Dao-AILab/flash-attention
GitHub: Dao-AILab/flash-attention
针对 Transformer 模型注意力机制的 GPU 加速库,通过 IO 感知算法显著降低显存占用并提升计算速度。
Stars: 24157 | Forks: 2831
# FlashAttention
本仓库提供了以下论文中 FlashAttention 和 FlashAttention-2 的官方实现。
**FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness**
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, Christopher Ré
论文: https://arxiv.org/abs/2205.14135
IEEE Spectrum 关于我们使用 FlashAttention 提交 MLPerf 2.0 基准测试的[文章](https://spectrum.ieee.org/mlperf-rankings-2022)。
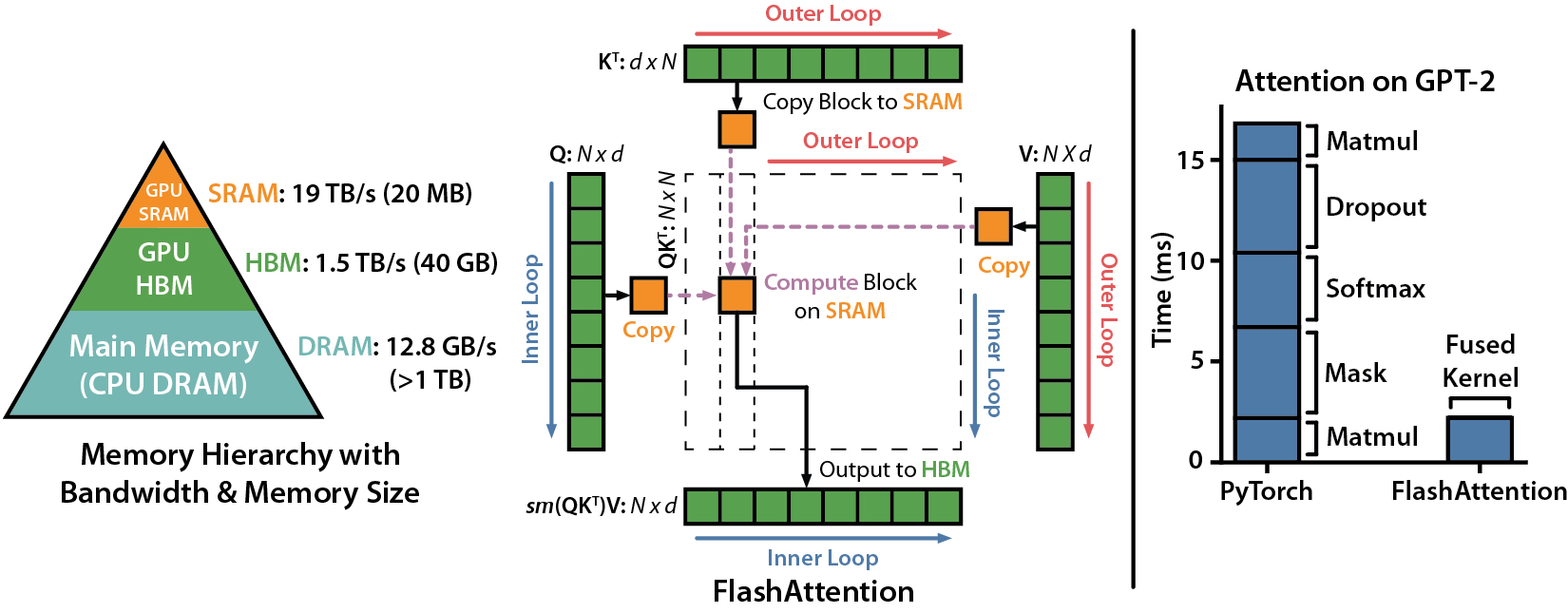
**FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning**
Tri Dao
论文: https://tridao.me/publications/flash2/flash2.pdf

## 用法
我们很高兴看到 FlashAttention 在发布后如此短的时间内被广泛采用。这个[页面](https://github.com/Dao-AILab/flash-attention/blob/main/usage.md)包含了使用 FlashAttention 的部分场景列表。
FlashAttention 和 FlashAttention-2 可免费使用和修改(参见 LICENSE)。
如果您使用了 FlashAttention,请引用并致谢。
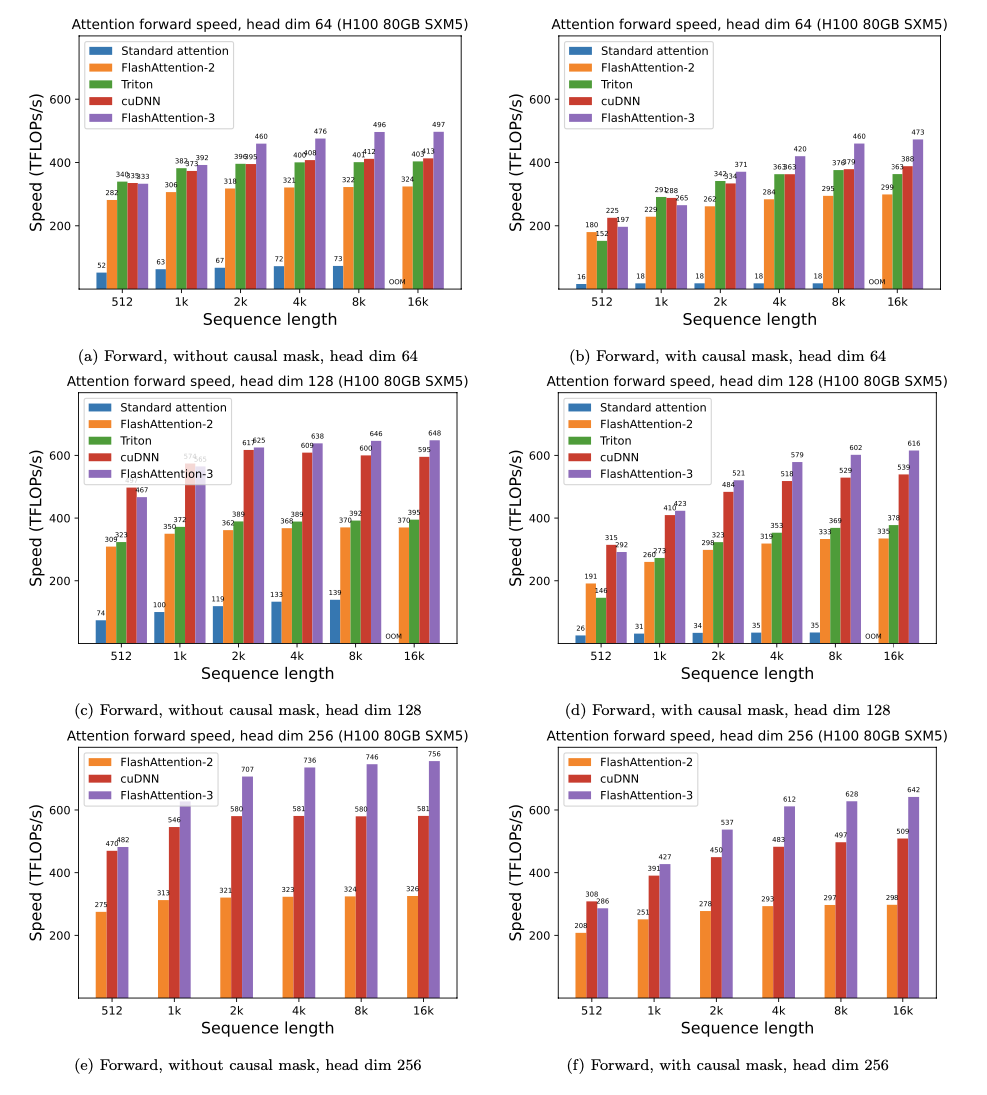
## FlashAttention-3 测试版发布
FlashAttention-3 针对 Hopper GPU(例如 H100)进行了优化。
博文: https://tridao.me/blog/2024/flash3/
论文: https://tridao.me/publications/flash3/flash3.pdf
这是一个测试版发布,用于在我们将其与仓库其余部分集成之前进行测试/基准测试。
当前已发布:
- FP16 / BF16 前向和反向传播,FP8 前向传播
要求: H100 / H800 GPU, CUDA >= 12.3。
我们强烈推荐使用 CUDA 12.8 以获得最佳性能。
安装:
```
cd hopper
python setup.py install
```
运行测试:
```
export PYTHONPATH=$PWD
pytest -q -s test_flash_attn.py
```
安装包之后,您可以按如下方式导入:
```
import flash_attn_interface
flash_attn_interface.flash_attn_func()
```
## FlashAttention-4 (CuTeDSL)
FlashAttention-4 使用 CuTeDSL 编写,并针对 Hopper 和 Blackwell GPU(例如 H100, B200)进行了优化。
安装:
```
pip install flash-attn-4
```
安装完成后,您可以按如下方式使用:
```
from flash_attn.cute import flash_attn_func
out = flash_attn_func(q, k, v, causal=True)
```
## 安装与功能
**要求:**
- CUDA toolkit 或 ROCm toolkit
- PyTorch 2.2 及以上版本。
- `packaging` Python 包 (`pip install packaging`)
- `psutil` Python 包 (`pip install psutil`)
- `ninja` Python 包 (`pip install ninja`) *
