
[](https://github.com/spiceai/spiceai/actions/workflows/codeql-analysis.yml?query=branch%3Atrunk+event%3Apush)
[](https://opensource.org/licenses/Apache-2.0)
[](https://spice.ai/slack)
[](https://x.com/intent/follow?screen_name=spice_ai)
[](https://github.com/spiceai/spiceai/stargazers)
[](https://github.com/spiceai/spiceai/actions/workflows/build_nightly.yml?query=branch%3Atrunk)
[](https://github.com/spiceai/spiceai/actions/workflows/spiced_docker_dev.yml?query=branch%3Atrunk)
[](https://github.com/spiceai/spiceai/actions/workflows/build_and_release.yml?query=branch%3Atrunk)
[](https://github.com/spiceai/spiceai/actions/workflows/integration.yml?query=branch%3Atrunk)
[](https://github.com/spiceai/spiceai/actions/workflows/integration_models.yml?query=branch%3Atrunk)
[](https://github.com/spiceai/spiceai/actions/workflows/testoperator_run_bench.yml?query=branch%3Atrunk)
📄 Docs | ⚡️ Quickstart | 🧑🍳 Cookbook | 🤖 AI Skills | 📰 Blog
**Spice** is a portable, accelerated SQL query, search, and LLM-inference engine, written in Rust, for data-grounded AI apps and agents. Run it as a sidecar next to your application — or scale to a multi-node distributed cluster — to get **millisecond data and AI on localhost**, backed by your existing data sources.
🎯 **Goal**: Build data-grounded AI apps and agents in minutes, not months. No pipelines. No glue. Just SQL, search, and inference — federated across your data, accelerated locally, served on localhost.
## Why Spice?
- 🚀 **Localhost latency at any scale** — Millisecond queries against a sandboxed working set on each pod, transparently delegated to a distributed cluster for the long tail.
- 🦀 **Built in Rust** on industry-leading open foundations: [Apache DataFusion](https://datafusion.apache.org), [Apache Ballista](https://datafusion.apache.org/ballista/), [Apache Arrow](https://arrow.apache.org), [Apache Iceberg](https://iceberg.apache.org), [Vortex](https://github.com/vortex-data/vortex), [DuckDB](https://duckdb.org), and [SQLite](https://www.sqlite.org).
- ⚡ **Distributed query without the operational tax** — Apache Ballista with multi-active schedulers coordinated through object storage. **2.9x faster than single-node DataFusion** on TPC-H SF100, **8x less RAM than Spark**.
- 💎 **Spice Cayenne** data accelerator on Vortex — **1.4x faster than DuckDB with 3x less memory** on TPC-H SF100. **100x faster random access vs. Parquet**.
- 🔍 **Petabyte-scale hybrid search** — Native Amazon S3 Vectors, Tantivy BM25, DuckDB HNSW, and Elasticsearch kNN, with reciprocal rank fusion (RRF) and reranker UDTFs — all in a single SQL query.
- 🤖 **AI-native runtime** — OpenAI-compatible APIs, MCP server + gateway, LLM memory, NSQL text-to-SQL, multi-vector ColBERT-style embeddings, provider-aware prompt caching.
