GoogleCloudPlatform/dlp-pdf-redaction
GitHub: GoogleCloudPlatform/dlp-pdf-redaction
该方案利用Google Cloud服务构建无服务器架构,自动识别并脱敏PDF文件中的敏感数据。
Stars: 66 | Forks: 29
# 解决方案指南
本解决方案提供了一种自动化、无服务器的方式,使用 Google Cloud 服务(如 [Data Loss Prevention (DLP)](https://cloud.google.com/dlp)、[Cloud Workflows](https://cloud.google.com/workflows) 和 [Cloud Run](https://cloud.google.com/run))对 PDF 文件中的敏感数据进行脱敏。
## 解决方案架构图
下图描述了 PDF 脱敏流程的解决方案架构。
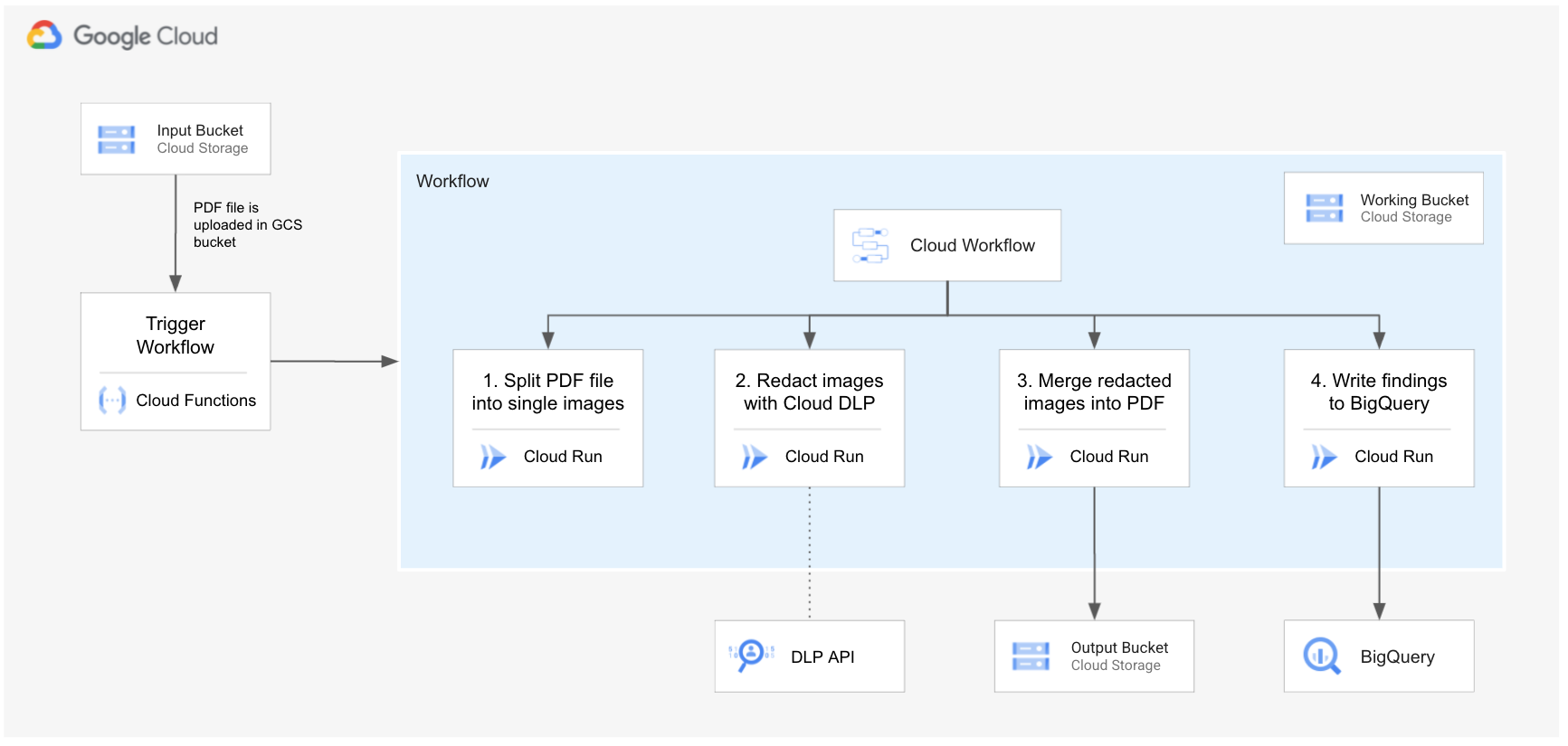
## 工作流步骤
该工作流包含以下步骤:
1. 用户将 PDF 文件上传到 GCS 存储桶
2. [EventArc](https://cloud.google.com/eventarc/docs) 触发一个工作流。该工作流编排 PDF 文件脱敏,包含以下步骤:
- 将 PDF 拆分为单页,将页面转换为图像,并将它们存储在工作存储桶中
- 使用 DLP 图像脱敏 API 对每个图像进行脱敏
- 从脱敏后的图像列表中重新组装 PDF 文件,并将其存储在 GCS 上(输出存储桶)
