labgeek/HashExtractor
GitHub: labgeek/HashExtractor
一款基于 PyQt5 的桌面应用,能递归扫描 PDF 文件并自动识别提取其中的 MD5、SHA1、SHA256、SHA512 哈希值,结果输出为 CSV 文件。
Stars: 1 | Forks: 0
# HashExtractor
作者:labgeek@gmail.com (JD Durick)
`HashExtractor` 是一款 PyQt5 桌面应用程序,用于扫描文件夹中的 PDF 文件以查找加密哈希值,并将结果写入 CSV 格式的输出文件。它通过使用负向断言匹配精确的十六进制长度,来检测 MD5、SHA1、SHA256 和 SHA512 哈希值,从而确保较短的匹配模式永远不会在较长的模式中被匹配到。
 ## 支持的哈希类型
| 算法 | 十六进制长度 |
|-----------|-----------|
| MD5 | 32 |
| SHA1 | 40 |
| SHA256 | 64 |
| SHA512 | 128 |
## 功能
- 在单次扫描过程中检测 MD5、SHA1、SHA256 和 SHA512 哈希值。
- 递归 PDF 搜索 —— 包含所选文件夹下的所有 `.pdf` 文件。
- 多线程提取确保在长时间扫描期间 GUI 保持响应。
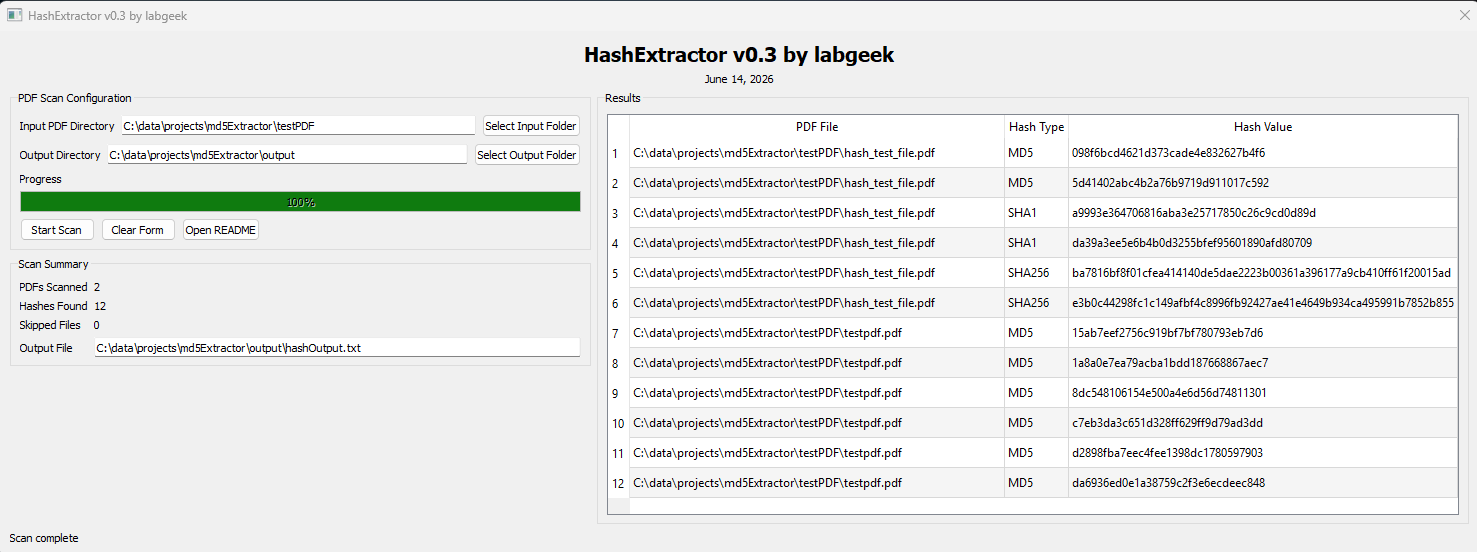
- 结果表包含三列:**PDF 文件**、**哈希类型** 和 **哈希值**。
- 交替的行颜色和可调整大小的列,提高可读性。
- 每处理一个文件更新一次的进度条。
- 扫描摘要面板显示已扫描的 PDF、找到的哈希、跳过的文件以及输出路径。
- 只读的输出路径字段,带有用于显示长路径的提示框。
- “清除表单”按钮可重置所有输入、结果、进度和摘要字段。
- README 查看器可在应用程序内的单独只读窗口中打开此文件。
- 如果输出目录尚不存在,则会自动创建。
- 同一 PDF 内重复的哈希值只会被写入一次。
- 跳过的文件(无法读取的 PDF)会被计数,但不会中断扫描。
## 环境要求
- Python 3
- `pypdf`
- `PyQt5`
从项目根目录安装依赖项:
```
python -m pip install -r requirements.txt
```
## 运行应用程序
```
cd C:\data\projects\md5Extractor
python hashExtractor.py
```
### GUI 控件
| 控件 | 描述 |
|---------|-------------|
| **输入 PDF 目录** 字段 | 输入或浏览选择包含 PDF 的文件夹。 |
| **选择输入文件夹** | 打开 PDF 目录的文件夹选择器。 |
| **输出目录** 字段 | 输入或浏览选择写入 `hashOutput.txt` 的文件夹。 |
| **选择输出文件夹** | 打开输出目录的文件夹选择器。 |
| **开始扫描** | 验证输入并开始多线程扫描。 |
| **清除表单** | 重置所有字段、结果表、进度条和摘要计数。 |
| **打开 README** | 在只读查看器中打开此文件。再次点击可将其关闭。|
您可以直接在任一目录字段中输入路径,而无需使用文件夹选择器。
## 输出文件
结果写入至:
```
## 支持的哈希类型
| 算法 | 十六进制长度 |
|-----------|-----------|
| MD5 | 32 |
| SHA1 | 40 |
| SHA256 | 64 |
| SHA512 | 128 |
## 功能
- 在单次扫描过程中检测 MD5、SHA1、SHA256 和 SHA512 哈希值。
- 递归 PDF 搜索 —— 包含所选文件夹下的所有 `.pdf` 文件。
- 多线程提取确保在长时间扫描期间 GUI 保持响应。
- 结果表包含三列:**PDF 文件**、**哈希类型** 和 **哈希值**。
- 交替的行颜色和可调整大小的列,提高可读性。
- 每处理一个文件更新一次的进度条。
- 扫描摘要面板显示已扫描的 PDF、找到的哈希、跳过的文件以及输出路径。
- 只读的输出路径字段,带有用于显示长路径的提示框。
- “清除表单”按钮可重置所有输入、结果、进度和摘要字段。
- README 查看器可在应用程序内的单独只读窗口中打开此文件。
- 如果输出目录尚不存在,则会自动创建。
- 同一 PDF 内重复的哈希值只会被写入一次。
- 跳过的文件(无法读取的 PDF)会被计数,但不会中断扫描。
## 环境要求
- Python 3
- `pypdf`
- `PyQt5`
从项目根目录安装依赖项:
```
python -m pip install -r requirements.txt