- 🔗 **30+ data connectors** with advanced query push-down — federate Postgres, MySQL, Snowflake, Databricks, Iceberg, Delta Lake, S3, Spark, MSSQL, DynamoDB, MongoDB, GitHub, SharePoint, Kafka, and more.
- ⏱️ **Real-time CDC** — Native PostgreSQL WAL streaming and DynamoDB Streams (no Debezium or Kafka required), plus Debezium when you need it.
- 📝 **Open table formats, first-class** — Query, **accelerate, and write** to Apache Iceberg with ACID guarantees via standard SQL `INSERT INTO`. No Spark required.
- 🛡️ **Enterprise-ready** — HashiCorp Vault and Azure Key Vault secret stores, mTLS, read-only API keys, observability via OpenTelemetry, and an extensibility model used in production at companies like Twilio and Barracuda.
📣 **Latest:** Read [Localhost Latency at Scale: The Spice Cluster-Sidecar Architecture](https://spice.ai/blog/cluster-sidecar-architecture) and [Apache Ballista at Spice AI: Distributed Query Execution Without the Operational Tax](https://spice.ai/blog/apache-ballista-at-spice-ai). | [📊 2025 Year in Review](https://spice.ai/blog/2025-spice-ai-year-in-review)
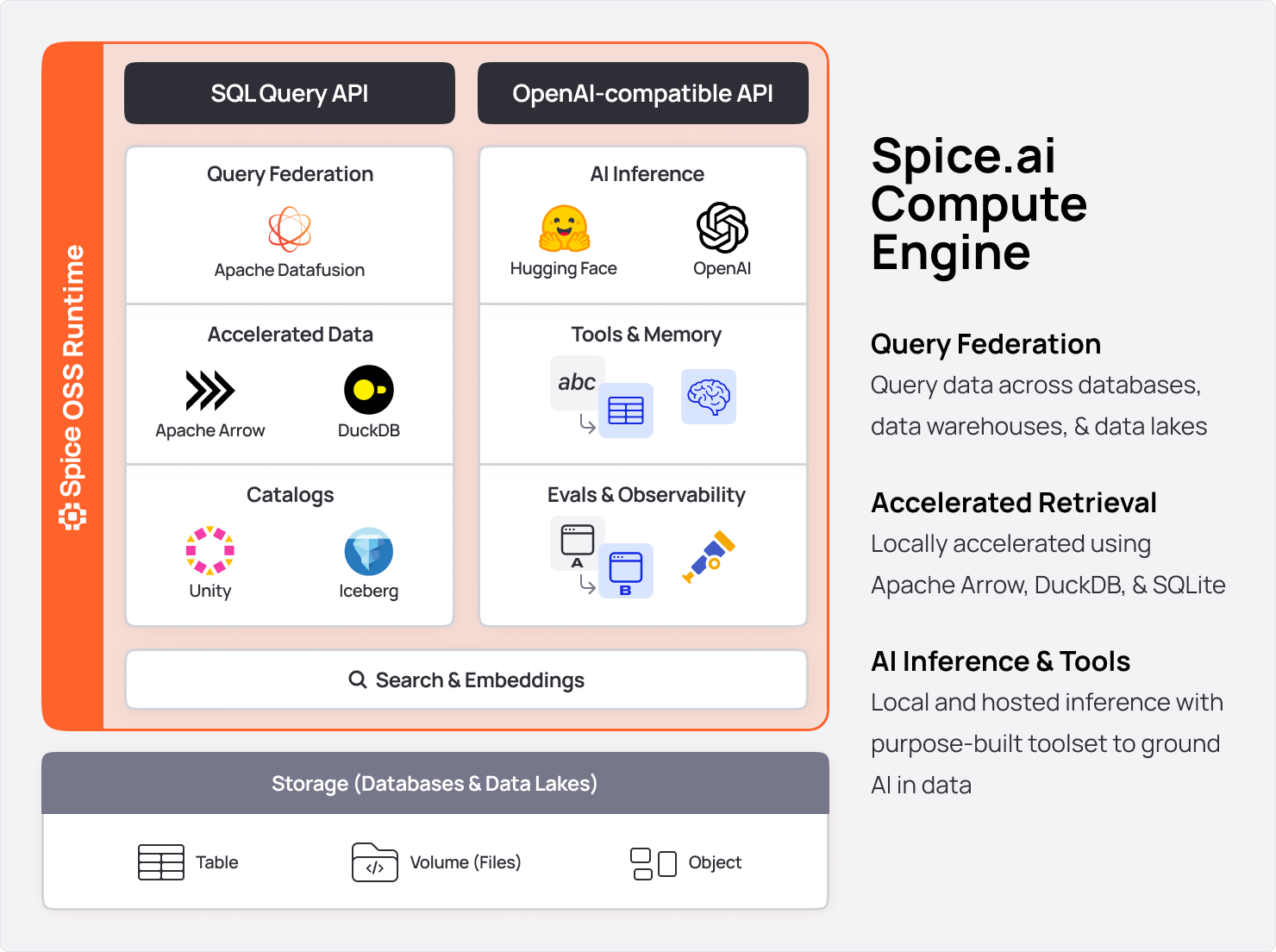
## What you get
Spice provides five APIs and interfaces in a lightweight, portable runtime (single binary or container):
1. **SQL Query & Search**: HTTP, Arrow Flight, Arrow Flight SQL, ODBC, JDBC, and ADBC APIs; `vector_search`, `text_search`, `rrf`, and `rerank` UDTFs.
2. **Text-to-SQL (NSQL)**: Natural-language SQL generation grounded in your federated schema with built-in sampling tools — usable from the HTTP API, the SQL REPL, or directly inside agent tool calls.
3. **OpenAI-Compatible APIs**: Hosted LLM gateway (OpenAI, Anthropic, xAI, Bedrock) and local model serving (CUDA/Metal accelerated). Includes the OpenAI Responses API, web search, and tool calls.
4. **Iceberg Catalog REST APIs**: A unified Iceberg REST Catalog API for query and write.
5. **MCP HTTP+SSE APIs**: Model Context Protocol server *and* gateway with Streamable HTTP transport.
## 🎥 Watch & Learn
- 🎓 [**CMU Databases: Accelerating Data and AI with Spice.ai Open-Source**](https://www.youtube.com/watch?v=tyM-ec1lKfU) — Luke Kim at the Carnegie Mellon Database Group
- ☁️ [**AWS re:Invent 2025 (STG364): How Spice AI operationalizes data lakes for AI using Amazon S3**](https://www.youtube.com/watch?v=KuWI0yDOnIU)
- 🔍 [**How to search with Amazon S3 Vectors**](https://www.youtube.com/watch?v=QPbqPf5W36g)
- 💎 [**Introducing the Spice Cayenne Data Accelerator**](https://www.youtube.com/watch?v=HTdv6-cxKV4)
- 🧊 [**Writing to Apache Iceberg Tables with Spice.ai**](https://www.youtube.com/watch?v=LGGFmNN9-3w)
- 🔌 [**Using Spice as an MCP Server and Gateway**](https://www.youtube.com/watch?v=0Cm-_xqVBFU)
- 🛠️ [**How to Query Data using Spice, OpenAI, and MCP**](https://www.youtube.com/watch?v=TFAu4qxjTPk)
📺 More on the [Spice.ai YouTube channel](https://www.youtube.com/playlist?list=PLesJrUXEx3U9anekJvbjyyTm7r9A26ugK).
