开始。 我们的 Citus 文档包含关于如何构建[多租户 SaaS 应用程序](https://docs.citusdata.com/en/stable/use_cases/multi_tenant.html)、[实时分析仪表板]( https://docs.citusdata.com/en/stable/use_cases/realtime_analytics.html)或处理[时间序列数据](https://docs.citusdata.com/en/stable/use_cases/timeseries.html)的全面用例指南。 ## 架构 Citus 数据库集群通过添加 worker 节点,从单个 PostgreSQL 节点发展成为集群。在 Citus 集群中,应用程序连接的原始节点被称为主节点。Citus 主节点既包含分布式表和引用表的元数据,也包含常规(本地)表、序列和其他数据库对象(例如外部表)。 分布式表中的数据存储在“分片”中,这些分片实际上只是 worker 节点上的常规 PostgreSQL 表。在主节点上查询分布式表时,Citus 将向 worker 节点发送常规 SQL 查询。这样,所有常用的 PostgreSQL 优化和扩展都可以自动与 Citus 一起使用。 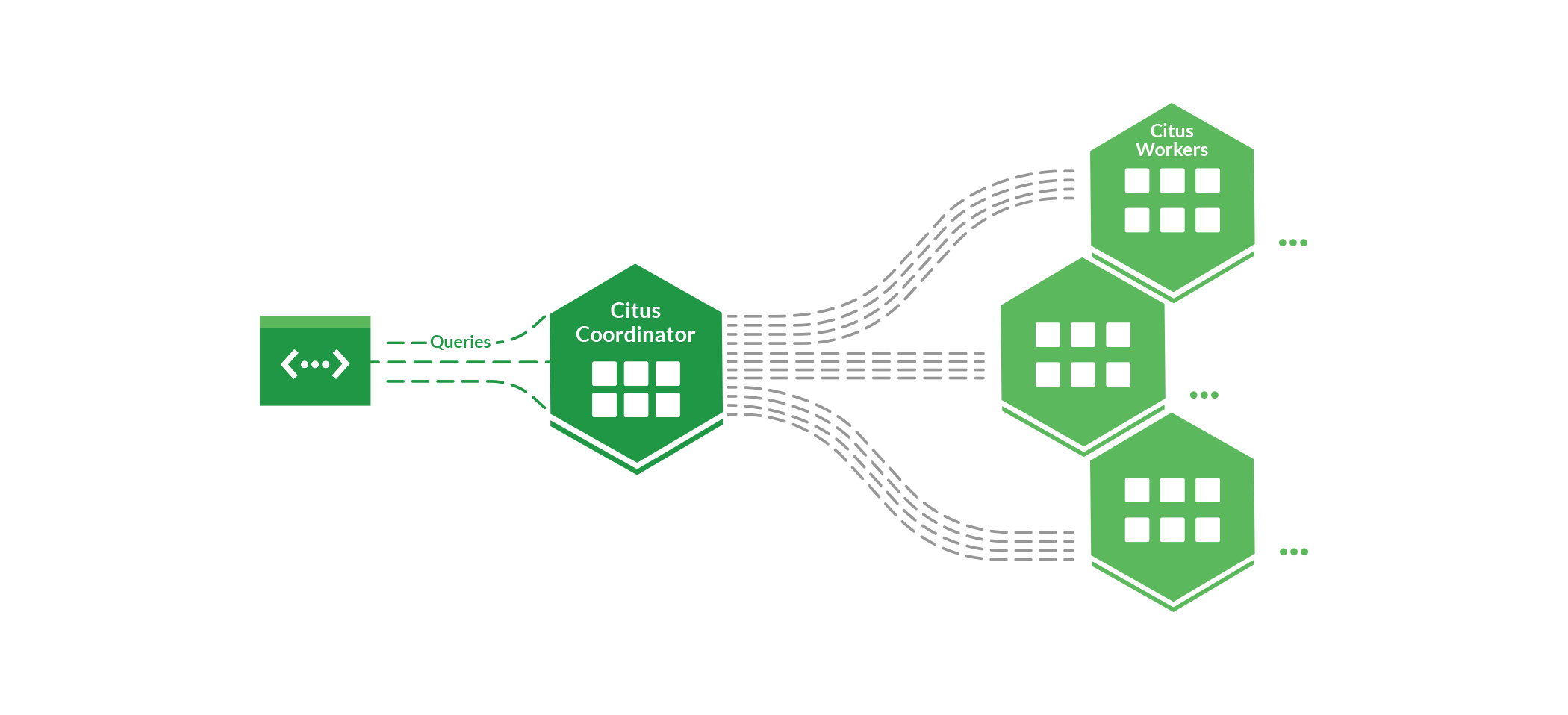 分布式表和引用表的 schema 和元数据会自动同步到集群中的所有节点。这样,您就可以连接到任何节点来运行分布式查询。schema 更改和集群管理仍然需要通过主节点进行。 为 Citus 开发者提供的实现详细描述在 [Citus 技术文档](src/backend/distributed/README.md)中。 ## 何时使用 Citus - **[面向客户的分析仪表板](http://docs.citusdata.com/en/stable/use_cases/realtime_analytics.html)**: Citus 使您能够构建分析仪表板,在数据库中同时摄取和处理大量数据,即使有大量并发用户也能提供亚秒级的响应时间。 Citus 中先进的并行、分布式查询引擎结合了 PostgreSQL 的功能(如[数组类型](https://www.postgresql.org/docs/current/arrays.html)、[JSONB](https://www.postgresql.org/docs/current/datatype-json.html)、[横向连接](https://heap.io/blog/engineering/postgresqls-powerful-new-join-type-lateral))和扩展(如 [HyperLogLog](https://github.com/citusdata/postgresql-hll) 和 [TopN](https://github.com/citusdata/postgresql-topn)),让您无论拥有多少客户或多少数据,都能构建响应迅速的分析仪表板。 实时分析用户示例:[Algolia](https://www.citusdata.com/customers/algolia) - **[时间序列数据](http://docs.citusdata.com/en/stable/use_cases/timeseries.html)**: Citus 使您能够处理和分析极大量的时间序列数据。最大的 Citus 集群存储了超过 1 PB 的时间序列数据,并且每天摄取数 TB 的数据。 Citus 与 [Postgres 表分区](https://www.postgresql.org/docs/current/ddl-partitioning.html)无缝集成,并具有[按时间分区的内置函数](https://www.citusdata.com/blog/2021/10/22/how-to-scale-postgres-for-time-series-data-with-citus/),可以加快时间序列表上的查询和写入速度。您可以利用 Citus 的并行、分布式查询引擎进行快速的分析查询,并使用内置的*列式存储*来压缩旧分区。 用户示例:[MixRank](https://www.citusdata.com/customers/mixrank) - **[软件即服务 应用程序](http://docs.citusdata.com/en/stable/use_cases/multi_tenant.html)**: SaaS 和其他多租户应用程序需要能够随着租户/客户数量的增长而扩展其数据库。Citus 使您能够按租户维度透明地对复杂数据模型进行分片,从而让您的数据库可以与您的业务一起增长。 通过沿租 ID 列分布表并协同定位同一租户的数据,Citus 可以水平扩展复杂(租户范围)的查询、事务和外键图。与手动分片相比,引用表和分布式 DDL 命令使数据库管理变得轻而易举。最重要的是,您拥有一个内置的分布式查询引擎,可以在数据库内部执行跨租户分析。 多租户 SaaS 用户示例:[Salesloft](https://fivetran.com/case-studies/replicating-sharded-databases-a-case-study-of-salesloft-citus-data-and-fivetran)、[ConvertFlow](https://www.citusdata.com/customers/convertflow) - **[微服务](https://docs.citusdata.com/en/stable/get_started/tutorial_microservices.html)**:Citus 支持基于 schema 的分片,允许将常规的数据库 schema 分布在多台机器上。