- Linux。从 v2.3.2 开始可能支持 Windows(我们看到了一些积极的[报告](https://github.com/Dao-AILab/flash-attention/issues/595)),但 Windows 编译仍需要更多测试。如果您有关于如何为 Windows 设置预构建 CUDA wheels 的想法,请通过 Github issue 联系我们。
\* 请确保 `ninja` 已安装且工作正常(例如 `ninja --version` 然后 `echo $?` 应该返回退出代码 0)。如果不是(有时 `ninja --version` 然后 `echo $?` 返回非零退出代码),请卸载然后重新安装 `ninja`(`pip uninstall -y ninja && pip install ninja`)。如果没有 `ninja`,编译可能会花费很长时间(2小时),因为它不使用多个 CPU 核心。使用 `ninja`,在使用 CUDA toolkit 的 64 核机器上编译只需 3-5 分钟。
**安装:**
```
pip install flash-attn --no-build-isolation
```
或者您可以从源码编译:
```
python setup.py install
```
如果您的机器内存小于 96GB 且有很多 CPU 核心,`ninja` 可能会运行过多的并行编译作业,从而耗尽内存。要限制并行编译作业的数量,您可以设置环境变量 `MAX_JOBS`:
```
MAX_JOBS=4 pip install flash-attn --no-build-isolation
```
**接口:** `src/flash_attention_interface.py`
### NVIDIA CUDA 支持
**要求:**
- CUDA 12.0 及以上版本。
我们推荐使用 Nvidia 的 [Pytorch](https://catalog.ngc.nvidia.com/orgs/nvidia/containers/pytorch) 容器,其中包含安装 FlashAttention 所需的所有工具。
支持 CUDA 的 FlashAttention-2 目前支持:
1. Ampere, Ada, 或 Hopper GPU(例如 A100, RTX 3090, RTX 4090, H100)。对 Turing GPU(T4, RTX 2080)的支持即将推出,请暂时在 Turing GPU 上使用 FlashAttention 1.x。
2. 数据类型 fp16 和 bf16(bf16 需要 Ampere, Ada, 或 Hopper GPU)。
3. 所有最大为 256 的 head 维度。~~Head dim > 192 backward 需要 A100/A800 或 H100/H800~~。从 flash-attn 2.5.5 开始,Head dim 256 backward 现在可在消费级 GPU 上运行(如果没有 dropout)。
### AMD ROCm 支持
ROCm 版本有两个后端。有 [composable_kernel](https://github.com/ROCm/composable_kernel) (ck),这是默认后端,以及一个 [Triton](https://github.com/triton-lang/triton) 后端。它们提供了 FlashAttention-2 的实现。
**要求:**
- ROCm 6.0 及以上版本。
我们推荐使用 ROCm 的 [Pytorch](https://hub.docker.com/r/rocm/pytorch) 容器,其中包含安装 FlashAttention 所需的所有工具。
#### Composable Kernel 后端
FlashAttention-2 ROCm CK 后端目前支持:
1. MI200x, MI250x, MI300x, 和 MI355x GPU。
2. 数据类型 fp16 和 bf16
3. 前向和反向传播的 head 维度最大为 256。
#### Triton 后端
[Flash Attention](https://tridao.me/publications/flash2/flash2.pdf) 的 Triton 实现支持 AMD 的 CDNA (MI200, MI300) 和 RDNA GPU,使用 fp16, bf16, 和 fp32 数据类型。它提供具有因果掩码、可变序列长度、任意 Q/KV 序列长度和 head 大小、MQA/GQA、dropout、rotary embeddings、ALiBi、paged attention 以及 FP8(通过 Flash Attention v3 接口)的前向和反向传播。Sliding window attention 目前正在开发中。