- 将脱敏的引用结果写入 BigQuery
# 部署 PDF 脱敏应用
`terraform` 文件夹包含部署 PDF 脱敏应用程序所需的代码。
## 创建了哪些资源?
主要资源:
- Workflow(工作流)
- 为每个组件提供 CloudRun 服务,包括其服务账号和权限
1. `pdf-spliter` - 将 PDF 拆分为单页图像文件
2. `dlp-runner` - 将每个页面文件通过 DLP 运行以脱敏敏感信息
3. `pdf-merger` - 将页面重新组装为单个 PDF
4. `findings-writer` - 将发现结果写入 BigQuery
- Cloud Storage 存储桶
- *输入存储桶* - 存储原始文件的存储桶
- *工作存储桶* - 一个工作存储桶,用于在整个不同的工作流阶段存储所有临时文件
- *输出存储桶* - 存储脱敏文件的存储桶
- DLP 模板,其中指定了 InfoTypes 和规则。您可以修改 `dlp.tf` 文件来指定您自己的 INFO_TYPES 和规则集(请参阅 [DLP 模板的 terraform 文档](https://registry.terraform.io/providers/hashicorp/google/latest/docs/resources/data_loss_prevention_inspect_template))
- 用于写入发现结果的 BigQuery 数据集和表
## 如何部署?
应在 Google Cloud Console 的 Cloud Shell 中执行以下步骤。
### 1. 创建项目并启用结算
按照 [本指南](https://cloud.google.com/resource-manager/docs/creating-managing-projects) 中的步骤操作。
### 2. 获取代码
克隆此 github 仓库并转到仓库的根目录。
```
git clone https://github.com/GoogleCloudPlatform/dlp-pdf-redaction
cd dlp-pdf-redaction
```
### 3. 为 Cloud Run 构建镜像
您首先需要为每个微服务构建 docker 镜像。
```
PROJECT_ID=[YOUR_PROJECT_ID]
PROJECT_NUMBER=$(gcloud projects list --filter="PROJECT_ID=$PROJECT_ID" --format="value(PROJECT_NUMBER)")
REGION=us-central1
DOCKER_REPO_NAME=pdf-redaction-docker-repo
CLOUD_BUILD_SERVICE_ACCOUNT=cloudbuild-sa
# 启用必需的 APIs
gcloud services enable cloudbuild.googleapis.com artifactregistry.googleapis.com --project $PROJECT_ID
# 创建 Docker image repo 以存储应用 docker images
gcloud artifacts repositories create $DOCKER_REPO_NAME --repository-format=docker --description="PDF Redaction Docker Image repository" --project $PROJECT_ID --location=$REGION
# 为 CloudBuild 创建 Service Account 并授予必需的角色
gcloud iam service-accounts create $CLOUD_BUILD_SERVICE_ACCOUNT \
--description="Service Account for CloudBuild created by PDF Redaction solution" \
--display-name="CloudBuild SA (PDF Readaction)"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$CLOUD_BUILD_SERVICE_ACCOUNT@$PROJECT_ID.iam.gserviceaccount.com" \
--role="roles/cloudbuild.serviceAgent"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$CLOUD_BUILD_SERVICE_ACCOUNT@$PROJECT_ID.iam.gserviceaccount.com" \
--role="roles/storage.objectUser"
# 构建应用的 docker images 并将其存储在 artifact registry repo
gcloud builds submit \
--config ./build-app-images.yaml \
--substitutions _REGION=$REGION,_DOCKER_REPO_NAME=$DOCKER_REPO_NAME \