```
## 运行应用程序
```
cd C:\data\projects\md5Extractor
python hashExtractor.py
```
### GUI 控件
| 控件 | 描述 |
|---------|-------------|
| **输入 PDF 目录** 字段 | 输入或浏览选择包含 PDF 的文件夹。 |
| **选择输入文件夹** | 打开 PDF 目录的文件夹选择器。 |
| **输出目录** 字段 | 输入或浏览选择写入 `hashOutput.txt` 的文件夹。 |
| **选择输出文件夹** | 打开输出目录的文件夹选择器。 |
| **开始扫描** | 验证输入并开始多线程扫描。 |
| **清除表单** | 重置所有字段、结果表、进度条和摘要计数。 |
| **打开 README** | 在只读查看器中打开此文件。再次点击可将其关闭。|
您可以直接在任一目录字段中输入路径,而无需使用文件夹选择器。
## 输出文件
结果写入至:
```
\hashOutput.txt
```
该文件使用 CSV 格式,包含三列:
```
Absolute_Path,Hash_Type,Hash_Value
C:\path\to\file.pdf,MD5,44d88612fea8a8f36de82e1278abb02f
C:\path\to\file.pdf,SHA1,da39a3ee5e6b4b0d3255bfef95601890afd80709
C:\path\to\file.pdf,SHA256,e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855
C:\path\to\file.pdf,SHA512,cf83e1357eefb8bdf1542850d66d8007d620e4050b5715dc83f4a921d36ce9ce47d0d13c5d85f2b0ff8318d2877eec2f63b931bd47417a81a538327af927da3e
```
| 列 | 描述 |
|--------|-------------|
| `Absolute_Path` | 包含该哈希的 PDF 的完整文件系统路径。 |
| `Hash_Type` | 匹配的算法:`MD5`、`SHA1`、`SHA256` 或 `SHA512`。 |
| `Hash_Value` | 小写的十六进制哈希字符串。 |
在 PDF 中找到的每个唯一哈希值都会生成一行。如果同一个哈希在同一个 PDF 中出现多次,则只会被写入一次。每次扫描会话都会追加到文件中,并写入各自的表头行。
## 重要行为
- 哈希值仅通过十六进制长度和字符集进行匹配。应用程序不会验证匹配到的值是否为任何文件的实际哈希。
- 64 个字符的十六进制字符串将被归类为 SHA256,而不是两个 MD5 值。精确长度的负向断言可防止较短的匹配模式在较长的模式中被匹配到。
- 哈希值在存储和写入之前会被统一转换为小写。
- 无法打开或读取的 PDF 将被跳过,并在扫描摘要中进行计数,且不会停止扫描。
- `hashOutput.txt` 以追加模式打开,因此会保留先前扫描的结果。
- 控件在扫描运行期间会被禁用,并在完成或失败时重新启用。
- 除非事先应用了 OCR,否则纯图像或扫描版 PDF 不会产生结果。
## 项目结构
```
hashExtractor.py PyQt5 GUI, worker thread, and README viewer
extractor.py HashExtractor class — PDF walking, regex matching, CSV output
requirements.txt Runtime dependencies (pypdf, PyQt5)
testpdf.pdf Sample PDF for manual testing
README.md This file
contributors.txt Contributor information
```
## 实现说明
[extractor.py](extractor.py) 中的 `HashExtractor` 是核心类。它没有 GUI 依赖项,可以独立使用。
```
from extractor import HashExtractor
extractor = HashExtractor(directory="/path/to/pdfs", save_path="/path/to/hashOutput.txt")
results = extractor.extract()
# results: {pdf_path: (hash_type, hash_value) tuples 的集合}
```
### 核心方法
| 方法 | 描述 |