要安装,首先从 https://pytorch.org/get-started/locally/ 获取 PyTorch for ROCm,然后安装 Triton 和 Flash Attention:
```
pip install triton==3.5.1
cd flash-attention
FLASH_ATTENTION_TRITON_AMD_ENABLE="TRUE" python setup.py install
```
运行测试(注意:完整套件需要数小时):
```
FLASH_ATTENTION_TRITON_AMD_ENABLE="TRUE" pytest tests/test_flash_attn_triton_amd.py
```
为了获得更好的性能,请使用 `FLASH_ATTENTION_TRITON_AMD_AUTOTUNE="TRUE"` 启用 autotune。
或者,如果_不_进行 autotuning,可以使用 `FLASH_ATTENTION_FWD_TRITON_AMD_CONFIG_JSON` 来设置单个 triton 配置,以覆盖 `attn_fwd` 的硬编码默认值。例如:
```
FLASH_ATTENTION_FWD_TRITON_AMD_CONFIG_JSON='{"BLOCK_M":128,"BLOCK_N":64,"waves_per_eu":1,"PRE_LOAD_V":false,"num_stages":1,"num_warps":8}'
```
使用 Docker 快速入门:
```
FROM rocm/pytorch:latest
WORKDIR /workspace
# 安装 triton
RUN pip install triton==3.5.1
# 使用 triton 后端构建 flash attention
RUN git clone https://github.com/Dao-AILab/flash-attention &&\
cd flash-attention &&\
FLASH_ATTENTION_TRITON_AMD_ENABLE="TRUE" python setup.py install
# 设置工作目录
WORKDIR /workspace/flash-attention
# 设置环境变量以使用 triton 后端
ENV FLASH_ATTENTION_TRITON_AMD_ENABLE="TRUE"
```
构建并运行:
```
docker build -t flash-attn-triton .
docker run -it --network=host --user root --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ipc=host --shm-size 16G --device=/dev/kfd --device=/dev/dri flash-attn-triton
```
## 如何使用 FlashAttention
主要函数实现缩放点积注意力 (softmax(Q @ K^T * softmax_scale) @ V):
```
from flash_attn import flash_attn_qkvpacked_func, flash_attn_func
```
```
flash_attn_qkvpacked_func(qkv, dropout_p=0.0, softmax_scale=None, causal=False,
window_size=(-1, -1), alibi_slopes=None, deterministic=False):
"""dropout_p should be set to 0.0 during evaluation
If Q, K, V are already stacked into 1 tensor, this function will be faster than
calling flash_attn_func on Q, K, V since the backward pass avoids explicit concatenation
of the gradients of Q, K, V.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between [i - window_size[0], i + window_size[1]] inclusive.