## What's New
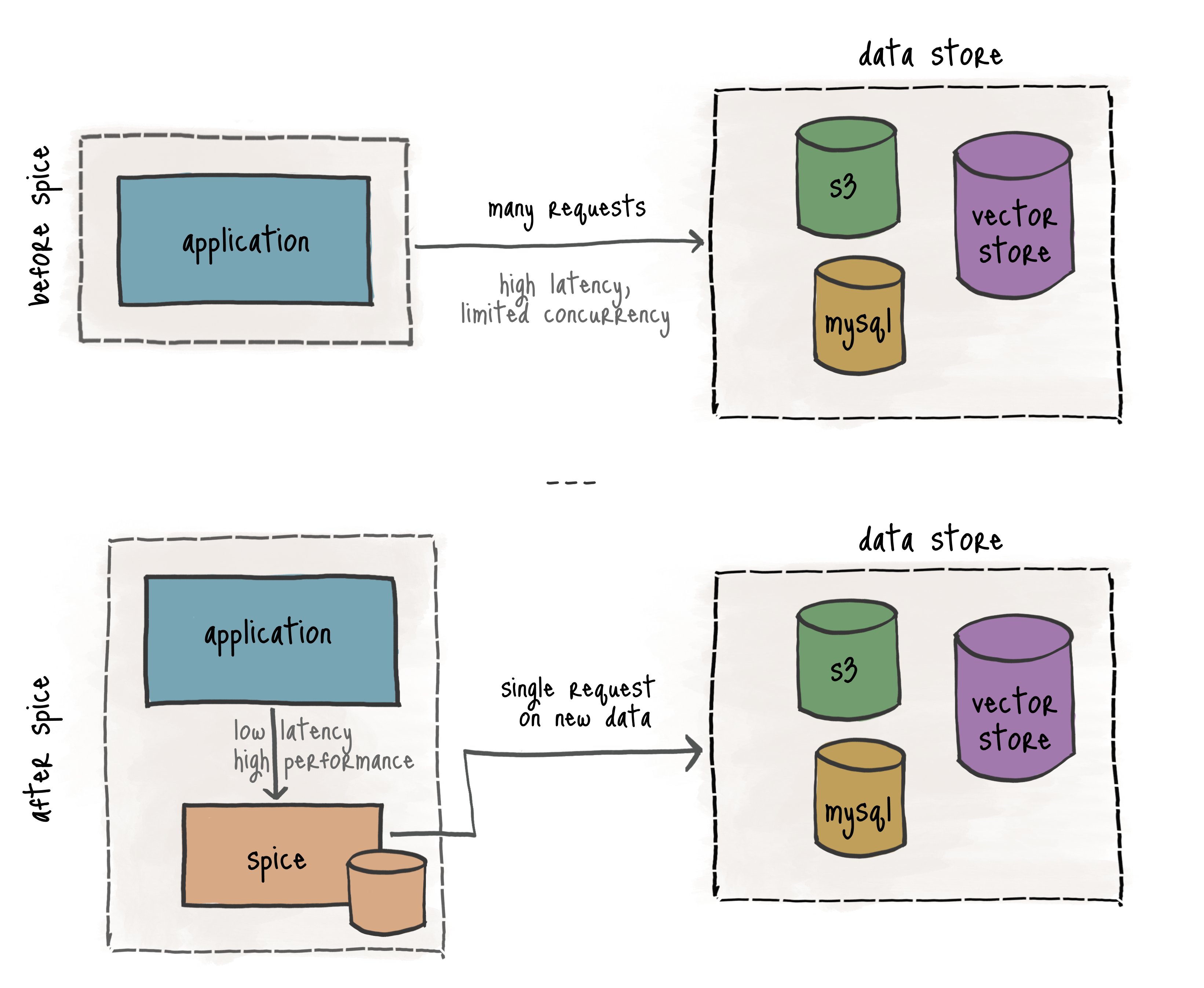
### Cluster-Sidecar Architecture: localhost latency, cluster scale
Each application gets a complete data plane on `localhost`. A lightweight Spice sidecar runs in the application pod, serves SQL/search/LLM-inference from a scoped working set, and transparently delegates the long tail to a central Spice cluster (Ballista distributed query, Cayenne acceleration, hybrid search indexing) over Arrow Flight. Three latency tiers: results cache (microseconds) → local working set (single-digit milliseconds) → cluster delegation. The application **never holds credentials** to Postgres, S3, Snowflake, or Iceberg — only a token to its sidecar. [Read the architecture deep dive →](https://spice.ai/blog/cluster-sidecar-architecture)
### Apache Ballista distributed query
Spice extends Apache Ballista with **multi-active scheduler HA coordinated through object storage** (no etcd, ZooKeeper, or Redis required), bidirectional gRPC control streams, mandatory mTLS, multiple shuffle backends (local, in-memory, S3/Azure/GCS), Vortex-encoded shuffle data, and distributed embeddings inside SQL. **TPC-H SF100: 2.9x faster than single-node DataFusion. 8x less RAM than Apache Spark with 2–8x better query performance** in early preview. [Read the engineering deep dive →](https://spice.ai/blog/apache-ballista-at-spice-ai)
### Spice Cayenne — next-gen data acceleration on Vortex
Cayenne pairs the [Vortex columnar format](https://github.com/vortex-data/vortex) with SQLite metadata to deliver multi-file acceleration without DuckDB's single-file ceiling or memory overhead. **TPC-H SF-100: 1.4x faster than DuckDB-file with 3x less memory. ClickBench: 14% faster, 3.4x less memory.** Vortex itself is **100x faster on random access**, **10–20x faster on full scans**, and **5x faster writes** than Parquet — compute kernels run directly on encoded data, skipping decompression entirely for many operations. [Read the Vortex deep dive →](https://spice.ai/blog/vortex-at-spice-ai-the-columnar-format-for-data-intensive-workloads)
### Apache Iceberg: query, accelerate, and write
Connect to any Iceberg catalog (REST, AWS Glue, Hadoop), query tables with full SQL semantics, selectively accelerate hot datasets for **sub-10ms reads** (down from 500ms–5s on S3), and write back with ACID guarantees via Iceberg's optimistic concurrency protocol — using standard SQL `INSERT INTO`. No Spark required. [Read the Iceberg deep dive →](https://spice.ai/blog/apache-iceberg-at-spice-ai)
### Petabyte-scale hybrid search
Native **Amazon S3 Vectors** (Day 1 launch partner) for billions of vectors at up to 90% lower cost than traditional vector DBs. Plus DuckDB HNSW and Elasticsearch kNN as `.vectors.engine` backends. Spice manages the full lifecycle — ingestion → embedding (AWS Bedrock, HuggingFace, OpenAI, Model2Vec for 500x faster static embeddings, multi-vector ColBERT-style late interaction with MaxSim) → indexing → query. SQL-integrated via `vector_search`, `text_search`, `rrf` (reciprocal rank fusion), and `rerank` UDTFs.