|--------|-------------|
| `dir_exists()` | 如果配置的输入目录存在,则返回 `True`。 |
| `read_dir()` | 递归查找输入目录下的所有 `.pdf` 文件,并已排序。 |
| `get_pdf_content(path)` | 使用 `pypdf` 提取 PDF 每一页的纯文本。 |
| `extract(...)` | 运行完整扫描,触发可选的回调,写入输出,并返回结果。 |
| `write_data()` | 将当前结果的 dict 以 CSV 格式追加到 `hashOutput.txt` 中。 |
`extract()` 接受三个可选的回调:
| 回调 | 签名 | 触发时机 |
|----------|-----------|------------|
| `progress_callback` | `(int)` | 每处理完一个 PDF 后(0–100)。 |
| `status_callback` | `(str)` | 当 PDF 由于错误被跳过时。 |
| `result_callback` | `(pdf_path, hash_type, hash_value)` | 每次找到哈希时。 |
[hashExtractor.py](hashExtractor.py) 中的 GUI 将这些回调连接到由运行在 `QThread` 中的 `ScanWorker` 发出的 PyQt5 信号。
## 开发验证
语法检查:
```
python -m py_compile hashExtractor.py extractor.py
```
构建独立的 Windows 可执行文件:
```
python -m PyInstaller --clean --onefile --windowed --name HashExtractor --hidden-import PyQt5.sip --add-data "README.md;." hashExtractor.py
```
`--add-data "README.md;."` 会将此 README 打包进去,以便编译后的可执行文件也能使用应用内的 README 查看器。
## 支持的哈希类型
| 算法 | 十六进制长度 |
|-----------|-----------|
| MD5 | 32 |
| SHA1 | 40 |
| SHA256 | 64 |
| SHA512 | 128 |
## 功能
- 在单次扫描过程中检测 MD5、SHA1、SHA256 和 SHA512 哈希值。
- 递归 PDF 搜索 —— 包含所选文件夹下的所有 `.pdf` 文件。
- 多线程提取确保在长时间扫描期间 GUI 保持响应。
- 结果表包含三列:**PDF 文件**、**哈希类型** 和 **哈希值**。
- 交替的行颜色和可调整大小的列,提高可读性。
- 每处理一个文件更新一次的进度条。
- 扫描摘要面板显示已扫描的 PDF、找到的哈希、跳过的文件以及输出路径。
- 只读的输出路径字段,带有用于显示长路径的提示框。
- “清除表单”按钮可重置所有输入、结果、进度和摘要字段。
- README 查看器可在应用程序内的单独只读窗口中打开此文件。
- 如果输出目录尚不存在,则会自动创建。
- 同一 PDF 内重复的哈希值只会被写入一次。
- 跳过的文件(无法读取的 PDF)会被计数,但不会中断扫描。
## 环境要求
- Python 3
- `pypdf`
- `PyQt5`
从项目根目录安装依赖项:
```
python -m pip install -r requirements.txt
```
## 运行应用程序
```
cd C:\data\projects\md5Extractor
python hashExtractor.py
```
### GUI 控件
| 控件 | 描述 |
|---------|-------------|
| **输入 PDF 目录** 字段 | 输入或浏览选择包含 PDF 的文件夹。 |
| **选择输入文件夹** | 打开 PDF 目录的文件夹选择器。 |
| **输出目录** 字段 | 输入或浏览选择写入 `hashOutput.txt` 的文件夹。 |
| **选择输出文件夹** | 打开输出目录的文件夹选择器。 |
| **开始扫描** | 验证输入并开始多线程扫描。 |
| **清除表单** | 重置所有字段、结果表、进度条和摘要计数。 |
| **打开 README** | 在只读查看器中打开此文件。再次点击可将其关闭。|
您可以直接在任一目录字段中输入路径,而无需使用文件夹选择器。
## 输出文件
结果写入至:
```
标签:PDF处理, PyQt5, 哈希提取, 文本提取, 桌面应用, 漏洞挖掘, 逆向工具