--service-account=projects/$PROJECT_ID/serviceAccounts/$CLOUD_BUILD_SERVICE_ACCOUNT@$PROJECT_ID.iam.gserviceaccount.com \
--default-buckets-behavior=regional-user-owned-bucket \
--project $PROJECT_ID
```
注意:如果您收到权限弹窗,可以授权 gcloud 请求您的凭据并发出 GCP API 调用。
上述命令将构建 4 个 docker 镜像并将其推送到 Google Container Registry (GCR)。运行以下命令并确认镜像存在于 GCR 中。
```
gcloud artifacts docker images list $REGION-docker.pkg.dev/$PROJECT_ID/$DOCKER_REPO_NAME
```
### 4. 使用 Terraform 部署基础设施
此 terraform 部署需要以下变量。
- project_id = "YOUR_PROJECT_ID"
- region = "YOUR_REGION_REGION"
- docker_repo_name = "DOCKER_REPO_NAME"
- wf_region = "YOUR_WORKFLOW_REGION"
从此仓库的根文件夹,运行以下命令:
```
export TF_VAR_project_id=$PROJECT_ID
export TF_VAR_region=$REGION
export TF_VAR_wf_region=$REGION
export TF_VAR_docker_repo_name=$DOCKER_REPO_NAME
terraform -chdir=terraform init
terraform -chdir=terraform apply -auto-approve
```
**注意:**
* 如果遇到与 `eventarc` 或 `worklflows` 配置相关的错误,请稍等几秒钟,然后重新运行 `terraform -chdir=terraform apply -auto-approve` 命令。解释:Terraform 会启用某些服务(如 `eventarc` 和 `workflows`),这些服务可能需要几分钟才能完成资源配置和权限设置,只需重新运行 apply 命令即可解决此问题。
* 区域和工作流区域默认均为 `us-central1`。如果您希望将资源部署在不同的区域,请指定 `region` 和 `wf_region` 变量(即使用 `TF_VAR_region` 和 `TF_VAR_wf_region`)。Cloud Workflows 仅在特定区域可用,更多信息请查看 [文档](https://cloud.google.com/workflows/docs/locations)。
* 如果遇到问题,请查看 [问题部分](https://github.com/GoogleCloudPlatform/dlp-pdf-redaction/issues)。如果您的问题未在其中列出,请将其报告为新问题。
### 5. 记录 Terraform 输出
一旦 terraform 完成所有资源的配置,您将看到其输出。请注意 `input_bucket` 和 `output_bucket` 存储桶。上传到 `input_bucket` 存储桶的文件将自动处理,脱敏后的文件将被写入 `output_bucket` 存储桶。
如果您错过了首次运行的输出,可以通过运行以下命令列出输出
```
terraform -chdir=terraform output
```
### 6. 测试
使用以下命令将测试文件上传到 `input_bucket`。几秒钟后,您应该在 `output_bucket` 中看到脱敏后的 PDF 文件。
```
gcloud storage cp ./test_file.pdf [INPUT_BUCKET_FROM_OUTPUT e.g. gs://pdf-input-bucket-xxxx]
```
如果您对幕后操作感兴趣,可以尝试:
- 在 `output_bucket` 中查看脱敏后的文件。
gcloud storage ls [OUTPUT_BUCKET_FROM_OUTPUT e.g. gs://pdf-output-bucket-xxxx]
- 下载脱敏后的 pdf 文件,使用您首选的 pdf 阅读器打开它,并在 PDF 文件中搜索文本。
- 在 GCP Web 控制台中查看 [Cloud Workflows](https://console.cloud.google.com/workflows)。您将看到当您将文件上传到 GCS 时触发了工作流执行。
- 探索 BigQuery 中的 `pdf_redaction_xxxx` 数据集,并查看插入到 `findings` 表中的元数据。
标签:API, BigQuery, Cloud Run, Cloud Storage, Cloud Workflows, Data Loss Prevention, DLP, ECS, EventArc, GCP, Google Cloud, PDF 处理, PDF 红字, Serverless, Terraform, 合规, 敏感信息处理, 数据脱敏, 网络安全, 请求拦截, 隐私保护