Arguments:
qkv: (batch_size, seqlen, 3, nheads, headdim)
dropout_p: float. Dropout probability.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of (-alibi_slope * |i - j|) is added to
the attention score of query i and key j.
deterministic: bool. Whether to use the deterministic implementation of the backward pass,
which is slightly slower and uses more memory. The forward pass is always deterministic.
Return:
out: (batch_size, seqlen, nheads, headdim).
"""
```
```
flash_attn_func(q, k, v, dropout_p=0.0, softmax_scale=None, causal=False,
window_size=(-1, -1), alibi_slopes=None, deterministic=False):
"""dropout_p should be set to 0.0 during evaluation
Supports multi-query and grouped-query attention (MQA/GQA) by passing in KV with fewer heads
than Q. Note that the number of heads in Q must be divisible by the number of heads in KV.
For example, if Q has 6 heads and K, V have 2 heads, head 0, 1, 2 of Q will attention to head
0 of K, V, and head 3, 4, 5 of Q will attention to head 1 of K, V.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between
[i + seqlen_k - seqlen_q - window_size[0], i + seqlen_k - seqlen_q + window_size[1]] inclusive.
Arguments:
q: (batch_size, seqlen, nheads, headdim)
k: (batch_size, seqlen, nheads_k, headdim)
v: (batch_size, seqlen, nheads_k, headdim)
dropout_p: float. Dropout probability.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of
(-alibi_slope * |i + seqlen_k - seqlen_q - j|)
is added to the attention score of query i and key j.
deterministic: bool. Whether to use the deterministic implementation of the backward pass,
which is slightly slower and uses more memory. The forward pass is always deterministic.
Return:
out: (batch_size, seqlen, nheads, headdim).
"""
```
```
def flash_attn_with_kvcache(
q,
k_cache,
v_cache,
k=None,
v=None,
rotary_cos=None,
rotary_sin=None,
cache_seqlens: Optional[Union[(int, torch.Tensor)]] = None,
cache_batch_idx: Optional[torch.Tensor] = None,
block_table: Optional[torch.Tensor] = None,
softmax_scale=None,
causal=False,
window_size=(-1, -1), # -1 means infinite context window
rotary_interleaved=True,
alibi_slopes=None,
):
"""
If k and v are not None, k_cache and v_cache will be updated *inplace* with the new values from
k and v. This is useful for incremental decoding: you can pass in the cached keys/values from
the previous step, and update them with the new keys/values from the current step, and do
attention with the updated cache, all in 1 kernel.
If you pass in k / v, you must make sure that the cache is large enough to hold the new values.
For example, the KV cache could be pre-allocated with the max sequence length, and you can use
cache_seqlens to keep track of the current sequence lengths of each sequence in the batch.
Also apply rotary embedding if rotary_cos and rotary_sin are passed in. The key @k will be
rotated by rotary_cos and rotary_sin at indices cache_seqlens, cache_seqlens + 1, etc.
If causal or local (i.e., window_size != (-1, -1)), the query @q will be rotated by rotary_cos
and rotary_sin at indices cache_seqlens, cache_seqlens + 1, etc.
If not causal and not local, the query @q will be rotated by rotary_cos and rotary_sin at
indices cache_seqlens only (i.e. we consider all tokens in @q to be at position cache_seqlens).
See tests/test_flash_attn.py::test_flash_attn_kvcache for examples of how to use this function.
Supports multi-query and grouped-query attention (MQA/GQA) by passing in KV with fewer heads
than Q. Note that the number of heads in Q must be divisible by the number of heads in KV.
For example, if Q has 6 heads and K, V have 2 heads, head 0, 1, 2 of Q will attention to head
0 of K, V, and head 3, 4, 5 of Q will attention to head 1 of K, V.
If causal=True, the causal mask is aligned to the bottom right corner of the attention matrix.
For example, if seqlen_q = 2 and seqlen_k = 5, the causal mask (1 = keep, 0 = masked out) is:
1 1 1 1 0
1 1 1 1 1
If seqlen_q = 5 and seqlen_k = 2, the causal mask is:
0 0
0 0
0 0
1 0
1 1
If the row of the mask is all zero, the output will be zero.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between
[i + seqlen_k - seqlen_q - window_size[0], i + seqlen_k - seqlen_q + window_size[1]] inclusive.
Note: Does not support backward pass.
Arguments:
q: (batch_size, seqlen, nheads, headdim)
k_cache: (batch_size_cache, seqlen_cache, nheads_k, headdim) if there's no block_table,
or (num_blocks, page_block_size, nheads_k, headdim) if there's a block_table (i.e. paged KV cache)
page_block_size must be a multiple of 256.
v_cache: (batch_size_cache, seqlen_cache, nheads_k, headdim) if there's no block_table,
or (num_blocks, page_block_size, nheads_k, headdim) if there's a block_table (i.e. paged KV cache)
k [optional]: (batch_size, seqlen_new, nheads_k, headdim). If not None, we concatenate
k with k_cache, starting at the indices specified by cache_seqlens.
v [optional]: (batch_size, seqlen_new, nheads_k, headdim). Similar to k.
rotary_cos [optional]: (seqlen_ro, rotary_dim / 2). If not None, we apply rotary embedding
to k and q. Only applicable if k and v are passed in. rotary_dim must be divisible by 16.
rotary_sin [optional]: (seqlen_ro, rotary_dim / 2). Similar to rotary_cos.
cache_seqlens: int, or (batch_size,), dtype torch.int32. The sequence lengths of the
KV cache.
block_table [optional]: (batch_size, max_num_blocks_per_seq), dtype torch.int32.
cache_batch_idx: (batch_size,), dtype torch.int32. The indices used to index into the KV cache.