这种分片方法非常适合典型的微服务架构,在这种架构中,存储完全由服务拥有,因此无法与其他租户共享相同的 schema 定义。Citus 允许在服务之间分布水平可扩展的状态,解决了微服务的[主要问题](https://stackoverflow.blog/2020/11/23/the-macro-problem-with-microservices/)之一。 - **地理空间**: 由于 Postgres 强大的 [PostGIS](https://postgis.net/) 扩展为 Postgres 添加了对地理对象的支持,许多人在 Postgres 之上运行空间/GIS 应用程序。并且由于空间位置信息已经成为我们日常生活的一部分,现在的地理空间应用程序比以往任何时候都多。当您的 Postgres 数据库需要向外扩展以处理增加的工作负载时,Citus 是一个很好的选择。 地理空间用户示例:[赫尔辛基地区交通管理局 (HSL)](https://customers.microsoft.com/story/845146-transit-authority-improves-traffic-monitoring-with-azure-database-for-postgresql-hyperscale)、[MobilityDB](https://www.citusdata.com/blog/2020/11/09/analyzing-gps-trajectories-at-scale-with-postgres-mobilitydb/)。 ## 需要帮助? ## 行为准则 本项目采用了 [微软开源行为准则](https://opensource.microsoft.com/codeofconduct/)。 有关更多信息,请参阅[行为准则常见问题解答](https://opensource.microsoft.com/codeofconduct/faq/)或 联系 [opencode@microsoft.com](mailto:opencode@microsoft.com) 并提出任何其他问题或意见。 ## 保持联系 版权所有 © Citus Data, Inc.
Citus 数据库是 100% 开源的。
了解 [Citus 13.0 发布博客](https://www.citusdata.com/blog/2025/02/06/distribute-postgresql-17-with-citus-13/) 和 [Citus 更新页面](https://www.citusdata.com/updates/) 中的新功能。
**| |---|
 [](https://docs.citusdata.com/) [](https://stackoverflow.com/questions/tagged/citus) [](https://slack.citusdata.com/) [](https://app.codecov.io/gh/citusdata/citus) [](https://twitter.com/intent/follow?screen_name=citusdata) ## 什么是 Citus? Citus 是一个 [PostgreSQL 扩展](https://www.citusdata.com/blog/2017/10/25/what-it-means-to-be-a-postgresql-extension/),它将 Postgres 转变为分布式数据库——让您在任何规模下都能实现高性能。 通过 Citus,您可以为 PostgreSQL 数据库扩展新的超能力: - **分布式表** 在 PostgreSQL 节点集群中进行分片,以整合它们的 CPU、内存、存储和 I/O 容量。 - **引用表** 被复制到所有节点,用于来自分布式表的连接和外键,并最大化读取性能。 - **分布式查询引擎** 在整个集群中路由并并行化分布式表上的 SELECT、DML 和其他操作。 - **列式存储** 压缩数据,加快扫描速度,并支持快速投影,适用于常规表和分布式表。 - **从任意节点查询** 使您能够将集群的全部容量用于分布式查询。 您可以使用 Citus 的这些超能力,使您的 Postgres 数据库在单个 Citus 节点上即可具备向外扩展的能力。或者,您也可以构建一个能够处理**高事务吞吐量**(尤其是在**多租户应用**中)、运行**快速分析查询**,并处理大量**时间序列**或 **IoT 数据**以进行**实时分析**的大型集群。当您的数据大小和容量增长时,您可以轻松地向集群添加更多 worker 节点并重新平衡分片。 我们的 [SIGMOD '21](https://2021.sigmod.org/) 论文 [Citus:用于数据密集型应用的分布式 PostgreSQL](https://doi.org/10.1145/3448016.3457551) 更详细地介绍了 Citus 是什么、它是如何工作的,以及它为什么以这种方式工作。  由于 Citus 是 Postgres 的扩展,因此您可以在最新的 Postgres 版本中使用 Citus。而且 Citus 能与您已经熟悉的 PostgreSQL 工具和扩展无缝协作。 - [为什么选择 Citus?](#why-citus) - [入门指南](#getting-started) - [使用 Citus](#using-citus) - [基于 schema 的分片](#schema-based-sharding) - [设置高可用性](#setting-up-with-high-availability) - [文档](#documentation) - [架构](#architecture) - [何时使用 Citus](#when-to-use-citus) - [需要帮助?](#need-help) - [贡献](#contributing) - [保持联系](#stay-connected) ## 为什么选择 Citus? 