SELECT * FROM rerank(
rrf(
vector_search('docs', 'how does Spice accelerate Iceberg?'),
text_search('docs', 'how does Spice accelerate Iceberg?')
),
document => content
) LIMIT 10;
### Multi-tenancy for AI agents — without per-tenant pipelines
Spin up one Spice runtime per tenant or agent — each with its own sandboxed datasets, accelerators, secrets, and policies. Or share a runtime with config-level tenant isolation. Or do both with a hybrid model. The lightweight runtime makes "one Spicepod per tenant" actually viable — even at high tenant counts. [Read the patterns →](https://spice.ai/blog/multi-tenancy-for-ai-agents-without-pipelines)
### Real-time CDC, the simple way
- **PostgreSQL Native CDC via WAL** — Stream INSERT/UPDATE/DELETE events directly from `pgoutput` logical replication into any local accelerator. **No Debezium or Kafka required.** Auto-managed replication slots and LSN acknowledgement.
- **DynamoDB Streams** — Two-tier acceleration pattern that fans out from a central Spice layer to thousands of edge sidecars with sub-second propagation. Used in production for global control-plane sync. [Read the pattern →](https://spice.ai/blog/real-time-acceleration-with-dynamodb-streams)
- **Debezium + Kafka** — Available when you want it.
### Spice Skills for AI coding agents
Drop-in skills for Claude Code, Cursor, and any agent that supports the open Agent Skills format. Skills auto-activate to set up datasets, connect data sources, configure acceleration, run federated queries, and wire models — without you re-explaining Spice's configuration model.
In Claude Code:
/plugin marketplace add spiceai/skills
[github.com/spiceai/skills](https://github.com/spiceai/skills) | [Read the announcement →](https://spice.ai/blog/introducing-spice-skills-for-ai-coding-agents)
### Acceleration Snapshots
Bootstrap accelerated datasets from S3 in **seconds, not minutes**. Cold-start ephemeral pods with pre-built Vortex/DuckDB/SQLite files. Recover from federated source outages by serving from the last known good snapshot. Critical for sidecar deployments and serverless environments.
### Enterprise hardening (latest)
- **HashiCorp Vault** and **Azure Key Vault** secret stores
- **Read-only API keys** enforced on Flight DoGet and async query paths
- **Provider-aware LLM prompt caching** for cost reduction
- **mTLS** for all internal cluster communication; OpenTelemetry metric export with delta temporality
- **Streamable HTTP MCP transport**, MCP gateway, MCP server
- **30+ data connectors** with shared HTTP rate control, dynamic headers, schema decomposition
## How is Spice different?
1. **Cluster-sidecar architecture** — Each application gets its own Spice sidecar serving SQL, search, and LLM inference on `localhost`, transparently delegating the long tail to a central Spice cluster (Ballista distributed query, Cayenne acceleration, hybrid search indexing) over Arrow Flight. You get three latency tiers in one engine: **results cache (microseconds) → local working set (single-digit milliseconds) → cluster delegation (distributed)**. No other open-source runtime gives you all three behind one connection. [Read the architecture →](https://spice.ai/blog/cluster-sidecar-architecture)
2. **Structural data sandboxing** — Datasets a sidecar doesn't declare in its `spicepod.yaml` are *physically absent from the catalog*, not filtered at query time. The application never holds credentials to Postgres, S3, Snowflake, or Iceberg — only a token to its sidecar. A compromised pod gets a loopback scoped to that tenant's working set, not database credentials.
3. **Ingest once, serve everywhere** — The cluster ingests each source dataset once and produces one authoritative materialization that every sidecar pulls. Source systems see one stable connection pool, not one per pod. Pull-based refresh + acceleration snapshots in S3 mean cold starts in seconds and graceful degradation when the cluster is unreachable.
4. **AI-Native Runtime** — Data query and AI inference live in one engine, so retrieval, ranking, and generation happen in one query plan, in one process — `vector_search`, `text_search`, `rrf`, `rerank`, NSQL, and tool calls are all SQL primitives.
5. **Dual-engine acceleration** — Per-dataset choice of OLAP (Cayenne/Vortex, Arrow, DuckDB) and OLTP (SQLite, PostgreSQL) engines, so you can match workload to engine instead of forcing everything into one shape.
6. **Edge to cloud, single binary** — Runs on a laptop, as a Kubernetes sidecar, as a microservice, or as a multi-node Ballista cluster across edge, on-prem, and public clouds. Self-hosted OSS, Spice Cloud (managed cluster), and Spice.ai Enterprise (on-prem full stack) all use identical `spicepod.yaml` manifests — no app changes to migrate.
If you build with **DataFusion**, **DuckDB**, **Vortex**, **Iceberg**, or **Ballista**, Spice gives you a flexible, production-ready engine you can just use — instead of stitching them together yourself.