If None, we assume that the batch indices are [0, 1, 2, ..., batch_size - 1].
If the indices are not distinct, and k and v are provided, the values updated in the cache
might come from any of the duplicate indices.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
rotary_interleaved: bool. Only applicable if rotary_cos and rotary_sin are passed in.
If True, rotary embedding will combine dimensions 0 & 1, 2 & 3, etc. If False,
rotary embedding will combine dimensions 0 & rotary_dim / 2, 1 & rotary_dim / 2 + 1
(i.e. GPT-NeoX style).
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of
(-alibi_slope * |i + seqlen_k - seqlen_q - j|)
is added to the attention score of query i and key j.
Return:
out: (batch_size, seqlen, nheads, headdim).
"""
```
要查看这些函数如何在多头注意力层中使用(包括 QKV 投影,输出投影),请参阅 MHA [实现](https://github.com/Dao-AILab/flash-attention/blob/main/flash_attn/modules/mha.py)。
### 与 🤗 Kernels 一起使用
如果您的硬件环境属于上述任何一种,您也可以使用 [`kernels` 库](https://github.com/huggingface/kernels) 来立即使用 Flash Attention 2 和 3。
```
# pip 安装内核
from kernels import get_kernel
# FA2
fa_module = get_kernel("kernels-community/flash-attn2", version=1)
flash_attn_func = fa_module.flash_attn_func
# FA3
fa3_module = get_kernel("kernels-community/flash-attn3", version=1)
flash_attn_func = fa3_module.flash_attn_func
```
## 更新日志
### 2.0: 完全重写,速度提升 2 倍
从 FlashAttention (1.x) 升级到 FlashAttention-2
这些函数已重命名:
- `flash_attn_unpadded_func` -> `flash_attn_varlen_func`
- `flash_attn_unpadded_qkvpacked_func` -> `flash_attn_varlen_qkvpacked_func`
- `flash_attn_unpadded_kvpacked_func` -> `flash_attn_varlen_kvpacked_func`
如果同一批次中的输入具有相同的序列长度,使用这些函数会更简单且更快捷:
```
flash_attn_qkvpacked_func(qkv, dropout_p=0.0, softmax_scale=None, causal=False)
```
```
flash_attn_func(q, k, v, dropout_p=0.0, softmax_scale=None, causal=False)
```
### 2.1: 更改 causal 标志的行为
如果 seqlen_q != seqlen_k 且 causal=True,causal 掩码将对齐到注意力矩阵的右下角,而不是左上角。
例如,如果 seqlen_q = 2 且 seqlen_k = 5,causal 掩码(1 = 保留,0 = 屏蔽)为:
v2.0:
1 0 0 0 0
1 1 0 0 0
v2.1:
1 1 1 1 0
1 1 1 1 1
如果 seqlen_q = 5 且 seqlen_k = 2,causal 掩码为:
v2.0:
1 0
1 1
1 1
1 1
1 1
v2.1:
0 0
0 0
0 0
1 0
1 1
如果掩码的行全为零,则输出将为零。
### 2.2: 针对推理进行优化
当 query 具有非常小的序列长度(例如,query 序列长度 = 1)时,针对推理(迭代解码)进行优化。此处的瓶颈是尽可能快地加载 KV cache,我们将加载分散到不同的 thread block 中,并使用一个单独的 kernel 来合并结果。
请参阅函数 `flash_attn_with_kvcache`,它具有更多用于推理的功能(执行 rotary embedding,就地更新 KV cache)。
感谢 xformers 团队,特别是 Daniel Haziza 的合作。
### 2.3: 局部(即滑动窗口)注意力
实现滑动窗口注意力(即局部注意力)。感谢 [Mistral AI](https://mistral.ai/) 特别是 Timothée Lacroix 的贡献。Sliding window 在 [Mistral 7B](https://mistral.ai/news/announcing-mistral-7b/) 模型中被使用。
### 2.4: ALiBi (带线性偏置的注意力), 确定性反向传播。
实现 ALiBi (Press et al., 2021)。感谢 Kakao Brain 的 Sanghun Cho 的贡献。
实现确定性反向传播。感谢 [Meituan](www.meituan.com) 的工程师的贡献。