开发者选择 Citus 有两个原因: 1. 您的应用程序正在超出单个 PostgreSQL 节点的承受能力 如果您的数据大小和数量随着时间的推移而增加,您可能会开始在单个 PostgreSQL 节点上遇到各种性能和可扩展性问题。例如:高 CPU 利用率和 I/O 等待时间减慢了您的查询速度,SQL 查询返回内存不足错误,autovacuum 无法跟上导致表膨胀等。 使用 Citus,您可以分布并有选择地压缩表,以始终保持足够的内存、CPU 和 I/O 容量,从而在大规模下实现高性能。分布式查询引擎可以在整个集群中高效地路由事务,同时在所有核心上并行化分析查询和批处理操作。此外,您仍然可以使用您所熟知和喜爱的 PostgreSQL 功能和工具。 2. PostgreSQL 能做其他系统做不到的事情 有许多为向外扩展而构建的数据处理系统,但很少有系统能拥有像 PostgreSQL 那样强大的功能,包括:高级连接和子查询、用户定义的函数、update/delete/upsert、约束和外键、强大的扩展(例如 PostGIS、HyperLogLog)、多种类型的索引、时间分区以及复杂的 JSON 支持。 Citus 使 PostgreSQL 最强大的功能能够在任何规模下发挥作用,允许您在单个数据库系统上处理复杂的数据密集型工作负载。 ## 入门指南 开始使用 Citus 最快的方法是使用云中的 [Azure Cosmos DB for PostgreSQL](https://learn.microsoft.com/azure/cosmos-db/postgresql/quickstart-create-portal) 托管服务——或者[在本地设置 Citus](https://docs.citusdata.com/en/stable/installation/single_node.html)。 ### Azure 上的 Citus 托管服务 您可以在几分钟内通过 [Azure Cosmos DB for PostgreSQL 门户](https://azure.microsoft.com/products/cosmos-db/)获得一个完全托管的 Citus 集群。Azure 将为您所有的服务器管理备份、通过自动故障转移实现的高可用性、软件更新、监控等。要开始在 Azure 上使用 Citus,请使用 [Azure Cosmos DB for PostgreSQL 快速入门](https://learn.microsoft.com/azure/cosmos-db/postgresql/quickstart-create-portal)。 ### 使用 Docker 运行 Citus 最小可能的 Citus 集群是带有 Citus 扩展的单个 PostgreSQL 节点,这意味着您可以通过运行单个 Docker 容器来试用 Citus。 ``` # 在端口 5500 上运行带有 Citus 的 PostgreSQL docker run -d --name citus -p 5500:5432 -e POSTGRES_PASSWORD=mypassword citusdata/citus # 在 Docker 容器内使用 psql 连接 docker exec -it citus psql -U postgres # 或者,使用本地 psql 连接 psql -U postgres -d postgres -h localhost -p 5500 ``` ### 在本地安装 Citus 如果您已经在本地安装了 PostgreSQL,安装 Citus 最简单的方法是使用我们的打包仓库 在 Ubuntu / Debian 上安装包: 在 Red Hat 上安装包: 要将 Citus 添加到您的本地 PostgreSQL 数据库中,请将以下内容添加到 `postgresql.conf`: ``` shared_preload_libraries = 'citus' ``` 重启 PostgreSQL 后,使用 `psql` 连接并运行: ``` CREATE EXTENSION citus; ``` 您现在已准备好开始在单节点上使用 Citus 表。 ### 在多节点上安装 Citus 如果您想设置多节点集群,您也可以设置额外的带有 Citus 扩展的 PostgreSQL 节点,并将它们添加进来组成一个 Citus 集群: ``` -- before adding the first worker node, tell future worker nodes how to reach the coordinator SELECT citus_set_coordinator_host('10.0.0.1', 5432); -- add worker nodes SELECT citus_add_node('10.0.0.2', 5432); SELECT citus_add_node('10.0.0.3', 5432); -- rebalance the shards over the new worker nodes SELECT rebalance_table_shards(); ``` 有关更多详细信息,请参阅我们关于在各种操作系统上[如何设置多节点 Citus 集群的文档](https://docs.citusdata.com/en/stable/installation/multi_node.html)。 ## 使用 Citus 拥有 Citus 集群后,您就可以开始创建分布式表、引用表并使用列式存储了。 ### 创建分布式表 `create_distributed_table` UDF 将在本地或 worker 节点上透明地对您的表进行分片: ``` CREATE TABLE events ( device_id bigint, event_id bigserial, event_time timestamptz default now(), data jsonb not null, PRIMARY KEY (device_id, event_id) ); -- distribute the events table across shards placed locally or on the worker nodes SELECT create_distributed_table('events', 'device_id'); ``` 在此操作之后,针对特定设备 ID 的查询将被高效地路由到单个 worker 节点,而跨设备 ID 的查询将在整个集群中并行化。 ``` -- insert some events INSERT INTO events (device_id, data) SELECT s % 100, ('{"measurement":'||random()||'}')::jsonb FROM generate_series(1,1000000) s; -- get the last 3 events for device 1, routed to a single node SELECT * FROM events WHERE device_id = 1 ORDER BY event_time DESC, event_id DESC LIMIT 3; ┌───────────┬──────────┬───────────────────────────────┬───────────────────────────────────────┐ │ device_id │ event_id │ event_time │ data │ ├───────────┼──────────┼───────────────────────────────┼───────────────────────────────────────┤ │ 1 │ 1999901 │ 2021-03-04 16:00:31.189963+00 │ {"measurement": 0.88722643925054} │ │ 1 │ 1999801 │ 2021-03-04 16:00:31.189963+00 │ {"measurement": 0.6512231304621992} │ │ 1 │ 1999701 │ 2021-03-04 16:00:31.189963+00 │ {"measurement": 0.019368766051897524} │ └───────────┴──────────┴───────────────────────────────┴───────────────────────────────────────┘ (3 rows) Time: 4.588 ms -- explain plan for a query that is parallelized across shards, which shows the plan for -- a query one of the shards and how the aggregation across shards is done EXPLAIN (VERBOSE ON) SELECT count(*) FROM events; ┌────────────────────────────────────────────────────────────────────────────────────┐ │ QUERY PLAN │ ├────────────────────────────────────────────────────────────────────────────────────┤ │ Aggregate │ │ Output: COALESCE((pg_catalog.sum(remote_scan.count))::bigint, '0'::bigint) │ │ -> Custom Scan (Citus Adaptive) │ │ ... │ │ -> Task │ │ Query: SELECT count(*) AS count FROM events_102008 events WHERE true │ │ Node: host=localhost port=5432 dbname=postgres │ │ -> Aggregate │ │ -> Seq Scan on public.events_102008 events │ └────────────────────────────────────────────────────────────────────────────────────┘ ``` ### 创建具有协同定位的分布式表 具有相同分布列的分布式表可以进行协同定位,以在分布式表之间实现高性能的分布式连接和外键。 默认情况下,分布式表将根据分布列的类型进行协同定位,但您可以使用 `create_distributed_table` 中的 `colocate_with` 参数显式定义协同定位。 ``` CREATE TABLE devices ( device_id bigint primary key, device_name text, device_type_id int ); CREATE INDEX ON devices (device_type_id); -- co-locate the devices table with the events table SELECT create_distributed_table('devices', 'device_id', colocate_with := 'events'); -- insert device metadata INSERT INTO devices (device_id, device_name, device_type_id) SELECT s, 'device-'||s, 55 FROM generate_series(0, 99) s; -- optionally: make sure the application can only insert events for a known device ALTER TABLE events ADD CONSTRAINT device_id_fk FOREIGN KEY (device_id) REFERENCES devices (device_id); -- get the average measurement across all devices of type 55, parallelized across shards SELECT avg((data->>'measurement')::double precision) FROM events JOIN devices USING (device_id) WHERE device_type_id = 55; ┌────────────────────┐ │ avg │ ├────────────────────┤ │ 0.5000191877513974 │ └────────────────────┘ (1 row) Time: 209.961 ms ``` 协同定位还可以帮助您扩展 [INSERT..SELECT](https://docs.citusdata.com/en/stable/articles/aggregation.html)、[存储过程](https://www.citusdata.com/blog/2020/11/21/making-postgres-stored-procedures-9x-faster-in-citus/)和[分布式事务](https://www.citusdata.com/blog/2017/06/02/scaling-complex-sql-transactions/)。 ###在不中断应用程序的情况下分布表 ``` CREATE TABLE device_logs ( device_id bigint primary key, log text ); -- insert device logs INSERT INTO device_logs (device_id, log) SELECT s, 'device log:'||s FROM generate_series(0, 99) s; -- convert device_logs into a distributed table without interrupting the application SELECT create_distributed_table_concurrently('device_logs', 'device_id', colocate_with := 'devices'); -- get the count of the logs, parallelized across shards SELECT count(*) FROM device_logs; ┌───────┐ │ count │ ├───────┤ │ 100 │ └───────┘ (1 row) Time: 48.734 ms ``` ### 创建引用表 当您需要不包含分布列的快速连接或外键时,您可以使用 `create_reference_table` 将表复制到集群中的所有节点。 ``` CREATE TABLE device_types ( device_type_id int primary key, device_type_name text not null unique ); -- replicate the table across all nodes to enable foreign keys and joins on any column SELECT create_reference_table('device_types'); -- insert a device type INSERT INTO device_types (device_type_id, device_type_name) VALUES (55, 'laptop'); -- optionally: make sure the application can only insert devices with known types ALTER TABLE devices ADD CONSTRAINT device_type_fk FOREIGN KEY (device_type_id) REFERENCES device_types (device_type_id); -- get the last 3 events for devices whose type name starts with laptop, parallelized across shards SELECT device_id, event_time, data->>'measurement' AS value, device_name, device_type_name FROM events JOIN devices USING (device_id) JOIN device_types USING (device_type_id) WHERE device_type_name LIKE 'laptop%' ORDER BY event_time DESC LIMIT 