## How does Spice compare?
### Data Query and Analytics
| Feature | **Spice** | Trino / Presto | Dremio | ClickHouse | Materialize |
| -------------------------------- | --------------------------------------------------- | -------------------- | --------------------- | ------------------- | ------------------- |
| **Primary Use-Case** | Data & AI apps/agents | Big data analytics | Interactive analytics | Real-time analytics | Real-time analytics |
| **Primary deployment model** | Sidecar + Cluster | Cluster | Cluster | Cluster | Cluster |
| **Federated Query Support** | ✅ | ✅ | ✅ | ❌ | ❌ |
| **Distributed Query Execution** | ✅ (Apache Ballista, multi-active HA) | ✅ | ✅ | ✅ | Limited |
| **Acceleration/Materialization** | ✅ (Cayenne/Vortex, Arrow, SQLite, DuckDB, Postgres) | Intermediate storage | Reflections (Iceberg) | Materialized views | ✅ (Real-time views) |
| **Catalog Support** | ✅ (Iceberg, Unity Catalog, AWS Glue, Databricks) | ✅ | ✅ | ❌ | ❌ |
| **Iceberg Write (SQL INSERT)** | ✅ | ✅ | Limited | ❌ | ❌ |
| **Query Result Caching** | ✅ | ✅ | ✅ | ✅ | Limited |
| **Multi-Modal Acceleration** | ✅ (OLAP + OLTP per dataset) | ❌ | ❌ | ❌ | ❌ |
| **Native CDC** | ✅ (Postgres WAL, DynamoDB Streams, Debezium) | ❌ | ❌ | ❌ | ✅ (Debezium) |
| **Built-in AI / LLM inference** | ✅ | ❌ | ❌ | ❌ | ❌ |
### AI Apps and Agents
| Feature | **Spice** | LangChain | LlamaIndex | AgentOps.ai | Ollama |
| ----------------------------- | ----------------------------------------------------------- | ------------------ | ---------- | ---------------- | ----------------------------- |
| **Primary Use-Case** | Data & AI apps | Agentic workflows | RAG apps | Agent operations | LLM apps |
| **Programming Language** | Any (HTTP / Flight / ODBC / JDBC) | JavaScript, Python | Python | Python | Any language (HTTP interface) |
| **Unified Data + AI Runtime** | ✅ | ❌ | ❌ | ❌ | ❌ |
| **Federated Data Query** | ✅ | ❌ | ❌ | ❌ | ❌ |
| **Distributed Query** | ✅ | ❌ | ❌ | ❌ | ❌ |
| **Accelerated Data Access** | ✅ | ❌ | ❌ | ❌ | ❌ |
| **Tools/Functions** | ✅ (MCP server + gateway, Streamable HTTP) | ✅ | ✅ | Limited | Limited |
| **LLM Memory** | ✅ | ✅ | ❌ | ✅ | ❌ |
| **Hybrid Search** | ✅ (BM25 + vector + RRF + rerank UDTFs) | ✅ | ✅ | Limited | Limited |
| **Caching** | ✅ (query, results, and provider-aware LLM prompt caching) | Limited | ❌ | ❌ | ❌ |
| **Embeddings** | ✅ (Built-in & pluggable; multi-vector ColBERT-style MaxSim) | ✅ | ✅ | Limited | ❌ |
✅ = Fully supported · ❌ = Not supported · Limited = Partial or restricted support
## Example Use-Cases
### Data-grounded Agentic AI Applications
- **OpenAI-compatible AI Gateway**: Hosted (OpenAI, Anthropic, xAI, Bedrock) or local models (Llama, NVIDIA NIM) with Responses API, streaming tool calls, web search, and provider-aware prompt caching. [AI Gateway Recipe](https://github.com/spiceai/cookbook/blob/trunk/openai_sdk/README.md)
- **Federated Data Access**: SQL and NSQL (text-to-SQL) across 30+ sources with advanced push-down, scaling to multi-node Ballista. [Federated SQL Query Recipe](https://github.com/spiceai/cookbook/blob/trunk/federation/README.md)
- **Search and RAG**: Petabyte-scale vector search via Amazon S3 Vectors, BM25 full-text via Tantivy, ColBERT-style multi-vector embeddings with MaxSim, hybrid search with RRF, rerank UDTF. [Amazon S3 Vectors Recipe](https://github.com/spiceai/cookbook/tree/trunk/vectors/s3/README.md)
- **LLM Memory and Observability**: Persistent agent memory + deep visibility into data flows, model performance, and traces. [LLM Memory Recipe](https://github.com/spiceai/cookbook/blob/trunk/llm-memory/README.md) | [Observability Docs](https://spiceai.org/docs/features/observability)
### Database CDN and Query Mesh
- **Co-located acceleration**: Materialize working sets as Cayenne (Vortex), Arrow, SQLite, DuckDB, or Postgres alongside your app for sub-second query. Bootstrap from S3 snapshots. [DuckDB Accelerator Recipe](https://github.com/spiceai/cookbook/blob/trunk/duckdb/accelerator/README.md)
- **Resiliency**: Maintain availability with local replicas of critical datasets; recover from source outages from snapshots. [Local Dataset Replication Recipe](https://github.com/spiceai/cookbook/blob/trunk/localpod/README.md)
- **Responsive dashboards**: Sub-second BI with configurable refresh and CDC. [Sales BI Demo](https://github.com/spiceai/cookbook/blob/trunk/sales-bi/README.md)
- **Legacy modernization**: One endpoint that federates legacy systems with modern infrastructure. [Federation Recipe](https://github.com/spiceai/cookbook/blob/trunk/federation/README.md)
### Multi-Tenant AI Agents
- **One Spicepod per tenant or per agent** — sandboxed datasets, sources, secrets, and policies per agent. The runtime is light enough to make this actually viable. [Patterns →](https://spice.ai/blog/multi-tenancy-for-ai-agents-without-pipelines)
### Retrieval-Augmented Generation (RAG)
- **Hybrid search in SQL**: Combine vector + BM25 with RRF and rerank, in one query plan, against your own data — accelerated.