### 2.5: 分页 KV cache。
支持分页 KV cache(即 [PagedAttention](https://arxiv.org/abs/2309.06180))。
感谢 @beginlner 的贡献。
### 2.6: Softcapping。
支持带 softcapping 的注意力,如 Gemma-2 和 Grok 模型中所使用的。
感谢 @Narsil 和 @lucidrains 的贡献。
### 2.7: 与 torch compile 的兼容性
感谢 @ani300 的贡献。
## 性能
我们展示了在不同 GPU 上,根据序列长度的不同,使用 FlashAttention 相对于 PyTorch 标准注意力的预期加速(前向 + 反向传播结合)和内存节省(加速取决于内存带宽 - 我们在较慢的 GPU 内存上看到更多加速)。
目前我们有以下 GPU 的基准测试:
* [A100](#a100)
* [H100](#h100)
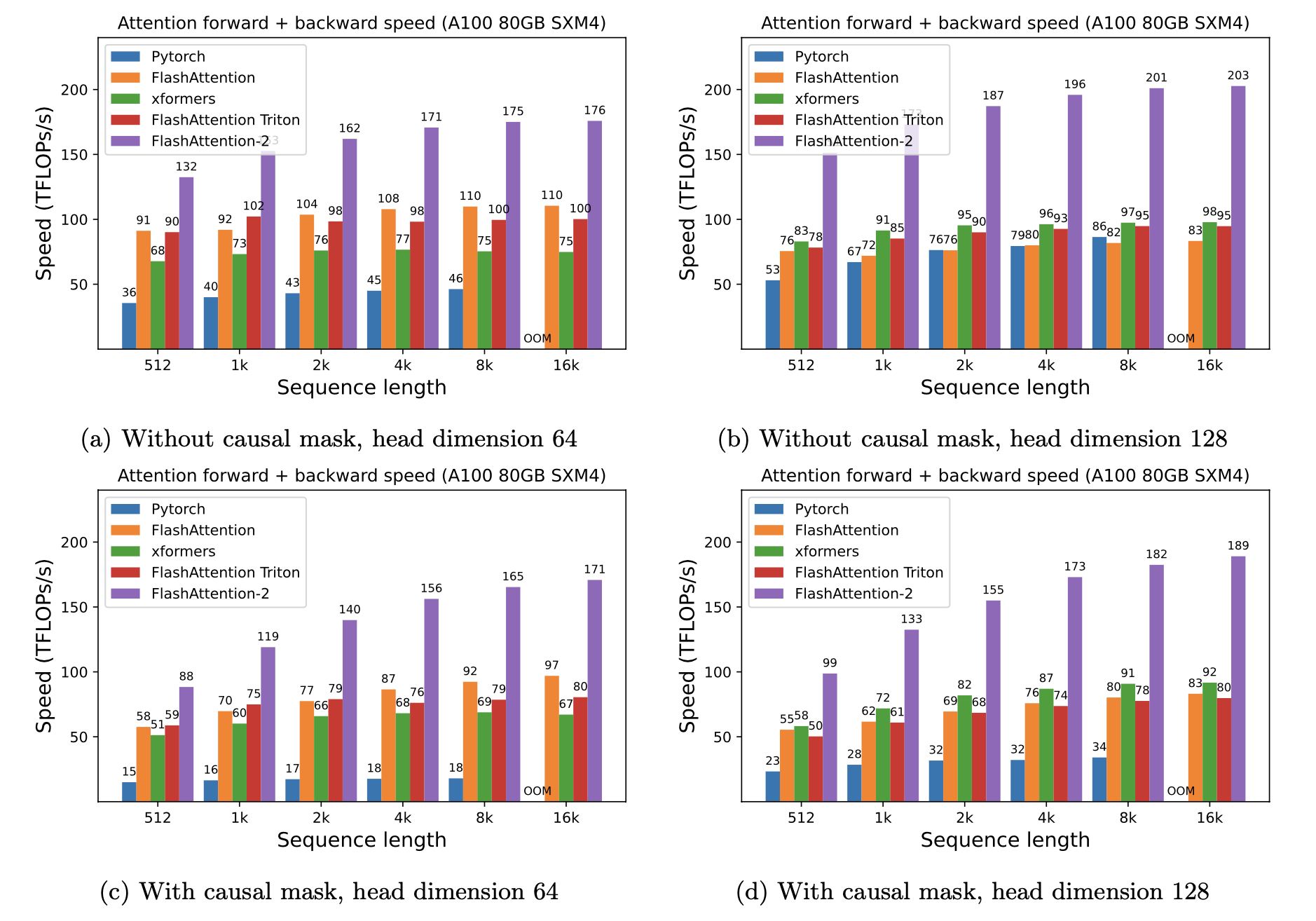
### A100
我们使用以下参数展示 FlashAttention 的加速效果:
* Head 维度 64 或 128,隐藏层维度 2048(即 32 或 16 个 heads)。
* 序列长度 512, 1k, 2k, 4k, 8k, 16k。
* Batch size 设置为 16k / seqlen。
#### 加速
#### 内存
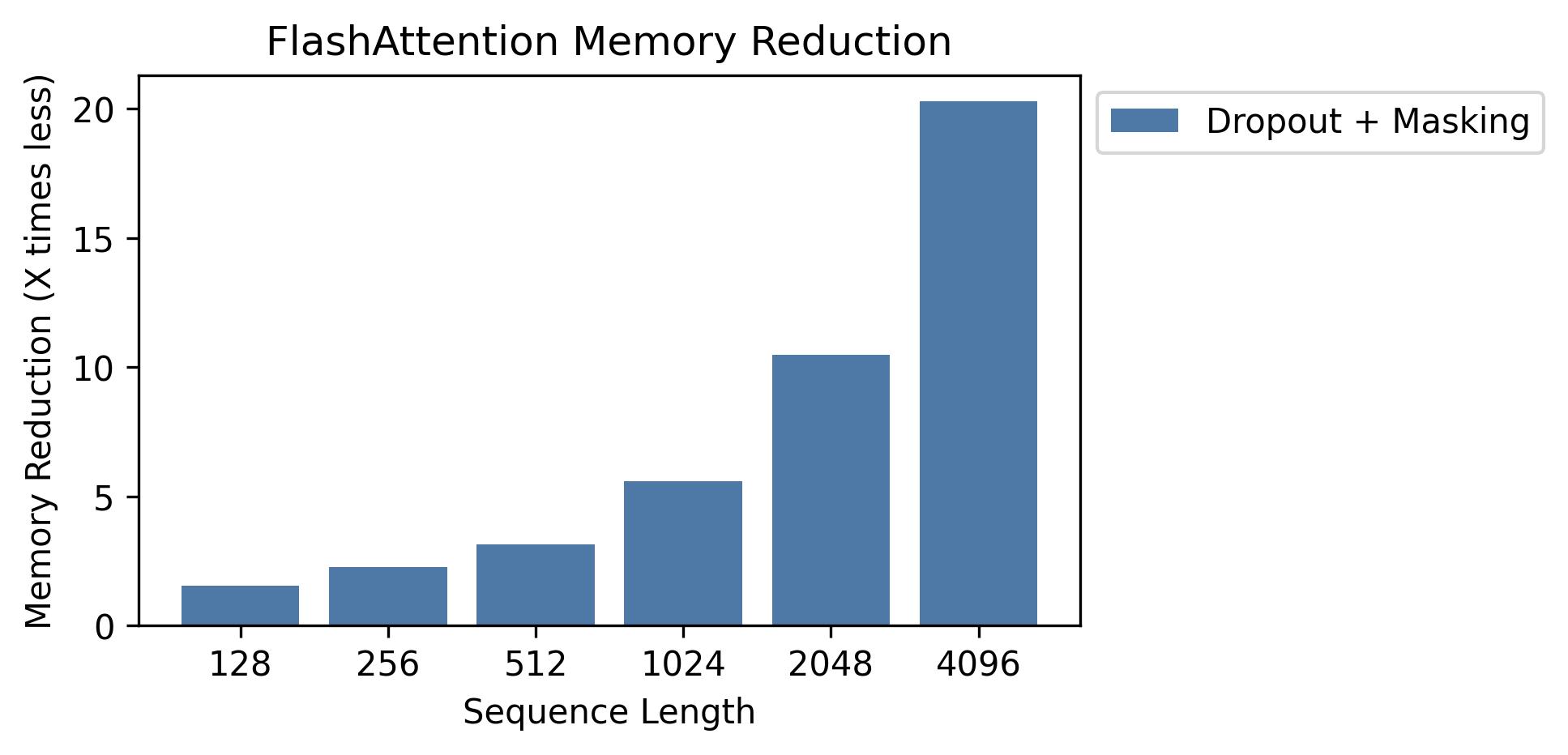
我们在此图表中展示了内存节省(请注意,无论您是否使用 dropout 或 masking,内存占用都是相同的)。
内存节省与序列长度成正比——因为标准注意力的内存与序列长度呈二次方关系,而 FlashAttention 的内存与序列长度呈线性关系。
我们在序列长度 2K 时看到 10 倍的内存节省,在 4K 时看到 20 倍。
因此,FlashAttention 可以扩展到更长的序列长度。
### H100
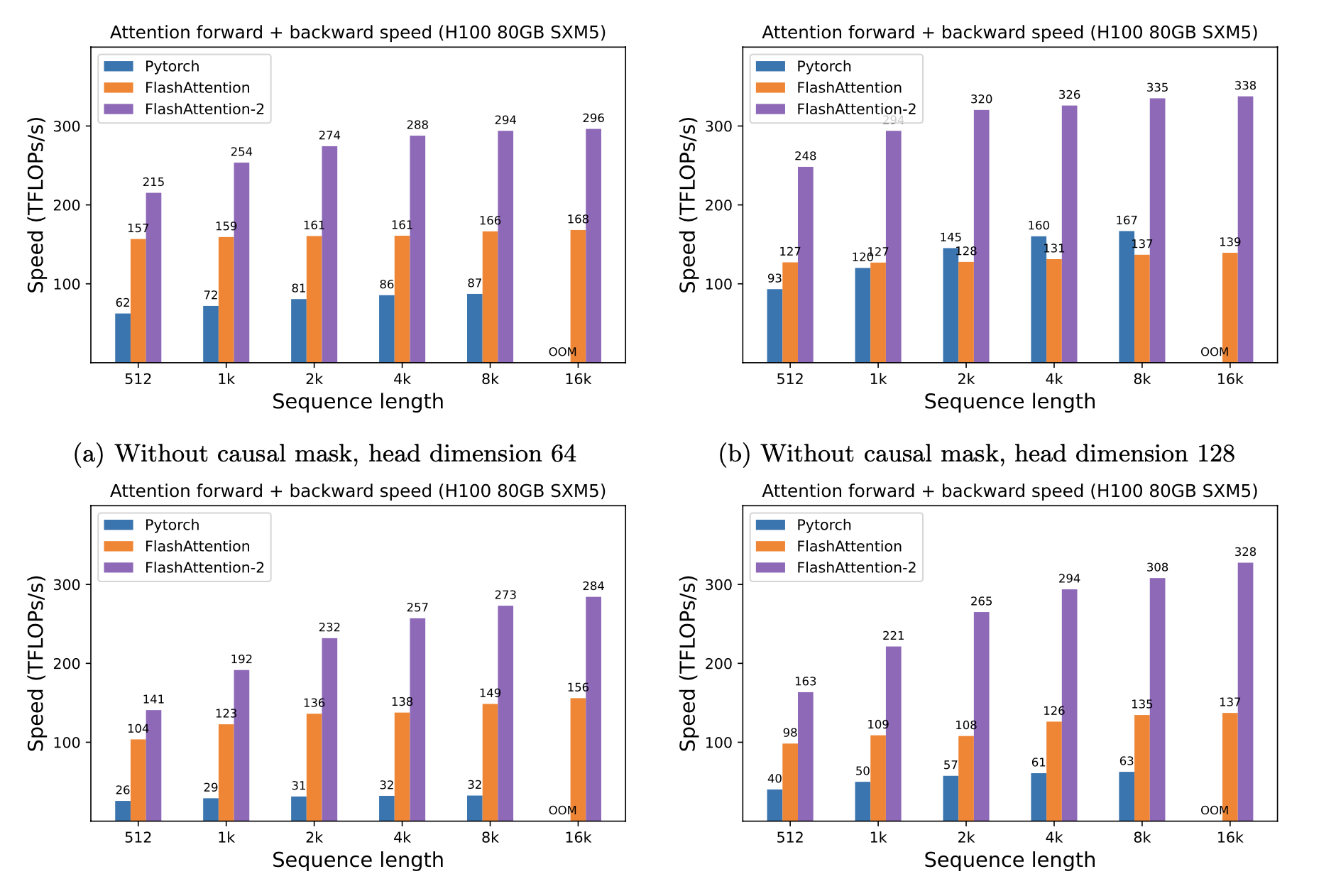
## 完整模型代码和训练脚本
我们发布了完整的 GPT 模型[实现](https://github.com/Dao-AILab/flash-attention/blob/main/flash_attn/models/gpt.py)。
我们还提供其他层的优化实现(例如 MLP, LayerNorm, cross-entropy loss, rotary embedding)。总体而言,与 Huggingface 的基线实现相比,这将训练速度提高了 3-5 倍,在每个 A100 上达到高达 225 TFLOPs/sec,相当于 72% 的模型 FLOPs 利用率(我们不需要任何 activation checkpointing)。
我们还包含了一个训练[脚本](https://github.com/Dao-AILab/flash-attention/tree/main/training),用于在 Openwebtext 上训练 GPT2 以及在 The Pile 上训练 GPT3。
## FlashAttention 的 Triton 实现
Phil Tillet (OpenAI) 在 Triton 中有一个 FlashAttention 的实验性:
https://github.com/openai/triton/blob/master/python/tutorials/06-fused-attention.py
由于 Triton 是比 CUDA 更高级的语言,它可能更容易理解和实验。Triton 实现中的符号也更接近我们论文中使用的符号。
我们还有一个支持注意力偏置(例如 ALiBi)的 Triton 实验性实现:
https://github.com/Dao-AILab/flash-attention/blob/main/flash_attn/flash_attn_triton.py
## 测试
我们测试 FlashAttention 是否产生与参考实现相同的输出和梯度,达到一定的数值容差。特别是,我们检查 FlashAttention 的最大数值误差是否最多是 Pytorch 中基线实现数值误差的两倍(对于不同的 head 维度、输入 dtype、序列长度、因果/非因果)。
运行测试:
```
pytest -q -s tests/test_flash_attn.py
```
## 当您遇到问题时
这个新版本的 FlashAttention-2 已经在多个 GPT 风格的模型上进行了测试,主要是在 A100 GPU 上。
如果您发现 bug,请提交 GitHub Issue!
## 测试
运行测试:
```
pytest tests/test_flash_attn_ck.py
```
## 引用
如果您使用此代码库,或认为我们的工作有价值,请引用:
```
@inproceedings{dao2022flashattention,
title={Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness},
author={Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{\'e}, Christopher},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2022}
}
@inproceedings{dao2023flashattention2,
title={Flash{A}ttention-2: Faster Attention with Better Parallelism and Work Partitioning},
author={Dao, Tri},
booktitle={International Conference on Learning Representations (ICLR)},
year={2024}
}
```
标签:AI基础设施, CUDA, FlashAttention, H100, HPC, IO感知, PyTorch, Transformer, Vectored Exception Handling, 人工智能, 凭据扫描, 大模型, 并行计算, 底层优化, 推理优化, 显存优化, 模型训练, 注意力机制, 深度学习, 用户模式Hook绕过, 计算加速, 逆向工具, 高性能计算