3; ┌───────────┬───────────────────────────────┬─────────────────────┬─────────────┬──────────────────┐ │ device_id │ event_time │ value │ device_name │ device_type_name │ ├───────────┼───────────────────────────────┼─────────────────────┼─────────────┼──────────────────┤ │ 60 │ 2021-03-04 16:00:31.189963+00 │ 0.28902084163415864 │ device-60 │ laptop │ │ 8 │ 2021-03-04 16:00:31.189963+00 │ 0.8723803076285073 │ device-8 │ laptop │ │ 20 │ 2021-03-04 16:00:31.189963+00 │ 0.8177634801548557 │ device-20 │ laptop │ └───────────┴───────────────────────────────┴─────────────────────┴─────────────┴──────────────────┘ (3 rows) Time: 146.063 ms ``` 引用表使您能够向外扩展复杂的数据模型,并充分利用关系数据库的功能。 ### 创建具有列式存储的表 要在您的 PostgreSQL 数据库中使用列式存储,您只需在 `CREATE TABLE` 语句中添加 `USING columnar`,您的数据将使用列式访问方法自动压缩。 ``` CREATE TABLE events_columnar ( device_id bigint, event_id bigserial, event_time timestamptz default now(), data jsonb not null ) USING columnar; -- insert some data INSERT INTO events_columnar (device_id, data) SELECT d, '{"hello":"columnar"}' FROM generate_series(1,10000000) d; -- create a row-based table to compare CREATE TABLE events_row AS SELECT * FROM events_columnar; -- see the huge size difference! \d+ List of relations ┌────────┬──────────────────────────────┬──────────┬───────┬─────────────┬────────────┬─────────────┐ │ Schema │ Name │ Type │ Owner │ Persistence │ Size │ Description │ ├────────┼──────────────────────────────┼──────────┼───────┼─────────────┼────────────┼─────────────┤ │ public │ events_columnar │ table │ marco │ permanent │ 25 MB │ │ │ public │ events_row │ table │ marco │ permanent │ 651 MB │ │ └────────┴──────────────────────────────┴──────────┴───────┴─────────────┴────────────┴─────────────┘ (2 rows) ``` 您可以单独使用列式存储,也可以在分布式表中使用它,以结合压缩和分布式查询引擎的优势。 使用列式存储时,您应该只使用 `COPY` 或 `INSERT..SELECT` 批量加载数据,以实现良好的压缩。列式表目前不支持 update、delete 和外键。但是,您可以使用分区表,其中较新的分区使用基于行的存储,而较旧的分区使用列式存储进行压缩。 要了解有关列式存储的更多信息,请查看[列式存储 README](https://github.com/citusdata/citus/blob/master/src/backend/columnar/README.md)。 ## 基于 schema 的分片 从 Citus 12.0 开始可用,[基于 schema 的分片](https://docs.citusdata.com/en/stable/get_started/concepts.html#schema-based-sharding)是共享数据库、独立 schema 的模型,schema 成为数据库中的逻辑分片。多租户应用可以为每个租户使用一个 schema,从而轻松地沿租户维度进行分片。不需要修改查询,并且应用程序通常只需要进行微小的修改,以便在切换租户时设置正确的 search_path。基于 schema 的分片是微服务的理想解决方案,也适用于部署无法进行基于行的分片所需更改的应用程序的 ISV。 ### 创建分布式 schema 您可以通过调用 `citus_schema_distribute` 将现有 schema 转换为分布式 schema: ``` SELECT citus_schema_distribute('user_service'); ``` 或者,您可以设置 `citus.enable_schema_based_sharding`,使所有新创建的 schema 自动转换为分布式 schema: ``` SET citus.enable_schema_based_sharding TO ON; CREATE SCHEMA AUTHORIZATION user_service; CREATE SCHEMA AUTHORIZATION time_service; CREATE SCHEMA AUTHORIZATION ping_service; ``` ### 运行查询 查询将基于 `search_path` 或通过在查询中显式使用 schema 名称被正确路由到相应的 schema。 对于[微服务](https://docs.citusdata.com/en/stable/get_started/tutorial_microservices.html),您将为每个与 schema 名称匹配的服务创建一个 USER,因此默认的 `search_path` 将包含该 schema 名称。连接后,用户查询将自动路由,无需对微服务进行任何更改。 ``` CREATE USER user_service; CREATE SCHEMA AUTHORIZATION user_service; ``` 对于典型的多租户应用程序,您将在应用程序中将搜索路径设置为租户的 schema 名称: ``` SET search_path = tenant_name, public; ``` ## 设置高可用性 Citus 集群的 patronictl list 输出示例: ``` postgres@coord1:~$ patronictl list demo ``` ``` + Citus cluster: demo ----------+--------------+---------+----+-----------+ | Group | Member | Host | Role | State | TL | Lag in MB | +-------+---------+-------------+--------------+---------+----+-----------+ | 0 | coord1 | 172.27.0.10 | Replica | running | 1 | 0 | | 0 | coord2 | 172.27.0.6 | Sync Standby | running | 1 | 0 | | 0 | coord3 | 172.27.0.4 | Leader | running | 1 | | | 1 | work1-1 | 172.27.0.8 | Sync Standby | running | 1 | 0 | | 1 | work1-2 | 172.27.0.2 | Leader | running | 1 | | | 2 | work2-1 | 172.27.0.5 | Sync Standby | running | 1 | 0 | | 2 | work2-2 | 172.27.0.7 | Leader | running | 1 | | +-------+---------+-------------+--------------+---------+----+-----------+ ``` ## 文档 如果您准备好开始使用 Citus 或想了解更多信息,我们建议您阅读 [Citus 开源文档](https://docs.citusdata.com/en/stable/)。或者,如果您正在 Azure 上使用 Citus,那么可以从 [Azure Cosmos DB for PostgreSQL](https://learn.microsoft.com/azure/cosmos-db/postgresql/introduction) 开始。 我们的 Citus 文档包含关于如何构建[多租户 SaaS 应用程序](https://docs.citusdata.com/en/stable/use_cases/multi_tenant.html)、[实时分析仪表板]( https://docs.citusdata.com/en/stable/use_cases/realtime_analytics.html)或处理[时间序列数据](https://docs.citusdata.com/en/stable/use_cases/timeseries.html)的全面用例指南。 ## 架构 Citus 数据库集群通过添加 worker 节点,从单个 PostgreSQL 节点发展成为集群。在 Citus 集群中,应用程序连接的原始节点被称为主节点。Citus 主节点既包含分布式表和引用表的元数据,也包含常规(本地)表、序列和其他数据库对象(例如外部表)。 分布式表中的数据存储在“分片”中,这些分片实际上只是 worker 节点上的常规 PostgreSQL 表。在主节点上查询分布式表时,Citus 将向 worker 节点发送常规 SQL 查询。这样,所有常用的 PostgreSQL 优化和扩展都可以自动与 Citus 一起使用。  分布式表和引用表的 schema 和元数据会自动同步到集群中的所有节点。这样,您就可以连接到任何节点来运行分布式查询。schema 更改和集群管理仍然需要通过主节点进行。 为 Citus 开发者提供的实现详细描述在 [Citus 技术文档](src/backend/distributed/README.md)中。 ## 何时使用 Citus - **[面向客户的分析仪表板](http://docs.citusdata.com/en/stable/use_cases/realtime_analytics.html)**: Citus 使您能够构建分析仪表板,在数据库中同时摄取和处理大量数据,即使有大量并发用户也能提供亚秒级的响应时间。 