- **Semantic Knowledge Layer**: Define a semantic context model so agents understand the shape and meaning of your data. [Semantic Model Docs](https://spiceai.org/docs/features/semantic-model)
- **Text-to-SQL**: Built-in NSQL with sampling tools for grounded SQL generation. [Text-to-SQL Recipe](https://github.com/spiceai/cookbook/blob/trunk/text-to-sql/README.md)
## FAQ
- **Is Spice a cache?** Not exactly — think of Spice acceleration as an *active* cache: a materialization or data prefetcher. A cache fetches on miss; Spice prefetches and materializes filtered data on an interval, trigger, or via CDC. Spice also supports [results caching](https://spiceai.org/docs/features/caching).
- **Is Spice a CDN for databases?** Yes — a common use-case is shipping a working set of a database, data lake, or data warehouse to where it's most frequently accessed: data-intensive applications and AI context.
- **Can I use Spice without Spice Cloud?** Yes, the entire runtime is open-source under Apache 2.0. Spice Cloud is an optional managed cluster.
[➡️ Docs FAQ](https://spiceai.org/docs/faq)
### Watch a 30-sec BI dashboard acceleration demo
See more demos on [YouTube](https://www.youtube.com/playlist?list=PLesJrUXEx3U9anekJvbjyyTm7r9A26ugK).
## Supported Data Connectors
| Name | Description | Status | Protocol/Format |
| ---------------------------------- | ------------------------------------- | ----------------- | ---------------------------- |
| `databricks (mode: delta_lake)` | [Databricks][databricks] | Stable | S3/Delta Lake |
| `delta_lake` | Delta Lake | Stable | Delta Lake |
| `dremio` | [Dremio][dremio] | Stable | Arrow Flight |
| `duckdb` | DuckDB | Stable | Embedded |
| `file` | File | Stable | Parquet, CSV |
| `github` | GitHub | Stable | GitHub API |
| `postgres` | PostgreSQL (with native WAL CDC) | Stable | |
| `s3` | [S3][s3] | Stable | Parquet, CSV |
| `mysql` | MySQL | Stable | |
| `spice.ai` | [Spice.ai][spiceai] | Stable | Arrow Flight |
| `dynamodb` | Amazon DynamoDB (with Streams) | Stable | |
| `graphql` | GraphQL | Release Candidate | JSON |
| `cosmosdb` | Azure Cosmos DB (NoSQL) | Release Candidate | |
| `git` | Git repositories | Release Candidate | |
| `snowflake` | Snowflake | Release Candidate | Arrow |
| `adbc` | ADBC | Release Candidate | Arrow |
| `iceberg` | [Apache Iceberg][iceberg] (read+write) | Release Candidate | Parquet |
| `databricks (mode: spark_connect)` | [Databricks][databricks] | Beta | [Spark Connect][spark] |
| `ducklake` | [DuckLake][ducklake] | Beta | Parquet |
| `flightsql` | FlightSQL | Beta | Arrow Flight SQL |
| `mssql` | Microsoft SQL Server | Beta | Tabular Data Stream (TDS) |
| `odbc` | ODBC | Beta | ODBC |
| `spark` | Spark | Beta | [Spark Connect][spark] |
| `sharepoint` | Microsoft SharePoint | Beta | Object-store listing |
| `oracle` | Oracle | Alpha | [Oracle ODPI-C][ODPIC] |
| `abfs` | Azure BlobFS | Alpha | Parquet, CSV |
| `clickhouse` | ClickHouse | Alpha | |
| `debezium` | Debezium CDC | Alpha | Kafka + JSON |
| `elasticsearch` | Elasticsearch (BM25 + kNN + RRF) | Alpha | |
| `gcs`, `gs` | [Google Cloud Storage][gcs] | Alpha | Parquet, CSV, JSON |
| `kafka` | Kafka | Alpha | Kafka + JSON |
| `ftp`, `sftp` | FTP/SFTP | Alpha | Parquet, CSV |
| `glue` | [AWS Glue][glue] | Alpha | Iceberg, Parquet, CSV |
| `http`, `https` | HTTP(s) (dynamic headers, pagination) | Alpha | Parquet, CSV, JSON |
| `imap` | IMAP | Alpha | IMAP Emails |
| `localpod` | [Local dataset replication][localpod] | Alpha | |
| `mongodb` | MongoDB | Alpha | |
| `scylladb` | ScyllaDB | Alpha | |
| `smb` | SMB 3.1.1 | Alpha | SMB |
| `nfs` | NFS | Alpha | Parquet, CSV, JSON |
## Supported Data Accelerators
| Name | Description | Status | Engine Modes |
| ---------- | --------------------------------- | ----------------- | ---------------- |
| `cayenne` | [Spice Cayenne (Vortex)][cayenne] | Release Candidate | `file` |
| `arrow` | [In-Memory Arrow Records][arrow] | Stable | `memory` |
| `duckdb` | Embedded [DuckDB][duckdb] | Stable | `memory`, `file` |
| `postgres` | Attached [PostgreSQL][postgres] | Release Candidate | N/A |
| `sqlite` | Embedded [SQLite][sqlite] | Release Candidate | `memory`, `file` |
## Supported Model Providers
| Name | Description | Status | ML Format(s) | LLM Format(s) |
| ------------- | -------------------------------------------- | ----------------- | ------------ | ------------------------------- |
| `openai` | OpenAI (or compatible) LLM endpoint | Release Candidate | - | OpenAI-compatible HTTP endpoint |
| `file` | Local filesystem | Release Candidate | ONNX | GGUF, GGML, SafeTensor |
| `huggingface` | Models hosted on HuggingFace | Release Candidate | ONNX | GGUF, GGML, SafeTensor |
| `spice.ai` | Models hosted on the Spice.ai Cloud Platform | | ONNX | OpenAI-compatible HTTP endpoint |
| `azure` | Azure OpenAI | | - | OpenAI-compatible HTTP endpoint |
| `bedrock` | Amazon Bedrock (Nova models) | Alpha | - | OpenAI-compatible HTTP endpoint |
| `anthropic` | Models hosted on Anthropic | Alpha | - | OpenAI-compatible HTTP endpoint |
| `xai` | Models hosted on xAI | Alpha | - | OpenAI-compatible HTTP endpoint |
## Supported Embeddings Providers
| Name | Description | Status | ML Format(s) | LLM Format(s) |
| ------------- | -------------------------------------------- | ----------------- | ------------ | -------------------------------------- |
| `openai` | OpenAI (or compatible) embeddings endpoint | Release Candidate | - | OpenAI-compatible embeddings endpoint |
| `file` | Local filesystem | Release Candidate | ONNX | GGUF, GGML, SafeTensor |
| `huggingface` | Models hosted on HuggingFace | Release Candidate | ONNX | GGUF, GGML, SafeTensor |
| `model2vec` | Static embeddings (500x faster) | Release Candidate | Model2Vec | - |
| `azure` | Azure OpenAI | Alpha | - | OpenAI-compatible HTTP endpoint |
| `bedrock` | AWS Bedrock (Titan, Cohere, Nova, Nova 2) | Alpha | - | OpenAI-compatible HTTP endpoint |
## Supported Vector Engines
Configured as `.vectors.engine` on a column-level embedding.
| Name | Description | Status |
| --------------- | -------------------------------------------------------------------- | ------ |
| `s3_vectors` | Amazon S3 Vectors for petabyte-scale vector storage and querying | Alpha |
| `duckdb` | DuckDB with HNSW vector index | Alpha |
| `elasticsearch` | Elasticsearch with kNN | Alpha |
## Supported Catalogs
Catalog Connectors connect to external catalog providers and make their tables available for federated SQL query in Spice. The schema hierarchy of the external catalog is preserved.
| Name | Description | Status | Protocol/Format |
| --------------- | ----------------------- | ------ | ---------------------------- |
| `spice.ai` | Spice.ai Cloud Platform | Stable | Arrow Flight |
| `unity_catalog` | Unity Catalog | Stable | Delta Lake |
| `databricks` | Databricks | Beta | Spark Connect, S3/Delta Lake |
| `iceberg` | Apache Iceberg | Beta | Parquet |
| `ducklake` | DuckLake | Beta | Parquet |
| `glue` | AWS Glue | Alpha | CSV, Parquet, Iceberg |
## Supported Secret Stores
| Name | Description | Status |
| --------------------- | --------------------- | ----------------- |
| `env` | Environment variables | Stable |
| `kubernetes` | Kubernetes secrets | Stable |
| `keyring` | OS keychain | Stable |
| `aws_secrets_manager` | AWS Secrets Manager | Stable |
| `hashicorp_vault` | HashiCorp Vault | Release Candidate |
| `azure_keyvault` | Azure Key Vault | Release Candidate |
## ⚡️ Quickstart (Local Machine)
### Installation
Install the Spice CLI:
On **macOS, Linux, and WSL**:
curl https://install.spiceai.org | /bin/bash
Or using `brew`:
brew install spiceai/spiceai/spice
On **Windows** using PowerShell:
iex ((New-Object System.Net.WebClient).DownloadString("https://install.spiceai.org/Install.ps1"))
### Usage
**Step 1.** Initialize a new Spice app with the `spice init` command:
spice init spice_qs
A `spicepod.yaml` file is created in the `spice_qs` directory. Change to that directory:
cd spice_qs
**Step 2.** Start the Spice runtime:
spice run
Example output will be shown as follows:
2025/01/20 11:26:10 INFO Spice.ai runtime starting...
2025-01-20T19:26:10.679068Z INFO runtime::init::dataset: No datasets were configured. If this is unexpected, check the Spicepod configuration.
2025-01-20T19:26:10.679716Z INFO runtime::flight: Spice Runtime Flight listening on 127.0.0.1:50051
2025-01-20T19:26:10.679786Z INFO runtime::metrics_server: Spice Runtime Metrics listening on 127.0.0.1:9090
2025-01-20T19:26:10.680140Z INFO runtime::http: Spice Runtime HTTP listening on 127.0.0.1:8090
2025-01-20T19:26:10.879126Z INFO runtime::init::results_cache: Initialized sql results cache; max size: 128.00 MiB, item ttl: 1s
The runtime is now started and ready for queries.
**Step 3.** In a new terminal window, add the `spiceai/quickstart` Spicepod. A Spicepod is a package of configuration defining datasets and ML models.
spice add spiceai/quickstart
The `spicepod.yaml` file will be updated with the `spiceai/quickstart` dependency.
version: v1
kind: Spicepod
name: spice_qs
dependencies:
- spiceai/quickstart
The `spiceai/quickstart` Spicepod will add a `taxi_trips` data table to the runtime which is now available to query by SQL.
2025-01-20T19:26:30.011633Z INFO runtime::init::dataset: Dataset taxi_trips registered (s3://spiceai-demo-datasets/taxi_trips/2024/), acceleration (arrow), results cache enabled.
2025-01-20T19:26:30.013002Z INFO runtime::accelerated_table::refresh_task: Loading data for dataset taxi_trips
2025-01-20T19:26:40.312839Z INFO runtime::accelerated_table::refresh_task: Loaded 2,964,624 rows (399.41 MiB) for dataset taxi_trips in 10s 299ms
**Step 4.** Start the Spice SQL REPL:
spice sql
The SQL REPL interface will be shown:
Welcome to the Spice.ai SQL REPL! Type 'help' for help.
show tables; -- list available tables
sql>
Enter `show tables;` to display the available tables for query:
sql> show tables;
+---------------+--------------+---------------+------------+
| table_catalog | table_schema | table_name | table_type |
+---------------+--------------+---------------+------------+
| spice | public | taxi_trips | BASE TABLE |
| spice | runtime | query_history | BASE TABLE |
| spice | runtime | metrics | BASE TABLE |
+---------------+--------------+---------------+------------+
Time: 0.022671708 seconds. 3 rows.