Citus 中先进的并行、分布式查询引擎结合了 PostgreSQL 的功能(如[数组类型](https://www.postgresql.org/docs/current/arrays.html)、[JSONB](https://www.postgresql.org/docs/current/datatype-json.html)、[横向连接](https://heap.io/blog/engineering/postgresqls-powerful-new-join-type-lateral))和扩展(如 [HyperLogLog](https://github.com/citusdata/postgresql-hll) 和 [TopN](https://github.com/citusdata/postgresql-topn)),让您无论拥有多少客户或多少数据,都能构建响应迅速的分析仪表板。 实时分析用户示例:[Algolia](https://www.citusdata.com/customers/algolia) - **[时间序列数据](http://docs.citusdata.com/en/stable/use_cases/timeseries.html)**: Citus 使您能够处理和分析极大量的时间序列数据。最大的 Citus 集群存储了超过 1 PB 的时间序列数据,并且每天摄取数 TB 的数据。 Citus 与 [Postgres 表分区](https://www.postgresql.org/docs/current/ddl-partitioning.html)无缝集成,并具有[按时间分区的内置函数](https://www.citusdata.com/blog/2021/10/22/how-to-scale-postgres-for-time-series-data-with-citus/),可以加快时间序列表上的查询和写入速度。您可以利用 Citus 的并行、分布式查询引擎进行快速的分析查询,并使用内置的*列式存储*来压缩旧分区。 用户示例:[MixRank](https://www.citusdata.com/customers/mixrank) - **[软件即服务 应用程序](http://docs.citusdata.com/en/stable/use_cases/multi_tenant.html)**: SaaS 和其他多租户应用程序需要能够随着租户/客户数量的增长而扩展其数据库。Citus 使您能够按租户维度透明地对复杂数据模型进行分片,从而让您的数据库可以与您的业务一起增长。 通过沿租 ID 列分布表并协同定位同一租户的数据,Citus 可以水平扩展复杂(租户范围)的查询、事务和外键图。与手动分片相比,引用表和分布式 DDL 命令使数据库管理变得轻而易举。最重要的是,您拥有一个内置的分布式查询引擎,可以在数据库内部执行跨租户分析。 多租户 SaaS 用户示例:[Salesloft](https://fivetran.com/case-studies/replicating-sharded-databases-a-case-study-of-salesloft-citus-data-and-fivetran)、[ConvertFlow](https://www.citusdata.com/customers/convertflow) - **[微服务](https://docs.citusdata.com/en/stable/get_started/tutorial_microservices.html)**:Citus 支持基于 schema 的分片,允许将常规的数据库 schema 分布在多台机器上。这种分片方法非常适合典型的微服务架构,在这种架构中,存储完全由服务拥有,因此无法与其他租户共享相同的 schema 定义。Citus 允许在服务之间分布水平可扩展的状态,解决了微服务的[主要问题](https://stackoverflow.blog/2020/11/23/the-macro-problem-with-microservices/)之一。 - **地理空间**: 由于 Postgres 强大的 [PostGIS](https://postgis.net/) 扩展为 Postgres 添加了对地理对象的支持,许多人在 Postgres 之上运行空间/GIS 应用程序。并且由于空间位置信息已经成为我们日常生活的一部分,现在的地理空间应用程序比以往任何时候都多。当您的 Postgres 数据库需要向外扩展以处理增加的工作负载时,Citus 是一个很好的选择。 地理空间用户示例:[赫尔辛基地区交通管理局 (HSL)](https://customers.microsoft.com/story/845146-transit-authority-improves-traffic-monitoring-with-azure-database-for-postgresql-hyperscale)、[MobilityDB](https://www.citusdata.com/blog/2020/11/09/analyzing-gps-trajectories-at-scale-with-postgres-mobilitydb/)。 ## 需要帮助? ## 行为准则 本项目采用了 [微软开源行为准则](https://opensource.microsoft.com/codeofconduct/)。 有关更多信息,请参阅[行为准则常见问题解答](https://opensource.microsoft.com/codeofconduct/faq/)或 联系 [opencode@microsoft.com](mailto:opencode@microsoft.com) 并提出任何其他问题或意见。 ## 保持联系 版权所有 © Citus Data, Inc.
标签:多线程, 客户端加密, 测试用例, 请求拦截