Enter a query to display the longest taxi trips:
SELECT trip_distance, total_amount FROM taxi_trips ORDER BY trip_distance DESC LIMIT 10;
Output:
+---------------+--------------+
| trip_distance | total_amount |
+---------------+--------------+
| 312722.3 | 22.15 |
| 97793.92 | 36.31 |
| 82015.45 | 21.56 |
| 72975.97 | 20.04 |
| 71752.26 | 49.57 |
| 59282.45 | 33.52 |
| 59076.43 | 23.17 |
| 58298.51 | 18.63 |
| 51619.36 | 24.2 |
| 44018.64 | 52.43 |
+---------------+--------------+
Time: 0.045150667 seconds. 10 rows.
## ⚙️ Container & Cluster Deployment
### Docker
docker pull spiceai/spiceai
FROM spiceai/spiceai:latest
### Helm (Kubernetes)
helm repo add spiceai https://helm.spiceai.org
helm install spiceai spiceai/spiceai
### AWS Marketplace
Spice is available in the [AWS Marketplace](https://aws.amazon.com/marketplace/pp/prodview-jmf6jskjvnq7i).
### Distributed cluster (Apache Ballista)
Run Spice as a multi-node cluster: start scheduler nodes with `--role scheduler` and start executor nodes with `--scheduler-address ` to join them. Multi-active schedulers coordinate through your object store (configured via `runtime.scheduler.state_location`) — no etcd, ZooKeeper, or Redis. mTLS certificates are managed via the Spice CLI. See the [Ballista architecture deep dive](https://spice.ai/blog/apache-ballista-at-spice-ai) and the [distributed query docs](https://spiceai.org/docs/features/query-federation).
## 🏎️ Next Steps
### Add Spice Skills to your AI coding agent
Drop-in skills for Claude Code, Cursor, and more.
In Claude Code (slash command):
/plugin marketplace add spiceai/skills
In Cursor and other agents (shell):
npx skills add spiceai/skills
### Explore the Spice.ai Cookbook
86+ recipes and end-to-end examples — federation, acceleration, search, RAG, agents, CDC, and more — at [github.com/spiceai/cookbook](https://github.com/spiceai/cookbook#readme).
### Use the Spice.ai Cloud Platform (optional)
Access ready-to-use Spicepods and datasets hosted on the Spice.ai Cloud Platform with the open-source Spice runtime. Browse public Spicepods at [spicerack.org](https://spicerack.org/).
To use public datasets, create a free account on Spice.ai:
1. Visit [spice.ai](https://spice.ai/) and click **Try for Free**.
2. After creating an account, create an app to generate an API key.
Once set up, you can access ready-to-use Spicepods including datasets. For this demonstration, use the `taxi_trips` dataset from the [Spice.ai Quickstart](https://spice.ai/spiceai/quickstart).
**Step 1.** Initialize a new project.
spice init spice_app
cd spice_app
**Step 2.** Log in and authenticate. A pop-up browser window will prompt you to authenticate:
spice login
**Step 3.** Start the runtime:
spice run
**Step 4.** Configure the dataset:
In a new terminal window:
spice dataset configure
dataset name: (spice_app) taxi_trips
description: Taxi trips dataset
from: spice.ai/spiceai/quickstart/datasets/taxi_trips
Locally accelerate (y/n)? y
**Step 5.** Query from the SQL REPL:
spice sql
SELECT tpep_pickup_datetime, passenger_count, trip_distance from taxi_trips LIMIT 10;
### 📄 Documentation
Comprehensive documentation at [spiceai.org/docs](https://spiceai.org/docs/).
### 🔌 Extensibility
Spice.ai is designed to be extensible. See [EXTENSIBILITY.md](./docs/EXTENSIBILITY.md) to build custom [Data Connectors](https://spiceai.org/docs/components/data-connectors), [Data Accelerators](https://spiceai.org/docs/components/data-accelerators), [Catalog Connectors](https://spiceai.org/docs/components/catalogs), [Secret Stores](https://spiceai.org/docs/components/secret-stores), [Models](https://spiceai.org/docs/components/models), or [Embeddings](https://spiceai.org/docs/components/embeddings).
### 🔨 Roadmap
🚀 See the [Roadmap](https://github.com/spiceai/spiceai/blob/trunk/docs/ROADMAP.md). Highlights:
- **[v2.0](https://github.com/spiceai/spiceai/milestone/58) (June 2026)** — Cayenne GA, multi-active HA GA, distributed query GA, mTLS, Cedar policy engine (Beta)
- **[v2.1](https://github.com/spiceai/spiceai/milestone/95) (July 2026)** — Distributed search, schema registry, schema evolution
- **[v2.2](https://github.com/spiceai/spiceai/milestone/99) (September 2026)** — Webhooks, reactive event-driven actions (Drasi-based)
### 🤝 Connect with us
- 📰 Read our [blog](https://spice.ai/blog) for engineering deep dives
- 💬 Join the conversation on [Slack](https://spice.ai/slack), [X](https://twitter.com/spice_ai), or [LinkedIn](https://www.linkedin.com/company/74148478)
- 🐛 [File an issue](https://github.com/spiceai/spiceai/issues/new) — we triage fast
- 💼 We're hiring! See [spice.ai/careers](https://spice.ai/careers)
- 🛠️ Contribute code or docs (see [CONTRIBUTING.md](CONTRIBUTING.md))
- ✉️ Send feedback to [hey@spice.ai](mailto:hey@spice.ai)
⭐️ **Star this repo** to follow along — it helps us a ton, and you'll see new releases as they ship. 🙏